文章目录
- 一、项目问题定义
- [二、 数据处理](#二、 数据处理)
-
- [2.1 数据集获取](#2.1 数据集获取)
- [2.2 数据增强与标准化](#2.2 数据增强与标准化)
- [2.3 数据集划分](#2.3 数据集划分)
- [2.4 数据加载](#2.4 数据加载)
- [三、 模型架构](#三、 模型架构)
-
- 3.1模型设计基础
- [3.2 整体网络架构](#3.2 整体网络架构)
- [四、 训练配置](#四、 训练配置)
- [五、 评估结果](#五、 评估结果)
一、项目问题定义
本项目针对Fashion-MNIST 衣物图像数据集,解决多类别图像分类问题。该数据集包含 10 类常见衣物如T恤、裤子、套头衫等,所有样本为28×28像素的单通道灰度图,需构建模型实现对衣物类别的精准识别。
基于卷积神经网络架构,利用数据增强、早停、Dropout等策略,在划分后的训练集70%、验证集15%、测试集15%上完成模型训练与评估,目标是使测试集准确率最大化,同时避免过拟合,确保模型具备良好的泛化能力,能够很好的识别图像分类任务。
二、 数据处理
2.1 数据集获取
通过PyTorch的torchvision.datasets模块下载原始数据集,分为训练集60000张和测试集10000张,下载后暂不施加任何数据变换,保留原始图像数据用于后续统一处理。
为实现自定义比例的数据划分,构建CombinedDatase类将原始训练集与测试集合并为全量数据集,通过索引判断机制灵活读取原训练集或测试集数据,确保后续划分过程中数据分布的完整性与均匀性。
matlab
class CombinedDataset(Dataset):
def __init__(self, train_dataset, test_dataset, transform=None):
self.train_data = train_dataset
self.test_data = test_dataset
self.transform = transform
self.total_len = len(self.train_data) + len(self.test_data)
def __len__(self):
return self.total_len
def __getitem__(self, idx):
#索引小于训练集长度:取训练集数据;否则取测试集数据
if idx < len(self.train_data):
img, target = self.train_data[idx]
else:
img, target = self.test_data[idx - len(self.train_data)]
if self.transform is not None:
img = self.transform(img)
return img, target
#下载原始数据集
raw_train = datasets.FashionMNIST(root='./data', train=True, download=True, transform=None)
raw_test = datasets.FashionMNIST(root='./data', train=False, download=True, transform=None)
#创建3个不同transform的全量数据集(训练/验证/测试)
train_full_dataset = CombinedDataset(raw_train, raw_test, transform=train_transform)
val_full_dataset = CombinedDataset(raw_train, raw_test, transform=val_test_transform)
test_full_dataset = CombinedDataset(raw_train, raw_test, transform=val_test_transform)
2.2 数据增强与标准化
针对图像分类任务中常见的过拟合问题,结合数据集特点设计变换策略,分为训练集变换与验证/测试集变换两类:训练集变换train_transform:包含随机裁,28×28像素,4像素填充,避免边缘信息丢失、随机旋转±15度、转为 Tensor 格式、标准化均值 0.2860、方差0.3530。
验证/测试集变换val_test_transform:仅包含Tensor格式转换与相同参数的标准化操作,避免数据增强对验证、测试结果的干扰,确保评估的客观性与准确性。基于上述变换策略,分别创建训练集、验证集、测试集对应的全量数据集train_full_dataset、val_full_dataset、test_full_dataset,为后续划分提供带变换的数据源。
matlab
#数据增强:训练集添加旋转、随机裁剪,验证/测试集仅标准化
train_transform = transforms.Compose([
transforms.RandomCrop(28, padding=4), # 随机裁剪(padding避免边缘信息丢失)
transforms.RandomRotation(15), # 随机旋转±15度
transforms.ToTensor(),
transforms.Normalize((0.2860,), (0.3530,)) # FashionMNIST统计均值/方差
])
val_test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.2860,), (0.3530,))
])
2.3 数据集划分
为实现模型的有效训练、验证与测试,按预设比例训练集70%、验证集15%、测试集 15%对合并后的全量数据集进行划分:
首先通过sklearn.model_selection.train_test_split将全量数据索引分为训练集索引train_id与剩余数据索引rest_idx,训练集占比70%,设置随机种子保证划分结果可复现,且开启shuffle=True打乱数据分布。对剩余30% 数据索引rest_idx再次进行划分,按验证集与测试集 1:1 的比例拆分出验证集索引val_idx与测试集索引test_idx,同样固定随机种子确保划分一致性。
利用 PyTorch的Subse类,根据上述索引从对应全量数据集中提取样本,生成最终的训练集、验证集、测试集,数据量分别为 49000 张、10500 张、10500 张。
matlab
#基于全量数据长度划分索引
total_indices = np.arange(len(train_full_dataset))
#划分训练集和剩余数据(训练集70%,剩余30%)
train_idx, rest_idx = train_test_split(
total_indices,
train_size=TRAIN_RATIO,
random_state=42,
shuffle=True
)
#划分验证集和测试集
val_idx, test_idx = train_test_split(
rest_idx,
train_size=VAL_RATIO/(VAL_RATIO+TEST_RATIO),
random_state=42
)
train_dataset = Subset(train_full_dataset, train_idx)
val_dataset = Subset(val_full_dataset, val_idx)
test_dataset = Subset(test_full_dataset, test_idx)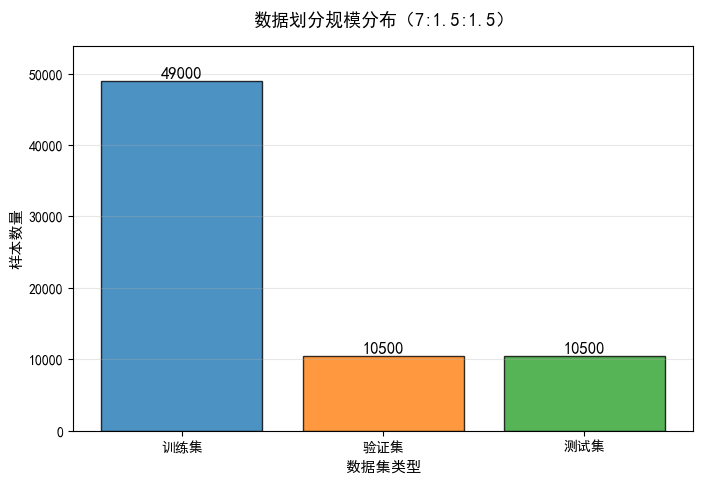
2.4 数据加载
通过torch.utils.data.DataLoader构建数据加载器,实现批量数据读取与高效迭代:
训练集加载器train_iter:设置批量大小batch_size=256,开启shuffle=True打乱批次数据,提升训练稳定性;验证集与测试集加载器val_iter、test_iter:批量大小同样为 256,关闭shuffle以保证评估结果可复现;另外所有加载器均设置num_workers=0(单线程加载)、pin_memory=True锁页内存加速 GPU 数据传输。
matlab
train_iter = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
val_iter = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
test_iter = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
print(f"数据划分完成:训练集{len(train_dataset)}张 | 验证集{len(val_dataset)}张 | 测试集{len(test_dataset)}张")
数据划分完成:训练集49000张 | 验证集10500张 | 测试集10500张三、 模型架构
3.1模型设计基础
本项目采用卷积神经网络架构,设计如下:分层特征提取,根据"局部感知、权值共享" 的核心思想,从低级纹理特征如衣物边缘、纹理逐步提取高级语义:特征衣物款式、类别,同时采用"卷积+池化"的组合,在降低特征维度的同时保留关键信息;融入Dropout层等正则化组件,兼顾模型拟合能力与泛化能力。
3.2 整体网络架构
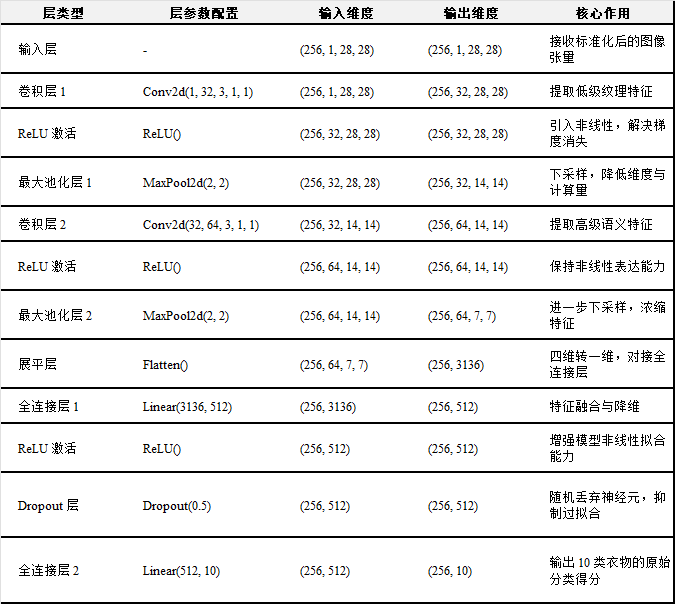
本项目设计的CNN模型分为五大模块:输入层、卷积特征提取模块、特征展平层、全连接分类模块、输出层,整体架构流程为:输入层→卷积块1→卷积块2→展平层→全连接层1→Dropout→全连接层2→输出层。
3.2.1输入层:模型输入维度为(batch_size, in_channels=1, height=28, width=28),与数据处理阶段输出的图像张量格式一致:
• batch_size:本项目为 256,支持批量并行训练;
• in_channels=1:对应 Fashion-MNIST 的单通道灰度图;
• height=28、width=28:对应图像的像素尺寸,无需额外尺寸调整,直接输入卷积层进行特征提取。
3.2.2 卷积特征提取模块:采用两个串联的卷积块实现特征提取,每个卷积块由 "卷积层 + 激活函数 + 最大池化层" 组成,逐步提升特征通道数、降低空间维度:
- 卷积块1
o 卷积层:Conv2d(in_channels=1, out_channels=32, kernel_size=3, stride=1, padding=1)
o 卷积核尺寸 3×3:平衡感受野大小与计算量,能够捕捉衣物的局部纹理特征;
o 步长 stride=1:保证特征图空间维度不被过度压缩;
o 填充 padding=1:采用 "same padding" 策略,使卷积后特征图尺寸保持 28×28,避免边缘信息丢失;
o 输出通道 32:将单通道输入映射到 32 维特征空间,初步提取低级纹理特征。
o 激活函数:ReLU,可以解决sigmoid等激活函数的梯度消失问题,提升模型训练效率;
o 最大池化层:MaxPool2d(kernel_size=2, stride=2),将28×28的特征图下采样为14×14,降低特征维度与计算量,同时保留关键纹理特征,输出维度为(batch_size, 32, 14, 14)。 - 卷积块2
o 卷积层:Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
o 输入通道32:对接卷积块 1 的输出通道;
o 输出通道64:进一步提升特征表达能力,提取更高级的衣物语义特征,如领口形状、裤型轮廓等;
o 同样采用3×3卷积核、same padding,卷积后特征图尺寸保持14×14;
o 激活函数:ReLU,保持非线性表达能力;
o 最大池化层:MaxPool2d(kernel_size=2, stride=2),将14×14 的特征图下采样为 7×7,输出维度为(batch_size, 64, 7, 7),完成特征提取的最终步骤。
3.2.3 特征展平层:由于全连接层仅支持一维向量输入,需将卷积模块输出的四维特征张量(batch_size, 64, 7, 7)展平为一维特征向量:通过Flatten()层实现,将每个样本的64×7×7个特征值按顺序拼接,输出维度为(batch_size, 64×7×7) = (batch_size, 3136)。
3.2.4 全连接分类模块:采用 "全连接层+Dropout+全连接层" 的结构,实现从特征向量到分类结果的映射,同时抑制过拟合:
- 全连接层 1(隐藏层):Linear(in_features=3136, out_features=512)
o 输入特征数 3136:对接展平层的输出维度;
o 输出特征数 512:将高维特征映射到 512 维低维空间,提升分类效率;
o 激活函数:ReLU,保持模型的非线性拟合能力。 - Dropout 层:Dropout(p=0.5)
o 丢弃概率 p=0.5:训练过程中随机丢弃50%的神经元连接,避免模型对局部特征过度依赖,有效抑制过拟合;
o 测试阶段:自动关闭 Dropout,恢复所有神经元连接,保证分类结果的稳定性。 - 全连接层 2(分类层):Linear(in_features=512, out_features=10)
o 输入特征数 512:对接 Dropout 层的输出;
o 输出特征数 10:对应 Fashion-MNIST 的 10 类衣物,输出每个类别的原始得分。
3.2.5 输出层:模型最终输出维度为(batch_size, 10),每个元素对应样本属于某一衣物类别的原始得分,通过Softmax函数将得分转换为概率分布,其取概率最大值对应的类别作为模型的预测类别。
四、 训练配置
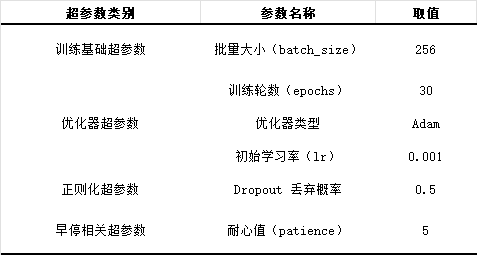
其中优化器选择采用 Adam优化器而非传统 SGD,Adam的自适应学习率机制可快速捕捉梯度变化,在轻量级CNN上能实现更快的收敛速度,同时减少手动调参的工作量。
行逻辑如下:
对于早停策略如下:
1.完成当前epoch的训练集训练,计算训练集平均损失;
2.检查:训练损失是否<LOSS_THRESHOLD=0.1?若是,立即终止训练,加载最优模型;
3.若不满足,在验证集上评估,计算验证集平均损失,更新早停计数器;
4.检查:是否连续5个epoch验证损失未有效下降?若是,立即终止训练,加载最优模型;
5.若不满足,检查:当前epoch是否达到MAX_EPOCHS=30?若是,强制终止训练;
6.若均不满足,进入下一个epoch的训练,重复上述流程。
matlab
#早停机制
class EarlyStopping:
def __init__(self, patience=5, min_delta=0.0001):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_val_loss = float('inf')
self.early_stop = False
self.best_model_path = 'best_fashion_cnn.pth'
def __call__(self, val_loss, model, optimizer):
#验证损失下降超过阈值→更新最佳损失和模型
if val_loss < self.best_val_loss - self.min_delta:
self.best_val_loss = val_loss
self.counter = 0
#保存最佳模型
torch.save({
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict()
}, self.best_model_path)
else:
# 损失未下降→计数器+1
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
print(f"早停触发!连续{self.patience}个epoch验证损失未下降")五、 评估结果
从"损失变化曲线"可见:训练损失与验证损失均呈现持续下降→逐渐平稳的趋势:前5个 epoch 损失快速下降,训练损失从近 1.0降至 0.4左右,验证损失从0.5降至 0.3左右,说明模型快速学习到衣物的基础纹理与轮廓特征;
15个 epoch后损失下降速率放缓,最终在30轮时稳定为:训练损失0.2882、验证损失0.2288。验证损失始终低于训练损失且未出现上升趋势,说明早停策略中的正则化有效抑制了过拟合,模型对验证集数据具备良好的适配性。
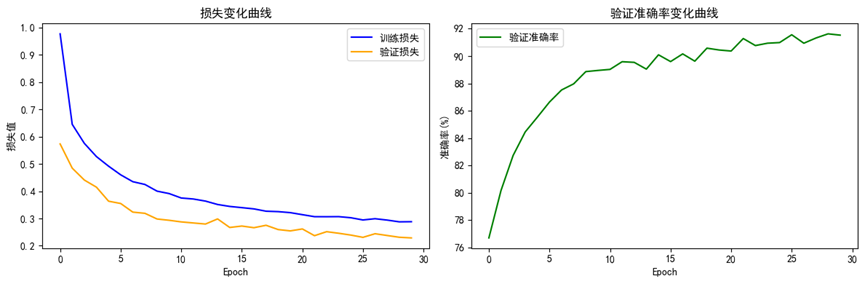
另外"验证准确率变化曲线" 可见验证准确率随 epoch 增加持续上升,前5个 epoch从 76%快速提升至 88%,体现模型对衣物类别的区分能力快速增强;20个epoch后准确率趋于平稳,最终在30轮时达到91.53%,说明模型已充分学习到衣物的高级语义特征。
最终测试集准确率为91.00%,可见模型未出现过拟合问题,在新数据上的分类性能稳定,满足 Fashion-MNIST 衣物分类任务的精度要求。
matlab
print("\n加载最佳模型进行最终测试...")
#加载早停保存的最佳模型
checkpoint = torch.load(early_stopping.best_model_path)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
#测试集评估
correct = 0
total = 0
with torch.no_grad():
for X, y in test_iter:
X, y = X.to(DEVICE), y.to(DEVICE)
pred, _ = model(X)
_, predicted = torch.max(pred, 1)
total += y.size(0)
correct += (predicted == y).sum().item()
test_acc = 100 * correct / total
print(f"最终测试集准确率: {test_acc:.2f}%")从卷积层特征图可视化可见第一层特征图聚焦于衣物的边缘、纹理等低级特征如裤装的纵向轮廓、布料纹理,对应 CNN "局部感知" 的底层功能;
后几层特征图逐渐抽象为高级语义特征,仅保留类别区分的关键区域,弱化无关细节,说明模型已从"识别纹理"过渡到"识别类别"。

预测结果可视化可以看到所有展示样本的真实类别与预测类别完全一致,说明模型对常见衣物类别的特征识别准确;即使是纹理相对简单的样本或轮廓复杂的样本,模型仍能精准匹配类别,体现了卷积层特征提取与全连接层分类的有效性。
