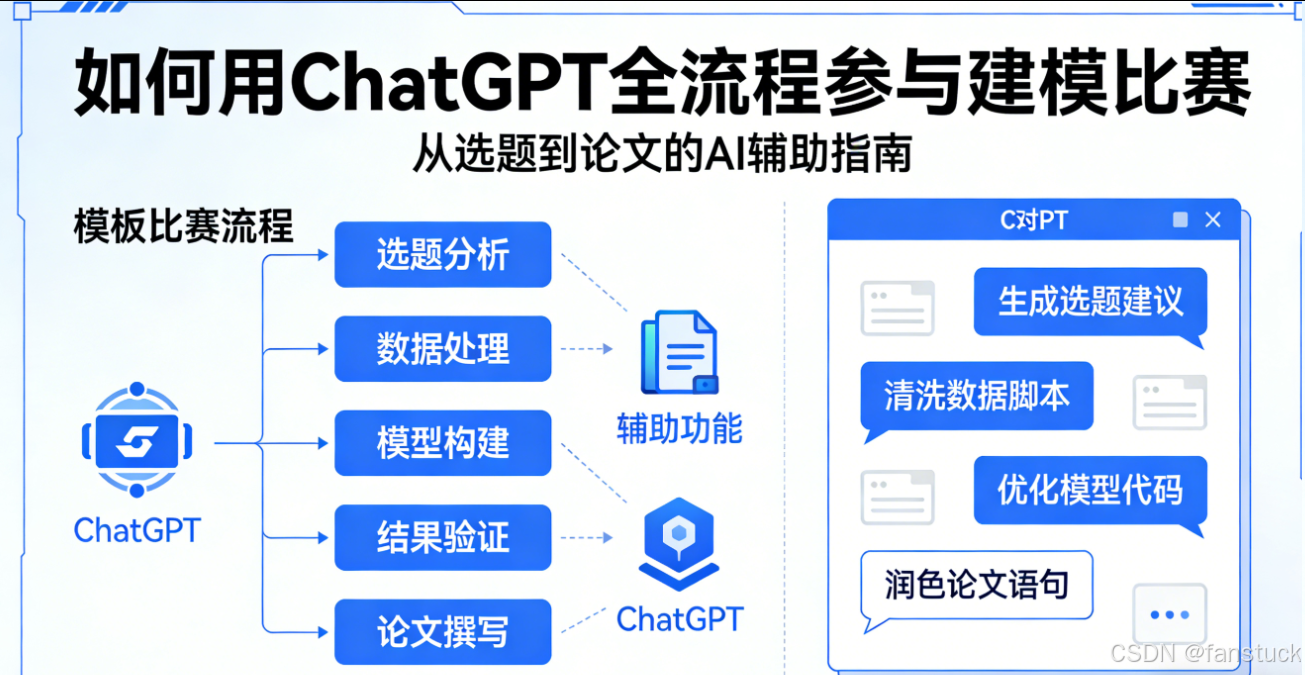
在我真正开始用 AI 参与一场数学建模比赛之前,我对它的预期其实不高。
一开始,它不过是我们计划中的"润色工具人":负责最后三页的英语论文润色、生成几张美观的图表,顺便润色一下摘要。
但 96 小时后,我彻底改观。
我们把它从"文书外包"拉到了模型设计现场。当队伍卡在"怎么定义公平""用哪个模型能说服评委""怎么写才能让论文有结构"这些问题上时,AI 给出的建议,居然让我们少走了不少弯路。
它不会替你决策,但它能帮你理清你真正需要决策的是什么。
这篇文章不会兜售"AI 无所不能"的故事,而是更实用地复盘我们是怎么在 MCM 比赛里用 ChatGPT 辅助完成建模任务的:
-
它怎么帮我们拆清楚题目,避免走题;
-
它如何参与模型方案比选,明确假设边界;
-
它怎么协助我们写出结构清晰的论文,让评委能迅速看懂决策逻辑;
-
它在哪些地方真的派上了用场,在哪些场景完全不行;
-
以及我们实际使用的 prompt 案例(全公开)
写这篇文章,是因为我想说一句实话:
ChatGPT 无法让你"速成建模高手",但它能帮你更早拥有"像工程师一样思考"的方式。
尤其是对于初次参加建模比赛,或者希望更系统化推进建模流程的人来说,把 AI 当成"智能合作者"而不是"万能外挂",你会真正意识到:这不是什么捷径,而是方法论的升级。
一、ChatGPT 是怎么参与建模拆题的?它不是"抢答",而是"澄清者"
真正让我们愿意信任 AI 的,是在赛题刚发布时,它比我们更冷静。
我们参加的是 2023 年 MCM 比赛,当时拿到的题目是关于多地点服务设施的最优选址问题(E 题)。刚看完题目的时候,我们脑子里全是关键词:
-
多目标优化?NP 难问题?
-
该不该建模成线性规划?还是遗传算法?
-
这是不是那个 Facility Location Problem 的改版?
但是经验告诉我们,一旦直接跳模型,很容易走题。我们决定先停下来,让 AI 帮我们**"反向解构题目"**:
Prompt 案例 #1:让 AI 做"题目拆分器"
"你现在是一个有多年 MCM 教学经验的建模教练。请你只做一件事:不要推荐模型,只从建模角度分析这个赛题的核心任务有哪些、难点在哪、信息缺失在哪、可能的风险点有哪些。"
ChatGPT 的回答非常像一个经验丰富的助教,它并没有直接推荐模型,而是条理清晰地拆解任务:
-
哪些目标函数是明确的,哪些是隐性的;
-
哪些输入数据缺失,可能需要假设补充;
-
哪些指标是可以量化建模的,哪些则需要归一处理;
-
哪些场景(如"多个紧急响应点同时请求服务")需要特殊建模,而不是当作均值处理;
-
有无时间维度、有无多目标之间的 trade-off 讨论空间......
这一步帮我们从"关键词堆砌"转变为"任务清单梳理"。更重要的是,它帮我们意识到一件事:
建模不是直接选模型,而是先搞清楚你在试图回答哪个问题。
ChatGPT 帮我们补了哪些"题目逻辑断层"?
比赛中经常遇到的一种情况是:题面看起来清楚,但要建模的时候一堆模糊点。比如:
-
"最优"到底怎么定义?是平均响应时间最小?还是最大覆盖率?有无 trade-off?
-
题目说可以建多种类型设施,但每种设施间有没有共享资源?有没有建设成本?
-
目标区域是抽象地图,是否要投影到真实地理结构?是否考虑地形/交通网络?
这些问题,有些是经验能想到的,但在比赛紧张氛围中很容易忽略。而我们通过下面的 prompt,让 ChatGPT 成为一个**"假设敏感度探测器"**:
Prompt 案例 #2:让 AI 扮演"假设挑战者"
"请你扮演一位建模评审专家,从建模严谨性的角度出发,帮我列出这个问题中可能存在但未显式说明的假设有哪些?并指出这些假设如果不成立,可能会对模型结果造成什么影响。"
这一步的效果是:ChatGPT 不再是"告诉你做什么",而是帮你思考"哪些假设如果不澄清,你的模型会崩"。
我们原以为"建设设施的服务半径固定"是理所当然,但它提醒我们:如果服务半径随设施类型或建设预算变化,模型就需要引入动态边界条件。
这类讨论直接反映到我们的模型选择上:是否要做多阶段优化?是否要加"软约束"而非硬性限制?
这一步 AI 真正起作用的地方是:
-
它不是替你"定义问题",而是逼你"澄清问题";
-
它不会提出最优模型,但能清楚列出你要决策的变量与结构;
-
它不会省略细节,而是从评审视角让你提前"踩坑"。
比起"我来告诉你怎么做",AI 更像一个冷静得近乎残酷的"建模合伙人":它时刻提醒你,模型能否说服别人,靠的不是你做了什么,而是你为什么这么做。
二、模型选型:ChatGPT 帮我们补的是"决策证据"
数学建模从来不是"答题",而是"做决策"。
做建模比赛的人,最熟的一句话可能就是:
"这个问题可以尝试用 XX 模型,比如线性规划、灰色预测、层次分析法......"
但这恰恰是建模新手最容易栽的坑:模型名字你都认识,真正难的是"什么时候用、为什么用、怎么组合"。
而 ChatGPT 在这一环的价值,不是"提供模板",而是变成你身边那个最懂 trade-off 的技术合伙人。
Prompt 案例 #3:不是问"用什么模型",而是问"建模选型有哪些分歧点"
我们在比赛中遇到的核心问题,是要在多个设施点中选址,兼顾服务效率和资源成本。而我们的问题不是"用什么模型",而是:
-
如果目标是覆盖率最大,是不是就该用整数规划?
-
如果我们考虑不确定性因素(需求波动),是不是要用鲁棒优化?
-
如果评委看重的是"清晰解释"而不是"高精度预测",是不是更该用分层模型+可解释指标?
-
如果不同模型得出的结果相左,哪个更可信?
我们给 ChatGPT 的 prompt 是这样的:
"请你从建模结构设计角度分析:在处理一个选址优化类问题时,线性规划、层次分析法、遗传算法、贪心启发式、模拟退火等模型适用于什么条件?这些模型各自在哪些限制条件下会出错?如果要组合使用,它们能如何协同?"
结果比我们预期的更有帮助。它没有给出"最优解",但列出了几种典型场景-模型的配对逻辑,比如:
| 问题特征 | 推荐模型 | 原因解释 |
|---|---|---|
| 明确约束、目标函数可线性表示 | 线性/整数规划 | 易于求解,结果可解释 |
| 无法表达精确约束、目标不单一 | 启发式算法(如遗传) | 适合非凸搜索、全局探索 |
| 需要快速原型、结构直观 | 贪心策略 + 灵敏度分析 | 便于调参和时间控制 |
| 存在目标优先级不明确 | AHP / 层次加权模型 | 有助于指标融合和主观判断融合 |
| 多方案之间缺乏比较指标 | TOPSIS / 模糊评价 | 可构建统一评分尺度 |
一次模型选择中的博弈过程:我们经历的真实分歧
我们三人组其实最早倾向用一个三阶段优化模型搞定:
-
第一阶段:基于地理位置初筛(聚类或最近邻算法)
-
第二阶段:布点后做局部优化(遗传算法)
-
第三阶段:利用蒙特卡洛模拟不确定因素,检验鲁棒性
这套方案听起来挺高大上,但 ChatGPT 问了我们一句:
"这个方案每个阶段都需要训练和调参,是否在比赛时间内能控制好调试成本?如果遗传算法未收敛,你的兜底方案是什么?"
这直接点醒我们:我们的方案复杂度很高,但鲁棒性不够。于是我们改成了"双轨建模":主模型采用简化优化 + 灵敏度分析,辅助用启发式策略覆盖边界场景。
这种"主-辅模型配合"的策略,也是 ChatGPT 多次推荐的结构框架之一:主模型保证主逻辑清晰可解释,辅模型用来"救场"和处理极端情况。
Prompt 案例 #4:结构设计 + 多模型协同
"我想构建一个组合模型结构,主模型是线性规划用于最优设施配置,辅模型是规则策略用于处理边界/异常情景,请帮我梳理如何组织结构和写清楚它们的配合关系。"
ChatGPT 给出了非常工程化的建议,类似我们后期用于写论文的结构逻辑:
-
建模目标与任务拆分
-
主模型作用及假设边界
-
辅模型使用场景与触发条件
-
模型间接口变量与数据流
-
整体评估指标与模型切换标准
这一套结构让我们写作时少走很多弯路,而且更容易向评委讲清楚**"我们不是模型套娃,而是分工明确、结构清晰。"**
小结:ChatGPT 在模型阶段带来的提升
| 作用点 | 人工容易忽视的问题 | ChatGPT 提供的增益 |
|---|---|---|
| 选型取舍 | 只看模型名字,不看约束/数据/目标匹配 | 提供结构图谱、适配边界 |
| 模型组合 | 忽略模型间逻辑不一致 | 提供"主-辅模型协同"框架 |
| 时间控制 | 只考虑效果,不考虑可实现性 | 帮你评估调参和求解成本 |
| 假设验证 | 没有回头验证模型是否合理 | 提出需要回测和灵敏度分析的部分 |
AI 不会告诉你唯一解法,但它能始终帮你抓住"你到底在为哪个目标做决策"。
三、协作写作:ChatGPT 是团队里最冷静的线索梳理者
如果你参加过建模比赛,一定见过这种"论文修罗场":
-
模型做出来了,每个人都说"我来写我那一段"
-
写着写着发现:有些模型写了两遍,有些压根没人写
-
摘要写完发现结论和正文完全对不上
-
格式不一致,有人用 LaTeX,有人 Word,有人 Markdown
-
论文主线像拼图,最后只能靠队长硬怼一遍通宵大改
这时候,不是缺"文字能力",而是缺一个人把论文当"产品说明书"去看待:有没有说清楚我们做了什么、为什么做、做得怎么样。
ChatGPT 正是填这个空缺的绝佳选手。
Prompt 案例 #5:我们让它做"结构线索检查员"
我们的做法是这样的:
当我们三个人各自写完自己负责的一节后,把三个部分都贴进 ChatGPT,提问如下:
"请你检查下面三段建模论文是否存在以下问题:
各节之间是否存在逻辑跳跃或模型重复;
是否清楚交代了假设、输入数据和变量定义;
是否有'我们做了什么'但没解释'为什么这么做'的地方;
语言风格是否统一;
能否给出一个建议的统一写作框架。"
你别说,它真的逐条检查,还指出了很多我们自己忽略的点,比如:
-
"第二节的假设 B 在第一节中未提前提出"
-
"第三节结果部分的数据单位与前文不一致"
-
"第一节使用'本文'视角,第三节变成了'我们'视角"
-
"第二节用了多个'我们提出了一个新的模型',但未说明它解决了前文哪种不足"
它不仅能指出问题,还建议了修改方式,例如:
"建议所有模型介绍采用统一模板:模型目的 → 假设 → 变量说明 → 数学结构 → 结果与意义"。
这不就是我们理想中论文主线设计师的样子吗?
Prompt 案例 #6:润色不是堆辞藻,是提炼结构主语
我们还会让它做"建模语法润色"。但我们发现,与其说让它"美化语言",不如说让它"强化结构表达"。
举个例子,我们原文写的是:
"我们通过构建一个预测模型,分析了未来趋势,并对其做了敏感性分析。"
ChatGPT 改写成:
"为预测未来趋势,我们构建了一个多因素回归模型,并通过敏感性分析验证其稳定性。"
从"过程描述"转变为"目的导向",主语变成"模型",而非"我们"。
这种改写方式不仅更专业,也更符合工程报告/建模论文的写作风格------把建模过程当成一种设计流程,而非实验流水账。
我们后来甚至把这个 prompt 固化成模板:
"请将以下段落润色为数学建模论文风格,要求清晰交代每一段的目的、方法与结果,语气克制,语言偏工程/技术报告风格。"
Prompt 案例 #7:一稿成文式摘要生成器
还有最管用的一个用途,就是在论文写完后,请它用下面这个 prompt 来"写一个摘要草稿":
"以下是我们数学建模论文的正文内容,请你根据建模任务、方法、结果,写一段不超过 300 字的摘要,要求包括背景、问题目标、主要方法、关键结果和结论,语言客观克制。"
效果出奇地好,至少是一个 80 分的草稿。
我们再人工精修,通常两轮就能定稿。而不是像以前一样反复改 10 版,越改越乱。
小结:ChatGPT 在协作写作中的真正作用
| 团队痛点 | ChatGPT 解决方式 |
|---|---|
| 多人写作风格不一致 | 检查人称统一、语气风格 |
| 模型描述跳跃 | 强化因果链、补足前后文线索 |
| 内容结构割裂 | 给出统一结构模板建议 |
| 论文主线不清 | 强化"我们为什么这么做"的表达 |
| 摘要难写 | 快速生成摘要初稿,提高起点 |
在这个阶段,我们逐渐明白:
ChatGPT 不是"更快写完",而是"让写作变成结构性创作,而不是靠堆字数"。
四、代码生成与验证:ChatGPT 是工具箱,不是自动驾驶仪
很多人用 AI 帮忙写代码,图的是一个"快"字。但在建模比赛里,"快"从来不是终点------尤其当你用 ChatGPT 写模型代码,它写得再多,不如你理解得清。
这节我们主要讲两个问题:
-
ChatGPT 在建模建模时,到底该怎么用?
-
哪些环节可以交给它?哪些反而容易踩坑?
Prompt 案例 #8:用它"还原数学公式的代码骨架"
比赛现场,我们常有这种场景:
"我们决定用 logistic 回归建个分类模型,但变量多、权重设定复杂,一时不知道该怎么写。"
这时我们不会直接问 "帮我写一个 logistic 回归模型",而是用更清晰的提问:
"请帮我写出一个 Python 函数,用来实现如下结构的逻辑回归模型,包含变量 w1--w6、输入为矩阵 X、输出为概率预测值,要求可扩展到多分类。"
ChatGPT 会写出标准逻辑回归骨架,并在代码中标明各变量含义、如何调整。我们只需要替换具体数据,或者手动调整权重设定。
关键点在于:我们先有数学结构,再用它写代码,而不是反过来"想看看它能生成什么模型"。
Prompt 案例 #9:代码验证器,帮你"交叉检查推导是否正确"
还有一种常见用途,是当我们自己写出一个模型,想看看 ChatGPT 有没有更简洁、更规范的写法,或者能不能 catch 到我们公式里有疏漏。
我们会这样提问:
"下面是我们为某资源调度问题设计的线性规划模型,请你根据变量定义,帮我们检查约束条件是否冗余或缺失,并重新整理为标准 LP 格式。"
这个 prompt 帮了我们大忙。在一次调度题中,我们忘记加了一个"资源不可重复分配"的约束,ChatGPT 直接指出了这一点,并给出了修正建议。
它甚至能识别我们变量的维度冲突,比如你把 t 写成了 scalar,后面却当作向量用了,它会提醒"下标可能冲突"。
换句话说:
它不是给你"最优代码",而是帮你"把建模推理补完"。
Prompt 案例 #10:这些时候,千万不要直接用它的代码
ChatGPT 再强,也不是懂竞赛上下文的模型工程师。
以下几类场景,我们测试后发现,它给出的代码不能直接信赖:
情况1:多阶段联动的模型求解流程
比如你做一个"预测-调度"类问题,模型流程是:
-
先用时间序列预测未来供需;
-
再将预测值作为输入,进行优化求解。
如果你直接让 ChatGPT "写一个供需调度模型",它通常会假定数据是已知的,忽略掉前面预测部分的不确定性,也不会建一个多阶段流程的"pipeline"。
它写出的只是"一个静态优化",和你的"预测-决策"联动模型,是两个概念。
情况2:涉及不完整假设的复杂动态仿真
我们有一次做的是无人机调度问题,需要模拟无人机在山区火场中的路径和中继部署,ChatGPT 虽然能写出 A* 或最短路径算法代码,但它对"火场扩散""风力影响""飞行高度"等实际假设理解模糊,经常代码逻辑自洽但完全偏题。
我们后来统一处理是:
先由我们写好建模逻辑图、列出变量定义和更新流程,再让它协助填充代码细节或改写性能更优的实现。
小结:如何更"工程化"地使用 ChatGPT 写建模代码
| 使用方式 | 效果 | 建议用法 |
|---|---|---|
| 结构清晰的模型翻译为代码 | 高效准确 | 明确模型公式和变量先行,再请求代码 |
| 作为推导检查器 | 有效补盲点 | 请求审查变量定义、维度一致性、约束逻辑完整性 |
| 多模型联动或仿真 | 容易跑偏 | 不建议直接生成,建议手动控制流程结构 |
用一句话总结就是:
ChatGPT 是极强的结构实现工具,但它不懂你的比赛目标与建模主线。
真正的主线,永远在你脑中------它只是帮你写清楚,而不是替你决定怎么建。
五、建模能力的重构:你才是模型的提出者,AI 只是"回声"
我们见过太多人拿 ChatGPT 写论文、做模型,结果却越做越没主见。
不是工具不好用,而是用错了方向:本来该你做决策的地方,变成在等它给建议;该你思考逻辑的时候,却在反复 prompt 找"标准答案"。
但建模这件事最核心的能力,恰恰是你自己------能不能从一个模糊问题中,推演出结构、逻辑、解法。
这节我们来讲几个反向使用 ChatGPT的思维方式:不是它帮你建模,而是你借它"看见自己还没想清的部分"。
🧭 练习 1:我能不能复原一个"优秀论文"的建模逻辑?
我们平时经常训练一个技能:拿一篇 O 奖 / M 奖论文,把它"当作题目"来练习:
"我不看正文,只看摘要和结论部分,我能否推测出它的建模结构?"
这一步做完后,再将推测出的结构输入 ChatGPT:
"我准备将该问题分为 A、B、C 三个子任务,分别建模型,然后串联求解。请你假设我是这样做的,帮我补出中间各部分的变量、模型种类和因果逻辑。"
你会发现:它确实能生成一套逻辑自洽的结构,但同时你也会发现,它的设计与你刚才的推演有什么不同。
这些"不同"就是关键。
你不需要全盘接受它的方案,但你可以用来反问自己:"它为什么这样拆?它选的模型会不会比我的更稳定、更容易验证?"
这就是典型的**"反向工程式练习"**:你拿 ChatGPT 当作另一个模型思维者,去检视自己思考的缺口。
练习 2:我能不能把自己的模型"复述一遍"?
还有一个我们经常用的方式叫做:
"让 ChatGPT 帮我重写我的模型逻辑,看看它能不能复现我真正想表达的结构。"
很多时候你以为写清楚了,其实只是自己"懂自己"。
把你建好的模型框架描述交给它,prompt 像这样:
"我为某河流水资源调度设计了一套两阶段模型,第一阶段预测来水量,第二阶段做线性规划求最优分配。请你根据这个描述,用清晰的工程语言重写一遍逻辑和目的,适合写入论文或答辩中。"
ChatGPT 给出的内容,就是你模型的"表达镜像"。
你能立刻看到:
-
有哪些变量定义模糊?
-
有哪些逻辑它无法还原?
-
哪些地方需要你补充动机和限制条件?
这比你闷头检查代码、反复斟酌表述有效得多。
它就是一个"即时镜像反馈器"------你能不能清晰表达你的结构,它一试就知道。
练习 3:我能不能用 AI 工具训练自己的"建模套路"?
这是我们更长期的训练方式。
你可以把自己做过的题目模型结构、论文摘要、设计动机------统统存在一个文档里,然后用 RAG、Embedding 工具(甚至直接给 ChatGPT 喂过去)做一件事:
"给我复述一下我过去常用的模型拆解思路,是否存在模式?"
我们团队实际做过一版这样的 ChatGPT embedding 项目,它能识别出:
-
我们在做时间序列预测时,偏爱组合建模(ARIMA+ML)
-
在做空间调度时,总是先划分网格,再建局部最优模型
-
遇到突发资源问题时,习惯建兜底线性模型以保守解法
这些"套路"不是坏事,它们反而是你真正风格的体现。
但有了这些识别,你就可以进一步提升自己:
-
我能不能换个问题,尝试不同模型路径?
-
我能不能用反例去挑战我习惯的思维模式?
这才是 AI 最有用的地方:它不是替代你,而是让你"更清楚你是谁"。
小结:真正的建模者,从来不会迷信工具
你可以用 ChatGPT 快速生成模型骨架、代码模板、甚至帮你优化表达。
但真正决定问题怎么拆、结构怎么搭、结果怎么验证的,只有你。
AI 能带来效率、验证、反馈,但不能替代你的工程推理。
如果说写建模题是一场模拟的决策战,那你要做的不是"找到一套标准解",而是:
在高度不确定中,搭出一条可验证、可落地的逻辑路径。
用工具提升认知,而不是逃避判断 ------ 这是我们理解 AI 与建模关系的根本立场。