基于GPU的Spark应用加速 Cloudera CDP/华为CMP鲲鹏版+Nvidia联合解决方案
下载地址:
https://pan.baidu.com/s/1PDj6dySUNHotNABp7d1a0w?pwd=57is 提取码: 57is
查找"Hadoop信创",输入"CMP"恢复最新下载地址
博文末尾处有下载方式:
基于GPU的Apache Spark应用加速是当前大数据与AI融合的关键技术方向。Cloudera 与 NVIDIA 联合推出的 "Cloudera Data Platform + RAPIDS Accelerator for Apache Spark " 解决方案,为企业提供了一套无需修改代码、安全合规、可扩展且高性能的端到端GPU加速数据分析平台。以下从架构、能力、部署与价值四个维度系统阐述该联合解决方案。
一、解决方案核心组成
该方案深度融合了 Cloudera CDP 的企业级数据治理能力与 NVIDIA RAPIDS 的GPU加速引擎:
| 组件 | 提供方 | 功能 |
|---|---|---|
| Cloudera Data Platform(CDP) | Cloudera | 提供统一的数据湖仓、安全管控、多云编排、作业调度与治理(Ranger/Atlas) |
| RAPIDS Accelerator for Apache Spark | NVIDIA | 基于 cuDF 的 Spark SQL 插件,自动将支持的操作卸载到 GPU 执行 |
| NVIDIA GPU 集群(A100/V100/T4) | NVIDIA/硬件厂商 | 提供并行计算底座,支持大规模分布式GPU计算 |
| CUDA 与 UCX 通信库 | NVIDIA | 优化GPU内存管理与节点间GPU-to-GPU高速通信 |
如资料所述:"通过Cloudera和NVIDIA的这一技术整合......数据工程和数据科学工作流程以一半的成本获得了超过10倍的速度提升。"
二、关键技术能力
1. 零代码改造,自动GPU 加速
- 用户现有 Spark SQL、DataFrame 或 PySpark 应用无需任何代码修改;
- 仅需在 CDP 作业配置中启用插件:
--conf spark.plugins=com.nvidia.spark.SQLPlugin \
--conf spark.rapids.sql.enabled=true
- RAPIDS 插件在物理执行计划阶段自动识别支持的操作(如 Join、Sort、Agg、Window、Parquet Scan),将其重写为 GPU 算子;不支持的操作则回退至 CPU,确保兼容性 。
2. 端到端GPU 优化数据链路
- Parquet 列式读取加速:利用 cuDF 微内核技术,高效解析 Snappy 压缩列块,吞吐提升超 100% ;
- Shuffle 优化:集成 UCX(Unified Communication X),实现 GPU 显存直通传输,避免 Host 内存拷贝瓶颈 ;
- 内存池管理:RAPIDS 内置 GPU 显存池,减少频繁分配/释放开销,提升稳定性。
3. 企业级安全与治理集成
- 与 CDP 原生安全体系无缝对接:
- Ranger:控制谁可以提交 GPU 作业;
- Knox:保护 REST API 访问;
- Atlas:追踪 GPU 加速作业的数据血缘;
- 加密传输:支持 TLS 加密 Spark Shuffle 数据。
- 满足金融、政务等强监管行业对审计、权限、数据隔离的要求 。
4. 混合云与弹性调度
- 支持在 CDP Private Cloud (on-prem) 与 CDP Public Cloud (AWS/Azure) 上部署;
- 在 Kubernetes 环境中,通过 spark.executor.resource.gpu.amount=1 自动申请 GPU 资源 ;
- 结合 CDP 的 Auto Scaling,实现 GPU 资源按需伸缩,降低成本。
三、典型应用场景与性能收益
1. 金融风控与反欺诈
- 美国国税局案例:使用 Cloudera + NVIDIA 方案处理 300TB 交易日志,ETL 时间从数小时缩短至分钟级,整体提速 10 倍以上,成本降低 50% 。
- 实时特征工程:用户行为序列聚合、图关系挖掘(结合 cuGraph)在 GPU 上加速 8--15 倍 。
2. 智能营销与客户洞察
- 电商用户画像:每日 5TB 行为数据,ETL 从 4 小时 12 分降至 38 分钟(6.6x 加速),模型训练从 2.5 小时降至 18 分钟(8.3x)。
3. AI/ML 训练预处理
- 特征生成、数据清洗、采样等占 ML 流程 80% 时间的环节,在 GPU 上加速后显著缩短端到端训练周期;
- 支持与 XGBoost4j-GPU、cuML 集成,实现全链路 GPU 加速 。
四、部署架构建议
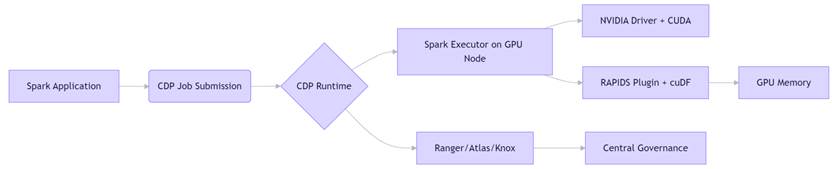
- 硬件要求:每节点至少 1 块 NVIDIA T4/V100/A100,PCIe 3.0+,32GB+ 显存;
- 软件栈:
- CDP 7.1.7+(含 Spark 3.2+)
- RAPIDS Accelerator 22.10+
- CUDA 11.0+
- Java 11 / Python 3.8+
- 资源配置:推荐 1 Executor : 1 GPU,Executor 内存设为 GPU 显存的 2--3 倍 。
五、总结:为什么选择 Cloudera + NVIDIA ?
| 维度 | 优势 |
|---|---|
| 易用性 | 零代码改造,现有 Spark 应用秒级 GPU 化 |
| 性能 | 核心算子加速 5--10 倍,端到端作业提速 6--10 倍 |
| 成本 | 单 GPU 可替代多台 CPU 服务器,能耗降低 3.8 倍 |
| 安全合规 | 深度集成 CDP 企业级治理,满足金融级要求 |
| 未来就绪 | 支持 AI/ML 全流程加速,打通数据工程到模型训练 |
正如 Cloudera 首席产品官所言:"Cloudera 与 NVIDIA 的合作......帮助客户充分发掘真正的 AI 转型潜力。"
该联合解决方案不仅是性能升级工具,更是企业构建智能化数据平台的战略基础设施,助力从"大数据"迈向"大智能"。