对任一假设 h ∈ H h \in \mathcal{H} h∈H,定义其泛化误差 (真实错误率):
e r r D ( h ) = P x ∼ D h ( x ) ≠ h ∗ ( x ) \mathrm{err}D(h) = \mathbb{P}{x\sim D}h(x)\\neq h\^\*(x) errD(h)=Px∼Dh(x)=h∗(x)
这是在真实分布 D D D 下的错误概率,而不是训练集上的错误
"近似正确"指的是:
e r r D ( h ) ≤ ε \mathrm{err}_D(h) \le \varepsilon errD(h)≤ε
允许模型犯错
但错误率不能超过一个事先给定的容忍上限 ε\varepsilonε
ε = 0.03 \varepsilon=0.03 ε=0.03:最多允许 3% 的样本被分错
概率正确PC
PAC 中的概率是 对训练样本随机性的概率 :
P S ∼ D m ( e r r D ( h S ) ≤ ε ) ≥ 1 − δ \mathbb{P}_{S\sim D^m} \Big( \mathrm{err}_D(h_S) \le \varepsilon \Big) \ge 1-\delta PS∼Dm(errD(hS)≤ε)≥1−δ
老师知道真实规律 c c c, 精心生成一批 ( x , c ( x ) ) (x, c(x)) (x,c(x))
特点:
数据干净
分布"友好"
比随机采样省数据
-> 现实中老师往往也不知道真实规律
3.随机生成(现在机器学习最常用)
样本 x ∼ P ( X ) x \sim P(X) x∼P(X) 自然随机出现
老师只负责打标签
可能大量重复、简单、无区分度的样本
关键难例出现概率低
-> 所以需要最多的数据(样本复杂度研究的主战场)
训练错误率 vs 真实错误率
三个"集合":X、C、H
实例集合 X X X: 所有可能输入的集合
-> 训练集只是从 X X X 中抽出来的一小撮
目标函数 C C C(或 c c c): 世界中"真正正确的分类规则"
-> 终极标准, 真实规律
-> 学习的目标是逼近这个 C C C
假设集合 H H H: 算法"能想到"的所有模型
所有线性分类器
所有深度 ≤ 5 的决策树
所有参数在某范围内的神经网络
-> 真正的 C C C 往往 不在 H H H 里 , 我们只能在 H H H 中选"最像 C 的那个"
训练错误率 e r r o r t r a i n ( h ) error_{train}(h) errortrain(h)
模型在训练集 D D D上的错误比例:
e r r o r t r a i n ( h ) = Pr x ∈ D h ( x ) ≠ c ( x ) error_{train}(h)= \Pr_{x \in D} h(x) \\ne c(x) errortrain(h)=x∈DPrh(x)=c(x)
可计算
可被算法直接优化
很容易被压到 0
真实错误率 e r r o r t r u e ( h ) error_{true}(h) errortrue(h)
模型在"真实世界分布 P ( X ) P(X) P(X)"上的错误概率:
e r r o r t r u e ( h ) = Pr x ∼ P ( X ) h ( x ) ≠ c ( x ) error_{true}(h)= \Pr_{x \sim P(X)} h(x) \\ne c(x) errortrue(h)=x∼P(X)Prh(x)=c(x)
永远无法精确计算
只能用理论去"保证"
过拟合
e r r o r t r a i n ( h ) error_{train}(h) errortrain(h) 很小但 e r r o r t r u e ( h ) error_{true}(h) errortrue(h) 很大
本质原因: 模型"记住了样本",而不是"学会了规律"
为什么要"泛化能力"
学习的目标:
不是在所有输入上都表现好
而是在"高概率出现的输入"上表现好
一致性(Consistent)
如果某个假设 hhh 在训练集上 一个都没错 ,则称 h h h 与训练集 D D D 一致 (consistent)
e r r o r t r a i n ( h ) = 0 error_{train}(h)=0 errortrain(h)=0
一致 ≠ 好模型
复杂模型几乎总能做到一致(记忆)
不会保证这个模型在新数据上好不好
版本空间 Version Space
所有能把训练集全分对的模型的集合
V S H , D = { h ∈ H ∣ h 在训练集 D 上无错误 } VS_{H,D} = \{h \in H \mid h \text{ 在训练集 } D \text{ 上无错误}\} VSH,D={h∈H∣h 在训练集 D 上无错误}
Haussler 定理
问题: 如果我随机抽 m 个样本,版本空间里还会不会混进"坏模型"
"ε-耗尽": 版本空间中 已经没有任何坏模型 :
∀ h ∈ V S H , D , e r r o r t r u e ( h ) < ε \forall h \in VS_{H,D},\quad error_{true}(h) < \varepsilon ∀h∈VSH,D,errortrue(h)<ε
Haussler 定理:
P ( 版本空间未被 ϵ 耗尽 ) < ∣ H ∣ e − ϵ m P(\text{版本空间未被} \epsilon \text{耗尽}) < |H|e^{-\epsilon m} P(版本空间未被ϵ耗尽)<∣H∣e−ϵm
∣ H ∣ |H| ∣H∣:模型数量(复杂度)
e − ε m e^{-\varepsilon m} e−εm: 一个"坏模型"恰好在 m 个样本上都没被戳穿的概率
"在所有 m 个样本上都没被戳穿": Pr ( 全部分对 ) ≤ ( 1 − ε ) m \Pr(\text{全部分对}) \le (1-\varepsilon)^m Pr(全部分对)≤(1−ε)m
则 ( 1 − ε ) m ≤ ( e − ε ) m = e − ε m (1-\varepsilon)^m \le (e^{-\varepsilon})^m = e^{-\varepsilon m} (1−ε)m≤(e−ε)m=e−εm
乘起来:"至少有一个坏模型混进版本空间"的上界
解出 m m m:
m ≥ 1 ε ( ln ∣ H ∣ + ln ( 1 / δ ) ) m \ge \frac{1}{\varepsilon} \big(\ln|H| + \ln(1/\delta)\big) m≥ε1(ln∣H∣+ln(1/δ))
1 ε \frac{1}{\varepsilon} ε1:要求越精确 → 数据越多
ln ∣ H ∣ \ln|H| ln∣H∣:模型越复杂 → 数据越多
ln ( 1 / δ ) \ln(1/\delta) ln(1/δ):置信度越高 → 数据越多
定义:"存在一个训练全对、但泛化很差的模型"的概率
δ = P ∃ h ∈ H : e r r o r t r a i n ( h ) = 0 且 e r r o r t r u e ( h ) \> ε \delta = P\\exists h\\in H: error_{train}(h)=0\\ \\text{且}\\ error_{true}(h)\>\\varepsilon δ=P∃h∈H:errortrain(h)=0 且 errortrue(h)\>ε
目标就是让这种事几乎不发生 -> 让 δ \delta δ足够小
结论
只要模型复杂度受控、数据足够多、并且算法能拟合训练集,那么"训练全对"就意味着"泛化也大概率不错"
不可知学习agnostic learning
为什么要引入「不可知学习」
PAC(consistent / realizable case)的核心前提 是:真实世界的规律 c c c 就在假设空间 H H H 里
而在真实机器学习中,几乎总是:
模型是近似的
特征不完备
假设空间受限
于是:真实目标函数 c c c 根本不在 H H H 里
这时:
不存在"训练误差 = 0"的好模型
版本空间可能是空的
一致性学习直接失效
-> 这就是不可知学习(agnostic learning)出现的原因
学习类型
核心假设
学习目标
ε的含义
PAC学习(可实现学习)
真实模型 c ∈ H c ∈ H c∈H(假设空间包含完美真理)
找到训练误差为0的假设
真实错误率的上界(保证学到的模型错误率<ε)
不可知学习
真实模型 c ∉ H c ∉ H c∈/H(假设空间不包含完美真理)
找到训练误差最小的假设
训练错误率与真实错误率的差距
ε 的含义
ε:训练误差与真实误差之间的偏差容忍
e r r o r t r u e ( h ) ≤ e r r o r t r a i n ( h ) + ε error_{true}(h) \le error_{train}(h) + \varepsilon errortrue(h)≤errortrain(h)+ε
霍夫丁不等式 (不可知学习的基础)
固定一个假设 h h h,考虑随机变量:
Z = { 1 , h ( x ) ≠ c ( x ) 0 , h ( x ) = c ( x ) Z = \begin{cases} 1, & h(x)\neq c(x) \\ 0, & h(x)=c(x) \end{cases} Z={1,0,h(x)=c(x)h(x)=c(x)
Z Z Z 是 伯努利随机变量
E Z = θ = e r r o r t r u e ( h ) \mathbb{E}Z = \theta = error_{true}(h) EZ=θ=errortrue(h)
训练集上:
θ ^ = 1 m ∑ i = 1 m Z i = e r r o r t r a i n ( h ) \hat{\theta} = \frac{1}{m}\sum_{i=1}^m Z_i = error_{train}(h) θ^=m1i=1∑mZi=errortrain(h)
完全等价于:
抛一枚正面概率为 θ \theta θ 的硬币,抛 m m m 次,观察正面频率 θ ^ \hat{\theta} θ^
P ( ⋃ i A i ) ≤ ∑ i P ( A i ) P\left(\bigcup_i A_i\right) \le \sum_i P(A_i) P(i⋃Ai)≤i∑P(Ai)
-> "至少存在一个坏模型"的概率 ≤ 所有模型"各自出问题"的概率之和
泛化误差界:
Pr ∃ h ∈ H : e r r o r t r u e ( h ) \> e r r o r t r a i n ( h ) + ε ≤ ∣ H ∣ e − 2 m ε 2 \Pr\\exists h\\in H: error_{true}(h) \> error_{train}(h) + \\varepsilon \le |H|e^{-2m\varepsilon^2} Pr∃h∈H:errortrue(h)\>errortrain(h)+ε≤∣H∣e−2mε2
等价于说:只要数据足够多,几乎所有模型的训练误差都不会严重低估真实误差
整理得到:
e r r o r t r u e ( h ) ≤ e r r o r t r a i n ( h ) + ln ∣ H ∣ + ln ( 1 / δ ) 2 m ( ∀ h ∈ H ) error_{true}(h) \le error_{train}(h) + \sqrt{ \frac{\ln|H| + \ln(1/\delta)}{2m} } \quad (\forall h\in H) errortrue(h)≤errortrain(h)+2mln∣H∣+ln(1/δ) (∀h∈H)
第一项:模型在训练集上的表现
第二项:模型复杂度惩罚 + 数据不足惩罚
也是**结构风险最小化(SRM)**的理论原型
为什么会出现 2 ε 2\varepsilon 2ε
h h h:训练误差最小的模型(算法选的)
h ∗ h^* h∗:真实误差最小的模型(理论最优)
对任意模型都成立:
e r r o r t r u e ( h ) ≤ e r r o r t r a i n ( h ) + ε e r r o r t r u e ( h ∗ ) ≥ e r r o r t r a i n ( h ∗ ) − ε error_{true}(h) \le error_{train}(h) + \varepsilon \\ error_{true}(h^*) \ge error_{train}(h^*) - \varepsilon errortrue(h)≤errortrain(h)+εerrortrue(h∗)≥errortrain(h∗)−ε
又因为算法选择了训练误差最小的:
e r r o r t r a i n ( h ) ≤ e r r o r t r a i n ( h ∗ ) error_{train}(h) \le error_{train}(h^*) errortrain(h)≤errortrain(h∗)
合起来:
e r r o r t r u e ( h ) ≤ e r r o r t r u e ( h ∗ ) + 2 ε error_{true}(h) \le error_{true}(h^*) + 2\varepsilon errortrue(h)≤errortrue(h∗)+2ε
-> 即使世界上不存在完美模型, 我们学到的模型也不会比"理论最优模型"差太多
VC维
VC维是无限假设空间 H H H的复杂度衡量 是最坏情形下, 模型的记忆能力上限
为什么需要 VC 维
以下问题中, H H H 通常是 无限的
神经网络
线性分类器
多项式模型
-> 那么 ∣ H ∣ |H| ∣H∣ 没法用了
VC 维不再问:
❌ 有多少个假设?
而是问:
✅ 在最坏情况下,你能"随意解释"多少个样本?
二分法 + 打散
VC 维衡量的是:在最坏情况下,假设空间 H H H 能够对多少个样本点实现"任意标记"的能力
给定数据集的 n n n 个点, 对于所有 2 n 2^n 2n 种标记方式, 如果 H H H 全都能实现
-> 数据集的 n n n 个点被 H H H 打散
如果模型仍能做到:对这 2 n 2^n 2n 种情况 全部零误差
那说明模型可以完美记忆噪声
-> 打散 ≡ 对纯噪声数据也能 0 训练误差
V C ( H ) VC(H) VC(H)
V C ( H ) VC(H) VC(H):能被 H H H 打散的最大实例集大小
-> V C ( H ) VC(H) VC(H) = 模型在最坏情况下"可以记住多少个样本点"的上限
VC维与模型复杂度的关系
VC维越高 → 模型拟合能力越强、复杂度越高(如高次多项式>直线)
VC维越低 → 模型越简单、拟合能力越弱
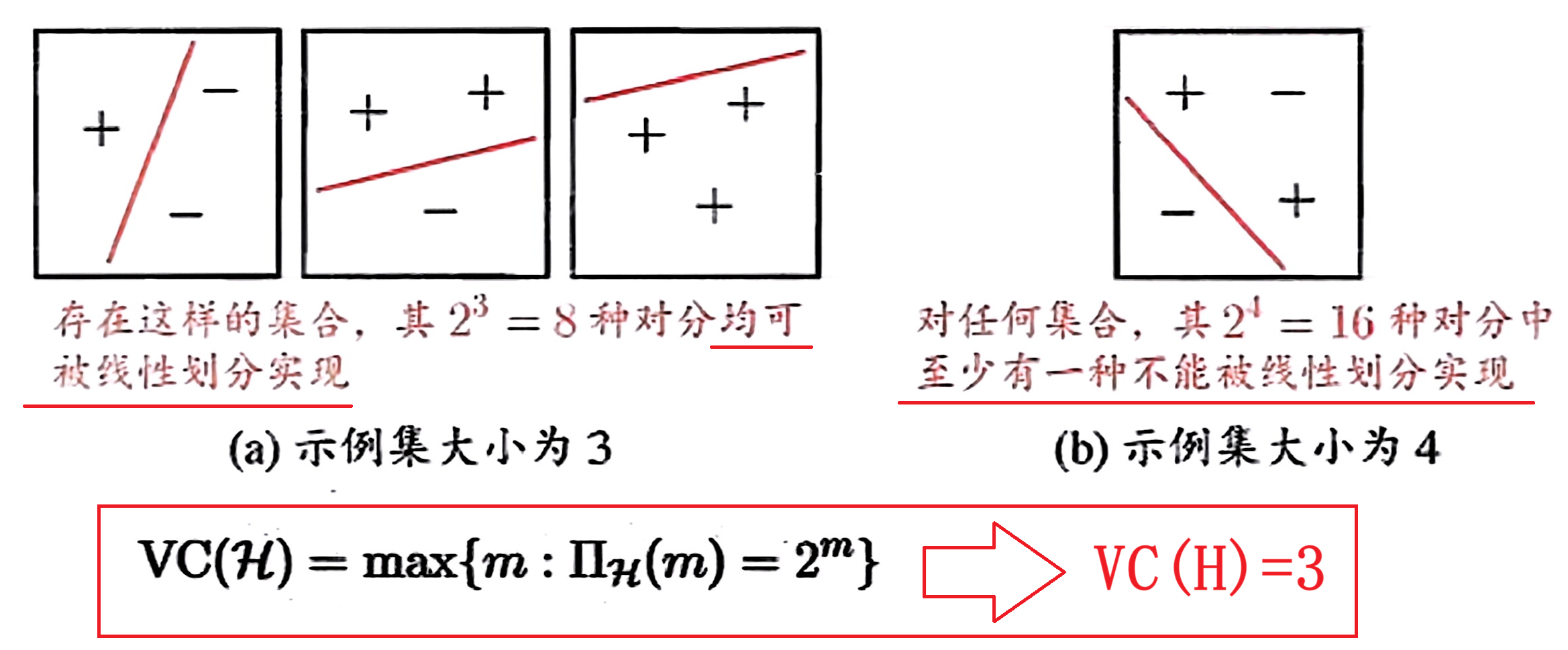
二维平面上线性分类器的 VC 维是 3
V C ( H ) = 3 VC(H)=3 VC(H)=3 -> 最多区分3个数据点
-> 线性模型不可能无限度拟合噪声(这就是它能泛化的根本原因)
VC维将无限假设空间的复杂度量化,使得统计学习理论可应用于复杂模型(支持向量机、神经网络等)
所需最小数据量为:
m ⩾ 1 ϵ ( 4 log 2 ( 2 / δ ) + 8 ⋅ V C ( H ) ⋅ log 2 ( 13 / ϵ ) ) m \geqslant \frac{1}{\epsilon} (4\log_2(2/\delta) + 8 \cdot VC(H) \cdot \log_2(13/\epsilon)) m⩾ϵ1(4log2(2/δ)+8⋅VC(H)⋅log2(13/ϵ))
本质结构是:
m ∼ 1 ϵ ( log 1 δ ⏟ 失败概率 + V C ( H ) ⏟ 模型自由度 ⋅ log 1 ϵ ⏟ 精度要求 ) m \;\sim\; \frac{1}{\epsilon} \Big( \underbrace{\log \frac{1}{\delta}}{\text{失败概率}} + \underbrace{VC(H)}{\text{模型自由度}} \cdot \underbrace{\log \frac{1}{\epsilon}}_{\text{精度要求}} \Big) m∼ϵ1(失败概率 logδ1+模型自由度 VC(H)⋅精度要求 logϵ1)