⭐ 深度学习入门体系(第 15 篇): 从 RNN 到 LSTM:为什么深度网络需要"记忆能力"?
------教你真正听懂深度学习中的"时间建模"
卷积网络(CNN)擅长处理图片,
Transformer 擅长处理大规模序列,
但在它们崛起之前,序列建模的老大哥其实是 RNN/LSTM。
要理解为什么 RNN / LSTM 会出现,我们先回答一个核心问题:
为什么深度网络需要"记忆功能"?
文章目录
- [⭐ 深度学习入门体系(第 15 篇): 从 RNN 到 LSTM:为什么深度网络需要"记忆能力"?](#⭐ 深度学习入门体系(第 15 篇): 从 RNN 到 LSTM:为什么深度网络需要“记忆能力”?)
- [🧩 一、为什么深度网络需要记忆?](#🧩 一、为什么深度网络需要记忆?)
- [🔄 二、RNN:最简单的"记忆网络"](#🔄 二、RNN:最简单的“记忆网络”)
- [⚠️ 三、RNN 的致命问题:记不住长信息](#⚠️ 三、RNN 的致命问题:记不住长信息)
- [🔒 四、LSTM:深度学习时代最强"记忆模块"](#🔒 四、LSTM:深度学习时代最强“记忆模块”)
- [🤖 五、为什么 LSTM 能解决梯度消失?](#🤖 五、为什么 LSTM 能解决梯度消失?)
- [🛠 六、PyTorch 中使用 LSTM 极其简单](#🛠 六、PyTorch 中使用 LSTM 极其简单)
- [📚 七、RNN / LSTM / GRU 的关系](#📚 七、RNN / LSTM / GRU 的关系)
- [🧠 八、为什么 RNN/LSTM 最终被 Transformer 取代?](#🧠 八、为什么 RNN/LSTM 最终被 Transformer 取代?)
- [🎯 九、总结:让网络"理解时间"的第一代武器](#🎯 九、总结:让网络“理解时间”的第一代武器)
- [🔜 下一篇](#🔜 下一篇)
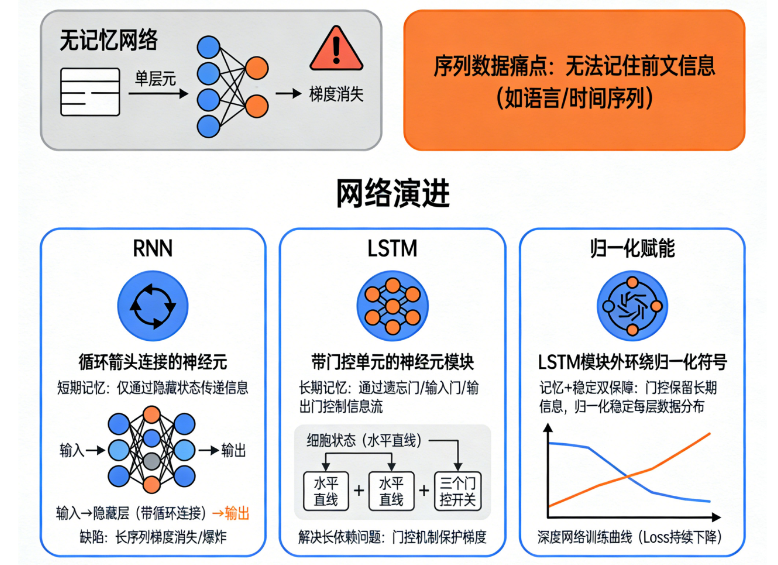
🧩 一、为什么深度网络需要记忆?
深度学习处理序列任务时(文本、语音、视频、时间序列),面临一个关键挑战:
当前的数据往往依赖于"前面发生过什么"。
例如:
-
"我今天很开 ..."
模型看到"心"后知道应该输出"开心"
-
语音识别中,一个音素决定下一个可能的音素
-
股票预测中,下一步走势和过去几十个点相关
-
视频理解中,当前动作依赖于之前动作
这些都是典型的 时序依赖(temporal dependency)。
如果你只用一个普通的前馈网络:
- 输入是固定的
- 没有历史信息
- 没有记忆机制
- 无法理解"上下文"
这就像你听别人讲话:
对方只说一个字,你就要猜整句话------基本不可能。
所以我们需要一种模型:
- 能记住过去
- 能理解上下文
- 能根据历史推断当前
- 能在时间维度上累计信息
这就是 RNN 的使命。
🔄 二、RNN:最简单的"记忆网络"
RNN(Recurrent Neural Network)结构非常简单,核心思想一句话:
当前输出不仅依赖当前输入,还依赖前一个隐藏状态。
结构示意:
t-1 ----> h_{t-1} ----\
---> h_t --> 输出
输入 x_t --------------/可以理解为:
RNN 像在读文章,每读一个字就把当前理解存到"脑子里(h_t)"。
生活化类比:读小说
RNN 的隐藏状态 h_t 就像:
你读一章后脑子里的记忆。
下一章你会基于已经读过的内容继续理解。
⚠️ 三、RNN 的致命问题:记不住长信息
RNN 虽然能记东西,但有一个致命缺陷:
只能记住很短的信息。
越往前的内容越容易被遗忘。
这就是 梯度消失 和 梯度爆炸 问题。
想象你上一个月记的事情,现在还能清楚吗?
但昨天的事情你还记得很清楚。
RNN 就是这种"短期记忆模型"。
工程结果:
- 句子稍微长一点就崩
- 对跨句依赖几乎无效
- 训练速度慢
- 梯度极其不稳定
所以需要一个改进方案。
🔒 四、LSTM:深度学习时代最强"记忆模块"
为了解决 RNN 的"记不住"的问题,LSTM(Long Short-Term Memory)被提出。
LSTM 的核心目标:
让网络具备长期记忆能力,保留重要信息,忘掉无关信息。
它用三个"门"来解决记忆问题:
- 输入门(Input Gate):决定要存多少新信息
- 遗忘门(Forget Gate):决定哪些旧信息要丢弃
- 输出门(Output Gate):决定输出多少记忆内容
它还有一个关键结构:
一个"单独的记忆单元":C_t
作为长期存储空间。
生活化类比:
把 RNN 和 LSTM 理解成"学生":
-
RNN 是短期记忆学生:看了就忘,看了就忘
-
LSTM 是用"学习笔记"的学生:
- 笔记(C_t)保存长期重要内容
- 不重要的划掉(遗忘门)
- 新知识加入笔记(输入门)
- 考试时从笔记拿关键内容(输出门)
LSTM 的成功来自:
用门结构精细管理信息的流动 → 解决长期依赖 → 稳定梯度
这使它成为 NLP、时间序列、语音识别的黄金时代主力。
🤖 五、为什么 LSTM 能解决梯度消失?
传统 RNN 的隐藏状态 h_t 会不断被矩阵乘法压缩或扩大。
长序列 → 梯度很快就炸了或消失。
LSTM 中的记忆单元 C_t 结构如下:
C_t = f_t * C_{t-1} + i_t * g_t其中:
- f_t(遗忘门)控制旧记忆保留多少
- i_t(输入门)控制新记忆加入多少
关键在:
遗忘门 f_t 可以接近 1,使 C_t ≈ C_{t-1},
这样梯度在 C_t 这条"高速通道"上不会衰减。
就像高速公路加了"直行车道",让信息可以长距离传递。
🛠 六、PyTorch 中使用 LSTM 极其简单
python
nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)RNN 和 GRU 也都类似。
工程中你几乎不会自己实现门结构,因为框架已经高度优化。
📚 七、RNN / LSTM / GRU 的关系
| 模型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RNN | 简单、快 | 梯度消失、记不住 | 短序列 |
| LSTM | 记忆长、稳定 | 参数多、慢 | NLP、语音、时间序列 |
| GRU | 比 LSTM 更轻 | 性能略弱一点 | 工程上常用 |
一句话总结:
RNN 是大脑,LSTM 是有笔记的大脑,GRU 是简化版的笔记大脑。
🧠 八、为什么 RNN/LSTM 最终被 Transformer 取代?
原因很简单:
- 不能并行
- 序列越长越慢
- 对超长依赖仍然困难
- 训练代价高
而 Transformer:
- 全并行
- 全局计算
- Attention 无距离限制
- 更容易扩展
但理解 RNN/LSTM 是理解深度学习序列模型的基础。
🎯 九、总结:让网络"理解时间"的第一代武器
用最简单的话总结 RNN→LSTM:
1)深度网络必须有"记忆能力"
2)RNN 只能短记忆
3)LSTM 给网络装上了"记忆放大器",能长期记住东西
4)门结构让模型能:
- 选择性记忆
- 选择性遗忘
- 稳定梯度
5)LSTM 是 Transformer 之前序列建模的绝对主力
理解它,对未来理解 Attention、Transformer、LLM 都非常重要。
🔜 下一篇
《深度学习入门体系(第 16 篇):ViT ------ 为什么 Transformer 能征服图像世界?》