文章目录
- 智能体
-
- deepseek
- GPT
- [PromptTemplate 教程](#PromptTemplate 教程)
-
- 一、背景
- 二、示例代码
- [三、PromptTemplate 的优势](#三、PromptTemplate 的优势)
- [四、Prompt 设计小技巧](#四、Prompt 设计小技巧)
- [五、Python 内置模板:f-string](#五、Python 内置模板:f-string)
-
- [PromptTemplate vs 直接 f-string](#PromptTemplate vs 直接 f-string)
- [六、Jinja2 模板生成 AI Prompt](#六、Jinja2 模板生成 AI Prompt)
- [七、Prompt 序列化:使用文件管理提示词](#七、Prompt 序列化:使用文件管理提示词)
-
- [1.JSON 格式 Prompt 示例](#1.JSON 格式 Prompt 示例)
- [2.YAML 格式 Prompt 示例](#2.YAML 格式 Prompt 示例)
- 八、消息模板
- 增强检索
-
- [LangChain 文本切分](#LangChain 文本切分)
- [LangChain 字符切割](#LangChain 字符切割)
- [LangChain 代码文档切割](#LangChain 代码文档切割)
- [LangChain Token 切割](#LangChain Token 切割)
- [LangChain 文档加载器](#LangChain 文档加载器)
-
- [Markdown 文件加载](#Markdown 文件加载)
- 目录加载(批量文件)
- [CSV 文件加载](#CSV 文件加载)
- [HTML 文件加载](#HTML 文件加载)
- [JSON 文件加载](#JSON 文件加载)
- [PDF 文件加载](#PDF 文件加载)
- 文档加载器使用经验总结
- 实战:智能机器人
智能体
deepseek
1:产品介绍
DeepSeek-V3 是一款高性能的开源 AI 模型,支持自然语言处理、智能对话生成等任务。其 API 接口与 OpenAI 完全兼容,用户可以通过简单的配置迁移现有项目,同时享受更低的成本和更高的性能。本文 档将详细介绍如何快速接入 DeepSeek-V3 API
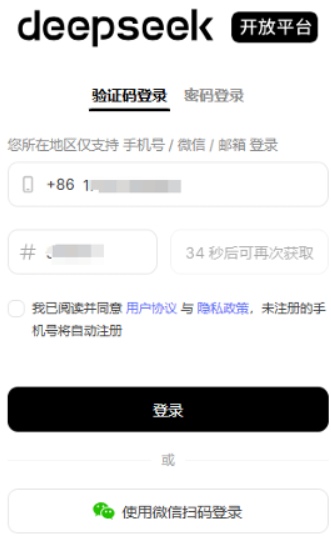
2:注册账号

点击注册
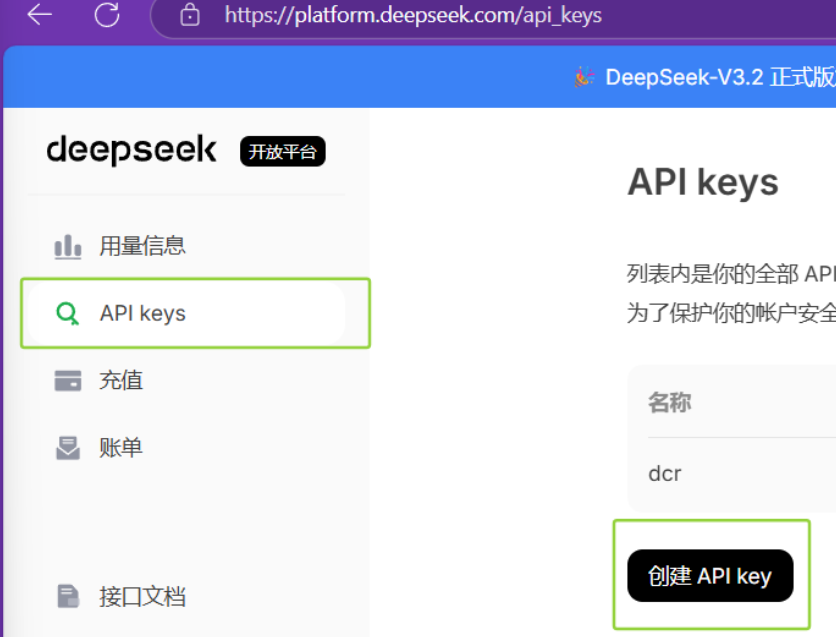
3:创建API key

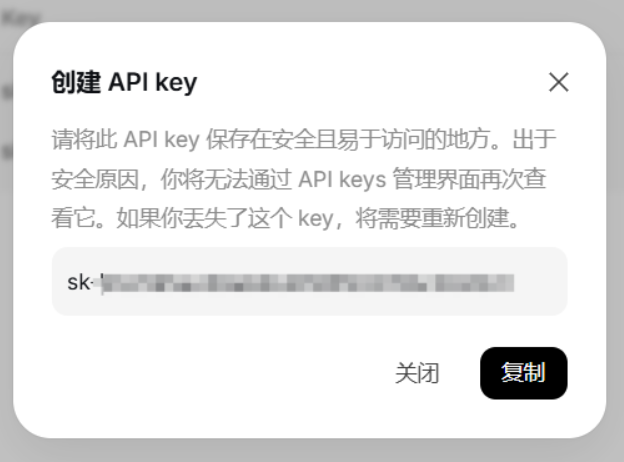
注意:创建后API key只出现一次,请存储在安全位置,例如:环境变量或者配置文件中
4:使用Python调用API
1)安装OpenAI API库
bash
pip install openai2)API 是一个"无状态" API,即服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对 话历史拼接好后,传递给对话 API。
1.单次会话
python
from openai import OpenAI
#创建客户端
client = OpenAI(
api_key='sk-a8.....',
base_url='https://api.deepseek.com'
)
#发送终端对话
response = client.chat.completions.create(
#模型类型
model='deepseek-chat',
messages=[
{'role':'system','content':'你是一位运维工程师助手'},
{'role':'user','content':'你是谁'}
],
#流式输出
stream=False #是慢慢的输出内容,不是突然全部输出
)
#回应信息
print(response.choices[0].message.content)
#################也可以使用交互式的收入问题方法######################
from openai import OpenAI
#创建客户端
client = OpenAI(
api_key='sk-a8.....',
base_url='https://api.deepseek.com'
)
#发送终端对话
response = client.chat.completions.create(
#模型类型
model='deepseek-chat',
messages=[
{'role':'system','content':'你是一位运维工程师助手'},
{'role':'user','content':input('请输入你的问题:')}
],
#流式输出
stream=False
)
#回应信息
print(response.choices[0].message.content)
#########################优化后防止信息泄露#############################
from openai import OpenAI
import os
#创建客户端
client = OpenAI(
api_key=os.getenv('deepseek_key'), #使用系统的环境标量,调用
base_url='https://api.deepseek.com'
)
#发送终端对话
response = client.chat.completions.create(
#模型类型
model='deepseek-chat',
messages=[
{'role':'system','content':'你是一位运维工程师助手'},
{'role':'user','content':input('请输入你的问题:')}
],
#流式输出
stream=False
)
#回应信息
print(response.choices[0].message.content)2.多轮会话
python
import os
from openai import OpenAI
text = input('请输入问题:\n')
print('正在与deepseek对话,请稍等...')
client = OpenAI(
api_key = os.getenv('deepseek_key'),
base_url = 'https://api.deepseek.com'
)
messages = [{
'role':'user',
'content':text
}]
response = client.chat.completions.create(
#模式类型
model = 'deepseek-chat',
#消息
messages = messages,
stream = False
)
#解释回应
print('deepseek回复:\n')
print(response)
请输入问题:
写一首诗
正在与deepseek对话,请稍等...
deepseek回复:
ChatCompletion(id='7f5ab025-1c97-4faa-9a54-661476765293', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='《秋窗书怀》。。)。。]
########想得到搜索结果需要定位#################
print(response.choices)
#列表 类
[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='《夜泊枫桥》..)..] ############继续定位#############
print(response.choices[0].message) ChatCompletionMessage(content='《夜泊枫桥》。。)...]
###########最后#############
#多轮会话
import os
from openai import OpenAI
text = input('请输入问题:\n')
print('正在与deepseek对话,请稍等...')
client = OpenAI(
api_key = os.getenv('deepseek_key'),
base_url = 'https://api.deepseek.com'
)
messages = [{
'role':'user',
'content':text
}]
response = client.chat.completions.create(
#模式类型
model = 'deepseek-chat',
#消息
messages = messages,
stream = False
)
#解释回应
print('deepseek回复:\n')
print(response.choices[0].message.content)
print()
while True: ###持续的会话
text = input('继续会话:')
print('正在与deepseek对话,请稍等...')
client = OpenAI(
api_key=os.getenv('deepseek_key'),
base_url='https://api.deepseek.com'
)
messages = [{
'role': 'user',
'content': text
}]
response = client.chat.completions.create(
# 模式类型
model='deepseek-chat',
# 消息
messages=messages,
stream=False
)
# 解释回应
print('deepseek回复:\n')
print(response.choices[0].message.content)
print()GPT
bash
from openai import OpenAI
client = OpenAI(
api_key="sk-proj-xCN5xjNhT-。。。。"
)
response = client.responses.create(
model="gpt-5-nano",
input="帮我介绍一下karina",
store=True,
)
print(response.output_text);PromptTemplate 教程
一、背景
在使用大语言模型(LLM)时,Prompt(提示词)决定了模型的行为方式。
如果 Prompt 写死在代码中,会导致:
- 难以复用
- 难以维护
- 不利于扩展
LangChain 提供了 PromptTemplate,用于参数化、标准化Prompt。
二、示例代码
bash
#导入PromptTemplate模块
from langchain_core.prompts import PromptTemplate
#from_template创建模块
prompt = PromptTemplate.from_template(
'你是一位{name},轻微这个女孩起一个带有{county}特色的名字'
)
#使用format传入变量
print(prompt.format(name='大师',county='中国'))三、PromptTemplate 的优势
- Prompt 参数化
bash
prompt.format(name='智者', county='英国')
prompt.format(name='导师', county='法国')- 避免 Prompt 写死在代码里
bash
"你是智者,帮我的机器人起个具有英国特色的男孩名字"
prompt.format(name="智者", county="英国")- 为后续链式调用打基础
PromptTemplate 是:
- LLMChain
- Runnable
- ChatPromptTemplate
四、Prompt 设计小技巧
1:明确角色(Role)
2:任务描述清晰
3:限制输出形式(可扩展)
五、Python 内置模板:f-string
bash
#导入PromptTeplate模块
from langchain_core.prompts import PromptTemplate
#定义模板字符串
fstring_template = '''
给我讲一个关于{name}的{what}故事
'''
#创建PromptTemplate对象
prompt = PromptTemplate.from_template(fstring_template)
#传入参数并格式化
print(prompt.format(name='karina',what='唱歌'))PromptTemplate vs 直接 f-string
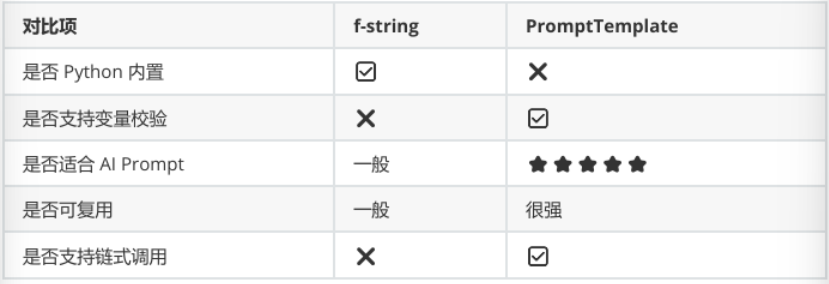
六、Jinja2 模板生成 AI Prompt
在 AI 应用中,我们经常需要动态生成大量 Prompt,例如:
- 生成 HTML / Markdown 文档
- 构造复杂 Prompt(条件、循环)
- 批量生成结构化提示词
如果只使用 Python 的 f-string:
一旦 Prompt 变复杂,就会变得难维护、难扩展。
一、什么是 Jinja2?
Jinja2 是 Python 生态中最流行的模板引擎之一
常见应用场景:
- Flask / FastAPI 的 HTML 模板
- Markdown / 文档生成
- 配置文件(YAML / JSON)
- AI Prompt 模板(LangChain)
二、环境准备
bash
pip install jinja2实战:
bash
from langchain_core.prompts import PromptTemplate
#jinja2模板
jinja2_template = '给我讲一个关于{{name}}的{{what}}故事'
prompt = PromptTemplate.from_template(
jinja2_template,
template_format='jinja2' #必须要指定jinja2
)
print(prompt.format(name='karina',what='唱歌'))
#############使用if 和 for 语句#######################
from langchain_core.prompts import PromptTemplate
jinja2_template = '''
给我讲一个关于{{name}}的{{what}}的故事
{% if level == "easy" %}
要求:语言简单,适用初学者
{% elif level == "hard" %}
要求:包含商业分析和战略思考
{% endif %}
'''
prompt = PromptTemplate.from_template(
jinja2_template,
template_format='jinja2'
)
print(prompt.format(name='karina',what='song',level='hard'))条件控制(if)
bash
{% if level == "beginner" %}
请使用通俗语言讲解
{% else %}
请进行深入技术分析
{% endif %}循环生成 Prompt
bash
请分别介绍以下人物:
{% for p in people %}
- {{ p }}
{% endfor %}七、Prompt 序列化:使用文件管理提示词
1.JSON 格式 Prompt 示例
json
{
"_type": "prompt",
"input_variable": ["name","what"],
"template": "给我讲一个关于{name}的{what}故事"
}
python
from langchain_core.prompts import load_prompt
prompt = load_prompt('simple_prompt.json',encoding='utf-8')
print(prompt.format(name='karina',what='出道至今'))2.YAML 格式 Prompt 示例
yaml
_type: prompt
input_variables:
["name","what"]
template:
给我讲一个关于{name}{what}的故事
python
from langchain_core.prompts import load_prompt
prompt = load_prompt('simple_prompt.yaml',encoding='utf-8')
print(prompt.format(name='karina',what='出道至今'))字符串(固化)-> 模板(参数)-> 多轮会话(角色)-> 消息(字符串)-> 消息模板
八、消息模板
python
from langchain_core.prompts import ChatPromptTemplate
messages = [
('system','你是一个大师,你的名字是{name}'),
('human','你好{name},你感觉怎么样'),
('ai','你好,我的状态很好'),
('human','你叫什么名字呢'),
('ai','我叫{name}'),
('human','{user_input}')
]
#会话模板
prompt = ChatPromptTemplate.from_messages(messages)
#参数传入
print(prompt.format_messages(name='ding',user_input='你的朋友是谁'))
[SystemMessage(content='你是一个大师,你的名字是ding', additional_kwargs={}, response_metadata={}), HumanMessage(content='你好ding,你感觉怎么样', additional_kwargs={}, response_metadata={}), AIMessage(content='你好,我的状态很好', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='你叫什么名字呢', additional_kwargs={}, response_metadata={}), AIMessage(content='我叫ding', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='你的朋友是谁', additional_kwargs={}, response_metadata={})]
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
sy = SystemMessage(
content='你是一个智能体',
additional_kwargs={'智能体名字':'ding'}
)
hu = HumanMessage(
content='请问智能体叫什么名字?'
)
ai = AIMessage(
content='我的名字叫ding'
)
for msg in [sy,hu,ai]:
print(msg.type,msg.content)
system 你是一个智能体
human 请问智能体叫什么名字?
ai 我的名字叫ding
from langchain_core.prompts import ChatMessagePromptTemplate
prompt = '有一种英雄主义在认清{subject}的真相后,依然热爱{subject}'
chat_message_prompt = ChatMessagePromptTemplate.from_template(
template = prompt,
role = '张无忌'
)
print(chat_message_prompt.format(subject='江湖'))
content='有一种英雄主义在认清江湖的真相后,依然热爱江湖' additional_kwargs={} response_metadata={} role='张无忌'
from langchain_core.prompts import (
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
ChatPromptTemplate
)
chat_prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(
'你正在扮演一部{subject}世界'
),
HumanMessagePromptTemplate.from_template(
'请发表一句{subject}感悟'
),
])
messages = chat_prompt.format_messages(subject='江湖')
for m in messages:
print(m.type,":",m.content)
system : 你正在扮演一部江湖世界
human : 请发表一句江湖感悟增强检索
增强检索(Enhanced Retrieval)* 通常指在信息检索或大模型应用中,通过 *更聪明的检索 + 更好的 上下文组织,显著提升答案的准确性、相关性和可解释性。最常见的落地形态就是 RAG(Retrieval Augmented Generation,检索增强生成)。
LangChain 文本切分
从本地 txt 文件 → 自动识别编码 → 使用 LangChain 进行文本切分
bash
#准备环境
pip install -U langchain-text-splitters chardet
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
import chardet
#文件路径
file_path = './text2/story.txt'
#自动检测文件编码
def get_encoding(file_path):
"""
使用chardet自动检测文本编码
避免中文txt出现UnicodeDecodeError
"""
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
return encoding
#读取原始文件
with open(file_path,'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
#创建递归字符切割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=20,
length_function=len,
add_start_index=True,
)
#执行文本切割
documents = text_splitter.create_documents([raw_data])
#输出切割结果
for doc in documents:
print(doc)
page_content='《荆棘虹桥与铃兰星屑》' metadata={'start_index': 0}
page_content='月光在墨蓝的夜空中碎成银箔,小兔子雪绒踩着噼啪作响的枯叶迷了路,她裹紧蒲公英织的斗篷,' metadata={'start_index': 12}
page_content='忽然望见前方飘着团幽蓝的磷火,火焰里蜷着只半透明的萤火虫,翅膀上裂着细小的冰纹。' metadata={'start_index': 56}
page_content='"请别熄灭!"萤火虫突然开口,尾灯随着话语明明灭灭,"我本是北极星碎片化成的星萤,' metadata={'start_index': 97}
page_content='被黑女巫的咒语困在这里,只要天亮前能抵达彩虹尽头,我就能变回星星照亮你的路。' metadata={'start_index': 139}
page_content='"雪绒用蘑菇伞接住脆弱的星萤,按它指引的方向奔跑,树根突然暴起缠住她的脚踝,' metadata={'start_index': 178}
page_content='泥土里钻出上百只毒蝎,尾针齐刷刷对准她们。"抓紧!"雪绒扯断颈间妈妈给的护身符,' metadata={'start_index': 217}
page_content='铃兰花苞迸出清光逼退毒蝎,自己却被荆棘割得浑身渗血。黎明将临时她们终于冲到悬崖边,' metadata={'start_index': 258}
page_content='星萤突然脱离蘑菇伞冲向瀑布,在撞碎成星尘的瞬间,整条瀑布倒流成虹桥,雪绒的伤口绽放出铃兰,' metadata={'start_index': 300}
page_content='每一朵花蕊都坠着发光的星屑。当第一缕阳光切开夜幕,铃兰星屑汇成银河铺向家的方向,而夜空从此多了一颗' metadata={'start_index': 346}
page_content='汇成银河铺向家的方向,而夜空从此多了一颗会降下花雨的星星。' metadata={'start_index': 375}LangChain 字符切割
python
from langchain_text_splitters import CharacterTextSplitter
import chardet
#文件路径
file_path = './text2/story.txt'
#自动检测文件编码
def get_encoding(file_path):
"""
使用chardet自动检测文本编码
避免中文txt出现UnicodeDecodeError
"""
with open(file_path, 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
return encoding
#读取原始文件
with open(file_path,'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
#创建递归字符切割器
text_splitter = CharacterTextSplitter(
separator='. ', # 指定分隔符(中文逗号)
chunk_size=50, # 每个文本块最大长度
chunk_overlap=20, # 相邻文本块重叠部分
length_function=len, # 长度计算方式
add_start_index=True, # 记录原文起始索引
is_separator_regex=False # 分隔符是否为正则
)
#执行文本切割
documents = text_splitter.create_documents([raw_data])
#输出切割结果
for doc in documents:
print(doc)
page_content='《荆棘虹桥与铃兰星屑》
月光在墨蓝的夜空中碎成银箔,小兔子雪绒踩着噼啪作响的枯叶迷了路,她裹紧蒲公英织的斗篷,
忽然望见前方飘着团幽蓝的磷火,火焰里蜷着只半透明的萤火虫,翅膀上裂着细小的冰纹。
"请别熄灭!"萤火虫突然开口,尾灯随着话语明明灭灭,"我本是北极星碎片化成的星萤,
被黑女巫的咒语困在这里,只要天亮前能抵达彩虹尽头,我就能变回星星照亮你的路。
"雪绒用蘑菇伞接住脆弱的星萤,按它指引的方向奔跑,树根突然暴起缠住她的脚踝,
泥土里钻出上百只毒蝎,尾针齐刷刷对准她们。"抓紧!"雪绒扯断颈间妈妈给的护身符,
铃兰花苞迸出清光逼退毒蝎,自己却被荆棘割得浑身渗血。黎明将临时她们终于冲到悬崖边,
星萤突然脱离蘑菇伞冲向瀑布,在撞碎成星尘的瞬间,整条瀑布倒流成虹桥,雪绒的伤口绽放出铃兰,
每一朵花蕊都坠着发光的星屑。当第一缕阳光切开夜幕,铃兰星屑汇成银河铺向家的方向,而夜空从此多了一颗会降下花雨的星星。' metadata={'start_index': 0}LangChain 代码文档切割
bash
#导入模块
from langchain_text_splitters import (
RecursiveCharacterTextSplitter,
Language
)
#显示python代码
PYTHON_CODE ='''
def sum():
a = 0
for i in range(1,11):
a += i
print(a)
sum()
'''
#创建python专用代码切割器
py_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=10
)
#执行代码切割
python_docs = py_splitter.create_documents([PYTHON_CODE])
#查看结果
for doc in python_docs:
print(doc)
page_content='def sum():
a = 0
for i in range(1,11):'
page_content='a += i
print(a)'
page_content='def sum():
a = 0
for i in range(1,11):'
page_content='a += i
print(a)
sum()'LangChain Token 切割
bash
from langchain_text_splitters import CharacterTextSplitter
import chardet
import tiktoken
file_path = './text2/story.txt'
def get_encoding(file_path):
"""
返回文件的字符编码
避免直接open中文文本时出现UnicodeDecodeError
"""
with open(file_path, 'rb') as f:
return chardet.detect(f.read())['encoding']
with open(file_path, 'r',encoding=get_encoding(file_path)) as f:
raw_data = f.read()
token_splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator=". ",
chunk_size=10,
chunk_overlap=2
)
Chunk 0:
Token count:612
《荆棘虹桥与铃兰星屑》
月光在墨蓝的夜空中碎成银箔,小兔子雪绒踩着噼啪作响的枯叶迷了路,她裹紧蒲公英织的斗篷,
忽然望见前方飘着团幽蓝的磷火,火焰里蜷着只半透明的萤火虫,翅膀上裂着细小的冰纹。
"请别熄灭!"萤火虫突然开口,尾灯随着话语明明灭灭,"我本是北极星碎片化成的星萤,
被黑女巫的咒语困在这里,只要天亮前能抵达彩虹尽头,我就能变回星星照亮你的路。
"雪绒用蘑菇伞接住脆弱的星萤,按它指引的方向奔跑,树根突然暴起缠住她的脚踝,
泥土里钻出上百只毒蝎,尾针齐刷刷对准她们。"抓紧!"雪绒扯断颈间妈妈给的护身符,
铃兰花苞迸出清光逼退毒蝎,自己却被荆棘割得浑身渗血。黎明将临时她们终于冲到悬崖边,
星萤突然脱离蘑菇伞冲向瀑布,在撞碎成星尘的瞬间,整条瀑布倒流成虹桥,雪绒的伤口绽放出铃兰,
每一朵花蕊都坠着发光的星屑。当第一缕阳光切开夜幕,铃兰星屑汇成银河铺向家的方向,而夜空从此多了一颗会降下花雨的星星。
==================================================LangChain 文档加载器
Markdown 文件加载
bash
from langchain_community.document_loaders import TextLoader
loader = TextLoader('./text/MD示例.md',encoding='utf-8')
docs = loader.load()
for i in docs:
print(i.page_content)
markdown加载示例
项目1:贪吃蛇
项目2:购物网
项目3:智能体目录加载(批量文件)
bash
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader('./text',glob='*.csv')
docs = loader.load()
print('目录中csv文件数量:',len(docs))CSV 文件加载
bash
from langchain_community.document_loaders import CSVLoader
import chardet
file_path = './text/score.csv'
def get_encoding(file_path):
with open(file_path, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
loader = CSVLoader(file_path,encoding=get_encoding(file_path),source_column='英语')
docs = loader.load()
for i in docs:
print(i.metadata)
{'source': '145', 'row': 0}
{'source': '139', 'row': 1}
{'source': '148', 'row': 2}
{'source': '131', 'row': 3}
{'source': '121', 'row': 4}
{'source': '112', 'row': 5}HTML 文件加载
bash
from langchain_community.document_loaders import BSHTMLLoader
loader = BSHTMLLoader("./text/index.html")
docs = loader.load()
for i in docs:
print(i.page_content)
first web
this is first web!!!JSON 文件加载
bash
pip install jq
bash
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path='./text/simple_prompt.json',
jq_schema='.template', # 使用 jq 提取字段
text_content=False
)
docs = loader.load()
print(docs)PDF 文件加载
bash
#加载pdf文件
from langchain_community.document_loaders import PythonLoader
loader = PythonLoader('./text/pulsar.pdf')
docs = loader.load_and_split()
for i in docs:
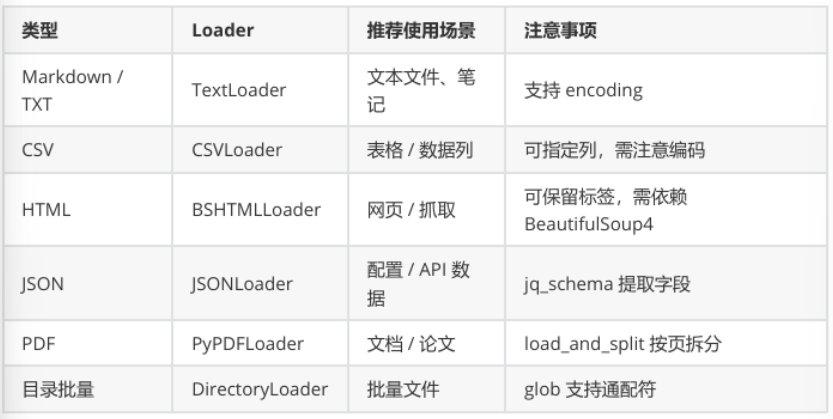
print(i)文档加载器使用经验总结
实战:智能机器人
阶段1:机器人雏形
bash
from openai import OpenAI
import os
#创建客户端
client = OpenAI(
api_key=os.getenv('AI_KEY'), #提前在电脑上设置环境变量
)
#创建消息(语境,对话)
messages = [
#设置系统语境
{'role':'system','content':'你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'},
{'role':'user','content':'我正在购买一个游戏笔记本电脑,但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?'}
]
#创建模型,获取回应消息
completion = client.chat.completions.create(
model = 'gpt-4o-mini',
messages = messages,
max_tokens=500,
temperature=0.7,
)
print(completion.choices[0].message.content)阶段2:机器人升级
bash
#机器人升级
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import os
#提示词模板
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你被用于抑制用户的购买欲望。当用户说想要买什么东西时,你需要提供理由让用户不要买'),
('human','我正在购买一个{product},但我想抑制这个购买欲望。你帮我列出一些理由,让我思考一下我是否真的需要个买这个商品吗?')
]
)
prompt_template.format(product='手机')
#创建会话模板
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens = 200,
temperature = 0.7,
)
#输出处理
def output_parser(output:str):
parser_model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
temperature = 0.7,
)
message = '你需要将传入的文本改写,使用一首诗描述。这时你需要改写的文本:{text}'
return parser_model.invoke(message.format(text=output))
#调用链处理 提示词输入->模型->输出->模型->输出格式化
chain = prompt_template | model | output_parser
while True:
answer_string = input('你想买什么?\n')
answer = chain.invoke(input={'product': answer_string})
print(answer.content)阶段3:机器人设计
bash
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
embeddings = HuggingFaceEmbeddings(
#模型名称
model_name = 'sentence-transformers/all-MiniLM-L6-v2',
#模型关键字
model_kwargs = {'device': 'cpu'}
)
text = [
'篮球是一项伟大的运动。',
'带我飞往月球是我最喜欢的歌曲之一。',
'这是一篇关于波士顿凯尔特人的文章。',
'我非常喜欢去看电影。',
'波士顿凯尔特人队以20分的优势赢得了比赛。',
'这只是一段随机的文字。',
'《艾尔登之环》是过去15年最好的游戏之一。',
'L.科内特是凯尔特人队最好的队员之一。',
'拉里.博德是一位标志性的NBA球员。'
]
#初始化Chroma、
retrieval = Chroma.from_texts(
#长文件
texts = text,
#传入模型实例
embeddings = embeddings,
).as_retriever(search_kwargs={'k':3})
query = '关于凯尔特人对你知道什么'
docs = retrieval.invoke(query)
for i in docs:
print(i.page_content)阶段4:机器人基础记忆
bash
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人'),
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
response = prompt_template.invoke(
{'history':
[
('human','你好'),
('ai','你好呀,很高兴认识你')
],
'new_message':'你是谁?'
}
).messages
for line in response:
print(line.content)记忆整合
bash
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
import os
#提示词模板
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人'),
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
#模板
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens = 200
)
#调用链
chain = prompt_template | model
#历史记录初始化
history = []
def chat(new_message):
response = chain.invoke({'history':history,'new_message':new_message})
history.extend([
('human',new_message),
('ai',response.content)
])
return response.content
print(chat('你好,我是ding,是一名学生,正在学习AI智能体开发课程'))
print(chat('请你叙述所知道的关于我的信息'))阶段5:完善机器人
bash
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_openai import ChatOpenAI
import os
prompt_template = ChatPromptTemplate.from_messages(
[
('system','你是一个聊天机器人'),
MessagesPlaceholder(variable_name='history'),
('human','{new_message}')
]
)
model = ChatOpenAI(
model = 'gpt-4o-mini',
openai_api_key = os.getenv('AI_KEY'),
max_tokens = 200
)
chain = prompt_template | model
from langchain_community.chat_message_histories import ChatMessageHistory
history = ChatMessageHistory()
#内容总结
def summarize_message(chain_input):
stored_message = history.messages
if len(stored_message) >= 6:
summarize_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name='history'),
('user','将上述聊天信息提炼成一条重要信息,尽可能多的包含具体细节。')
]
)
summarize_chain = summarize_prompt | model
summarize_message = summarize_chain.invoke({'history':stored_message})
history.clear()
history.add_message(summarize_message)
return chain_input
#记忆添加
chain_with_memory = RunnableWithMessageHistory(
chain,
lambda x:history,
input_messages_key = 'new_message',
history_messages_key = 'history'
)
chain_with_summarization = summarize_message | chain_with_memory
#多轮会话
while True:
new_message = input('You:')
response = chain_with_summarization.invoke(
{
'new_message': new_message,
},
config={
"configurable": {
"session_id": 'unused'
}
}
)
print(response.content)