网易数帆EasyData使用Cloud CMP(华为鲲鹏版)作为底座的ChatBI方案
网易数帆 EasyData 并未官方推出" 以 Cloud CMP 为底座" 的 ChatBI 标准方案 。但根据企业实际落地需求和技术可行性,可以构建一种混合架构:将 Cloud CMP 作为底层数据湖/ 计算引擎,而网易数帆 EasyData (含其 ChatBI 能力)作为上层智能分析与对话交互平台。
这种组合属于 " 异构集成" 模式 ,并非开箱即用的产品,而是需要定制化对接。下面从技术可行性、架构设计、实施挑战和适用场景四个方面详细说明:
一、技术可行性:是否能打通?
✅ 答案是:可以,但需中间层适配。
关键打通点:
| 组件 | 网易数帆 EasyData 需求 | Cloud CMP 提供能力 | 对接方式 |
|---|---|---|---|
| 元数据 | 获取表结构、字段注释、业务口径 | Apache Atlas / Hive Metastore | 通过 JDBC 或 Atlas API 同步 |
| SQL 执行引擎 | 发送 NL2SQL 生成的查询语句 | Impala / Hive LLAP / Spark SQL | 通过 JDBC/ODBC 连接 CMP 查询服务 |
| 权限控制 | 字段级行级权限继承 | Apache Ranger | 需在 EasyData 中映射 Ranger 策略(或通过代理用户) |
| 数据源注册 | 将 CMP 表注册为 EasyData 数据资产 | CMP 支持标准 SQL 接口 | 在 EasyData 中添加 CMP 为"外部数据源" |
🔸 结论 :只要 CMP 开放 JDBC/ODBC 接口 + 元数据访问权限,EasyData 即可将其视为一个"高性能 MPP 数据库"来集成。
二、推荐架构设计(混合部署)
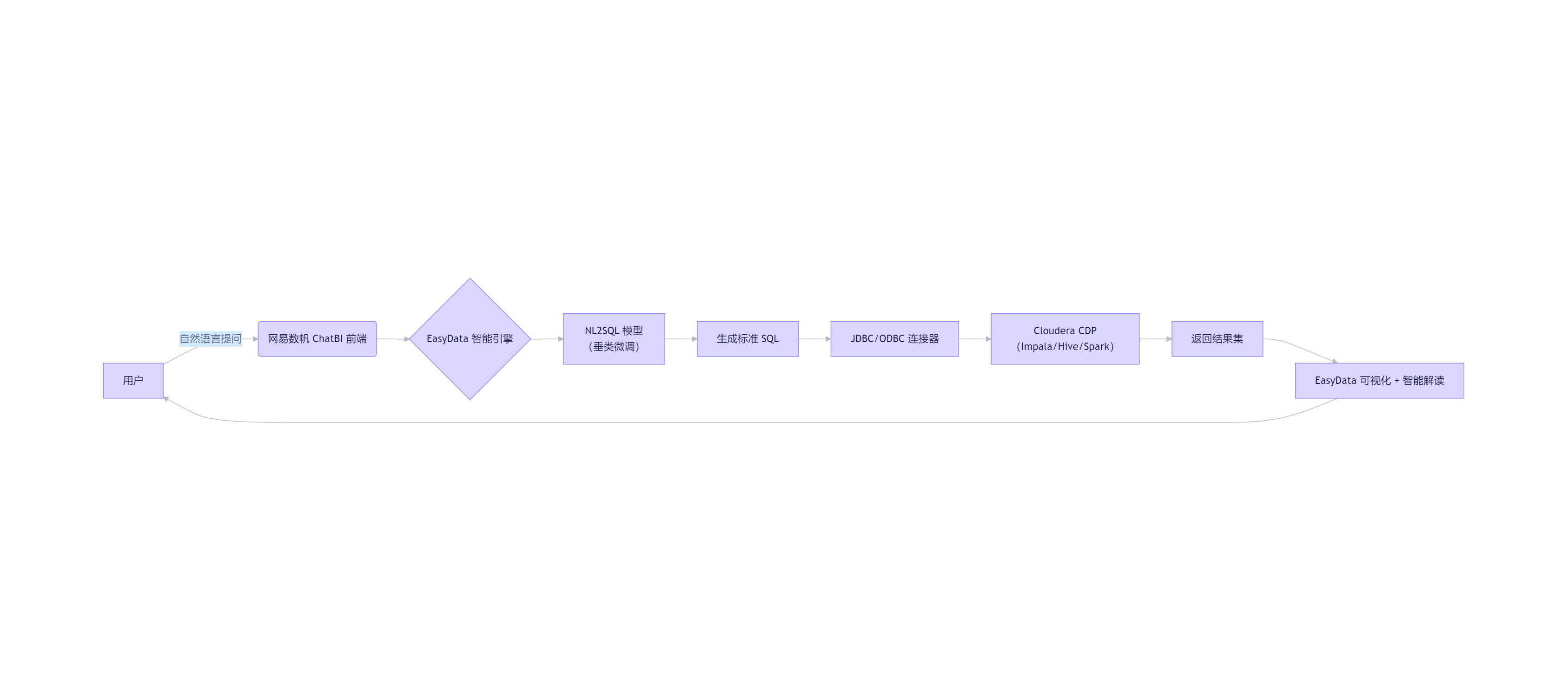 架构说明:
架构说明:
- 底层:Cloud CMP 存储原始数据(HDFS/Iceberg/Kudu),提供高性能查询;
- 中间层:EasyData 通过 JDBC 连接 CMP,将其注册为"逻辑数据源";
- 上层:ChatBI 用户输入中文问题 → EasyData 的 NL2SQL 引擎生成 SQL → 下推至 CMP 执行 → 返回结果并自动可视化+解读。
三、实施中的关键挑战
| 挑战 | 解决方案 |
|---|---|
| 1. 元数据同步滞后 | 使用 EasyData 的"外部数据源元数据采集器",定时拉取 CMP Hive Metastore |
| 2. 权限不一致 | 在 EasyData 中配置"代理用户"(Proxy User),使每个查询以用户身份透传到 CMP,由 Ranger 控制 |
| 3. SQL 方言差异 | EasyData 的 NL2SQL 引擎需支持 Impala/Hive SQL****语法模板 (网易已支持主流方言) |
| 4. 性能瓶颈 | 复杂查询可能因 CMP 资源争抢变慢 → 建议在 CMP 中为 BI 查询创建独立资源池(YARN Queue / Impala Pool) |
| 5. 中文注释缺失 | 若 CMP 表无中文字段名,需在 EasyData 中手动维护"业务术语映射表" |
四、适用场景(谁会这么用?)
这种混合方案通常出现在以下背景的企业:
- ✅ 已有 Cloud CMP 投资:大型国企/外企多年前部署了 CDH/CMP,不愿推倒重来;
- ✅ 需要国产化上层应用:因政策要求,需替换 Tableau/Power BI,引入国产 ChatBI;
- ✅ 追求" 保底+ 升级" 策略:保留 CMP 底座稳定性,叠加 EasyData 的智能交互能力;
- ✅ 多云/ 混合环境:CMP 在本地,EasyData 可部署在私有云或信创云。
📌 典型案例 :
某跨国银行中国区:
- 全球统一使用 Cloud CMP 存储客户交易数据;
- 中国区合规要求不得使用国外 BI 工具;
- 引入网易数帆 EasyData 作为 ChatBI 前端,对接 CMP,实现"中文问数、安全可控"。
五、网易官方态度
- 网易数帆 支持将任意 JDBC 兼容数据库作为数据源,包括 Cloud Impala/Hive;
- 但在其标准交付方案中,优先推荐自研 NDH (NetEase Data Hub )或开源 Hadoop 生态;
- 不提供 CMP 专属插件,但可通过通用 JDBC 方式集成(需客户 IT 团队配合)。
✅ 总结
网易数帆 EasyData 可以基于 Cloud CMP 构建 ChatBI 方案,但属于" 客户定制集成" 而非标准产品。
优势在于:复用现有 CMP 投资 + 获得国产智能 BI 能力 ;
风险在于:需解决元数据、权限、性能协同问题,实施周期较长。