英伟达在CES 2026上抛出一系列重磅炸弹,直接宣告了AI算力工厂时代的到来。没有游戏显卡的更新,却有一场彻底改变AI产业格局的技术革命。

算力革命,Vera Rubin平台横空出世
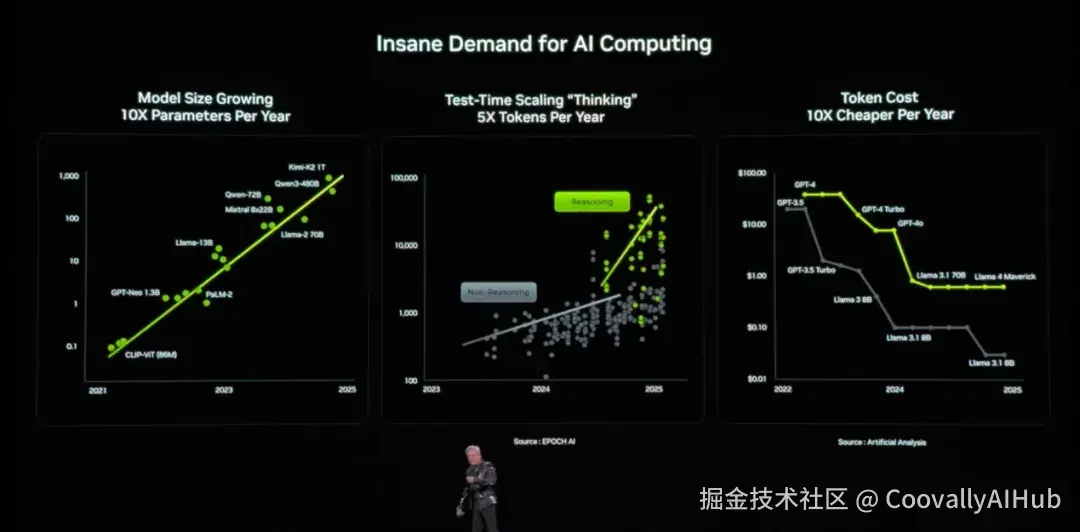
"全球AI算力告急?"面对这个困扰行业许久的问题,黄仁勋给出了霸气回应:Vera Rubin平台已全面投产。
这款以天文学家Vera Florence Cooper Rubin命名的新架构,是对上一代Blackwell的"降维打击"------推理Token成本直接暴降10倍,算力性能狂飙5倍。
训练MoE模型所需的GPU数量,更是减少了4倍。曾经,Blackwell终结了Hopper;如今,Rubin亲手埋葬了Blackwell。
Rubin平台的核心突破在于:英伟达首次将CPU、GPU、网络、存储、安全作为一个整体来设计。
不再单纯"堆卡",而是把整个数据中心变成一台AI超算。这一思路转变,让算力真正开始像电力一样廉价且可规模化供应。

六大组件,构建AI超算新范式
整个Rubin平台由六个关键组件构成,每个都是技术突破:
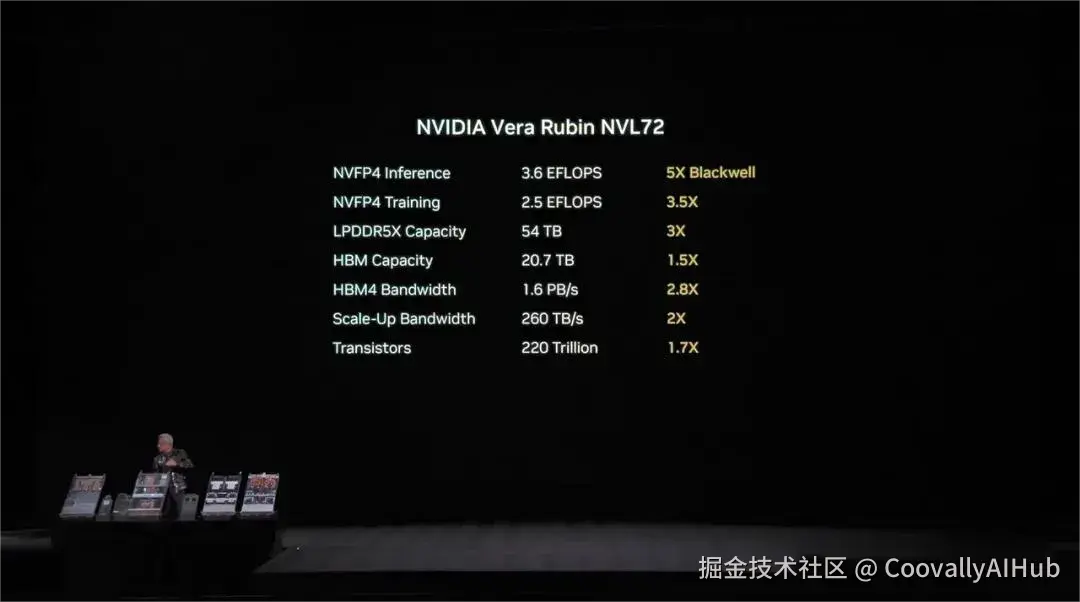
- Rubin GPU搭载第三代Transformer引擎,提供50 PFLOPS的NVFP4算力,性能达到Blackwell的5倍。
- 其NVFP4张量核心能分析Transformer各层的计算特性,动态调整数据精度与计算路径,实现效率最大化。
- Vera CPU专为智能体推理设计,采用88个自研Olympus核心,兼容Armv9.2,I/O带宽和能效比直接翻倍。
- BlueField-4 DPU管理AI的上下文记忆系统,解决了存储瓶颈。
- NVLink 6的互联能力令人咋舌:单芯片提供每秒400Gb交换能力,每块GPU提供3.6TB/s带宽。
- 而Rubin NVL72机架更提供260TB/s带宽------超过整个互联网。
72个GPU通过3.6 TB/s带宽互联,像一个超级GPU协同工作,直接把推理成本打至1/7。

性能飞跃,训练推理效率暴增
测试结果显示,Rubin架构训练模型速度达到Blackwell的3.5倍,推理任务速度高达5倍。
在超大规模MoE训练中,Rubin所需GPU数量相比Blackwell减少至1/4,整体能耗显著下降。
推理侧表现更加惊人:单位token推理效率提升最高达10倍。
同样的模型和响应延迟,算力成本直接下降到原来的1/10。这意味着模型可以轻松跑百万token长下文,企业级AI应用部署门槛大幅降低。
黄仁勋现场展示了Vera Rubin的托盘:小小托盘集成了2颗Vera CPU、4颗Rubin GPU、1颗BlueField-4 DPU和8颗ConnectX-9网卡,整个计算单元算力达到100 PetaFLOPS。
存储突破,解决KV Cache难题
让AI模型"多跑一会"的关键挑战在于上下文数据,大量KV Cache该如何处理?
英伟达推出了由BlueField-4驱动的推理上下文内存存储平台,在GPU内存和传统存储之间创建了"第三层",让每秒处理的token数提升高达5倍。
更令人瞩目的是,Rubin是首个支持第三代机密计算的AI超算平台。
模型参数、推理数据、用户请求全链路加密,即使云厂商也无法直接访问明文数据。这解决了金融、医疗、政府等行业"敢不敢把核心AI放到云上"的安全顾虑。
自动驾驶,AlphaMayo实现0接管
英伟达正式发布"端到端"自动驾驶AI------AlphaMayo。
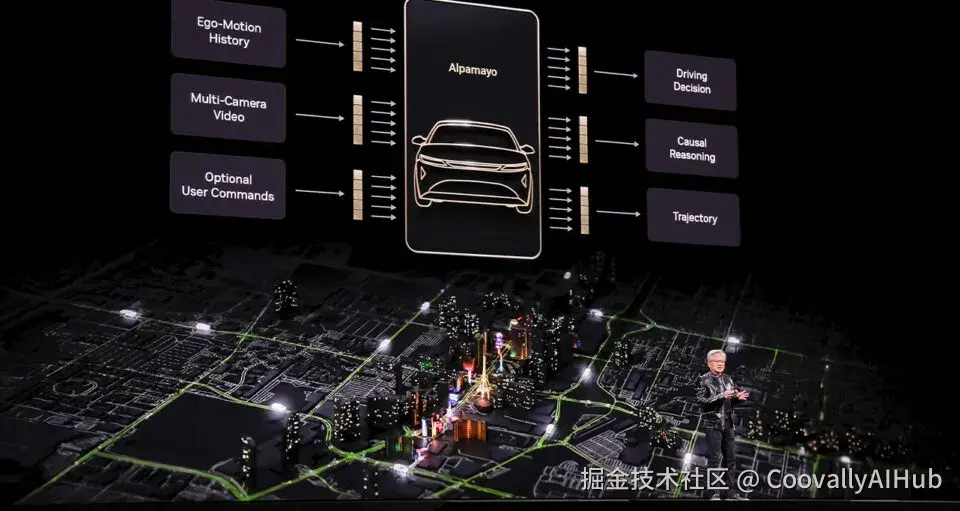
这是一个会思考、会推理的自动驾驶系统,从摄像头输入到车辆执行动作,全流程由模型完成。
AlphaMayo的独特之处在于具备显式推理能力。系统不仅执行转向、制动、加速动作,还会给出即将采取行动的理由及对应轨迹。
面对自动驾驶的"长尾场景"挑战,AlphaMayo的策略是将复杂场景拆解为多个熟悉的物理与交通子问题,通过推理将罕见情况分解为常见组合。
演示中,车辆在全程0接管状态下完成路径规划与行驶,顺利抵达目的地。
机器人ChatGPT时刻,全家桶开源
英伟达扔下了针对物理AI的"开源全家桶"------模型、框架及基础设施,应有尽有。老黄直言:机器人的ChatGPT时刻已经到来。
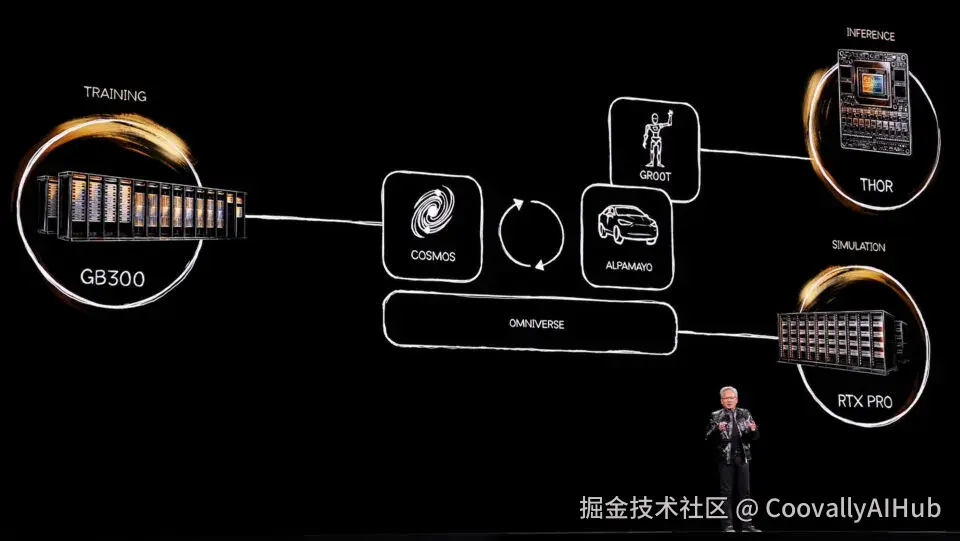
所有新模型均已上线Hugging Face:
- NVIDIA Cosmos Transfer/Predict 2.5: 完全可定制的世界模型,在虚拟世界里生成符合物理规律的数据
- NVIDIA Cosmos Reason 2: 让机器像人一样"看懂"世界并进行逻辑推理
- NVIDIA Isaac GR00T N1.6: 专为人形机器人打造,解锁全身控制
两大开发神器同步推出:
- Isaac Lab-Arena: 开源框架,连接主流基准测试,让机器人在虚拟世界千锤百炼
- NVIDIA OSMO: 统一调度数据生成、模型训练和测试,大幅缩短开发周期
硬件方面,全新的Jetson T4000模组将Blackwell架构带到边缘端:算力高达1200 FP4 TFLOPS(上一代的4倍),1000台起订单价仅1999美元,70瓦低功耗。
老黄预言:未来所有应用都建在AI之上
演讲伊始,黄仁勋回顾计算产业演进:从大型机到PC,到互联网、云计算,再到移动计算。
他判断,当前产业正同时经历两次平台级转变:一是从传统计算走向AI,另一个是整个软件、硬件栈的底层重塑。
"AI正成为全新的'底座',应用开始建立在AI之上。"
老黄特别提到开源模型的冲击:DeepSeek R1作为首批开源推理模型之一,给行业带来巨大震动。
他现场展示了英伟达开源模型的亮眼成绩,涵盖多模态Nemotron 3、世界模型Cosmos、机器人模型GR00T、蛋白预测模型OpenFold 3等多个领域。
最令人震惊的是Perplexity展示的能力:AI在推理任何环节,直接调用最顶尖的模型。
老黄明确表示:"这就是未来AI应用的基本形态。或者说,因为未来应用都构建在AI之上,这就是未来应用的基础框架。"
彩蛋:桌上AI超算即将上线
演讲最后还有幕后花絮:DGX Station台式AI超算将在2026年春季上线。
这款设备堪称"放在办公桌上的微型数据中心":
- 搭载GB300 Grace Blackwell Ultra超级芯片
- 配备高达775GB的FP4精度一致性内存
- 拥有Petaflop级AI算力,支持在本地运行高达1万亿参数的超大规模模型
实测威力惊人:LLM预训练速度高达250,000 Token/秒,支持对数百万数据点进行聚类和大型可视化。
从DeepSeek R1的开源震动,到Agentic AI的全面爆发,计算产业正在经历一场前所未有的重塑。
在这个游戏玩家略感失望的早晨,一个由物理AI驱动的全新世界,正在Vera Rubin的轰鸣声中,加速向我们走来。
英伟达不再只是一家显卡公司,它正在成为AI时代的"电力公司"------为智能世界提供最基础的算力能源。
未来已来,只是尚未均匀分布。而英伟达,正在加速这种分布。
参考来源:英伟达CES 2026主题演讲及相关技术发布材料