档案数字化进程中,财务报表、统计台账、人事登记表等包含大量复杂表格的资料,一直是成本最高、效率最低的"硬骨头"。传统OCR识别结果支离破碎,表格结构尽失,导致大量数字化档案沦为不可检索、不可分析的"死数据"。如何突破这一瓶颈,释放档案深层价值?一种专注于复杂表格内容的精准解析与表格结构的版面还原的智能表格识别技术,正重新定义档案数字化的质量标准。
复杂表格识别:破解档案数字化难题
档案资料中广泛存在手写登记表、财务报表、人事档案卡、统计汇总表等结构复杂、格式多样的表格内容。这些表格往往具有以下特点:
- 表格线缺失或模糊(如扫描件质量差、老旧纸张)
- 合并单元格、嵌套表格、跨页表格普遍存在
- 手写与印刷体混排,字体大小不一
- 多语言、多栏布局、非标准排版
传统OCR技术在面对此类复杂表格时,常常出现内容错位、结构丢失、语义断裂等问题,难以满足档案系统对数据完整性与准确性的严苛要求。
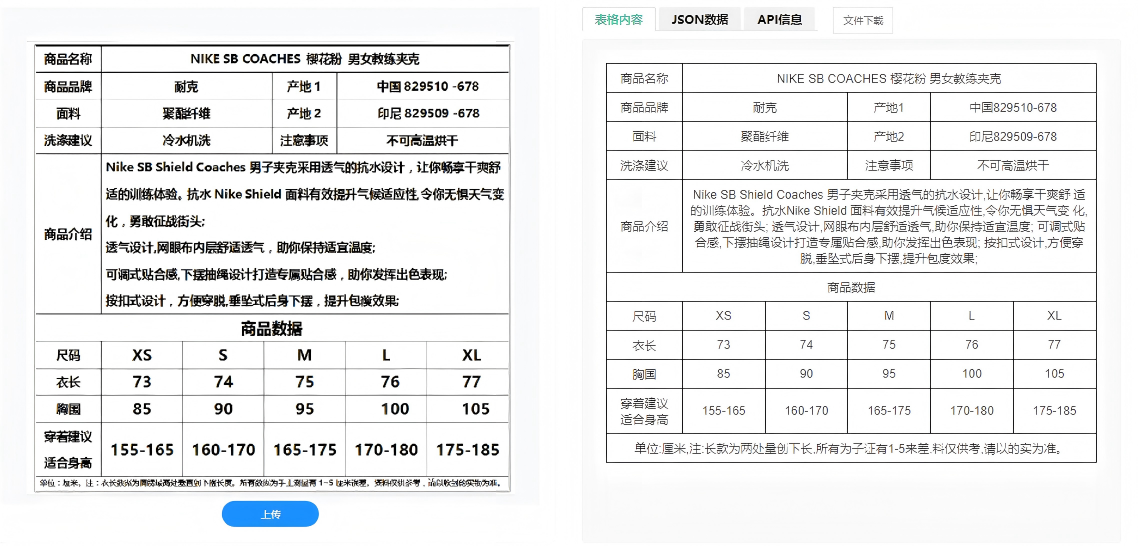
技术原理深度剖析:如何实现复杂表格的"理解"与"重生"
表格识别技术基于"感知-理解-还原"三位一体的深度学习架构,融合计算机视觉、自然语言处理与版面分析技术,实现从原始图像到结构化数据的端到端解析。其核心技术流程如下:
1.表格区域检测(Table Detection)
采用YOLOv8目标检测模型,在复杂背景中精准定位一个或多个表格区域,即使面对无边框、虚线框或手绘表格,也能通过上下文语义与布局先验进行鲁棒识别。
2.单元格结构解析(Cell Structure Parsing)
引入基于图神经网络的表格结构建模方法,对行/列进行聚类与对齐,智能推断合并单元格、跨行跨列表头等复杂结构。该模块不依赖显式线条,而是通过文本位置、字体、间距等视觉线索重建逻辑网格。
3.内容识别与语义校正(Content Recognition & Semantic Refinement)
集成多语言OCR引擎,支持印刷体、手写体及低质量扫描文本的高精度识别;同时结合领域词典与上下文语义模型,对易混淆字符(如"0/O"、"1/l/I")进行智能纠错,提升字段级准确率。
4.版面还原与结构化输出(Layout Reconstruction & Structured Export)
在保留原始排版风格的基础上,生成可视化还原图(如HTML或带坐标的PDF),并同步输出多种结构化格式(JSON、CSV、Excel、数据库记录),确保"所见即所得"的一致性,便于人工复核与系统对接。
整个流程支持GPU加速与批量处理,单页复杂表格平均处理时间低于2秒,结构还原准确率超过98.5% 。
赋能档案管理系统:从"图像存档"到"结构化知识库"
在档案管理系统的实际部署中,表格识别技术实现了三大核心价值:
1.自动化结构化入库
将扫描后的档案图像自动解析为结构化数据库记录,无需人工录入,大幅提升归档效率。例如,一份包含50个字段的人事档案表可在数秒内完成全字段提取,并直接写入档案数据库。
2.全文检索与智能关联
表格内容被转化为可索引的文本数据后,用户可通过关键词、字段值(如"姓名=张三""入职年份=2010")快速定位相关档案,打破"图像不可搜"的信息孤岛。
3.历史数据活化与分析
长期积累的纸质表格数据经识别后形成结构化时间序列,为统计分析、趋势预测、合规审计等高级应用提供数据基础。例如,财务档案中的历年收支表可自动生成可视化图表,辅助决策。
表格识别的典型应用场景
- 政府机关档案数字化:人事任免表、户籍登记表、行政审批表等批量处理;
- 企业人事与财务档案管理:员工履历表、报销单、工资单的自动归档与查询;
- 医疗健康档案系统:病历记录表、体检报告、药品使用清单的结构化解析;
- 司法与公证文书处理:案件登记表、证据清单、调解协议书的智能提取。
表格识别技术不仅解决了"看得见"的问题,更实现了"看得懂、用得上"的目标。通过将图像级档案转化为可计算、可关联、可分析的结构化知识单元,该技术正成为推动档案管理系统从"数字化存档"迈向"智能化服务"的核心驱动力。未来,结合大模型语义理解能力,将进一步释放历史档案的数据价值,构建面向未来的数字记忆基础设施。