最近在学习分布式系统的数据同步和实时流处理相关知识,重点梳理一下了Kafka的核心知识点和底层细节。这篇文章就以我的学习总结为基础,把Kafka的核心内容梳理清楚
一、初识Kafka:什么是分布式事件流平台?
很多人会把Kafka简单理解成消息队列,但其实它的定位是"分布式事件流平台"。官方定义是:一个开源的分布式事件流平台,被成千上万的公司用于构建高性能数据管道、流分析、数据集成和关键任务应用。简单说,Kafka不仅能像消息队列一样实现系统间的异步通信,还能支撑大规模的实时数据处理场景,这也是它区别于传统MQ的核心优势。
1. 核心应用场景
梳理学习资料后发现,Kafka的应用场景主要分为两类,基本覆盖了分布式系统中的核心数据流转需求:
- 构建实时流数据管道:实现系统或应用间的可靠数据传输,相当于高性能的消息队列。比如电商系统中,订单创建后通过Kafka将订单数据同步到库存系统、支付系统、数据分析系统,避免了系统间的直接耦合,还能应对高并发场景下的流量削峰。
- 构建实时流式应用程序:对流转的数据进行实时处理和转换。比如通过Kafka Stream处理用户行为日志,实时统计商品点击量、计算用户活跃度,再将处理结果推送至下游系统或存储介质。
二、Kafka核心架构:从组件到集群协同
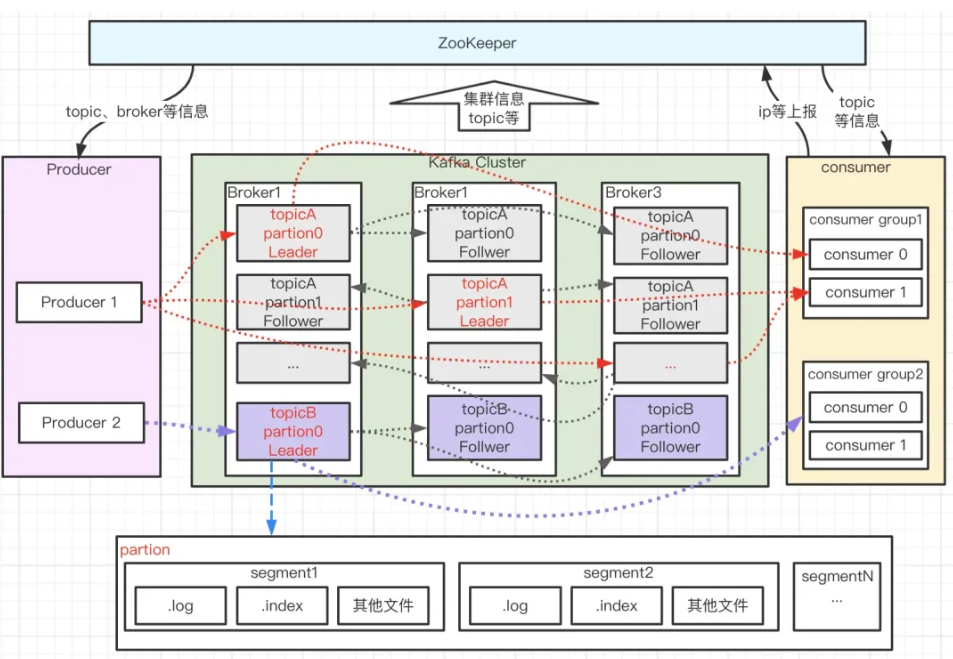
Kafka的高性能和高可用性,源于其简洁且精妙的架构设计。刚开始学习时,我对生产者、Broker、消费者这些组件的协同关系理解得不够透彻,通过梳理架构图和组件文档,才逐步理清逻辑。下面结合我的学习理解,拆解Kafka的核心架构组件及协同机制。
1. 核心架构组件
Kafka集群主要由生产者(Producer)、 Broker、消费者(Consumer)三大核心组件构成,再加上主题(Topic)、分区(Partition)等核心概念,共同实现消息的生产、存储和消费全流程:
(1)生产者(Producer)
生产者负责将数据发布到指定的主题(Topic)中,核心职责除了发送消息,还要决定将消息分配到哪个分区(Partition)。最常用的分配策略是按消息Key的哈希值分配,确保相同Key的消息进入同一个分区;如果没有Key,也可以采用轮询方式分配,实现多个Broker的负载均衡。
(2)Broker与集群容错
Broker即Kafka集群中的服务器节点,主题的分区会分布式存储在不同的Broker上。为保障容错性,每个分区会在多个Broker上进行备份(即副本,Replica)。这部分有两个关键概念需要重点区分,也是学习过程中容易混淆的点:
- 主副本(Leader):每个分区有且仅有一个Leader副本,所有的读写请求都由Leader处理,保证了数据一致性。
- 从副本(Follower):Follower副本仅被动同步Leader的数据,不处理读写请求。当Leader宕机时,Kafka会自动从Follower中选举一个新的Leader,确保服务不中断。
值得注意的是,每个Broker既会作为某些分区的Leader,也会作为其他分区的Follower,这样能保证集群的负载均衡,避免单个节点压力过大。
(3)消费者(Consumer)与消费组(Consumer Group)
消费者通过消费组(Group)进行标识,其核心逻辑是:发布到主题的每条消息,会分配到订阅该主题的消费组中的一个消费者实例。这里有两个核心规则,直接决定了消费模式,是学习的重点也是难点:
- 负载均衡模式:如果所有消费者实例在同一个消费组,消息会均匀分配到每个实例(每个分区只能被同一个消费组的一个实例消费),适合高吞吐的消息处理场景。
- 广播模式:如果所有消费者实例在不同的消费组,每条消息会被广播到所有消费组,适合多系统同时获取同一批消息的场景(比如订单数据同时同步到数据分析和数据备份系统)。
举个实际例子:一个Kafka集群有2个Broker,某个主题有4个分区,有两个消费组。此时每个分区的消息会广播到两个消费组,每个消费组内的消费者实例再负载均衡消费各自组内的消息。
(4)主题(Topic)与分区(Partition)
主题是消息的逻辑分类,相当于一个消息队列;分区是主题的物理拆分,每个主题可以包含多个分区,消息会被分布式存储在不同的分区中。分区的核心作用有两个:一是实现水平扩展,通过增加分区数量提升集群的存储和处理能力;二是保证分区内消息的有序性(注意:跨分区无法保证全局有序)。
三、深度解析:生产者与消费者架构原理
理解完核心组件后,进一步拆解生产者和消费者的内部架构与工作流程,这部分是掌握Kafka核心原理的关键。通过学习相关源码文档和技术解析,对这部分的优化思路也有了初步的认识。
1. 生产者架构与工作流程
生产者的核心目标是高效、可靠地将消息发送到Broker,内部通过拦截器、序列化器、分区器、消息累加器等组件协同完成这一过程,具体工作流程可梳理为以下几步:
-
主线程处理:生产者主线程会先将消息传递给拦截器,对消息进行预处理(比如添加额外属性);接着通过序列化器将消息对象转换成字节数组,方便网络传输;然后由分区器决定消息要发送到当前主题的哪个分区,之后将处理完毕的消息发送到消息累加器。
-
消息累加器缓存:消息累加器会为每个分区对应维护一个队列,收到消息后就将其存入对应分区的队列中。这里可以通过配置buffer.memory参数设置累加器的总缓存大小,默认是32MB,用于控制缓存消息的上限。
-
批量发送准备:为了提升发送效率、减少网络带宽消耗,消息会以ProducerBatch(消息批次)的形式批量发送给Sender线程。也就是说,Sender线程处理的不是单条消息,而是包含多条消息的批次。
-
消息发送与响应处理:Sender线程从各个分区队列的头部读取消息批次,创建对应的请求对象(request)并缓存;之后将请求提交到Selector(选择器),由Selector负责将消息发送到Kafka集群。对于尚未收到Kafka集群ack(确认)响应的请求,会暂时缓存起来;当收到ack响应后,再从缓存中清除对应的请求,并移除消息累加器中已成功发送的消息。
2. 消费者架构与工作流程
消费者的核心逻辑是从Kafka集群订阅并消费消息,结合参考资料,其详细工作流程和核心机制梳理如下:
(1)基本消费流程
消费组(Consumer Group)中的每个消费者,会向对应的分区注册并消费消息。消费者消费完消息后,会将当前的消费位移(offset,即消息在分区中的位置标识)以消息的形式提交到位移主题中进行记录。消费组内的多个消费者会自动进行负载均衡,若其中一个消费者宕机,其负责消费的分区会自动切换到组内其他消费者,保证消费不中断。
(2)消费组关键特性
学习时总结了消费组的几个核心要点,需要重点掌握:
- 组内消费者标识:同一个消费组内的多个消费者可以共用一个Consumer ID。
- 分区消费限制:组内所有消费者只能注册到一个分区进行消费,即一个分区只能被同一个消费组内的一个消费者消费。
- 主题订阅限制:一个消费组只能订阅一个主题进行消费。
(3)位移主题的作用与版本演变
位移主题的核心功能是保存Kafka消费者的消费位移信息,方便消费者重启后能从上次中断的位置继续消费,这部分在不同Kafka版本中有不同实现,是学习的重点:
- Kafka老版本(基于Zookeeper):老版本中,消费者的位移数据需要自动或手动提交到Zookeeper中保存。消费者重启后,会自动从Zookeeper读取之前的消费位移,从而在上次的offset位置继续消费。
这种方式的优点是Kafka Broker不需要保存位移数据,减少了Broker端的状态信息,有利于集群动态扩展;但缺点很明显,Zookeeper适用于协调管理,并不适合高频写操作,而消费者每消费一批消息就需提交一次位移,高频写操作会降低Zookeeper性能,进而影响集群稳定性。
- Kafka最新版本(基于位移主题):为解决老版本的性能问题,最新版本中消费者的位移信息会作为普通消息,提交到专门的位移主题(_consumer_offsets)中保存,彻底摆脱了对Zookeeper的依赖,提升了位移提交的效率和稳定性。
四、Kafka文件存储架构
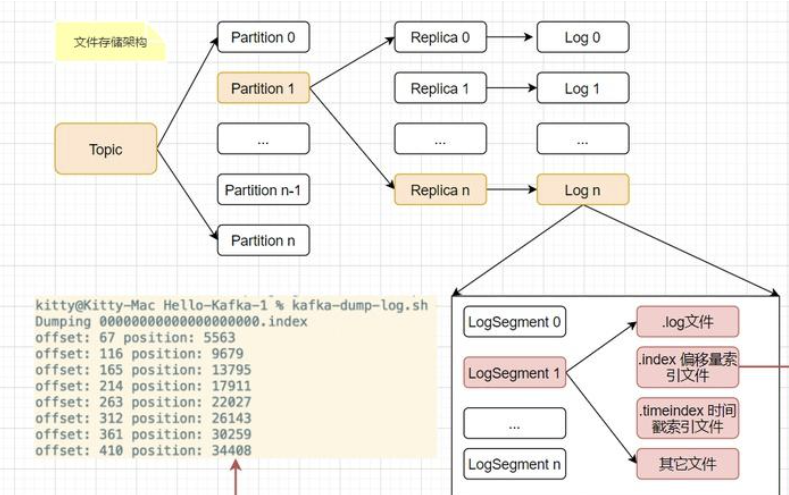
Kafka的文件存储架构层级清晰,可按以下层级理解:
-
主题与分区:一个主题(Topic)的数据会分布式存储在不同的分区(Partition)中,每个分区对应多个副本(Replica),副本用于保障数据容错性。
-
副本与日志:每个副本(Replica)对应一个日志(Log),日志是消息存储的核心载体。
-
日志与分段:每个日志(Log)由多个日志分段(LogSegment)组成,每个LogSegment包含三类文件:存储消息的.log文件、用于快速检索的索引文件(.index位移索引和.timeindex时间戳索引)以及其他辅助文件。这种分段设计便于消息的过期清理和高效检索。
五、Kafka核心问题:有序性与可靠性保障
数据的有序性和可靠性是Kafka学习中的核心难点,也是实际应用中容易出问题的地方,结合参考资料梳理解决方案和核心机制如下:
1. 数据有序性保障
Kafka默认无法保证全局消息有序,因为消息可能被发送到多个分区,不同分区的消息由不同线程处理消费,跨分区无法保证顺序。但部分业务场景(如订单处理)需要有序消费,解决方案如下:
核心思路:将需要顺序消费的消息发送到指定分区。具体可通过两种方式实现:一是直接指定目标分区;二是根据消息Key的哈希值与分区数量运算,确保相同Key的消息进入同一个分区。由于单个分区内的消息是有序存储和消费的,再配合"一个消费者对应一个线程"的模式,将同一哈希Key的消息放入同一个队列,由同一个消费者的同一个线程消费,即可保证这部分消息的有序性。
总结链路:一个生产者 → 一个分区 → 一个队列 → 一个消费者 → 一个线程。需注意,这种方式会增加单个分区的压力,当有序消费的消息量较大时,会影响整体吞吐量。
2. 数据可靠性保障
Kafka通过多个核心概念(AR、OSR、ISR、HW、LEO)和机制保障数据可靠性,这些概念相互关联,需结合理解:
(1)核心概念定义
- AR(Assigned Replicas):分区的所有副本统称AR。所有消息先发送到主副本(Leader),再由从副本(Follower)从Leader拉取同步,同步期间Follower可能滞后于Leader,处于非完全同步状态。
- OSR(Out Sync Replicas):与Leader副本未完全同步、滞后较多的副本集合。
- ISR(In Sync Replicas):AR的子集,包含所有与Leader完全同步的副本。若ISR中的Follower滞后过多,会被移出ISR进入OSR;当OSR中的副本重新与Leader完全同步,会被移回ISR。
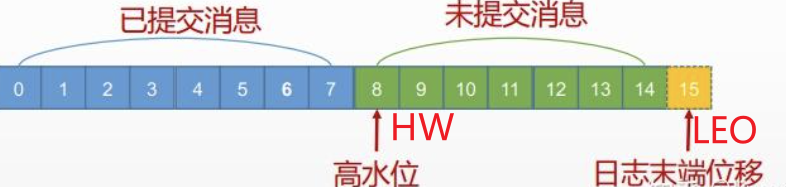
- HW(High Watermark):高水位线,标识特定消息偏移量,消费者仅能拉取HW之前的消息。
- LEO(Log End Offset):标识日志文件中下一条待写入消息的offset。ISR中的每个副本都会维护自身的LEO,正常同步时HW等于LEO。
示例理解:若HW=8,消费者仅能拉取offset 0~7的消息;LEO=15表示Leader已写入0~14的消息,下一条待写入消息offset为15,且这些消息尚未同步到Follower。
(2)ISR、HW、LEO的同步过程
假设某分区有1个Leader和2个Follower,生产者向Leader写入offset 3、4两条消息,同步过程如下:
-
生产者写入消息后,Leader的LEO变为5,随后Follower开始从Leader拉取同步数据。
-
若因网络问题,Follower2同步滞后,未完成offset 3、4的同步,此时HW=4,消费者仅能看到offset 0~3的消息。
-
延迟后Follower2完成同步,此时Leader和两个Follower的LEO均为5,HW更新为5,两个Follower均在ISR中。若后续Leader或Follower宕机,会从ISR中选举新Leader。
(3)HW高水位的弊端
HW机制存在两个明显问题:一是高水位更新需要额外的拉取请求,增加同步开销;二是Leader与Follower的同步时差可能导致数据丢失或不一致。
- 数据丢失场景(min.insync.replicas=1):当最小同步副本数设置为1时,Leader写入消息后立即向生产者返回成功。若此时Leader宕机,Follower尚未同步该消息,新选举的Leader(从Follower产生)将缺失这条消息,导致数据丢失。
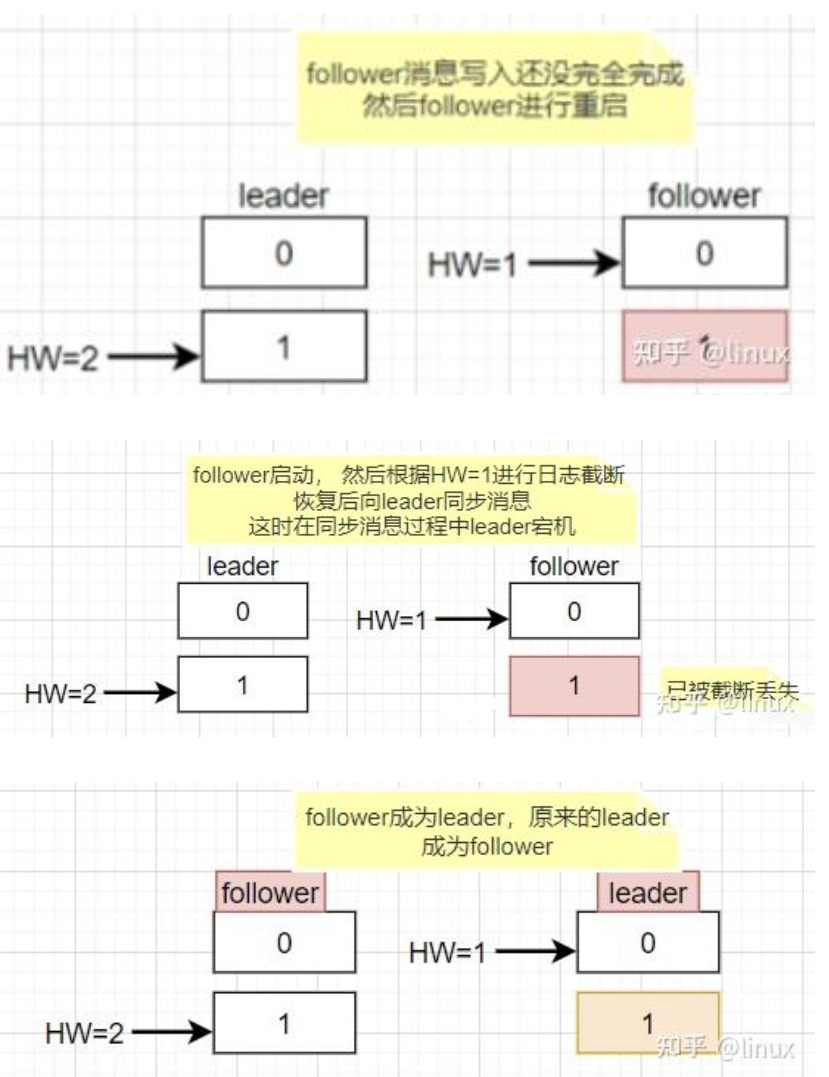
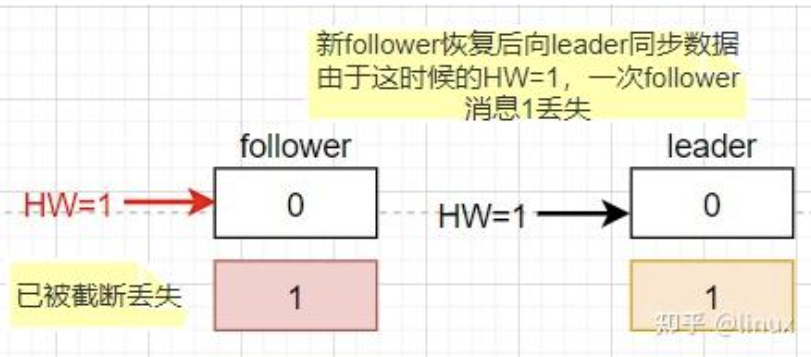
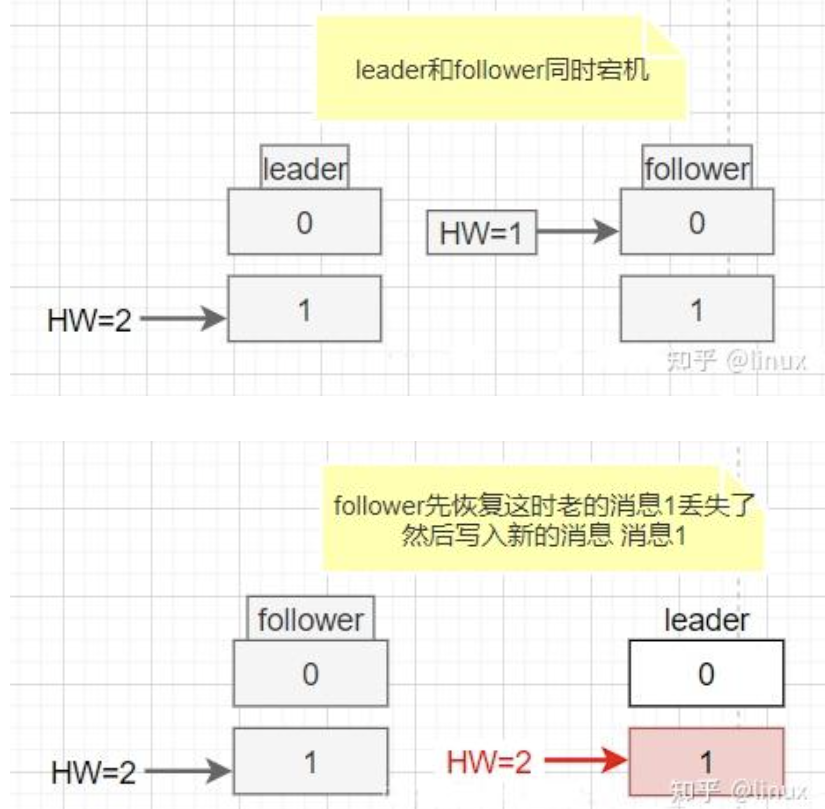
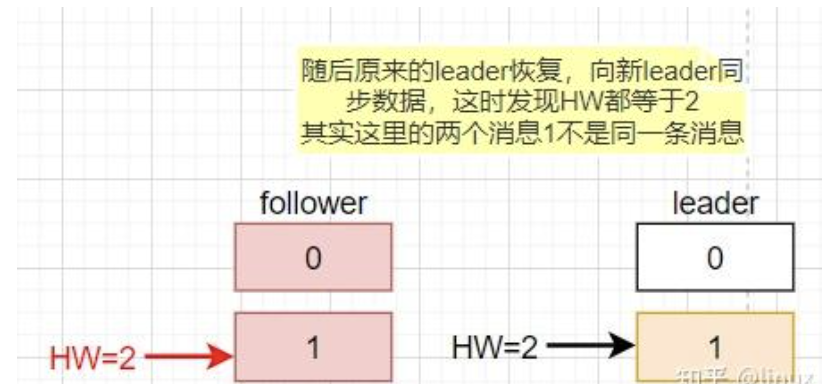
- 数据不一致场景:Leader与Follower同时宕机,Follower先恢复并写入消息1(HW=1),随后Leader恢复,发现两者HW相等未进行同步,但两者的消息1并非同一内容,导致数据不一致。
(4)解决方案:Leader Epoch
Kafka 0.11.0.0版本引入Leader Epoch解决HW的缺陷。Leader Epoch是(epoch, offset)的组合:epoch为Leader版本号,从0开始,每更换一次Leader则epoch+1;offset对应该epoch版本Leader写入第一条消息的位移。例如(0,0)表示第一个Leader(epoch=0)从offset=0开始写入;(1,120)表示第二个Leader(epoch=1)从offset=120开始写入。
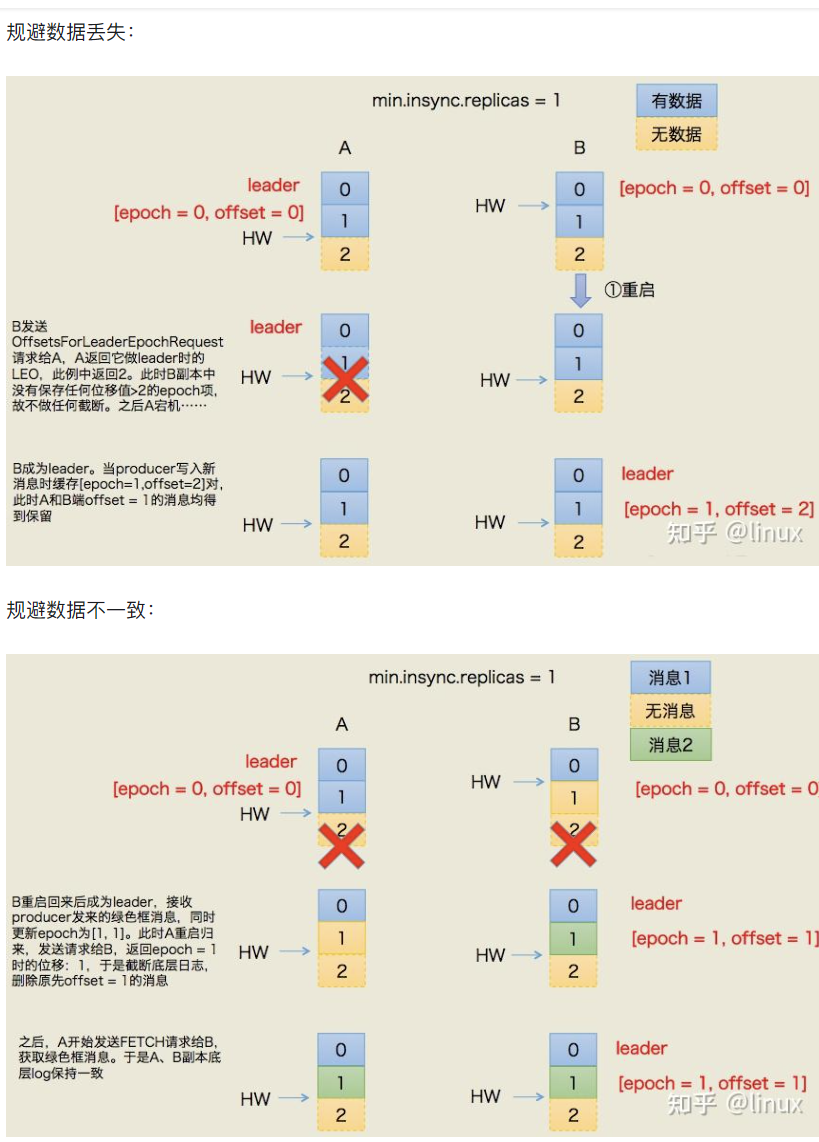
作用:通过epoch区分Leader版本,新Leader选举后可通过epoch确认缺失消息并补充,规避数据丢失;同时避免不同Leader版本的消息混淆,保证数据一致性。
六、Kafka高性能设计解析
Kafka能实现低延迟、高吞吐的消息处理,得益于一系列精妙设计,结合参考资料梳理如下:
1. 异步发送
Kafka支持异步和同步发送,异步发送是提升吞吐量的关键。异步发送中,调用发送方法后消息写入通道即返回成功,无需等待Broker响应;Dispatcher协程从通道轮询消息发送到Broker,另有异步协程处理Broker返回结果。同步发送本质也是异步,仅通过waitGroup将异步操作转为同步等待ack响应。
2. 批量发送
将多个消息打包成批次发送,减少网络传输开销,提升效率。由两个参数控制:
- batch.size:批量消息大小,默认16KB。适当增大可提升吞吐量,但过大会增加延迟,需平衡业务需求。
- linger.ms:批量发送等待时间,默认0(立即发送)。设置大于0时,Kafka会等待指定时间,若消息大小达batch.size或等待时间结束,则打包发送。适当设置(10~100ms)可提升批量率。
生产者将消息缓存到缓冲区,满足上述任一条件即触发发送;若等待时间内未达batch.size,也会发送缓存消息避免积压。
3. 压缩技术
通过压缩消息减少网络传输开销,提升吞吐量,但会消耗CPU资源。Kafka支持多种压缩算法:2.1.0版本前支持GZIP、Snappy、LZ4;2.1.0后新增Zstandard(Facebook开源,压缩比高)。性能对比(吞吐量、压缩比均越高越好):
- 吞吐量:LZ4 > Snappy > zstd 和 GZIP
- 压缩比:zstd > LZ4 > GZIP > Snappy
核心参数:compression.type控制压缩算法(默认none,不压缩);compression.level控制压缩级别(0-9,默认-1为算法默认级别)。注意:若Broker与生产者压缩算法不同,会先解压再重新压缩;消息版本兼容问题也可能触发该操作。
4. Pagecache机制 & 顺序追加落盘
Broker接收消息后,先写入PageCache(操作系统页缓存)即向生产者返回成功,PageCache中的数据由Linux flusher程序异步刷盘到日志文件。PageCache位于内存,读写速度快,避免同步刷盘的开销;同时消息顺序追加到日志尾部,利用磁盘顺序I/O性能(远高于随机I/O),提升吞吐量。
5. 零拷贝技术
Kafka存在大量"网络数据持久化到磁盘"(Producer→Broker)和"磁盘文件网络发送"(Broker→Consumer)操作,传统I/O存在多次拷贝和上下文切换,性能低。零拷贝技术优化该过程:
- 网络数据持久化磁盘:使用mmap(内存映射)技术,将内核读缓冲区与用户空间缓冲区地址映射,实现数据共享,省去"内核读缓冲区→用户缓冲区"的拷贝,减少开销。
- Broker→Consumer数据传输:使用sendfile技术,通过NIO的transferTo/transferFrom调用操作系统sendfile,实现"磁盘文件→内核读缓冲区→Socket缓冲区"直接传输,消除CPU拷贝,提升效率。
6. 稀疏索引
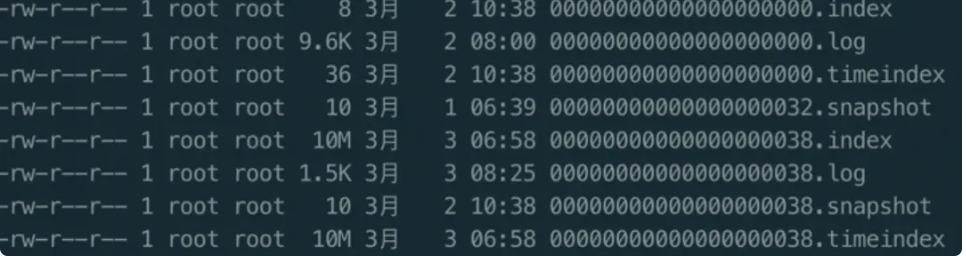
日志文件配套位移索引(.index)和时间戳索引(.timeindex),采用稀疏索引设计:不为每条消息建立索引,每写入一定量消息(log.index.interval.bytes参数控制,默认4KB)添加一个索引项。因索引项按顺序排列,可通过二分查找(时间复杂度O(lgN))快速检索,减少查找时间。
-
位移索引(.index):索引项含"相对位移"(消息位移与索引文件起始位移的差值,节省存储)和"文件物理位置"(消息在.log文件的存储地址),通过物理位置可快速定位消息。例如查找位移3550的消息,先通过二分查找找到小于3550的最大索引项,再从.log文件对应物理位置顺序查找。
-
时间戳索引(.timeindex):0.10.0.0版本后新增,用于按时间戳快速检索消息,索引项含时间戳和对应消息位移,检索流程与位移索引类似。
7. Broker与数据分区
Kafka集群含多个Broker,主题的多个分区分布式存储在不同Broker上,利用多台机器的存储和计算资源,实现并行处理和横向扩容,是高吞吐的基础。
8. 多Reactor多线程网络模型
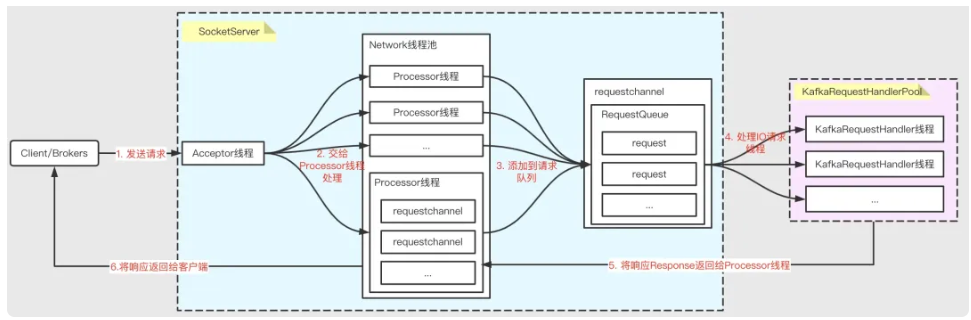
Broker端采用该模型提升并发处理能力,核心组件为SocketServer和KafkaRequestHandlerPool:
- SocketServer:实现Reactor模式,接收多个客户端(Producer、Consumer、其他Broker)的并发请求并返回结果。
- KafkaRequestHandlerPool:Worker线程池,含多个工作线程,处理实际I/O请求逻辑。
处理流程:
- Acceptor线程接收客户端请求;
- 轮询分发给Processor线程;
- Processor封装请求为Request对象,放入RequestQueue队列;
- KafkaRequestHandlerPool分配工作线程处理队列中的请求;
- 工作线程处理完请求后,将响应返回给Processor;
- Processor将响应返回给客户端。
参考资料链接
https://zhuanlan.zhihu.com/p/671827061