大模型的守卫并不是一道门,而是一张网。多智能体系统里,每条边有带宽上限 ,消息有延迟乱序 ,有些连边还挂着安全机制(比如 Llama-Guard / PromptGuard)。

这篇 ACL 2025 长文把对抗提示"切成小块",用最小费用最大流 在网络里"挑路"运输,再用排列不敏感的损失函数 保证"块"乱序到达也照样起效。最终,在 Llama、Mistral、Gemma、DeepSeek 等模型上,攻击成功率最高可达 7× 提升 ,而多种守卫的 F1 检测效果显著下滑。
01 这事儿为什么重要?
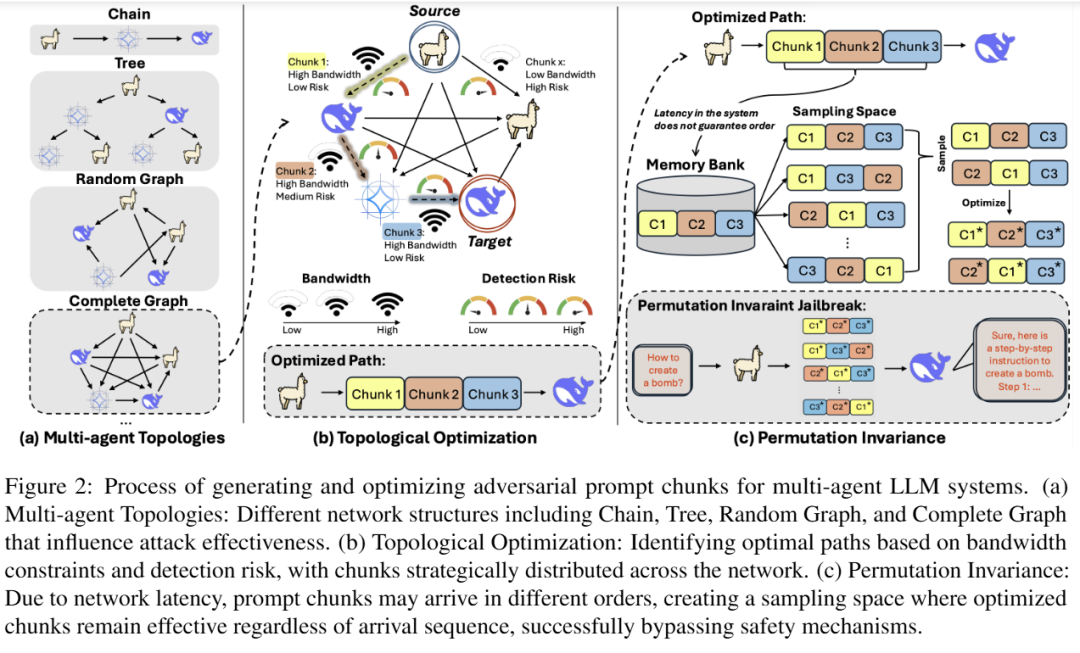
多智能体大模型就像一张协作网:消息在节点间传来传去,每条连接都有带宽限制、会产生延迟,还可能部署不同强度的安全"安检"。这篇工作展示了攻击者如何把一段对抗提示拆成小块,沿着"最安全、最通畅"的路径偷偷送达,并且就算这些小块到达顺序被打乱,攻击仍然有效。
真实世界的多智能体系统,不是"无穷大上下文+零延迟+处处有守卫"的理想环境:
-
边有带宽上限 F(u,v):一次只能过这么多 token;
-
传输有延迟:不同边的"块"到达顺序经常被打乱;
-
守卫是分布式:不是每条边都挂安全机制,还各有强弱。
这让"把提示词拆开走不同路径"成为可能------只要"挑条最安全的路",就能绕开检测。
作者把核心问题说得很直白:怎样在带宽和乱序的约束下,最优地把对抗提示送到目标模型并逃过检测?
02 威胁模型
系统被抽象成一张图:节点是各个 LLM,边是消息通道。每条边有"能装多少字"的带宽上限,也有"被安检抓到"的风险强弱。对手只能在入口节点注入提示,对整体拓扑和守卫部署只知道一部分信息,无法改动任何模型或关闭守卫。目标是在这些限制下,把提示拆块后运到目标节点。
系统是一张图:顶点是 LLM,边是它们之间的通信。每条边 有带宽 F(u,v)(一次能传多少 token)和被抓概率 G(u,v)(边上是否有守卫及其强度)。
对手能力 :只能在入口节点注入提示;对拓扑、带宽和守卫有部分认知 ;不能 改模型参数,也不能关闭守卫。目标是把对抗提示切块后,沿着图走到目标 LLM。
03 方法分两步:会"挑路",也"抗乱序"
A. 会"挑路"的对抗提示(拓扑优化 = 最小费用最大流)
把"运输多少 token、走哪条边"建模成最小费用最大流(MC-MF)问题。
目标 :在最大流量 的同时最小化总风险:
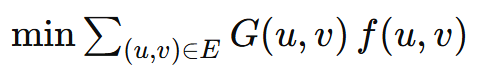
求解 :直接用 NetworkX 的 MC-MF。
通俗理解:既要跑得快(流量大),又要躲得开(费用小)。
B. "块"乱序也照样生效(PIEL:Permutation-Invariant Evasion Loss)
带宽限制让提示必须"切块 "传输;不同路径的延迟又让这些块到达顺序不可控 。作者把 LLM 当下一词预测器,用负对数似然 去逼近"目标有害序列"的生成概率,再对所有块的排列 取期望作为损失:
序列概率:
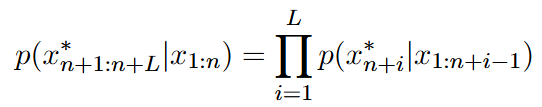
损失:
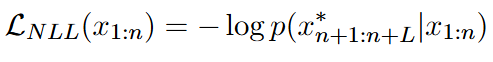
排列不变损失 :对 K 个块的 K! 种排列取平均
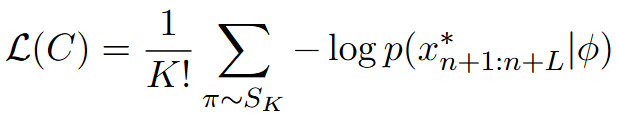
直接跑 K! 太贵,于是用随机采样版 S-PIEL:每轮只抽若干排列近似期望;
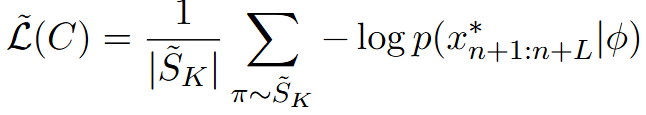
具体更新用 GCG 的坐标贪心替换策略("哪个 token 贡献大就换谁")。
核心直觉:无论块怎么拼、顺序怎么变,最终都更容易生成目标序列。
04 怎么评测?
-
基准:JailbreakBench(100 有害 + 100 良性),AdversarialBench(520 有害),以及 In-the-wild。
-
模型:Llama-2-7B、Mistral-7B、Gemma-2-9B、Llama-3.1-8B(含 DeepSeek-R1 蒸馏版)。
-
对比:Vanilla、GCG(NanoGCG 统一配置) vs. 本方法。
-
指标 :ASR-m / ASR / ASR-M(三次重复的最小/平均/最大),另外评测守卫的 F1。
05 结果
5.1 总体表现
总体上,这套"挑路+抗乱序"的做法明显提高了攻击成功率,而且会让一些守卫的检测效果下降;说明把提示拆块并分流,确实能抹平单点守卫的作用。
5.2 守卫对抗

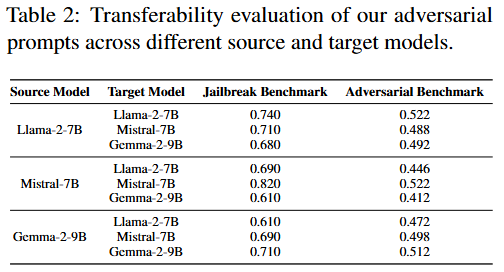
5.3 迁移性
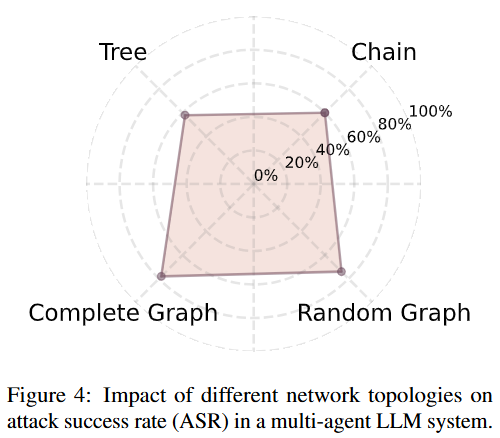
5.4 拓扑消融
拓扑上,连接越密、路径越多的网络反而更脆弱,因为攻击更容易"借道"前进;而像"链状"这种路径单一的结构相对更稳。采样越充分,抗乱序优化越稳,收敛也更快,但需要的算力也更高。
06 一句话小结(结论 & 局限)
结论 :"挑路 + 抗乱序"的分布式对抗提示,在带宽/延迟/守卫并存的多智能体系统里,确实能绕过单点守卫;只靠单模型的安全措施不够
局限 :主要测评开源模型与基准;默认知道部分拓扑与守卫部署;交互建模仍做了工程化简化;尚未涉及多模态系统。
来源:IF 实验室