
反射内存-【LabVIEW实战】当 PXI 遇上反射内存:图形化编程如何驾驭 2.125Gbps 实时通讯?
文章目录
- [反射内存-【LabVIEW实战】当 PXI 遇上反射内存:图形化编程如何驾驭 2.125Gbps 实时通讯?](#反射内存-【LabVIEW实战】当 PXI 遇上反射内存:图形化编程如何驾驭 2.125Gbps 实时通讯?)
-
- [前言:LabVIEW 工程师的"速度与激情"](#前言:LabVIEW 工程师的“速度与激情”)
- [第一部分:为什么 LabVIEW 需要反射内存?](#第一部分:为什么 LabVIEW 需要反射内存?)
-
- [1.1 协议对比:TCP vs RFM](#1.1 协议对比:TCP vs RFM)
- [第二部分:LabVIEW 驱动封装 ------ 告别"调用库节点"的噩梦](#第二部分:LabVIEW 驱动封装 —— 告别“调用库节点”的噩梦)
-
- [2.1 驱动层级架构设计](#2.1 驱动层级架构设计)
- [2.2 实战:如何封装 Write VI](#2.2 实战:如何封装 Write VI)
- [第三部分:核心技术 ------ 在 LabVIEW 中实现 DMA](#第三部分:核心技术 —— 在 LabVIEW 中实现 DMA)
-
- [3.1 内存锁定 (Memory Locking)](#3.1 内存锁定 (Memory Locking))
- [3.2 LabVIEW 侧的 DMA 流程](#3.2 LabVIEW 侧的 DMA 流程)
- [第四部分:高级应用 ------ 中断与事件结构 (User Events)](#第四部分:高级应用 —— 中断与事件结构 (User Events))
-
- [4.1 架构原理:C 回调 -> LabVIEW 用户事件](#4.1 架构原理:C 回调 -> LabVIEW 用户事件)
- [4.2 LabVIEW 实现步骤](#4.2 LabVIEW 实现步骤)
- [第五部分:NI PXI 系统集成的避坑指南](#第五部分:NI PXI 系统集成的避坑指南)
-
- [5.1 RT (Real-Time) 系统下的坑](#5.1 RT (Real-Time) 系统下的坑)
- [5.2 大端小端 (Endianness)](#5.2 大端小端 (Endianness))
- [5.3 64位系统的兼容性](#5.3 64位系统的兼容性)
- [第六部分:实战案例 ------ 飞机姿态仿真系统](#第六部分:实战案例 —— 飞机姿态仿真系统)
- [结语:让 LabVIEW 飞起来](#结语:让 LabVIEW 飞起来)
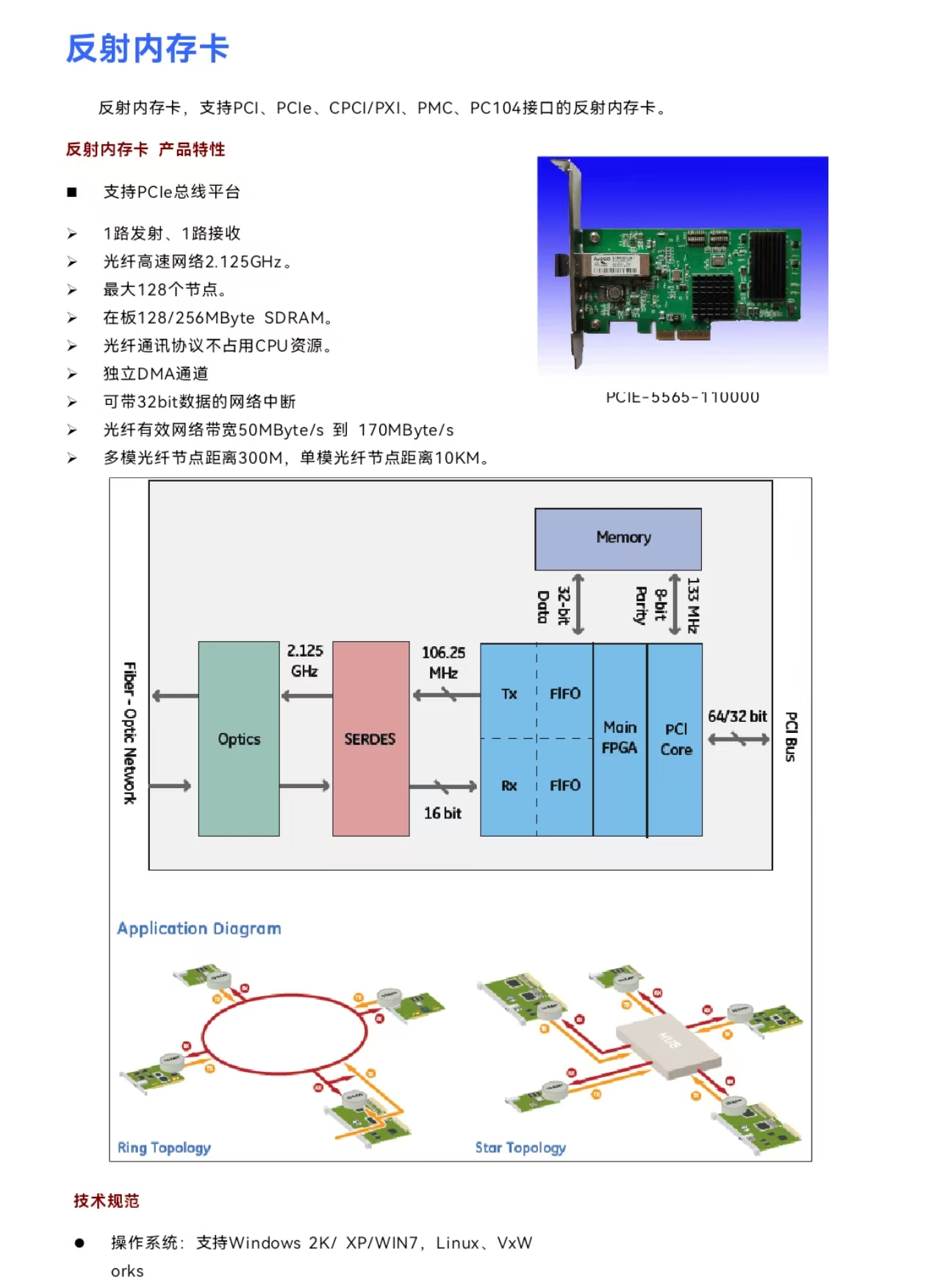
从"卡顿掉帧"到"确定性传输"------为 NI 自动化测试系统装上"光纤神经"。
关键字: 反射内存、实时网、低延迟、5565、HIL硬件在环测试 、自动化测试架构、HIL硬件在环测试
前言:LabVIEW 工程师的"速度与激情"
各位 NI 的忠实粉丝,PXI 系统的玩家们,大家在这个行业里摸爬滚打,肯定遇到过这样的场景:
你的 PXI 机箱里插满了 AD 采集卡,数据像洪水一样涌进来。你需要把这些数据实时传给旁边的仿真机、或者另一台处理数据的上位机。 这时候你发现,以前引以为傲的 TCP/IP 居然卡了! 延迟不可控,数据包抖动,CPU 占用率飙升...
这时候,老板问你:"能不能搞个更快的?" 你心里想:"光纤?" 对,就是光纤!就是反射内存(Reflective Memory)。
今天,我们就来聊聊如何在 LabVIEW 这个"连线游戏"里,驯服 GE 5565 这种工业级怪兽,实现微秒级的跨机箱数据同步。
第一部分:为什么 LabVIEW 需要反射内存?
在讲怎么做之前,先讲为什么。 很多 LabVIEW 新手会问:"Shared Variable(共享变量)不好用吗?Network Stream 不香吗?"
1.1 协议对比:TCP vs RFM
看一张架构对比图,你就知道为什么在 HIL(硬件在环)测试里,反射内存是刚需。
反射内存架构
1.直接内存写入
2.光速同步
3.瞬间到达
4.DMA/直接读取
LabVIEW APP A
5565 卡
光纤环网
5565 卡 B
LabVIEW APP B
传统以太网/TCP架构
1.打包
2.系统调用/拷贝
3.交换机转发
4.接收
5.拆包/校验
6.读取
LabVIEW APP A
OS TCP/IP 协议栈
网卡
交换机
网卡 B
OS TCP/IP 协议栈
LabVIEW APP B
- TCP/IP:经过了 OS -> 驱动 -> 协议栈 -> 网卡,中间任何一个环节繁忙(比如 Windows 在更新),你的数据就会延迟。
- 反射内存 :对于 CPU 来说,写光纤 = 写本地内存。没有协议栈,没有 CPU 负载,甚至不需要 CPU 参与(DMA)。
第二部分:LabVIEW 驱动封装 ------ 告别"调用库节点"的噩梦
GE 原厂提供的驱动通常是 C 语言的 DLL。直接在 LabVIEW 里用 Call Library Function Node (CLFN) 也是可以的,但那简直是噩梦:
- 指针满天飞:LabVIEW 处理 C 指针非常痛苦。
- 内存泄漏风险:忘记 Free 一个句柄,LabVIEW 就崩溃了。
- 调试困难:VI 连线乱成一团麻。
所以,我们需要构建一层面向对象的 LabVIEW 封装层 (LvClass/GOOP)。
2.1 驱动层级架构设计
建议大家在项目中采用这样的三层架构:
应用层
业务逻辑层 -Action Engine
硬件抽象层 -Wrapper VI
Open.vi
Write_DMA.vi
Read_DMA.vi
Wait_Interrupt.vi
rfm2g.dll / rfm2g_api.h
Functional Global Variable\n-FGV: RFM_Engine.vi
Main_HIL_Test.vi
Monitor_Panel.vi
2.2 实战:如何封装 Write VI
不要直接传数组指针!要利用 LabVIEW 的 "Adapt to Type" 功能。
步骤:
- 创建一个名为
RFM_Write.vi。 - 放置一个 Call Library Function Node。
- 配置 DLL 函数
rfm2gWrite。 - 关键点 :将数据输入参数配置为
Array Data Pointer,而不是Array Handle。这样 LabVIEW 会直接把数据的内存地址传给 DLL,避免了内部的二次拷贝,速度极快!
第三部分:核心技术 ------ 在 LabVIEW 中实现 DMA
LabVIEW 自身的内存管理机制很安全,但也导致它比较"封闭"。要实现 DMA(直接内存访问),我们需要一点"黑魔法"。
3.1 内存锁定 (Memory Locking)
DMA 需要物理地址连续且固定的内存。但 LabVIEW 的数据在内存里是可能会被操作系统搬来搬去的。 解决方案: 我们不能直接对 LabVIEW 的数组做 DMA。我们需要在 DLL 内部申请一块内存,然后把这块内存的指针传回给 LabVIEW(作为一个 U64 数值)。
3.2 LabVIEW 侧的 DMA 流程
- Init 阶段:调用 DLL,申请 10MB 的 DMA 缓冲区。
- Mapping :DLL 返回两个地址------
LocalPtr(给 CPU 用的)和PCIPtr(给板卡用的)。 - LabVIEW 读写:
- LabVIEW 使用
MoveBlock.vi(系统自带的隐藏 VI,用于内存拷贝) 将采集卡(如 DAQmx)获取的数组数据,高速memcpy到LocalPtr指向的区域。 - 调用
rfm2gTransfer启动 DMA 引擎,把数据发走。
- LabVIEW 使用
注意 :MoveBlock 极其高效,比 LabVIEW 原生的循环赋值快 10 倍以上。
第四部分:高级应用 ------ 中断与事件结构 (User Events)
这是本文最精华的部分。 如何让 LabVIEW 不轮询也能收到数据?
传统的 LabVIEW 写法是放一个 While Loop,里面延时 1ms 不断查寄存器。这太 Low 了。我们要用 LabVIEW 强大的 Event Structure(事件结构)。
4.1 架构原理:C 回调 -> LabVIEW 用户事件
我们需要编写一个小型的 C++ 中间层 DLL,作为桥梁。
LabVIEW事件结构 中间层DLL 反射内存卡 LabVIEW事件结构 中间层DLL 反射内存卡 1. 注册 LabVIEW User Event 引用给 DLL 5. 事件结构捕获事件 2. 触发硬件中断 (IRQ) 3. 中断回调函数执行 4. 调用 PostLVUserEvent
4.2 LabVIEW 实现步骤
- 创建用户事件 :在 LabVIEW 里使用
Create User Event,定义数据类型(比如一个 Cluster,包含 SenderID 和 Payload)。 - 注册回调 :调用你的中间层 DLL,把这个 Event 的
Refnum传进去。 - 等待事件 :在主程序的
While Loop里放置一个事件结构,添加User Event分支。 - 运行:当 A 机写入数据并发送中断时,B 机的 LabVIEW 事件结构会瞬间响应,就像你在界面上按了一个按钮一样灵敏!
这种方式可以将 LabVIEW 的 CPU 占用率控制在 1% 以下 ,同时实现 <50us 的响应延迟。
第五部分:NI PXI 系统集成的避坑指南
作为一名在现场被坑过无数次的工程师,这几条建议价值千金。
5.1 RT (Real-Time) 系统下的坑
如果你的 PXI 跑的是 Pharlap ETS 或者 NI Linux RT 系统:
- 驱动签名:NI Linux RT 要求内核模块(ko文件)必须匹配。你不能直接用厂家给的 Desktop Linux 驱动,必须在 NI 提供的工具链下重新编译。
- DLL vs SO :代码里调用库节点时,记得用条件编译结构。Windows 下调
.dll,Linux RT 下调.so。 - VIPM 打包:把你封装好的驱动打成 VIPM 包,这样分发给同事时,依赖关系不会乱。
5.2 大端小端 (Endianness)
- 反射内存卡本身通常是不管大小端的,它只搬运字节。
- 但是!LabVIEW (尤其在 Windows 上) 是 Little Endian。
- 如果你通讯的对方是 VxWorks (PowerPC) 或者是某些老式 PLC ,它们可能是 Big Endian。
- 解决 :在 LabVIEW 写入前,使用
Swap Bytes原语进行转换。别小看这个,数据错乱全赖它。
5.3 64位系统的兼容性
现在 LabVIEW 64-bit 越来越普及。
- 注意 DLL 的位数必须和 LabVIEW 匹配。32位 LabVIEW 调不了 64位 DLL,反之亦然。
- 在配置 CLFN 节点时,指针类型一定要选
Pointer-sized Integer,不要选U32。否则在 64 位系统下,地址会被截断,直接报内存访问违规。
第六部分:实战案例 ------ 飞机姿态仿真系统
为了让大家更有代入感,我们看一个简化版的实际案例。
场景:
- 节点 A (PXIe-8880):运行飞行动力学模型,计算飞机姿态(Pitch, Roll, Yaw)。
- 节点 B (PXIe-8880):控制转台,模拟飞机运动。
- 要求:1kHz 闭环控制,延迟 < 1ms。
LabVIEW 代码逻辑 (节点 A):
- Timed Loop (1kHz):保证确定性定时。
- 模型计算:解算微分方程,得出当前角度。
- 写入 RFM :将
{Pitch, Roll, Yaw, FrameCount}打包成 Cluster,直接 Cast 成 U8 数组。 - DMA Write:一键推送到光纤。
LabVIEW 代码逻辑 (节点 B):
- RFM 中断响应:收到新数据中断。
- 读取 RFM:从内存读出 U8 数组。
- Unflatten from String:还原为 LabVIEW Cluster。
- DA 输出:控制板卡输出模拟量驱动电机。
结果 : 整个链路(A机计算 -> 光纤传输 -> B机输出)的总延迟稳定在 200us 左右,Jitter(抖动)小于 5us。这就是反射内存的威力。
结语:让 LabVIEW 飞起来
LabVIEW 不仅仅是用来画画界面的,它完全有能力承担最硬核的实时控制任务。 关键在于,你是否能打破"控件"的思维限制,去理解底层的内存、指针和中断。
反射内存卡是 PXI 系统的一双翅膀,一旦你掌握了如何通过 LabVIEW 驾驭它,你就能在自动化测试、半实物仿真领域俯视众生。
如果你在 PXI 集成反射内存时遇到过莫名其妙的 Error 1097,或者搞不定 Linux RT 的驱动编译,欢迎在评论区留言。技术无止境,我们一起探索!
如果你对反射内存卡驱动开发、多机同步架构设计 感兴趣,或者在项目中遇到了实时性不足的坑,欢迎在评论区留言或者私信交流。
