M-ASK 论文解读:超越单体架构的多智能体搜索与知识优化框架
一句话总结:M-ASK 通过将智能体搜索解耦为"搜索行为代理"和"知识管理代理"两类五个专门角色,并采用轮次级密集奖励机制,彻底解决了单体架构在复杂问答任务中的训练崩溃问题,实现了稳定且高效的智能体搜索。
📖 目录
- 引言:智能体搜索的困境
- 核心问题:单体架构的三大顽疾
- [M-ASK 框架:分工协作的智能体军团](#M-ASK 框架:分工协作的智能体军团)
- 技术细节:结构化知识状态与奖励机制
- 实验结果:稳定性与性能的双重突破
- 消融实验:每个组件都不可或缺
- 实际应用与复现思考
- 总结与未来展望
1. 引言:智能体搜索的困境
什么是智能体搜索(Agentic Search)?
想象一下,你问一个 AI 助手:"DeepSeek 和 OpenAI 在 2024 年分别发布了哪些重要模型?它们的技术路线有什么区别?"
传统的 RAG(检索增强生成)系统会:
- 把你的问题丢给搜索引擎
- 取回一堆文档
- 让 LLM 基于这些文档生成答案
但这种方式有个致命问题:一次检索往往不够。复杂问题需要多轮推理和检索,每一步的检索结果都可能影响下一步的搜索方向。
这就是智能体搜索 (Agentic Search)的用武之地------让 LLM 像一个真正的研究员一样,在推理过程中主动规划搜索策略、执行检索、分析结果、决定是否需要进一步搜索。
研究背景
近年来,以 Search-R1 为代表的智能体搜索系统通过强化学习(RL)让 LLM 学会了自主调用搜索引擎进行多轮推理。这些系统在问答任务上取得了显著进步,但它们都面临一个共同的问题:训练极不稳定。
本文要介绍的 M-ASK(Multi-Agent Search and Knowledge)框架,来自中国人民大学和百度的研究团队,正是为了解决这一核心问题而生。
论文信息:
- 标题:Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
- 作者:Yiqun Chen, Lingyong Yan, Zixuan Yang, Erhan Zhang, Jiashu Zhao, Shuaiqiang Wang, Dawei Yin, Jiaxin Mao
- 机构:中国人民大学、百度
- 代码开源 :https://github.com/chenyiqun/M-ASK
2. 核心问题:单体架构的三大顽疾
在深入 M-ASK 之前,我们需要理解它要解决的问题到底有多棘手。
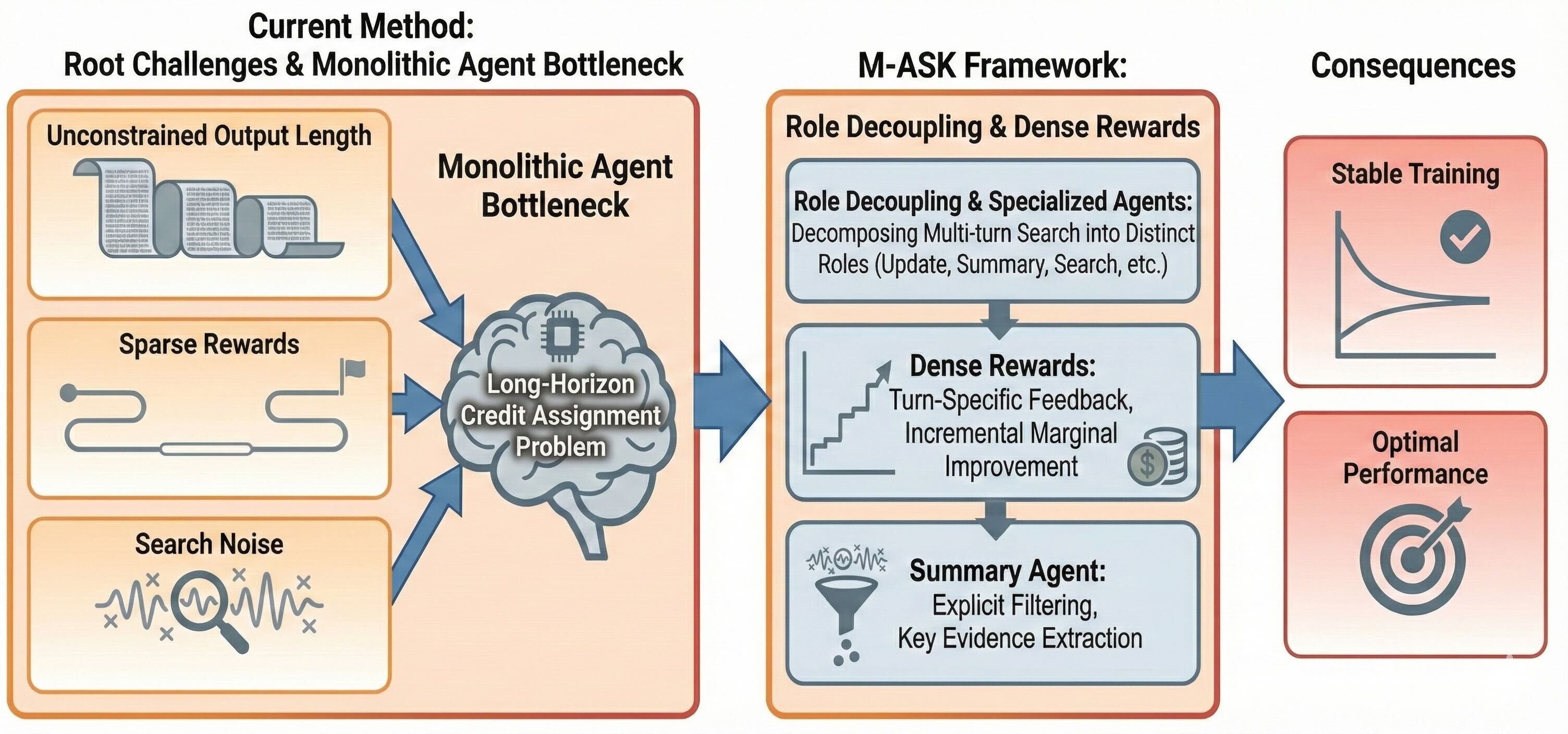
图1:当前单体智能体搜索方法的挑战与 M-ASK 解决方案对比。左侧展示了单体架构面临的三大结构性瓶颈:(1) 不受限制的推理输出导致轨迹过长、信息密度低;(2) 稀疏的结果级奖励导致长时距信用分配困难;(3) 随机的搜索噪声与 RL 探索噪声叠加,训练信号极不稳定。右侧展示了 M-ASK 如何通过角色解耦(将任务分解为 5 个专门代理)和轮次级密集奖励(每一轮迭代都给予反馈)来彻底解决这些问题。
2.1 不受限制的推理输出(Unbounded Reasoning Outputs)
生活化比喻:想象一个员工被要求写一份报告,但没有人给他字数限制和格式要求。结果他洋洋洒洒写了几万字,其中真正有用的信息可能只有几百字。
在单体架构中,LLM 需要同时处理:
- 规划搜索策略
- 生成搜索查询
- 分析检索结果
- 维护推理链
- 生成最终答案
所有这些任务都由一个模型在一个长序列中完成。这导致:
- 轨迹过长:模型输出可能达到数千甚至上万 token
- 信息密度低:大量冗余信息混杂在关键推理步骤中
- 梯度方差大:长序列导致 RL 训练时梯度估计不稳定
2.2 稀疏的结果级奖励(Sparse Outcome-Level Reward)
生活化比喻:想象一个厨师学做一道复杂的菜,但老师只在他做完整道菜后说"好吃"或"不好吃",从不告诉他哪个步骤做得对或错。这样学习效率会非常低,因为厨师不知道问题出在选材、切配、火候还是调味。
在智能体搜索中,传统方法只在最后根据答案是否正确给予奖励。但一个多步搜索任务可能包含:
- 初始规划
- 多轮搜索查询
- 多次信息提取
- 最终答案生成
如果只有最终奖励,模型很难知道哪个中间步骤做得好,哪个需要改进。这就是强化学习中经典的信用分配问题(Credit Assignment Problem)。
2.3 随机的搜索噪声(Stochastic Search Noise)
生活化比喻:想象你正在学习如何研究一个课题,但每次你用同样的关键词搜索,搜索引擎都给你完全不同的结果------有时有用,有时全是垃圾信息。在这种情况下,你很难判断是你的搜索策略有问题,还是只是运气不好。
真实的搜索引擎具有高度的随机性:
- 相同的查询可能返回不同的结果
- 检索质量波动大
- 噪声信息可能淹没关键证据
这种随机性与 RL 中固有的策略探索噪声叠加,导致训练信号极不稳定,模型容易陷入"模式崩溃"(Mode Collapse)。
惊人的崩溃率
论文中的实验数据触目惊心:
| 方法 | 1000步时崩溃率 |
|---|---|
| Search-r1 (单体架构) | 90% |
| M-ASK (多智能体) | 0% |
也就是说,10 次独立训练中,单体架构有 9 次会在 1000 步左右崩溃,而 M-ASK 一次都不会崩溃!
3. M-ASK 框架:分工协作的智能体军团
M-ASK 的核心思想很朴素:既然一个人干不好,那就分工合作。
M-ASK 框架的整体架构包含两部分:
- 推理时的工作流程(Rollout) :Planning Agent 首先初始化知识状态 K 0 \mathcal{K}_0 K0,然后 Search Agent 决定是否需要检索,Summary Agent 从检索结果中提取关键证据,Update Agent 更新推理轨迹,Answer Agent 生成当前答案------这个循环不断迭代直到 Search Agent 决定终止
- 训练时的奖励分配机制(Training) :Planning 和 Answer Agent 获得基于绝对 F1 分数的奖励,而 Search、Summary、Update 三个代理共享边际改进收益 Δ F 1 \Delta F_1 ΔF1,激励紧密协作
3.1 两类五个专门代理
M-ASK 将智能体搜索任务解耦为两类代理:
🔍 搜索行为代理(Search Behavior Agents, SBA)
负责规划和执行搜索动作:
| 代理名称 | 角色定位 | 核心功能 |
|---|---|---|
| Planning Agent | 系统初始化器 | 根据用户问题生成初始推理轨迹和初步答案 |
| Search Agent | 导航员 | 评估当前信息是否充分,决定继续搜索还是终止 |
| Answer Agent | 求解器 | 基于当前推理轨迹综合生成最终答案 |
📚 知识管理代理(Knowledge Management Agents, KMA)
负责聚合、过滤和维护紧凑的内部上下文:
| 代理名称 | 角色定位 | 核心功能 |
|---|---|---|
| Summary Agent | 过滤器 | 从检索文档中提取关键证据,丢弃噪声 |
| Update Agent | 状态精炼器 | 决定如何更新推理轨迹:原地修正还是扩展新步骤 |
3.2 结构化知识状态(Structured Knowledge State)
五个代理如何协作?答案是通过一个共享的结构化知识状态 K t \mathcal{K}_t Kt:
json
{
"question": "原始用户问题",
"thinking_trajectory": [
{"sub_query": "子问题1", "sub_answer": "子答案1"},
{"sub_query": "子问题2", "sub_answer": "子答案2"},
...
],
"predicted_answer": "当前预测的最终答案"
}这个设计有几个巧妙之处:
- 信息共享:所有代理都能看到当前的推理状态
- 紧凑表示:轨迹被压缩为(子问题, 子答案)的元组序列,避免冗余
- 可追溯:每一步推理都有迹可循,便于调试和分析
3.3 一次搜索迭代的工作流程
让我们通过一个具体例子来理解 M-ASK 的工作流程。
用户问题:"谁导演了《泰坦尼克号》?这位导演的其他代表作有哪些?"
第 0 步:Planning Agent 初始化
Planning Agent 接收到问题后,调用其参数化记忆(即 LLM 的预训练知识)生成初始推理轨迹:
thinking_trajectory: [
{"sub_query": "《泰坦尼克号》的导演是谁?", "sub_answer": "詹姆斯·卡梅隆"},
{"sub_query": "詹姆斯·卡梅隆的其他代表作", "sub_answer": "不确定具体作品"}
]
predicted_answer: "詹姆斯·卡梅隆导演了《泰坦尼克号》,但我不确定他的其他代表作。"第 1 步:Search Agent 决策
Search Agent 评估当前轨迹:
- "第一个子问题已有答案"
- "第二个子问题答案不确定"
- 决策:生成搜索查询 "詹姆斯·卡梅隆 代表作品 导演作品列表"
第 2 步:执行检索
搜索引擎返回一堆文档,可能包含:
- 詹姆斯·卡梅隆的维基百科页面
- 电影评论网站的导演作品列表
- 无关的新闻报道
第 3 步:Summary Agent 提取证据
Summary Agent 从检索结果中提取关键信息:
证据 E: "詹姆斯·卡梅隆的主要导演作品包括:《终结者》(1984)、
《终结者2》(1991)、《泰坦尼克号》(1997)、《阿凡达》(2009)、
《阿凡达2》(2022)。"第 4 步:Update Agent 更新状态
Update Agent 决定如何整合新证据:
操作: <Update>τ_2</Update>
更新后的 thinking_trajectory: [
{"sub_query": "《泰坦尼克号》的导演是谁?", "sub_answer": "詹姆斯·卡梅隆"},
{"sub_query": "詹姆斯·卡梅隆的其他代表作",
"sub_answer": "《终结者》、《终结者2》、《阿凡达》、《阿凡达2》等"}
]第 5 步:Answer Agent 生成答案
Answer Agent 综合当前轨迹生成最终答案:
predicted_answer: "《泰坦尼克号》由詹姆斯·卡梅隆导演。
他的其他代表作包括《终结者》系列、《阿凡达》系列等。"第 6 步:Search Agent 再次决策
Search Agent 评估更新后的轨迹:
- 信息已足够完整
- 决策 :输出
<end>终止搜索
3.4 参数共享策略
一个重要的设计细节:五个代理共享同一个 LLM 骨干(如 Qwen2.5-7B-Instruct)。
不同代理通过不同的系统指令来区分角色:
python
PLANNING_PROMPT = "你是一个规划专家,根据用户问题生成初始推理轨迹..."
SEARCH_PROMPT = "你是一个搜索决策专家,评估当前信息是否充分..."
SUMMARY_PROMPT = "你是一个信息提取专家,从文档中提取关键证据..."
UPDATE_PROMPT = "你是一个状态更新专家,决定如何整合新证据..."
ANSWER_PROMPT = "你是一个答案生成专家,综合推理轨迹生成最终答案..."这种设计的好处:
- 参数效率:只需训练一个模型,而非五个
- 知识共享:不同角色可以利用相同的基础知识
- 易于部署:推理时只需加载一个模型
4. 技术细节:结构化知识状态与奖励机制
4.1 形式化建模:顺序去中心化 Dec-POMDP
M-ASK 将多智能体搜索任务建模为顺序去中心化部分可观察马尔可夫决策过程(Sequential Decentralized POMDP):
- 状态空间 S \mathcal{S} S :所有可能的知识状态 K \mathcal{K} K 的集合
- 动作空间 A i \mathcal{A}_i Ai :每个代理 i i i 可执行的动作(生成文本)
- 观察空间 O i \mathcal{O}_i Oi:每个代理能看到的信息(知识状态 + 代理特定输入)
- 转移函数 P P P:环境如何响应代理动作(检索结果等)
- 奖励函数 R R R:如何评估当前状态的好坏
4.2 轮次级密集奖励(Turn-Level Dense Rewards)
这是 M-ASK 最核心的技术创新之一。
传统方法的问题
传统的智能体搜索只在最后给予奖励:
r = 1 answer = ground_truth r = \mathbb{1}\\text{answer} = \\text{ground\\_truth} r=1answer=ground_truth
这种稀疏奖励在长序列任务中会导致严重的信用分配问题。
M-ASK 的解决方案:混合奖励机制
M-ASK 设计了两种类型的奖励:
1. 基于状态的奖励(State-Based Reward)------绝对 F1
针对 Planning Agent 和 Answer Agent,直接评估当前答案的质量:
r p l a n = F 1 ( a 0 , y ) r_{plan} = F_1(a_0, y) rplan=F1(a0,y)
r a n s ( t ) = F 1 ( a t , y ) r_{ans}^{(t)} = F_1(a_t, y) rans(t)=F1(at,y)
其中:
- a t a_t at 是第 t t t 步的预测答案
- y y y 是真实答案
- F 1 F_1 F1 是 F1 分数(精确度和召回率的调和平均)
直觉解释:这就像给员工一个明确的 KPI------你生成的答案与正确答案的匹配度。
2. 基于转移的奖励(Transition-Based Reward)------共享增量收益
针对 Search Agent、Summary Agent 和 Update Agent,评估它们的协作效果:
r i t e r ( t ) = r a n s ( t ) − r a n s ( t − 1 ) = F 1 ( a t , y ) − F 1 ( a t − 1 , y ) r_{iter}^{(t)} = r_{ans}^{(t)} - r_{ans}^{(t-1)} = F_1(a_t, y) - F_1(a_{t-1}, y) riter(t)=rans(t)−rans(t−1)=F1(at,y)−F1(at−1,y)
这三个代理在每一轮迭代中共享这个边际改进收益。
直觉解释:这就像一个销售团队------不管是谁找到了客户、谁谈成了合同、谁维护了关系,只要这个月业绩比上个月好,整个团队都能拿到奖金。这种机制激励团队紧密协作,而不是各自为战。
为什么这个设计有效?
- 及时反馈:每一轮迭代都有奖励,不需要等到最后
- 信用分配:Search-Summary-Update 三个代理共享收益,避免了复杂的贡献分解
- 激励协作:只有当三个代理协同工作良好时,整体才能获得正向奖励
- 抑制噪声:如果某次检索结果很差,Update Agent 可以选择不更新,避免引入噪声
4.3 训练算法:Independent PPO
M-ASK 使用 Independent PPO 进行优化,即每个代理独立地使用 PPO 算法更新参数(由于参数共享,实际上是同一个模型在不同角色下的更新)。
PPO 目标函数:
L ( θ ) = E ( s , a ) ∼ π θ o l d min ( π θ ( a ∣ s ) π θ o l d ( a ∣ s ) A π θ o l d ( s , a ) , clip ( ⋅ , 1 − ϵ , 1 + ϵ ) A π θ o l d ( s , a ) ) \mathcal{L}(\theta) = \mathbb{E}{(s,a) \sim \pi{\theta_{old}}} \left \\min \\left( \\frac{\\pi_\\theta(a\|s)}{\\pi_{\\theta_{old}}(a\|s)} A\^{\\pi_{\\theta_{old}}}(s,a), \\text{clip}(\\cdot, 1-\\epsilon, 1+\\epsilon) A\^{\\pi_{\\theta_{old}}}(s,a) \\right) \\right L(θ)=E(s,a)∼πθoldmin(πθold(a∣s)πθ(a∣s)Aπθold(s,a),clip(⋅,1−ϵ,1+ϵ)Aπθold(s,a))
值函数损失:
L ( ϕ ) = E s ∼ π θ o l d ( V ϕ ( s ) − R ( s ) ) 2 \mathcal{L}(\phi) = \mathbb{E}{s \sim \pi{\theta_{old}}} \left (V_\\phi(s) - R(s))\^2 \\right L(ϕ)=Es∼πθold(Vϕ(s)−R(s))2
其中 A π ( s , a ) A^{\pi}(s,a) Aπ(s,a) 是优势函数, V ϕ V_\phi Vϕ 是状态值函数(Critic)。
5. 实验结果:稳定性与性能的双重突破
5.1 实验设置
数据集:
- 单跳问答:Natural Questions (NQ)、PopQA、AmbigQA
- 多跳问答:HotpotQA、2WikiMultiHopQA、Musique、Bamboogle
基线方法:
- 非智能体方法:Direct、RAG、IRCoT
- 单体智能体方法:ReAct、Search-o1、Search-r1
- 多智能体方法:DeepNote、M-ASK(本文)
骨干模型:Qwen2.5-7B-Instruct
搜索引擎:Wikipedia 语料库 + Contriever 检索器
5.2 主要性能对比
在 7 个问答数据集上的 F1 分数对比,包括 3 个单跳数据集(NQ、PopQA、AmbigQA)和 4 个多跳数据集(HotpotQA、2Wiki、Musique、Bamboogle)。对比了非智能体方法(Direct、RAG、IRCoT)、单体智能体方法(ReAct、Search-o1、Search-r1)和多智能体方法(DeepNote、M-ASK)。M-ASK 在多跳任务上表现尤为突出,总平均 F1 达到 50.09,显著领先于其他方法。
关键发现:
| 方法 | 单跳平均 | 多跳平均 | 总平均 |
|---|---|---|---|
| Direct (无检索) | 35.66 | 22.02 | 27.91 |
| RAG | 43.07 | 28.75 | 34.93 |
| Search-r1 | 55.41 | 35.64 | 43.91 |
| DeepNote | 59.29 | 39.03 | 46.79 |
| M-ASK | 59.24 | 43.70 | 50.09 |
核心观察:
- 多跳任务优势明显 :M-ASK 在多跳问答上比 Search-r1 高出 +8.06 F1 点 ,比 DeepNote 高出 +4.67 F1 点
- HotpotQA 表现突出 :在最具挑战性的 HotpotQA 数据集上,M-ASK 达到 44.83 F1 ,比最佳基线高 +5.82 点
- 泛化能力强:在未见过的数据集(2Wiki、Musique)上也表现优异
5.3 训练稳定性分析
这是本文最令人印象深刻的结果。
训练曲线对比
下面展示了 HotpotQA 数据集上 M-ASK 与 Search-r1 的训练动态对比:
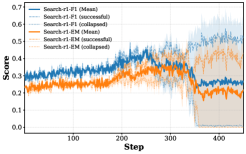
图2a:Search-r1 在 HotpotQA 上的训练动态------横轴为训练步数(step 100-400),可以观察到训练过程中的不稳定性。
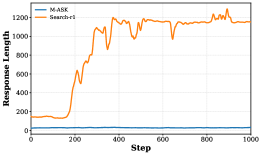
图2b:平均响应长度对比------Search-r1 的输出长度随训练不断膨胀(可达 1200 tokens),而 M-ASK 始终保持在约 200-400 tokens 的紧凑范围,显示了多智能体架构在控制输出长度上的优势。
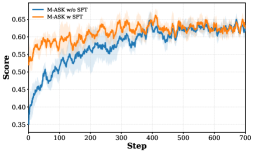
图2c:M-ASK 在 HotpotQA 上的训练动态------F1 分数从 0.35 稳定上升到 0.65,展示了稳定且持续上升的收敛曲线,方差极小。
训练崩溃现象
论文进行了 10 次独立训练实验,结果令人震惊:
| 方法 | 1000步时崩溃率 | 平均输出长度 |
|---|---|---|
| Search-r1 | 90% | 6000+ tokens (膨胀) |
| M-ASK | 0% | ~200 tokens (稳定) |
崩溃的原因分析
Search-r1 等单体方法为什么会崩溃?论文分析了三个相互强化的因素:
- 上下文膨胀:模型在长轨迹中迷失方向,输出越来越长
- 噪声累积:检索噪声不断积累,污染推理过程
- 梯度方差爆炸:长序列 + 稀疏奖励 = 梯度估计极不稳定
M-ASK 为什么稳定?
- 角色解耦:每个代理只负责一个小任务,输出短且精确
- 知识压缩:KMA 代理持续过滤噪声,维护紧凑的上下文
- 密集奖励:每一轮都有反馈,避免长程信用分配问题
6. 消融实验:每个组件都不可或缺
论文通过消融实验验证了各组件的必要性。
6.1 知识管理代理的作用
实验:移除 KMA(Summary + Update Agent),让模型直接使用原始检索结果
| 配置 | 单跳平均 | 多跳平均 | 总平均 |
|---|---|---|---|
| M-ASK (完整) | 59.24 | 43.70 | 50.09 |
| w/o KMA | 59.63 | 40.84 | 48.27 |
结论:
- 单跳任务影响不大(甚至略有提升)
- 多跳任务下降 2.86 F1 点
- 说明 KMA 对于过滤噪声、维护复杂推理至关重要
6.2 轮次级奖励的作用
实验:移除轮次级奖励,改用传统的最终奖励
| 配置 | 单跳平均 | 多跳平均 | 总平均 |
|---|---|---|---|
| M-ASK (完整) | 59.24 | 43.70 | 50.09 |
| w/o T-L Reward | 62.11 | 28.47 | 41.99 |
结论:
- 单跳任务反而提升(因为单跳不需要多步信用分配)
- 多跳任务暴跌 15.23 F1 点!
- 证明密集奖励对于长序列任务的绝对必要性
6.3 消融实验的启示
这两个消融实验揭示了一个重要规律:
任务复杂度越高,结构化分解和密集反馈越重要
对于简单的单跳问答,单体架构和稀疏奖励或许能够应付。但一旦任务需要多步推理,传统方法就会迅速崩溃。
7. 实际应用与复现思考
7.1 核心设计原则
从 M-ASK 中,我们可以提炼出几个在构建智能体搜索系统时值得借鉴的设计原则:
原则 1:角色解耦胜于大一统
传统思路 :让一个强大的 LLM 完成所有任务
M-ASK 思路:将任务分解为多个专门角色
这类似于软件工程中的"单一职责原则"------每个模块只做一件事,做到最好。
原则 2:紧凑状态胜于完整历史
传统思路 :保留所有历史信息,让模型自己筛选
M-ASK 思路:主动压缩和过滤,维护紧凑的知识状态
这解决了两个问题:
- 上下文长度限制
- 模型在长上下文中的注意力分散
原则 3:密集反馈胜于稀疏奖励
传统思路 :只在最后评估结果
M-ASK 思路:每一步都给予反馈
这是强化学习的基本常识,但在智能体搜索领域往往被忽视。
7.2 复现建议
如果你想复现或扩展 M-ASK,以下是一些实用建议:
硬件需求
- 训练:至少 4×A100 80GB(论文使用的配置)
- 推理:单张 A100 或 4090 应该可以运行
关键超参数
python
# 基于论文描述的推测值
config = {
"backbone": "Qwen2.5-7B-Instruct",
"max_iterations": 5, # 最大搜索迭代次数
"max_tokens_per_agent": 512, # 每个代理最大输出长度
"ppo_clip": 0.2,
"learning_rate": 1e-5,
"batch_size": 128,
"retrieval_top_k": 5, # 每次检索返回的文档数
}工程技巧
- 温度调度:训练初期使用较高温度鼓励探索,后期降低以稳定
- KL 惩罚:防止模型偏离预训练分布太远
- 梯度裁剪:避免长序列导致的梯度爆炸
7.3 潜在改进方向
1. 动态代理激活
当前 M-ASK 在每次迭代中都调用所有代理。可以设计一个"路由器"来决定哪些代理需要激活,减少不必要的计算。
2. 异构代理
目前所有代理共享同一个 LLM。可以尝试:
- Summary Agent 使用更小的模型(专注提取)
- Planning Agent 使用更大的模型(专注推理)
3. 强化学习算法升级
Independent PPO 是比较基础的多智能体 RL 算法。可以尝试:
- MAPPO(多智能体 PPO)
- QMIX(基于值分解的方法)
- 通信机制学习
4. 奖励工程
当前使用 F1 分数作为奖励信号。可以探索:
- 中间步骤的语义相关性奖励
- 搜索效率奖励(更少的迭代次数)
- 多样性奖励(避免重复搜索)
8. 总结与未来展望
8.1 核心贡献回顾
M-ASK 在智能体搜索领域做出了三个重要贡献:
- 架构创新:首次将智能体搜索显式解耦为搜索行为代理和知识管理代理两类角色
- 训练机制:提出轮次级密集奖励,有效解决长序列任务中的信用分配问题
- 稳定性突破:将训练崩溃率从 90% 降低到 0%,这对于实际应用至关重要
8.2 局限性
论文也坦诚地讨论了 M-ASK 的局限性:
- 计算成本:多智能体工作流增加了 LLM 调用次数,延迟和成本较高
- 任务覆盖:目前只在文本 QA 任务上验证,代码生成、多模态推理等领域待探索
- 角色设计:五个代理的分工是否最优?是否可以更细或更粗?
8.3 未来展望
M-ASK 代表了智能体搜索从"单打独斗"到"团队协作"的范式转变。未来可能的发展方向包括:
- 自适应架构:让模型自己学习如何分工,而不是人为设计固定的角色
- 多模态扩展:将框架扩展到图像、视频、代码等多模态检索场景
- 在线学习:在实际使用中持续优化,而不仅仅是离线训练
- 规模化验证:在更大的模型(70B+)和更复杂的任务上验证
8.4 对从业者的启示
如果你正在构建智能体搜索或复杂 AI 系统,M-ASK 提供了一个重要的教训:
不要试图让一个模型做所有事情。分解任务、明确职责、及时反馈------这些软件工程的基本原则在 AI 系统设计中同样适用。
当你的系统变得不稳定时,不要一味地增加模型规模或训练数据。试着问自己:
- 任务是否可以分解?
- 中间状态是否足够紧凑?
- 反馈是否足够及时?
M-ASK 用实验数据证明:这些看似"常识"的原则,确实能带来巨大的差异。
📚 参考资料
- 论文原文 : Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
- 代码仓库 : https://github.com/chenyiqun/M-ASK
- Search-R1 论文: Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
- Qwen2.5 模型 : https://github.com/QwenLM/Qwen2.5