在数字化转型的深水区,企业面临的已非简单的文字扫描,而是海量报告、票据、合同中那些结构各异、格式不一的表格。传统OCR对此束手无策,数据录入的"最后一公里"仍依赖人工,成为效率瓶颈与错误源头。如今,融合了深度学习与版面分析的智能表格识别技术,正扮演着"关键解码器"的角色,它不仅能读字,更能解构表格本身,实现从图像到结构化数据的端到端智能转化。
技术挑战:表格识别的复杂性与难点
表格识别看似简单,实则面临诸多技术挑战。表格种类繁多,从规则的财务表格到不规则的科学实验记录,从清晰打印的文档到拍照变形的票据,其多样性和复杂性远超想象。技术难点主要体现在三个方面:
- 版面复杂性:表格可能包含合并单元格、嵌套表格、斜线表头等复杂结构;
- 环境干扰:如光照不均、图像倾斜、背景干扰、印章覆盖等问题;
- 语义理解:如何将识别出的文字与表格结构正确对应,恢复数据的逻辑关系,这是表格识别最核心的挑战。
什么是表格识别技术?
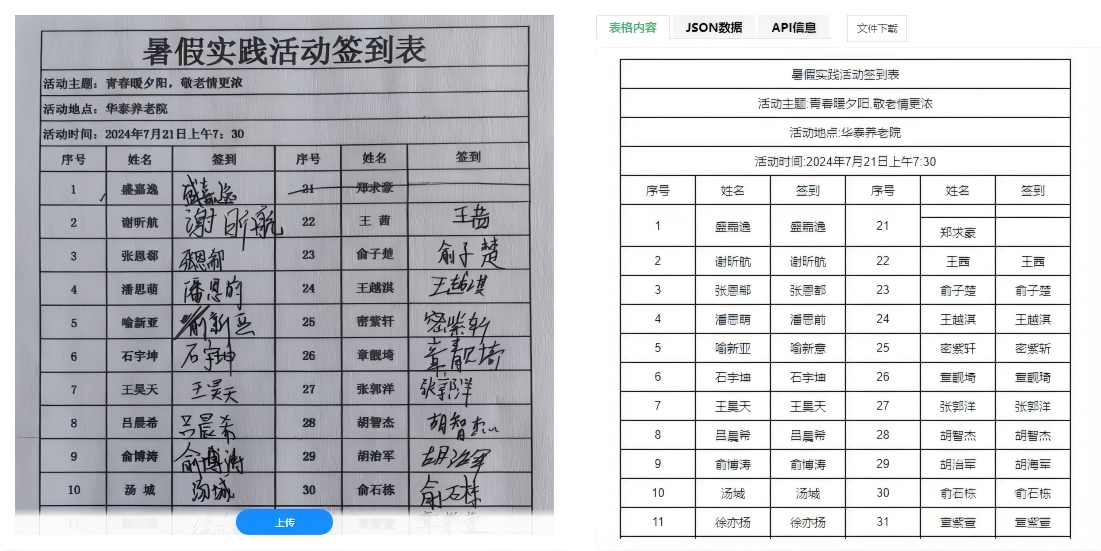
表格识别技术采用计算机视觉(CV)、光学字符识别(OCR)和深度学习等人工智能方法,从图像或PDF等非结构化格式中自动检测、分割并重建表格结构,并准确提取单元格中的文本内容,最终输出可编辑、可分析的结构化数据(如CSV、Excel、JSON等格式)的技术体系。
其核心目标包括两个方面:
- 内容识别:准确识别表格中每个单元格内的文字;
- 结构还原:重建原始表格的行列关系、合并单元格、边框布局等版面信息。
核心技术流程
早期的表格识别主要基于规则和模板,这种方法对格式规范的表格效果尚可,但缺乏泛化能力。随着计算机视觉和深度学习的发展,现代表格识别技术已形成多阶段、多模型的成熟解决方案。系统通常包含以下关键模块:
- 表格区域检测(Table Detection)
- 使用目标检测模型或基于规则的方法,在整页文档图像中定位表格区域。对于多表格页面,需支持多个实例的检测。
- 表格结构识别(Table Structure Recognition)
- 这是最核心也是最具挑战性的环节。基于深度学习:采用语义分割(如U-Net)或图神经网络(GNN)预测单元格位置与行列关系。
- 文字识别(Text Recognition)
- 对每个单元格区域应用OCR引擎提取文本内容。需处理旋转、弯曲、低分辨率等干扰因素。
- 后处理与结构对齐
- 将识别出的文本与结构信息对齐,处理合并单元格、空单元格、跨页表格等情况,并校验逻辑一致性(如行列数匹配)。
实际应用:多领域的价值实现
表格识别技术在众多行业具有广泛应用:
- 金融领域:自动处理银行对账单、财务报表和保险索赔表,极大提高了数据录入效率。
- 医疗行业:识别病历表格、化验单和医疗记录,加速医疗数据电子化进程。
- 企业办公:合同、发票和采购订单的自动化处理,减少人工输入。
- 学术研究:从学术文献中提取实验数据表格,支持科学数据挖掘。
表格识别技术正从"能用"迈向"好用"和"智能用"的新阶段。随着大模型与多模态AI的发展,未来的表格识别系统不仅能还原版面,还能理解表格语义、关联上下文、甚至进行数据验证与推理。这项技术将成为智能文档处理、知识抽取和企业数字化转型不可或缺的基础设施,真正打通从"纸面信息"到"数字资产"的最后一公里。