trtllm-serve启动流程--HTTP Request
- TensorRT-LLM软件流程系列一和二 Blog写了加载模型和启动server整个流程,server启动之后就是接收http请求
- 这篇博客主要介绍server端接收HTTP Request,并且对request处理生成response整个流程
Register Routes
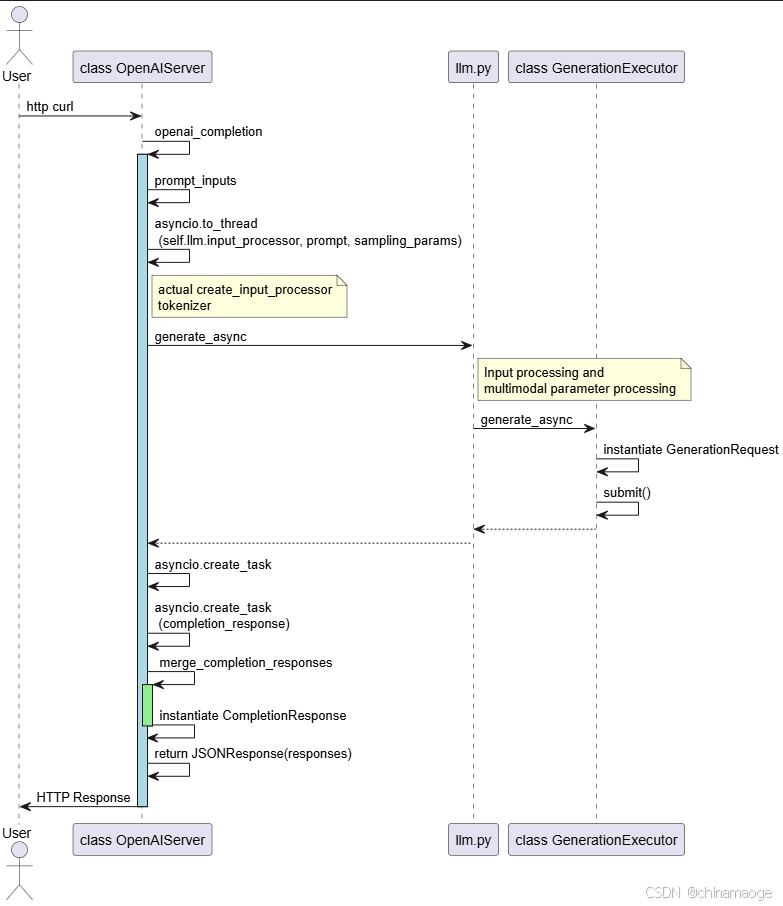
- OpenAIServer init的时候会调用register_routes function,对请求的类型注册到router中,当接收到对应请求的时候会调用对应的处理函数
- 使用curl请求作为client端向server发送请求,其中类型是/v1/completions,所以执行openai_responses function
py
// tensorrt_llm\serve\openai_server.py
def register_routes(self):
self.app.add_api_route("/health", self.health, methods=["GET"])
self.app.add_api_route("/kv_cache_events", self.get_kv_cache_events, methods=["POST"])
self.app.add_api_route("/v1/completions",
self.openai_completion,
methods=["POST"])
self.app.add_api_route("/v1/chat/completions",
self.openai_chat if not self.use_harmony else self.chat_harmony,
methods=["POST"])
self.app.add_api_route("/v1/responses",
self.openai_responses,
methods=["POST"])
if self.llm.args.return_perf_metrics:
# register /prometheus/metrics
self.mount_metrics()
//curl http请求
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3-7B/",
"prompt": "Please describe what is Qwen.",
"max_tokens": 12,
"temperature": 0
}'openai_completion
- prompt_inputs function把input prompt 转化为TextPrompt instance,然后对TextPrompt 消息进行tokenizer
- 通过asyncio.to_thread把任务线程池处理,因为之前input_processor已经在create_input_processor function中赋值为DefaultInputProcessor,所以会直接调用DefaultInputProcessor class call function
- call function会调用之前设置qwen大模型专用的tokenizer(运行trtllm-serve,设置的参数--tokenizer ./tmp/Qwen/7B/)把prompt先分词为单个token,再把单个token转化为对应的数字 ID(即 prompt_token_ids)
- generate_async function实例化GenerationRequest,然后submit到任务queue中
py
// tensorrt_llm\serve\openai_server.py
prompt_token_ids, extra_processed_inputs = await asyncio.to_thread(self.llm.input_processor, prompt, sampling_params)
self.input_processor = create_input_processor(self._hf_model_dir,
self.tokenizer)
//tensorrt_llm\inputs\registry.py
class DefaultInputProcessor(InputProcessor):
"""Preprocess the inputs to the model."""
def __init__(self,
model_path,
model_config,
tokenizer,
trust_remote_code: bool = True) -> None:
self.tokenizer = tokenizer
self.model_config = model_config
self.model_path = model_path
self.multimodal_hashing_supported = None
def __call__(
self, inputs: TextPrompt, sampling_params: SamplingParams
) -> Tuple[List[int], Optional[ExtraProcessedInputs]]:
"""The default input processor handles only tokenization."""
with nvtx_range_debug("tokenize prompt"):
try:
token_ids = self.tokenizer.encode(
inputs["prompt"],
add_special_tokens=sampling_params.add_special_tokens,
**kwargs)
except:
# Tiktoken path
token_ids = self.tokenizer.encode(
inputs["prompt"], allowed_special=toktoken_special_tokens)
return token_ids, None- submit执行结束之后create_task function execution of a coroutine object in a spawn task
- merge_completion_responses function instantiate CompletionResponse
- 最后JSONResponse接口将模型生成的结果CompletionResponse,按 OpenAI API 协议封装为标准 JSON 响应,返回给客户端
流程图:
submit
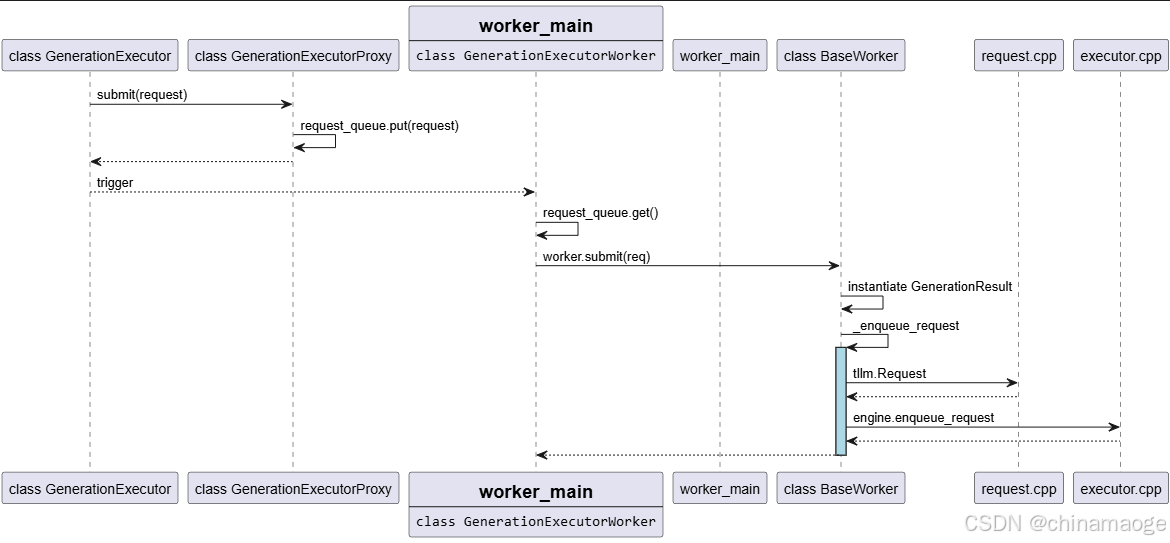
- submit函数主要功能是把request发送到大模型中进行处理
- self 执行submit function实际执行的是class GenerationExecutorProxy中的submit function,因为之前self._executor = self._executor_cls.create就是instance GenerationExecutorProxy
py
## tensorrt_llm\executor\executor.py
def generate_async():
result = self.submit(request)
## tensorrt_llm\executor\proxy.py
def submit(self, request: GenerationRequest) -> GenerationResult:
with nvtx_range_debug("request_queue.put"):
self.request_queue.put(request)
## tensorrt_llm\executor\worker.py
## class GenerationExecutorWorker
def worker_main function(){
request_queue = IpcQueue(worker_queues.request_queue_addr,
is_server=False,
name="worker_request_queue")
with worker:
try:
worker.block_subordinates()
if is_leader:
if postproc_worker_config.enabled:
worker.set_postproc_queues(result_queues)
else:
worker.set_result_queue(result_queue)
# Send ready signal with confirmation
ready_msg = (ready_signal, None)
if not worker_init_status_queue.notify_with_retry(ready_msg):
logger.warning(
"Failed to deliver ready signal to proxy, continuing anyway"
)
while (req := request_queue.get()) is not None:
if isinstance(req, CancellingRequest):
worker.abort_request(req.id)
elif isinstance(req, GenerationRequest):
try:
worker.submit(req)
except RequestError as e:
logger.error(f"submit request failed: {e}")
logger.error(traceback.format_exc())
worker._await_response_helper.temp_error_responses.put(
ErrorResponse(req.id, e, req.id))
else:
raise ValueError(f"Unknown request type: {type(req)}")- class GenerationExecutorProxy submit function把request加入request_queue中等待worker_main function中获取处理
- worker_main function获取request,直接调用worker.submit(req)处理,实际执行是class BaseWorker submit function
- 通过Request 构建GenerationResult,并且与client_id相对应
- 使用tllm.Request调用到C++ Layer instantiate Request任务
- 创建成功executor_request之后,self.engine.enqueue_request(executor_request)执行到C++ Layer executor.cpp中,因为Engine就是实例化的C++ class Executor
- 特别注意:在_enqueue_request代码中有对MULTIMODAL的注释,目前仅 PyTorch Backend 支持多模态输入的处理,TensorRT backen 目前应该是不支持的(2025/11/2 version,main branch)
流程图:
tllm.Request and engine.enqueue_request
- 从Python Layer 到C++ Layer 都是需要通过pybind中间件转化,
- Request调用到request.cpp中逻辑就是实例化,然后对参数进行赋值
cpp
//cpp\tensorrt_llm\pybind\executor\request.cpp
py::class_<tle::Request> request(m, "Request", pybind11::dynamic_attr());
//cpp\tensorrt_llm\executor\request.cpp
Request::Request(VecTokens inputTokenIds, SizeType32 maxTokens, bool streaming, SamplingConfig const& samplingConfig,
OutputConfig const& outputConfig, std::optional<SizeType32> const& endId, std::optional<SizeType32> const& padId,
std::optional<std::vector<SizeType32>> positionIds, std::optional<std::list<VecTokens>> badWords,
std::optional<std::list<VecTokens>> stopWords, std::optional<Tensor> embeddingBias,
std::optional<ExternalDraftTokensConfig> externalDraftTokensConfig, std::optional<PromptTuningConfig> pTuningConfig,
std::optional<MultimodalInput> multimodalInput, std::optional<Tensor> multimodalEmbedding,
std::optional<MropeConfig> mRopeConfig, std::optional<LoraConfig> loraConfig,
std::optional<LookaheadDecodingConfig> lookaheadConfig,
std::optional<KvCacheRetentionConfig> kvCacheRetentionConfig, std::optional<std::string> logitsPostProcessorName,
std::optional<LogitsPostProcessor> logitslogitsPostProcessor, std::optional<VecTokens> encoderInputTokenIds,
std::optional<IdType> clientId, bool returnAllGeneratedTokens, float priority, RequestType type,
std::optional<ContextPhaseParams> contextPhaseParams, std::optional<Tensor> encoderInputFeatures,
std::optional<SizeType32> encoderOutputLength, std::optional<Tensor> crossAttentionMask,
SizeType32 numReturnSequences, std::optional<EagleConfig> eagleConfig, std::optional<Tensor> skipCrossAttnBlocks,
std::optional<GuidedDecodingParams> guidedDecodingParams, std::optional<SizeType32> languageAdapterUid,
std::optional<MillisecondsType> allottedTimeMs, std::optional<CacheSaltIDType> cacheSaltID)
: mImpl(std::make_unique<Impl>(std::move(inputTokenIds), maxTokens, streaming, samplingConfig, outputConfig, endId,
padId, std::move(positionIds), std::move(badWords), std::move(stopWords), std::move(embeddingBias),
std::move(externalDraftTokensConfig), std::move(pTuningConfig), std::move(multimodalInput),
std::move(multimodalEmbedding), std::move(mRopeConfig), std::move(loraConfig), lookaheadConfig,
std::move(kvCacheRetentionConfig), std::move(logitsPostProcessorName), std::move(logitslogitsPostProcessor),
std::move(encoderInputTokenIds), clientId, returnAllGeneratedTokens, priority, type,
std::move(contextPhaseParams), std::move(encoderInputFeatures), encoderOutputLength, crossAttentionMask,
numReturnSequences, eagleConfig, skipCrossAttnBlocks, std::move(guidedDecodingParams), languageAdapterUid,
allottedTimeMs, cacheSaltID))
{
}
//cpp\tensorrt_llm\executor\executor.cpp
IdType Executor::enqueueRequest(Request const& llmRequest)
{
return mImpl->enqueueRequest(llmRequest);
}
//cpp\tensorrt_llm\executor\executorImpl.cpp
IdType Executor::Impl::enqueueRequest(Request const& request)
{
return enqueueRequests({&request, 1}).at(0);
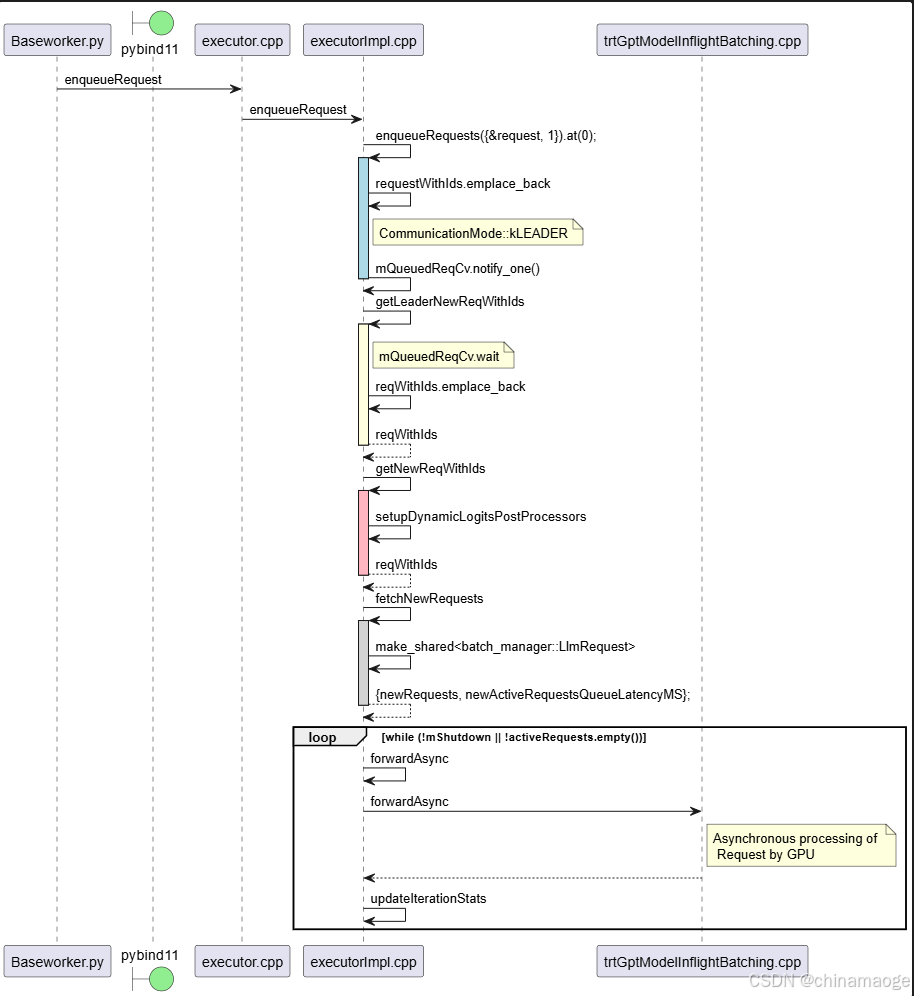
}- enqueueRequest function在Executor中的调用会经过Executor::Impl中转
- 当executorImpl 中执行enqueueRequest,发送mQueuedReqCv.notify_one消息会对getLeaderNewReqWithIds function中mQueuedReqCv.wait激活
- 取出nextRequest push到reqWithIds中。然后return到getNewReqWithIds function
- getNewReqWithIds执行完之后return到最外层while循环,执行forwardAsyn function,进而调用TrtGptModelInflightBatching forwardAsyn,在forwardAsyn中实现GPU异步处理Request请求
- 最后执行updateIterationStats和updateRequestStats
- executionLoop function是在 Executor::Impl::initialize中执行的,这个是在TensorRT LLM初始化的流程中会执行到的函数
cpp
// Executor::Impl::initialize function
mExecutionThread = std::thread(&Impl::executionLoop, this);流程图:
cpp
//executorImpl.cpp
// Executor::Impl::loadModel 赋值流程
mModel = createModel(rawEngine, modelConfig, worldConfig, executorConfig);
std::shared_ptr<Model> Executor::Impl::createModel(runtime::RawEngine const& rawEngine,
runtime::ModelConfig const& modelConfig, runtime::WorldConfig const& worldConfig,
ExecutorConfig const& executorConfig)
{
auto const gptModelType = [&executorConfig, &modelConfig]()
{
switch (executorConfig.getBatchingType())
{
case BatchingType::kSTATIC:
TLLM_THROW(
"Static batching type is deprecated. Please use in-flight batching with "
"CapacitySchedulerPolicy::kSTATIC_BATCH instead.");
case BatchingType::kINFLIGHT:
return modelConfig.isRnnBased() ? batch_manager::TrtGptModelType::InflightBatching
: batch_manager::TrtGptModelType::InflightFusedBatching;
default: TLLM_THROW("Invalid batching strategy");
}
}();
bool const isLeaderInOrchMode = (mCommMode == CommunicationMode::kORCHESTRATOR) && mIsLeader;
auto const& fixedExecutorConfig = executorConfigIsValid(executorConfig, modelConfig)
? executorConfig
: fixExecutorConfig(executorConfig, modelConfig);
std::cout << "Entering Impl() createModel gptModelType :"<< std::endl;
return batch_manager::TrtGptModelFactory::create(
rawEngine, modelConfig, worldConfig, gptModelType, fixedExecutorConfig, isLeaderInOrchMode);
}
//trtGptModelFactory.h
static std::shared_ptr<TrtGptModel> create(runtime::RawEngine const& rawEngine,
runtime::ModelConfig const& modelConfig, runtime::WorldConfig const& worldConfig, TrtGptModelType modelType,
executor::ExecutorConfig const& executorConfig, bool isLeaderInOrchMode)
{
auto logger = std::make_shared<runtime::TllmLogger>();
auto const device = worldConfig.getDevice();
auto const rank = worldConfig.getRank();
TLLM_LOG_INFO("Rank %d is using GPU %d", rank, device);
TLLM_CUDA_CHECK(cudaSetDevice(device));
std::cout << "modelType = " << static_cast<int>(modelType) << std::endl;
if ((modelType == TrtGptModelType::InflightBatching) || (modelType == TrtGptModelType::InflightFusedBatching))
{
executor::ExecutorConfig const& fixedExecutorConfig
= TrtGptModelInflightBatching::executorConfigIsValid(modelConfig, executorConfig)
? executorConfig
: TrtGptModelInflightBatching::fixExecutorConfig(modelConfig, executorConfig);
bool const ctxGenFusion = modelType == TrtGptModelType::InflightFusedBatching;
return std::make_shared<TrtGptModelInflightBatching>(
logger, modelConfig, worldConfig, rawEngine, ctxGenFusion, fixedExecutorConfig, isLeaderInOrchMode);
}
throw std::runtime_error("Invalid modelType in trtGptModelFactory");
}
//调用
void Executor::Impl::forwardAsync(RequestList& activeRequests)
{
try
{
TLLM_LOG_DEBUG("num active requests in scope: %d", activeRequests.size());
mModel->forwardAsync(activeRequests);
}
}
forwardAsync中调用mModel->forwardAsync,mModel赋值是在create中赋值为TrtGptModelInflightBatching class 实例forwardAsync
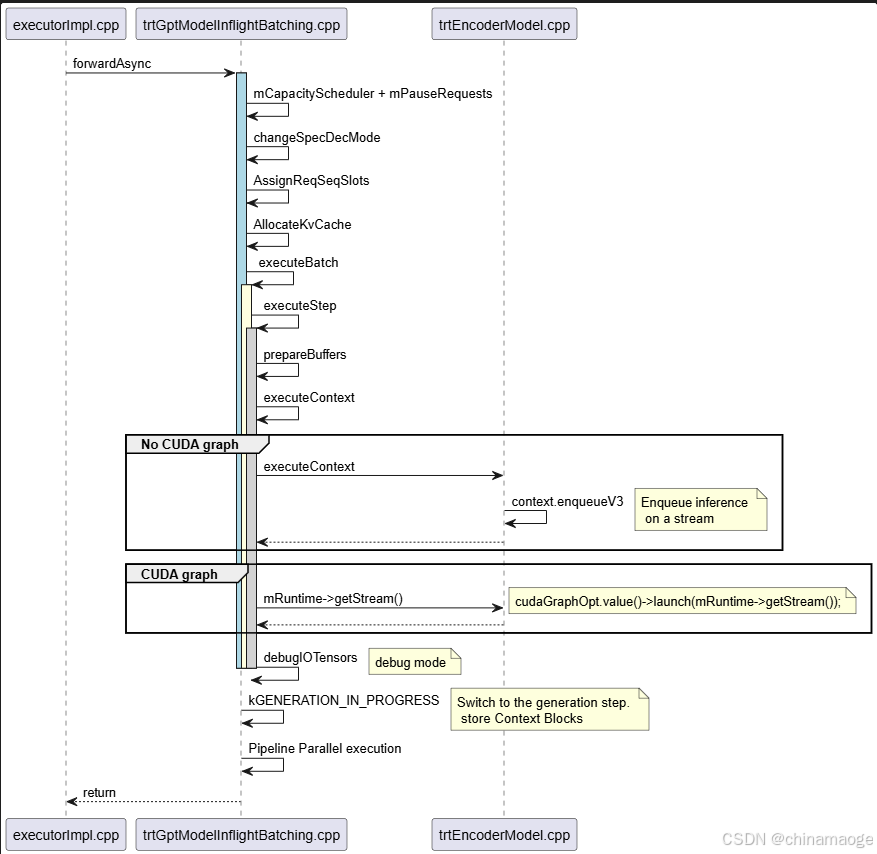
- class TrtGptModelInflightBatching forwardAsync function负责异步调度和执行 LLM 解码阶段的请求。
- mCapacityScheduler对activeRequests通过MaxRequestsScheduler、MaxUtilizationScheduler、GuaranteedNoEvictScheduler三种算法进行调度,产生出fittingRequests(可执行)、requestsToPause(需暂停)分类。 然后在mPauseRequests中对需暂停请求(requestsToPause)执行 "资源释放 + 状态更新 + 移出活跃队列" 的操作。这两个操作对Request实现的动态优先级调度。
cpp
// TensorRT-LLM-main\cpp\tensorrt_llm\batch_manager\capacityScheduler.cpp
std::tuple<RequestVector, RequestVector, RequestVector> CapacityScheduler::operator()(RequestList const& activeRequests,
OptionalRef<kv_cache_manager::BaseKVCacheManager> kvCacheManager,
OptionalRef<BasePeftCacheManager const> peftCacheManager,
OptionalRef<kv_cache_manager::BaseKVCacheManager const> crossKvCacheManager) const
{
NVTX3_SCOPED_RANGE(capacitySchedulerScheduling);
return std::visit(
[&activeRequests, &kvCacheManager, &crossKvCacheManager, &peftCacheManager](
auto const& scheduler) -> std::tuple<RequestVector, RequestVector, RequestVector>
{
RequestVector tmpFittingRequests;
RequestVector pausedRequests;
if constexpr (std::is_same_v<std::decay_t<decltype(scheduler)>, MaxRequestsScheduler>)
{
std::tie(tmpFittingRequests, pausedRequests) = scheduler(activeRequests);
}
else if constexpr (std::is_same_v<std::decay_t<decltype(scheduler)>, MaxUtilizationScheduler>)
{
std::tie(tmpFittingRequests, pausedRequests)
= scheduler(*kvCacheManager, peftCacheManager, activeRequests);
}
else if constexpr (std::is_same_v<std::decay_t<decltype(scheduler)>, GuaranteedNoEvictScheduler>
|| std::is_same_v<std::decay_t<decltype(scheduler)>, StaticBatchScheduler>)
{
std::tie(tmpFittingRequests, pausedRequests)
= scheduler(*kvCacheManager, crossKvCacheManager, peftCacheManager, activeRequests);
}
else
{
throw std::runtime_error("Unsupported capacity scheduler policy");
}
TLLM_LOG_DEBUG("[Summary] Capacity scheduler allows %d requests, pauses %d requests",
tmpFittingRequests.size(), pausedRequests.size());
RequestVector fittingRequests;
RequestVector fittingDisaggGenInitRequests;
for (auto const& llmReq : tmpFittingRequests)
{
if (llmReq->isDisaggGenerationInitState())
{
fittingDisaggGenInitRequests.push_back(llmReq);
}
else
{
fittingRequests.push_back(llmReq);
}
}
return {std::move(fittingRequests), std::move(fittingDisaggGenInitRequests), std::move(pausedRequests)};
},
mScheduler);
}
这段代码我觉得写得高效并且简洁,
constexpr编译器期间确定scheduler,std::visit安全访问 variant 存储的实际类型,std::tie简化 Tuple 解包,一次性赋值
在MaxUtilizationScheduler中的调度方法中,会使用如下原则调度Request
//MaxUtilizationScheduler::operator() function capacityScheduler.cpp
auto startedReqLambda = [this](std::shared_ptr<LlmRequest> const& req)
{
return (req->hasReachedState(getNoScheduleUntilState()) && !req->hasReachedState(getNoScheduleAfterState())
&& ((req->isContextInitState() && !req->isFirstContextChunk()) || req->isGenerationInProgressState()));
};
原本我有一个疑问:如果是相同优先级,那一个Request换一个意义在哪里?
答案其实是注释写的:Find last active in case we need to evict
最久没有活跃的Request硬件的使用效率基本就是最低,可以先evict出来pause,替换硬件效率高的Request先处理,这个理念符合Max Utilization
在TensorRT LLM中并没有通过优先级调度Request,因为Request优先级是业务逻辑,需要用户自己来定义,所以TensorRT LLM原生没有这部分功能的- changeSpecDecMode中会切换Speculative Decoding Mode,目前只有一种Lookahead算法
- AssignReqSeqSlots会对Request通过slot进行承接,实现 GPU 显存 / 计算资源的预分配与复用,避免动态内存开销和显存碎片;支撑 Inflight Batching 动态调度,突破静态批处理的效率瓶颈;统一管控序列全生命周期状态,确保推理连贯性与可追溯性,这种设计方式对同一个slot 多个Request是可以KV cache复用
- executeBatch实现使用GPU处理Request,其中有通过prepareBuffers调用prepareStep,实现将用户的推理请求(上下文请求 + 生成请求)转换为模型推理所需的GPU 缓冲区数据
- executeContext 中会先获取是否有CudaGraph,分两条路线执行。如果没有就直接enqueue到cuda stream,如果有就通过cuda graph来执行
- 在debug 模式下会保存IO Tensors信息,查看输出异常是logic tensor或者其他元素导致的,IO tensor的意思是inputMap、outputMap中的数据
- executeBatch中对GenFusion做区分,如果没有fusion会对contextRequests、generationRequests分别执行executeStep。
- 后面会对contextRequests的处理逻辑和generationRequests进行交换,在inflight batching模式下不断地交替执行prefill和decode。
流程图:
Summary
- 当forwardAsync处理完之后,最后处理的数据使用Mpi communication进行同步,最后整合生成数据封装格式返回response消息到Client端。
运行报错经验分享
修改C++代码不生效
我有出现过修改C++ 代码,python3 ./scripts/build_wheel.py编译不生效的问题,编译过程中都出现修改报错,但是就是没有生效。
最好的方式是先pip unistall tensorrt_llm,然后再pip install ./build/tensorrt_llm*.whl,
直接安装会因为版本相同可能没有安装的情况
bash
Traceback (most recent call last):
File "/usr/local/bin/trtllm-serve", line 5, in <module>
from tensorrt_llm.commands.serve import main
File "/usr/local/lib/python3.12/dist-packages/tensorrt_llm/__init__.py", line 66, in <module>
import tensorrt_llm._torch.models as torch_models
File "/usr/local/lib/python3.12/dist-packages/tensorrt_llm/_torch/__init__.py", line 1, in <module>
from .llm import LLM
File "/usr/local/lib/python3.12/dist-packages/tensorrt_llm/_torch/llm.py", line 1, in <module>
from tensorrt_llm.llmapi.llm import _TorchLLM
File "/usr/local/lib/python3.12/dist-packages/tensorrt_llm/llmapi/__init__.py", line 2, in <module>
from ..executor import CompletionOutput, LoRARequest, RequestError
ImportError: cannot import name 'CompletionOutput' from 'tensorrt_llm.executor' (/usr/local/lib/python3.12/dist-packages/tensorrt_llm/executor/__init__.py)
运行trtllm-serve会出现这个报错,原因应该是出现TensorRT-LLM Python whl包安装不完整,再执行pip install -e .重新安装就可以解决报错