一、概述
- 知识目标:理解RAG技术的基本原理、向量化模型的工作机制、向量检索的核心思想
- 技能目标:能够独立搭建简单的RAG系统,实现对PDF文档的处理与问答,掌握向量存储与检索的基本操作
- 素养目标:培养解决实际问题的能力,提升对AI技术应用场景的认知,建立系统思维
前置知识要求
- 基本的Python编程能力
- 机器学习基础知识(了解神经网络基本概念)
- 数据结构基础(了解向量、矩阵等概念)
二、实验原理详解
1. RAG技术核心原理
检索增强生成(RAG)是一种结合信息检索与生成式AI的混合技术,通过以下流程提升大模型输出质量:
- 知识检索:从私有知识库中查找与问题相关的信息
- 信息整合:将检索到的信息作为上下文提供给大模型
- 智能生成:大模型基于上下文生成准确回答
RAG的优势在于:
- 解决大模型"幻觉"问题,提高输出准确性
- 扩展大模型知识范围,处理领域特定内容
- 支持私有数据处理,保护数据安全
- 无需重新训练模型即可更新知识
2. 向量化技术基础
向量化是将非结构化数据(文本、图像等)转换为数值向量的过程:
- 文本向量化:通过预训练模型将文本转换为固定维度的向量,保留语义信息
- 多模态向量化:将不同类型的数据(如图文)映射到同一向量空间,实现跨模态检索
- 向量特性:语义相似的内容,其向量在空间中的距离更近
3. 向量检索原理
- 向量空间模型:将所有数据表示为高维空间中的点
- 相似性度量:常用余弦相似度、欧氏距离等计算向量间的相似性
- 高效检索:通过索引结构(如FAISS提供的多种索引)加速大规模向量的相似性搜索
三、实验环境准备(已配置)
1. 环境配置指南
pip install modelscope newspaper4k lxml_html_clean jieba faiss-cpu vllm
pip install -U sentence-transformers2. 依赖库功能说明
| 依赖库 | 核心功能 | 实验中的作用 |
|---|---|---|
modelscope |
模型管理与加载平台 | 提供模型下载与加载支持 |
sentence-transformers |
句子向量生成工具 | 实现文本向量化处理 |
faiss-cpu |
向量检索引擎 | 存储向量并提供高效检索 |
newspaper4k |
网页内容提取工具 | 支持在线信息检索功能 |
jieba |
中文分词工具 | 辅助文本预处理 |
vllm |
高效LLM推理引擎 | 提供大模型推理支持 |
3. 硬件环境要求
- 推荐配置: GPU显存≥8GB,内存≥16GB,CPU≥4核
- 最低配置:CPU模式(性能会显著降低,部分模型可能无法运行)
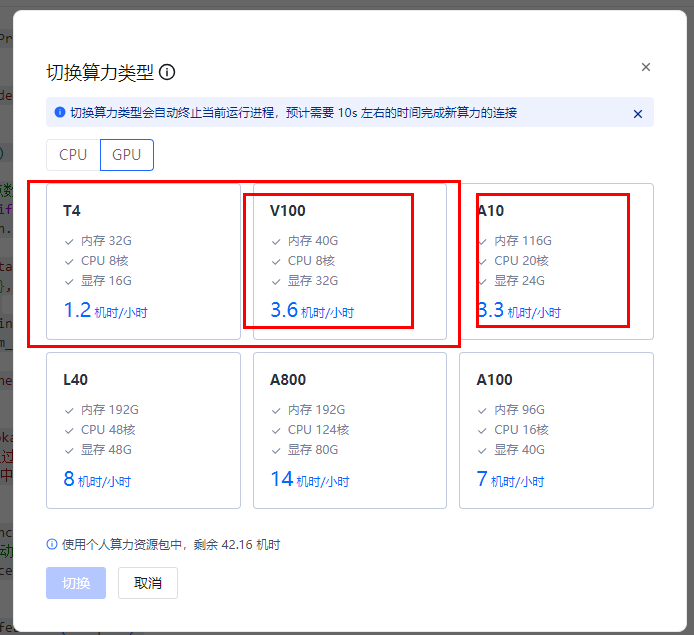
- 推荐A10
四、实验内容与步骤(分阶段实施)
第一阶段:基础准备
1. 模型下载与验证
在workspace目录下 运行download_model.py文件,完成模型的下载。该脚本会自动从指定的远程服务器或存储库中下载所需的模型文件,并将其保存到本地的指定目录中。如果需要其他模型,可以将模型的下载链接或配置添加到脚本中,然后重新运行该文件。
运行命令如下:
# 切换到工作目录 cd /workspace # 运行模型下载脚本 python download_model.py关键检查点:
- 确认模型文件成功下载(检查目标文件夹中的模型文件)
- 验证模型文件完整性(可通过文件大小或校验和确认)
- 常见问题处理:网络超时解决方案、权限问题处理
第二阶段:向量化技术实践
1. 使用m3e-embedding-small进行embedding向量化
在本步骤中,我们使用 m3e-embedding-small 模型对数据进行向量化处理。向量化是将文本数据转换为数值向量的过程,这些向量可以用于相似性计算、聚类或其他机器学习任务。
cd /workspace/Codes && python test_embedding.py
from transformers import CLIPProcessor, CLIPModel
import torch
model_dir = "/workspace/AI-ModelScope/clip-vit-large-patch14"
# 方案1: 强制使用CPU
# device = torch.device("cpu")
# 方案2: 使用GPU但启用半精度浮点数(float16)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dtype = torch.float16 if torch.cuda.is_available() else torch.float32
print(f"loading {model_dir} start ...")
print(f"Using device: {device}, dtype: {dtype}")
# 使用半精度浮点数加载模型到GPU
model = CLIPModel.from_pretrained(model_dir, torch_dtype=dtype).to(device)
processor = CLIPProcessor.from_pretrained(model_dir, use_fast=False) # 禁用快速处理器以避免 Torchvision 依赖
print(f"loaded {model_dir} done...")
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
inputs = processor(text=sentences, return_tensors="pt", padding=True, truncation=True, max_length=77)
# 将输入转换为正确的数据类型并移动到设备上
inputs = {k: v.to(device=device, dtype=dtype if v.dtype == torch.float32 else v.dtype) for k, v in inputs.items()}
with torch.no_grad():
outputs = model.get_text_features(**inputs)
# 将输出转换回CPU和float32以便进行numpy操作
embeddings = outputs.cpu().to(torch.float32).numpy()
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")脚本 test_embedding.py 的作用是加载 m3e-embedding-small 模型,对输入数据进行处理并生成对应的向量。
运行后会得到如下结果:
实验任务:
- 观察不同长度文本的向量化结果
- 比较语义相似文本的向量距离
- 分析向量维度对语义表达的影响
思考问题:
- 为什么相同意思的不同表达方式会有相似的向量表示?
- 文本长度对向量化结果有什么影响?
2. 使用 CLIP 进行图文 Embedding 向量化
在多模态任务中,图文的联合表示(embedding)是一个重要的研究方向。CLIP(Contrastive Language--Image Pretraining)是一种强大的模型,可以将图像和文本映射到同一个向量空间,从而实现图文的对齐和相似性计算。
在Codes目录下 ,使用以下命令用于运行脚本 test_multimodal_embedding.py:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
import requests
from io import BytesIO
import numpy as np
import time
import asyncio
from concurrent.futures import ThreadPoolExecutor
# 使用绝对路径
model_path = "/workspace/AI-ModelScope/clip-vit-large-patch14" # 修正路径格式
# 加载模型和处理器
print(f"loading model {model_path}")
try:
model = CLIPModel.from_pretrained(model_path)
processor = CLIPProcessor.from_pretrained(model_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
print(f"load model {model_path} done...")
except Exception as e:
print(f"Error loading model: {e}")
raise
# 函数:生成文本嵌入
def get_text_embedding(text):
inputs = processor(text=[text], return_tensors="pt", padding=True).to(device)
with torch.no_grad():
embedding = model.get_text_features(**inputs)
return embedding.cpu().numpy()
def get_image_embedding(image_url):
try:
response = requests.get(image_url)
image = Image.open(BytesIO(response.content)).convert("RGB")
inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
embedding = model.get_image_features(**inputs)
return embedding.cpu().numpy()
except Exception as e:
return None
## 计算相似度
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2.T) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
## 找到相似度
def similarity(query, candidates, query_type, candidate_type):
# 解析请求数据
query = query
candidates = candidates
query_type = query_type
candidate_type = candidate_type
# 生成查询嵌入
if query_type == "text":
query_embedding = get_text_embedding(query).tolist() # 转换为可序列化格式
elif query_type == "image":
query_embedding = get_image_embedding(query)
query_embedding = query_embedding.tolist() # 转换为可序列化格式
# 计算相似度
similarities = []
for candidate in candidates:
candidate_embedding = get_image_embedding(candidate)
similarity_score = cosine_similarity(query_embedding, candidate_embedding)
similarities.append((candidate, float(similarity_score))) # 确保 similarity_score 是 float 类型
# 按相似度排序并返回最相似的候选结果
similarities.sort(key=lambda x: x[1], reverse=True)
return {"similarities": similarities}
if __name__ == '__main__':
query = "What is the cycle life of this 3.2V 280ah Lifepo4 battery?"
candidates = [
"https://sc04.alicdn.com/kf/H3510328463d740b2afbcf401c8c108f2J/240062176/H3510328463d740b2afbcf401c8c108f2J.jpg",
"https://sc04.alicdn.com/kf/H75608c12162a47a4ad41fd331c212e29X/240062176/H75608c12162a47a4ad41fd331c212e29X.jpg",
"https://sc04.alicdn.com/kf/H1c593aa026e64725a43e1a538be6951ay/240062176/H1c593aa026e64725a43e1a538be6951ay.jpg",
"https://sc04.alicdn.com/kf/Hb7cda33e8bdc476091ff2962cb4f0ae3x/240062176/Hb7cda33e8bdc476091ff2962cb4f0ae3x.jpg",
"https://sc04.alicdn.com/kf/Hc00c90da8dcb43b8aeee7eb11b12291b1/240062176/Hc00c90da8dcb43b8aeee7eb11b12291b1.jpg",
"https://sc04.alicdn.com/kf/H9b13be1329344c3a96f295f144932582u/240062176/H9b13be1329344c3a96f295f144932582u.jpg",
"https://sc04.alicdn.com/kf/H471ca5edf21a4caea852192af7fbefe7T/240062176/H471ca5edf21a4caea852192af7fbefe7T.jpg",
"https://sc04.alicdn.com/kf/H38de8263ae5847cb9e6662cdee53743cA/240062176/H38de8263ae5847cb9e6662cdee53743cA.jpg",
"https://sc04.alicdn.com/kf/H1ea2aa793f5c4d009923d18a473ac219k/240062176/H1ea2aa793f5c4d009923d18a473ac219k.png",
"https://sc04.alicdn.com/kf/H7fec7cd6293c48168fdd1d41c48ab9e0O/240062176/H7fec7cd6293c48168fdd1d41c48ab9e0O.jpg",
"https://sc04.alicdn.com/kf/He8d4b88d4323492689455acfa3e44564g/240062176/He8d4b88d4323492689455acfa3e44564g.jpg",
"https://sc04.alicdn.com/kf/Hff4f46cf682d4deea2094bb71ecc446fu/240062176/Hff4f46cf682d4deea2094bb71ecc446fu.jpg",
"https://sc04.alicdn.com/kf/Hc5b49b124f1c491aa2fb3078a921929db/240062176/Hc5b49b124f1c491aa2fb3078a921929db.png"
]
query_type = "text"
candidate_type = "image"
res = similarity(query, candidates, query_type, candidate_type)
print(res)cd /workspace/Codes && python test_multimodal_embedding.py
运行上述脚本后,会生成图文的 embedding 向量,并可能输出一些可视化结果或日志信息。以下是运行脚本后生成的示例输出结果:
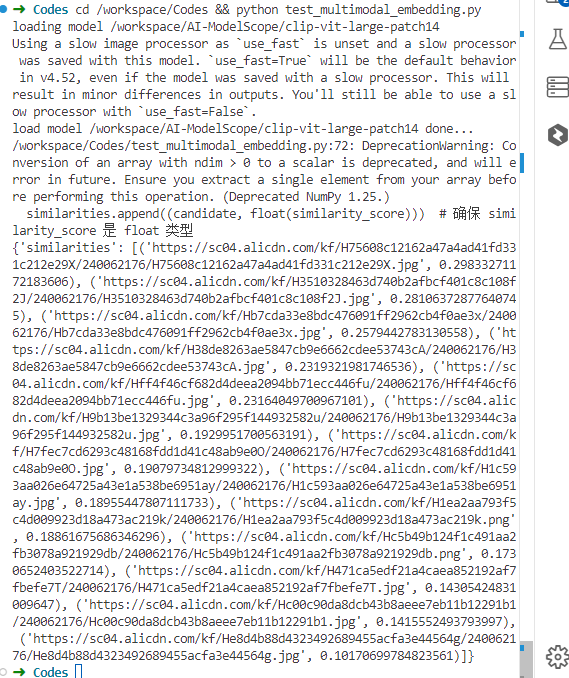
实验任务:
- 测试文本与图像的跨模态匹配
- 分析不同类型图像的向量特征
- 观察文本描述与图像内容的匹配程度
技术原理: CLIP模型通过对比学习,将文本和图像映射到同一向量空间,使得语义相关的图文向量距离更近,从而实现跨模态检索。
第三阶段:向量存储与检索
在Codes目录下 ,使用以下命令用于运行脚本 embedding.py,该脚本的作用是生成文本向量和图文向量的组合。
1. FAISS向量存储实践
cd /workspace/Codes && python embedding.py
处理结果: 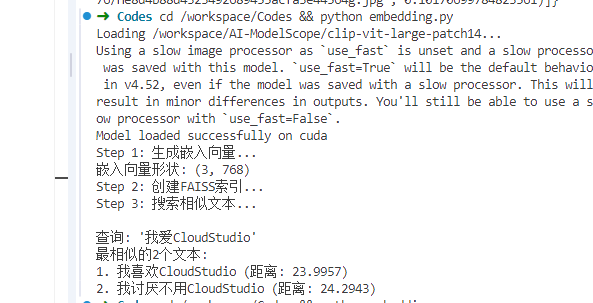
实验步骤:
- 理解向量索引的创建过程
- 观察不同索引类型(Flat、IVF等)的性能差异
- 测试不同检索参数对结果的影响
关键概念解析:
- 索引类型 :
- Flat:精确检索,适合小规模数据
- IVF:倒排文件索引,适合大规模数据的近似检索
- HNSW:基于图的索引,平衡检索速度与精度
2. 多测试
修改embedding.py中的以下参数进行对比实验:
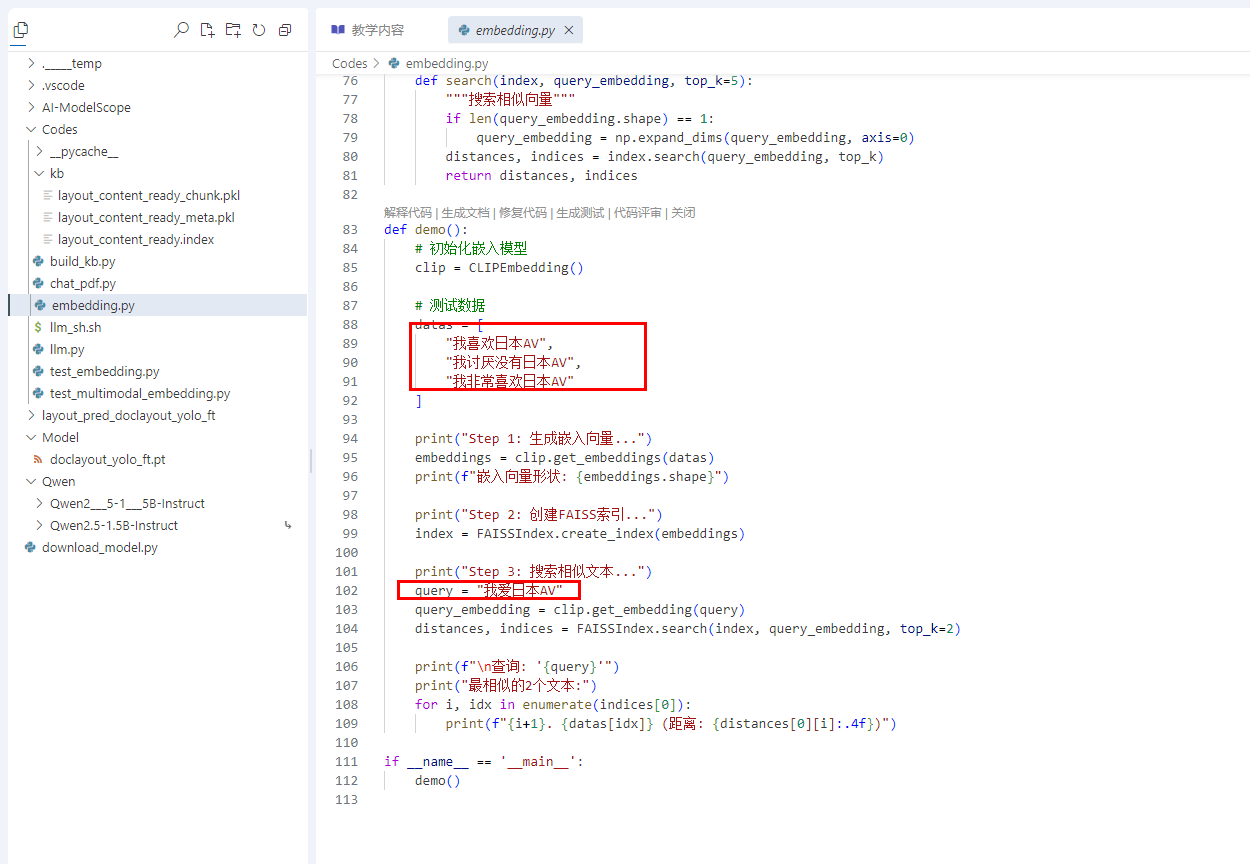
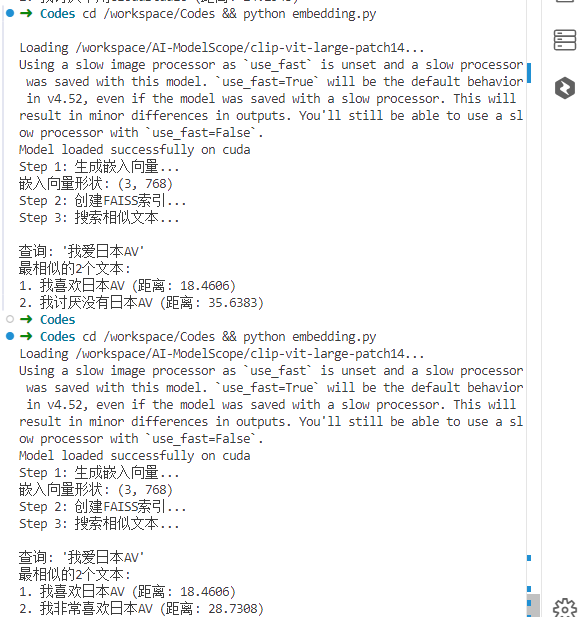
第四阶段:RAG系统搭建
1. 知识库构建
在Codes目录下 ,使用以下命令用于运行脚本 build_kb.py 构建kb
# coding=utf-8
import os
import json
import pickle
import numpy as np
import torch
from embedding import CLIPEmbedding, FAISSIndex # 使用新的类接口
class KnowledgeBaseBuilder:
def __init__(self, json_file, kb_dir="kb"):
self.json_file = json_file
self.kb_dir = kb_dir
self.embedder = CLIPEmbedding()
os.makedirs(self.kb_dir, exist_ok=True)
@staticmethod
def save_dict(data_dict, file_name):
"""保存字典到pickle文件"""
with open(file_name, 'wb') as f:
pickle.dump(data_dict, f)
def process_blocks(self, pdf_json):
"""处理所有文本块并生成嵌入"""
meta_dict = {}
chunk_dict = {}
embeddings = []
chunk_id = 0
for page_idx, page in enumerate(pdf_json):
print(f"Processing page {page_idx + 1}/{len(pdf_json)}...")
blocks = page["data"]
for block_idx, block in enumerate(blocks):
chunk = block.get("content", "").strip()
label = block.get("label", "").lower()
# 跳过空内容和特定标签
if not chunk or label == "abandon":
continue
try:
torch.cuda.empty_cache() # 清理GPU内存
# 获取嵌入向量
embedding = self.embedder.get_embedding(chunk)
if embedding is None:
print(f"Warning: Empty embedding for chunk {chunk_id}")
continue
# 存储数据
meta_key = f"page_{page_idx}_block_{block_idx}_{label}"
meta_dict[chunk] = meta_key
chunk_dict[chunk_id] = {
"text": chunk,
"meta": meta_key,
"label": label
}
embeddings.append(embedding)
chunk_id += 1
except Exception as e:
print(f"Error processing block {block_idx}: {str(e)}")
continue
return chunk_dict, meta_dict, embeddings
def build_knowledge_base(self):
"""构建知识库主函数"""
# 读取JSON文件
try:
with open(self.json_file, 'r', encoding='utf-8') as f:
pdf_json = json.load(f)
except Exception as e:
raise RuntimeError(f"Failed to load JSON file: {str(e)}")
# 处理文本块
print("Step 1: Processing text blocks and generating embeddings...")
chunk_dict, meta_dict, embeddings = self.process_blocks(pdf_json)
if not embeddings:
raise ValueError("No valid embeddings generated")
# 准备保存路径
base_name = os.path.splitext(os.path.basename(self.json_file))[0]
faiss_index_path = os.path.join(self.kb_dir, f"{base_name}.index")
chunk_id_path = os.path.join(self.kb_dir, f"{base_name}_chunk.pkl")
meta_path = os.path.join(self.kb_dir, f"{base_name}_meta.pkl")
# 构建FAISS索引
print("Step 2: Building FAISS index...")
try:
embeddings_array = np.stack(embeddings) # 比concatenate更安全的堆叠方式
print(f"Embeddings shape: {embeddings_array.shape}")
faiss_index = FAISSIndex.create_index(embeddings_array)
# 保存所有文件
print("Step 3: Saving knowledge base files...")
self.save_dict(chunk_dict, chunk_id_path)
self.save_dict(meta_dict, meta_path)
FAISSIndex.save_index(faiss_index, faiss_index_path)
print(f"Knowledge base built successfully at: {self.kb_dir}")
return True
except Exception as e:
print(f"Error building index: {str(e)}")
raise
def main():
import argparse
parser = argparse.ArgumentParser(description='Build knowledge base from JSON layout file')
parser.add_argument('--json', default="/workspace/layout_pred_doclayout_yolo_ft/layout_content_ready.json",
help='Path to input JSON file')
parser.add_argument('--kb_dir', default="kb", help='Output directory for knowledge base')
args = parser.parse_args()
try:
builder = KnowledgeBaseBuilder(args.json, args.kb_dir)
builder.build_knowledge_base()
except Exception as e:
print(f"Failed to build knowledge base: {str(e)}")
return 1
return 0
if __name__ == "__main__":
main()cd /workspace/Codes && python build_kb.py
处理结果: 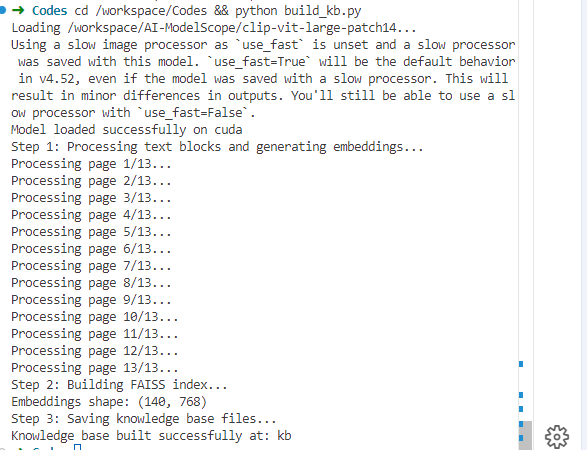
实验任务:
- 上传不同类型的PDF文档(文本密集型、图表型等)
- 观察文档分割策略对后续检索的影响
- 分析知识库构建的时间复杂度
优化建议:
- 文档分割策略:根据内容逻辑分段,而非固定长度
- 特殊内容处理:提取表格、公式等结构化信息
- 元数据管理:为向量添加文档来源、页码等元数据
2. 大模型部署与测试
在Codes目录下,启动Vllm
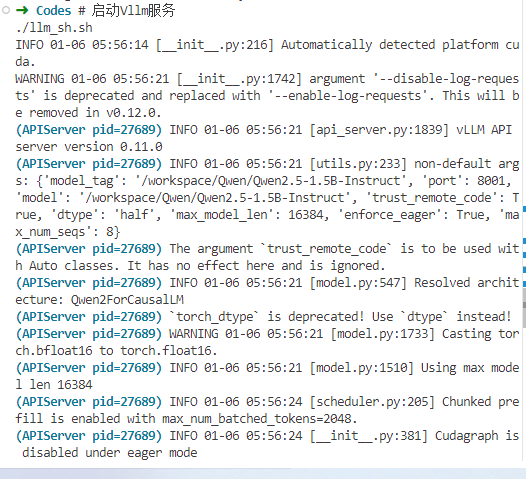
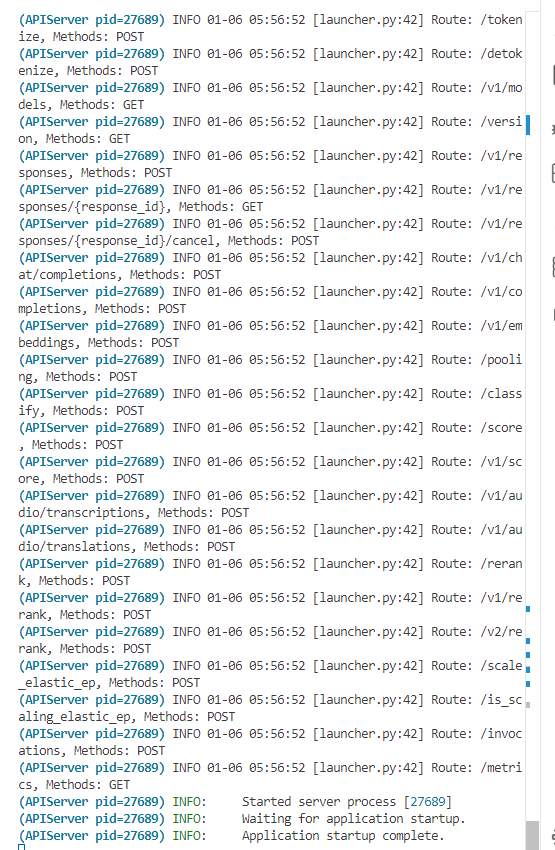
# 启动Vllm服务 ./llm_sh.sh
启动成功如下图所示:
服务验证:
- 检查服务启动日志,确认无错误信息
- 验证端口监听状态
- 测试基础对话功能
3. 问答系统实现与测试
新建一个终端,进行问答。
# 在新终端中运行 cd /workspace/Codes && python chat_pdf.py
测试结果:
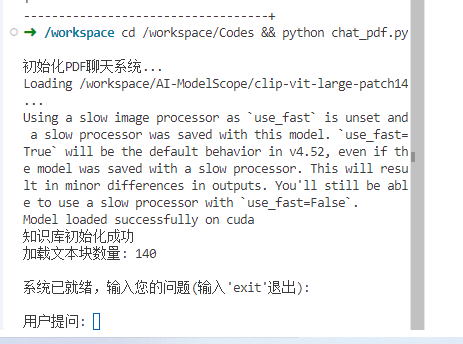
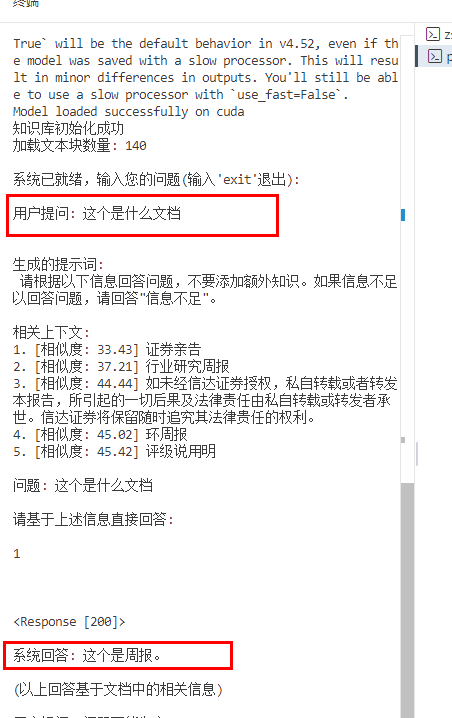

示例问题回答的正确
其它问题回答堪忧。。。

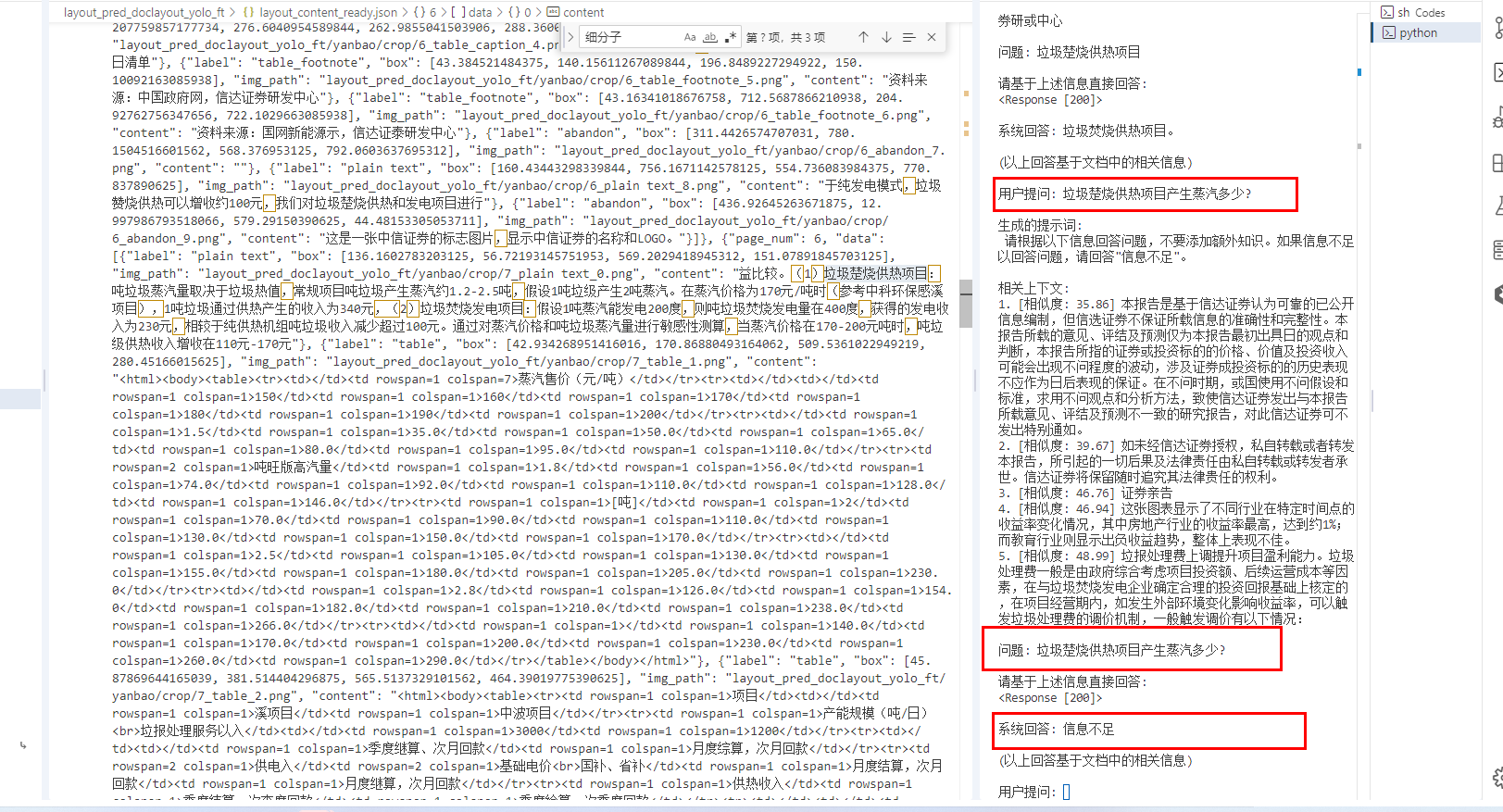
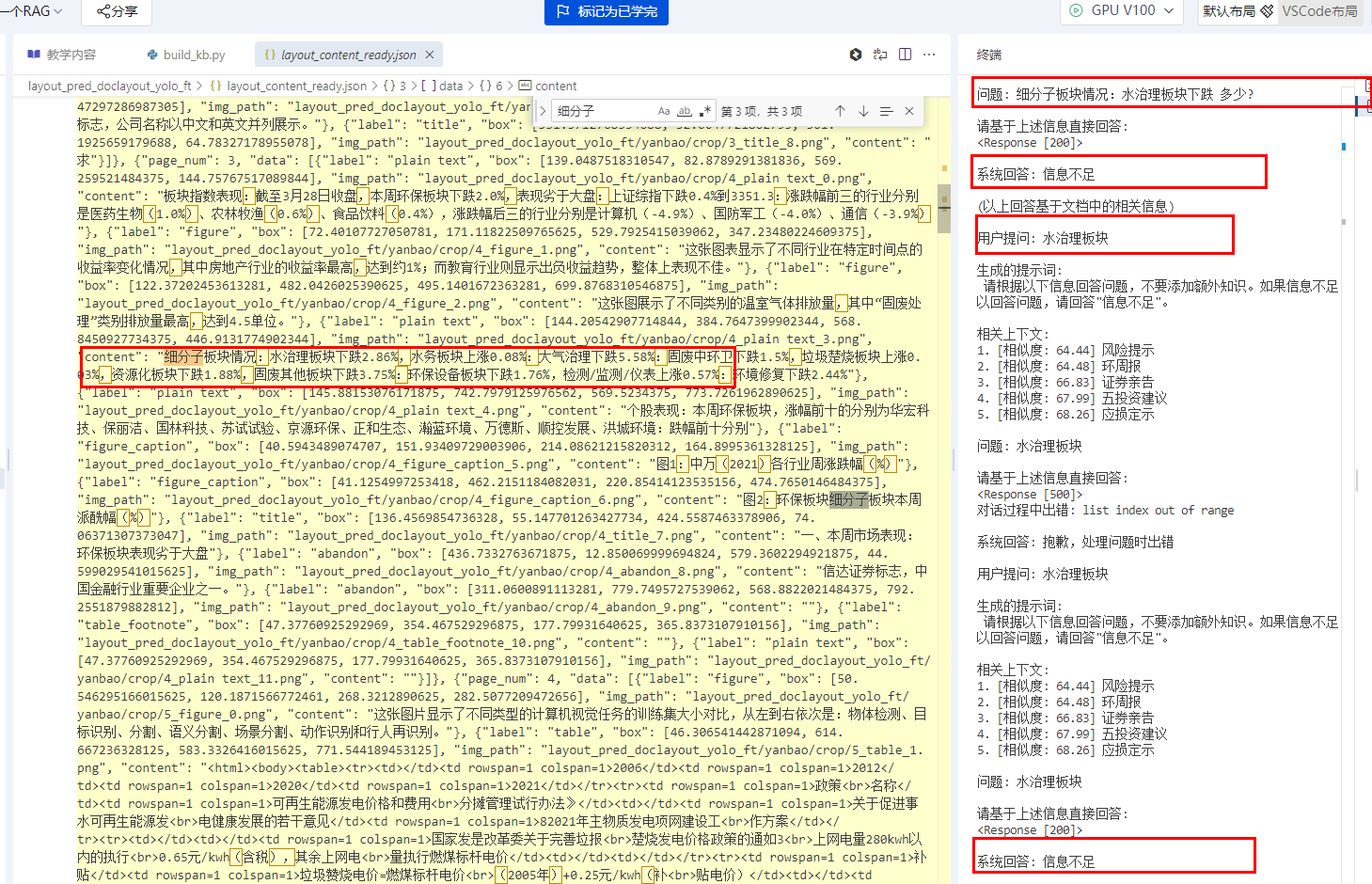
资料来源是
图片中来,清洗后形成一个json

所以资料的清洗,切割还需要优化!
实验任务:
-
设计不同类型的问题进行测试:
- 事实性问题(验证信息检索准确性)
- 推理型问题(验证逻辑处理能力)
- 复杂问题(验证多文档信息整合能力)
-
评估系统性能:
- 回答准确率(与文档内容比对)
- 响应时间(从提问到回答的耗时)
- 相关性(回答与问题的关联程度)
五、实验评估与考核
1. 过程性评估(60%)
- 实验环境搭建完成度(10%)
- 各阶段实验任务完成质量(30%)
- 问题解决能力(20%):记录实验中遇到的问题及解决方案
2. 成果性评估(40%)
提交以下实验成果:
- 实验报告:包含实验过程、参数设置、结果分析
- 系统演示:能展示RAG系统的核心功能
- 优化方案:针对实验中发现的问题,提出至少2项改进方案
3. 评分标准
| 评估维度 | 优秀(90-100) | 良好(80-89) | 及格(60-79) | 不及格(<60) |
|---|---|---|---|---|
| 系统完整性 | 功能完整,运行稳定 | 核心功能完整 | 基本功能可用 | 无法正常运行 |
| 检索准确性 | 相关结果占比>90% | 相关结果占比>70% | 相关结果占比>50% | 相关结果占比<50% |
| 回答质量 | 准确、全面、逻辑清晰 | 基本准确、较完整 | 部分准确、有遗漏 | 错误较多 |
| 创新性 | 有独特优化方案 | 应用了常见优化方法 | 无优化但功能正常 | 未完成基本功能 |
六、常见问题与解决方案
1. 环境配置问题
- GPU模式切换失败:检查显卡驱动是否正常,确认CUDA版本兼容性
- 依赖安装错误 :使用
pip install --upgrade pip更新pip,或手动安装指定版本依赖 - 模型下载缓慢:配置国内镜像源,或使用离线模型包
2. 运行时错误
- 内存溢出:减少批量处理大小,或使用更小的模型
- 服务启动失败:检查端口是否被占用,释放端口后重试
- 中文显示问题:安装中文字体库,配置matplotlib字体
3. 性能优化建议
- 对低频访问的知识库使用量化压缩向量
- 实现增量更新机制,避免每次重建知识库
- 对热门问题实现缓存机制,减少重复计算
七、扩展学习资源
推荐阅读
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(RAG原始论文)
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks(句子向量生成基础)
- FAISS: A Library for Efficient Similarity Search(向量检索引擎原理)
进阶实践方向
- 多模态RAG系统:支持图像、音频等多种数据类型
- 个性化RAG:根据用户历史调整检索策略
- 分布式RAG:处理超大规模知识库
- RAG评估体系:构建自动评估指标
相关工具与框架
- LangChain:RAG应用开发框架
- LlamaIndex:专注于索引优化的RAG框架
- Weaviate:开源向量数据库
- Qdrant:高性能向量搜索引擎
八、实验报告模板
实验报告基本结构
-
实验目的与环境
- 实验目标回顾
- 软硬件环境配置
- 遇到的环境问题及解决方案
-
实验过程记录
- 各阶段实验步骤
- 关键参数设置
- 实验现象描述
-
结果分析与讨论
- 实验数据整理(表格/图表)
- 结果对比分析
- 异常现象解释
-
总结与展望
- 实验收获
- 系统改进建议
- 后续学习计划
通过本实验课程的优化,学习者将获得更系统的RAG技术实践体验,不仅掌握基本操作,更能理解各组件间的关联与优化空间,为实际应用开发奠定基础。实验设计注重理论与实践结合,通过问题引导和自主探索,培养解决复杂AI系统问题的能力。