系列文章目录
- 第一章 【大数据环境安装指南】 JDK安装
- 第二章 【大数据环境安装指南】 Python安装
- 第三章 【大数据环境安装指南】VMware虚拟机静态IP及多IP配置
- 第四章 【大数据环境安装指南】zookeeper单机版环境搭建教程
- 第五章 【大数据环境安装指南】Hadoop单机版环境搭建教程
- 第六章 【大数据环境安装指南】HBase单机环境搭建教程
文章目录
- 系列文章目录
- [🔥 前言](#🔥 前言)
- 一、环境前提与依赖检查
-
- [1.1 基础环境要求](#1.1 基础环境要求)
-
- [1.1.1 网络配置](#1.1.1 网络配置)
- [1.1.2配置主机名和 hosts 映射](#1.1.2配置主机名和 hosts 映射)
- [1.1.3 创建普通用户和免密登录](#1.1.3 创建普通用户和免密登录)
- [1.2 核心依赖组件](#1.2 核心依赖组件)
- 二、集群节点规划
- 三、核心配置步骤
-
- [3.1 下载并解压HBase安装包](#3.1 下载并解压HBase安装包)
- [3.2 配置HBase环境变量](#3.2 配置HBase环境变量)
- [3.3 修改核心配置文件](#3.3 修改核心配置文件)
-
- [3.3.1 配置hbase-env.sh(环境变量配置)](#3.3.1 配置hbase-env.sh(环境变量配置))
- [3.3.2 配置hbase-site.xml(核心核心配置)](#3.3.2 配置hbase-site.xml(核心核心配置))
- [3.3.3 配置regionservers(指定RegionServer节点)](#3.3.3 配置regionservers(指定RegionServer节点))
- [3.3.4 配置backup-masters(指定备用Master,可选但推荐)](#3.3.4 配置backup-masters(指定备用Master,可选但推荐))
- [3.4 同步配置到所有节点](#3.4 同步配置到所有节点)
- 四、集群启动与状态验证
-
- [4.1 启动集群](#4.1 启动集群)
- [4.2 状态验证(3种方式,确保集群正常)](#4.2 状态验证(3种方式,确保集群正常))
-
- [4.2.1 查看进程(最直接)](#4.2.1 查看进程(最直接))
- [4.2.2 通过HBase Shell验证](#4.2.2 通过HBase Shell验证)
- [4.2.3 通过Web UI验证](#4.2.3 通过Web UI验证)
- 五、常见问题排查方案
-
- [5.1 启动HBase后无HMaster进程](#5.1 启动HBase后无HMaster进程)
- [5.2 RegionServer无法启动](#5.2 RegionServer无法启动)
- [5.3 Web UI无法访问](#5.3 Web UI无法访问)
- [5.4 HBase Shell执行命令报错:Connection refused](#5.4 HBase Shell执行命令报错:Connection refused)
- 六、总结与后续操作建议
🔥 前言
-
集群搭建环境:
操作系统环境:Centos 7、Rocky 9 、Kylin V11
hadoop版本:3.4.2
JDK版本:8
Hbase版本:2.5.13
Zookeeper版本:3.8.4
-
HBase作为Hadoop生态下的分布式列存储数据库,具备高可靠性、高扩展性和海量数据存储能力,是大数据领域核心组件之一。本文将从环境依赖、节点规划、核心配置到集群启动验证,手把手教你搭建一套可用的HBase集群,适配Hadoop3.x版本,新手也能轻松上手!
一、环境前提与依赖检查
HBase集群运行依赖基础环境和核心组件支撑,搭建前务必完成以下准备工作,避免后续配置踩坑!
1.1 基础环境要求
1.1.1 网络配置
集群节点间网络互通,关闭防火墙/SELinux(生产环境可配置白名单,测试环境直接关闭更便捷)
bash
# 临时关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭SELinux
setenforce 0 # 临时
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config # 永久1.1.2配置主机名和 hosts 映射
- 配置主机名(每个节点对应修改):
bash
# node1节点
hostnamectl set-hostname node1
# node2节点
hostnamectl set-hostname node2
# node3节点
hostnamectl set-hostname node3- 配置 hosts 文件(所有节点):
bash
vim /etc/hosts
# 添加以下内容
192.168.3.129 node1
192.168.3.130 node2
192.168.3.131 node31.1.3 创建普通用户和免密登录
Hadoop 组件之间需要基于 SSH 进行通讯,实现主节点到所有从节点的SSH免密登录(集群间通信必备)
(1)、创建hadoop用户
Hadoop 官方不建议用 root 运行集群(安全风险 + 权限混乱),核心思路是创建专属普通用户(如 hadoop),并赋予相关目录权限,全程以该用户操作。
bash
useradd -m hadoop
passwd hadoop # 设置密码(如hadoop123)
# 在/usr/local目录下新建app目录作为应用安装目录
mkdir /usr/local/app
#app属主授权给hadoop用户
chown -R hadoop:hadoop /usr/local/app(2)、赋予hadoop用户sudo权限(可选,方便后续操作)
bash
echo "hadoop ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers(3)、 在 Master 节点(node1)生成密钥对:
bash
#切换到hadoop用户,生成密钥:
su - hadoop
ssh-keygen -t rsa # 一路回车,生成密钥执行命令会提示相关操作,默认按回车就好
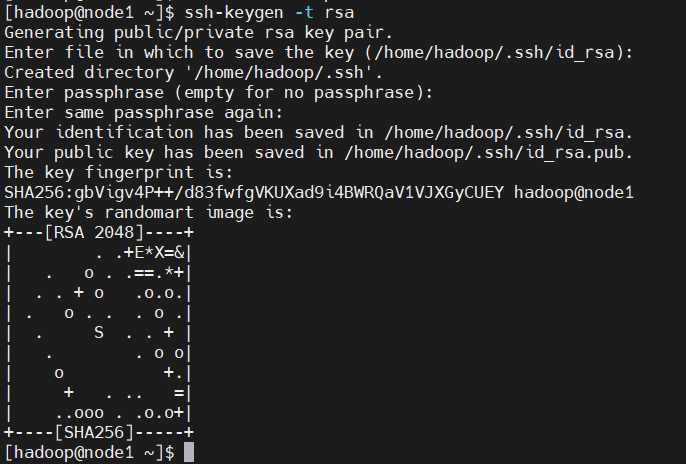
(4)、 授权
进入 ~/.ssh 目录下,查看生成的公匙和私匙
bash
cd ~/.ssh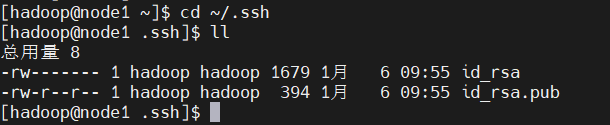
将公钥分发到所有节点(包括自身):
bash
# 写入公匙到授权文件
cat id_rsa.pub >> authorized_keys
# 授权给node1(和localhost是同一台机器,可省略,但建议加)
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
chmod 600 authorized_keys检查 SELinux / 防火墙:若开启 SELinux,需确保 SSH 目录上下文正确,执行如下命令:
bash
restorecon -R ~/.ssh验证免密登录是否生效,执行以下命令验证(无需输入密码即表示成功):
bash
ssh node2若直接进入node2主机的命令行,说明免密登录配置完成。

1.2 核心依赖组件
HBase依赖HDFS存储数据、ZooKeeper实现分布式协调,需提前搭建并验证可用:
-
Hadoop集群:推荐3.x版本(如3.4.2),需确保HDFS和YARN正常启动
-
ZooKeeper集群:需确保集群正常启动,且节点间选举正常
提示:如果还未搭建Hadoop和ZooKeeper集群,可以参考我之前的文章:
二、集群节点规划
根据实际服务器资源规划节点角色,以下为3节点集群示例(可根据资源调整,最小集群建议3节点),所有节点均部署ZooKeeper(组成ZK集群):
| 节点IP | 主机名 | 集群角色 | 说明 |
|---|---|---|---|
| 192.168.3.129 | node1 | HMaster、RegionServer、ZooKeeper | 主Master节点,负责集群管理 |
| 192.168.3.130 | node2 | BackupMaster、RegionServer、ZooKeeper | 备用Master,主Master故障时接管,提升可用性 |
| 192.168.3.131 | node3 | RegionServer、ZooKeeper | 数据节点,负责数据存储和读写服务 |
⚠️ 注意:主机名与IP的映射需配置在所有节点的/etc/hosts文件中,示例配置:
bash
192.168.3.129 node1
192.168.3.130 node2
192.168.3.131 node3三、核心配置步骤
本步骤以主节点(node1)为操作中心,完成HBase安装包下载、配置后,同步到其他节点,全程附详细命令。
3.1 下载并解压HBase安装包
选择适配Hadoop3.x的HBase版本(本文以2.5.13为例,稳定且兼容),在node1执行以下命令:
- 下载HBase 2.5.13安装包(官网镜像,速度较慢可换国内镜像)
bash
wget https://dlcdn.apache.org/hbase/2.5.13/hbase-2.5.13-hadoop3-bin.tar.gz- 解压到指定安装目录(如/usr/local/app)
bash
tar -zxvf hbase-2.5.13-bin.tar.gz -C /usr/local/app/- 软链接(简化后续操作,可选但推荐)
bash
ln -s /usr/local/app/hbase-2.5.13 /usr/local/app/hbase3.2 配置HBase环境变量
在所有节点配置环境变量,确保全局可调用HBase命令:
- 编辑环境变量配置文件
bash
vim /etc/profile- 添加以下内容(指定HBase安装路径)
powershell
export HBASE_HOME=/usr/local/app/hbase
export PATH=$PATH:$HBASE_HOME/bin- 生效环境变量
bash
source /etc/profile- 验证配置是否生效(出现版本信息即成功)
bash
hbase version
3.3 修改核心配置文件
HBase核心配置文件位于$HBASE_HOME/conf目录,需修改4个关键文件:hbase-env.sh、hbase-site.xml、regionservers、backup-masters。
3.3.1 配置hbase-env.sh(环境变量配置)
该文件用于指定JDK路径、禁用内置ZK等核心环境参数:
bash
vim $HBASE_HOME/conf/hbase-env.sh添加/修改以下关键配置(注释掉原有冲突配置):
powershell
# 1. 指定JDK路径(替换为你的实际JDK安装路径)
export JAVA_HOME=/usr/local/jdk8
# 2. 禁用HBase内置的ZooKeeper(使用独立ZK集群,必配置)
export HBASE_MANAGES_ZK=false
# 3. 解决HBase与Hadoop版本兼容问题(Hadoop3.x必备)
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP=true
# 4. 配置HBase日志目录(可选,默认在$HBASE_HOME/logs)
export HBASE_LOG_DIR=$HBASE_HOME/logs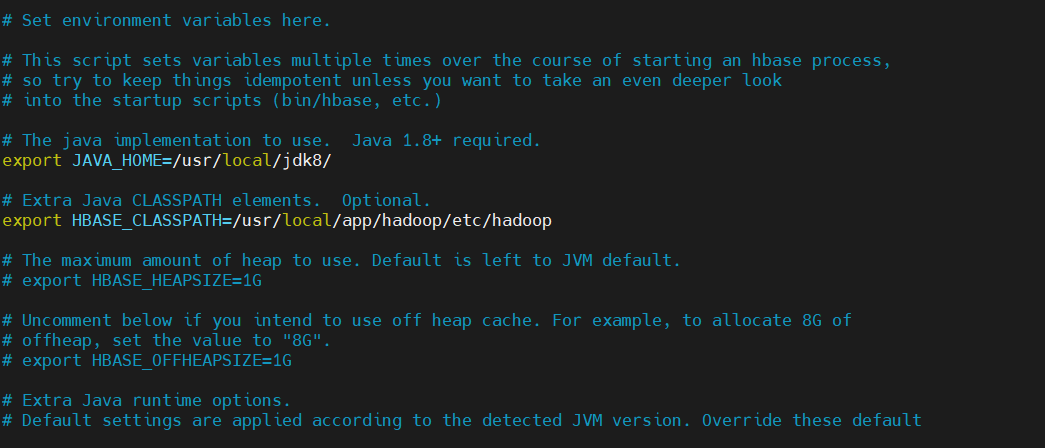
3.3.2 配置hbase-site.xml(核心核心配置)
该文件是HBase集群最核心的配置文件,指定HDFS存储路径、ZK集群地址等关键信息:
bash
vim $HBASE_HOME/conf/hbase-site.xml完整配置内容(替换对应节点信息):
xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- 1. 指定HBase数据在HDFS的存储路径(对应Hadoop的fs.defaultFS) -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!-- 2. 启用分布式集群模式(true为分布式,false为单机) -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 3. 指定ZooKeeper集群地址(逗号分隔所有ZK节点) -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
<!-- 4. 指定ZooKeeper数据存储目录(与ZK集群配置的dataDir一致) -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/app/zookeeper/data</value>
</property>
<!-- 5. 指定HMaster绑定地址(主节点主机名+端口,默认16000) -->
<property>
<name>hbase.master.address</name>
<value>node1:16000</value>
</property>
<!-- 6. HMaster Web UI端口(默认16010,可自定义) -->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!-- 7. RegionServer Web UI端口(默认16030) -->
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<!-- 8. 关闭元数据预分区(新手友好,避免初始配置复杂) --><property>
<name>hbase.master.meta.thread.rescanfrequency</name>
<value>10000</value>
</property>
</configuration>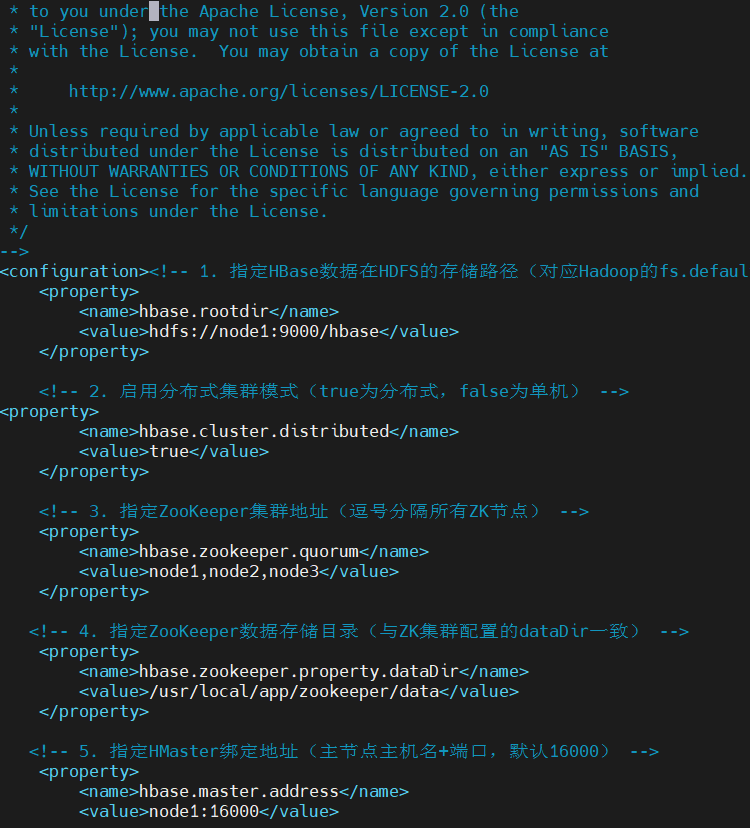
3.3.3 配置regionservers(指定RegionServer节点)
该文件用于指定集群中所有RegionServer节点的主机名,HBase启动时会自动在这些节点启动RegionServer进程:
bash
vim $HBASE_HOME/conf/regionservers删除原有内容,添加以下节点(每行一个):
powershell
node1
node2
node3
3.3.4 配置backup-masters(指定备用Master,可选但推荐)
为提升集群可用性,配置备用Master节点(node2),主Master故障时自动接管:
- 创建backup-masters文件(该文件默认不存在)
bash
vim $HBASE_HOME/conf/backup-masters- 添加备用Master节点主机名:
bash
node23.4 同步配置到所有节点
将node1上配置好的HBase目录同步到node2和node3,避免重复配置:
bash
# 同步到node2
scp -r /usr/local/app/hbase node2:/usr/local/app/
# 同步到node3
scp -r /usr/local/app/hbase node3:/usr/local/app/
# 同步环境变量配置文件(若其他节点未手动配置)
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
# 在node2和node3分别执行,生效环境变量
source /etc/profile四、集群启动与状态验证
⚠️ 启动顺序至关重要!必须严格遵循:ZooKeeper集群 → Hadoop集群 → HBase集群
4.1 启动集群
bash
# 1. 启动ZooKeeper集群(所有ZK节点执行)
zkServer.sh start
# 2. 启动Hadoop集群(主节点node1执行)
start-dfs.sh
start-yarn.sh
# 3. 启动HBase集群(主节点node1执行)
start-hbase.sh4.2 状态验证(3种方式,确保集群正常)
4.2.1 查看进程(最直接)
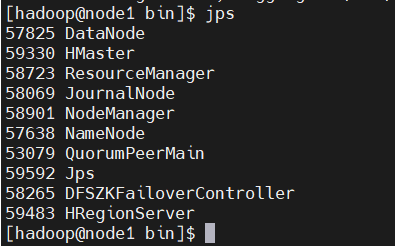
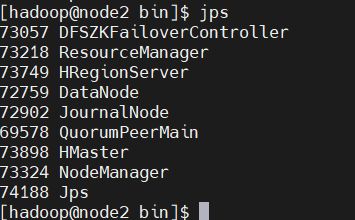
在各节点执行jps命令,查看对应进程是否存在:
-
node1(主Master):HMaster、RegionServer、QuorumPeerMain(ZK)、NameNode、ResourceManager
-
node2(备用Master):HMaster(备用)、RegionServer、QuorumPeerMain(ZK)、DataNode、NodeManager
-
node3:RegionServer、QuorumPeerMain(ZK)、DataNode、NodeManager

4.2.2 通过HBase Shell验证
在主节点执行hbase shell进入交互模式,执行以下命令测试:
bash
#进入交互模式
hbase shell
# 查看集群状态(显示节点数、Region数等信息)
status
# 列出所有表(初始为空,无报错即正常)
list
# 创建测试表(可选,验证写入能力)
create 'test_table', 'info'
# 插入数据
put 'test_table', 'row1', 'info:name', 'zhangsan'
# 读取数据
get 'test_table', 'row1'
# 删除测试表(可选)
disable 'test_table'
drop 'test_table'
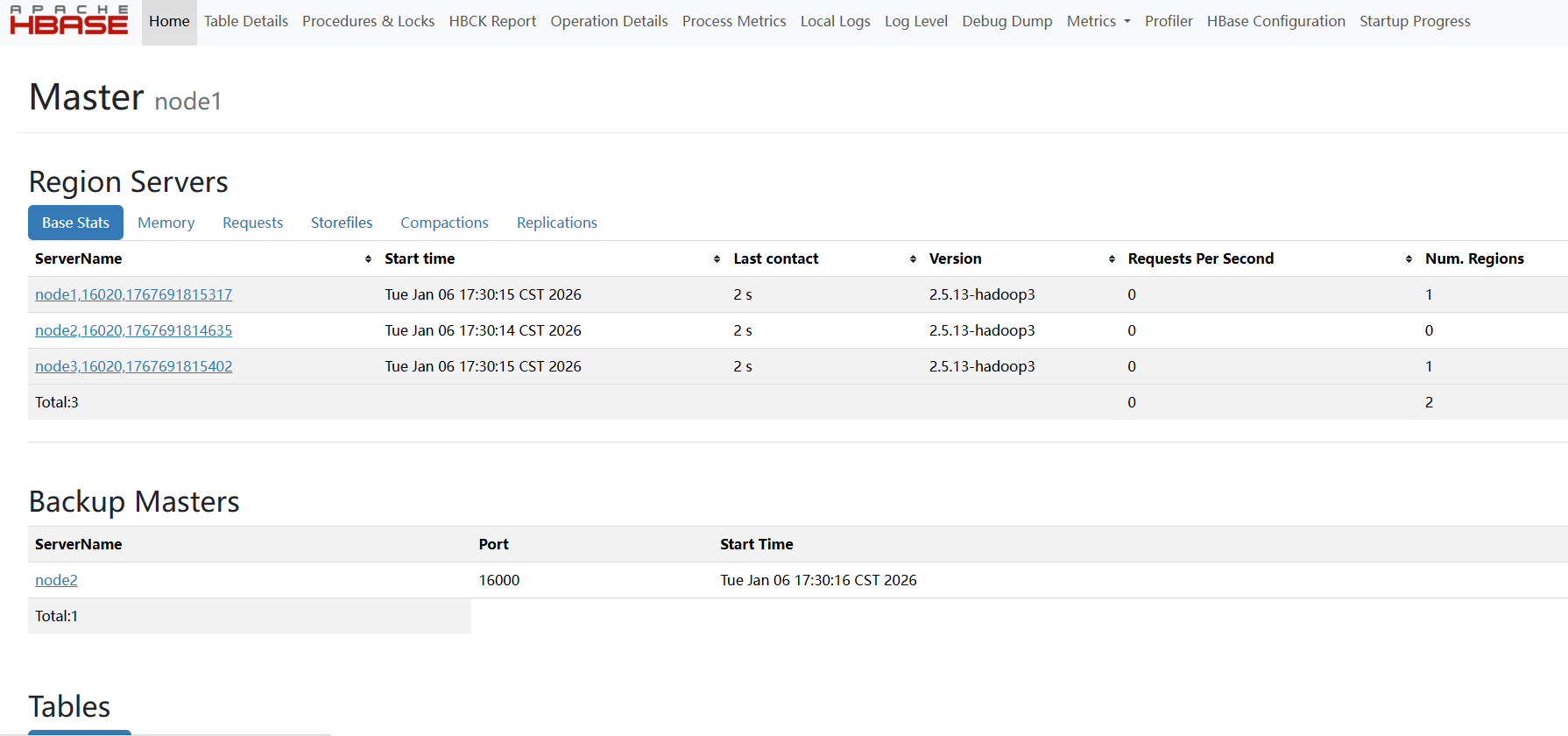
4.2.3 通过Web UI验证
打开浏览器,访问主Master的Web UI(默认端口16010):
在UI中可查看:集群拓扑、RegionServer状态、Master日志、表信息等,直观验证集群健康度。
五、常见问题排查方案
搭建过程中难免遇到问题,以下是高频问题及解决方案:
5.1 启动HBase后无HMaster进程
-
原因1:hbase-site.xml中hbase.rootdir配置错误,或HDFS未启动
-
解决方案:检查HDFS是否正常(hdfs dfsadmin -report),修正hbase.rootdir路径,确保与Hadoop的fs.defaultFS一致
-
原因2:权限不足,HBase无法写入HDFS目录
-
解决方案:执行hdfs dfs -chmod 777 /hbase授权,或指定HBase运行用户为HDFS管理员
5.2 RegionServer无法启动
-
原因1:ZooKeeper集群未正常启动,或hbase.zookeeper.quorum配置错误
-
解决方案:在各ZK节点执行zkServer.sh status验证ZK状态,确保集群有Leader节点;修正hbase-site.xml中的ZK地址
-
原因2:节点间时间不同步
-
解决方案:所有节点启动ntp服务(systemctl start ntpd),执行ntpdate ntp.aliyun.com手动同步时间
5.3 Web UI无法访问
-
原因1:防火墙未关闭,端口16010被拦截
-
解决方案:关闭防火墙(systemctl stop firewalld),并禁用开机自启(systemctl disable firewalld)
-
原因2:hbase.master.info.port被占用
-
解决方案:修改hbase-site.xml中的该端口配置(如改为16011),重启HBase
5.4 HBase Shell执行命令报错:Connection refused
原因:HMaster或RegionServer未正常启动,或网络不通
解决方案:检查对应进程是否存在,验证节点间网络互通性(ping node1、telnet node1 16000)
六、总结与后续操作建议
至此,HBase集群已搭建完成!核心要点回顾:
-
- 依赖优先:先确保ZooKeeper和Hadoop集群正常运行,再配置HBase
-
- 核心配置:hbase-site.xml中的hbase.rootdir和hbase.zookeeper.quorum是必对参数
-
- 启动顺序:ZK → Hadoop → HBase,验证优先查进程、再用Shell、最后看UI
后续操作建议:
-
- 生产环境优化:调整RegionServer内存(hbase-env.sh中的HBASE_HEAPSIZE)、配置数据备份策略
-
- 学习进阶:尝试HBase表的分区设计、批量数据导入导出、性能调优
-
- 监控运维:集成Prometheus+Grafana实现集群监控,配置日志收集方案
如果本文对你有帮助,欢迎点赞+收藏+关注!如有问题,欢迎在评论区留言讨论~