文章目录
- [零 多模态模型强化学习情况说明](#零 多模态模型强化学习情况说明)
- [一 训练环境准备和Unsloth框架安装](#一 训练环境准备和Unsloth框架安装)
- [二 数据集准备和处理](#二 数据集准备和处理)
- [三 奖励函数的设置](#三 奖励函数的设置)
- [四 模型下载和运行测试](#四 模型下载和运行测试)
- [五 训练前推理](#五 训练前推理)
- [六 模型强化学习训练](#六 模型强化学习训练)
- [七 训练后推理](#七 训练后推理)
- [八 保存LoRA参数和模型](#八 保存LoRA参数和模型)
- [九 日志查看](#九 日志查看)
零 多模态模型强化学习情况说明
- 通过使用视觉模型qwen3-VL-8B模型,在unsloth框架上借助GSPO算法进行强化学习训练。
目标:视觉语言模型(VLM)集合图像和问题,学会推理解答数学问题题。 - 输入:图像(比如图里的几何/表格/图表等数学题)。
- 输出:详细的推理步骤 + 最终答案。
- 优化方式:通过 RL(比如 GSPO)来奖励"答案正确+推理格式合理"的输出。
一 训练环境准备和Unsloth框架安装
- 这里推荐在autodl租用一张5090进行实验,同时具体的配置版本如下

-
创建虚拟conda环境并安装unsloth
bashmkdir -p /root/autodl-fs/code/qwen3vl-gspo cd /root/autodl-fs/code/qwen3vl-gspo conda create -n qwen3vl-gspo python=3.12 conda init # 重启ssh连接 conda activate qwen3vl-gspo pip install unsloth -
在虚拟环境中安装jupyter内核方便后续jupyter lab的使用。
bashconda install ipykernel python -m ipykernel install --user --name qwen3vl-gspo --display-name qwen3vl-gspo
二 数据集准备和处理
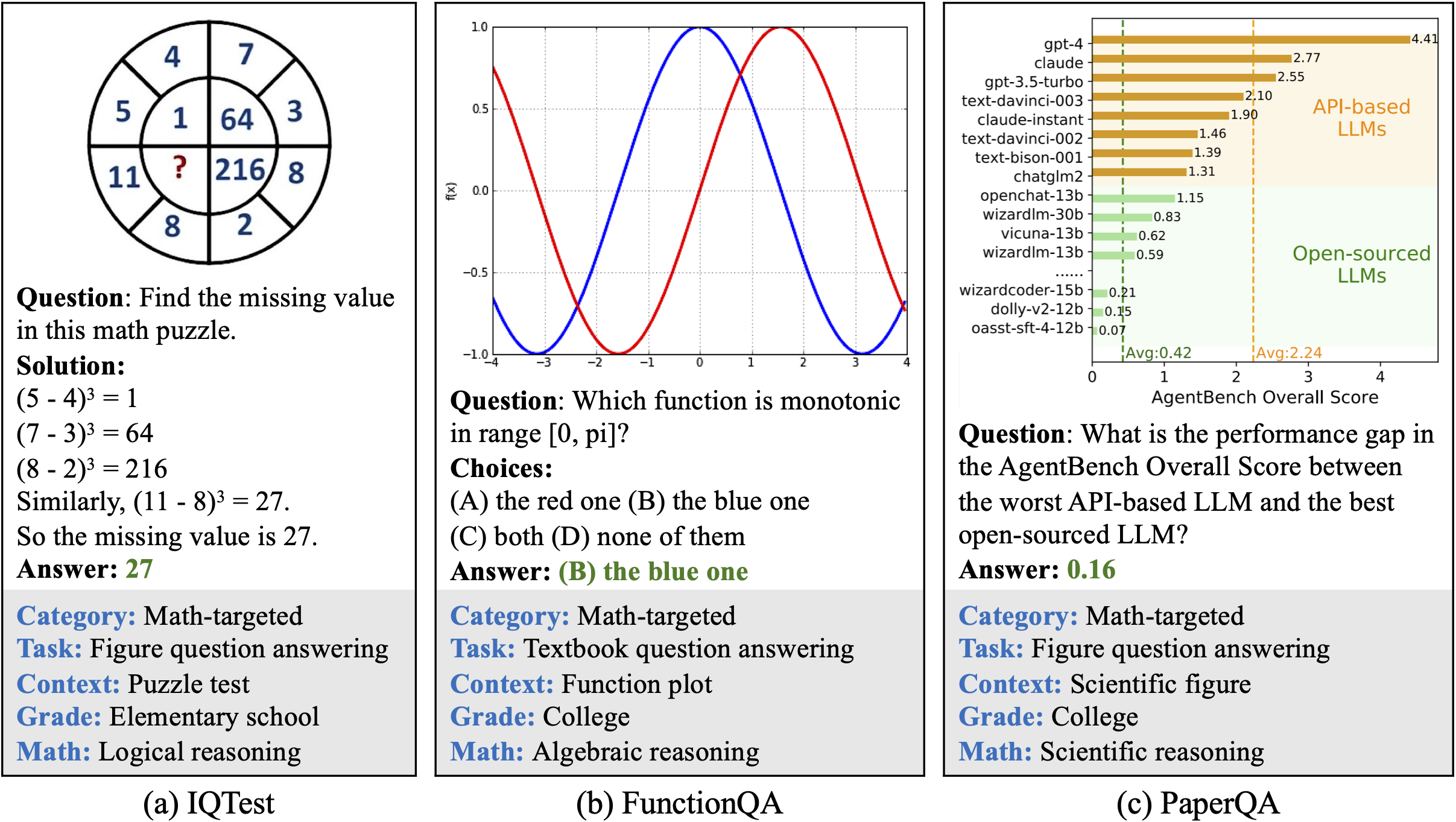
- AI4Math/MathVista数据集地址由微软AI4Math在ICLR 2024发布。总体包含6,141道题目,来自31个子数据集/源(28个已有数据集 + 新标注的3个:IQTest、FunctionQA、PaperQA)。
- MathVista分为:testmini(1,000例,用于模型开发/验证)和test(约5,141例,用于标准评测,且答案不公开)。
- 使用hf-mirror网站进行数据下载
bash
cd /root/autodl-fs/code/qwen3vl-gspo
sudo apt update
sudo apt install aria2
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
./hfd.sh AI4Math/MathVista --dataset- 在jupyter notebook中查看
python
from datasets import load_dataset
local_dataset_path = "/root/autodl-fs/code/qwen3vl-gspo/MathVista"
dataset = load_dataset(local_dataset_path, split = "testmini")
print(dataset)
js
Dataset({
features: ['pid', 'question', 'image', 'decoded_image', 'choices', 'unit', 'precision', 'answer', 'question_type', 'answer_type', 'metadata', 'query'],
num_rows: 1000
})- 数据清理和图像格式转化
python
from datasets import load_dataset
local_dataset_path = "/root/autodl-fs/code/qwen3vl-gspo/MathVista"
dataset = load_dataset(local_dataset_path, split = "testmini")
# 数据清理:只保留答案可转化为float(即数值答案)的数据,方便后续的强化学习使用和复杂奖励判定的设计。
def is_numeric_answer(example):
try:
float(example["answer"])
return True
except:
return False
dataset = dataset.filter(is_numeric_answer)
# 对图片进行统一尺寸和格式转换
'''
把图片统一到512×512的三通道RGB图像,减少视觉token占用上下文长度,确保模型能够正确读取图像格式。
'''
def resize_images(example):
image = example["decoded_image"]
image = image.resize((512, 512))
example["decoded_image"] = image
return example
dataset = dataset.map(resize_images)
def convert_to_rgb(example):
image = example["decoded_image"]
if image.mode != "RGB":
image = image.convert("RGB")
example["decoded_image"] = image
return example
dataset = dataset.map(convert_to_rgb)- 将数据转化为训练需要的结构化对话格式
- 多模态输入:将问题和图片设置在同一个消息中。
- 规范输出格式:
<REASONING>xxx</REASONING><SOLUTION>xxx</SOLUTION>。 - 适配具体模型的对话模版:用
tokenizer.apply_chat_template生成正确的 prompt 字符串。
- 最终对比解题的预测结果和数据集中的正确答案,计算奖励,进行策略更新。
python
# 定义分隔符变量
REASONING_START = "<REASONING>"
REASONING_END = "</REASONING>"
SOLUTION_START = "<SOLUTION>"
SOLUTION_END = "</SOLUTION>"
def make_conversation(example):
# 强格式化 Prompt,限制模型输出格式:任务说明和具体问题
text_content = (
f"{example['question']}. Also first provide your reasoning or working out"\
f" on how you would go about solving the question between {REASONING_START} and {REASONING_END}"
f" and then your final answer between {SOLUTION_START} and (put a single float here) {SOLUTION_END}"
)
# 多模态格式提示词
prompt = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": text_content},
],
},
]
return {"prompt": prompt, "image": example["decoded_image"], "answer": example["answer"]}
train_dataset = dataset.map(make_conversation)
# 重新格式化数据集,因为decoded_images才是实际的图像
# "image": example ["decoded_image"] 无法正确地对数据集进行格式化
# 1. 删除原始'image'列
train_dataset = train_dataset.remove_columns("image")
# 2. 重命名decoded_imageto 'image'
train_dataset = train_dataset.rename_column("decoded_image", "image")- 划分数据集
python
from datasets import DatasetDict
# train_dataset是整个可用数据,重命名避免误会
full_dataset = train_dataset
# 量划分,100条用作测试集
split_dataset = full_dataset.train_test_split(test_size=100, seed=42)
train_dataset = split_dataset["train"] # 用于 RL 训练
eval_dataset = split_dataset["test"] # 用于 baseline & 训练后测试
print("Train size:", len(train_dataset))
print("Eval size:", len(eval_dataset))- 使用tokenizer.apply_chat_template将对话结构转化为模型需要的字符串格式,包括token、角色标签、特殊image占位符。
python
train_dataset = train_dataset.map(
lambda example: {
"prompt": tokenizer.apply_chat_template(
example["prompt"],
tokenize = False,
add_generation_prompt = True,
)
}
)
eval_dataset = eval_dataset.map(
lambda example: {
"prompt": tokenizer.apply_chat_template(
example["prompt"],
tokenize = False,
add_generation_prompt = True,
)
}
)- Qwen-VL 官方标准模板
bash
<|im_start|>user
<image>
题目内容 + 指令 + 标签说明
<|im_end|>
<|im_start|>assistant- Tip: RL Debugging 必要性 :在强化学习实验中,务必显式打印(
print)或检查(inspect)中间数据(如观测值、动作、奖励、Q值等)。由于 RL 训练过程的高随机性,缺乏数据可视化会导致模型发散时,难以定位具体出错环节。
python
print(train_dataset[0]["prompt"])
bash
<|im_start|>user
<|vision_start|><|image_pad|><|vision_end|>As shown in the figure, in the diamond ABCD, ∠BAD = 120.0, the length of the diagonal AC is 3.0, then the perimeter of the diamond ABCD is ().
Also first provide your reasoning or working out on how you would go about solving the question between <REASONING> and </REASONING>
and then your final answer between <SOLUTION> and (put a single float here)
</SOLUTION><|im_end|>
<|im_start|>assistant三 奖励函数的设置
- 奖励分为格式奖励和正确性奖励。
python
# Format Reward functions
import re
FORMAT_WEIGHT = 0.3
def formatting_reward_func(completions,**kwargs):
thinking_pattern = f'{REASONING_START}(.*?){REASONING_END}'
answer_pattern = f'{SOLUTION_START}(.*?){SOLUTION_END}'
scores = []
for completion in completions:
score = 0
thinking_matches = re.findall(thinking_pattern, completion, re.DOTALL)
answer_matches = re.findall(answer_pattern, completion, re.DOTALL)
if len(thinking_matches) == 1:
score += 1.0
if len(answer_matches) == 1:
score += 1.0
# Fix up addCriterion issues
# See https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide/vision-reinforcement-learning-vlm-rl
if len(completion) != 0:
removal = completion.replace("addCriterion", "").replace("\n", "")
if (len(completion)-len(removal))/len(completion) >= 0.5:
score -= 2.0
scores.append(FORMAT_WEIGHT *score)
return scores- 检查模型输出内容格式是否正确,如果推理和结果回答过程只出现一次,给得1分,否则不加分,对模型疯狂重复输出某个词问题,如果占比超过
50%就-2分。
- 正确性奖励
python
# Correctness Reward functions
CORRECT_WEIGHT = 1.0
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
answer_pattern = f'{SOLUTION_START}(.*?){SOLUTION_END}'
responses = [re.findall(answer_pattern, completion, re.DOTALL) for completion in completions]
q = prompts[0]
print('-' * 20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:{completions[0]}")
def to_number(x: str):
try:
return float(x.strip())
except Exception:
return None
def score_one(r, a) -> float:
# r 是当前样本里提取到的所有答案片段列表,a 是标准答案
if len(r) != 1:
return 0.0
pred_text = r[0].replace('\n', '').strip()
gold_text = a.strip()
# 字符串完全相同 → 2 分
if pred_text == gold_text:
base = 2.0
# 字符串不相等,但数值等价(比如 3 vs 3.0)→ 1.5 分
pred_num = to_number(pred_text)
gold_num = to_number(gold_text)
if (
pred_num is not None
and gold_num is not None
and abs(pred_num - gold_num) < 1e-8
):
base = 1.5
else:
# 其他情况 → 0 分
base = 0.0
return CORRECT_WEIGHT * base
return [score_one(r, a) for r, a in zip(responses, answer)]四 模型下载和运行测试
-
在基础base环境安装modelscope,并下载
Qwen3-VL-8B-Instruct-unsloth-bnb-4bit模型。bashpip install modelscope mkdir -p /root/autodl-fs/models/unsloth modelscope download --model unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit --local_dir /root/autodl-fs/models/unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit- Qwen3-VL-8B-Instruct是Qwen3 系列,8B 参数的视觉语言指令模型,VL表明模型具有理解图片内容的能力,同时Instruct表明该模型已经经过指令调优,适合对话类型的任务。
- unsloth-bnb-4bit表示经过Unsloth格式和加速适配,使用 bitsandbytes 4比特量化,占用显存显著降低,非常适合在GPU资源有限的情况下,进行LoRA微调。
-
运行jupyter lab,新建notebook文件,选择qwen3vl-gspo内核。
pythonimport unsloth from unsloth import FastVisionModel max_seq_length = 16384 lora_rank = 16 # ✅ 使用本地模型路径 local_model_dir = ( "/root/autodl-fs/models/unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit" ) model, tokenizer = FastVisionModel.from_pretrained( model_name=local_model_dir, # 使地路径 max_seq_length=max_seq_length, # 超长序列长度 兼顾图像信息和解题过程 load_in_4bit=True, # 用 4bit 量化加载基础模型权重 fast_inference=False, # 关闭加速推理 gpu_memory_utilization=0.8, # 最多使用80%显存布置权重和缓存,发生OOM,可调小占比 local_files_only=True, # 强制只使用本地文件 )
- 超长序列长度:
max_seq_length = 16384。将序列长度设置为16K,保证模型可以输入完整的图像和推理过程。 - 视觉语言模型的输入包括视觉 token和语言token。
- lora_rank的秩越大,可学习的参数越多,拟合能力更强。
- 在Unsloth中,推理部分使用vLLM,两者共享模型权重,极大降级显存占用。本次实验为了借助vLLM节省显存仅在语言层上挂在LoRA,奖励和GSPO仍然基于看图解题的行为进行优化。
五 训练前推理
- 随机选取数据集中的第80条数据,测试原始模型的表现。
python
image = train_dataset[80]["image"]
prompt = train_dataset[90]["prompt"]
inputs = tokenizer(
image,
prompt,
add_special_tokens = False,
return_tensors = "pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1024,
use_cache = True, temperature = 1.0, min_p = 0.1)- 输出结果可以表明,模型成功遵守格式要求,生成了完整的推理链,并最终给出了答案,说明即使没有经过强化学习,模型也具备一定视觉推理能力。
python
# 对测试集做推理评估
import re
import torch
from tqdm.auto import tqdm
def extract_solution(completion: str):
"""
从模型生成的 completion 中抓取 <SOLUTION> ... </SOLUTION> 部分,
返回去掉换行的字符串;如果格式不对则返回 None。
"""
pattern = f"{SOLUTION_START}(.*?){SOLUTION_END}"
matches = re.findall(pattern, completion, re.DOTALL)
if len(matches) != 1:
return None
return matches[0].replace("\n", "").strip()
python
# "详细评估函数",返回每条样本的结果
@torch.no_grad()
def evaluate_with_details(dataset, model, tokenizer, max_new_tokens=512, device="cuda"):
model.eval()
records = []
for idx, example in enumerate(tqdm(dataset, desc="Evaluating")):
image = example["image"]
prompt = example["prompt"]
gold = str(example["answer"])
inputs = tokenizer(
image,
prompt,
add_special_tokens=False,
return_tensors="pt",
).to(device)
# 生成
output_ids = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=1.0,
min_p=0.1,
use_cache=True,
)
# 只取"新生成"的部分(去掉 prompt 部分)
gen_ids = output_ids[0, inputs["input_ids"].shape[1]:]
completion = tokenizer.decode(gen_ids, skip_special_tokens=False)
pred = extract_solution(completion)
format_ok = pred is not None
is_correct = format_ok and (pred == gold)
records.append({
"idx": idx,
"gold": gold,
"pred": pred,
"correct": is_correct,
"format_ok": format_ok,
"prompt": prompt,
"completion": completion,
})
return records
python
# 训练前在eval_dataset上跑baseline
baseline_records = evaluate_with_details(
eval_dataset,
model,
tokenizer,
max_new_tokens=512,
device="cuda",
)
# 统计 baseline 指标
total = len(baseline_records)
correct = sum(r["correct"] for r in baseline_records)
format_ok = sum(r["format_ok"] for r in baseline_records)
print(f"[Baseline] Eval samples = {total}")
print(f"[Baseline] Accuracy = {correct / total:.3f}")
print(f"[Baseline] Format rate = {format_ok / total:.3f}")
bash
[Baseline] Eval samples = 100
[Baseline] Accuracy = 0.060
[Baseline] Format rate = 0.780
python
# 保存基准测试结果
import json
import os
# 获取当前工作目录的绝对路径,确保文件保存位置准确
current_dir = os.getcwd()
save_path = os.path.join(current_dir, "baseline_records.json")
print(f"准备保存文件至: {save_path}")
# 保存基准测试结果
with open(save_path, "w", encoding='utf-8') as f:
json.dump(baseline_records, f, indent=4, ensure_ascii=False)
print(f"✅ baseline_records 已保存至当前目录: {os.path.basename(save_path)}")六 模型强化学习训练
bash
!pip install tensorboard
python
from unsloth import FastVisionModel
import torch
from trl import GRPOConfig, GRPOTrainer
max_seq_length = 16384
lora_rank = 16
# ✅ 使用本地模型路径
local_model_dir = (
"/root/autodl-fs/models/unsloth/Qwen3-VL-8B-Instruct-unsloth-bnb-4bit"
)
model, tokenizer = FastVisionModel.from_pretrained(
model_name=local_model_dir, # 模型路径
max_seq_length=max_seq_length, # 超长序列长度 兼顾图像信息和解题过程
load_in_4bit=True, # 用 4bit 量化加载基础模型权重
fast_inference=False, # 关闭加速推理
gpu_memory_utilization=0.8, # 最多使用80%显存布置权重和缓存,发生OOM,可调小占比
local_files_only=True, # 强制只使用本地文件
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = False, # 不微调视觉层
finetune_language_layers = True, # 微调语言层
finetune_attention_modules = True, # 微调注意力层
finetune_mlp_modules = True, # 微调MLP层(前馈网络)
r = 16, # 越大学习越细化,但也容易过拟合和消耗显存
lora_alpha = 16, # 缩放因子alpha 通常 ≥ r
lora_dropout = 0, # 表示不过滤。如果数据少、容易过拟合,设置小数值(如 0.05)
bias = "none", # 不对bias做可训练更新,减少可训练参数。
random_state = 666, # 随机种子
use_rslora = False, # 保持训练稳定
loftq_config = None, # 量化+LoRA 结合策略
use_gradient_checkpointing = "unsloth",
)
training_args = GRPOConfig(
learning_rate = 5e-6, # 低学习率 保证不破坏模型原始能力
adam_beta1 = 0.9, # 标准AdamW超参,偏向稳定更新
adam_beta2 = 0.99, # 标准AdamW超参,偏向稳定更新
weight_decay = 0.1, # 较强的L2正则,防止 LoRA 参数过拟合
warmup_ratio = 0.1, # 前10%的step做warmup,学习率从0慢慢升到目标值
lr_scheduler_type = "cosine", # 训练中后期用余弦衰减,让学习率平滑下降
optim = "adamw_8bit", # 8bit AdamW(来自 bitsandbytes)为节省显存,适合在单卡上做RL
# 训练日志&batch 设置
logging_steps = 1, # 每一步都log
log_completions = False, # 不每次都打印完整生成
per_device_train_batch_size = 8, # 每块GPU上 一次前向+反向传播实际放进去8个样本
gradient_accumulation_steps = 4, # 不做梯度累积(后面可以改大平滑训练)
num_generations = 4, # 每条Prompt生成4个不同的completion
# 序列长度 & 训练时间
max_prompt_length = 1024, # 问题中的问题prompt最大值
max_completion_length = 1024, # 模型响应的最长token限制
num_train_epochs = 1, # 训练一轮
# max_steps = 60, # 用step控制训练长度,可以改成显式的max_steps
save_steps = 60, # 每60 step保存一次checkpoint
max_grad_norm = 0.1, # 梯度裁剪,防止RL中reward波动导致梯度爆炸
report_to = "tensorboard", # 可以使用tensorboard,但是不兼容wandb
# 必须显式指定日志目录,通常放在输出目录下的 runs 文件夹
logging_dir = "outputs/runs", # 模型权重与日志的输出目录
output_dir = "outputs",
# GSPO配置
importance_sampling_level = "sequence", # 整条响应(完整思维链 + 答案)作为一个整体来算重要性比
mask_truncated_completions = False, # 不截断生成,让所有生成参与计算
loss_type = "dr_grpo", # 带Doubly-Robust修正的GSPO损失
)
trainer = GRPOTrainer(
model = model,
args = training_args,
# 传递处理器以处理多模态输入
processing_class = tokenizer,
reward_funcs = [
formatting_reward_func,
correctness_reward_func,
],
train_dataset = train_dataset,
)
trainer.train()
bash
pip install matplotlib
python
import matplotlib.pyplot as plt
# 提取奖励日志
steps, rewards = [], []
for log in trainer.state.log_history:
if "reward" in log:
steps.append(log["step"])
rewards.append(log["reward"])
# 平滑处理
import numpy as np
window = 10
rewards_smooth = np.convolve(rewards, np.ones(window)/window, mode='valid')
plt.figure(figsize=(8, 5))
plt.plot(steps, rewards, alpha=0.3, label="Raw Reward")
plt.plot(steps[:len(rewards_smooth)], rewards_smooth, label=f"Smoothed Reward ({window}-step MA)", linewidth=2)
plt.xlabel("Training Steps")
plt.ylabel("Reward")
plt.title("Reward Trend During VLM GSPO Finetuning")
plt.grid(True)
plt.legend()
plt.show()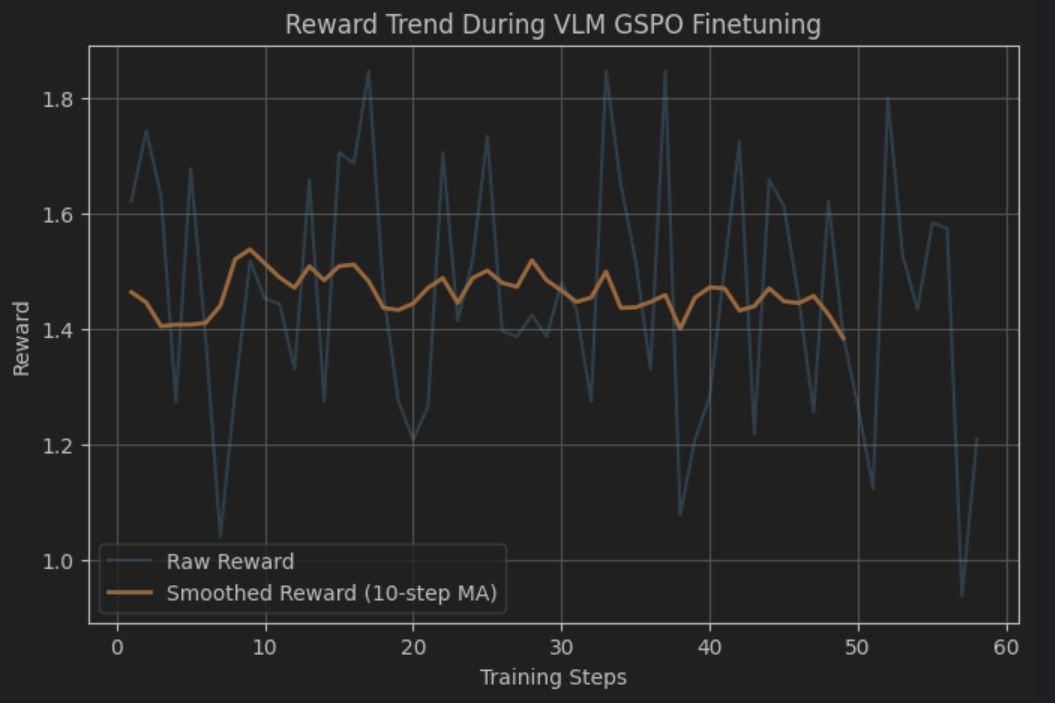
七 训练后推理
- 通过验证输出格式合规性、图像推理与答案准确性、推理链的简洁稳定性以及是否消除异常 token,来确认模型是否真正学到了奖励机制强化的行为。
- 随机选择一条测试样例,再次调用tokenizer,将视觉和文本一起编码。
python
image = train_dataset[450]["image"]
prompt = train_dataset[450]["prompt"]
inputs = tokenizer(
image,
prompt,
add_special_tokens = False,
return_tensors = "pt",
).to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt = True)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 1024,use_cache = True, temperature = 1.0, min_p = 0.1)- 训练后验证集评估
python
after_records = evaluate_with_details(
eval_dataset,
model,
tokenizer,
max_new_tokens=512,
device="cuda",
)
total = len(after_records)
correct = sum(r["correct"] for r in after_records)
format_ok = sum(r["format_ok"] for r in after_records)
print(f"[After RL] Eval samples = {total}")
print(f"[After RL] Accuracy = {correct / total:.3f}")
print(f"[After RL] Format rate = {format_ok / total:.3f}")
python
[After RL] Eval samples = 100
[After RL] Accuracy = 0.060
[After RL] Format rate = 0.830
python
# 保存训练后测试结果
import json
import os
# 获取当前工作目录的绝对路径,确保文件保存位置准确
current_dir = os.getcwd()
save_path = os.path.join(current_dir, "after_records.json")
print(f"准备保存文件至: {save_path}")
# 保存基准测试结果
with open(save_path, "w", encoding='utf-8') as f:
json.dump(baseline_records, f, indent=4, ensure_ascii=False)
print(f"✅ after_records 已保存至当前目录: {os.path.basename(save_path)}")八 保存LoRA参数和模型
- 检查lora参数是否被训练。
python
# 验证 LoRA 是否真正被训练
# 如果整个矩阵全是 0,说明LoRA根本没训练成功(毫无变化)。只有不为 0,才说明学习成功
from safetensors import safe_open
tensors = {}
print("开始检查 LoRA 权重...\n")
with safe_open("gspo_lora/adapter_model.safetensors", framework="pt", device="cpu") as f:
for key in f.keys():
tensor = f.get_tensor(key)
# 计算统计信息
total_elements = tensor.numel()
n_zeros = (tensor == 0).sum().item()
# 计算非零比例
non_zero_ratio = (total_elements - n_zeros) / total_elements * 100
# 计算绝对值的均值(用来看看权重的量级,如果非常小可能接近没训练)
mean_abs_val = tensor.abs().mean().item()
print(f"Layer: {key}")
print(f" 总参数量: {total_elements:,}")
print(f" 零值数量: {n_zeros:,} ({n_zeros/total_elements*100:.2f}%)")
print(f" 非零比例: {non_zero_ratio:.2f}%")
print(f" 平均绝对值: {mean_abs_val:.6f}")
print("-" * 40)
# 安全检查:防止全0(虽然大概率不会触发)
assert n_zeros != total_elements, f"❌ 警告:{key} 的权重全是 0!"
print("\n✅ 检查完成:所有 LoRA 层均包含非零权重,训练有效。")- 把当前模型训练出的 LoRA 权重保存在本地。
python
# 保存lora
model.save_pretrained("gspo_lora")
tokenizer.save_pretrained("gspo_lora")- 上面保存的lora参数不是完整的模型。LoRA 训练后需与基础模型合并并导出为指定精度(如float16、int4),便于vLLM、LM Studio、Ollama 等推理框架部署。
- Unsloth 支持
merged_16bit、merged_4bit或保留lora适配器。
- Unsloth 支持
python
model.save_pretrained_merged("/root/autodl-fs/models/unsloth/qwen3vl-gspo-16bit", tokenizer, save_method = "merged_16bit",)
model.save_pretrained_merged("/root/autodl-fs/models/unsloth/qwen3vl-gspo-4bit", tokenizer, save_method = "merged_4bit_forced",)九 日志查看
bash
tensorboard --logdir=./outputs --port 6008