文章目录


一、题目描述
题目链接:力扣 429. N 叉树的层序遍历
题目描述:

示例 1:
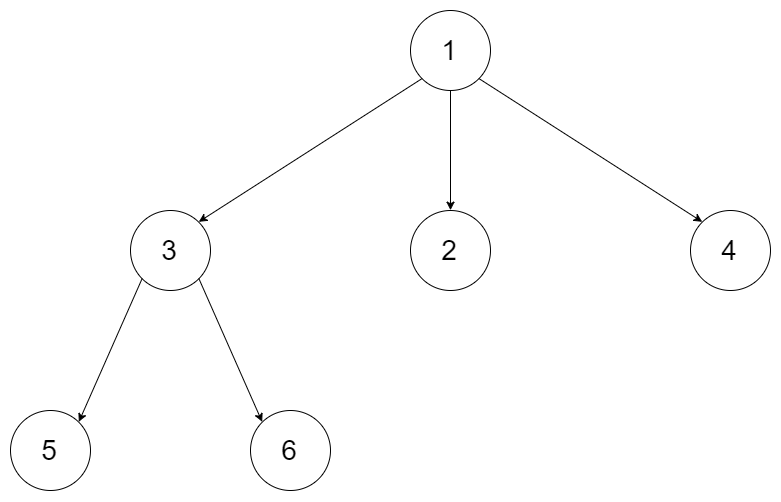
输入:root = 1,null,3,2,4,null,5,6
输出:\[1,3,2,4,5,6]
示例 2:输入:root = \[\]
输出:\[\]
提示:树的高度不会超过 1000
树的节点总数在 0, 104 之间
二、为什么这道题值得你花几分钟弄懂?
这道题是广度优先搜索(BFS)在N叉树中最经典的应用,也是面试中考察"层序遍历"的高频题。它没有复杂的语法陷阱,却能精准检验你是否真正理解队列"先进先出(FIFO)"的核心特性,以及如何在遍历中精准区分"层"的概念,是夯实BFS基础的必做题。
题目核心价值:
- BFS 本质的 "试金石":不考复杂 API,只考队列的核心规则 ------ 先进先出的顺序逻辑,以及如何通过 "统计层节点数" 实现分层,这是 BFS 解决层级问题的核心思路。
分层思维的训练场:普通层序遍历只需按顺序输出节点,而本题要求 "按层存储",需要在遍历中精准划分每一层,这种 - "分层处理" 的思维是解决树层级相关问题(如找每层最大值、找最底层最左节点)的通用思路。 - 面试的 "基础筛选题":大厂面试常把它当作树遍历的基础题,考察候选人对 BFS 的理解深度。能快速写出简洁解法,说明你对树的遍历和队列应用的基础扎实;反之,只会死记硬背的短板会被直接暴露。
- 边界场景的考量:覆盖 "空树""单节点树""多子节点树" 等所有 N 叉树场景,训练你考虑问题的全面性,避免因忽略极端情况导致代码漏洞。
- 代码简洁性的体现:最优解法仅需几行核心代码,能考察你 "用最少代码实现核心逻辑" 的能力,契合面试中 "代码简洁性" 的评分标准。
面试考察的核心方向:
- BFS 特性的理解深度:能否说清 "先进先出" 如何体现在层序遍历中,以及如何通过统计队列大小实现分层,而非单纯复述队列的定义。
- 分层逻辑的落地能力:能否将 "按层打印" 的需求转化为 "统计每层节点数→处理该层所有节点→存储结果" 的代码逻辑。
- 代码的健壮性:是否处理了空树、子节点为空的情况,避免空指针异常。
- 复杂度分析的准确性:能否快速分析出时间 / 空间复杂度,理解 BFS 遍历 N 叉树的代价。
掌握这道题,既能彻底吃透 BFS 遍历 N 叉树的核心规则,又能训练 "分层处理" 的解题思维。后续遇到树层级相关的进阶题,比如找每层最大值、N 叉树的右视图,都能快速找到解题思路,性价比极高。

三、题目解析
这道题的核心需求是把N叉树的节点按"层"划分,每层的节点值单独存入一个数组,最终返回二维数组。普通的层序遍历只是按顺序输出所有节点,而本题的关键是"分层"------要明确区分哪些节点属于第一层、哪些属于第二层,不能混在一起。
核心问题可以简化为:如何在广度优先遍历的过程中,精准识别并收集每一层的所有节点?
这个问题的答案,就藏在队列"先进先出"的规则里------每处理完一层节点前,队列的大小恰好是当前层的节点数,利用这个数值就能精准划分每一层。

四、算法原理
本题核心算法是 "基于队列的广度优先遍历(BFS)+ 分层统计",完全还原N叉树层序遍历的真实过程,用"统计每层节点数"的方式实现分层收集结果。思路简单且高效,和我们手动按层遍历N叉树的思路完全一致。
什么是BFS?
BFS(广度优先搜索)可以理解为"地毯式搜索":从根节点开始,先把当前层的所有节点都访问完,再依次访问下一层的所有节点。就像排队买奶茶,先到的人先买(队列先进先出),正好符合"从上到下、从左到右"的层序遍历顺序。
如何解决问题?
- 初始化一个队列,把N叉树的根节点入队(如果根节点为空,直接返回空结果)。
- 当队列不为空时,执行以下操作:
- 记录当前队列的大小(这个数值就是当前层的节点数,记为
level_size)。 - 创建一个临时数组,用于存储当前层的节点值。
- 循环
level_size次,依次取出队列头部的节点:- 将节点值存入临时数组。
- 遍历该节点的所有子节点,若子节点不为空则入队(为下一层遍历做准备)。
- 临时数组收集完当前层所有节点值后,将其存入最终结果数组。
- 记录当前队列的大小(这个数值就是当前层的节点数,记为
- 队列为空时,遍历完成,返回最终结果数组。
这个思路的本质是:用队列大小标记每层的节点边界,确保每一轮循环只处理当前层的节点,子节点入队后会成为下一轮循环的处理对象------这完全符合BFS"按层遍历"的规则。
模拟过程
我们用示例1完整模拟,帮你直观理解每一步的队列状态和分层收集过程。
场景:示例1 N叉树 1,null,3,2,4,null,5,6
(树结构说明:根节点1有3个子节点3、2、4;节点3有2个子节点5、6;节点2、4、5、6无子女)
初始状态:
- 队列
q = [1] - 最终结果
ret = []
| 步骤 | 队列状态 | 当前层节点数(level_size) | 临时数组(level_nums) | 操作(取出节点+入队子节点) | ret变化 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | \[\] | 取出1 → 存入1;入队3、2、4 | \[1] |
| 2 | 3,2,4 | 3 | \[\] | 取出3 → 存入3;入队5、6 取出2 → 存入2;无子女 取出4 → 存入4;无子女 | \[1,3,2,4] |
| 3 | 5,6 | 2 | \[\] | 取出5 → 存入5;无子女 取出6 → 存入6;无子女 | \[1,3,2,4,5,6] |
| 4 | \[\] | 0 | - | 队列空,结束遍历 | 不变 |
细节注意
- 层节点数统计时机:
level_size必须在处理当前层节点前获取队列大小,因为处理节点的过程中会将下一层节点入队,若在循环中获取会导致统计的节点数包含下一层内容,分层就会出错。 - 空节点处理:入队子节点前必须判断是否为空,避免空指针入队,导致后续访问节点值时出现程序崩溃。
- 边界条件:空树直接返回空的二维数组,这是避免后续操作访问空指针的关键。
- 队列数据结构选择:使用STL的
queue<TreeNode*>,其front()(取队头)、pop()(出队)、push()(入队)操作完全匹配BFS的需求,代码简洁且高效。
常见错误与避坑
- 忘记处理
root == nullptr:直接操作空根节点会触发空指针异常,这是最基础的边界错误。 level_size在循环中获取:比如把int level_size = q.size()写在for循环内部,会导致每次循环都读取最新队列大小(包含下一层节点),分层逻辑完全错误。- 遍历子节点时未判空:虽然力扣测试用例中子节点不会为空,但实际开发中可能存在空节点,直接入队会导致后续访问
child->val时崩溃。
五、代码实现
cpp
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> children;
Node() {}
Node(int _val) {
val = _val;
}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
*/
#include <queue>
#include <vector>
using namespace std;
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
// 存储最终的分层结果
vector<vector<int>> ret;
// 边界条件:空树直接返回空数组,避免后续操作空指针
if (root == nullptr) return ret;
// 队列存储待处理的节点,实现BFS的先进先出
queue<Node*> q;
q.push(root);
// 只要队列非空,说明还有未处理的层
while (!q.empty()) {
// 关键:记录当前层的节点数(循环前获取,避免混入下一层节点)
int level_size = q.size();
// 存储当前层的所有节点值
vector<int> level_nums;
// 遍历当前层的所有节点(循环次数=当前层节点数)
for (int i = 0; i < level_size; i++) {
// 取出队头节点
Node* curr_node = q.front();
q.pop();
// 记录当前节点值
level_nums.push_back(curr_node->val);
// 把当前节点的所有子节点入队(为下一层遍历做准备)
for (Node* child : curr_node->children) {
if (child != nullptr) {
q.push(child);
}
}
}
// 把当前层的结果加入最终数组
ret.push_back(level_nums);
}
return ret;
}
};细节说明
- 队列的使用 :用
queue<Node*>存储待处理的节点,push()入队根节点启动遍历,front()获取队头节点,pop()移除已处理的节点,完全匹配BFS"先进先出"的特性。 - 核心循环 :
- 外层
while循环:只要队列非空,说明还有未处理的层,继续遍历。 - 内层
for循环:循环次数等于当前层节点数level_size,确保只处理当前层的节点,这是实现分层的核心。
- 外层
- 子节点入队:遍历当前节点的所有子节点,先判断是否为空再入队------这是避免空指针入队和访问的关键。
- 结果收集 :每处理完一层节点,就将存储当前层值的临时数组
level_nums存入最终结果ret,保证结果的分层结构。
复杂度分析
- 时间复杂度:O(n)。n 是N叉树的节点数,每个节点只会入队一次、出队一次,总操作次数是 n,因此时间复杂度为线性级别。
- 空间复杂度:O(n)。最坏情况下,比如N叉树的根节点有n-1个子节点(第一层就有n-1个节点),此时队列的最大长度为 n-1,空间复杂度为 O(n)。
拓展:递归解法(DFS实现)
除了BFS,也可以用DFS递归实现层序遍历,核心思路是记录当前节点的层级,将节点值添加到对应层级的数组中:
cpp
class Solution {
private:
void dfs(Node* node, int level, vector<vector<int>>& ret) {
if (node == nullptr) return;
// 如果当前层级超出结果数组长度,新增一层
if (level >= ret.size()) {
ret.push_back({});
}
// 将当前节点值加入对应层级
ret[level].push_back(node->val);
// 递归遍历所有子节点,层级+1
for (Node* child : node->children) {
dfs(child, level + 1, ret);
}
}
public:
vector<vector<int>> levelOrder(Node* root) {
vector<vector<int>> ret;
dfs(root, 0, ret);
return ret;
}
};六、总结
- BFS的核心特性:队列"先进先出"是层序遍历的根本,通过统计每轮循环前的队列大小划分层级,是解决二叉树分层问题的核心思路。
- 分层思维:将"按层打印"的需求转化为"统计层节点数→处理层内节点→收集层结果"的逻辑,是解决所有层级相关问题的通用方法。
- 代码健壮性:处理空树、空节点等边界场景,避免空指针异常,是编写可靠代码的关键。
七、下题预告
下一篇我们一起学习BFS在而二叉树中的更多应用,一起攻克 力扣 103. 二叉树的矩形层序遍历。
喵~ 能啃完N叉树层序遍历的题喵,宝子超厉害的喵~ 要是对分层统计的逻辑、队列操作的时机还有小疑问喵,或者有更丝滑的解题思路喵,都可以甩到评论区喵,我看到会第一时间把问题给这个博主的喵~
别忘了给这个博主点个赞赞喵、关个注注喵~(๑˃̵ᴗ˂̵)و 你对这个博主的支持就是他继续肝优质算法内容的最大动力啦喵~我们下道题,不见不散喵~
