AI-Researcher:让 AI 自主完成从文献调研到论文发表的全流程科研
一句话总结:香港大学团队开源了 AI-Researcher------一个能够自主完成文献综述、假设生成、算法实现到论文撰写全流程的多智能体科研系统,在基准测试中展现出接近人类研究者的科研能力。
📖 引言:AI能否独立做科研?
想象一下,你只需要给 AI 几篇参考文献,它就能自动:
- 阅读并理解相关论文
- 从中发现研究空白
- 提出创新的研究方向
- 编写代码实现算法
- 运行实验验证想法
- 撰写完整的学术论文
这听起来像科幻小说?但香港大学数据科学实验室的研究团队已经把它变成了现实。
AI-Researcher 是一个完全自主的科研系统,它就像一个不知疲倦的博士生,能够24小时不间断地进行科学探索。更令人惊讶的是,它生成的研究论文质量,在某些情况下已经接近甚至达到了人类顶会论文的水平!

图1:AI-Researcher 系统架构概览。展示了从文献探索、想法生成、算法实现、实验验证到学术发表的端到端自主科研流程。左侧是输入(参考文献),中间是多智能体协作流程,右侧是输出(包括代码实现和学术论文)。
🧠 核心思想:像人类研究者一样思考
为什么需要 AI-Researcher?
传统的 AI 辅助工具只能帮助完成科研中的某个环节------比如文献检索、代码补全或语法检查。但真正的科学发现需要的是全局思维:
- 你需要广泛阅读文献,找到研究空白
- 你需要创造性地提出假设
- 你需要把想法变成可运行的代码
- 你需要设计实验来验证你的想法
- 你需要把成果写成论文与同行分享
这就像你不能只雇一个会打字的秘书来完成博士论文------你需要的是一个能独立思考的研究者。
AI-Researcher 的三大创新
论文提出了三个关键技术创新,让 AI 能够像人类研究者一样工作:
🔬 创新一:原子概念分解
就像化学家把复杂分子拆解成原子一样,AI-Researcher 把复杂的研究概念拆解成原子学术概念------不可再分的最小研究单元。
生活比喻:这就像学做一道复杂的菜,不是直接照着成品图去做,而是先把它分解成:切菜、调味、火候控制等基本步骤。
每个原子概念都建立数学公式↔代码实现的双向映射,确保理论和实践的一致性,大大减少了 AI "胡说八道"(幻觉)的风险。
🔄 创新二:导师-学生迭代机制
人类研究者是怎么成长的?通过与导师的反复讨论和修改!AI-Researcher 模拟了这种模式:
- Code Agent(学生):负责实现代码
- Advisor Agent(导师):审查代码,提供反馈
- 两者反复迭代,直到实现正确
生活比喻:就像你写论文初稿给导师看,导师说"这里的公式推导有问题",你修改后再给导师看,如此反复直到导师满意。
📝 创新三:层级式论文生成
让 AI 写一篇几千字的学术论文,最大的挑战是保持前后一致。AI-Researcher 采用三阶段方法:
- 大纲生成:先确定整体结构
- 内容填充:按章节逐步撰写
- 检查校对:用学术检查表系统验证
生活比喻:就像盖房子,先有蓝图(大纲),再砌墙装修(内容),最后质检验收(校对)。
🏗️ 系统架构详解
AI-Researcher 由多个专业智能体组成,它们各司其职又紧密协作,就像一个高效的科研团队。
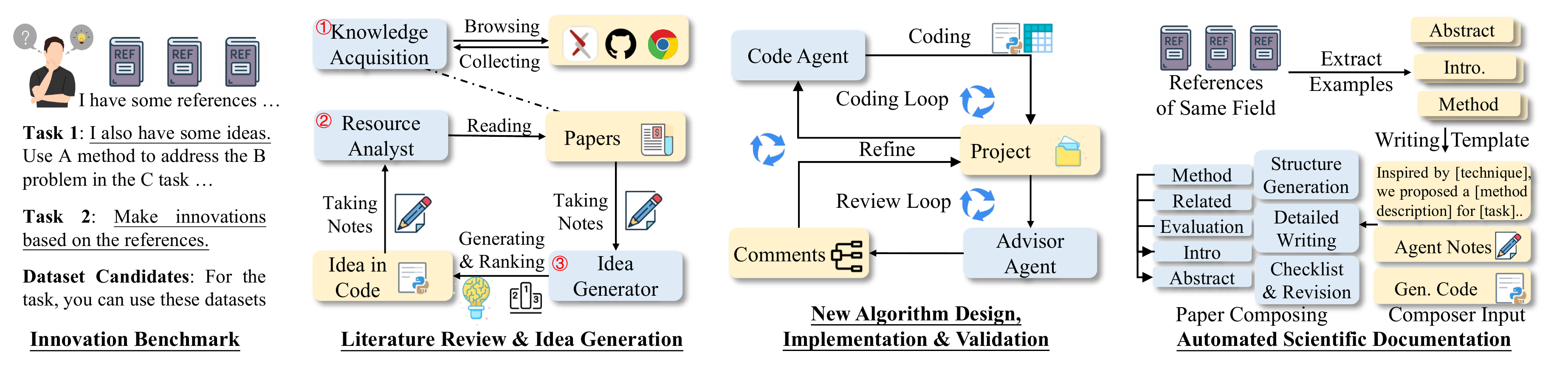
图2:AI-Researcher 框架详细架构。展示了用于端到端科学发现的全自动化 LLM 智能体系统,无缝编排文献综述、想法生成、算法实现、实验验证和论文写作等环节。
阶段一:文献综述与想法生成
1. Knowledge Acquisition Agent(知识获取智能体)
这个智能体负责搜集弹药------找到高质量的参考代码和论文。
工作流程:
- 用户只需提供 10-15 篇参考论文(远少于人类研究者需要的量)
- 智能体自动在 GitHub 上筛选至少 5 个高质量代码仓库
- 筛选标准包括:
- 📅 代码新鲜度(优先选择最新实现)
- ⭐ GitHub 星标数(社区认可度)
- 📚 README 完整性(文档质量)
- 🎯 领域相关性(与研究方向的匹配度)
- 📊 引用影响力(学术影响)
- 自动从 arXiv 下载对应论文的 LaTeX 源码
安全保障:所有操作都在 Docker 容器中执行,确保系统安全。
2. Resource Analyst Agent(资源分析智能体)
这个智能体负责消化知识------把复杂论文转化为可操作的信息。
它包含两个子智能体:
- Paper Analyst(论文分析师):从 LaTeX 文件中提取数学公式和理论定义
- Code Analyst(代码分析师):从代码仓库中找到对应的实现
核心工作:
- 概念分解:把研究目标拆解成原子学术概念
- 数学形式化:用 RAG 模式从论文中提取数学表达式
- 实现分析:定位每个数学表达式对应的代码实现
- 知识整合:建立理论↔实现的双向映射
最终生成一份详细的研究报告 ,作为后续开发的基础。Plan Agent 会把这份报告转化为具体的实施计划,包括数据集准备、训练策略和测试方案。
3. Idea Generator(想法生成器)
这是整个系统中最具创造性的部分------从无到有地产生研究想法。
发散-收敛框架:
输入:文献分析结果
↓
发散阶段:生成 5 个不同的研究方向
↓
收敛阶段:按以下标准评估和筛选
• 科学新颖性
• 技术可行性
• 变革潜力
↓
输出:最优研究方案每个研究提案都包含完整的六要素:
- Challenges:当前研究的根本局限
- Existing Methods:现有方法及其盲点
- Motivation:为什么需要新方法
- Proposed Method:创新的技术方案
- Technical Details:具体实现细节
- Expected Outcomes:预期的科学和实际影响
阶段二:算法设计、实现与验证
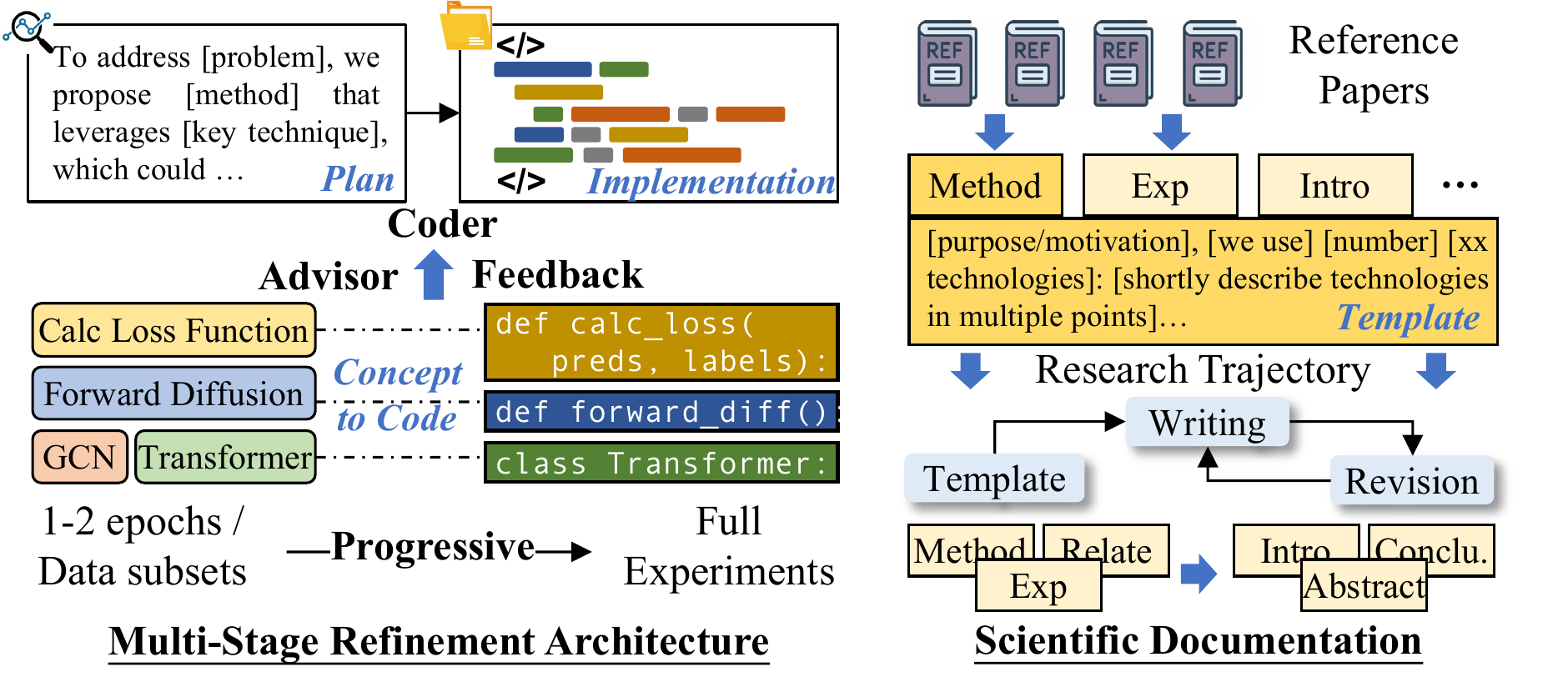
图3:多阶段实现细化和自动化科学文档说明图。左侧展示代码智能体与顾问智能体的迭代反馈循环(类似导师-学生关系),右侧展示层级式论文生成的三阶段流程。
Code Agent(代码智能体)
这是系统的执行者,负责把研究想法变成可运行的代码。
核心能力:
- 在受控工作区中创建结构化的代码实现
- 严格遵循代码独立性原则
- 确保学术概念被正确转化为代码
- 持续验证实现是否符合计划
Advisor Agent(顾问智能体)
这是系统的质量把关者,扮演"导师"角色。
工作职责:
- 系统比较代码与原子研究概念
- 通过专业工具和可视化分析结果
- 生成详细的评估报告
- 提供具体、可操作的修改建议
渐进式实验循环
整个实验过程遵循科学的迭代方法:
初始实现
↓
小规模测试(1-2 epoch,小数据集)
↓
基础可行性验证
↓ 通过
完整规模实验
↓
顾问评估 + 补充实验建议
↓
迭代优化直到满意如果多次尝试后仍无法成功执行,任务会被标记为"不可行"------这种诚实的失败承认比强行输出错误结果更有价值。
阶段三:自动化科学文档
Documentation Agent(文档智能体)
最后一步是把所有研究成果转化为学术论文。
三阶段层级文档生成:
| 阶段 | 内容 | 目标 |
|---|---|---|
| 1 | 研究轨迹综合 | 基于领域模板生成结构大纲 |
| 2 | 模板引导结构 | 按章节细化内容,保持跨文档一致性 |
| 3 | 层级文档过程 | 用学术检查表系统验证,修正错误遗漏 |
克服的关键挑战:
- 长文档一致性:学术论文动辄几千字,普通 LLM 很难保持前后逻辑一致
- 幻觉问题:AI 可能编造不存在的实验结果
- 格式规范:学术论文有严格的格式要求
通过层级分解和检查表机制,Documentation Agent 能够生成符合发表标准的学术论文。
🧪 评测体系:Scientist-Bench
为了客观评估 AI 的科研能力,研究团队开发了 Scientist-Bench------首个全面评估自主科研系统的基准测试。
数据集构成
| 研究领域 | 论文数量 | Level-1 任务 | Level-2 任务 |
|---|---|---|---|
| 扩散模型 (Diffusion Models) | 4 | 4 | 1 |
| 向量量化 (Vector Quantization) | 6 | 6 | 1 |
| 图神经网络 (GNN) | 7 | 7 | 1 |
| 推荐系统 (Recommender Systems) | 5 | 5 | 3 |
| 总计 | 22 | 22 | 6 |
论文来源:2022-2024年各领域顶会论文,经过严格的去匿名化处理。
两级任务设计
Level-1:引导式创新(Guided Innovation)
- 给定明确的研究指令 + 参考文献
- 测试 AI 的执行能力:能否按照指定方向完成研究
Level-2:开放式探索(Autonomous Exploration)
- 只给参考文献,不给研究指令
- 测试 AI 的创新能力:能否自主发现研究方向
两阶段评估协议
阶段一:实现验证
- 使用代码审查智能体检验实现的正确性
- 指标:
- Completeness(完整性):代码能否成功运行
- Correctness(正确性):实现是否符合研究提案(1-5分)
阶段二:科学质量评估
- 将 AI 论文与人类论文进行成对比较
- 使用 5 个不同的 LLM 作为评审员
- 评分范围:-3(显著较差)到 +3(显著更好)
- 关键指标:
- 平均评分:AI 与人类的质量差距
- 可比比例:评分 ≥ -1 的论文占比
📊 实验结果
RQ1:代码实现质量如何?
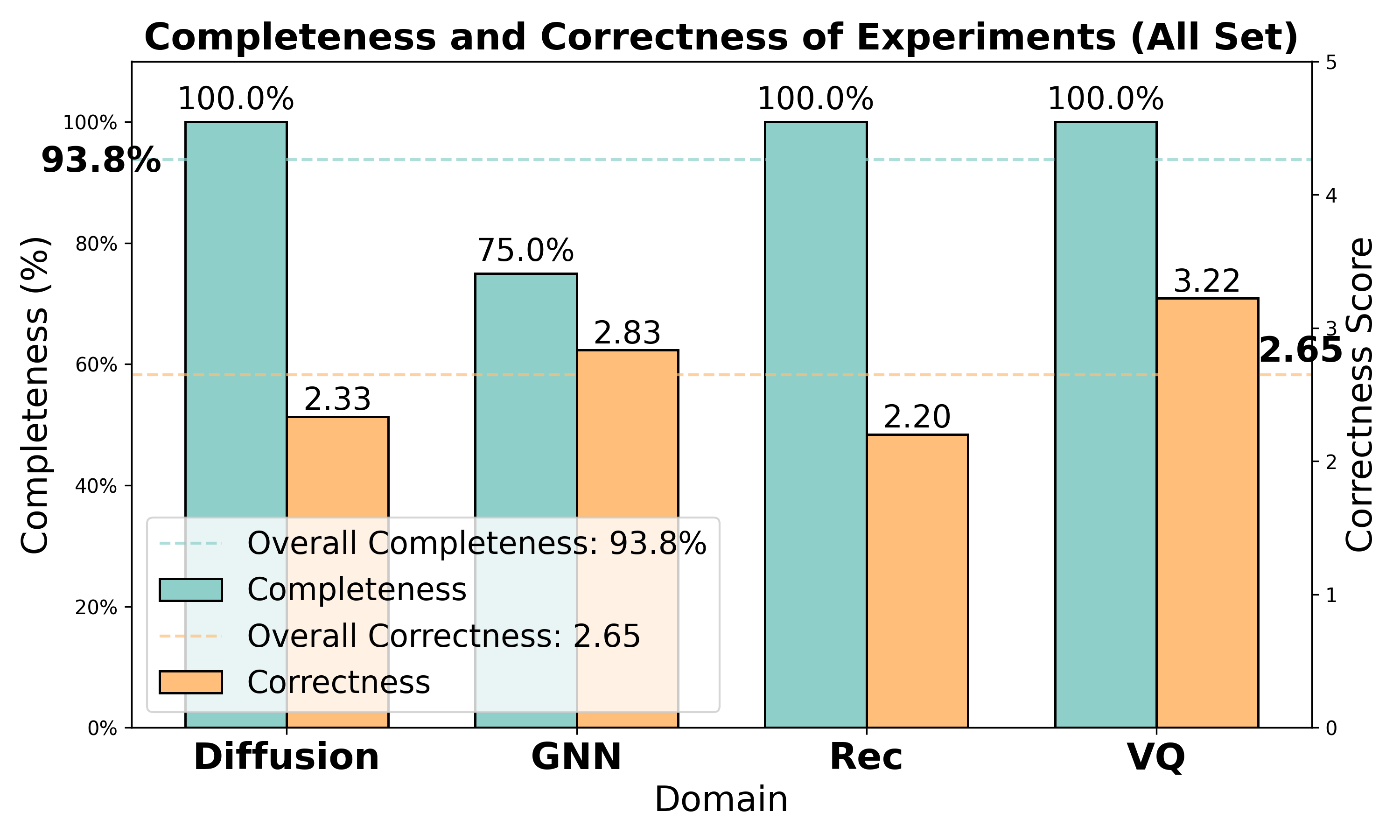
图4:使用 Claude 系列模型的实现质量评估。横轴为不同研究领域,左侧纵轴为完整性(橙色柱),右侧纵轴为正确性(蓝色线)。
核心发现:
- 完整性:93.8% ------ 绝大多数任务都能生成可运行的代码
- 正确性:2.65/5 ------ 超过中位数,表明多数需求被正确实现
- 少数失败案例主要是张量维度不匹配等复杂技术问题
领域差异:
- VQ 领域正确性最高(3.22分)
- 推荐系统领域正确性较低(2.20分)
- 这反映了不同领域的固有难度差异
RQ2:Claude vs GPT-4o,谁更适合做科研?
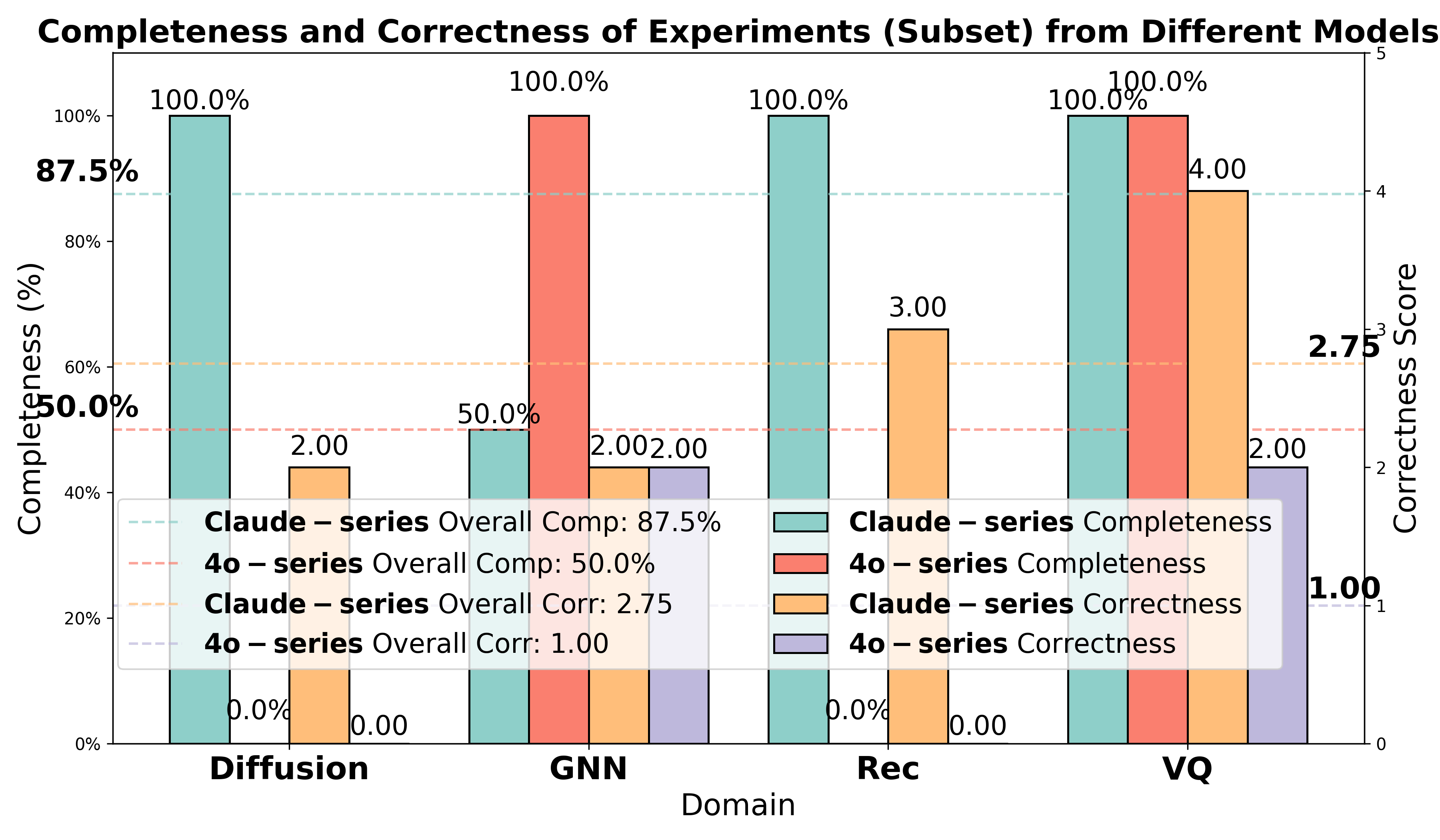
图5(左):Claude 系列与 4o 系列模型在实现完整性和正确性上的对比。
惊人的差距:
| 指标 | Claude 系列 | 4o 系列 |
|---|---|---|
| 完整性 | 87.5% | 50% |
| 正确性 | 2.75 | 1.0 |
GPT-4o 的致命问题:
在一个需要实现"扩散模型 + Vision Transformer"的任务中,GPT-4o 声称已经实现了 Diffusion Transformer,但检查代码发现只有 ViT,完全没有扩散模型组件!
这种"过度简化"的倾向在复杂任务中尤为明显,而 Claude 则能通过反复调试解决问题。
RQ3:Level-1 vs Level-2,哪个更难?

图5(右):Claude 系列在 Level-1(引导式)和 Level-2(创新式)任务上的表现对比。
反直觉的发现:
| 指标 | Level-1 | Level-2 |
|---|---|---|
| 完整性 | 87.5% | 100% |
| 正确性 | 2.5 | 2.25 |
Level-2 任务虽然是"更难的"开放式探索,但完整性反而达到了100%!
可能的解释:
- AI 自主生成的想法与自身能力更匹配
- 遵循人类给定的复杂指令反而可能超出 AI 的实现能力
RQ4:AI 论文 vs 人类论文,差距有多大?
这是整篇论文最核心的问题。研究团队让多个 LLM 作为评审员,对比 AI 生成的论文和人类顶会论文。
Level-1 任务(引导式创新)结果:
| 评估模型 | 平均评分 | 可比比例 |
|---|---|---|
| GPT-4o | -0.53 | 81.82% |
| o1-mini | -1.09 | 54.55% |
| o3-mini | -1.51 | 13.64% |
| Claude-3.5 | -1.58 | 13.64% |
| Claude-3.7 | -1.70 | 22.73% |
关键洞察:
- AI 论文平均评分为负,说明整体质量仍低于人类顶会论文
- 但 15.79%~78.95% 的 AI 论文达到了可比质量
- 不同评估模型的评价差异巨大(说明单一 LLM 评审有偏见)
Level-2 任务(开放式探索)结果:
| 评估模型 | 平均评分 | 可比比例 |
|---|---|---|
| GPT-4o | -0.23 | 100% |
| o1-mini | -0.85 | 66.67% |
| o3-mini | -1.22 | 66.67% |
| Claude-3.5 | -0.65 | 66.67% |
| Claude-3.7 | -0.95 | 50.00% |
惊人发现 :开放式探索任务的表现显著优于引导式任务!
- 平均评分从 -0.53~-1.70 提升到 -0.23~-1.22
- 可比比例从 13.64%~81.82% 提升到 50%~100%
这表明 AI-Researcher 在自主探索时表现更好,而不是被动执行人类的指令。
RQ5:案例研究------AI 生成的代码长什么样?
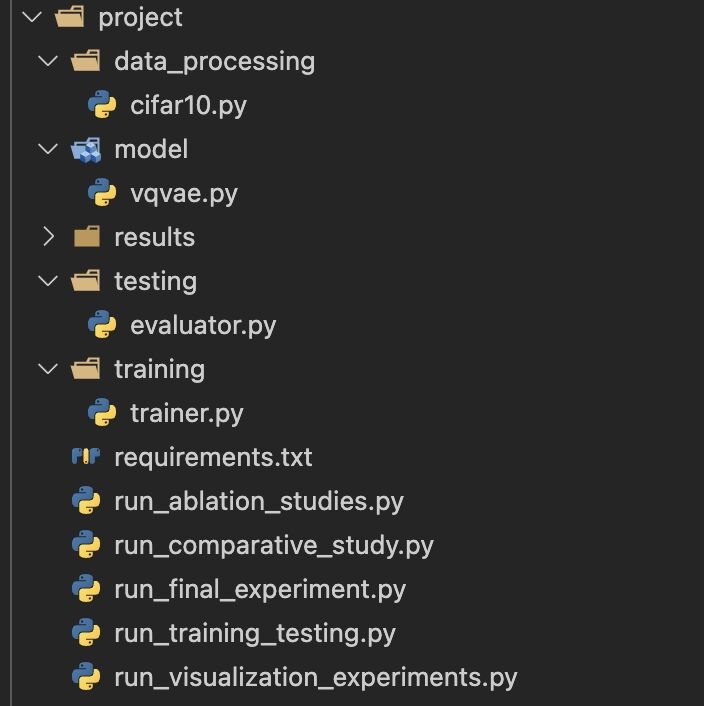
图6:AI-Researcher 生成的代码结构示例。展示了清晰的模块化设计,包括配置、数据、模型、训练器等组件。
代码质量亮点:
- ✅ 清晰的目录结构(configs/, data/, models/, trainers/)
- ✅ 模块化设计,各组件职责分明
- ✅ 自动生成的
main.py入口文件 - ✅ 配置与代码分离的最佳实践
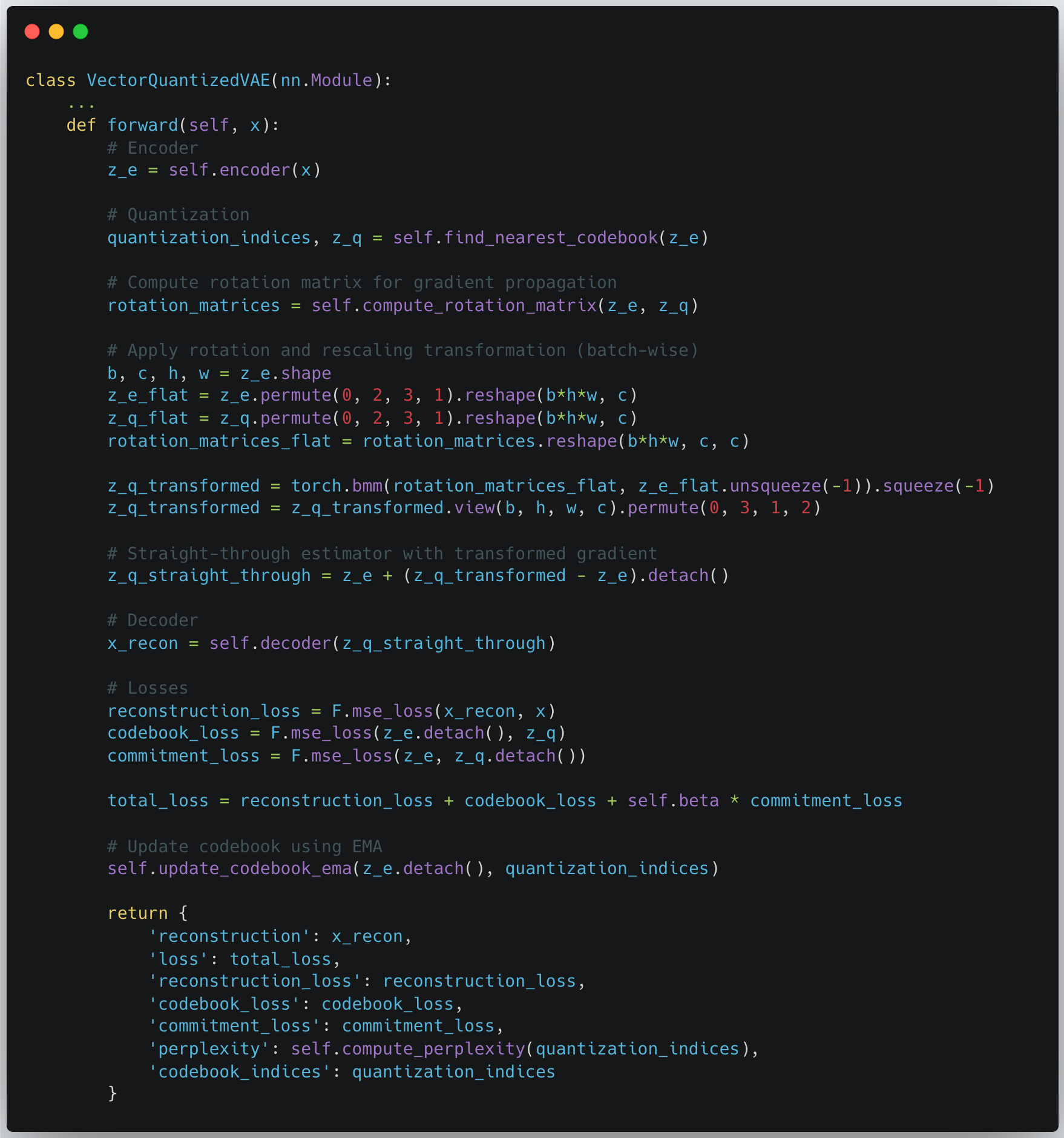
图7:AI-Researcher 生成的代码示例(一)。展示了模型定义和训练循环的实现。

图8:AI-Researcher 生成的代码示例(二)。展示了数据处理和实验配置的实现。
软件工程实践:
- 自动设计消融实验
- 自动生成可视化分析
- 遵循主流深度学习框架的代码规范
RQ6:失败案例分析------AI 还有哪些不足?

图9:AI-Researcher 生成研究的失败案例分析。左侧展示领域知识缺陷(如忽略 Gumbel 重参数化等前沿技术),右侧展示推理深度限制(如数学形式化能力不足)。
两大核心局限:
1. 领域知识缺陷
- 倾向使用传统方法而非前沿技术
- 例如:在图神经网络任务中忽略了 Gumbel 重参数化等高级优化方法
- 缺乏对最新研究动态的感知
2. 推理深度限制
- 难以进行多步复杂数学推导
- 倾向使用标准化的数学表达,而非创新性的公式构建
- 理论分析深度不够
根本原因:LLM 的知识来自预训练数据,难以突破其知识边界;同时,复杂的逻辑推理仍是当前 AI 的瓶颈。
🔬 技术细节深度解析
为什么选择多智能体架构?
单个 LLM 难以胜任完整的科研流程,原因包括:
- 上下文长度限制:科研涉及海量信息,超出单次对话的处理能力
- 专业化需求:不同任务需要不同的专业知识和工具
- 错误隔离:某个环节的错误不应影响整个系统
- 可扩展性:方便未来添加新的功能模块
多智能体架构通过分工协作解决了这些问题。
RAG 在 AI-Researcher 中的应用
检索增强生成(RAG) 是连接理论与实现的关键技术:
用户查询:如何实现 Attention 机制?
↓
向量检索:在论文数据库中搜索相关段落
↓
上下文增强:将检索结果与原始查询合并
↓
LLM 生成:基于增强上下文生成精确回答AI-Researcher 使用 RAG 实现:
- 从 LaTeX 文件中精确提取数学公式
- 从代码仓库中定位对应实现
- 建立公式↔代码的双向映射
Docker 容器化的安全考量
所有智能体操作都在 Docker 容器中执行:
优势:
- 🔒 安全隔离:防止恶意代码破坏主机系统
- 📦 环境一致:预装 PyTorch 等常用框架
- 🔧 动态扩展:智能体可自主安装额外依赖
- ♻️ 可复现性:相同容器配置保证实验可复现
论文评审智能体的可靠性验证
为确保 LLM 评审的可信度,研究团队进行了严格验证:
验证方法:
- 使用 ICLR 2021-2023 的接受/拒绝论文对作为金标准
- 让评审智能体判断哪篇论文质量更高
- 对比 AI 判断与人类专家的决策
验证结果:
| 评估模型 | 判断准确率 |
|---|---|
| GPT-4o | 81.25% |
| o3-mini | 90.62% |
| Claude-3.5 | 90.62% |
| Claude-3.7 | 81.25% |
结论:主流 LLM 的评审判断与人类专家高度一致(>80%),验证了评估体系的可靠性。
💡 思考与启示
对研究者的启示
-
AI 辅助科研时代已来临
- AI-Researcher 不是要取代人类研究者,而是成为强大的助手
- 它能处理繁琐的文献阅读、代码调试,让人类专注于创造性思考
-
开放式探索可能是 AI 的优势领域
- AI 在自主探索时表现反而更好
- 这启示我们可以让 AI 先探索,人类再筛选和指导
-
多样化评估的重要性
- 单一 LLM 评审存在偏见
- 未来需要更完善的自动化评估体系
当前局限与未来方向
局限:
- 领域知识受限于预训练数据
- 复杂数学推理能力不足
- 长程记忆管理仍是挑战
- 计算资源需求较高
未来方向:
- 增强记忆机制:开发跨工作流的知识库系统
- 提升推理深度:改进多步逻辑推理能力
- 实时知识更新:让 AI 能跟踪最新研究进展
- 更精细的评估体系:超越传统同行评审的局限
对 AI 发展的深远影响
AI-Researcher 代表了 AI 发展的一个重要里程碑------从工具 向智能体的转变。
按照 OpenAI 的五级演进模型:
- Level 1:对话系统(ChatGPT)
- Level 2:推理能力(o1/o3)
- Level 3-4:自主智能体(AI-Researcher 正在这个位置)
- Level 5:组织协调者
AI-Researcher 的成功表明,我们正在接近真正的自主智能体时代。
🛠️ 实际使用指南
如果你想亲自尝试 AI-Researcher,这里是一份快速入门指南。
环境准备
bash
# 克隆仓库
git clone https://github.com/HKUDS/AI-Researcher.git
cd AI-Researcher
# 安装依赖
pip install -r requirements.txt
# 配置 API 密钥
export ANTHROPIC_API_KEY="your-claude-api-key"
# 或
export OPENAI_API_KEY="your-openai-api-key"两种使用模式
模式一:引导式创新(Level-1)
提供详细的研究想法描述,系统据此生成实现策略。
python
# 示例:给定明确的研究指令
research_idea = """
我们想要研究基于图神经网络的推荐系统,
核心创新是引入对比学习来增强用户-物品表示...
"""
# 提供 10-15 篇参考文献
references = ["paper1.pdf", "paper2.pdf", ...]
# 运行 AI-Researcher
ai_researcher.run(idea=research_idea, references=references)模式二:开放式探索(Level-2)
只提供参考文献,让系统自主生成创新想法。
python
# 示例:不给具体指令,让 AI 自主探索
references = ["paper1.pdf", "paper2.pdf", ...]
# AI 会自动:
# 1. 分析文献,找到研究空白
# 2. 生成 5 个研究方向
# 3. 筛选最优方案
# 4. 实现并撰写论文
ai_researcher.run(references=references, mode="exploration")硬件要求
| 配置项 | 最低要求 | 推荐配置 |
|---|---|---|
| CPU | 8核 | 16核+ |
| 内存 | 32GB | 64GB+ |
| GPU | 可选(用于训练) | RTX 3090+ |
| 存储 | 100GB | 500GB+ SSD |
成本估算
使用 Claude-3.5-sonnet 作为主模型,单次完整研究流程的 API 成本约:
| 阶段 | Token 消耗 | 估算成本(美元) |
|---|---|---|
| 文献分析 | ~100K | ~$1.5 |
| 想法生成 | ~50K | ~$0.75 |
| 代码实现 | ~200K | ~$3 |
| 论文撰写 | ~100K | ~$1.5 |
| 总计 | ~450K | ~$6.75 |
注:实际成本会因任务复杂度而异
相比之下,OpenAI 的类似商业服务(如 Deep Research)月费高达 $200/月,AI-Researcher 的开源特性大大降低了使用门槛。
常见问题排查
Q1:代码执行失败怎么办?
- 检查 Docker 环境是否正确配置
- 确认必要的 Python 包已安装
- 查看错误日志,尝试增加迭代次数
Q2:生成的论文质量不佳?
- 提供更多高质量的参考文献
- 选择与任务更匹配的 LLM(推荐 Claude 系列)
- 检查研究指令是否足够清晰
Q3:运行速度太慢?
- 使用更快的 LLM 模型
- 减少文献数量
- 优化 Docker 容器配置
⚖️ 与相关工作的对比
与 OpenAI Deep Research 的对比
| 特性 | AI-Researcher | OpenAI Deep Research |
|---|---|---|
| 开源 | ✅ 是 | ❌ 否 |
| 价格 | ~$7/次 | $200/月 |
| 代码生成 | ✅ 支持 | ❌ 不支持 |
| 实验验证 | ✅ 支持 | ❌ 不支持 |
| 论文撰写 | ✅ 完整论文 | 研究报告 |
| 自定义性 | 高 | 低 |
与 AI-Scientist (Sakana AI) 的对比
| 特性 | AI-Researcher | AI-Scientist |
|---|---|---|
| 研究领域 | 多领域 | 主要 ML |
| 想法生成 | 发散-收敛框架 | 基础生成 |
| 代码质量 | 导师-学生迭代 | 单次生成 |
| 评估基准 | Scientist-Bench | 无标准基准 |
| 实验规模 | 22篇论文 | 较小规模 |
核心优势总结
- 完整工作流:唯一覆盖"文献→想法→代码→论文"全流程的开源系统
- 高质量代码:导师-学生迭代机制显著提升实现质量
- 标准化评测:Scientist-Bench 提供了业界首个全面评测基准
- 成本友好:开源免费,API 成本远低于商业方案
🔮 未来展望
短期改进方向
- 多模态支持:扩展到图像、视频等多模态研究
- 领域扩展:从 AI 领域扩展到生物、化学、物理等
- 协作模式:支持人机协作的混合研究模式
长期愿景
想象一下 5 年后的科研场景:
研究者早上醒来,AI-Researcher 已经分析了昨晚发布的 100 篇新论文,生成了 3 个有前景的研究方向,并完成了初步实验。研究者只需要审阅结果,选择最有潜力的方向深入探索。
这不是科幻,而是正在逐步实现的未来。AI-Researcher 只是这个旅程的开始。
潜在风险与伦理思考
当然,我们也需要正视一些潜在问题:
- 学术诚信:AI 生成的论文应如何标注?
- 就业影响:科研助理岗位会受到冲击吗?
- 知识产权:AI 基于他人论文生成的创新,归属如何界定?
- 质量把控:如何防止低质量 AI 论文泛滥?
这些问题需要学术界、产业界和政策制定者共同讨论解决。
🔗 资源链接
- 论文链接 :https://arxiv.org/abs/2505.18705
- 开源代码 :https://github.com/HKUDS/AI-Researcher
- 研究团队:香港大学数据科学实验室(HKUDS)
- 在线 Demo:https://novix.science/chat
📚 参考资料
- Tang, J., Xia, L., Li, Z., & Huang, C. (2025). AI-Researcher: Autonomous Scientific Innovation. arXiv:2505.18705
- Lu, C., et al. (2024). The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
- Shinn, N., et al. (2023). Storm: Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking
- Li, X., et al. (2024). Chain-of-Ideas: A Novel Paradigm for Research Ideation
作者说:这篇论文让我们看到了 AI 辅助科研的巨大潜力。虽然 AI 目前还不能完全取代人类研究者,但它已经能够承担相当一部分繁重的工作。未来,人机协作将成为科研的新范式------AI 负责广度探索,人类负责深度思考和创造性突破。