题目:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
作者:Ben Mildenhall Pratul P. Srinivasan Matthew Tancik Jonathan T. Barron Ravi Ramamoorthi Ren Ng
motivation
作者想用一种隐式表示的方法实现了照片级的视角合成效果;从整个计算机视觉的领域来讲,NeRF所解决的就是计算机视觉最根本的问题,它所展示的效果是计算机视觉领域最根本的进步。
methods

NeRF核心思想: 人眼或者相机观察三维场景的过程是,给定一个相机的pose(位置和旋转),根据三维场景参数,可以渲染得到一张投影图片。NeRF实现的其实就是这样的一个过程,将三维场景用MLP表示,前向的网络计算就和人眼或者相机观察三维场景的过程一致,当整个计算过程都可微的时候,通过渲染图片的监督,便可以对MLP进行优化,"学"出三维场景的"隐式"参数。
Neural Radiance Field Scene Representation:
可以把它看做是一个函数:如果我们从一个角度向一个静态空间发射一条射线,我们可以查询到这条射线在空间中每个点(x,y,z)的密度σ,以及该位置在射线角度(θ,φ), 下呈现出来的颜色c(R,G,B)
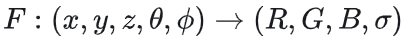
Volume Rendering with Radiance Fields:

体渲染,直观地说,我们知道相机的焦点,焦点和像素的连线可以连出来一条射线,我们可以对这条射线上所有的点的颜色做某种求和就可以得到这个像素的颜色值。理论上,我们可以对这条射线经过空间上的每个点的密度(只和空间坐标相关)和颜色(同时依赖空间坐标和入射角)进行某种积分就可以得到每个像素的颜色。当每个像素的颜色都计算出来,那么这个视角下的图像就被渲染出来了.
Pipeline
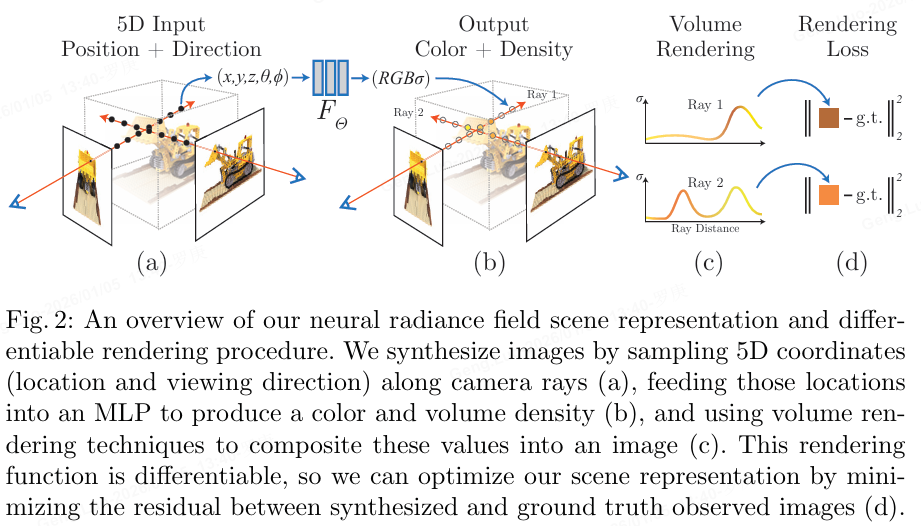
NeRF工作的过程可以分成两部分:三维重建和渲染;
- 三维重建部分本质上是一个2D到3D的建模过程,利用3D点的位置(x,y,z)及方位视角(θ,φ)作为输入,通过多层感知机(MLP)建模该点对应的颜色color(c)及体素密度volume density(σ),形成了3D场景的"隐式表示"
- 渲染部分本质上是一个3D到2D的建模过程,渲染部分利用重建部分得到的3D点的颜色及不透明度沿着光线进行整合得到最终的2D图像像素值。
- 在训练的时候,利用渲染部分得到的2D图像,通过与Ground Truth做L2损失函数(L2 Loss)进行网络优化
因为神经网络是可微分的,选取的体渲染方法是可微分;体渲染得到的图片和原图计算MSE Loss。整个过程可端到端地用梯度回传来优化非常漂亮。
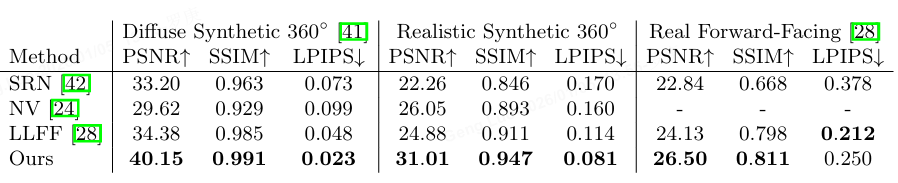
experiment

【完结】