
反射内存-【硬核】拒绝轮询!C++ 利用中断 + DMA 榨干反射内存卡的极限性能
文章目录
- [反射内存-【硬核】拒绝轮询!C++ 利用中断 + DMA 榨干反射内存卡的极限性能](#反射内存-【硬核】拒绝轮询!C++ 利用中断 + DMA 榨干反射内存卡的极限性能)
-
- [前言:别让 `while(true)` 毁了你的 CPU](#前言:别让
while(true)毁了你的 CPU) - 第一部分:为什么要用中断?
-
- [1.1 轮询 vs 中断 架构图](#1.1 轮询 vs 中断 架构图)
- [第二部分:实战 ------ 网络中断编程指南](#第二部分:实战 —— 网络中断编程指南)
-
- [2.1 核心 API](#2.1 核心 API)
- [2.2 接收端代码 (Receiver_Interrupt.cpp)](#2.2 接收端代码 (Receiver_Interrupt.cpp))
- [2.3 发送端代码 (Sender_Interrupt.cpp)](#2.3 发送端代码 (Sender_Interrupt.cpp))
- [第三部分:DMA ------ 数据搬运的终极奥义](#第三部分:DMA —— 数据搬运的终极奥义)
-
- [3.1 什么是 DMA?](#3.1 什么是 DMA?)
- [3.2 独立 DMA 通道的配置技巧](#3.2 独立 DMA 通道的配置技巧)
-
- [DMA 传输流程图](#DMA 传输流程图)
- [3.3 DMA 编程代码示例](#3.3 DMA 编程代码示例)
- [第四部分:避坑指南 ------ 中断与 DMA 的副作用](#第四部分:避坑指南 —— 中断与 DMA 的副作用)
-
- [4.1 中断风暴 (Interrupt Storm)](#4.1 中断风暴 (Interrupt Storm))
- [4.2 缓存一致性 (Cache Coherency)](#4.2 缓存一致性 (Cache Coherency))
- [4.3 实时性 vs 吞吐量](#4.3 实时性 vs 吞吐量)
- 结语:性能是调出来的,不是写出来的
- [前言:别让 `while(true)` 毁了你的 CPU](#前言:别让
从"傻傻死循环"到"毫秒级精准触发",这才是实时系统的正确打开方式。
关键字: 反射内存、实时网、低延迟、5565、C++高性能编程 、RFM2gDMA配置、中断延迟优化
前言:别让 while(true) 毁了你的 CPU
兄弟们,上一篇我们聊了基础的读写(Polling 轮询模式)。 很多小伙伴私信我说:"大佬,我的 Reader 程序跑起来,CPU 单核占用率直接飙到 100%,风扇呼呼转,老板以为我在挖矿。"
这就是轮询的代价。你为了那微秒级的延迟,让 CPU 像个强迫症一样,每秒钟去问内存几百万次:"有数据吗?有数据吗?" 这在简单 demo 里没问题,但在复杂的实时系统(RTOS)里,这就是灾难。你的 GUI 会卡死,你的其他线程会饿死。
今天,我们进阶一下。我们要用硬件最原始、最性感的功能 ------ 中断(Interrupts) 和 DMA,把 CPU 从苦力活中解放出来。
第一部分:为什么要用中断?
我们先看一张架构对比图,你就明白差距在哪里了。
1.1 轮询 vs 中断 架构图
模式二:中断 Interrupt
唤醒
收到信号
开始
CPU: 挂起/睡觉
硬件中断信号
唤醒线程
精准读取
处理业务
模式一:轮询 Polling
无
有
开始
CPU: 有数据吗?
读取数据
处理业务
- 左边(轮询):像是你在等快递,每隔 1 秒开一次门看看快递员来没来。累死人。
- 右边(中断):像是快递员到了直接按门铃。你平时该干嘛干嘛,门铃响了再去拿。
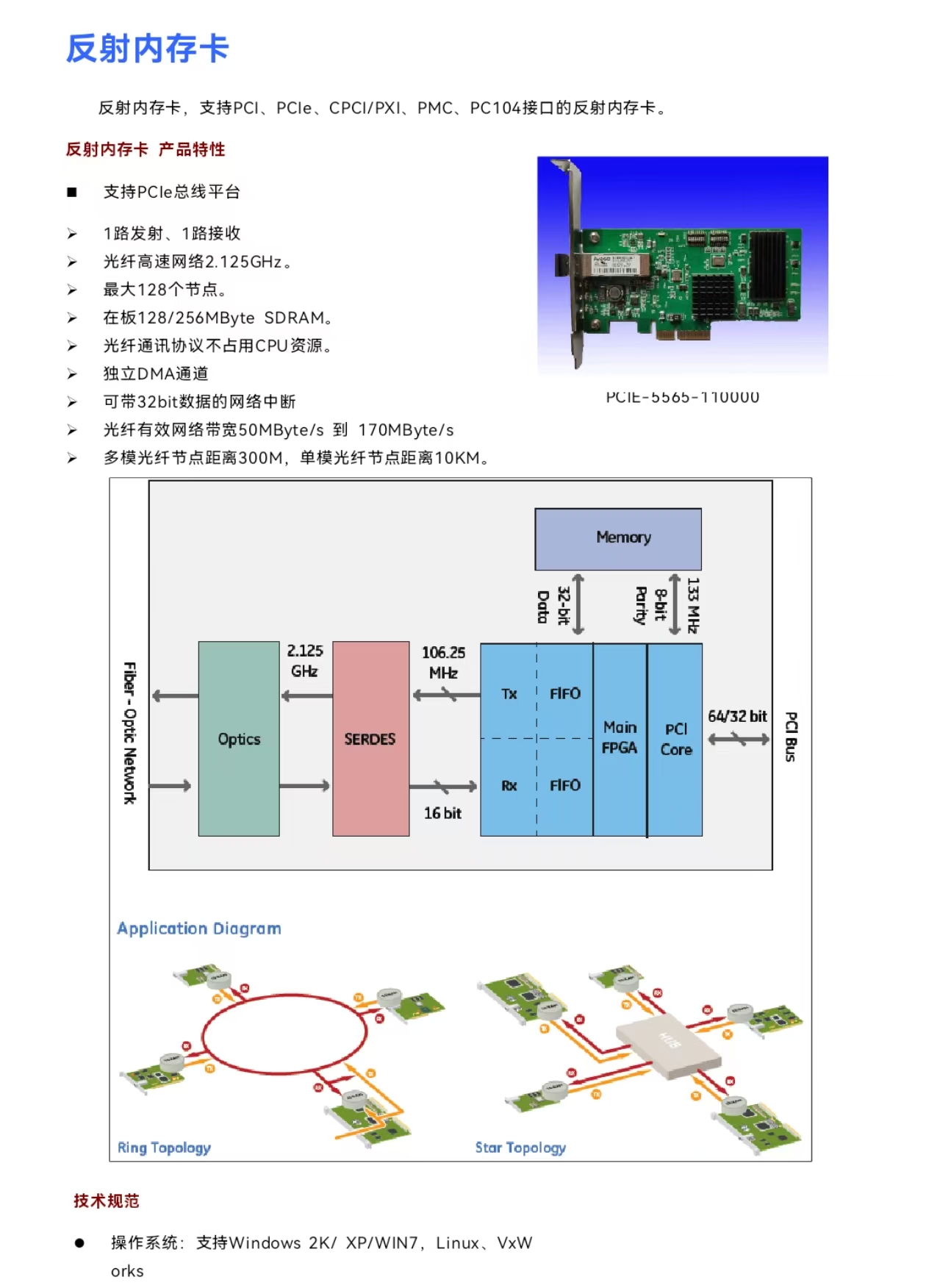
对于反射内存卡(如 GE 5565),网络中断(Network Interrupt) 是指:当 A 机往特定的内存地址写入数据时,B 机的卡会自动检测到这一写操作,并给 B 机的 CPU 发送一个物理中断信号。
第二部分:实战 ------ 网络中断编程指南
场景 :A 机写入数据后,B 机立马收到通知并读取。 难点:中断不是你想发就能发的,需要在协议层约定好。
2.1 核心 API
rfm2gEnableEvent(): 在接收端(B机)开启中断监听。rfm2gWaitForEvent(): 让线程进入睡眠状态,等待中断到来。rfm2gSendEvent(): 在发送端(A机)触发中断(部分型号支持直接写特定寄存器触发,也可以写特定内存地址触发)。
2.2 接收端代码 (Receiver_Interrupt.cpp)
这是整个架构的被动方,它负责"等待门铃响"。
C++
/**
* Receiver_Interrupt.cpp - 优雅的等待者
* 这是一个阻塞式程序,几乎不占 CPU,但响应速度极快。
*/
#include <iostream>
#include <windows.h>
#include "rfm2g_api.h"
using namespace std;
int main() {
RFM2G_HANDLE handle;
RFM2G_STATUS result;
// 1. 打开设备
if (rfm2gOpen("\\\\.\\rfm2g0", &handle) != RFM2G_SUCCESS) {
cerr << "板卡打开失败!" << endl;
return -1;
}
// 2. 配置中断
// 我们监听 "RFM2G_EVENT_INTR1",这是板卡上的 1 号中断线
// 意思就是:如果有人触发了网络中断1,请叫醒我。
result = rfm2gEnableEvent(handle, RFM2G_EVENT_INTR1);
if (result != RFM2G_SUCCESS) {
cerr << "中断开启失败,驱动可能未配置好!" << endl;
return -1;
}
cout << ">>> 接收端已就绪,CPU 进入休眠,等待中断信号..." << endl;
while (true) {
// 3. 核心代码:死等
// 参数 2 是超时时间(毫秒),INFINITE 表示一直等,直到海枯石烂
// 这一行执行时,操作系统会挂起当前线程,CPU 占用率直接归零。
result = rfm2gWaitForEvent(handle, RFM2G_EVENT_INTR1, INFINITE);
if (result == RFM2G_SUCCESS) {
// 4. 门铃响了!
cout << "[IRQ] 收到中断信号!开始处理数据..." << endl;
// 这里执行你的读取逻辑 (rfm2gRead 或直接读指针)
// ProcessData();
cout << "[Done] 处理完毕,继续睡觉。" << endl;
} else {
cerr << "等待超时或出错" << endl;
}
}
rfm2gClose(handle);
return 0;
}2.3 发送端代码 (Sender_Interrupt.cpp)
发送端不仅要写数据,还要负责"按门铃"。
C++
/**
* Sender_Interrupt.cpp - 暴躁的按铃人
*/
#include <iostream>
#include <windows.h>
#include "rfm2g_api.h"
using namespace std;
int main() {
RFM2G_HANDLE handle;
rfm2gOpen("\\\\.\\rfm2g0", &handle);
cout << ">>> 按 Enter 键发送一次中断..." << endl;
while (true) {
getchar(); // 等待用户按回车
// 1. 先写数据 (假设你要传的一大坨数据)
// WriteMyData();
// 2. 发送中断信号
// 这会让连接在光纤网上的所有开启了 INTR1 监听的板卡产生中断
// 最后一个参数 0 是保留位,填 0 即可
RFM2G_STATUS result = rfm2gSendEvent(handle, RFM2G_EVENT_INTR1, 0);
if (result == RFM2G_SUCCESS) {
cout << "[Tx] 数据已写,中断已发!" << endl;
} else {
cout << "[Error] 发送失败" << endl;
}
}
rfm2gClose(handle);
return 0;
}第三部分:DMA ------ 数据搬运的终极奥义
如果你只是发几个 int 或 float,用上面的代码就够了。 但如果你要传输 4K 高清视频流 或者 雷达原始点云数据 (几兆甚至几十兆),光靠 CPU 去 memcpy 拷贝内存,CPU 又要报警了。
这时候,DMA(Direct Memory Access,直接存储器访问) 必须登场。
3.1 什么是 DMA?
简单说,就是板卡上有一个专门的"搬运工芯片"。 CPU 对搬运工说:"把这块内存里的 10MB 数据,搬到那块内存去,搬完叫我。" 然后 CPU 就可以去算别的算法了。搬运工(DMA 控制器)会在后台默默干活,不占用 CPU 周期。
3.2 独立 DMA 通道的配置技巧
在 5565 卡上,通常有两个 DMA 通道(Channel 0 和 Channel 1)。我们可以利用它们实现全双工操作:通道 0 专门负责发,通道 1 专门负责收。
DMA 传输流程图
搬运完成
通知
开始传输
- 配置 DMA 参数\n源地址/目的地址/长度 2. 启动 DMA 引擎 CPU 去做别的事\n不被占用
DMA 硬件\n后台搬运数据
触发完成中断 - 执行回调函数 结束
3.3 DMA 编程代码示例
DMA 的代码稍微复杂一点,需要处理"本地内存"和"PCI 地址"的转换。
C++
// DMA 发送示例
void DmaTransfer(RFM2G_HANDLE handle, void* localBuffer, uint32_t rfmOffset, uint32_t length) {
RFM2G_STATUS result;
// 1. 准备 DMA 参数结构体
RFM2G_DMA_PARAM dmaParam;
memset(&dmaParam, 0, sizeof(dmaParam));
// 2. 关键配置
dmaParam.Channel = RFM2G_DMA_CHANNEL_0; // 使用通道 0
dmaParam.Direction = RFM2G_DMA_MM_TO_RFM; // 从主存(MM)搬到板卡(RFM)
dmaParam.LocalAddr = (RFM2G_UINT64)localBuffer; // 本地数据的指针
dmaParam.RfmAddr = rfmOffset; // 板卡里的偏移地址
dmaParam.Length = length; // 搬运长度
dmaParam.EnableInt = 1; // 搬完后触发一个中断通知我
cout << ">>> DMA 引擎启动..." << endl;
// 3. 启动传输
// rfm2gTransfer 是一个同步函数(如果没开异步模式),它会等待 DMA 完成
// 但在这个等待过程中,CPU 也是低功耗状态,而不是在那空转
result = rfm2gTransfer(handle, &dmaParam);
if (result == RFM2G_SUCCESS) {
cout << ">>> DMA 搬运完成!" << endl;
} else {
cout << ">>> DMA 失败,错误码:" << result << endl;
}
}第四部分:避坑指南 ------ 中断与 DMA 的副作用
技术没有银弹,用了中断和 DMA 也有代价,这里全是血泪教训。
4.1 中断风暴 (Interrupt Storm)
坑 :如果你的发送端发疯了,每微秒发一次中断(比如写在死循环里忘了加延时)。 后果 :接收端的操作系统会因为频繁响应中断,导致上下文切换过于频繁,直接卡死甚至蓝屏。 解法 :在协议层做速率限制。或者在驱动层设置"中断合并"(Interrupt Coalescing),比如攒够 10 个包再发一次中断。
4.2 缓存一致性 (Cache Coherency)
坑 :DMA 搬完数据了,但 CPU 看到的还是旧数据。 原因 :CPU 也是有缓存(L1/L2/L3)的。DMA 是直接改写物理内存,没有经过 CPU。如果 CPU 不知道内存变了,它还会去读自己的缓存。 解法:
- 对于写操作 :在启动 DMA 之前,做一次
FlushCache。 - 对于读操作:在 DMA 完成后,做一次
InvalidateCache.- 注:好消息是,rfm2g 的驱动通常会自动处理这个,但在嵌入式 Linux 环境下开发驱动时要格外小心。
4.3 实时性 vs 吞吐量
- 小数据(< 1KB) :不要用 DMA! 配置 DMA 寄存器本身也是要时间的。几百个字节的数据,CPU 还没配置好 DMA,直接
memcpy早就拷完了。 - 大数据(> 4KB):DMA 才是王者。
- 极低延迟 :不要用中断! 中断响应(ISR Latency)在 Windows 下通常是 10-50 微秒。如果你要求 5 微秒的响应,乖乖回去用轮询(Polling) + CPU 独占核心。
结语:性能是调出来的,不是写出来的
其实所谓的"高级开发",无非就是对计算机底层机制的压榨。 什么时候用轮询?什么时候用中断?什么时候上 DMA?这没有标准答案,全看你的业务场景。
- 如果是飞控闭环 (1kHz 频率,数据量小),我推荐 轮询 + 核心绑定。
- 如果是图像传输 (30Hz 频率,数据量大),我推荐 中断 + DMA。
希望这篇博文能帮你打开思路。别再让你的程序傻傻地跑死循环了,给 CPU 放个假吧!
如果你觉得这篇干货对你有帮助,点赞、收藏、关注三连走一波!有问题的在评论区尽管问,知无不言!
如果你对反射内存卡驱动开发、多机同步架构设计 感兴趣,或者在项目中遇到了实时性不足的坑,欢迎在评论区留言或者私信交流。
