文章目录


一、题目描述
题目链接:力扣 103. 二叉树的锯齿形层序遍历
题目描述:
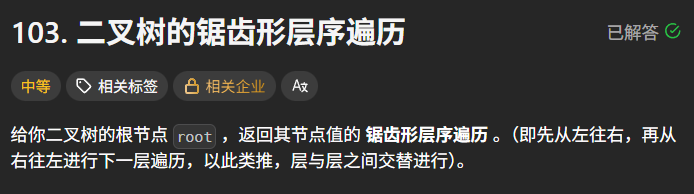
示例 1:
输入:root = 3,9,20,null,null,15,7
输出:\[3,20,9,15,7]
示例 2:输入:root = 1
输出:\[1]
示例 3:输入:root = \[\]
输出:\[\]
提示:树中节点数目在范围 0, 2000 内
-100 <= Node.val <= 100
二、为什么这道题值得你花几分钟弄懂?
这道题是BFS层序遍历的进阶应用,是大厂面试中考察"分层遍历+逻辑拓展"的高频题。它在基础层序遍历的核心逻辑上,增加了"奇偶层反向"的规则,既能检验你对BFS分层逻辑的掌握程度,又能考察你灵活调整遍历结果的能力,是夯实树遍历基础、提升逻辑拓展能力的必做题。
题目核心价值:
- 基础能力的延伸:在N叉树层序遍历的"分层"核心上,新增"方向控制"逻辑,检验你是否真正理解分层遍历的本质,而非死记硬背代码。
- 逻辑灵活性的体现:同一套BFS框架下,仅通过简单的"层数判断+数组反转"就能实现锯齿形遍历,训练你"在通用框架上定制化需求"的思维。
- 面试的"进阶筛选题":基础层序遍历是入门题,而锯齿形遍历是基础题的变形,能区分"只会写固定代码"和"能灵活调整逻辑"的候选人。
- 边界场景的再训练:同样需要处理空树、单节点树、满二叉树等场景,进一步强化你考虑问题的全面性。
- 代码简洁性的平衡:在不破坏BFS核心逻辑的前提下,用最少的代码实现方向反转,契合面试中"简洁且易读"的代码评分标准。
面试考察的核心方向:
- BFS分层逻辑的迁移能力:能否将N叉树分层遍历的思路无缝迁移到二叉树,并适配二叉树"左右子节点"的结构。
- 逻辑拓展能力:能否在基础遍历逻辑上,快速添加"奇偶层判断""数组反转"的拓展逻辑。
- 代码优化意识:是否能意识到"提前判断方向再收集值"和"先收集再反转"两种方式的优劣(本题中后者更简洁)。
- 复杂度分析:能否准确分析"数组反转"对时间复杂度的影响(本题中反转操作总次数仍为O(n),整体复杂度不变)。
掌握这道题,既能巩固BFS分层遍历的核心,又能训练"基础逻辑+定制化需求"的解题思路,后续遇到"按层求最大值""二叉树右视图"等进阶题,都能快速适配,性价比极高。
三、算法原理
本题我们完全可以参照上一篇博客力扣 429. N 叉树的层序遍历 C++,核心算法是 "基于队列的BFS分层遍历 + 奇偶层方向控制",在基础层序遍历的框架上,仅增加"层数标记"和"数组反转"两步操作,逻辑清晰且易于理解。
- 初始化一个队列,把二叉树的根节点入队(若根节点为空,直接返回空结果)。
- 初始化一个层数标记
depth(从0开始),用于判断当前层是否需要反向。 - 当队列不为空时,执行以下操作:
- 记录当前队列的大小(即当前层的节点数
n)。 - 创建临时数组
mark,存储当前层的节点值。 - 循环
n次,依次取出队列头部的节点:- 将节点值存入
mark。 - 若节点有左子节点,将左子节点入队;若有右子节点,将右子节点入队(为下一层遍历做准备)。
- 将节点值存入
- 根据
depth的奇偶性调整mark:- 若
depth为偶数(0、2、4...):直接将mark加入最终结果; - 若
depth为奇数(1、3、5...):反转mark后再加入最终结果。
- 若
depth加1,进入下一层遍历。
- 记录当前队列的大小(即当前层的节点数
- 队列为空时,遍历完成,返回最终结果数组。
这个思路的本质是:用BFS完成分层收集,用简单的"反转数组"实现方向控制,以最小的代码改动适配"锯齿形"需求。
模拟过程
我们用示例1完整模拟,帮你直观理解每一步的队列状态和结果调整过程。
场景:示例1 二叉树 3,9,20,null,null,15,7
(树结构说明:根节点3有左子节点9、右子节点20;9无子女;20有左子节点15、右子节点7)
初始状态:
- 队列
q = [3] - 最终结果
ret = [] - 层数
depth = 0
| 步骤 | 队列状态 | 当前层节点数(n) | 临时数组(mark) | 层数(depth) | 方向判断与操作 | ret变化 |
|---|---|---|---|---|---|---|
| 1 | 3 | 1 | 3 | 0(偶数) | 直接加入 | \[3] |
| 2 | 9,20 | 2 | 9,20 | 1(奇数) | 反转→20,9,加入 | \[3,20,9] |
| 3 | 15,7 | 2 | 15,7 | 2(偶数) | 直接加入 | \[3,20,9,15,7] |
| 4 | \[\] | 0 | - | 3 | 队列空,结束遍历 | 不变 |
细节注意
- 层数标记的起始值:
depth从0或1开始均可,只需保证奇偶判断逻辑和起始值匹配(比如从0开始则偶数层正向,从1开始则奇数层正向)。 - 子节点入队顺序:二叉树层序遍历需先入队左子节点、再入队右子节点,保证"从左到右"的收集顺序。
- 数组反转的时机:必须在当前层所有节点值收集完成后再反转,若在收集过程中反向入队,会增加逻辑复杂度。
- 边界条件:空树直接返回空数组,避免后续操作空指针;单节点树直接返回
[[val]],无需反转。
常见错误与避坑
- 子节点入队顺序错误:先入队右子节点再入队左子节点,导致基础收集顺序错误,后续反转也无法得到正确结果。
- 层数判断逻辑混乱:比如
depth从1开始,却仍按"偶数层反转"处理,导致方向完全错误。 - 反转操作时机错误:在收集节点值的循环中逐次反转,而非收集完一层后整体反转,导致逻辑混乱。
- 忘记处理空树:直接操作空根节点会触发空指针异常。
四、代码实现
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
#include <vector>
#include <algorithm> // 包含ranges::reverse所需的头文件
using namespace std;
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
// 存储最终的锯齿形遍历结果
vector<vector<int>> ret;
// 边界条件:空树直接返回空数组
if(root == nullptr)
return ret;
// 用vector模拟队列(也可用queue<TreeNode*>,逻辑完全一致)
vector<TreeNode*> q;
q.push_back(root);
// 层数标记,初始为0(第一层)
int depth = 0;
// 队列非空则继续遍历
while(!q.empty())
{
// 记录当前层的节点数(循环前获取,避免混入下一层节点)
int n = q.size();
// 存储当前层的节点值
vector<int> mark;
// 遍历当前层的所有节点
for(int i = 0; i < n; i++)
{
// 取出队头节点(vector的front()对应队列头)
TreeNode* tmp = q.front();
q.erase(q.begin()); // 移除已处理的队头节点
// 收集当前节点值
mark.push_back(tmp->val);
// 二叉树子节点入队:先左后右,保证基础层序的顺序
if(tmp->left != nullptr) q.push_back(tmp->left);
if(tmp->right != nullptr) q.push_back(tmp->right);
}
// 核心:根据层数奇偶性调整方向
if(depth % 2 == 0) {
// 偶数层:正向加入结果
ret.push_back(mark);
} else {
// 奇数层:反转后加入结果
ranges::reverse(mark.begin(), mark.end());
ret.push_back(mark);
}
// 层数加1,进入下一层
depth++;
}
return ret;
}
};代码细节说明
- 队列的实现 :你用
vector<TreeNode*>模拟队列(push_back入队、front()取队头、erase(q.begin())出队),也可以用C++标准库的queue<TreeNode*>(push入队、front()取队头、pop()出队),逻辑完全一致,后者效率更高(vector的erase头部元素时间复杂度为O(n),queue的pop为O(1))。 - 核心逻辑 :
- 外层
while循环:控制层的遍历,队列非空则继续; - 内层
for循环:遍历当前层的所有节点,收集值并将子节点入队; - 方向控制:通过
depth % 2判断奇偶层,奇数层用ranges::reverse反转数组(也可用reverse(mark.begin(), mark.end()),需包含<algorithm>)。
- 外层
- 子节点入队:二叉树需先入队左子节点、再入队右子节点,保证基础层序"从左到右"的收集顺序。
复杂度分析
- 时间复杂度:O(n)。n是二叉树的节点数,每个节点入队、出队各一次(O(n));数组反转操作总次数为O(n)(每层反转的元素数之和等于总节点数),因此整体时间复杂度仍为O(n)。
- 空间复杂度:O(n)。最坏情况下(完美二叉树的最后一层),队列存储的节点数为n/2,空间复杂度为O(n);结果数组存储所有节点值,空间复杂度也为O(n),整体为O(n)。
五、总结
- 核心逻辑:BFS分层遍历 + 奇偶层方向控制是解决锯齿形层序遍历的核心,先分层收集值,再通过反转实现方向调整是最简洁的方式。
- 细节要点:二叉树子节点需"先左后右"入队,层数标记的起始值需和方向判断逻辑匹配。
- 代码优化:标准库
queue比vector模拟队列效率更高,数组反转操作不影响整体时间复杂度。
六、下题预告
下一篇我们一起学习BFS在二叉树中的进阶应用,攻克 力扣 662. 二叉树最大宽度。
喵~ 能啃完二叉树层锯齿形层序遍历的题喵,宝子超厉害的喵~ 要是对分层统计的逻辑、队列操作的时机还有小疑问喵,或者有更丝滑的解题思路喵,都可以甩到评论区喵,我看到会第一时间把问题给这个博主的喵~
别忘了给这个博主点个赞赞喵、关个注注喵~(๑˃̵ᴗ˂̵)و 你对这个博主的支持就是他继续肝优质算法内容的最大动力啦喵~我们下道题,不见不散喵~
