
目录
一、性能测试入门:从本质到价值,搞懂 "为什么要做性能测试"
[1.1 什么是性能测试?------ 不止于 "快",更在于 "稳"](#1.1 什么是性能测试?—— 不止于 "快",更在于 "稳")
[1.1.1 官方定义](#1.1.1 官方定义)
[1.1.2 性能测试与功能测试的核心区别](#1.1.2 性能测试与功能测试的核心区别)
[1.1.3 哪些场景必须做性能测试?](#1.1.3 哪些场景必须做性能测试?)
[1.2 常见的性能问题:用户吐槽的 "痛点" 都是什么?](#1.2 常见的性能问题:用户吐槽的 "痛点" 都是什么?)
[1.2.1 响应时间过长](#1.2.1 响应时间过长)
[1.2.2 系统稳定性差](#1.2.2 系统稳定性差)
[1.2.3 并发处理能力弱](#1.2.3 并发处理能力弱)
[1.2.4 资源利用率异常](#1.2.4 资源利用率异常)
[2.1 并发数:系统 "同时接待" 的用户数](#2.1 并发数:系统 "同时接待" 的用户数)
[2.1.1 定义](#2.1.1 定义)
[2.1.2 案例解析](#2.1.2 案例解析)
[2.1.3 并发数的实际意义](#2.1.3 并发数的实际意义)
[2.2 吞吐量:系统的 "处理效率"](#2.2 吞吐量:系统的 "处理效率")
[2.2.1 定义](#2.2.1 定义)
[2.2.2 吞吐量的分类](#2.2.2 吞吐量的分类)
[2.2.3 案例与计算公式](#2.2.3 案例与计算公式)
[2.3 响应时间:用户的 "等待体验"](#2.3 响应时间:用户的 "等待体验")
[2.3.1 定义](#2.3.1 定义)
[2.3.2 响应时间的构成(Web 系统)](#2.3.2 响应时间的构成(Web 系统))
[2.3.3 响应时间的行业标准](#2.3.3 响应时间的行业标准)
[2.4 资源利用率:系统的 "硬件负载"](#2.4 资源利用率:系统的 "硬件负载")
[2.4.1 定义](#2.4.1 定义)
[2.4.2 核心资源指标说明](#2.4.2 核心资源指标说明)
[2.5 四大指标的关联关系:读懂系统性能曲线](#2.5 四大指标的关联关系:读懂系统性能曲线)
[3.1 终端用户:只关心 "用着爽不爽"](#3.1 终端用户:只关心 "用着爽不爽")
[3.2 系统运维人员:关心 "系统能不能扛住"](#3.2 系统运维人员:关心 "系统能不能扛住")
[3.3 软件设计开发人员:关心 "问题出在哪里"](#3.3 软件设计开发人员:关心 "问题出在哪里")
[3.4 性能测试人员:关心 "怎么测准、怎么定位"](#3.4 性能测试人员:关心 "怎么测准、怎么定位")
[4.1 基准测试:系统的 "基础体检"](#4.1 基准测试:系统的 "基础体检")
[4.1.1 定义](#4.1.1 定义)
[4.1.2 类比理解](#4.1.2 类比理解)
[4.1.3 测试目的](#4.1.3 测试目的)
[4.1.4 测试场景设计](#4.1.4 测试场景设计)
[4.2 并发测试:系统的 "多任务处理能力测试"](#4.2 并发测试:系统的 "多任务处理能力测试")
[4.2.1 定义](#4.2.1 定义)
[4.2.2 类比理解](#4.2.2 类比理解)
[4.2.3 测试目的](#4.2.3 测试目的)
[4.2.4 常见测试场景](#4.2.4 常见测试场景)
[4.2.5 注意事项](#4.2.5 注意事项)
[4.3 负载测试:系统的 "极限承重测试"](#4.3 负载测试:系统的 "极限承重测试")
[4.3.1 定义](#4.3.1 定义)
[4.3.2 类比理解](#4.3.2 类比理解)
[4.3.3 测试目的](#4.3.3 测试目的)
[4.3.4 测试场景设计](#4.3.4 测试场景设计)
[4.3.5 案例](#4.3.5 案例)
[4.4 压力测试:系统的 "极限挑战测试"](#4.4 压力测试:系统的 "极限挑战测试")
[4.4.1 定义](#4.4.1 定义)
[4.4.2 与负载测试的核心区别](#4.4.2 与负载测试的核心区别)
[4.4.3 类比理解](#4.4.3 类比理解)
[4.4.4 测试场景设计](#4.4.4 测试场景设计)
[4.4.5 案例](#4.4.5 案例)
[4.5 稳定性测试:系统的 "长期耐力测试"](#4.5 稳定性测试:系统的 "长期耐力测试")
[4.5.1 定义](#4.5.1 定义)
[4.5.2 类比理解](#4.5.2 类比理解)
[4.5.3 测试目的](#4.5.3 测试目的)
[4.5.4 测试场景设计](#4.5.4 测试场景设计)
[5.1 误区 1:并发用户数 = 在线用户数](#5.1 误区 1:并发用户数 = 在线用户数)
[5.2 误区 2:只关注 TPS,忽略响应时间和失败率](#5.2 误区 2:只关注 TPS,忽略响应时间和失败率)
[5.3 误区 3:测试环境与生产环境不一致](#5.3 误区 3:测试环境与生产环境不一致)
[5.4 误区 4:测试场景与真实用户行为不符](#5.4 误区 4:测试场景与真实用户行为不符)
[5.5 误区 5:性能测试只做一次就够了](#5.5 误区 5:性能测试只做一次就够了)
[6.1 入门级工具(适合新手、小型项目)](#6.1 入门级工具(适合新手、小型项目))
[6.2 企业级工具(适合大型项目、复杂场景)](#6.2 企业级工具(适合大型项目、复杂场景))
[6.3 开源高性能工具(适合高并发、分布式场景)](#6.3 开源高性能工具(适合高并发、分布式场景))
[6.4 监控工具(配合性能测试使用)](#6.4 监控工具(配合性能测试使用))
前言
在软件测试领域,有这样一个生动的比喻:功能测试验证系统 "能不能用",性能测试验证系统 "好不好用"。就像我们买汽车,五菱宏光和法拉利都能满足 "四个轮子跑起来" 的核心功能,但前者 0-100km/h 加速需要十几秒,后者只需几秒;前者座椅是人造皮,后者是真皮包裹 ------ 这就是性能的差距,直接决定了用户体验的上限。
在互联网时代,性能问题往往比功能缺陷更致命:双十一零点购物车结算页面加载超时、春运抢票时系统直接崩溃、APP 打开一篇文章要等 10 秒... 这些场景背后,都是性能测试不到位留下的隐患。对于开发者、测试工程师、运维人员而言,不懂性能测试,就如同医生不会看体检报告,无法精准定位系统 "健康隐患"。
本文将基于性能测试核心知识体系,用通俗的语言、真实的案例,从 "是什么、测什么、怎么测、谁来测" 四个维度,全面拆解性能测试的核心概念。无论你是刚入行的测试新手,还是想补全技术短板的开发 / 运维人员,都能对性能测试建立系统认知,轻松应对工作中的各类性能问题。下面就让我们正式开始吧!
一、性能测试入门:从本质到价值,搞懂 "为什么要做性能测试"
1.1 什么是性能测试?------ 不止于 "快",更在于 "稳"
1.1.1 官方定义
性能测试是在真实环境、特定负载条件下,通过工具模拟实际软件系统的运行及用户操作,监控系统各项性能指标,最终通过分析测试结果确定系统性能表现的测试行为。
简单来说,性能测试就像给系统做 "全面体检":不仅要测 "跑得有多快",还要测 "能扛多少人同时用"、"长时间运行会不会出问题"、"资源不够时能不能撑住"------ 核心目标是发现系统性能瓶颈,获取性能相关指标,为系统优化和容量规划提供数据支撑。
1.1.2 性能测试与功能测试的核心区别
很多新手会混淆性能测试和功能测试,这里用一张表清晰对比:
| 对比维度 | 功能测试 | 性能测试 |
|---|---|---|
| 核心目标 | 验证系统功能是否符合需求(能⽤) | 验证系统性能是否满足预期(好用) |
| 测试场景 | 单用户、正常流程操作 | 多用户并发、高负载、极限压力等 |
| 关注指标 | 功能是否实现、结果是否正确 | 响应时间、并发数、吞吐量、资源利用率等 |
| 问题定位 | 代码逻辑错误、功能缺失 | 资源瓶颈、架构设计缺陷、算法低效等 |
| 测试工具 | Selenium、Postman(功能验证) | JMeter、LoadRunner、Locust 等 |
举个例子:购物 APP 的 "提交订单" 功能,功能测试只需要验证点击提交后订单能成功创建、库存能减少;而性能测试需要验证:1000 人同时提交订单时,平均响应时间是否小于 2 秒?服务器 CPU 利用率会不会超过 80%?会不会出现订单重复创建或库存超卖的问题?
1.1.3 哪些场景必须做性能测试?
不是所有系统都需要投入大量精力做性能测试,但以下场景必须重点关注:
- 面向大众的互联网产品:电商、社交、支付、出行类 APP / 网站(用户量巨大,峰值压力突出);
- 核心业务系统:银行转账、证券交易、政务系统(稳定性和响应速度直接影响财产安全或公共服务);
- 预期用户量增长快的产品:新上线的创业项目、即将举办大型活动的平台(需提前规划扩容);
- 迭代频繁的系统:每次重大版本更新后,需验证新功能是否引入性能 regression(性能退化)。
1.2 常见的性能问题:用户吐槽的 "痛点" 都是什么?
性能问题的表现形式多种多样,但本质都是系统资源不足或设计不合理导致的。结合实际场景,常见的性能问题主要有以下几类:
1.2.1 响应时间过长
这是用户最直观的感受:打开页面要等 5 秒以上、点击按钮后半天没反应、查询数据时进度条一直加载。这类问题可能出在前端(页面渲染优化不足)、网络(带宽不够或延迟高)、后端(接口处理逻辑复杂)或数据库(SQL 查询效率低)。
1.2.2 系统稳定性差
- 长时间运行后崩溃:比如服务器连续运行 24 小时后,内存占用越来越高,最终 OutOfMemory;
- 偶发性故障:比如 100 人并发时正常,1000 人并发时偶尔出现请求失败,刷新后又恢复正常;
- 数据不一致:多用户同时操作同一数据时,出现库存超卖、订单重复提交等问题。
1.2.3 并发处理能力弱
- 峰值场景下系统瘫痪:比如双十一零点、春运抢票时,大量用户同时访问,导致服务器无法响应;
- 局部功能拥堵:比如某款 APP 的 "每日签到" 功能,早上 8 点集中签到时,该接口响应时间从 100ms 飙升到 3 秒。
1.2.4 资源利用率异常
- CPU 利用率过高:服务器 CPU 长期处于 90% 以上,导致系统处理能力下降;
- 内存泄漏:系统运行时间越长,内存占用越高,最终导致服务崩溃;
- 磁盘 I/O 瓶颈:数据库写入频繁时,磁盘读写速度跟不上,导致请求排队。
这些性能问题看似五花八门,但背后都能通过性能测试找到根源。接下来,我们就来拆解性能测试的核心指标 ------ 这是分析性能问题的 "语言"。
二、性能测试核心指标:读懂系统的 "健康仪表盘"
如果把系统比作一辆汽车,性能指标就是仪表盘上的转速、时速、油量、水温 ------ 只有看懂这些数据,才能判断汽车的运行状态。性能测试的核心指标有四个:并发数、吞吐量、响应时间、资源利用率,它们相互关联,共同构成了系统性能的完整画像。
2.1 并发数:系统 "同时接待" 的用户数
2.1.1 定义
并发数(并发用户数)有两个层面的理解:
- 业务层面:实际使用系统的用户总数,强调 "同时操作" 的业务场景;
- 技术层面:Web 服务器在一段时间内处理浏览器请求时建立的 HTTP 连接数或生成的处理线程数。
2.1.2 案例解析
一个公司内部 OA 系统,有 5000 名员工使用,最多同时有 2500 人在线操作,这些用户分别在做浏览通知、填写报销单、提交审批、查询工资单等操作。那么:
- 业务并发用户数:2500(同时在线操作的用户总数);
- 实际并发用户数:提交审批和查询工资单的用户(这两类操作会触发后端数据库交互,对系统资源消耗较大;而浏览通知属于轻量级操作,对系统压力较小)。
这里要注意一个误区:并发用户数≠在线用户数。在线用户数是指登录系统但可能处于 idle 状态的用户(比如打开页面后没操作),而并发用户数是指正在执行具体业务操作、对系统产生压力的用户。比如一个电商网站有 10 万用户在线,但同时在下单的可能只有 1000 人 ------ 这 1000 人才是真正的并发用户数。
2.1.3 并发数的实际意义
并发数是性能测试场景设计的核心依据。比如设计电商系统的性能测试时,需要先明确:
- 日常并发用户数:比如平时 1000 人同时下单;
- 峰值并发用户数:比如双十一零点 5 万人同时下单;
- 极限并发用户数:系统能承受的最大并发(超过这个数就会崩溃)。
2.2 吞吐量:系统的 "处理效率"
2.2.1 定义
吞吐量是指单位时间内系统处理的请求数或事务数,直接体现系统的负载承受能力 ------ 吞吐量越高,说明系统处理能力越强,性能越好。
2.2.2 吞吐量的分类
吞吐量主要有两类统计方式:
按请求 / 事务数统计:TPS 和 QPS
- TPS(Transactions Per Second):每秒处理事务数。一个 "事务" 是指用户完成一次完整的业务操作(比如 "登录→浏览商品→加入购物车→提交订单");
- QPS(Queries Per Second):每秒查询率。主要用于衡量查询类接口的性能,若一个事务中只有一个查询接口,则 QPS=TPS。
按网络数据包统计:单位时间内处理的网络数据量(如 KB/s),主要用于评估网络传输层面的性能瓶颈。
2.2.3 案例与计算公式
案例 1:基础计算
某系统 1 分钟内成功处理了 1000 个下单事务,那么 TPS=1000/60≈16.7。
案例 2:场景对比
- A 场景:100 个并发用户,每个用户每隔 1 秒发送一个请求;
- B 场景:1000 个并发用户,每个用户每隔 10 秒发送一个请求。
这两个场景的吞吐量相同(都是每秒 100 个请求),但 A 场景的 "思考时间"(用户两次请求之间的间隔)更短,对系统资源的占用更高 ------ 这说明设计性能测试场景时,不能只看并发数,还要结合用户行为模式(思考时间、操作频率)。
案例 3:实际业务估算(重点)
某电商平台 2022 年最高单日交易笔数为 10 万笔,2023 年业务预计增长 30%,如何估算 2023 年需要支撑的 TPS?
这里需要用到两个核心原则:
- 理想状态估算:假设交易均匀分布在 24 小时内,理论 TPS=(10 万 ×1.3)/(24×60×60)≈1.5;
- 实际场景估算(二八定律):80% 的交易集中在 20% 的时间内完成(比如双十一零点前后 1 小时),实际 TPS=(10 万 ×1.3×0.8)/(24×60×60×0.2)≈7.4;
- 峰值场景估算:如果有详细数据显示,5 万笔交易集中在晚上 8-9 点(1 小时)完成,2023 年增长 30% 后,峰值 TPS=(5 万 ×1.3)/(60×60)≈18。
这个案例告诉我们:性能测试的指标不能拍脑袋定,要基于真实业务数据和用户行为模式估算,否则测试结果毫无参考价值。
2.3 响应时间:用户的 "等待体验"
2.3.1 定义
响应时间是指从用户发起请求开始,到客户端接收到最后一个字节数据所消耗的总时间 ------ 这是用户最直观的性能感受,也是衡量系统性能的核心指标之一。
2.3.2 响应时间的构成(Web 系统)
一个完整的响应时间包含以下几个环节,任何一个环节出问题都会导致响应变慢:
- 前端展现时间:页面渲染、DOM 解析、资源加载(CSS/JS/ 图片)的时间;
- 网络传输时间:请求从客户端到服务器、响应从服务器返回客户端的时间(受带宽、延迟影响);
- 服务器处理时间:服务器接收请求后,业务逻辑处理、调用中间件(Redis、MQ)的时间;
- 数据库处理时间:数据库执行 SQL 查询、写入数据的时间。
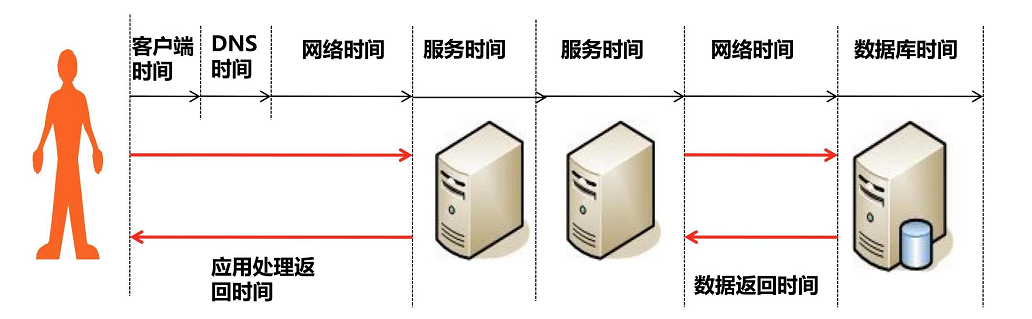
用一个公式总结:总响应时间 = 前端展现时间 + 网络时间(请求) + 服务器处理时间 + 数据库处理时间 + 网络时间(响应)
2.3.3 响应时间的行业标准
不同类型的系统,对响应时间的要求不同,以下是行业通用标准:
- 毫秒级(<100ms):查询类接口、缓存接口(如 Redis 查询);
- 快速响应(100ms-1s):核心业务操作(如登录、支付确认);
- 可接受(1s-3s):普通业务操作(如浏览商品、填写表单);
- 不可接受(>3s):超过 3 秒用户会明显感到等待,可能直接关闭页面。
2.4 资源利用率:系统的 "硬件负载"
2.4.1 定义
资源利用率是指系统运行时,硬件资源(CPU、内存、磁盘、网络)的占用比例,用于分析系统的资源瓶颈 ------ 比如 CPU 利用率长期过高,说明系统的计算能力不足;内存利用率持续上涨,可能存在内存泄漏。
2.4.2 核心资源指标说明
CPU 利用率:
- 正常范围:70%-80%(长期超过 80% 说明 CPU 瓶颈,处理能力不足);
- 常见问题:CPU 利用率 100%(可能是死循环、线程阻塞、SQL 执行效率低)。
内存利用率:
- 正常范围:根据服务器内存大小而定,一般不超过 85%;
- 常见问题:内存利用率持续上涨(内存泄漏,比如对象创建后未释放)、内存溢出(OOM,系统崩溃)。
磁盘 I/O 利用率:
- 正常范围:磁盘读写使用率不超过 70%;
- 常见问题:磁盘 I/O 过高(数据库频繁写入、日志打印过多、未使用缓存)。
网络带宽利用率:
- 正常范围:不超过带宽上限的 80%;
- 常见问题:带宽占满(大量静态资源未压缩、文件上传下载未做限流)。
2.5 四大指标的关联关系:读懂系统性能曲线
并发数、吞吐量、响应时间、资源利用率不是孤立的,它们之间存在明显的因果关系,用一张图就能看懂:
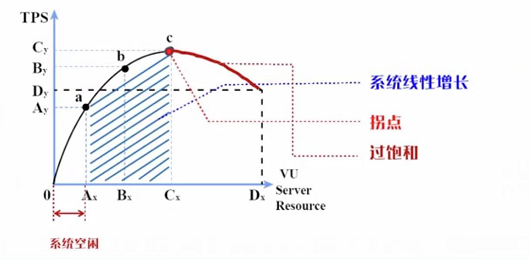
曲线解读:
- 空闲区间(0-A 点):并发用户少,系统资源充足,吞吐量低,响应时间短(比如凌晨 3 点的电商网站,只有几个用户访问,响应时间都在 100ms 内);
- 线性增长区间(A-B 点):随着并发用户增加,吞吐量呈线性增长,响应时间缓慢上升,资源利用率逐步提高(比如工作日的电商网站,用户量稳步增加,系统处理能力稳定);
- 拐点(B 点):吞吐量达到最大值,资源利用率接近饱和(比如 CPU 达到 80%),之后再增加并发用户,吞吐量不再增长,响应时间开始快速上升 ------ 这是系统的 "性能拐点",也是性能测试的核心关注点;
- 过饱和区间(B-D 点):并发用户继续增加,系统资源耗尽,吞吐量下降,响应时间急剧变长,甚至出现请求失败、系统崩溃(比如双十一零点的电商网站,若未做扩容,可能出现这种情况)。
性能测试的核心目标之一,就是找到这个 "拐点"------ 它能告诉我们:系统在不牺牲用户体验(响应时间)的前提下,能承受的最大负载是多少。
三、性能测试的关注点:不同角色的 "视角差异"
性能测试不是测试人员的 "独角戏",而是需要开发、运维、测试、产品等多个角色协同参与 ------ 不同角色看待性能测试的侧重点不同,就像医生、患者、营养师看待体检报告的角度不同一样。
3.1 终端用户:只关心 "用着爽不爽"
对于终端用户来说,性能测试的结果直接体现为 "主观体验"------ 他们不关心 TPS、CPU 利用率这些专业指标,只关心:
- 打开 APP 需要多久?
- 点击按钮后多久有反应?
- 高峰期会不会卡顿、闪退?
- 弱网环境下能不能正常使用?
用户的体验阈值很明确:响应时间越短,体验越好;超过 3 秒就会失去耐心;超过 5 秒可能直接卸载 APP。比如我们用打车软件,下单后 1 秒内匹配到司机,和 5 秒后才匹配到,体验天差地别 ------ 这就是用户视角下的性能测试核心:以 "用户体验" 为导向,确保核心操作的响应时间在可接受范围内。
3.2 系统运维人员:关心 "系统能不能扛住"
运维人员是系统的 "守护者",他们的核心目标是确保系统 7×24 小时稳定运行,因此关注点更宏观、更侧重 "全局利益最大化":
- 系统的最大并发用户数和响应时间的权衡:比如 A 方案支持 100 万并发,登录响应时间 3 秒;B 方案支持 500 万并发,登录响应时间 8 秒 ------ 运维人员可能更倾向于 B 方案,因为能覆盖更多用户,避免高峰期系统崩溃;
- 系统容量规划:根据性能测试结果,判断需要部署多少台服务器、分配多少内存、带宽,才能支撑峰值流量;
- 长期稳定性:系统在高负载下运行 24 小时以上,会不会出现内存泄漏、CPU 利用率持续上涨等问题;
- 可扩展性:当用户量增长时,能否通过扩容(增加服务器、升级硬件)快速提升系统性能。
运维人员的工作,就是基于性能测试数据,制定系统的 "应急预案"------ 比如双十一前根据性能测试结果扩容 10 倍服务器,避免流量峰值导致系统瘫痪。
3.3 软件设计开发人员:关心 "问题出在哪里"
开发人员是系统的 "建造者",他们的核心目标是找到性能瓶颈的根源并优化,因此关注点更微观、更侧重 "技术实现":
- 算法效率:核心业务逻辑的算法是否高效?有没有冗余计算、死循环?
- 架构设计:系统架构是否合理?比如是否存在单点故障、是否用到了缓存(Redis)减轻数据库压力、是否用消息队列(MQ)削峰填谷?
- 数据库优化:SQL 查询是否高效?有没有索引失效、全表扫描?数据库连接池配置是否合理?
- 代码质量:有没有内存泄漏、线程安全问题?比如创建的对象未释放、多线程并发时未加锁导致数据不一致。
举个例子:如果性能测试发现 "查询订单" 接口响应时间过长,开发人员需要排查:是 SQL 查询没有走索引?还是订单数据量太大没有做分页?或是缓存没有命中导致每次都查询数据库?------ 这些都是开发人员视角下的性能问题根源。
3.4 性能测试人员:关心 "怎么测准、怎么定位"
性能测试人员是系统的 "体检医生",需要具备 "全栈思维",既要懂业务,又要懂技术,核心关注点包括:
- 测试场景设计:如何模拟真实的用户行为?比如用户的思考时间、操作路径、峰值分布;
- 测试脚本开发:如何用工具(JMeter、Locust)编写高效的测试脚本,模拟多用户并发;
- 测试环境搭建:如何搭建与生产环境一致的测试环境,确保测试结果的准确性;
- 性能瓶颈定位:如何通过监控数据(TPS、响应时间、资源利用率),定位瓶颈出在前端、网络、服务器还是数据库;
- 测试报告输出:如何将复杂的测试数据转化为清晰的结论,为开发优化和运维扩容提供依据。
性能测试人员的核心能力,是 "透过现象看本质"------ 比如看到响应时间变长,能快速判断是网络延迟导致的,还是数据库查询效率低导致的;看到 CPU 利用率过高,能定位到是哪个线程、哪个方法占用了大量资源。
四、性能测试的分类:不同场景下的 "专项体检"
性能测试不是 "一刀切" 的,而是根据测试目标的不同,分为不同的类型 ------ 就像体检有常规体检、专项体检(如心血管检查、肿瘤筛查),性能测试也有对应的 "专项测试"。
4.1 基准测试:系统的 "基础体检"
4.1.1 定义
基准测试(Benchmark Testing)又称 "单用户测试",是在较低压力下(通常是单用户或少量并发用户),对被测系统的核心业务进行测试,记录各项性能指标(如响应时间、TPS、资源利用率),作为后续测试的 "基准线"。
4.1.2 类比理解
基准测试就像我们体检时的 "基础项目"(身高、体重、血压)------ 这些数据是评估身体状况的基础,后续的专项检查(如血脂、血糖)都要基于这些基础数据进行对比。
4.1.3 测试目的
- 验证系统在低负载下的运行状态是否正常(比如单用户操作时,响应时间是否稳定、有没有报错);
- 获取基础性能指标,为后续的并发测试、负载测试提供参考(比如基准测试中 "下单" 接口的响应时间是 100ms,后续负载测试中如果响应时间涨到 500ms,就说明负载对该接口有明显影响);
- 检查测试环境是否稳定(比如基准测试中各项指标波动很大,说明测试环境有问题,需要先排查环境)。
4.1.4 测试场景设计
- 测试对象:系统核心业务(如登录、下单、查询订单);
- 并发用户数:1-5 个;
- 测试时长:每个接口运行 1-5 分钟;
- 监控指标:响应时间(平均响应时间、最小 / 最大响应时间)、TPS、资源利用率(CPU、内存、磁盘、网络)。
4.2 并发测试:系统的 "多任务处理能力测试"
4.2.1 定义
并发测试(Concurrency Testing)是模拟多个用户同时执行同一操作或不同操作,评估系统在并发场景下的性能表现,重点发现并发带来的问题(如线程锁、资源争用、数据不一致)。
4.2.2 类比理解
并发测试就像测试一个餐厅的 "同时接待能力"------ 比如 10 个顾客同时点餐、5 个顾客同时结账,餐厅能否高效处理,不会出现漏单、错单或等待时间过长的问题。
4.2.3 测试目的
- 验证系统在多用户并发操作时的响应能力(比如 1000 人同时登录,平均响应时间是否小于 2 秒);
- 发现并发场景下的特有问题:
- 资源争用:多个线程同时竞争同一资源(如数据库连接池),导致部分请求阻塞;
- 数据不一致:多用户同时更新同一数据(如同时抢购最后一件商品),导致库存超卖;
- 死锁:线程之间相互等待资源,导致系统卡住;
- 评估系统的并发处理极限(最多支持多少用户同时操作而不出现问题)。
4.2.4 常见测试场景
- 同一功能并发:1000 用户同时登录、100 用户同时提交订单、50 用户同时查询同一商品;
- 不同功能并发:混合场景(如 30% 用户登录、40% 用户浏览商品、20% 用户下单、10% 用户查询订单)。
4.2.5 注意事项
并发测试对 "时间同步性" 要求很高,必须借助专业工具(如 JMeter 的同步定时器)确保多个用户在同一时刻发起请求,否则测试结果会失真。
4.3 负载测试:系统的 "极限承重测试"
4.3.1 定义
负载测试(Load Testing)是通过逐步增加系统负载(如并发用户数、请求频率),监控系统性能指标的变化,直到某项性能指标达到 "安全临界值"(如响应时间超过 3 秒、CPU 利用率超过 85%),最终确定系统在满足性能要求前提下的最大负载量。
4.3.2 类比理解
负载测试就像举重运动员的 "重量测试"------ 通过不断增加杠铃重量,直到运动员无法举起,从而确定其最大承重能力。

4.3.3 测试目的
- 确定系统的最大负载能力(如在响应时间≤2 秒的前提下,系统能支撑的最大并发用户数是 1 万人);
- 观察系统在不同负载下的性能变化趋势(如并发用户从 1000 增加到 5000 时,响应时间从 100ms 涨到 2 秒,TPS 从 1000 涨到 5000);
- 发现系统在中等负载下的潜在问题(如负载增加到 5000 用户时,内存利用率开始快速上涨)。
4.3.4 测试场景设计
- 负载递增方式:阶梯式递增(如每 5 分钟增加 1000 并发用户);
- 测试终止条件:
- 响应时间超过预设阈值(如 3 秒);
- 资源利用率超过安全范围(如 CPU≥85%);
- 请求失败率超过 1%;
- 监控指标:响应时间、TPS、并发用户数、资源利用率、请求失败率。
4.3.5 案例
某电商系统要求 "下单" 接口的响应时间≤2 秒,负载测试过程如下:
- 初始并发用户数 1000,响应时间 100ms,CPU 利用率 30%;
- 每 5 分钟增加 1000 并发用户,当并发用户数达到 1 万人时,响应时间 2 秒,CPU 利用率 80%;
- 继续增加到 1.1 万人时,响应时间涨到 3.5 秒,超过阈值;
- 结论:在响应时间≤2 秒的前提下,系统的最大负载量是 1 万人。
4.4 压力测试:系统的 "极限挑战测试"
4.4.1 定义
压力测试(Stress Testing)是在超过预期负载(如超过最大并发用户数、资源不足)的条件下,评估系统的性能表现,重点发现系统在极限压力下的问题(如崩溃、数据丢失、死锁),确定系统的极限处理能力。
4.4.2 与负载测试的核心区别
很多人会混淆负载测试和压力测试,这里用一张表清晰对比:
| 对比维度 | 负载测试 | 压力测试 |
|---|---|---|
| 核心目标 | 找到 "满足性能要求的最大负载" | 找到 "系统的极限处理能力" |
| 负载范围 | 预期负载范围内(如 1000-1 万人) | 超过预期负载(如 1 万 - 5 万人) |
| 终止条件 | 性能指标达到安全临界值 | 系统崩溃、请求失败率≥50% |
| 关注重点 | 性能指标的稳定性 | 系统的极限承受能力和故障表现 |
| 实际意义 | 指导日常容量规划 | 指导灾难恢复、应急预案制定 |
4.4.3 类比理解
如果说负载测试是 "测试电梯能安全承载 10 人",那么压力测试就是 "强行塞进 20 人,看电梯会不会报警、卡住甚至崩溃"------ 核心是测试系统在 "超纲" 情况下的表现。
4.4.4 测试场景设计
- 负载递增方式:快速递增(如每 2 分钟增加 2000 并发用户)或直接施加极限负载;
- 测试终止条件 :
- 系统崩溃(如服务器宕机、接口返回 500 错误);
- 请求失败率超过 50%;
- 系统无响应(响应时间超过 10 秒);
- 监控指标:除了常规指标,还需监控系统崩溃时的日志、错误信息、数据一致性。
4.4.5 案例
基于上面的电商系统负载测试结果(最大负载 1 万人),进行压力测试:
- 直接将并发用户数提升到 2 万人,响应时间涨到 5 秒,CPU 利用率 95%,请求失败率 5%;
- 继续提升到 3 万人,响应时间超过 10 秒,请求失败率 60%,部分用户出现订单提交失败;
- 提升到 3.5 万人时,服务器宕机,所有请求返回 500 错误;
- 结论:系统的极限处理能力是 3 万人,超过后会崩溃;在 2 万人负载下,系统仍能部分可用(失败率 5%),可作为应急预案的参考。
4.5 稳定性测试:系统的 "长期耐力测试"
4.5.1 定义
稳定性测试(Soak Testing)又称 "耐久性测试",是在持续负载(如最大负载的 70%-80%)下,让系统运行较长时间(通常 3×24 小时以上),评估系统的长期稳定运行能力,重点发现长时间运行带来的问题(如内存泄漏、磁盘碎片、连接池耗尽)。
4.5.2 类比理解
稳定性测试就像测试一辆汽车的 "长途耐力"------ 让汽车以 100km/h 的速度连续行驶 1000 公里,看发动机是否过热、油耗是否稳定、有没有异响。
4.5.3 测试目的
- 发现长期运行带来的隐性问题:
- 内存泄漏:系统运行时间越长,内存占用越高,最终导致 OOM;
- 磁盘 I/O 积累:日志文件不断增大,导致磁盘空间不足;
- 连接池耗尽:数据库连接、线程池未释放,导致新请求无法建立连接;
- 验证系统的 7×24 小时运行能力(如支付系统、政务系统需要全年无休运行);
- 评估系统的维护成本(如是否需要定期重启服务器释放资源)。
4.5.4 测试场景设计
- 负载设置:最大负载的 70%-80%(如前面案例中的 7000-8000 并发用户);
- 测试时长:3×24 小时(72 小时)以上,核心业务系统建议 7×24 小时;
- 监控指标:除常规指标外,重点监控内存利用率变化趋势、磁盘空间占用、连接池状态;
- 注意事项:测试期间需确保测试环境稳定(如网络不中断、电源正常),避免外部因素影响测试结果。
五、性能测试常见误区:这些坑一定要避开!
很多新手在做性能测试时,容易陷入一些误区,导致测试结果失真,无法为系统优化提供有效参考。以下是最常见的 5 个误区及避坑指南:
5.1 误区 1:并发用户数 = 在线用户数
错误认知:某系统有 10 万用户在线,就认为并发用户数是 10 万,按这个量级设计测试场景;
真实情况:在线用户数≠并发用户数,大部分在线用户处于 idle 状态(如打开页面后未操作),真正并发操作的用户可能只有 1 万甚至更少;
避坑指南:通过业务日志分析用户行为,计算 "活跃并发用户数"------ 比如统计 1 分钟内有多少用户发起了请求,以此作为并发数的参考。
5.2 误区 2:只关注 TPS,忽略响应时间和失败率
错误认知:认为 TPS 越高,系统性能越好,比如某系统 TPS 达到 1 万就觉得满足要求;
真实情况:TPS 高但响应时间长、失败率高,说明系统 "处理得快但处理得不好"------ 比如 1 万 TPS 中,有 30% 的请求失败,剩下的 70% 响应时间超过 5 秒,这样的系统毫无用户体验可言;
避坑指南:性能测试需综合评估四大核心指标,不能单一依赖某一个指标 ------ 理想状态是 "高 TPS、低响应时间、低失败率、合理资源利用率"。
5.3 误区 3:测试环境与生产环境不一致
错误认知:在本地开发环境(2 核 4G 内存)做性能测试,结果 TPS 达到 5000,就认为生产环境(16 核 32G 内存)能达到 4 万;
真实情况:测试环境的硬件配置、网络带宽、数据量、第三方依赖(如数据库、缓存)与生产环境差异很大,测试结果无法直接迁移;
避坑指南:尽量搭建与生产环境一致的测试环境 ------ 相同的硬件配置、相同的软件版本、相同的数据量(如生产环境有 100 万条订单数据,测试环境也需同步)、相同的网络拓扑。
5.4 误区 4:测试场景与真实用户行为不符
错误认知:模拟 1000 用户同时发起 "下单" 请求,认为这就是真实的峰值场景;
真实情况:真实用户的行为是多样化的 ------ 有的在登录、有的在浏览商品、有的在加入购物车、有的在下单,很少出现 1000 用户同时下单的情况;
避坑指南:基于用户行为分析,设计混合测试场景 ------ 比如 30% 登录、40% 浏览、20% 下单、10% 查询,更贴近真实业务场景。
5.5 误区 5:性能测试只做一次就够了
错误认知:系统上线前做一次性能测试,结果达标就认为后续不需要再做了;
真实情况:系统迭代过程中,新功能可能引入性能 regression(性能退化)------ 比如新增一个统计功能后,订单查询接口的响应时间从 100ms 涨到 1 秒;
避坑指南:将性能测试纳入 CI/CD 流程,每次重大版本更新后自动执行核心场景的性能测试,及时发现性能退化问题。
六、性能测试工具选型:不同场景下的 "利器推荐"
工欲善其事,必先利其器 ------ 选择合适的性能测试工具,能让测试效率翻倍。以下是主流的性能测试工具,按场景分类推荐:
6.1 入门级工具(适合新手、小型项目)
- JMeter:开源免费,功能强大,支持 HTTP、FTP、数据库等多种协议,图形化界面操作简单,适合 Web 应用、接口的性能测试;
- Postman + Newman:Postman 用于接口调试,Newman 是 Postman 的命令行工具,支持批量执行接口用例并生成报告,适合小型接口项目的性能测试。
6.2 企业级工具(适合大型项目、复杂场景)
- LoadRunner:功能全面,支持多种协议(HTTP、TCP/IP、WebService 等),能模拟复杂的用户行为(如文件上传、AJAX 请求),适合大型企业级应用的性能测试,但收费昂贵;
- NeoLoad:开源商业化工具,支持云原生、微服务架构,测试脚本录制和编辑功能强大,适合复杂分布式系统的性能测试。
6.3 开源高性能工具(适合高并发、分布式场景)
- Locust:基于 Python 开发,支持分布式压测,能模拟百万级并发用户,脚本编写简单(用 Python 代码),适合高并发场景(如电商峰值测试);
- Gatling:基于 Scala 开发,性能强劲,支持实时监控和 HTML 报告生成,适合高并发、低延迟的系统(如支付系统)。
6.4 监控工具(配合性能测试使用)
- Prometheus + Grafana:开源监控套件,能实时监控服务器 CPU、内存、磁盘等资源利用率,支持自定义仪表盘,适合分布式系统的监控;
- nmon:轻量级系统监控工具,能监控 CPU、内存、网络、磁盘 I/O 等指标,适合 Linux 服务器的实时监控;
- MySQL Slow Query Log:MySQL 自带的慢查询日志,能记录执行时间超过阈值的 SQL 语句,适合定位数据库性能瓶颈。
总结
性能测试不是 "一次性工作",而是贯穿系统全生命周期的持续过程 ------ 从系统设计阶段的性能预估,到开发阶段的性能自测,再到上线前的全面性能测试,以及上线后的性能监控和优化,性能测试无处不在。
对于技术人员而言,性能测试是一项 "加分技能":测试人员懂性能测试,能提供更有价值的测试报告;开发人员懂性能测试,能写出更高效的代码;运维人员懂性能测试,能更好地保障系统稳定运行。
最后,送给大家一句话:性能测试的本质是 "用数据说话"------ 没有数据支撑的性能优化都是 "瞎猜",只有通过严谨的测试、精准的监控、深入的分析,才能真正让系统 "跑得快、扛得住、用得爽"。
如果你在学习性能测试的过程中遇到了具体问题(如 JMeter 脚本编写、性能瓶颈定位),或者想获取某类工具的详细使用教程,可以在评论区留言!