Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models 论文解读
A New Axis of Sparsity for Large Language Models 论文解读)

这里为记忆模块起名叫做Engram, 中文含义是记忆痕迹,有趣的是核心设计中也涉及N-Gram算法. 本文将围绕Engram算法进行梳理;
背景
1.从MLA,到NSA,DSA(lightning Indexer),DeepSeek做了很多稀疏化的工作,从计算层面更加高效,节省,试图压榨尽所有的硬件资源;
2.从transformer到MoE------谁来算
但是对于一些简单问题,稠密模型可能存在资源浪费的情况,因为需要不加区分的过一遍所有参数,这对于小模型或许可以接受,但是对于超大量参数的模型难以忍受,因此转为只对部分参数激活;
3.从MoE到Engram------一定程度解耦计算和记忆
过去的transformer只有显示的链接,计算,没有所谓的记忆功能,一切产生的静态知识,其实都是节点间计算的结果,Engram就是为了解决这样一个问题;
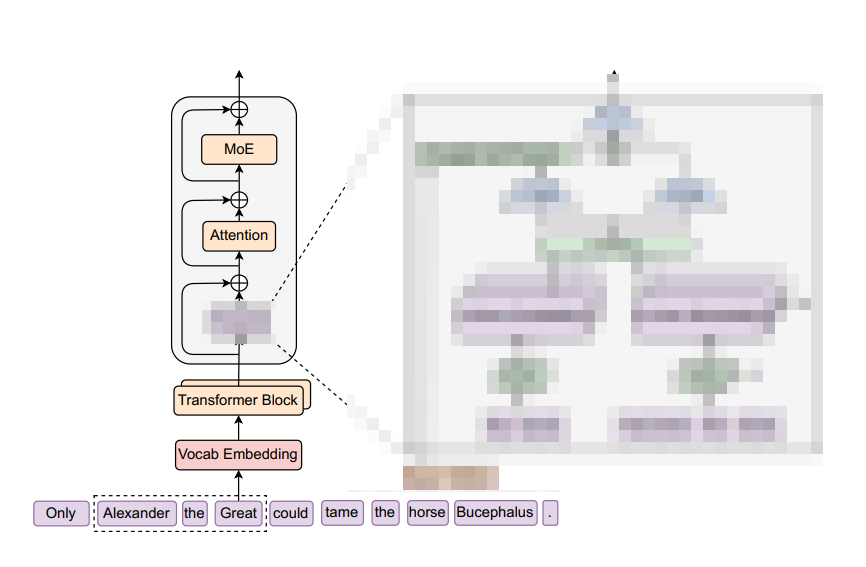
传统的Transformer 和 MoE结构实现"记忆"的 方式是优化参数,让tensor在交互中产生类似静态记忆,或者世界知识;

这是小X书某为博主的一个形象例子.
框架
简单来看,相比较于MoE结构,多了一个Engram模块,用于存储短词组;
技术背景
这里涉及一些其他算法,比如NLP中的N-Gram, 以及数据结构可能涉及的HASH 算法;
简单借由Gemini给出的解释进行理解:
N-Gram


优点是能够很好捕捉短程依赖;局部特性良好;
Hash & Multi-Head HASH

简而言之hash就是设置一套规则,建立索引和内容的关系;
多头hash采用的规则不一样,因此很大程度能够避免冲突;
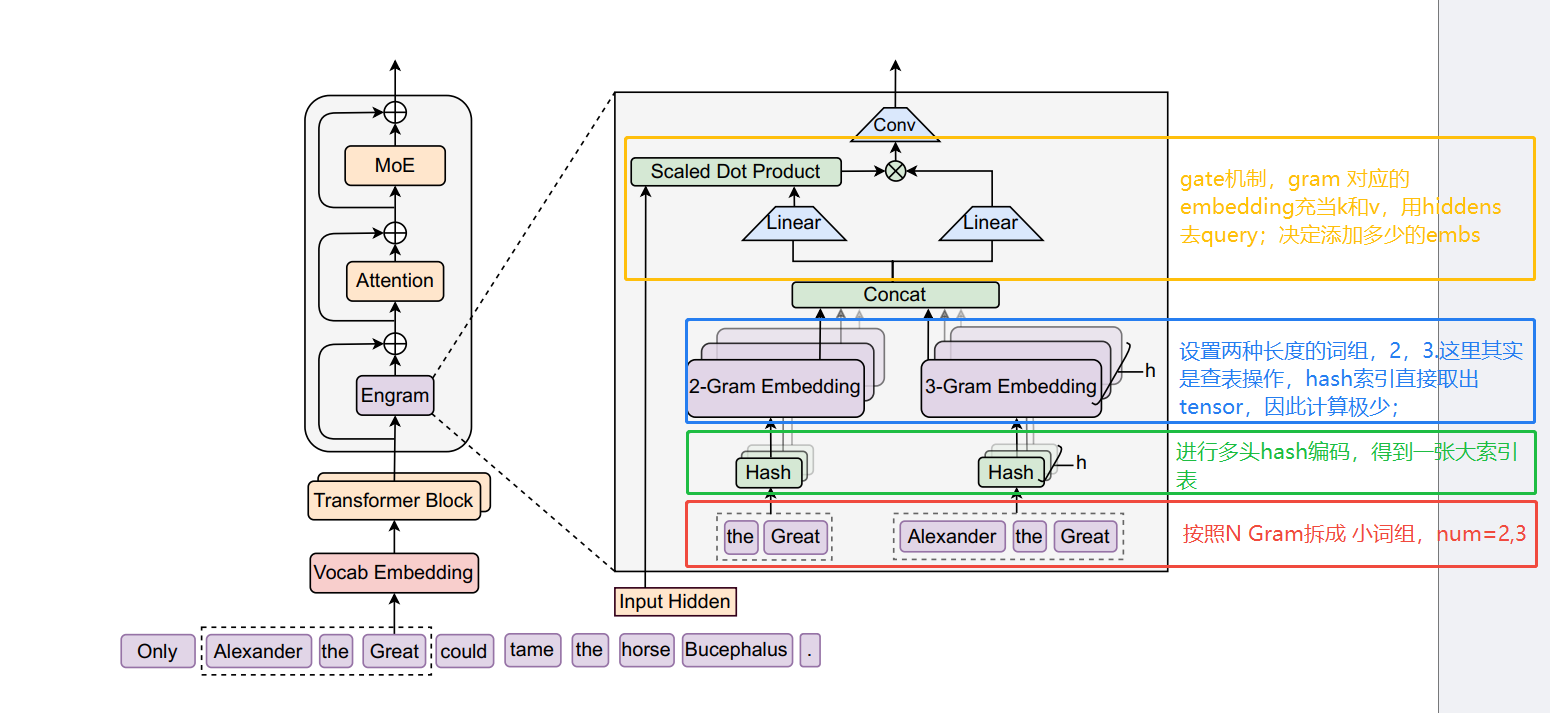
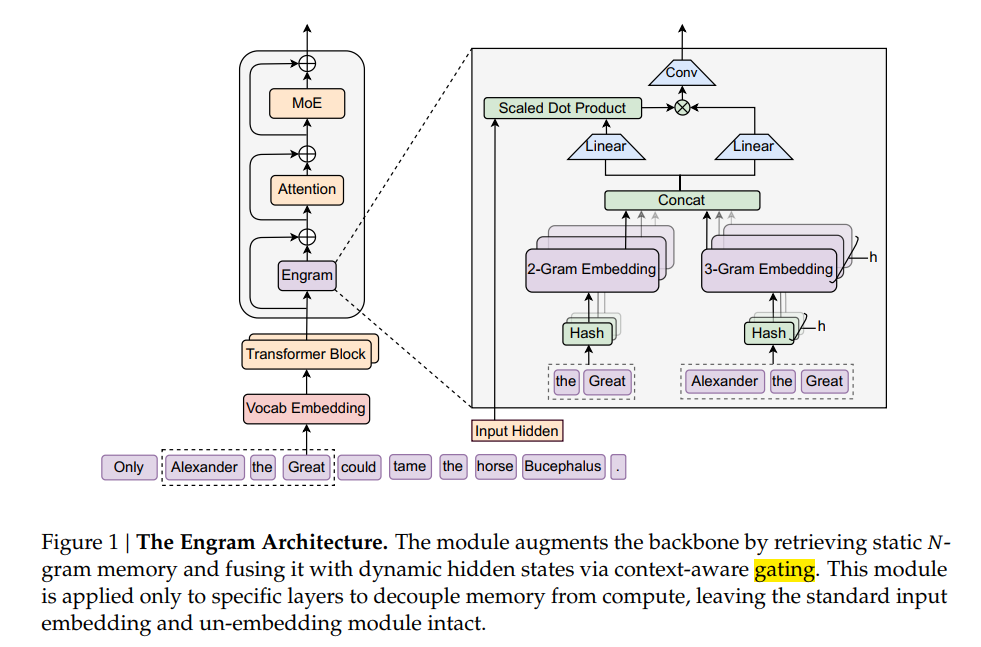
上面这张图自下而上即是做记忆模块的过程:
1.首先N-Gram 中N=2,3,即将2-3个词(实际是tokens,这里为了方便表述)组成一个词组;
2.进行多头HASH 操作,可以简单理解为不同的head采用的规则不一样,结合release的代码来看应该是不同的乘数(质数),目的是为了减少碰撞;
3.查表操作,取出index对应的embeddings;
4.做门控机制,用hiddens作为query, memory embedding作为key 和value, 形成激活值; 激活值决定融合多少比例的memory embedding;
背后的原理 :
因为人类语言里有很多"死记硬背"的固定搭配。 比如看到"United",后面大概率接"States";这些不需要逻辑推理,只需要记住就行。N-gram 就是用来捕捉这种"局部的小短语"的。
我目前的理解: 引入另一张词表,将一些局部短语,固定搭配的内容/知识进行了编码;使得这部分内容不需要反复计算就能得到,从而部分程度上让模型更能关注推理(原文的解释);
一些实验
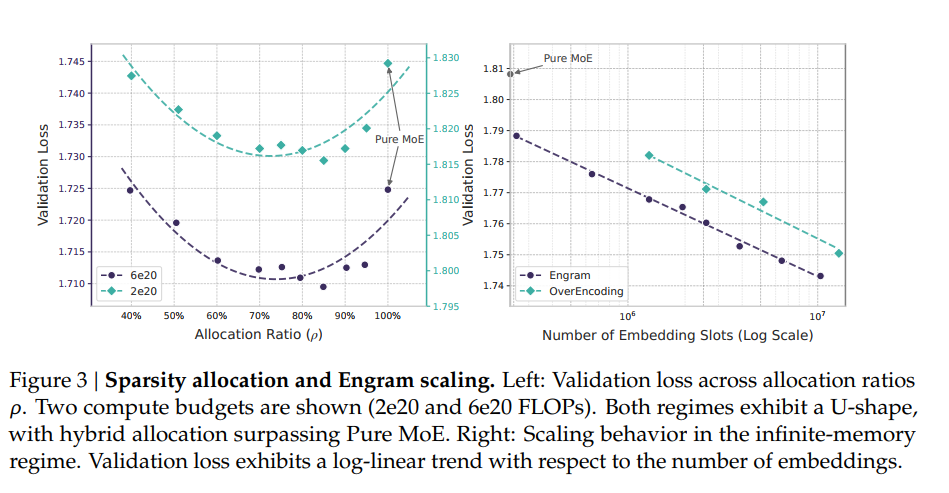
控制总参数/训练数,给engram和moe分配不同比例的参数,发现U-shape scaling low; 20-25%参数用于记忆更好;

Gates的激活值:越大表示可以直接预取出记忆,越小则越依赖transformer的计算;Engram 这里使用的是 N=3 的后缀 N-Gram。这意味着当某个词变红时,说明模型成功检索到了以该词结尾的、长度最多为 3 的词组。
其他设计
CompressedTokenizer
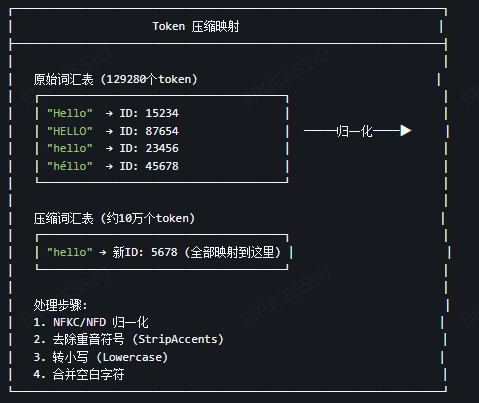
减少词汇表大小 → 降低哈希冲突概率||这个过程也会让表征只关注到背后的语义,而无关格式129k压缩到98k
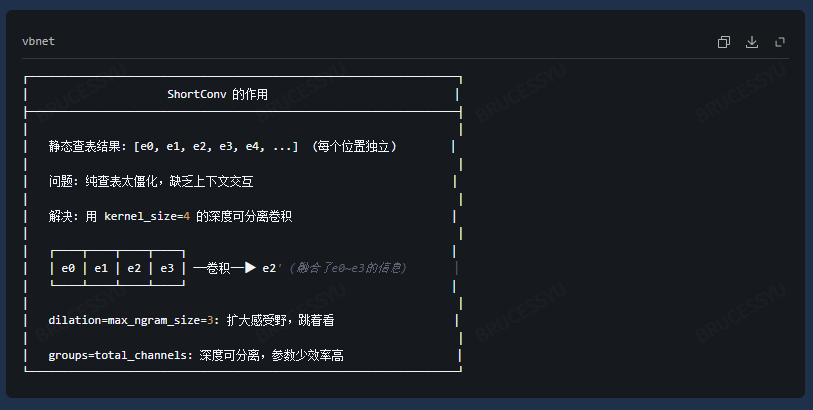
ShortConv - 短卷积层
张量offloading

XOR 按位异或
做多表的hash的时候,用XOR,计算高效
Muon优化
相比较于Adam, 可以节省1/3的优化器内存;
mHC

总结
总体来说, DS 给人的感觉是做了非常大量的稀疏性工作,在工程上; 这里的memory 其实与目前主流讨论的 long context memory是不一样的.这里是形成一些短词组,固定搭配,固定知识的记忆,从而用这样一张语义表来使得模型在较浅的layer就能形成一些语义聚类,让更多的计算用于推理.