👨🎓博主简介
💊交流社区: 运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
文章目录
- 前言
- 〇、PromQL介绍
- [一、PromQL node_exporter常用内置指标](#一、PromQL node_exporter常用内置指标)
-
- [1.1 CPU · 负载 · 内存 · 进程](#1.1 CPU · 负载 · 内存 · 进程)
- [1.2 磁盘 · 文件系统 · 描述符](#1.2 磁盘 · 文件系统 · 描述符)
- [1.3 网络](#1.3 网络)
- [1.4 systemd 服务](#1.4 systemd 服务)
- [1.5 系统 · 内核](#1.5 系统 · 内核)
- [1.6 Exporter 自身](#1.6 Exporter 自身)
- [1.7 写 PromQL 的万能公式](#1.7 写 PromQL 的万能公式)
- [1.8 其他应用层](#1.8 其他应用层)
- 二、数据类型
-
- [2.1 Instant vector 瞬时向量](#2.1 Instant vector 瞬时向量)
- [2.2 Range vector 区间向量](#2.2 Range vector 区间向量)
-
- [2.2.1 时间持续(Time Durations)](#2.2.1 时间持续(Time Durations))
- [2.2.2 偏移量修饰符(Offset modifier)](#2.2.2 偏移量修饰符(Offset modifier))
- [2.2.3 @ 修饰符](#2.2.3 @ 修饰符)
- [2.3 Scalar vector 简单向量](#2.3 Scalar vector 简单向量)
- 三、条件匹配
-
- [3.1 普通匹配](#3.1 普通匹配)
- [3.2 正则匹配](#3.2 正则匹配)
- 四、运算符
-
- [4.1 比较运算符](#4.1 比较运算符)
- [4.2 算术运算符](#4.2 算术运算符)
- [4.3 逻辑运算符](#4.3 逻辑运算符)
- [4.4 聚合运算符(聚合函数)](#4.4 聚合运算符(聚合函数))
-
- [4.4.1 sum:求和](#4.4.1 sum:求和)
- [4.4.2 count:计数](#4.4.2 count:计数)
- [4.4.3 max:求最大值](#4.4.3 max:求最大值)
- [4.4.4 min:求最小值](#4.4.4 min:求最小值)
- [4.4.5 avg:求平均值](#4.4.5 avg:求平均值)
- [4.4.6 topk:取前面几个较大值](#4.4.6 topk:取前面几个较大值)
- [4.4.7 bottomk:取后面几个较小值](#4.4.7 bottomk:取后面几个较小值)
- [4.5 匹配运算](#4.5 匹配运算)
-
- [4.5.1 on:关联标签](#4.5.1 on:关联标签)
- [4.5.2 ignoring:忽略标签](#4.5.2 ignoring:忽略标签)
- [4.5.3 by:以某一个标签进行计算](#4.5.3 by:以某一个标签进行计算)
- [4.5.4 without:舍弃某个标签进行计算](#4.5.4 without:舍弃某个标签进行计算)
- 五、函数
-
- [5.1 速率函数](#5.1 速率函数)
-
- [5.1.1 increase:区间内总增长量](#5.1.1 increase:区间内总增长量)
- [5.1.2 rate:每秒平均增长率](#5.1.2 rate:每秒平均增长率)
- [5.1.3 irate:每秒瞬时增长率](#5.1.3 irate:每秒瞬时增长率)
- [5.2 区间函数(包含速率函数)](#5.2 区间函数(包含速率函数))
-
- [5.2.1 predict_linear 预测指标](#5.2.1 predict_linear 预测指标)
- [5.3 取整函数](#5.3 取整函数)
-
- [5.3.1 ceil:向上取整](#5.3.1 ceil:向上取整)
- [5.3.2 floor:向下取整](#5.3.2 floor:向下取整)
- [5.3.3 round:四舍五入](#5.3.3 round:四舍五入)
- [5.3.4 三者的区别](#5.3.4 三者的区别)
- [5.4 排序函数](#5.4 排序函数)
-
- [5.4.1 sort:正向排序(升序)](#5.4.1 sort:正向排序(升序))
- [5.4.2 sort_desc:逆向排序(降序)](#5.4.2 sort_desc:逆向排序(降序))
- [5.5 其他函数](#5.5 其他函数)
-
- [5.5.1 abs:求绝对值](#5.5.1 abs:求绝对值)
- [5.5.2 absent:是否存在](#5.5.2 absent:是否存在)
- [5.5.3 absent_over_time:过去是否存在](#5.5.3 absent_over_time:过去是否存在)
- [5.6 函数总结](#5.6 函数总结)
- 参考文档
前言
Promethues是目前一个比较流行的开源监控项目,被使用也越来越多。我们都知道Prometheus是通过时序数据库来保存数据的,那么Prometheus采集到数据后,是如何保存在自已的时序数据库中的呢? 通常我们看到Prometheus的数据指标都类似这样:node_cpu_seconds_total{cpu="0",instance="172.16.11.230:9100",job="agent",mode="system"},可以看到它是通过指标名称(metrics name)以及对应的一组标签(labelset)来唯一标识一条时间序列。那么如何对这种数据进行筛选查询、四则运算、聚合运算,以实现我们想要绘制的指标监控数据,就需要用到下面将要讲到的PromeQL了。
〇、PromQL介绍
Prometheus提供了一种称为PromQL(Prometheus Query Language)的功能性查询语言,让用户可以实时选择和聚合时间序列数据。
在Prometheus默认的浏览器中,表达式的结果既可以显示为图形,也可以以表格数据的形式显示,或者由外部系统通过HTTP API使用。
PromeQL在很多地方都会被用到,在Prometheus UI界面搜索监控指标时会用到,在Alertmanager配置告警时也会用到,在Grafana配置监控展示的时候也会用到。
下面在讲解的过程中,使用到了很多例子,可能部分例子在真实的监控环境中并没有具体的实际含义,仅仅是为了进行演示,便于理解学习。因为在实际的生产环境中,要得到一些目标监控值,是要综合多个运算符或者函数来实现的。
一、PromQL node_exporter常用内置指标
1.1 CPU · 负载 · 内存 · 进程
| 指标 | 一句话说明 | 单位 |
|---|---|---|
node_cpu_seconds_total |
各核各模式累计时长 | 秒 |
node_load1 / node_load5 / node_load15 |
1、5、15 分钟系统平均负载 | 无(纯数值) |
node_memory_MemAvailable_bytes |
可用内存大小 | 字节 |
node_memory_MemTotal_bytes |
总内存大小 | 字节 |
node_memory_MemFree_bytes |
完全空闲内存(不含缓存) | 字节 |
node_memory_Cached_bytes |
页缓存(含 tmpfs) | 字节 |
node_memory_Buffers_bytes |
块设备缓存 | 字节 |
node_memory_Slab_bytes |
内核 slab 占用 | 字节 |
node_pressure_cpu_waiting_seconds_total |
CPU 调度延迟 | 秒 |
node_processes |
当前进程数 | 无 |
node_processes_state |
各状态进程数量计数(R/S/Z...) | 无 |
node_processes_threads |
系统线程数 | 个 |
node_vmstat_oom_kill |
OOM 杀死次数 | 次 |
1.2 磁盘 · 文件系统 · 描述符
| 指标 | 一句话说明 | 单位 |
|---|---|---|
node_filesystem_size_bytes |
分区总大小 | 字节 |
node_filesystem_avail_bytes |
分区可用空间 | 字节 |
node_disk_read_bytes_total |
磁盘累计读取字节 | 字节 |
node_disk_write_bytes_total |
磁盘累计写入字节 | 字节 |
node_disk_io_now |
当前磁盘 I/O 请求数 | 个 |
node_disk_io_time_seconds_total |
磁盘繁忙累计时长 | 秒 |
node_disk_io_time_weighted_seconds_total |
加权繁忙时长 | 秒 |
node_pressure_io_stall_seconds_total |
IO 阻塞累计 | 秒 |
node_filesystem_files_free |
inode 剩余量 | 个 |
node_disk_writes_completed_total |
磁盘写完成次数 | 次 |
node_disk_reads_completed_total |
磁盘读完成次数 | 次 |
node_disk_read_time_seconds_total |
读耗时累计 | 秒 |
node_disk_write_time_seconds_total |
写耗时累计 | 秒 |
node_filefd_allocated |
已分配文件描述符个数 | 个 |
node_filefd_maximum |
系统最大文件描述符数 | 个 |
node_filesystem_readonly |
文件系统只读标志 | 无(1/0) |
node_disk_discards_completed_total |
SSD TRIM/Discard 次数 | 次 |
node_disk_discarded_sectors_total |
SSD 被丢弃扇区数 | 扇区 |
1.3 网络
| 指标 | 一句话说明 | 单位 |
|---|---|---|
node_network_receive_bytes_total |
网卡累计接收量 | 字节 |
node_network_transmit_bytes_total |
网卡累计发送量 | 字节 |
node_network_receive_packets_total |
累计收包数 | 个 |
node_network_transmit_packets_total |
累计发包数 | 个 |
node_network_receive_errs_total |
接收错包累计 | 次 |
node_network_transmit_errs_total |
发送错包累计 | 次 |
node_network_receive_drop_total |
接收丢包累计 | 次 |
node_network_transmit_drop_total |
发送丢包累计 | 次 |
node_netstat_Tcp_CurrEstab |
TCP连接数 | 个 |
node_netstat_Tcp_RetransSegs |
TCP 重传段累计数 | 次 |
node_network_up |
网卡是否在线 | 无(1/0) |
node_network_speed_bytes |
网卡协商速率(单位 byte/s,0=down/unknown) | 字节/秒 |
node_network_mtu_bytes |
接口 MTU 大小 | 字节 |
1.4 systemd 服务
| 指标 | 一句话说明 | 单位 |
|---|---|---|
node_systemd_unit_state |
每个 systemd 单元在各个状态(active/failed/inactive... | 无(0/1) |
node_systemd_system_running |
systemd 是否运行 | 0/1 |
1.5 系统 · 内核
| 指标 | 一句话说明 | 单位 |
|---|---|---|
node_boot_time_seconds |
系统启动时间 | 秒(Unix 时间戳) |
node_temperature_celsius |
主板/CPU 温度 | ℃ |
node_hwmon_fan_rpm |
风扇转速 | RPM |
node_processes_pids_limit |
系统最大 PID 数 | 无 |
node_context_switches_total |
上下文切换次数 | 次 |
node_forks_total |
进程创建次数 | 次 |
1.6 Exporter 自身
| 指标 | 一句话说明 | 单位 |
|---|---|---|
up |
目标是否存活 | 无(1/0) |
scrape_duration_seconds |
单次采集耗时 | 秒 |
scrape_samples_scraped |
本次采到的样本条数 | 无 |
scrape_samples_post_metric_relabeling |
relabel 后剩余样本数 | 无 |
scrape_series_added |
新增时间序列数 | 无 |
node_exporter_build_info |
node_exporter 版本信息 | 无 |
prometheus_build_info |
Prometheus 版本信息 | 无 |
1.7 写 PromQL 的万能公式
- 不使用函数可以不带
();不是函数的例如:数据类型、条件匹配、比较、算法、逻辑运算; - 使用函数必须带
(),否则会报错;
sql
# 单层骨架
<函数>(<指标名>{<标签过滤>}[<范围>]) <比较符> <阈值>
# 左右对比、关联骨架
<函数>(<指标名>{<标签过滤>}[<范围>]) <比较符> <阈值> <算数、逻辑、匹配运算符> <函数>(<指标名>{<标签过滤>}[<范围>]) <比较符> <阈值>
# 嵌套双层函数
<函数>(<函数>(<指标名>{<标签过滤>}[<范围>])) <比较符> <阈值>各部分含义与可选值速查:
| 占位 | 可选内容 | 速记 |
|---|---|---|
| 函数 | rate increase sum avg max topk count ... |
先聚合再算率 |
| 指标 | node_cpu_seconds_total container_memory_working_set_bytes ... |
_exporter 里抄 |
| 标签过滤 | {instance="web-01",mode="user"} {} 表示全要 |
精准定位 |
| 范围 | [1m] [5m] [1h] |
小于 2 倍 scrape_interval 会失真 |
| 比较符 | > >= < <= == != |
告警用 > 最多 |
| 阈值 | 0.8 1024*1024*1024 80 |
单位与指标一致 |
| 算数、逻辑运算符 | + - * / and or unless |
计算常用 |
例子:
- CPU 使用率 > 80%
sql
100 - avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100 > 80- 容器内存 > 2 Gi
sql
container_memory_working_set_bytes{name="my-app"} / 1024 / 1024 / 1024 > 2- API QPM 环比下跌 30%
sql
rate(http_requests_total[1m]) < 0.7 * rate(http_requests_total[1m] offset 1h)- 1 分钟内网卡收包速率 > 50 MB/s 就报警
sql
rate(node_network_receive_bytes_total{device!="lo"}[1m]) > 50*1024*1024记住顺序:先聚合→再速率→再比较,永远套得上!
1.8 其他应用层
其他应用层常用指标可参考:【云原生】PromQL 常用内置指标
二、数据类型
在Prometheus的表达式语言中,表达式或子表达式的计算结果可以为四种类型之一:
- Instant vector - 瞬时向量:一组时间序列,每个时间序列包含一个样本,都共享相同的时间戳;
- Range vector - 区间向量:一组时间序列,其中包含每个时间序列随时间变化的一系列数据点;
- Scalar vector - 简单向量:一个简单的数字浮点值;
2.1 Instant vector 瞬时向量
简单理解:瞬时向量 表示的是在当前时刻的数据。
示例:查询cpu的使用时间
sql
node_cpu_seconds_total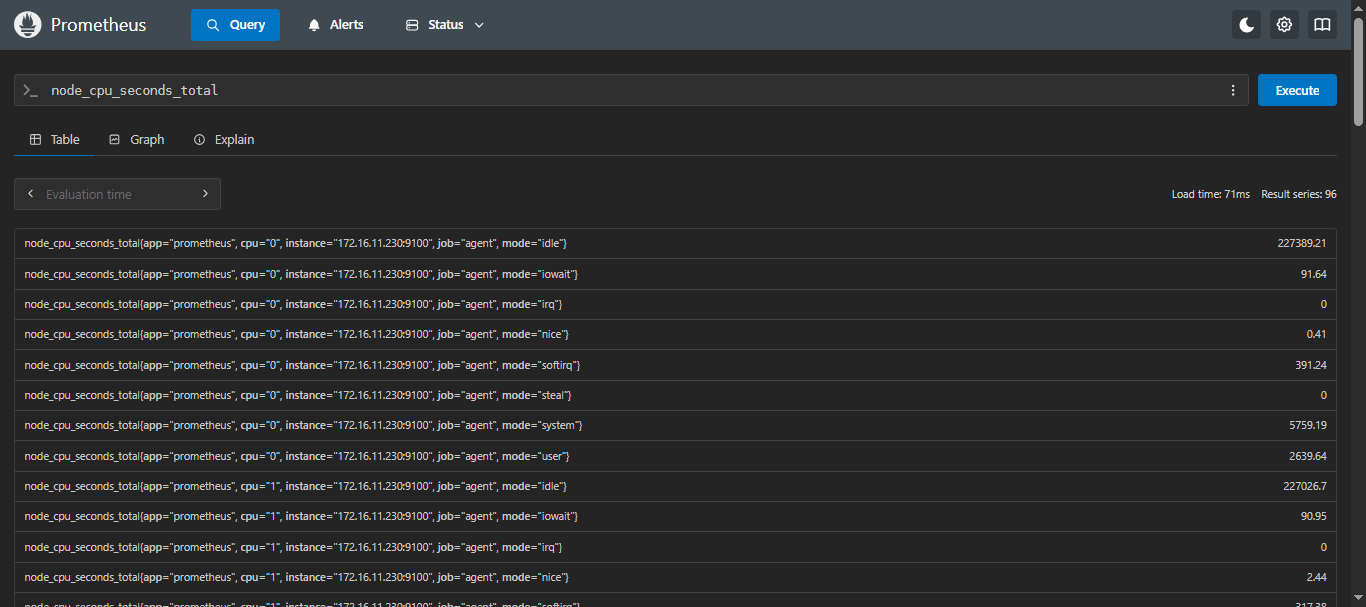
在这个例子中,你可以看到每个 CPU 核心的使用情况,每个核心都有用户态(
mode="user")、系统态(mode="system")和空闲态(mode="idle")的 CPU 时间等等。
mode 标签 |
含义 |
|---|---|
| user | 用户态时间,非操作系统内核的进程所占用的 CPU 时间。 |
| system | 系统态时间,操作系统内核进程所占用的 CPU 时间。 |
| idle | 空闲态时间,CPU 空闲等待任务的时间。 |
| iowait | 等待 I/O 操作完成的时间,CPU 因等待磁盘或网络 I/O 而空闲。 |
| irq | 硬中断处理时间,CPU 处理硬件中断请求所花费的时间。 |
| softirq | 软中断处理时间,CPU 处理软件中断请求所花费的时间。 |
| steal | 虚拟机偷取时间,在虚拟化环境中,虚拟机等待物理 CPU 的时间。 |
| guest | 客户机时间,CPU 在运行虚拟机客户操作系统的时间。 |
| guest_nice | 客户机 nice 时间,CPU 在运行虚拟机客户操作系统的 nice 进程时间。 |
使用场景
- 监控当前 CPU 使用情况:了解系统当前的 CPU 负载。
- 构建仪表板:在 Grafana 仪表板中显示实时 CPU 使用情况。
- 告警规则:设置基于 CPU 使用率的告警规则。
2.2 Range vector 区间向量
区间向量表示的是在某一个时间范围内的数据,可以分为以下几种:
- 时间持续(Time Durations)
- 偏移量修饰符(Offset modifier)
- @ 修饰符
下面来详细讲解。。。
2.2.1 时间持续(Time Durations)
时间持续用于指定查询的时间范围。PromQL 支持以下时间单位:
ms:毫秒s:秒m:分钟h:小时d:天w:周y:年
示例:查询 CPU 在过去 1 分钟内的使用时间
sql
node_cpu_seconds_total[1m]查询结果解析: 返回过去 1 分钟内,每 15 秒一个数据点的 CPU 使用时间序列,也就是每个指标有4个值。
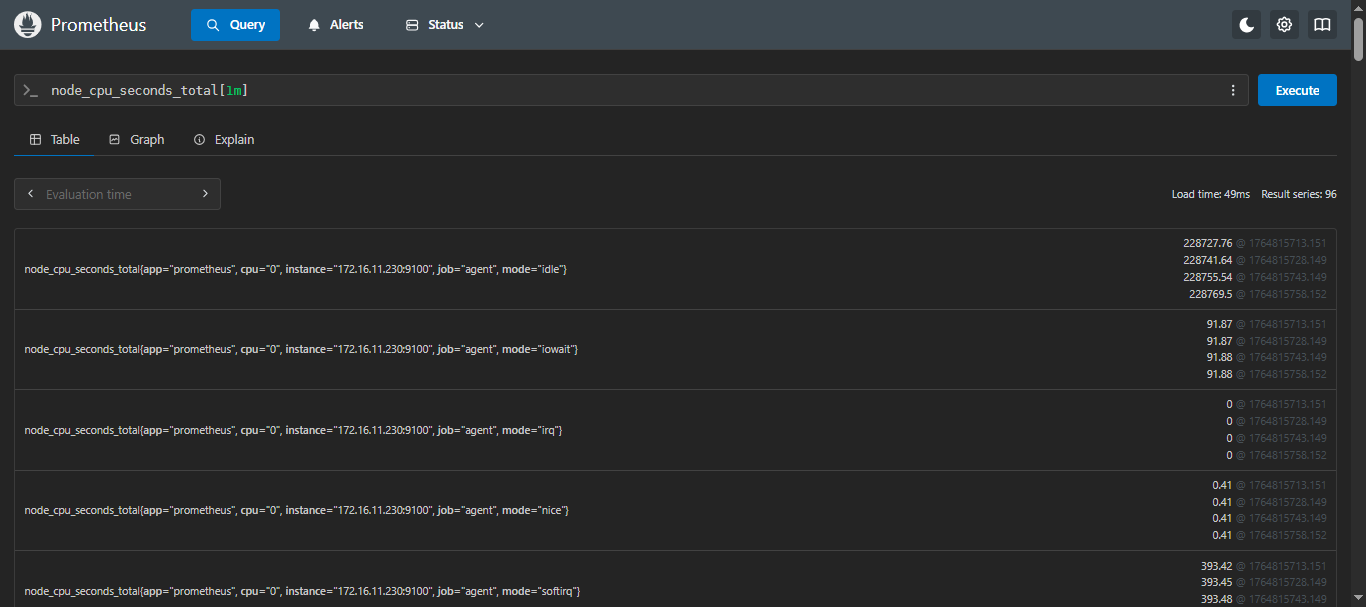
2.2.2 偏移量修饰符(Offset modifier)
偏移量修饰符用于将查询的时间范围向前或向后偏移指定的时间量。
示例:查询 CPU 在 5 分钟前的使用时间
sql
node_cpu_seconds_total offset 5m查询结果解析: 返回 5 分钟前开始,到当前时间为止,每 15 秒一个数据点的 CPU 使用时间序列。
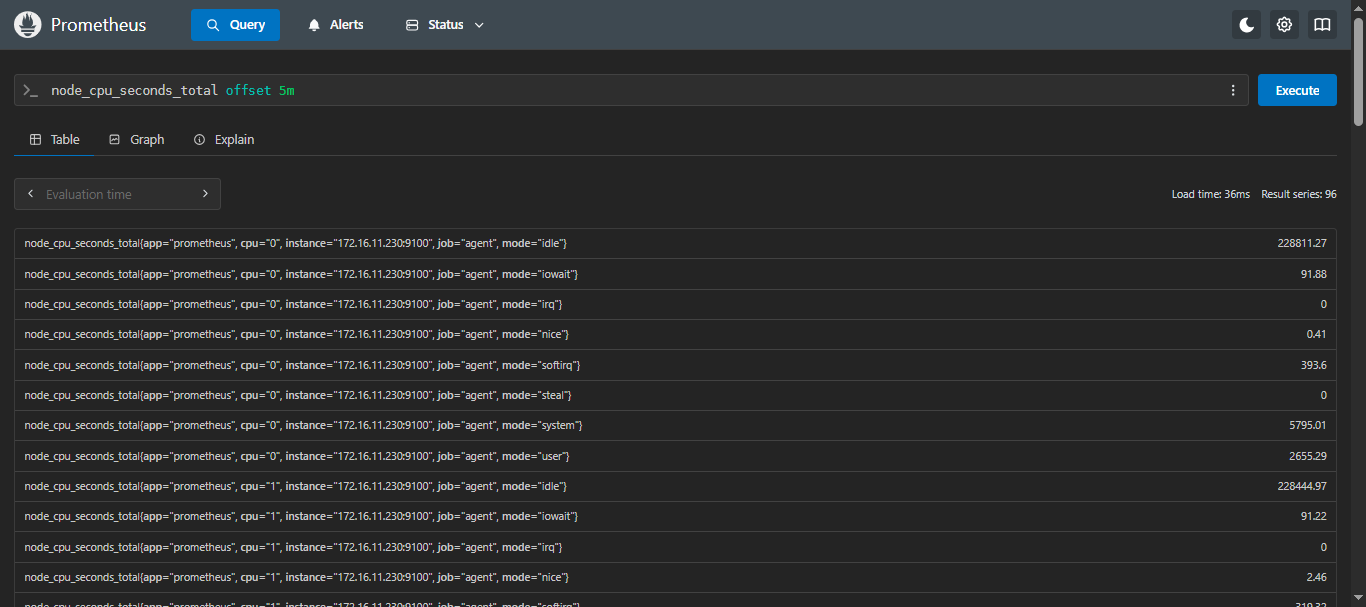
2.2.3 @ 修饰符
@ 修饰符用于查询特定时间点的数据。这需要 Prometheus 启用
promql-at-modifier功能,并且可能不被所有旧版本支持。
示例:查询 2025 年 12 月 3 日 18:00:00 这个时刻 CPU 的使用时间
sql
node_cpu_seconds_total @ 1764756000查询结果解析: 返回在 Unix 时间戳 1764756000(即 2025 年 12 月 3 日 18:00:00 UTC)时的 CPU 使用时间序列。
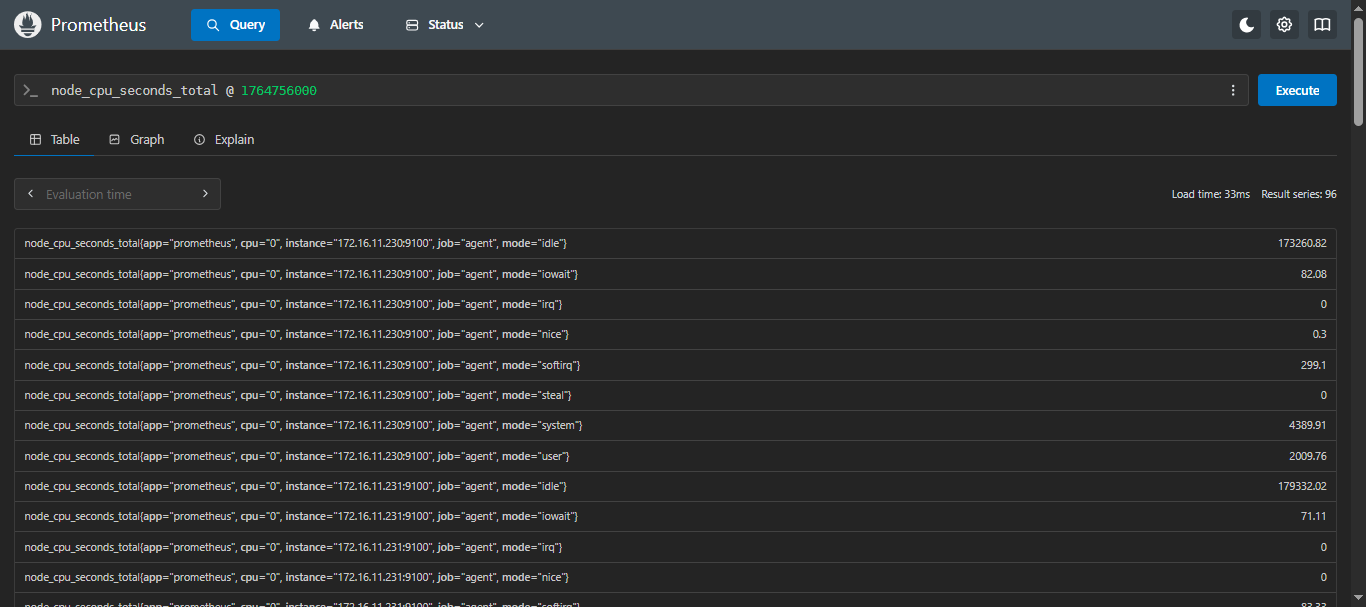
注意: 由于 Prometheus 的数据保留策略,查询的时间范围不能超过 Prometheus 配置的保留时间。此外,查询的时间分辨率取决于 Prometheus 的数据采样间隔和存储策略。
2.3 Scalar vector 简单向量
简单向量(Scalar vector)是一种特殊的向量,其中每个时间点的数值都是相同的。这种向量通常用于表示一个全局的、不变的数值,例如计数某个指标的所有时间序列的数量。
示例:查询 CPU 使用时间,所有标签的个数
sql
count(node_cpu_seconds_total)查询结果解析: 这个查询的目的是计算 node_cpu_seconds_total 指标的所有不同时间序列的数量。count 函数会忽略标签,只计算时间序列的数量。
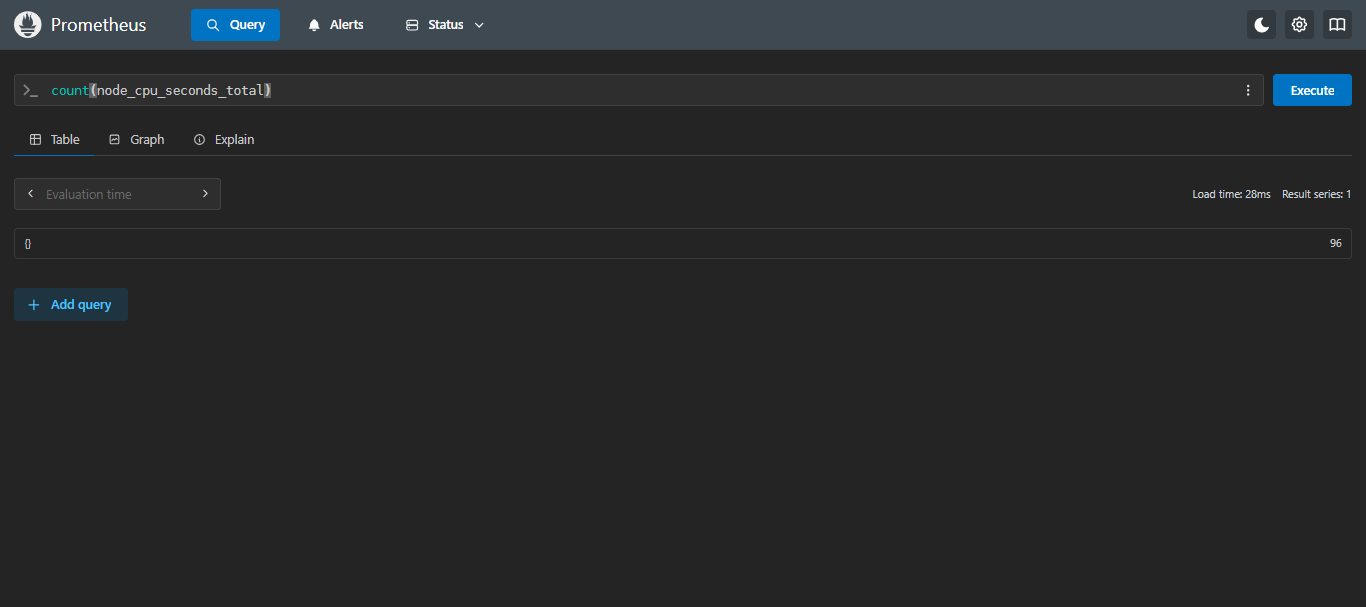
使用场景
- 监控指标的覆盖范围:了解有多少不同的实例或配置在报告某个指标。
- 验证数据采集:确保所有预期的实例都在正常报告数据。
- 告警规则:在告警规则中使用标量值来触发告警,例如,当某个指标的时间序列数量异常时。
总结来说,简单向量(Scalar vector)在 PromQL 中用于表示单一数值,常用于聚合操作的结果,如计数、求和等。通过这种方式,可以方便地获取全局的、不变的数值信息。
三、条件匹配
PromQL 支持多种条件匹配符来帮助我们精确地选择和过滤数据:
==:选择与提供的字符串完全相同的数据。!=:选择不等于提供的字符串的数据。=~:选择与提供的正则表达式匹配的数据。!~:选择与提供的正则表达式不匹配的数据。
3.1 普通匹配
- 查询 CPU 第一个核的使用时间:
sql
node_cpu_seconds_total{cpu="0"}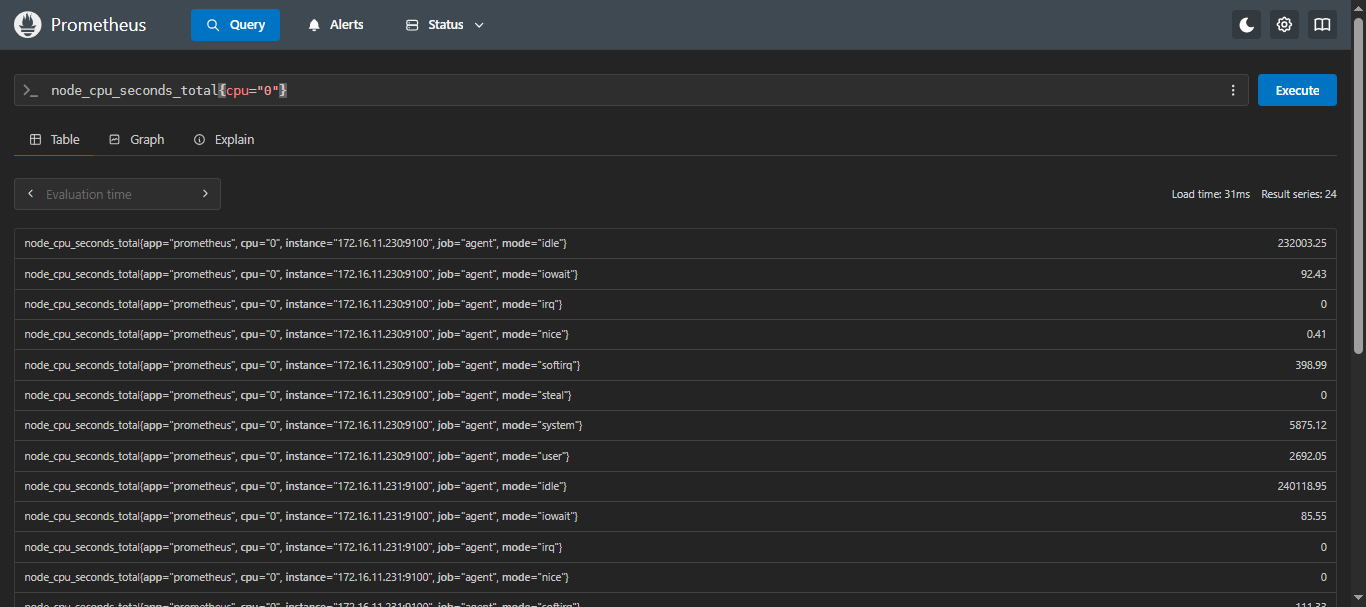
- 查询 CPU mode=idle的使用时间:
sql
node_cpu_seconds_total{mode="idle"}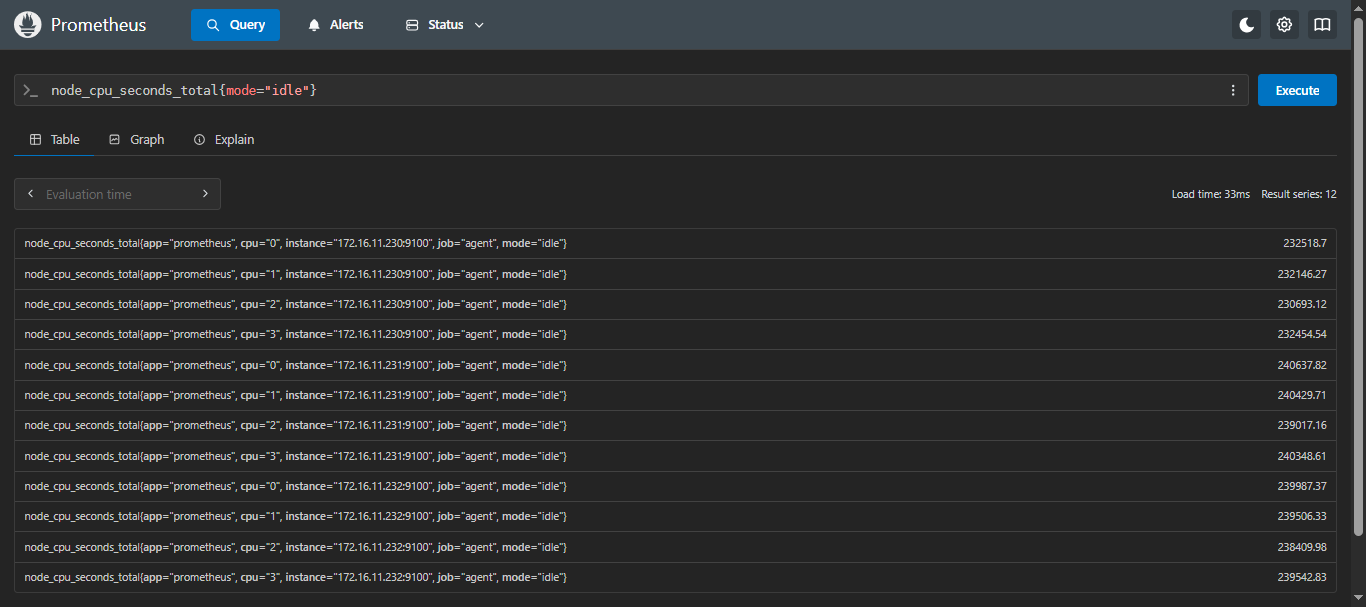
- 查询 CPU 除了第一个核以外的其他核的使用时间:
sql
node_cpu_seconds_total{cpu!="0"}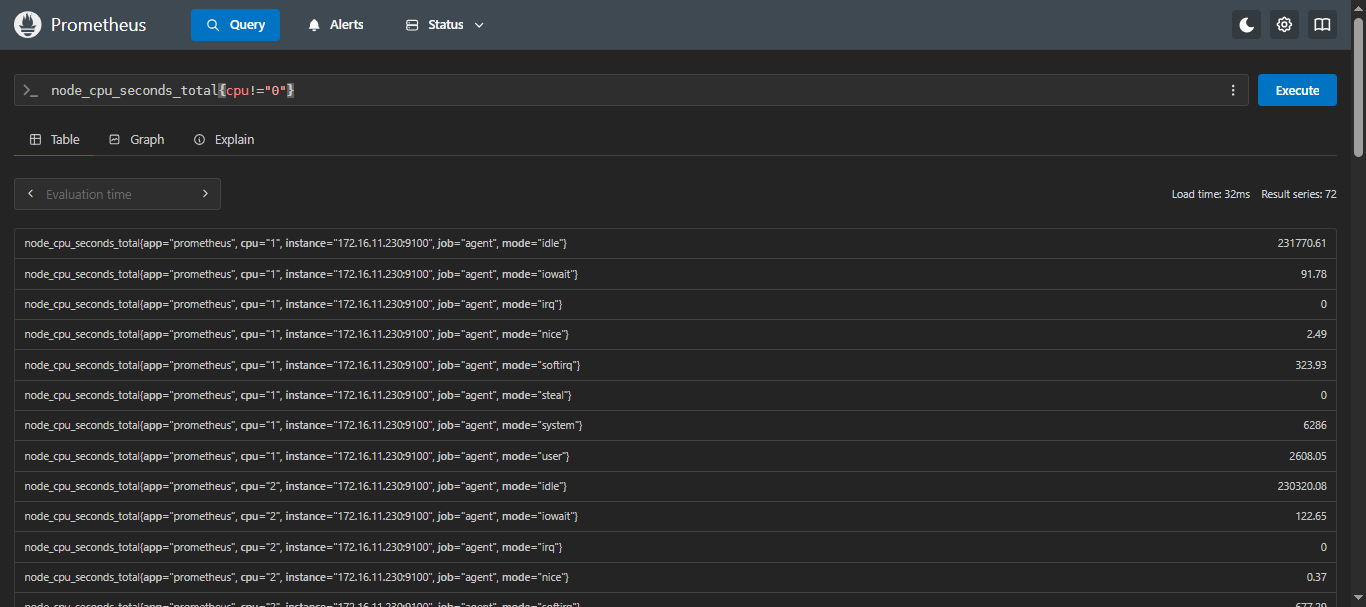
- 查询 CPU 第一个、第二个核的使用时间:
sql
node_cpu_seconds_total{cpu=~"0|1"}
- 查询 CPU 除了第一个、第二个核的使用时间:
sql
node_cpu_seconds_total{cpu!~"0|1"}
3.2 正则匹配
- 查询 CPU 第一个核,idle、iowait、irq 态的使用时间:
sql
node_cpu_seconds_total{cpu="1",mode=~"i.*"}
四、运算符
PromQL支持各种运算符,例如:
比较运算符、算数运算符、逻辑运算符、聚合运算符、函数运算符
4.1 比较运算符
比较运算符有:
==!=><>=<=与数学中和其他语言的含义是一样的 ;
- 示例1:查询cpu使用时间为0的标签
sql
node_cpu_seconds_total == 0
- 示例2:查询cpu使用时间不为0的标签
sql
node_cpu_seconds_total != 0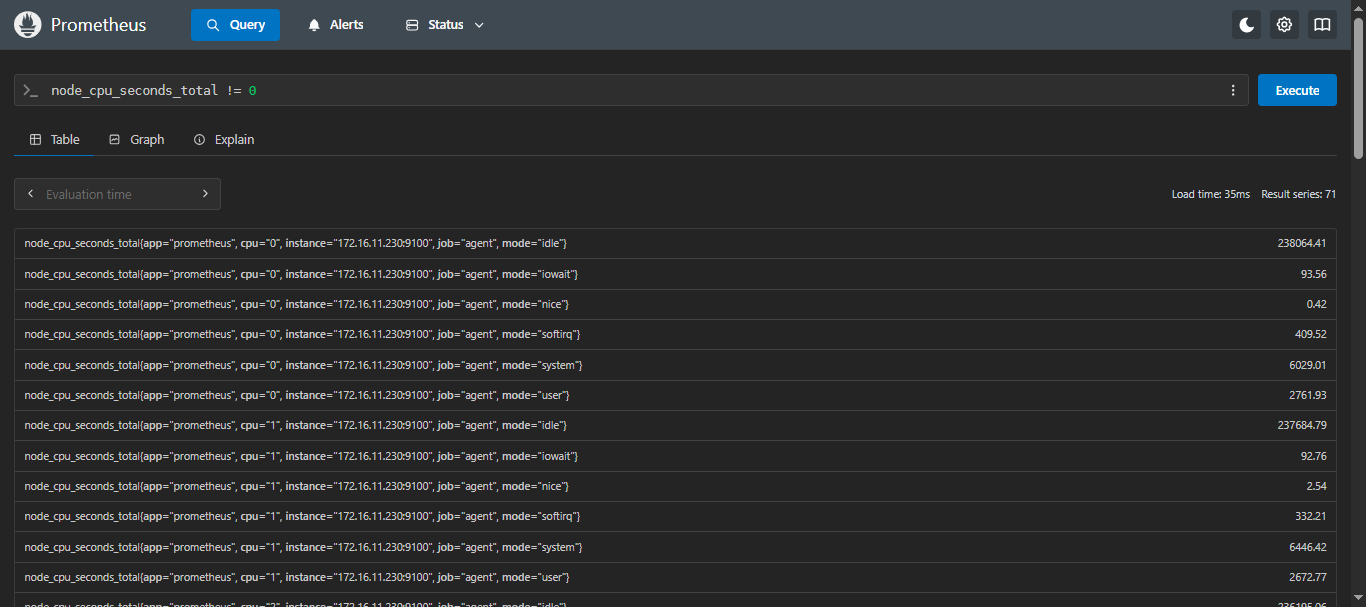
- 示例3:查询哪一台机器一分钟平均负载大于1
sql
node_load1 > 1
- 示例4:查询哪一台机器一分钟平均负载小于1
sql
node_load1 < 1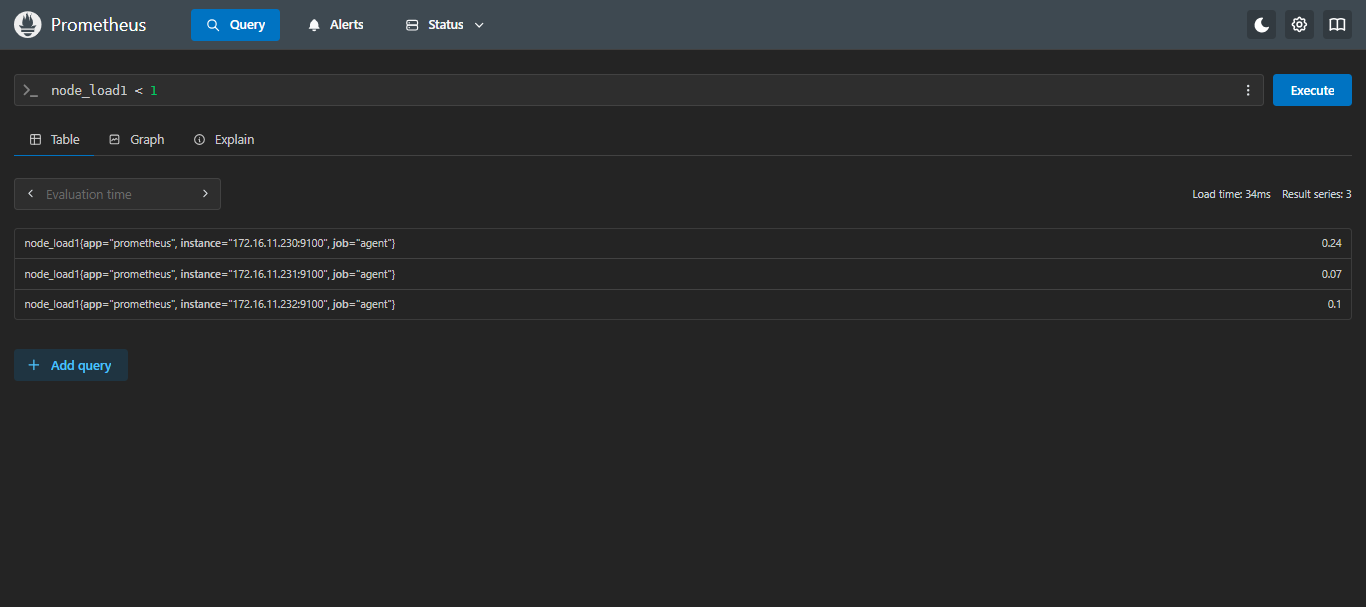
- 示例5:查询cpu使用时间大于等于10000的标签
sql
node_cpu_seconds_total >= 10000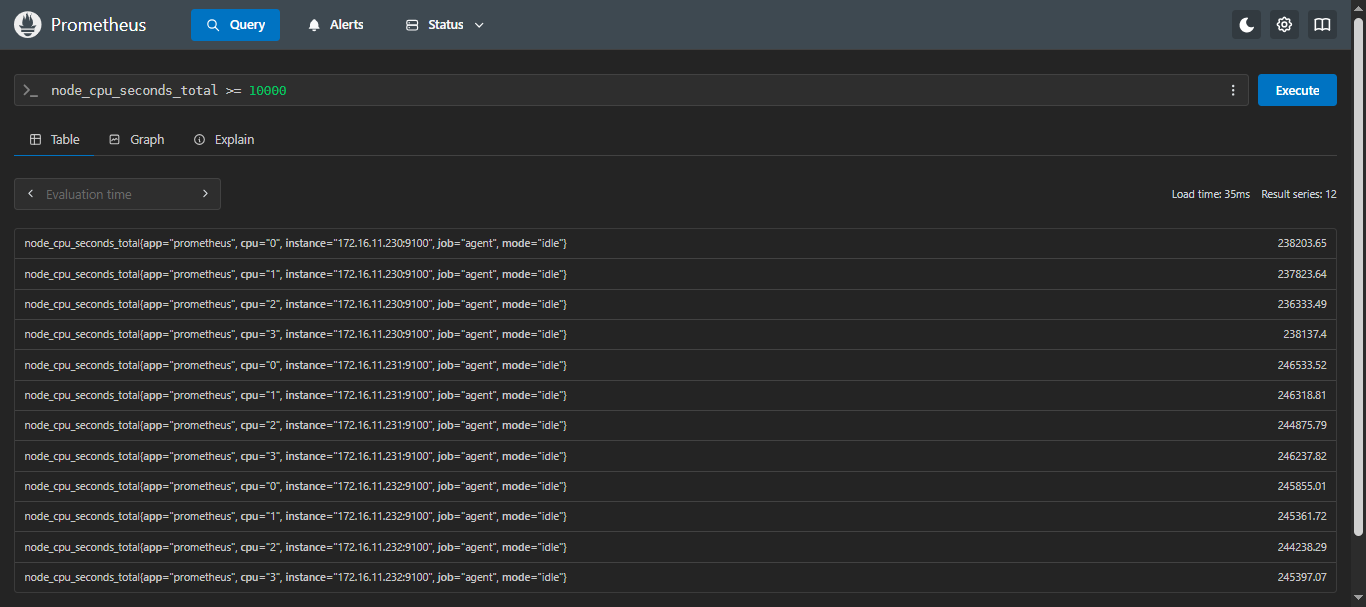
- 示例6:查询cpu使用时间小于等于23000的标签
sql
node_cpu_seconds_total <= 23000
4.2 算术运算符
算数运算符有:
+、-、*、/、%、^与数学里面的算数运算符含义一样,分别为:加、减、乘、除、取余、幂次方;优先级(高→低):
^→*/%→+-
- 示例1
+:计算主机cpu使用时间和主机上面虚拟机使用时间的和
sql
node_cpu_seconds_total + node_cpu_guest_seconds_total
- 示例2
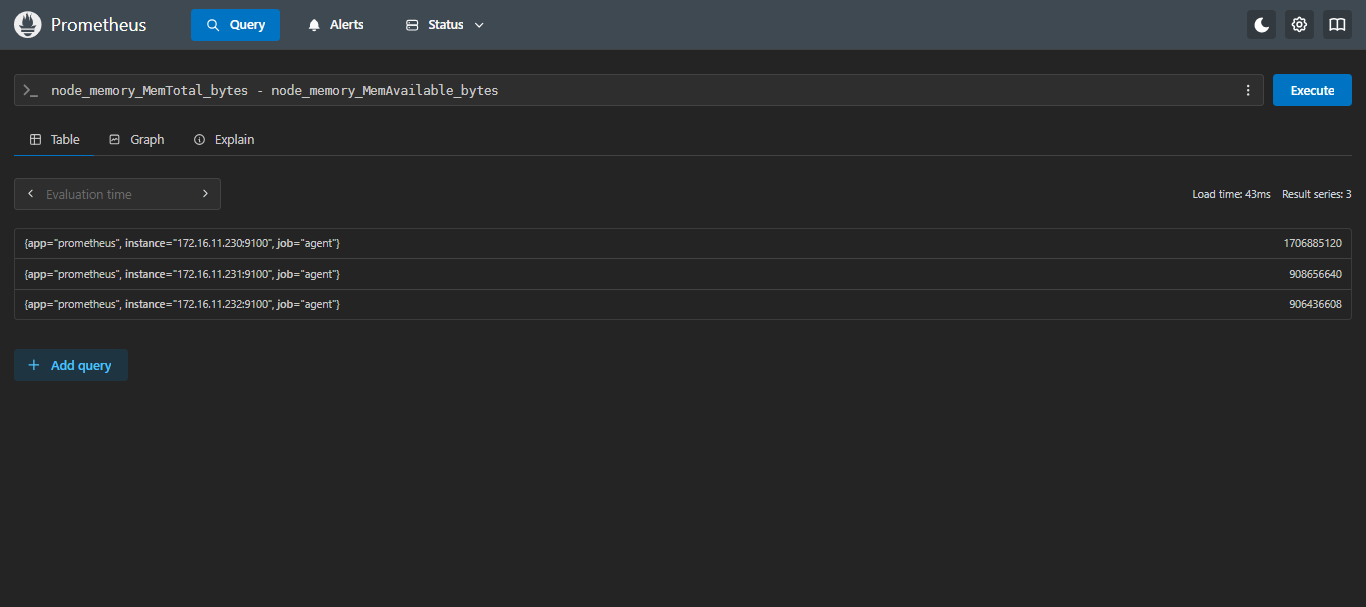
-:计算已经使用了多少内存
sql
node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes以字节为单位,230服务器大约使用了1.5G左右;
- 示例3
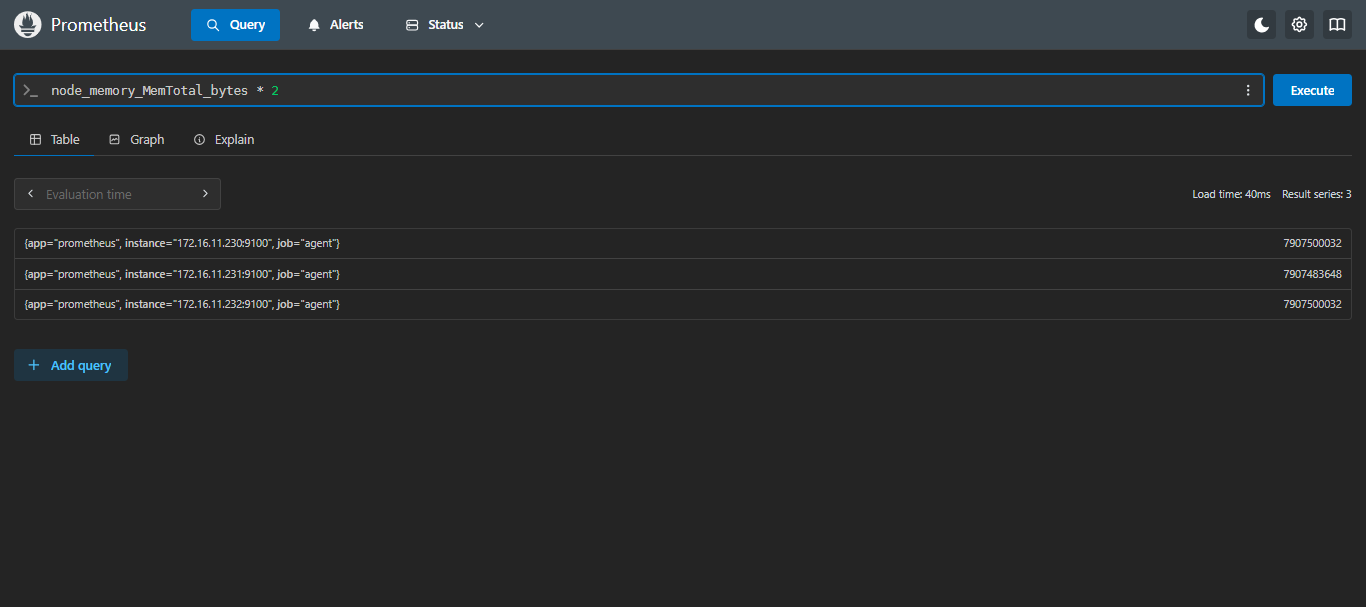
*:计算2倍总内存大小
sql
node_memory_MemTotal_bytes * 2以字节为单位,230服务器总内存大小大约为7.4G;
- 示例4
/:计算总内存大小,以G为单位
sql
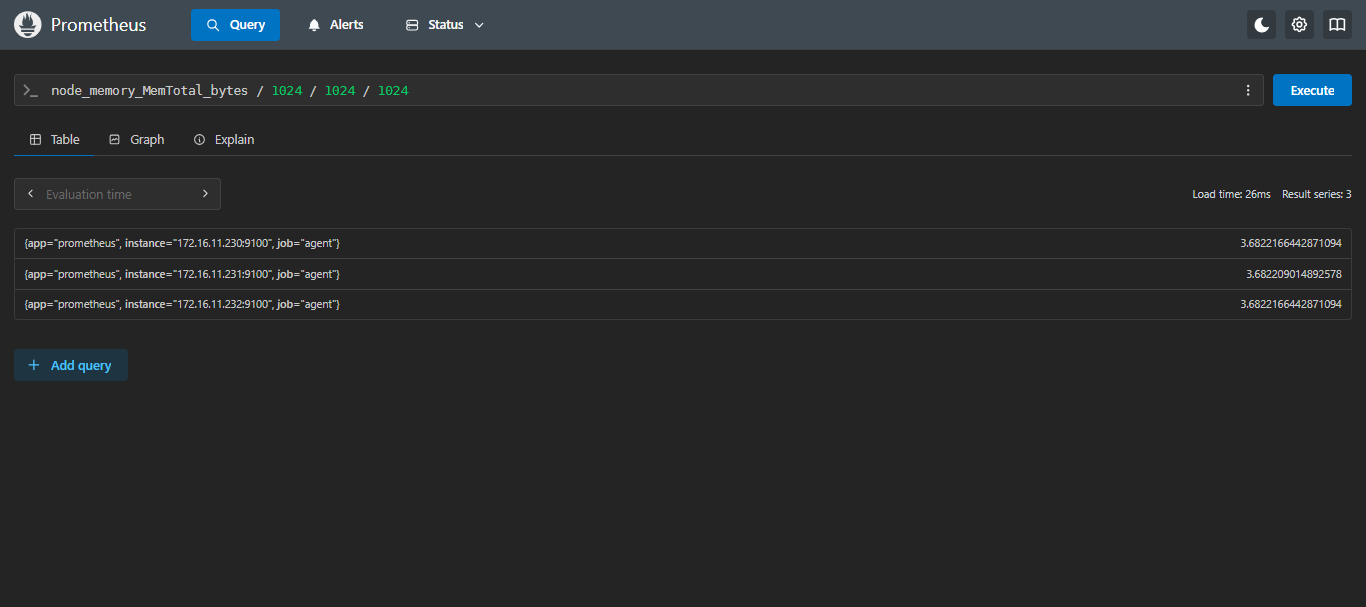
node_memory_MemTotal_bytes / 1024 / 1024 / 1024以G为单位,230服务器总内存大小大约为3.6G;
计算方式:默认是字节,字节网上是KB、MB、G,所以需要除以3次1024,得到G;
4.3 逻辑运算符
逻辑运算符有:
and、or、unless对应其他语言的与、或、非;
unless是"集合差":把左边出现、右边也出现的序列全部丢掉,只留下左边独有的。
- 示例1
and:查询可用内存大小大于2.2G并且小于2.75G的服务器
sql
node_memory_MemAvailable_bytes /1024/1024/1024 > 2.2 and node_memory_MemAvailable_bytes /1024/1024/1024 < 2.75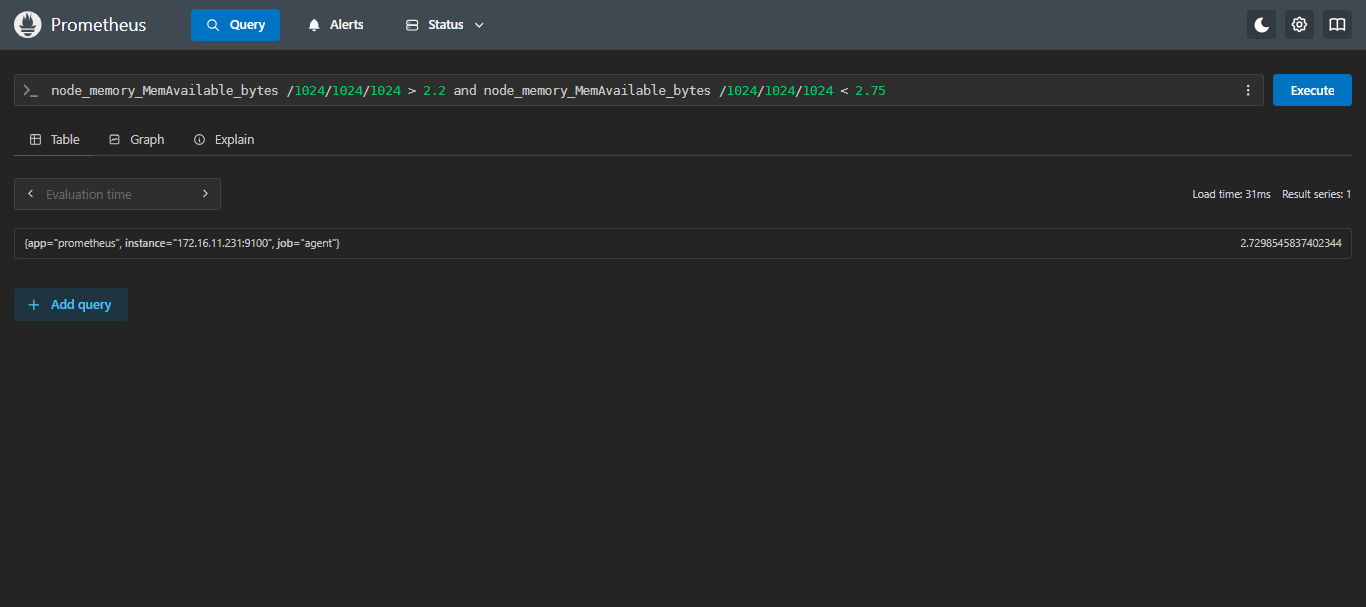
- 示例2
or:查询可用内存大小大于2.2G或者大于等于2.75G的服务器
sql
node_memory_MemAvailable_bytes /1024/1024/1024 > 2.2 or node_memory_MemAvailable_bytes /1024/1024/1024 >= 2.75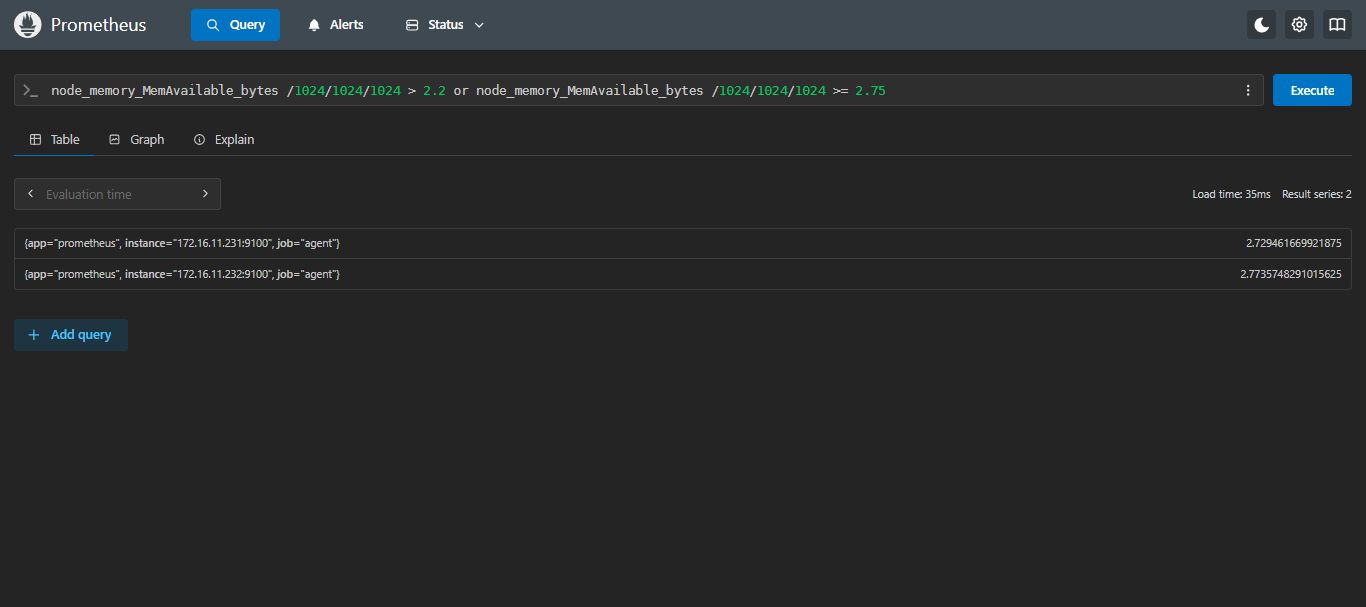
- 示例3
unless:查询可用内存大小非小于3G且大于2.5G的服务器
sql
node_memory_MemAvailable_bytes /1024/1024/1024 < 3 unless node_memory_MemAvailable_bytes /1024/1024/1024 > 2.5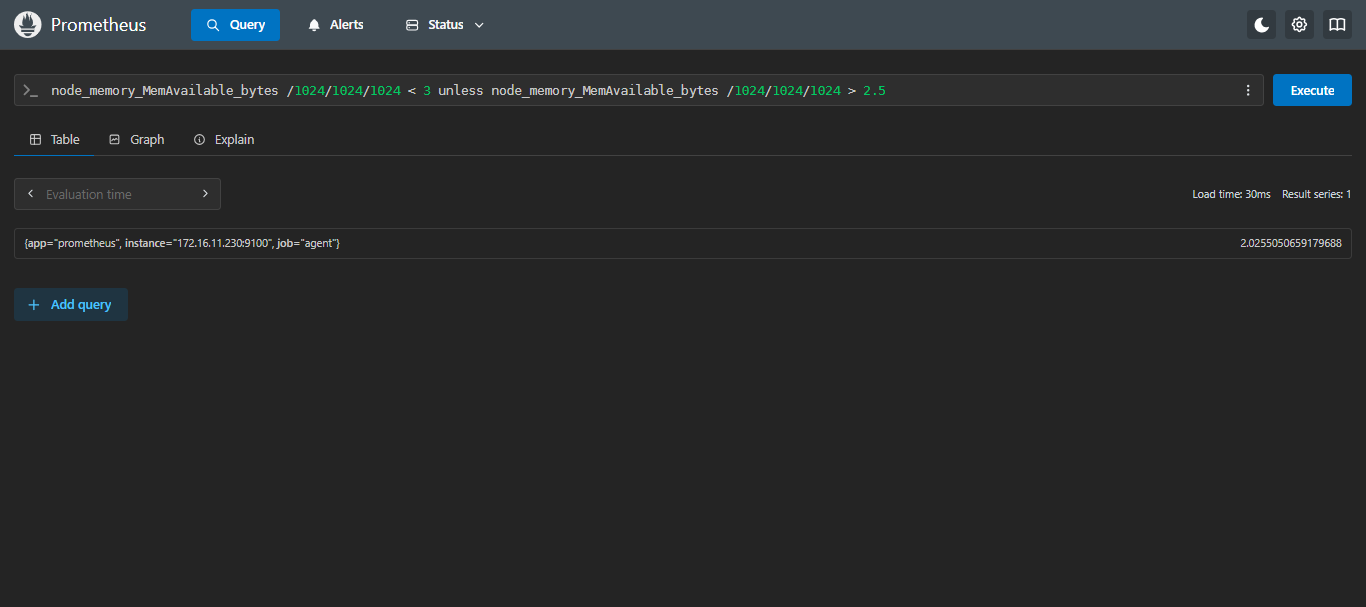
4.4 聚合运算符(聚合函数)
| 聚合运算符 | 作用 | 示例 |
|---|---|---|
sum |
求和 | sum(node_cpu_seconds_total) |
avg |
平均 | avg(node_cpu_seconds_total) |
max / min |
最大 / 小 | max(node_cpu_seconds_total) |
count |
计数 | count(node_cpu_seconds_total) |
topk(n, ...) |
前 n 大 | topk(3, node_cpu_seconds_total) |
bottomk(n, ...) |
后 n 小 | bottomk(3, node_cpu_seconds_total) |
4.4.1 sum:求和
计算所有机器的总内存
sql
sum(node_memory_MemTotal_bytes /1024/1024/1024)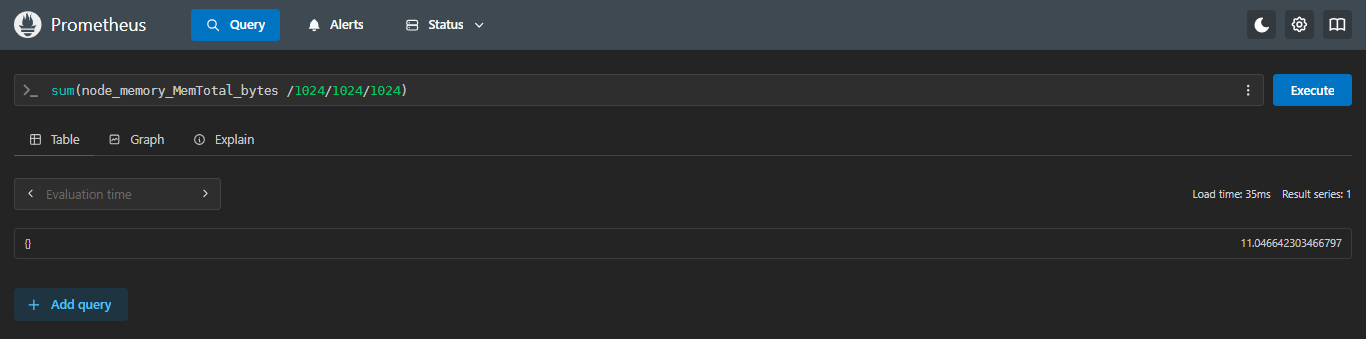
4.4.2 count:计数
统计所有服务器网卡数量
sql
count(node_network_up)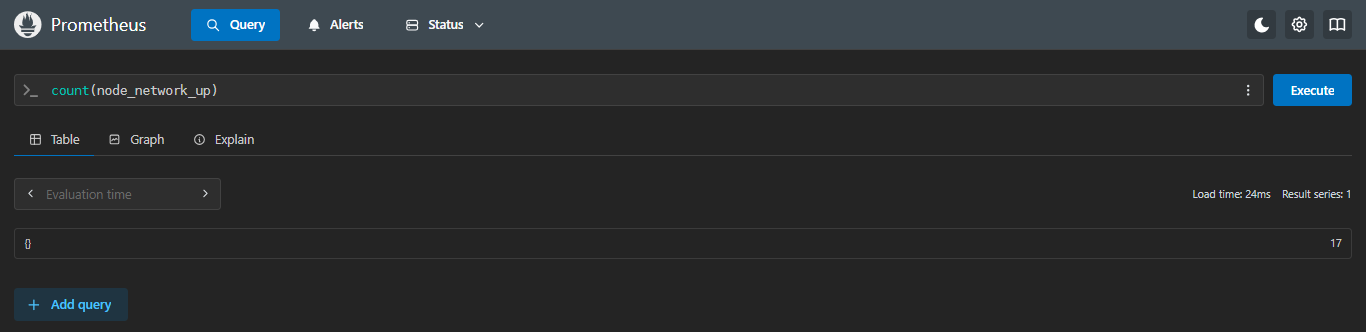
4.4.3 max:求最大值
查看剩余内存最多的是多少
sql
max(node_memory_MemAvailable_bytes /1024/1024/1024)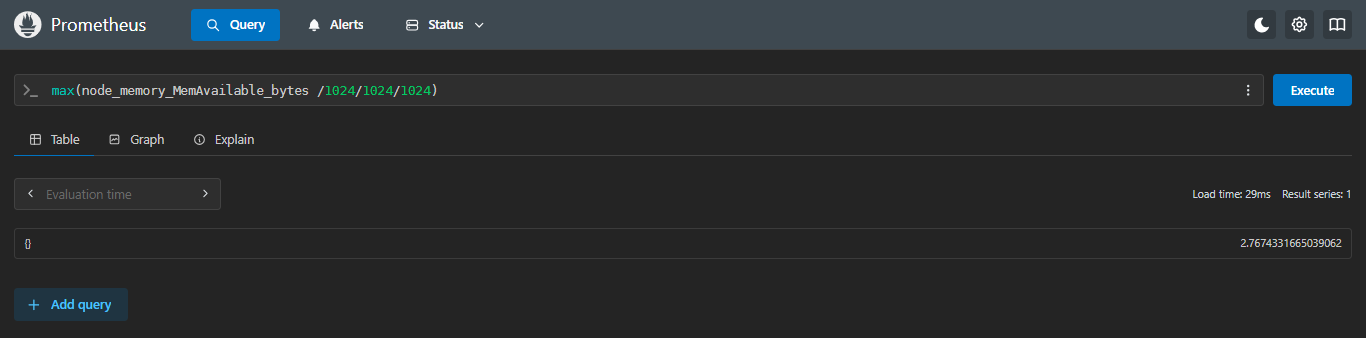
4.4.4 min:求最小值
查看剩余内存最少的是多少
sql
min(node_memory_MemAvailable_bytes /1024/1024/1024)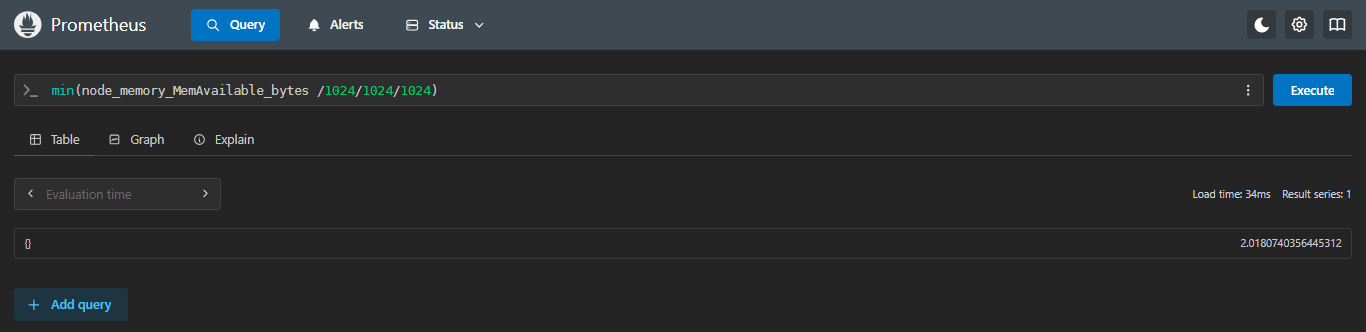
4.4.5 avg:求平均值
计算3台服务器ens33网卡的平均出口流量
sql
avg(node_network_transmit_bytes_total{device="ens33"} /1024/1024/1024)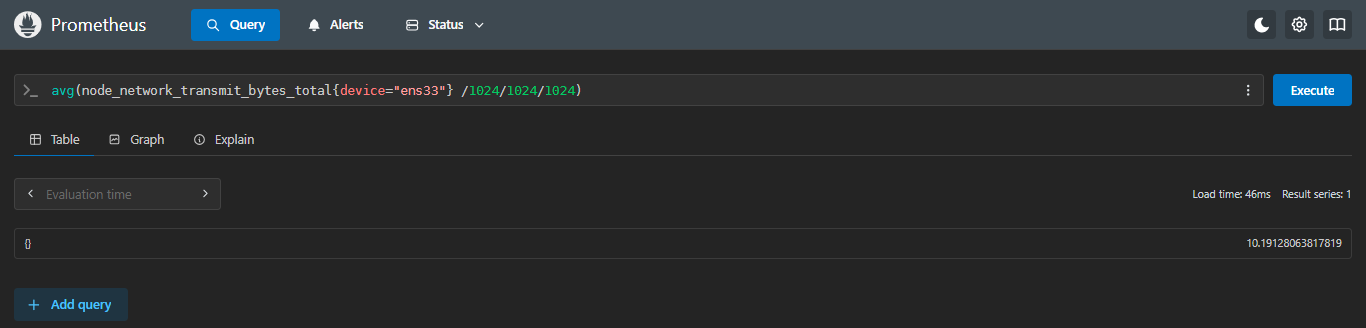
4.4.6 topk:取前面几个较大值
查询cpu内核态(system)的排名前两个的核
sql
topk(2,node_cpu_seconds_total{mode="system"})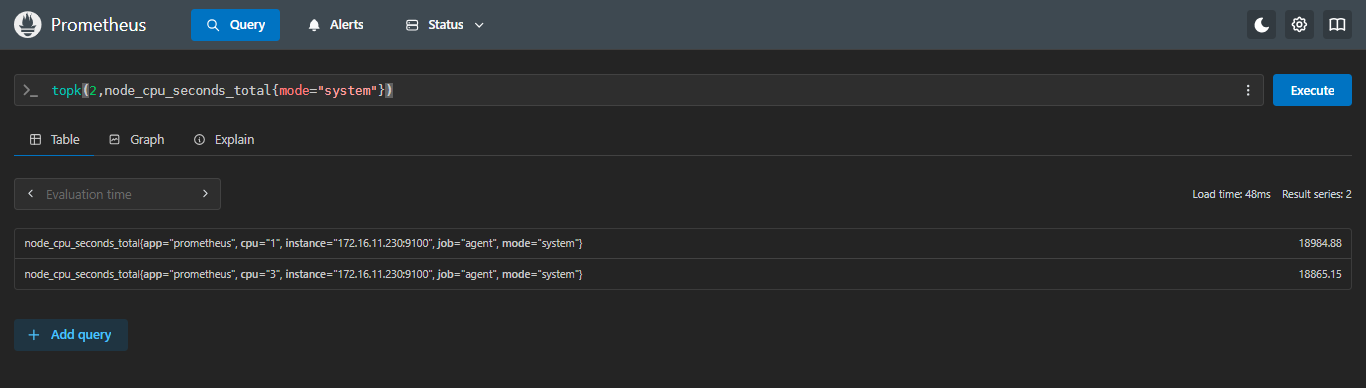
4.4.7 bottomk:取后面几个较小值
查询cpu内核态(system)的排名后两个的核
sql
bottomk(2,node_cpu_seconds_total{mode="system"})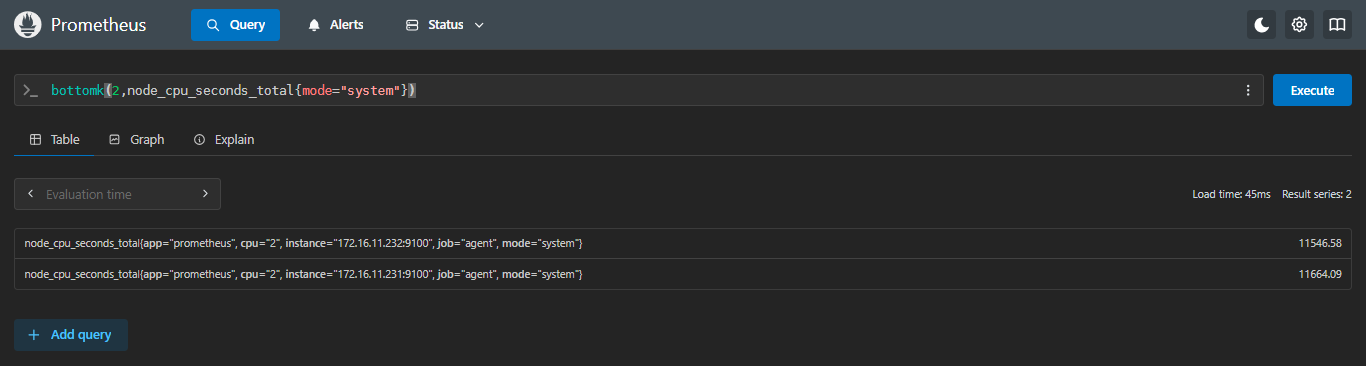
4.5 匹配运算
4.5.1 on:关联标签
在需要在两个时间序列之间执行算术运算,并且这两个序列具有共同的标签时,可以使用
on修饰符。这会确保仅在共同标签匹配的情况下执行运算。
- 示例:计算每个 CPU 核心的用户态和系统态的总使用时间
sql
node_cpu_seconds_total{mode="system"} + on (instance,cpu) node_cpu_seconds_total{mode="user"}这里,
on (instance, cpu)确保了只有当instance和cpu标签匹配时,才会将两个时间序列相加。
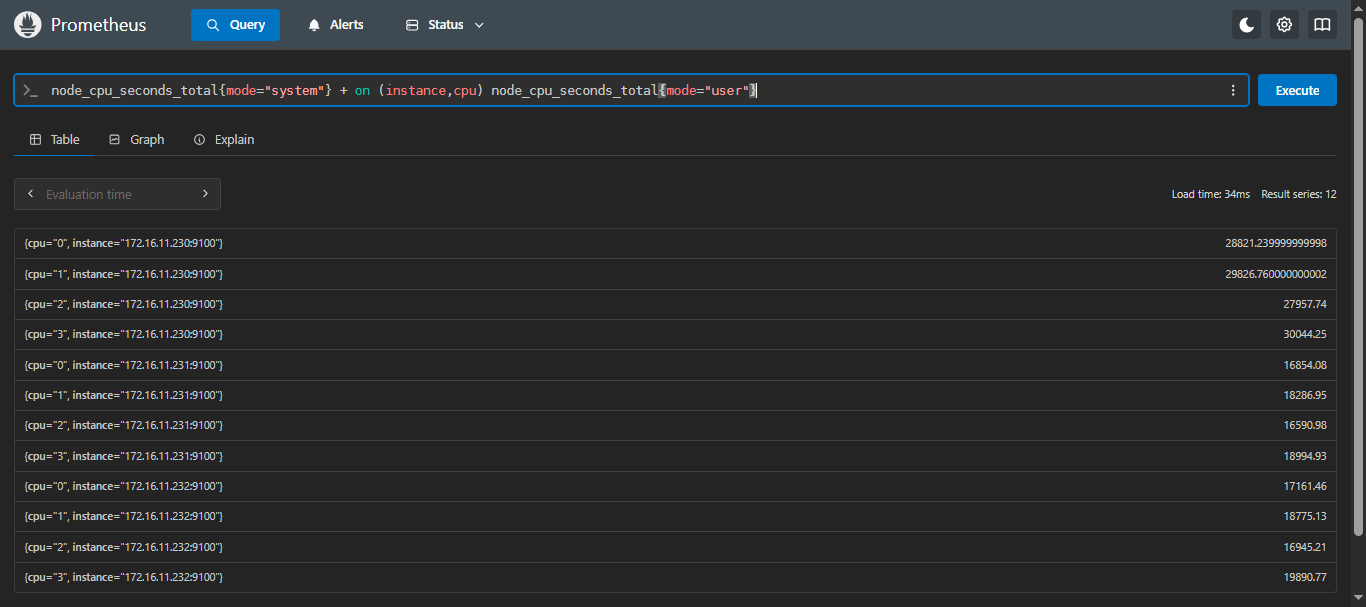
4.5.2 ignoring:忽略标签
在需要执行算术运算但不需要考虑某些标签时,可以使用
ignoring修饰符。这会忽略指定的标签,即使它们不匹配。
示例:忽略运行状态,计算每个 CPU 核心的用户态和系统态的总使用时间
sql
node_cpu_seconds_total{mode="system"} + ignoring (mode) node_cpu_seconds_total{mode="user"}这里,
ignoring (mode)允许即使mode标签不匹配,也会执行加法。
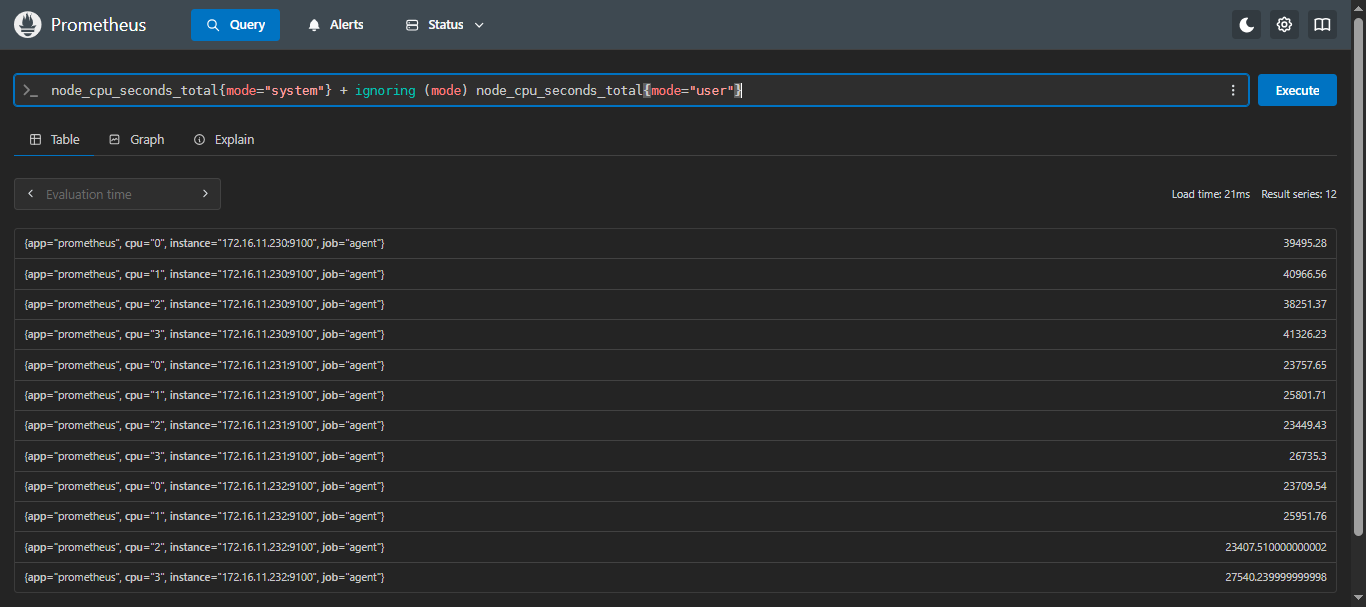
4.5.3 by:以某一个标签进行计算
by修饰符用于在聚合函数中指定如何分组数据。
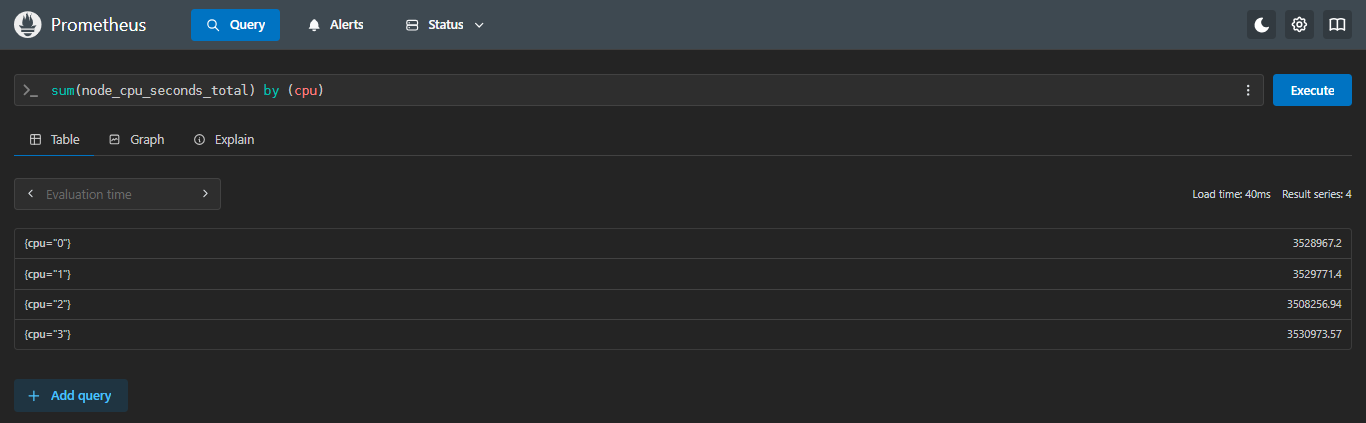
- 示例1:计算每个 CPU 核心的各个状态的总使用时间
sql
sum(node_cpu_seconds_total) by (cpu)这个查询会按
cpu标签对数据进行分组,并计算每组的总和。
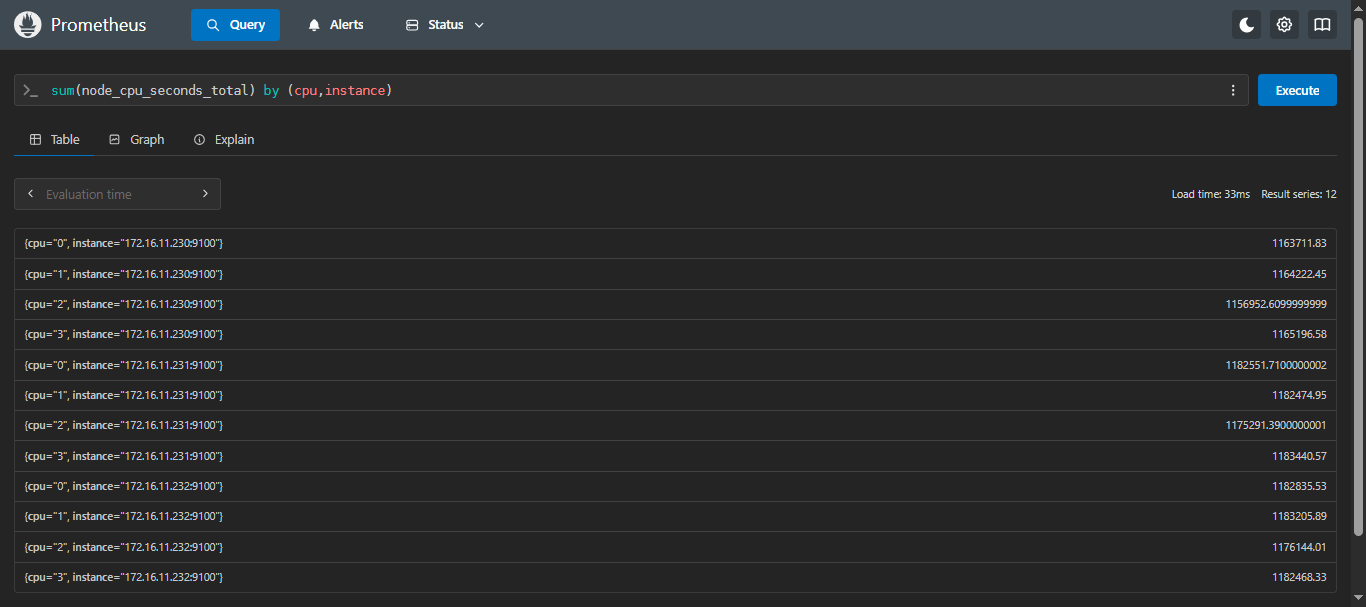
- 示例2:计算每台服务器每个 CPU 核心的各个状态的总使用时间
sql
sum(node_cpu_seconds_total) by (cpu,instance)这个查询会按
cpu和instance标签对数据进行分组,并计算每组的总和。
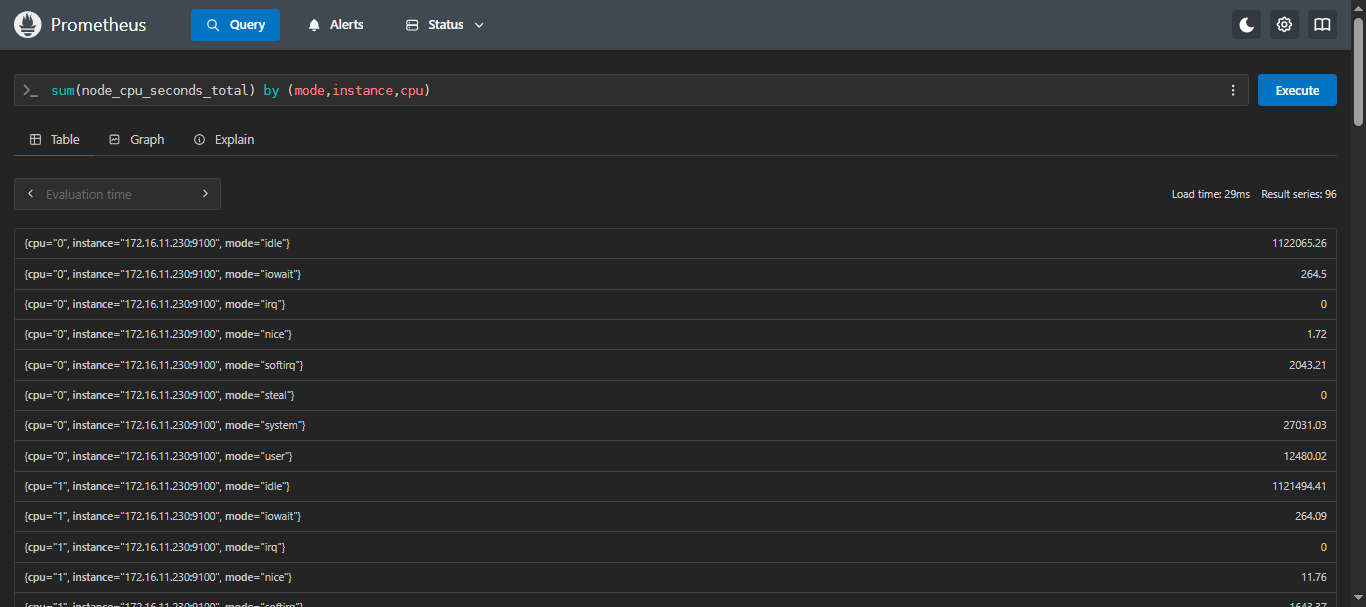
- 示例3:计算每台服务器 每个CPU核心 每个状态下 CPU 核心的总使用时间
sql
sum(node_cpu_seconds_total) by (mode,instance,cpu)这个查询会按
cpu、instance、mode标签对数据进行分组,并计算每组的总和。
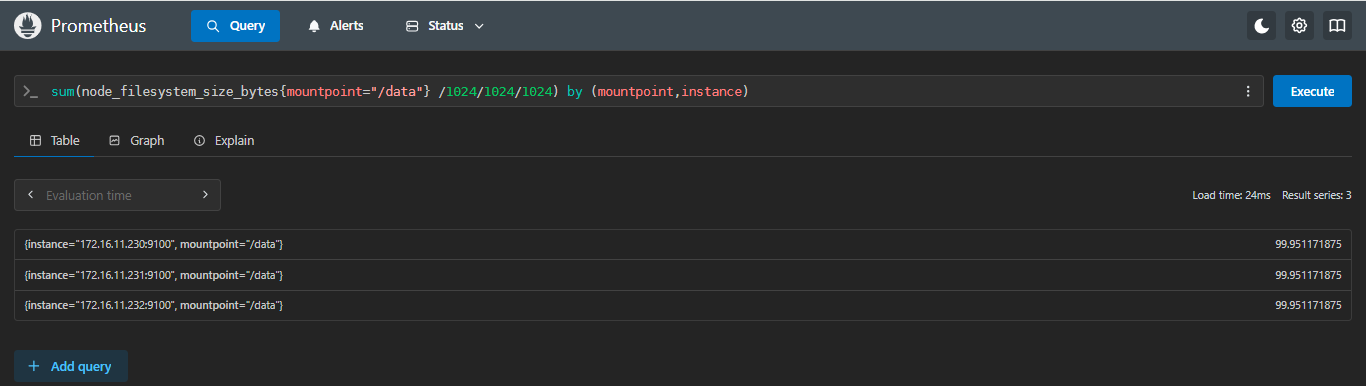
- 示例4:计算每台服务器 每个
/data磁盘共多少G
sql
sum(node_filesystem_size_bytes{mountpoint="/data"} /1024/1024/1024) by (mountpoint,instance)计算每台服务器 每个
/data磁盘共多少G,并按mountpoint、instance进行分组;
4.5.4 without:舍弃某个标签进行计算
without修饰符用于在聚合函数中指定需要舍弃的标签,与by刚好相反。
示例:计算ens33网卡出口流量有多少G,并按device和instance标签展示
sql
sum(node_network_transmit_bytes_total{device="ens33"} /1024/1024/1024) without (job,app)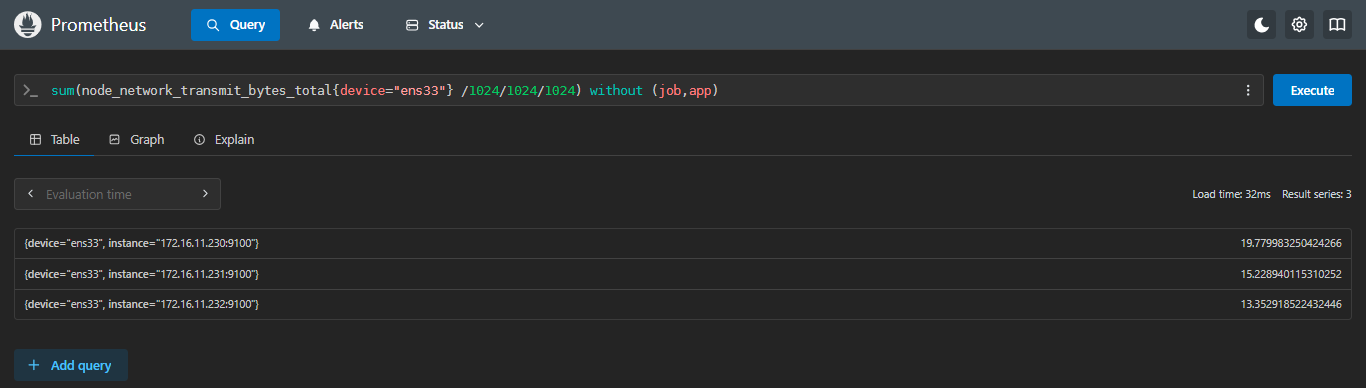
五、函数
5.1 速率函数
5.1.1 increase:区间内总增长量
示例:查看每台服务器 ens33 网卡过去 1 分钟的流量发送总量是多少G
sql
increase(node_network_transmit_bytes_total{device="ens33"}[1m])/1024/1024/1024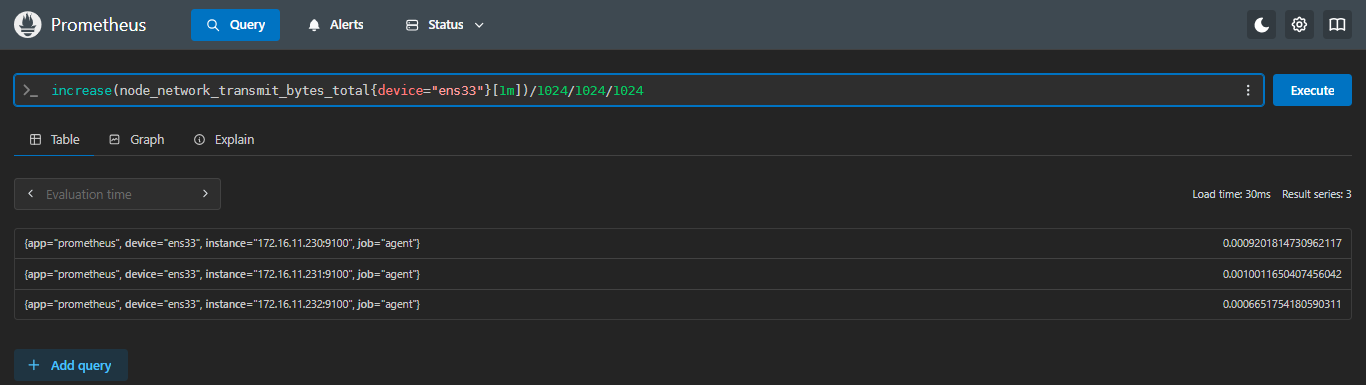
5.1.2 rate:每秒平均增长率
示例:查看每台服务器 ens33 网卡过去 1 分钟内的平均发送速率是多少字节
sql
rate(node_network_transmit_bytes_total{device="ens33"}[1m])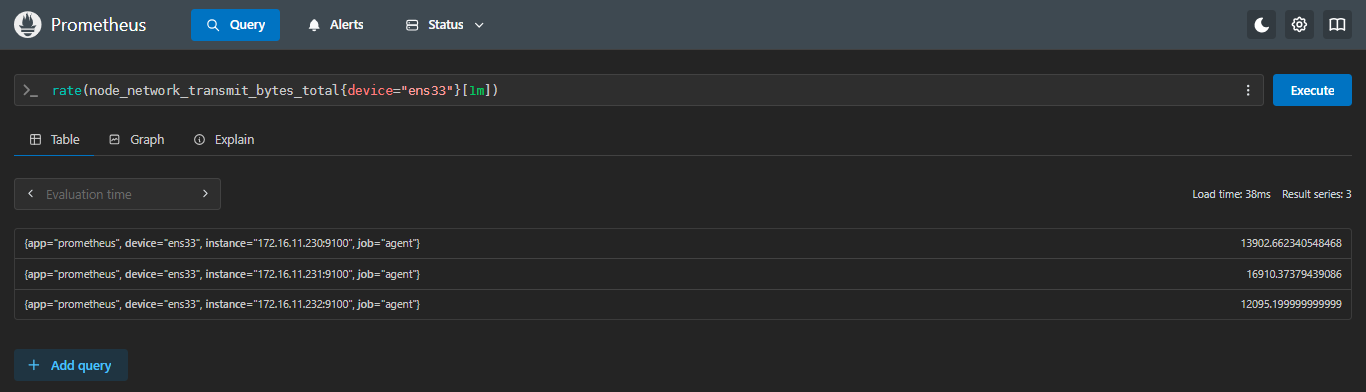
5.1.3 irate:每秒瞬时增长率
示例:查看每台服务器 ens33 网卡在过去 1 分钟内的「瞬时」发送速率是多少KB
sql
irate(node_network_transmit_bytes_total{device="ens33"}[1m]) /1024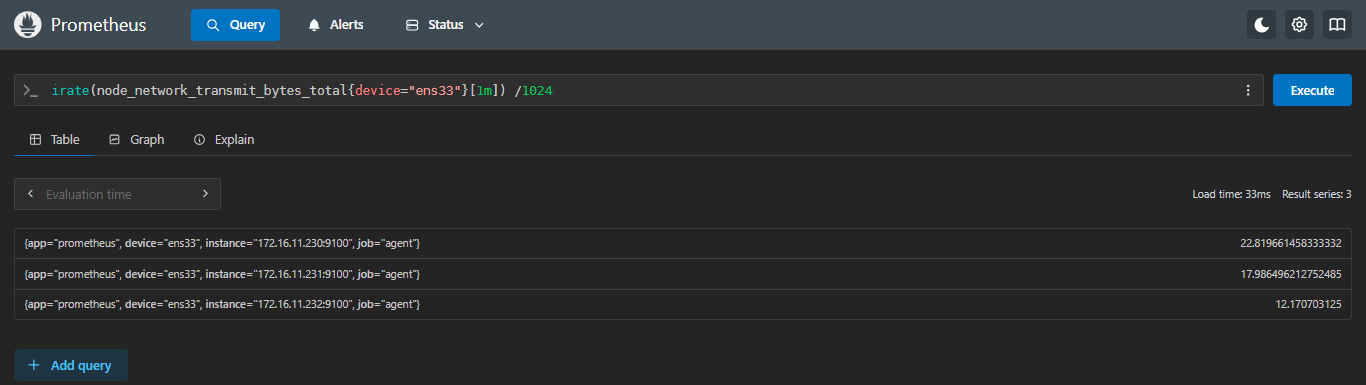
5.2 区间函数(包含速率函数)
5.2.1 predict_linear 预测指标
"按最近区间内的直线趋势,预测 N 秒后会把指标推到多少",常用于提前告警------"例如:按现在速度,再过 4 h 磁盘就满了"。
- 语法:
sql
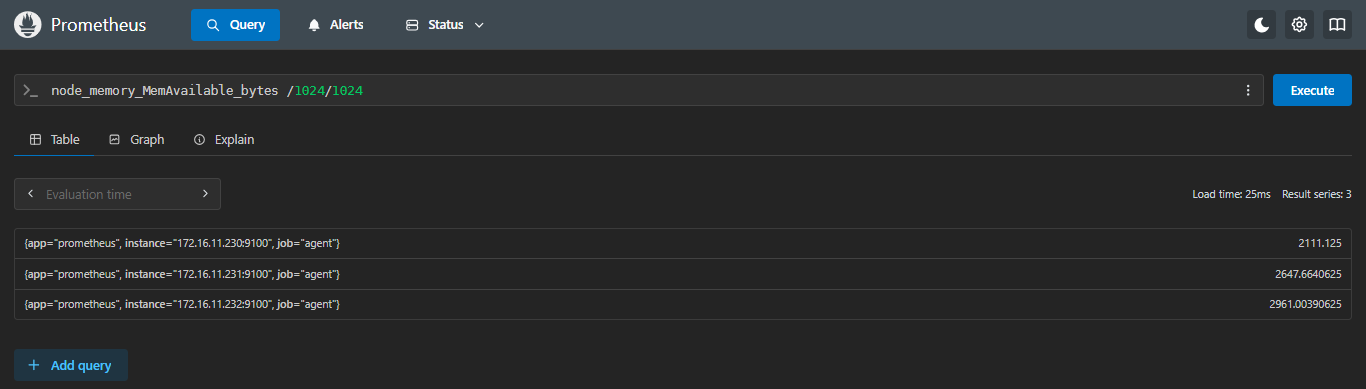
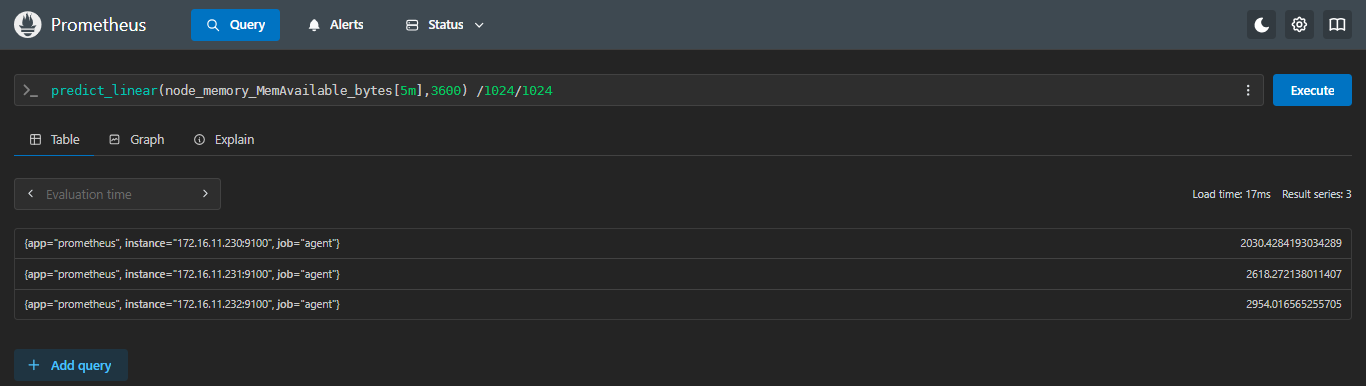
predict_linear(<指标名>[<范围>], <秒数>)- 示例:推测内存在一小时后能达到多少M
sql
predict_linear(node_memory_MemAvailable_bytes[5m],3600) /1024/1024- 当前时间内存有多少M
- 根据过去5分钟推算1小时后内存还有多少M
5.3 取整函数
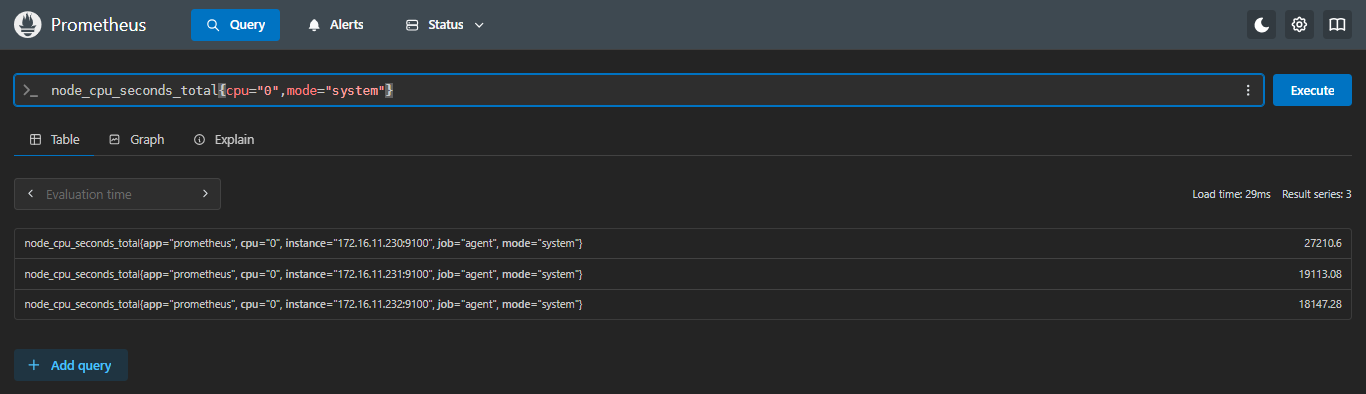
5.3.1 ceil:向上取整
示例:查看每台服务器第一块cpu,mode为system的使用时间,向上取整
sql
ceil(node_cpu_seconds_total{cpu="0",mode="system"})- 正常不取整
- 向上取整
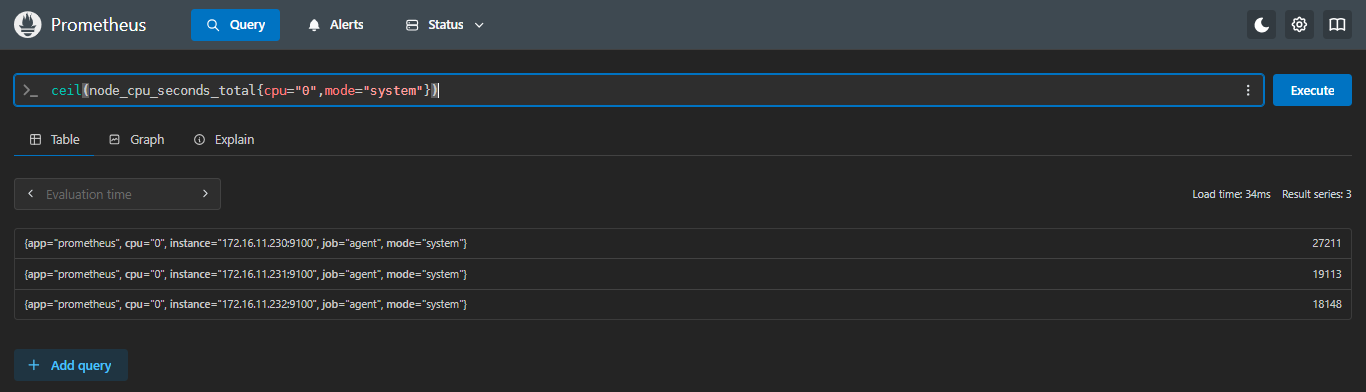
5.3.2 floor:向下取整
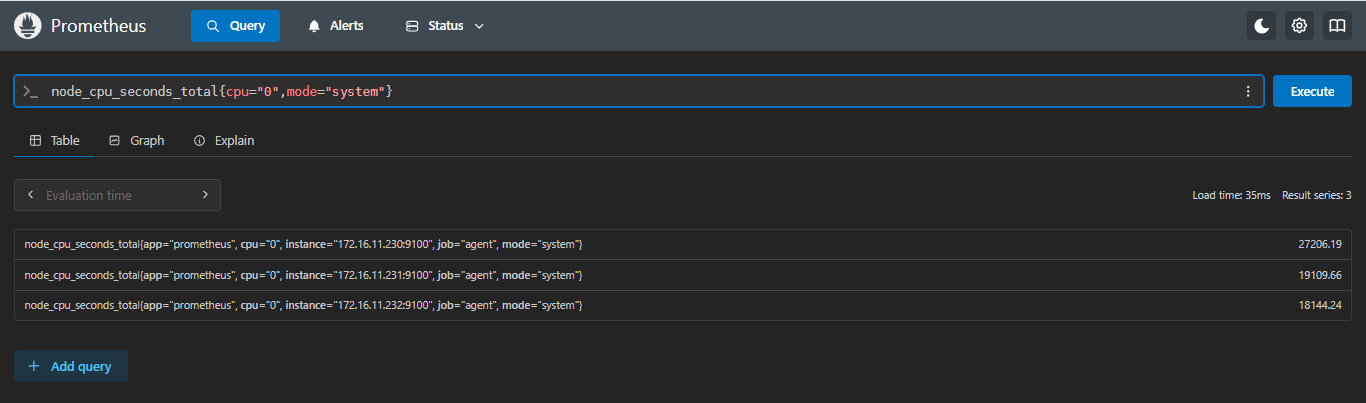
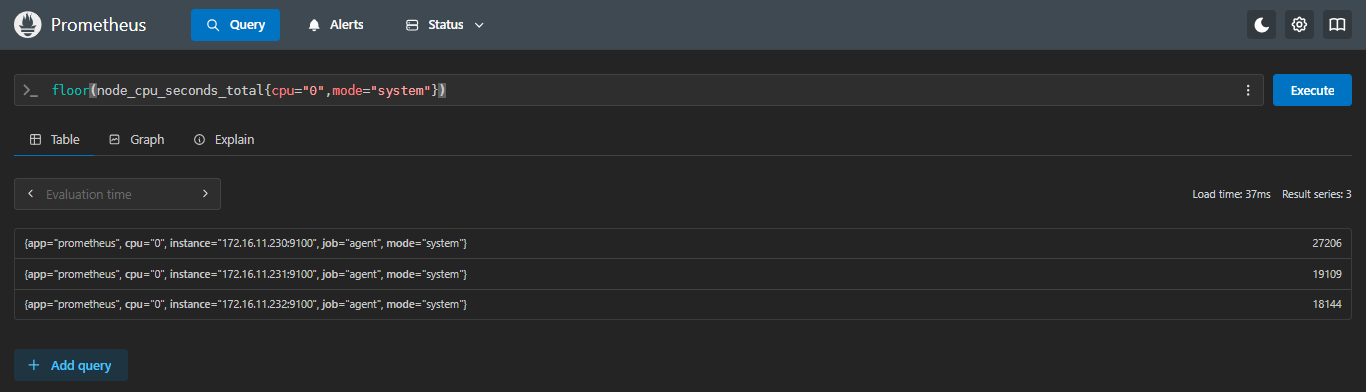
示例:查看每台服务器第一块cpu,mode为system的使用时间,向下取整
sql
floor(node_cpu_seconds_total{cpu="0",mode="system"})- 正常不取整
- 向下取整
5.3.3 round:四舍五入
示例:查看每台服务器第一块cpu,mode为system的使用时间,四舍五入
sql
round(node_cpu_seconds_total{cpu="0",mode="system"})- 正常不取整
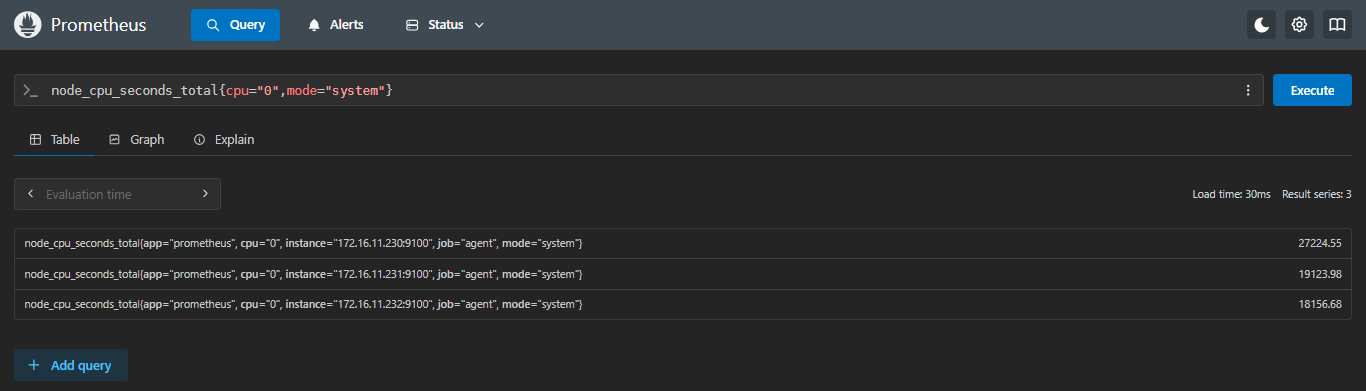
- 四舍五入
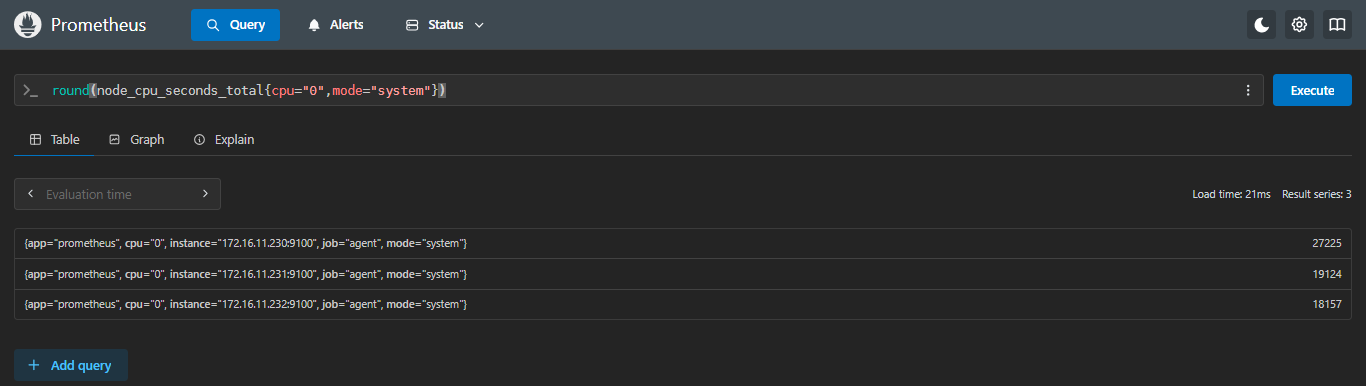
5.3.4 三者的区别
| 函数 | 正常取值 | 取整结果 | 取值说明 |
|---|---|---|---|
ceil 向上 |
27210.6 | 27211 | 不管小数点后面是几都会向上一位 |
floor 向下 |
27206.19 | 27206 | 不管小数点后面是几都会保持小数点前的值,舍掉后面的值 |
round 四舍 |
27224.55 | 27225 | 根据小数点后面,>=5向上,<5舍掉,和数学用法一样 |
5.4 排序函数
5.4.1 sort:正向排序(升序)
示例:查看每台机器ens33网卡出口流量,并进行从小到大排序
sql
sort(node_network_transmit_bytes_total{device="ens33"} /1024/1024/1024)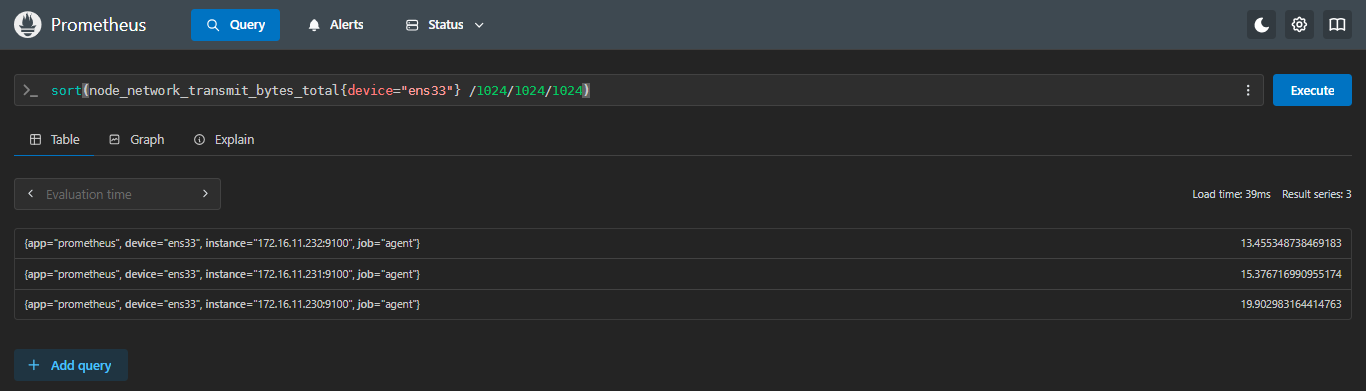
5.4.2 sort_desc:逆向排序(降序)
示例:查看每台机器ens33网卡出口流量,并进行从大到小排序
sql
sort_desc(node_network_transmit_bytes_total{device="ens33"} /1024/1024/1024)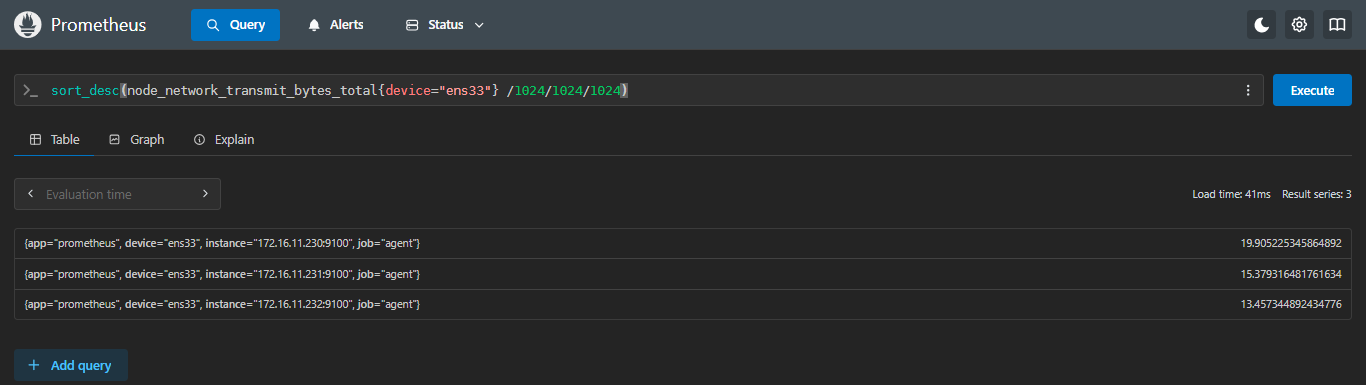
5.5 其他函数
5.5.1 abs:求绝对值
abs() 只干一件事:遇到负数就"去负号",正数原样不动。
例:
-1.2 → 1.2,3.4 → 3.4。
示例:求230服务器第一块cpu使用时间的绝对值
sql
abs(node_cpu_seconds_total{cpu="0",mode="system",instance="172.16.11.230:9100"})- 绝对值前
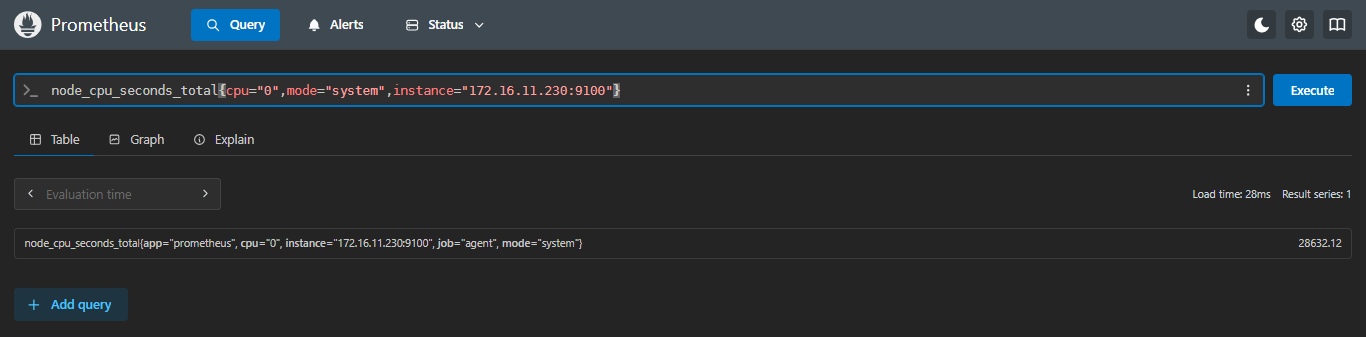
- 绝对值后
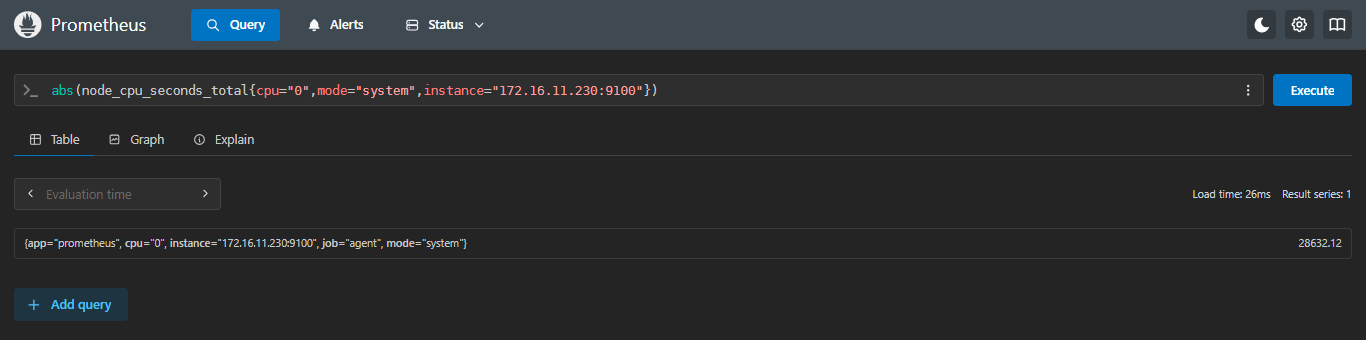
可以看出来是毫无变化的,因为正数的值是不会变的,只有遇到负数的值使用abs()才会变为正数绝对值;
5.5.2 absent:是否存在
当指标存在时返回空(无数据);当指标不存在时返回 1。
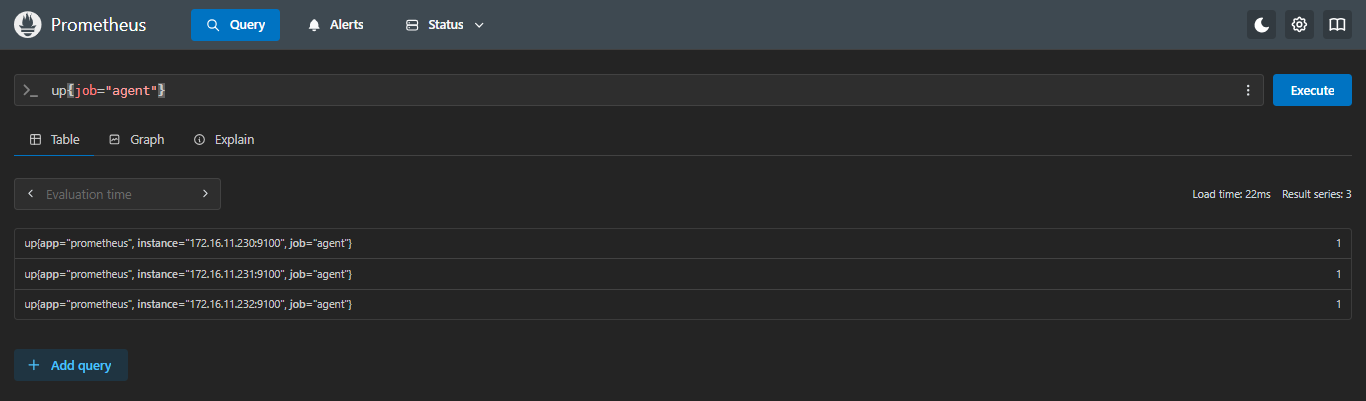
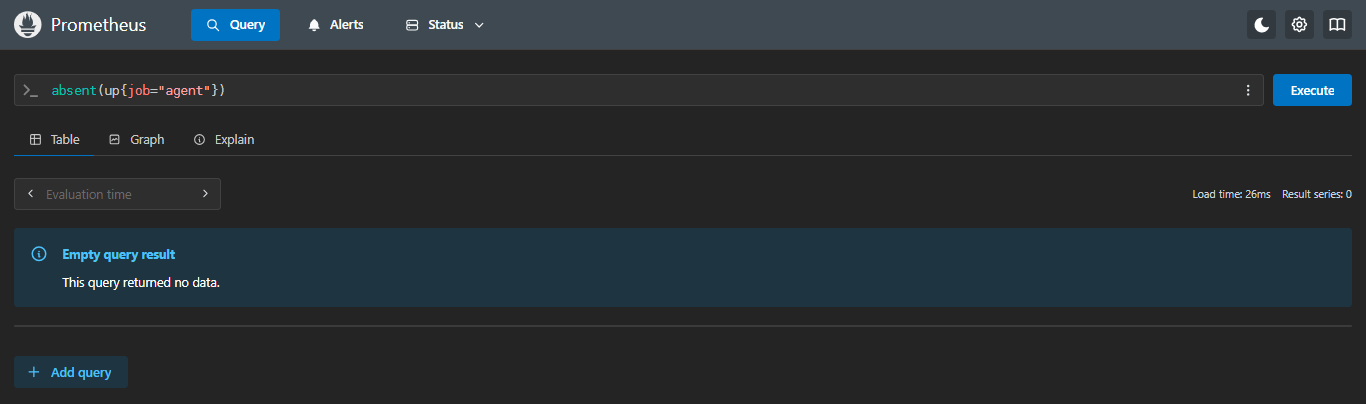
示例:当指标存在时:返回空;
sql
absent(up{job="agent"})- 指标存在
- 返回结果为空
示例:当指标不存在时:返回1;
sql
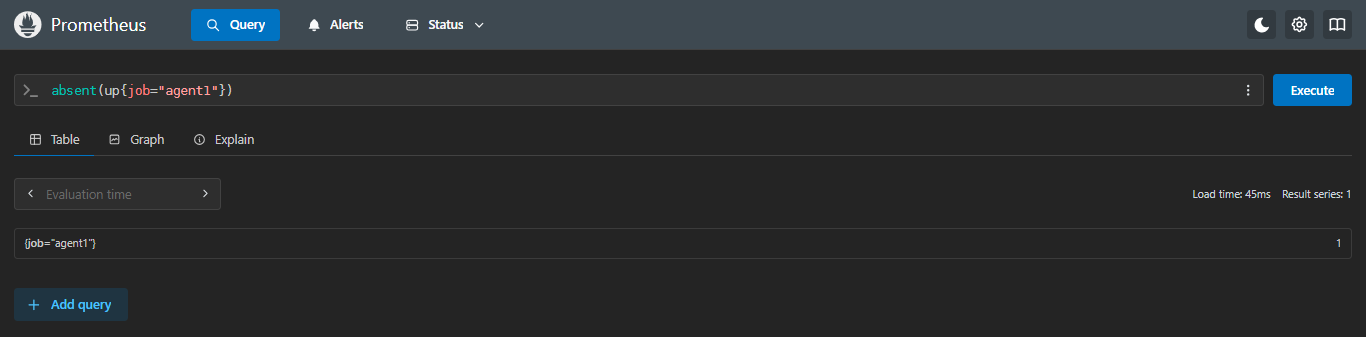
absent(up{job="agent1"})- 指标不存在
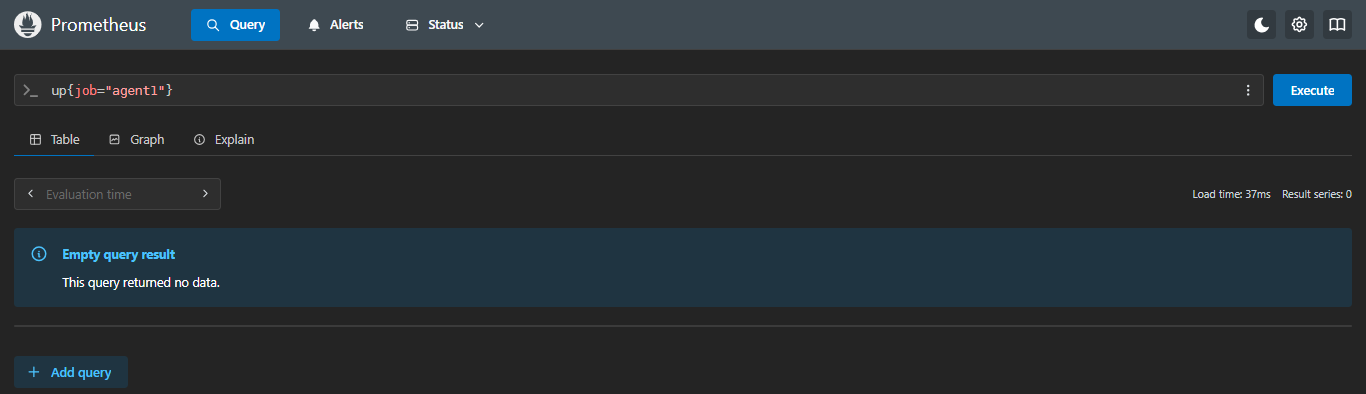
- 返回结果为:1
5.5.3 absent_over_time:过去是否存在
返回值和
absent是一样的,当指标存在时返回空(无数据);当指标不存在时返回 1。不过
absent_over_time主要是查看过去的时间是否存在;
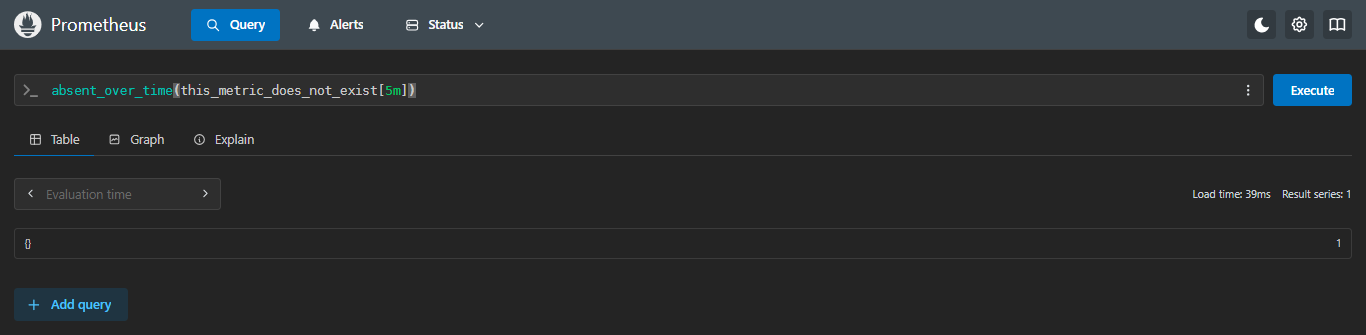
示例:查看是否有此指标
sql
absent_over_time(this_metric_does_not_exist[5m])因为这个指标是随便打的,所以分钟内都是不存在的,也就会返回1;
5.6 函数总结
| 函数类别 | 关键词记忆 |
|---|---|
| 速率类 | increase 是总量,rate 是平均,irate 是瞬时 |
| 取整类 | ceil 向上,floor 向下,round 四舍五入 |
| 排序类 | sort 升序,sort_desc 降序 |
| 其他类 | abs 绝对值,absent 是否存在(不存在返回 1) |
✅ 实战建议:
🔍 1. 用 irate 看 CPU 突发
promql
irate(node_cpu_seconds_total{mode="system"}[2m])适合看 瞬时飙升,比如 CPU 突然飙高但很快恢复的情况。
📊 2. 用 rate 看趋势
promql
rate(node_cpu_seconds_total{mode="system"}[5m])适合看 整体趋势,比如系统负载逐渐升高。
参考文档
| 文章标题 | 文章连接 |
|---|---|
| Prometheus官网基础查询 | https://prometheus.io/docs/prometheus/latest/querying/basics/ |
| Prometheus之PromQL用法详解 | https://blog.csdn.net/rainbowhhyhhy/article/details/122725139 |