1.普通哈希
假设一个场景:我们在一个分布式集群中有三台缓存服务器:node1,node2,node3,现在有大量存储数据的请求要求存储数据到这三台服务器组成的集群中,我们希望可以将这些数据均匀存储到三台服务器上,这时候我们应选择能实现负载均衡的方案。
首先最直接的方案就是直接使用哈希算法:对hash(key)%N,即对数据的Key进行哈希运算后取模,N是机器的数量;运算后的结构映射到对应集群中的节点。
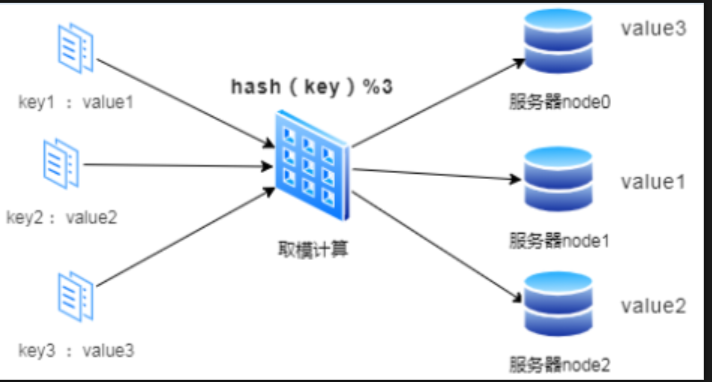
如上图所示,首先对key进行hash计算后的结果对3取模,得到的结果一定是0、1或者2;然后映射对应的服务器node0、node1、node2,最后直接找对应的服务器存取数据即可。
通过取模算法将每个数据请求都均匀的分散到了三个不同的服务器节点上,看起来很完美!但是,在分布式集群系统的负载均衡实现上,这种模型在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事,而服务器数量N发生变化后hash(key)%N计算的结果也会随之变化!导致整个集群的缓存数据必须重新计算调整,进而导致大量缓存在同一时间失效,造成缓存的雪崩,最终导致整个缓存系统的不可用,这是不能接受的。为了解决优化上述情况,一致性哈希算法应运而生。
2.一致性哈希简介
一致性哈希(Consistent Hash)算法是1997年提出,是一种特殊的哈希算法,目的是解决分布式系统的数据分区问题:当分布式集群移除或者添加一个服务器时,必须尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。
我们知道,传统的按服务器节点数量取模在集群扩容和收缩时存在一定的局限性。而一致性哈希算法正好解决了简单哈希算法在分布式集群中存在的动态伸缩的问题。降低节点上下线的过程中带来的数据迁移成本,同时节点数量的变化与分片原则对于应用系统来说是无感的,使上层应用更专注于领域内逻辑的编写,使得整个系统架构能够动态伸缩,更加灵活方便。
一致性哈希算法是分布式系统中的重要算法,使用场景也非常广泛。主要是是负载均衡、缓存数据分区等场景。
一致性哈希应该是实现负载均衡的首选算法,它的实现比较灵活,既可以在客户端实现,也可以在中间件上实现,比如日常使用较多的缓存中间件memcached 使用的路由算法用的就是一致性哈希算法。
此外,其它的应用场景还有很多:
- RPC框架Dubbo用来选择服务提供者
- 分布式关系数据库分库分表:数据与节点的映射关系
- LVS负载均衡调度器
3.一致性哈希实现原理
3.1 概述
前面介绍的取模算法虽然使用简单,但缺陷也很明显,如果服务器中保存有服务请求对应的数据,那么如果重新计算请求的哈希值,会造成缓存的雪崩的问题。这种情况在分布式系统中是非常糟糕的。一个设计良好的分布式系统应该具有良好的单调性,即服务器的添加与移除不会造成大量的哈希重定位,而一致性哈希恰好可以解决这个问题 。
其实,一致性哈希算法本质上也是一种取模算法。只不过前面介绍的取模算法是按服务器数量取模,而一致性哈希算法是对固定值2^32取模,这就使得一致性算法具备良好的单调性:不管集群中有多少个节点,只要key值固定,那所请求的服务器节点也同样是固定的。其算法的工作原理如下:
- 一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,整个哈希空间的取值范围为0~2^32-1;
- 计算各服务器节点的哈希值,并映射到哈希环上;
- 将服务发来的数据请求使用哈希算法算出对应的哈希值;
- 将计算的哈希值映射到哈希环上,同时沿圆环顺时针方向查找,遇到的第一台服务器就是所对应的处理请求服务器。
- 当增加或者删除一台服务器时,受影响的数据仅仅是新添加或删除的服务器到其环空间中前一台的服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他都不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性 。
3.2 实现方式
3.2.1 哈希环
首先,一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环。整个哈希空间的取值范围为0~2^32-1,按顺时针方向开始从0~2^32-1排列,最后的节点2^32-1在0开始位置重合,形成一个虚拟的圆环。
接下来,将服务器节点映射到哈希环上对应的位置。我们可以对服务器IP地址进行哈希计算,哈希计算后的结果对2^32取模,结果一定是一个0到2^32-1之间的整数。最后将这个整数映射在哈希环上,整数的值就代表了一个服务器节点的在哈希环上的位置。即:hash(服务器ip)% 2^32。下面我们依次将node0、node1、node2三个缓存服务器映射到哈希环上。
当服务器接收到数据请求时,首先需要计算请求Key的哈希值;然后将计算的哈希值映射到哈希环上的具体位置;接下来,从这个位置沿着哈希环顺时针查找,遇到的第一个节点就是key对应的节点;最后,将请求发送到具体的服务器节点执行数据操作。
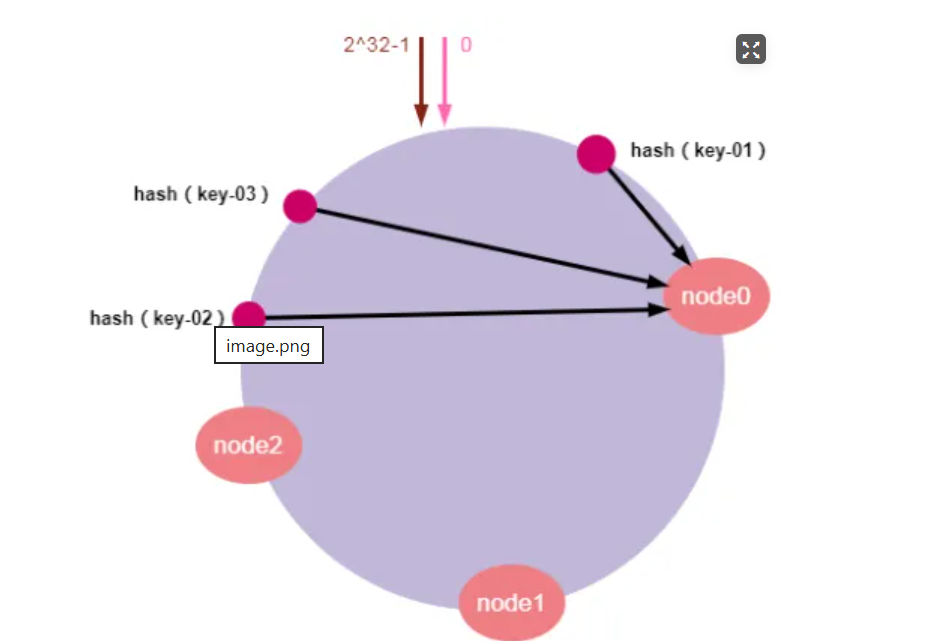
假设我们有"key-01:张三"、"key-02:李四"、"key-03:王五"三条缓存数据。经过哈希算法计算后,映射到哈希环上的位置如下图所示:
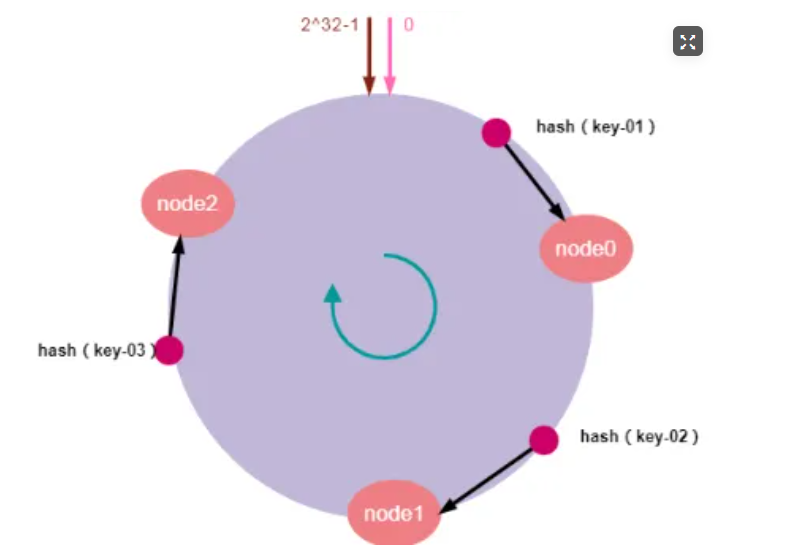
如上图所示,通过哈希计算后,key-01顺时针寻找将找到node0,key-02顺时针寻找将找到node1,key-03顺时针寻找将找到node2。最后,请求找到的服务器节点执行具体的业务操作。
3.2.2 服务器扩容
服务器扩容就是集群中需要增加一个新的数据节点,假设,由于需要缓存的数据量太大,必须对集群进行扩容增加一个新的数据节点。此时,只需要计算新节点的哈希值并将新的节点加入到哈希环中,然后将哈希环中从上一个节点到新节点的数据映射到新的数据节点即可。其他节点数据不受影响。新增节点后,前一个节点仍然使用,新增节点只会切割前一个节点的部分数据区间,前一个节点仍然保留未被切割的数据区间。
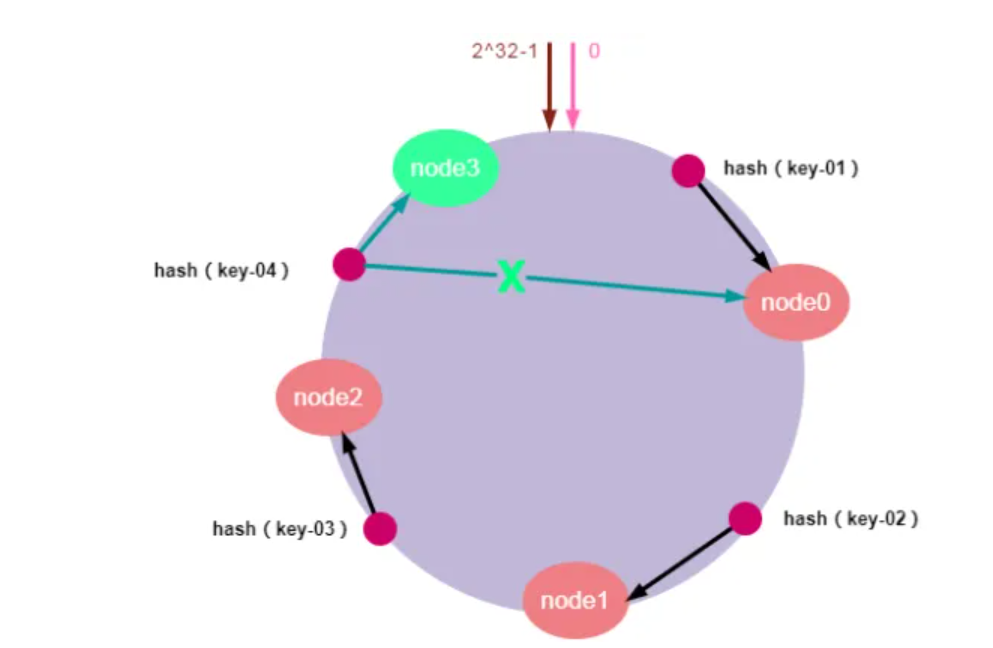
如上图所示,加入新的node3节点后,key-01、key-02不受影响,只有key-03的寻址被重定位到新节点node3,受影响的数据仅仅是会寻址到新节点和前一节点之间的数据。
通过一致性哈希算法,集群扩容或缩容时,只需要重新定位哈希环空间内的一小部分数据。其他数据保持不变。当节点数越多的时候,使用哈希算法时,需要迁移的数据就越多,使用一致哈希时,需要迁移的数据就越少。所以,一致哈希算法具有较好的容错性和可扩展性。
3.2.3 服务器缩容
服务器缩容就是减少集群中服务器节点的数量或是集群中某个节点故障。假设,集群中的某个节点故障,原本映射到该节点的请求,会找到哈希环中的下一个节点,数据也同样被重新分配至下一个节点,其它节点的数据和请求不受任何影响。这样就确保节点发生故障时,集群能保持正常稳定。
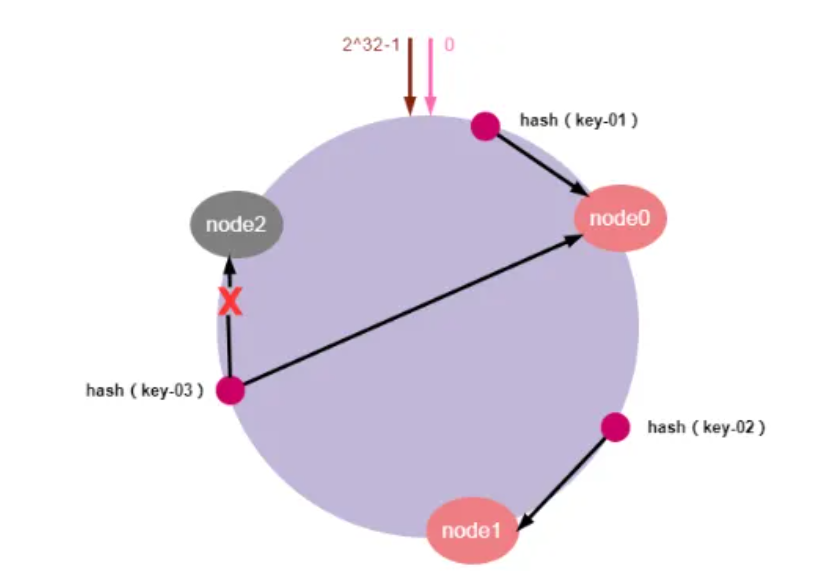
如上图所示:节点node2发生故障时,数据key-01和key-02不会受到影响,只有key-03的请求被重定位到node0。在一致性哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是会寻址到此节点和前一节点之间的数据。其他哈希环上的数据不会受到影响。
4.虚拟节点
4.1 数据倾斜问题
前面说了一致性哈希算法的原理以及扩容缩容的问题。但是,由于哈希计算的随机性,导致一致性哈希算法存在一个致命问题:数据倾斜,也就是说大多数访问请求都会集中少量几个节点的情况。特别是节点太少情况下,容易因为节点分布不均匀造成数据访问的冷热不均。这就失去了集群和负载均衡的意义。key-1、key-2、key-3可能被映射到同一个节点node0上。导致node0负载过大,而node1和node2却很空闲的情况。这有可能导致个别服务器数据和请求压力过大和崩溃,进而引起集群的崩溃。
4.2 虚拟节点
为了解决数据倾斜的问题,一致性哈希算法引入了虚拟节点机制,即对每一个物理服务节点映射多个虚拟节点,将这些虚拟节点计算哈希值并映射到哈希环上,当请求找到某个虚拟节点后,将被重新映射到具体的物理节点。虚拟节点越多,哈希环上的节点就越多,数据分布就越均匀,从而避免了数据倾斜的问题。
说起来可能比较复杂,一句话概括起来就是:原有的节点、数据定位的哈希算法不变,只是多了一步虚拟节点到实际节点的映射。具体如下图所示:
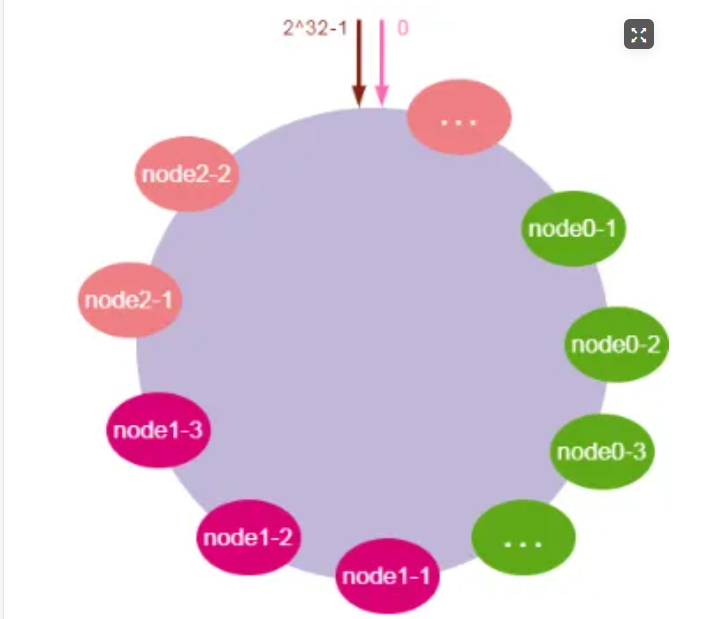
如上图所示,我们可以在服务器ip或主机名的后面增加编号来实现,将全部的虚拟节点加入到哈希环中,增加了节点后,数据在哈希环上的分布就相对均匀了。当有访问请求寻址到node0-1这个虚拟节点时,将被重新映射到物理节点node0。
5.代码实现
5.1 哈希算法设计
java
import java.util.Objects;
/**
* 哈希算法工具类
* 核心:实现FNV1_32_HASH算法,生成低碰撞、高均匀性的哈希值
* 用途:为一致性哈希的key和虚拟节点生成哈希值
*/
public class HashUtils {
/**
* FNV1_32_HASH算法实现(一致性哈希的核心哈希函数)
* FNV算法特点:分布均匀、计算速度快、碰撞率低,适合分布式哈希场景
* @param obj 要计算哈希的对象(key/虚拟节点标识)
* @return 正整数哈希值(范围:0 ~ 2^32-1)
*/
public static int hashcode(Object obj) {
// 空值校验:避免空指针异常
Objects.requireNonNull(obj, "哈希计算的对象不能为null");
// FNV1_32_HASH固定参数:质数p,减少哈希碰撞概率
final int p = 16777619;
// FNV1_32_HASH初始哈希值(固定魔数,保证初始值的散列性)
int hash = (int) 2166136261L;
// 将对象转为字符串(统一哈希计算的输入格式)
String str = obj.toString();
// 逐字符计算哈希:异或+乘法,增强散列性
for (int i = 0; i < str.length(); i++) {
// 异或当前字符的ASCII值 → 打乱哈希值
// 乘以质数p → 扩大哈希值的分布范围
hash = (hash ^ str.charAt(i)) * p;
}
// 位运算混合:进一步打乱哈希值,降低碰撞概率
hash += hash << 13; // 左移13位后相加
hash ^= hash >> 7; // 右移7位后异或
hash += hash << 3; // 左移3位后相加
hash ^= hash >> 17; // 右移17位后异或
hash += hash << 5; // 左移5位后相加
// 保证哈希值为正整数:避免负哈希值影响TreeMap的有序性
if (hash < 0) {
hash = Math.abs(hash);
}
// 返回最终哈希值
return hash;
}
}5.2 服务器节点设计
java
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;
/**
* 一致性哈希的物理节点封装类
* 包含:节点IP、虚拟节点哈希列表、节点本地缓存(模拟真实存储)
*/
public class Node {
/**
* 每个物理节点对应的虚拟节点数量(经验值:200个可保证数据均匀分布)
* 虚拟节点作用:解决物理节点数量少导致的数据分布不均问题
*/
private static final int VIRTUAL_NODE_NO_PER_NODE = 200;
/**
* 物理节点的唯一标识(IP地址)
* final修饰:保证节点IP不可修改,避免哈希环映射混乱
*/
private final String ip;
/**
* 当前物理节点的所有虚拟节点哈希值列表
* 每个虚拟节点对应一个哈希值,最终映射到哈希环上
*/
private final List<Integer> virtualNodeHashes = new ArrayList<>(VIRTUAL_NODE_NO_PER_NODE);
/**
* 节点本地缓存(模拟真实场景中的Redis/Memcached数据存储)
* Key-Value结构:存储当前节点负责的缓存数据
*/
private final Map<Object, Object> cacheMap = new HashMap<>();
/**
* 构造方法:初始化物理节点,生成虚拟节点哈希值
* @param ip 节点IP地址(非空)
*/
public Node(String ip) {
// 空值校验:IP是节点核心标识,不能为空
Objects.requireNonNull(ip, "节点IP不能为null");
this.ip = ip;
// 初始化虚拟节点哈希值列表
initVirtualNodes();
}
/**
* 初始化虚拟节点:为当前物理节点生成指定数量的虚拟节点,并计算哈希值
* 虚拟节点命名规则:IP#序号(如10.2.1.0#1),保证全局唯一
*/
private void initVirtualNodes() {
// 虚拟节点唯一标识(IP+序号)
String virtualNodeKey;
// 循环生成200个虚拟节点
for (int i = 1; i <= VIRTUAL_NODE_NO_PER_NODE; i++) {
// 生成虚拟节点唯一标识:避免不同物理节点的虚拟节点哈希冲突
virtualNodeKey = ip + "#" + i;
// 计算虚拟节点的哈希值,并添加到列表中
virtualNodeHashes.add(HashUtils.hashcode(virtualNodeKey));
}
}
/**
* 向当前节点的本地缓存添加数据
* @param key 缓存键
* @param value 缓存值
*/
public void addCacheItem(Object key, Object value) {
cacheMap.put(key, value);
}
/**
* 从当前节点的本地缓存获取数据
* @param key 缓存键
* @return 缓存值(不存在返回null)
*/
public Object getCacheItem(Object key) {
return cacheMap.get(key);
}
/**
* 从当前节点的本地缓存删除数据
* @param key 缓存键
*/
public void removeCacheItem(Object key) {
cacheMap.remove(key);
}
/**
* 获取当前节点的所有虚拟节点哈希值列表(只读)
* @return 虚拟节点哈希值列表
*/
public List<Integer> getVirtualNodeHashes() {
return virtualNodeHashes;
}
/**
* 获取物理节点的IP地址
* @return 节点IP
*/
public String getIp() {
return ip;
}
/**
* 重写toString:方便日志打印和调试,显示节点IP
* @return 节点IP字符串
*/
@Override
public String toString() {
return "Node{" + "ip='" + ip + '\'' + '}';
}
}5.3 一致性哈希实现
java
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.TreeMap;
/**
* 一致性哈希核心算法实现类
* 核心功能:维护哈希环、管理节点(增删)、实现key到节点的映射
* 哈希环实现:基于TreeMap(红黑树),支持O(logN)时间复杂度查找节点
*/
public class ConsistentHash {
/**
* 哈希环:有序映射(虚拟节点哈希值 → 物理节点)
* TreeMap特性:键有序,支持快速查找"大于等于指定哈希值的第一个节点"
*/
private final TreeMap<Integer, Node> hashRing = new TreeMap<>();
/**
* 所有物理节点列表:用于遍历节点、删除节点等批量操作
*/
public List<Node> nodeList = new ArrayList<>();
/**
* 增加物理节点
* 逻辑:为节点生成虚拟节点,将所有虚拟节点映射到哈希环上
* @param ip 节点IP地址(非空)
*/
public void addNode(String ip) {
// 空值校验:IP不能为空
Objects.requireNonNull(ip, "新增节点的IP不能为null");
// 创建物理节点对象(内部会初始化虚拟节点)
Node node = new Node(ip);
// 将物理节点添加到节点列表
nodeList.add(node);
// 遍历当前节点的所有虚拟节点,将"虚拟节点哈希 → 物理节点"映射到哈希环
for (Integer virtualNodeHash : node.getVirtualNodeHashes()) {
hashRing.put(virtualNodeHash, node);
// 日志打印:方便调试,查看虚拟节点添加情况
System.out.println("虚拟节点[" + node + "] hash:" + virtualNodeHash + ",被添加");
}
}
/**
* 移除物理节点(注意:原代码存在缺陷,已补充完整逻辑)
* 逻辑:1.从节点列表移除 2.从哈希环移除所有对应虚拟节点
* @param node 要移除的物理节点
*/
public void removeNode(Node node) {
// 空值校验
Objects.requireNonNull(node, "移除的节点不能为null");
// 1. 从节点列表中移除物理节点
nodeList.remove(node);
// 2. 从哈希环中移除该节点的所有虚拟节点映射(原代码遗漏此步骤)
for (Integer virtualNodeHash : node.getVirtualNodeHashes()) {
hashRing.remove(virtualNodeHash);
System.out.println("虚拟节点[" + node + "] hash:" + virtualNodeHash + ",被移除");
}
}
/**
* 根据key获取缓存数据
* 逻辑:先找到key对应的节点 → 从节点本地缓存获取数据
* @param key 缓存键
* @return 缓存值(不存在返回null)
*/
public Object get(Object key) {
// 找到key匹配的物理节点
Node node = findMatchNode(key);
// 日志打印:方便调试,查看key映射的节点
System.out.println("获取到节点:" + node.getIp());
// 从节点本地缓存获取数据
return node.getCacheItem(key);
}
/**
* 向缓存添加数据
* 逻辑:先找到key对应的节点 → 向节点本地缓存添加数据
* @param key 缓存键
* @param value 缓存值
*/
public void put(Object key, Object value) {
// 找到key匹配的物理节点
Node node = findMatchNode(key);
// 向节点本地缓存添加数据
node.addCacheItem(key, value);
}
/**
* 从缓存删除数据
* 逻辑:先找到key对应的节点 → 从节点本地缓存删除数据
* @param key 缓存键
*/
public void evict(Object key) {
// 找到key匹配的物理节点,并删除对应数据
findMatchNode(key).removeCacheItem(key);
}
/**
* 一致性哈希核心算法:找到key对应的物理节点
* 规则:计算key的哈希值 → 找哈希环上顺时针最近的虚拟节点 → 映射到物理节点
* @param key 缓存键
* @return 匹配的物理节点
*/
private Node findMatchNode(Object key) {
// 空值校验
Objects.requireNonNull(key, "查找节点的key不能为null");
// 1. 计算key的哈希值
int keyHash = HashUtils.hashcode(key);
// 2. 找哈希环上≥keyHash的第一个虚拟节点(ceilingEntry = 天花板Entry)
// TreeMap的ceilingEntry方法:O(logN)时间复杂度,高效查找
Map.Entry<Integer, Node> entry = hashRing.ceilingEntry(keyHash);
// 3. 闭环处理:如果keyHash大于哈希环所有虚拟节点的哈希值,取哈希环第一个节点
if (entry == null) {
entry = hashRing.firstEntry();
}
// 4. 返回虚拟节点对应的物理节点
return entry.getValue();
}
}5.4 测试
java
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
/**
* 一致性哈希算法测试类
* 测试场景:
* 1. 初始化多个节点,验证数据均匀分布
* 2. 随机读取数据,验证数据正确性
* 3. 新增节点,验证数据迁移(仅少量数据映射到新节点)
*/
public class ConsistentHashTest {
/**
* 初始化物理节点数量
*/
public static final int NODE_SIZE = 10;
/**
* 测试用缓存数据数量(10000条)
*/
public static final int STRING_COUNT = 100 * 100;
/**
* 一致性哈希实例(全局唯一)
*/
private static ConsistentHash consistentHash = new ConsistentHash();
/**
* 测试用缓存key列表
*/
private static List<String> sList = new ArrayList<>();
/**
* JDK原生随机数生成器(替代RandomUtils)
*/
private static final Random RANDOM = new Random();
/**
* 随机字符串的字符集(字母+数字)
*/
private static final String CHARACTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
public static void main(String[] args) {
// ========== 阶段1:初始化物理节点 ==========
System.out.println("===== 初始化物理节点 =====");
for (int i = 0; i < NODE_SIZE; i++) {
// 生成节点IP:10.2.1.0 ~ 10.2.1.9
String ip = new StringBuilder("10.2.1.").append(i).toString();
// 添加节点到一致性哈希环
consistentHash.addNode(ip);
}
// ========== 阶段2:生成测试用缓存数据(JDK原生实现随机字符串) ==========
System.out.println("\n===== 生成测试用缓存数据 =====");
for (int i = 0; i < STRING_COUNT; i++) {
// 生成10位随机字母数字字符串作为缓存key(替代RandomStringUtils.randomAlphanumeric(10))
sList.add(generateRandomAlphanumeric(10));
}
// ========== 阶段3:将数据存入一致性哈希缓存 ==========
System.out.println("\n===== 将数据存入缓存 =====");
for (String s : sList) {
// 键值一致:方便验证数据正确性
consistentHash.put(s, s);
}
// ========== 阶段4:随机读取数据,验证正确性(JDK原生实现随机索引) ==========
System.out.println("\n===== 随机读取数据,验证正确性 =====");
for (int i = 0; i < 10; i++) {
// 随机选择一个key的索引(替代RandomUtils.nextInt(0, STRING_COUNT))
int index = generateRandomInt(0, STRING_COUNT);
String key = sList.get(index);
// 从缓存读取数据
String cache = (String) consistentHash.get(key);
// 打印结果:验证读取的值与原始值是否一致
System.out.println("Random:" + index + ",key:" + key + ",consistentHash get value:" + cache + ",value is:" + key.equals(cache));
}
// ========== 阶段5:输出节点及数据分布(简化版:打印节点IP) ==========
System.out.println("\n===== 初始化后节点列表 =====");
for (Node node : consistentHash.nodeList) {
System.out.println("节点IP:" + node.getIp());
}
// ========== 阶段6:新增节点,验证数据迁移 ==========
System.out.println("\n===== 新增物理节点(10.2.1.110) =====");
consistentHash.addNode("10.2.1.110");
// ========== 阶段7:新增节点后,随机读取数据 ==========
System.out.println("\n===== 新增节点后,随机读取数据 =====");
for (int i = 0; i < 10; i++) {
int index = generateRandomInt(0, STRING_COUNT);
String key = sList.get(index);
String cache = (String) consistentHash.get(key);
System.out.println("Random:" + index + ",key:" + key + ",consistentHash get value:" + cache + ",value is:" + key.equals(cache));
}
// ========== 阶段8:输出新增节点后的节点列表 ==========
System.out.println("\n===== 新增节点后节点列表 =====");
for (Node node : consistentHash.nodeList) {
System.out.println("节点IP:" + node.getIp());
}
}
/**
* 替代RandomStringUtils.randomAlphanumeric(int):生成指定长度的随机字母数字字符串
* @param length 字符串长度
* @return 随机字母数字字符串
*/
private static String generateRandomAlphanumeric(int length) {
// 空值/负数校验
if (length <= 0) {
return "";
}
StringBuilder sb = new StringBuilder(length);
for (int i = 0; i < length; i++) {
// 随机选择字符集的索引
int randomIndex = RANDOM.nextInt(CHARACTERS.length());
// 追加字符
sb.append(CHARACTERS.charAt(randomIndex));
}
return sb.toString();
}
/**
* 替代RandomUtils.nextInt(int start, int end):生成[start, end)范围内的随机整数
* @param start 起始值(包含)
* @param end 结束值(不包含)
* @return 随机整数
*/
private static int generateRandomInt(int start, int end) {
// 边界校验:保证start < end
if (start >= end) {
throw new IllegalArgumentException("起始值必须小于结束值:start=" + start + ", end=" + end);
}
// 生成[start, end)的随机数:nextInt(end - start) 生成[0, end-start),加上start后就是[start, end)
return start + RANDOM.nextInt(end - start);
}
}