论文:StructGPT: A General Framework for Large Language Model to Reason over Structured Data
会议:EMNLP 2023
作者:Jinhao Jiang et al.(人大 RUCAI)
核心关键词:KG|LLM Reason|General Framework | KGQA | TableQA
一、研究背景与问题定义
1. 研究背景
近年来,大语言模型(LLMs)在结构化数据推理方面仍存在明显不足。
基于结构化数据的推理,形式上,可以被描述为一个问题回答任务:
给定 问题q 和 结构化数据S(例如,知识图、表或数据库),LLM需要从S中提取有用数据 ,然后基于有用数据来回答问题q。
常见结构化数据包括:
- 知识图谱(Knowledge Graph, KG)
- 数据表(Table)
- 关系型数据库(Database, DB)
这些数据具有明确的模式(schema)和结构,但 LLM 在预训练过程中主要接触自然语言文本,对结构化格式理解有限。
2. 现有方法的局限性
| 方法类型 | 局限 |
|---|---|
| 直接线性化结构化数据 | 输入过长、噪声大、上下文溢出 |
| 专用神经模型(GNN / Table Transformer) | 任务不通用、需要监督训练 |
| Text-to-Text(如 UnifiedSKG) | 仍受输入长度限制,难以扩展 |
核心问题:
- LLM 擅长推理,但不擅长理解结构化数据;
- 结构化数据易于查询,但LLM缺乏推理能力。
二、核心思想(Key Idea)
StructGPT 的核心思想是:
将"读取数据(Reading)"与"推理决策(Reasoning)"解耦。
- Reading:由结构化数据的接口(Interface)完成
- Reasoning:由大语言模型完成
通过这种方式,让 LLM 只专注于推理决策,而不直接操作复杂的结构化数据。
三、方案概述
本文提出了一个基于结构化数据的IRR(Iterative Reading-then Reasoning,迭代阅读推理 )框架StructGPT。
在 StructGPT 中,将结构化数据封装为一个黑盒系统,并为LLM提供了访问所包含数据的特定接口 。
模型推理被组织为一个 Iterative Reading-then-Reasoning(IRR) 过程。每一轮推理包含三个阶段:
bash
接口调用(Invoking)
↓
信息线性化(Linearization)
↓
LLM 生成(Generation)通过使用提供的接口不断进行IRR的迭代,逐步收集证据并逼近最终答案,直到模型生成最终答案或满足终止条件。
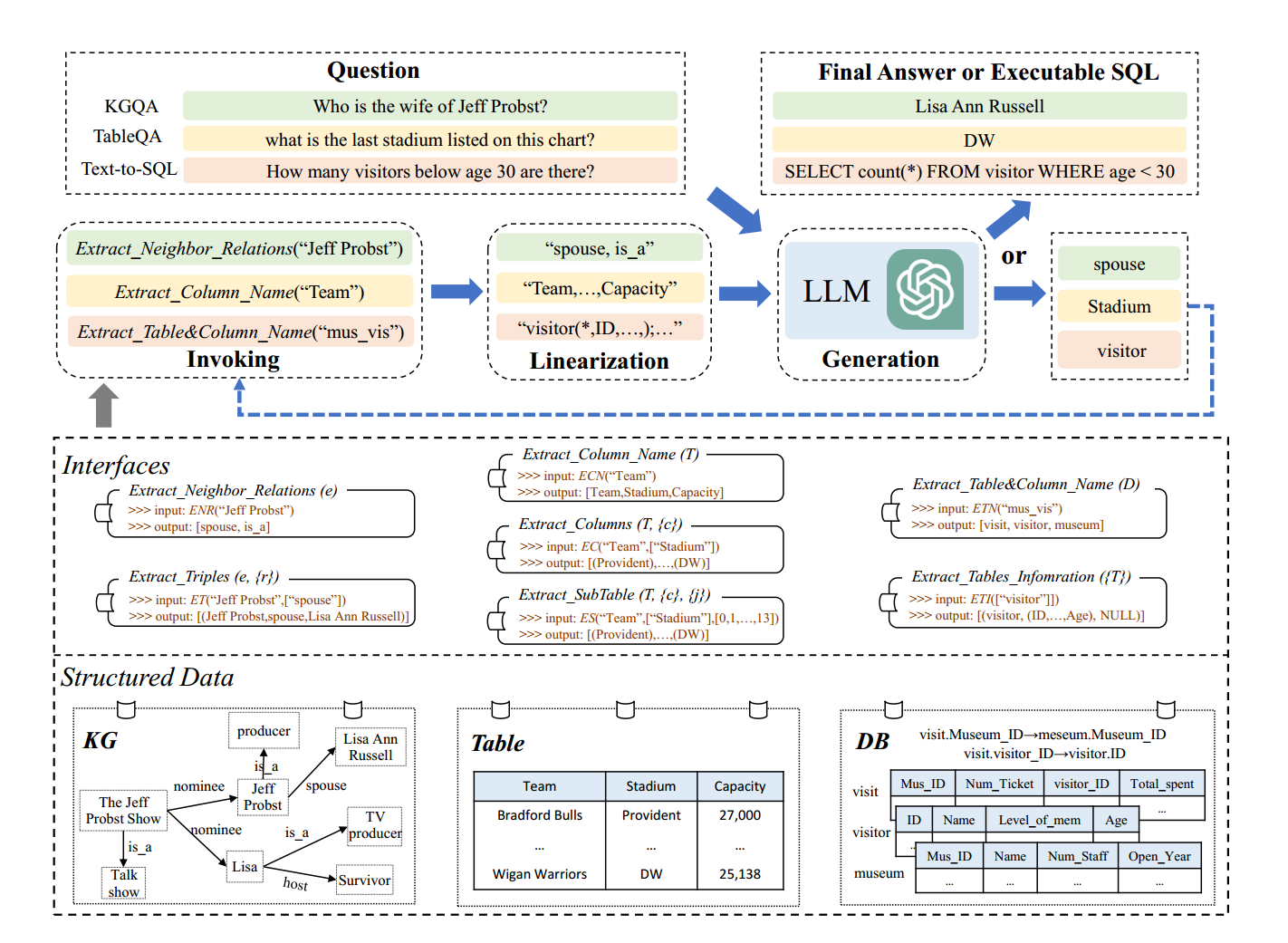
四、接口设计
1. 知识图谱接口(KG)
用于支持多跳推理:
-
Extract_Neighbor_Relations(e) : 获取实体
e的所有邻接关系 -
Extract_Triples(e, {r}) : 获取实体
e在指定关系{r}下的三元组
2. 表格接口(Table)
模拟人类"看表"的过程:
- Extract_Column_Name(T):获取列名
- Extract_Columns(T, {c}):获取指定列内容
- Extract_SubTable(T, {c}, {j}):获取子表
3. 数据库接口(Database / Text-to-SQL)
支持 Schema 感知的 SQL 生成:
- Extract_Table&Column_Name(D)
- Extract_Tables_Information({T})(包含外键信息)
五、Iterative Reading-then-Reasoning描述
1. Invoking(接口调用)
基于当前可用的数据作为输入,调用接口,获取更详细的相关信息。
再将详细信息馈送到LLM中以用于收集有用信息或生成答案。
2. Linearization(信息线性化)
将接口返回的结构化结果转换为 LLM 可理解的文本。
对于KG中的信息(即关系和三元组),会将它们连接成一个由特定分隔和边界符号标记的长句。
- 降低噪声
- 控制上下文长度
- 保留结构语义
3. Generation(LLM 生成)
线性化后,本文为LLM设计了两种类型的输入提示,以满足不同的需求,
LLM 在每一轮只执行两类任务之一:
-
信息选择
从候选信息中选择与问题最相关的部分
-
结果生成
生成最终答案或可执行表达式(如 SQL)
通过在设计的接口上迭代IRR过程,LLM可以逐步捕获更多有用的证据来推导最终答案。

六、下游任务实例化
1. KGQA(知识图谱问答)
- 识别主题实体
- 选择相关关系
- 提取三元组
- 多跳迭代直至得到答案
2. TableQA(表格问答)
- 选择相关列
- 选择相关行
- 构建子表
- 基于子表生成答案
3. Text-to-SQL(数据库语义解析)
- 选择相关表
- 获取 schema 与外键
- 生成可执行 SQL
七、实验结论
八、方法优势与局限
优势
-
StructGPT 在 零样本(zero-shot) 和 少样本(few-shot) 场景下效果显著
-
在多个数据集上,性能可接近甚至对标监督训练模型
-
框架具备良好的 通用性与可迁移性
-
统一支持 KG / Table / DB
-
不依赖模型微调
-
接口 + LLM 解耦设计清晰
局限与框架的常见错误
- 强依赖 LLM 的指令遵循能力
- 接口需人工设计
- Selection Error 仍然显著
该框架的常见错误包括:
- Selection Error:关键信息未被选中
- Reasoning Error:信息正确但推理失败
- Hallucination:生成内容与数据不一致
- 格式错误
不同任务的主要瓶颈不同:
- KGQA:信息选择困难
- Text-to-SQL:复杂推理难度高
原文链接
StructGPT: A General Framework for Large Language Model to Reason over Structured Data