什么是消息队列?
消息队列(MQ)是实现系统间异步通信的核心中间件,核心逻辑为:数据以「消息」形式存入队列,遵循先进先出原则,由消息生产者发送、消费者异步拉取处理,核心达成系统解耦、异步提速、流量削峰三大目标,是分布式架构中保障高可用、高并发的必备组件。
|-------|------------------|-----------------------------------------------------|
| MQ 角色 | 快递系统对应角色 | 核心职责 |
| 生产者 | 寄快递的你 | 产生 "消息"(快递),并把消息发送到 MQ 中(把快递交给快递公司)。 |
| 交换机 | 快递公司的分拣中心 | 接收生产者发来的消息,根据路由规则,把消息转发到对应的队列(分拣中心把快递分到不同的配送网点)。 |
| 队列 | 小区的快递柜 / 快递网点的货架 | 存储待处理的消息(存放待取的快递),消息一旦被消费就会被移除(快递被取走),支持持久化(快递不会丢)。 |
| 消费者 | 取快递的你 / 配送员 | 监听队列,从队列中取出消息并处理(从快递柜取走快递,拆包使用)。 |
++通用工作流程++
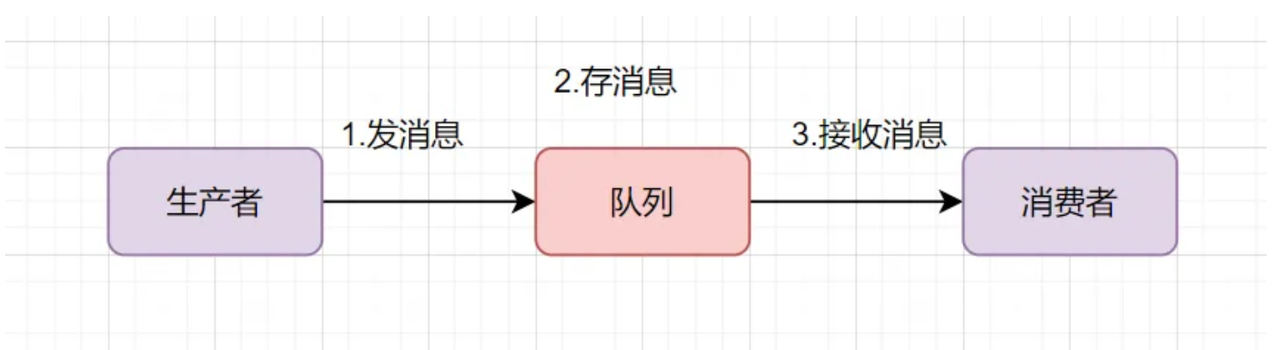
-
生产者:业务系统将待传递数据封装为消息,发送至消息队列;
-
消息存储:队列接收消息并持久化,按先进先出规则有序存放;
-
消费者:业务系统监听队列,主动拉取消息并执行业务处理;
-
完成确认:消费者处理成功后向队列反馈确认,队列移除该消息;处理失败则触发重试或转入死信队列。
消息队列怎么选型?
Kafka、ActiveMQ、RabbitMQ、RocketMQ来进行不同维度对比。
|-------|----------|-----------|---------------|
| 特性 | RabbitMQ | RocketMQ | Kafka |
| 单机吞吐量 | 万级 | 10 万级 | 10 万级 |
| 时效性 | 微秒级 | 毫秒级 | 毫秒级 |
| 可用性 | 高(主从) | 非常高(分布式) | 非常高(分布式) |
| 消息重复 | 至少一次 | 至少一次 最多一次 | 至少一次 最多一次 |
| 消息顺序性 | 有序 | 有序 | 分区有序 |
| 支持主题数 | 百万级 | 千级 | 百级,多了性能严重下滑 |
| 消息回溯 | 不支持 | 支持(按时间回溯) | 支持(按offset回溯) |
选择建议:
-
++高吞吐海量数据场景++(秒杀、日志收集、大数据):核心诉求是扛住瞬时高并发、处理海量消息,优先选 Kafka、RocketMQ。比如天猫双十一秒杀、用户行为日志采集,二者的高吞吐特性可轻松应对流量洪峰,避免系统过载。
-
企业级核心业务场景(金融交易、电商订单):核心诉求是可靠性、事务支持、稳定性,优先选 RocketMQ、RabbitMQ。比如金融转账、电商订单状态同步,++RocketMQ 的++ ++分布式++ ++事务消息、RabbitMQ 的确认机制,可保障消息不丢、不重复。++
-
++大规模多主题场景++(多租户平台、SaaS 服务):核心诉求是高主题容量、灵活扩展,优先选 RabbitMQ、RocketMQ,避免选 Kafka(百级主题上限易成为瓶颈)。
消息队列使用场景有哪些?
-
系统 解耦:将多个系统间的直接网络调用,改造为基于消息队列的异步通信。只要业务操作无需同步执行,即可通过消息队列传递数据,实现系统间的完全解耦。即使某一系统故障,也只会导致消息在队列中堆积,不会影响其他系统的正常运行,大幅提升整体架构的容错性。
-
异步通信 提速:针对包含多步骤的业务流程,若步骤间无需同步完成,可通过消息队列实现异步处理。核心业务流程执行完毕后立即返回结果,非核心流程的任务被封装为消息发送至队列,由对应系统异步消费处理。此举能显著缩短核心流程的响应时间,提升用户体验。
-
流量削峰填谷:应对系统的突发高并发流量冲击,将瞬时涌入的大量请求消息缓存至队列中。下游系统无需直面流量高峰,而是按照自身最大处理能力匀速消费队列中的消息,避免因流量过载导致系统或数据库崩溃。保障系统在高峰时段的稳定运行,同时兼顾业务处理的完整性。
如何保证数据一致性,事务消息如何实现?
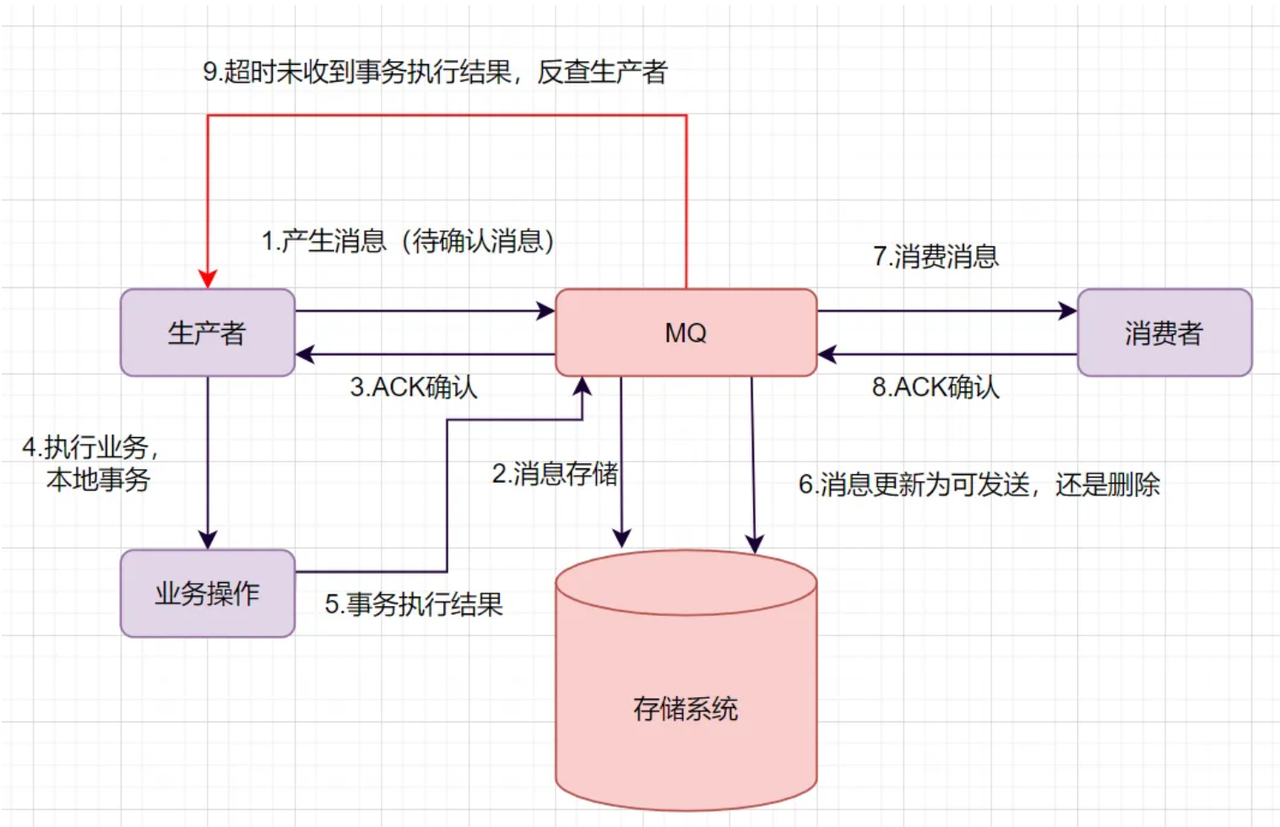
要保证数据一致性,核心是通过事务消息将 "本地业务操作" 与 "消息发送" 绑定为一个原子操作,避免 "业务成功但消息未发" 或 "消息已发但业务失败" 的情况。
-
发送 "半事务消息":生产者(订单系统)先向 MQ 发送一条待确认状态的消息,消息内容包含订单信息,但此时 MQ 不会将消息推送给消费者。
-
MQ 持久化半事务消息:MQ 收到半事务消息后,将其以 "待发送" 状态持久化到存储系统(如磁盘文件 / 数据库),保证消息不会丢失。
-
MQ 返回 ACK 给生产者:MQ 告知生产者 "半事务消息已成功存储",此时生产者可以执行本地业务。
-
生产者执行本地事务:生产者执行核心业务逻辑(如创建订单),这一步是本地数据库事务(比如订单表的
insert操作)。 -
反馈本地事务结果给 MQ:
-
若本地事务执行成功(订单创建成功):生产者向 MQ 发送
commit指令; -
若本地事务执行失败(订单创建失败):生产者向 MQ 发送
rollback指令。
-
-
MQ 更新消息状态:
-
收到
commit:MQ 将消息状态从 "待发送" 改为 "可发送"; -
收到
rollback:MQ 直接删除这条半事务消息,不会推送给消费者。
-
-
MQ 推送消息给消费者:若消息状态为 "可发送",MQ 将消息推送给对应的消费者(如下游库存系统)。
-
消费者消费并反馈 ACK:消费者接收消息并执行业务(如扣减库存),消费完成后向 MQ 返回 ACK;MQ 收到 ACK 后,在存储系统中删除该消息。
RabbitMQ
RabbitMQ如何保证消息不丢失?
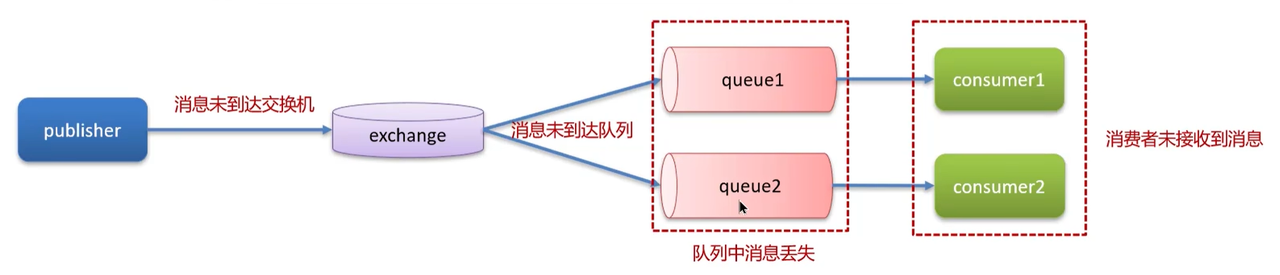
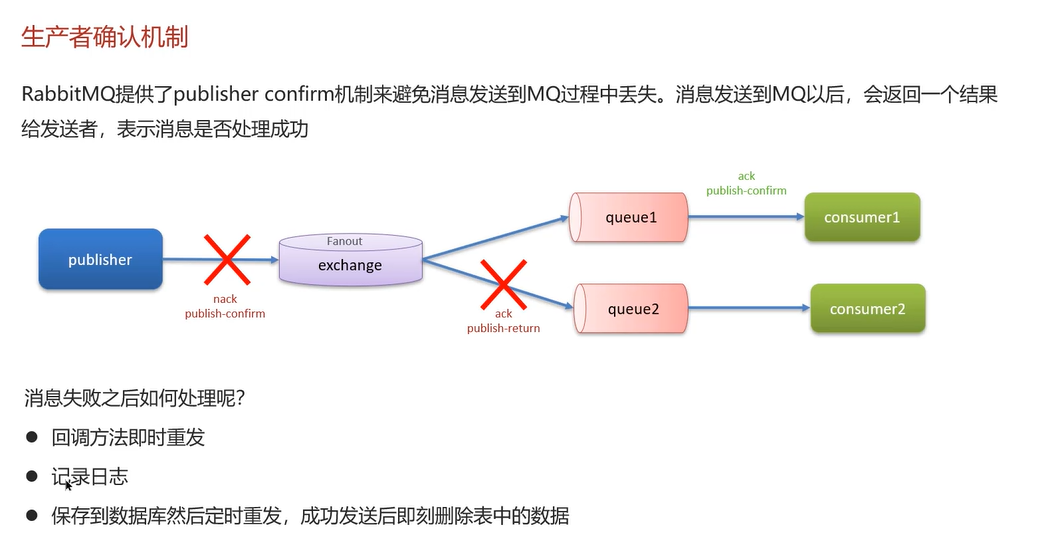
消息生产阶段:需同时开启publisher confirm 和publisher return两类机制:
-
开启
publisher confirm:生产者发消息后,等待 RabbitMQ 返回ack/nack:-
收到
ack:表示消息成功投递到交换机; -
收到
nack:表示消息投递到交换机失败,触发有限次重试,重试失败则存本地消息表定时兜底。
-
-
开启
publisher return:若消息成功到交换机,但未找到匹配的队列(路由失败),RabbitMQ 会通过return机制返回消息,此时需捕获该事件:可先尝试重新路由,重试失败则存本地消息表定时兜底。
只有同时处理confirm(投递交换机失败)和return(路由队列失败)这两种情况,才能完整覆盖 RabbitMQ 生产阶段的消息丢失风险。

消息存储阶段:需从交换机、队列、消息三个维度强制开启持久化,确保消息写入磁盘而非仅存于内存:
-
交换机持久化 :创建交换机时指定
durable=true,确保 MQ 重启后交换机不会丢失; -
队列持久化 :通过
QueueBuilder.durable("s.queue")创建持久化队列,保证队列在 MQ 重启后仍存在; -
消息持久化:Spring AMQP 中消息默认持久化,RabbitMQ 收到消息后,会先将消息写入磁盘,再返回 ACK 给生产者,避免 MQ 宕机时内存中的消息丢失。
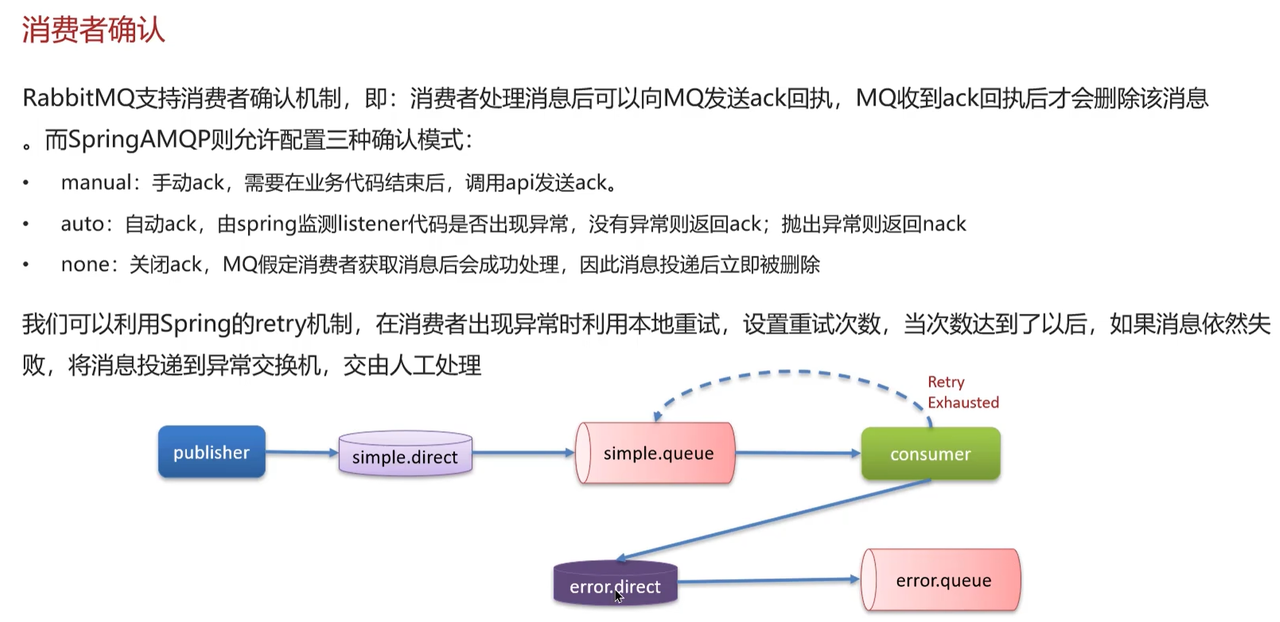
消息消费阶段:采用auto 自动确认模式,结合 Spring 的重试机制实现可靠消费:
-
配置自动确认:将 Spring AMQP 的消费确认模式设为
auto,由 Spring 自动监测监听器代码的执行状态; -
自动 ACK/NACK:业务处理无异常时,Spring 自动向 RabbitMQ 返回
ack,MQ 删除该消息;若业务抛出异常,Spring 会自动返回nack,触发消息重试; -
异常兜底:通过 Spring retry 机制设置重试次数,重试达到上限仍失败的消息,会被投递到异常交换机,交由人工后续处理,避免消息丢失或无限重试。
RabbitMQ消息重复消费怎么解决?/ 如何保证幂等写?
++解决重复消费问题的本质,就是在消费端针对业务写操作做幂等设计++
幂等性是指同一操作的多次执行对系统状态的影响与一次执行结果一致。例如,支付接口若因网络重试被多次调用,最终应确保仅扣款一次。实现幂等写的核心方案:
- 唯一标识(幂等键):客户端为每个请求生成全局唯一ID(如 UUID、业务主键),服务端校验该ID是否已处理,适用场景接口调用、消息消费等。
-
生产者:给订单消息绑定唯一业务标识:生产者发送 "创建订单" 消息时,将订单 ID作为全局唯一业务标识(幂等键),写入消息头,确保每条订单消息都有唯一标识
-
消费端:基于唯一标识做幂等校验,消费端先校验订单 ID 是否已处理,未处理则通过事务执行 "扣减余额 + 生成订单",处理完成后标记已消费;已处理则直接跳过。
- 数据库事务 + 乐观锁:通过版本号或状态字段控制并发更新,确保多次更新等同于单次操作,适用场景数据库记录更新(如余额扣减、订单状态变更)。
比如 "扣减用户余额 + 生成订单" 这两个操作,用事务包裹后:
-
若两个操作都成功,事务提交,数据永久生效;
-
若其中一个操作失败(比如扣余额时用户余额不足),事务回滚,之前的操作会被撤销(不会出现 "扣了余额但没生成订单" 的情况)。
sql
-- 开启事务
BEGIN;
-- 查订单当前版本(假设当前version=1)
SELECT version FROM orders WHERE order_id = '123';
-- 更新时校验版本号:只有version等于查询到的1,才会更新成功
UPDATE orders SET status = '已支付', version = version + 1 WHERE order_id = '123' AND version = 1;
-- 判断更新行数:若为0,说明版本号不匹配(重复请求),回滚事务
IF ROW_COUNT() = 0 THEN ROLLBACK;
-- 否则提交事务
ELSE COMMIT;-
数据库唯一约束:利用数据库唯一索引防止重复数据写入,适用场景数据插入场景(如订单创建)。
-
分布式锁:通过锁机制保证同一时刻仅有一个请求执行关键操作,适用场景高并发下的资源抢夺(如秒杀)。
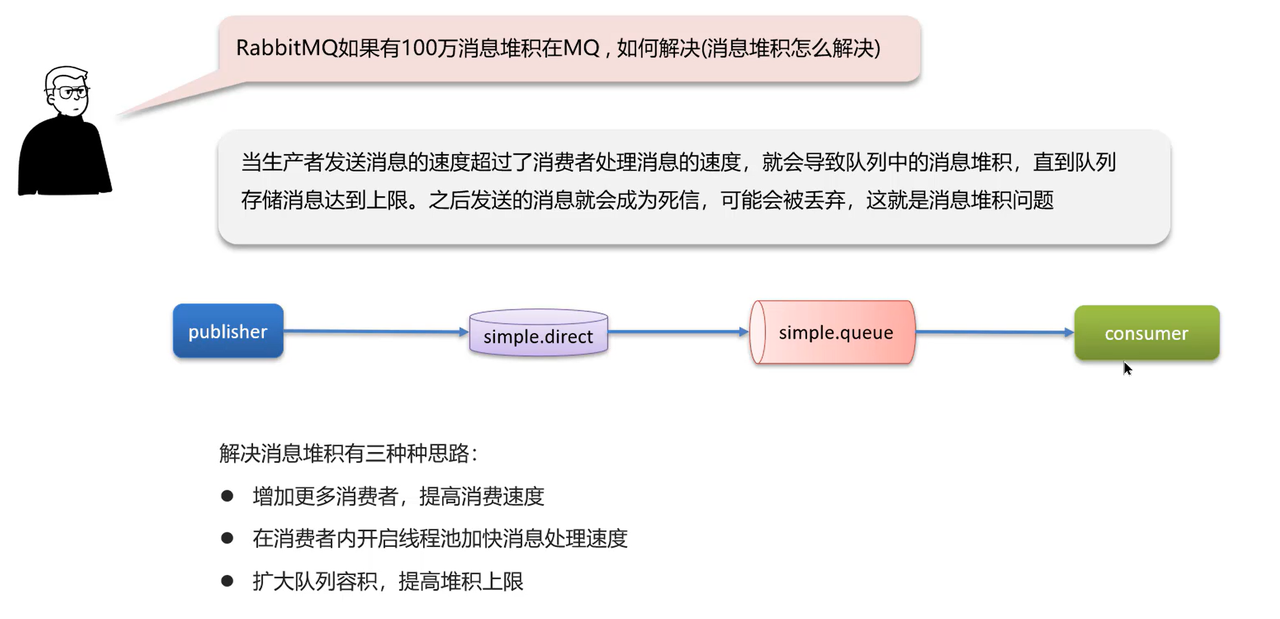
RabbitMQ如何解决消息堆积问题?
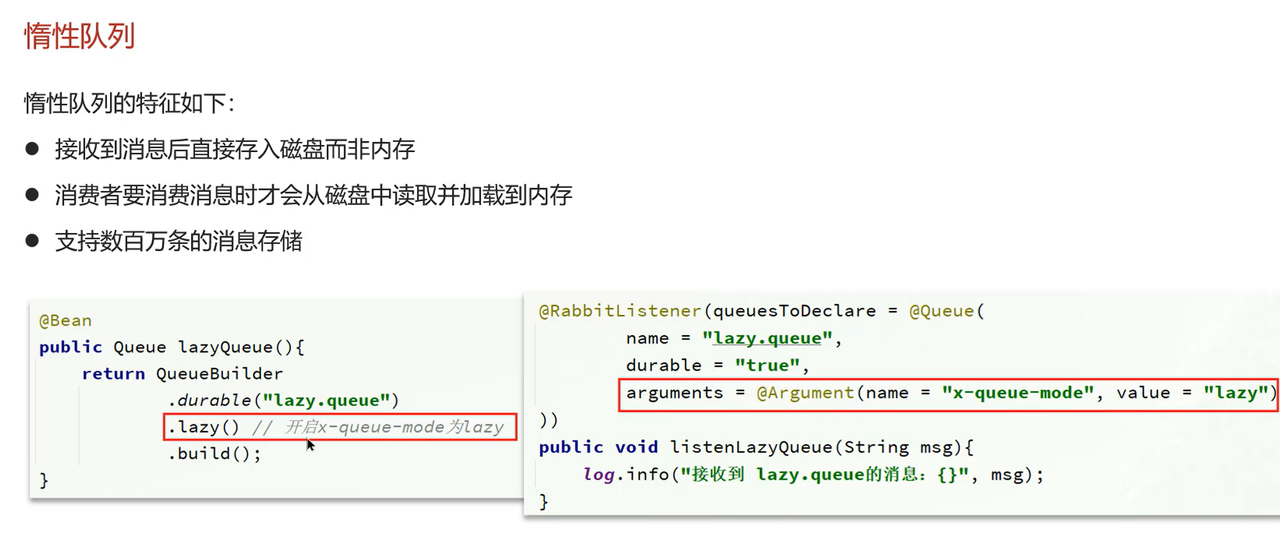
第三点:使用惰性队列,实现扩大队列容积,提高堆积上限
消息中间件RabbitMQ的可靠性保障怎么做?
RabbitMQ 的可靠性保障核心是确保 "消息不丢失、不重复、不积压"。(解决上述三大问题即可)
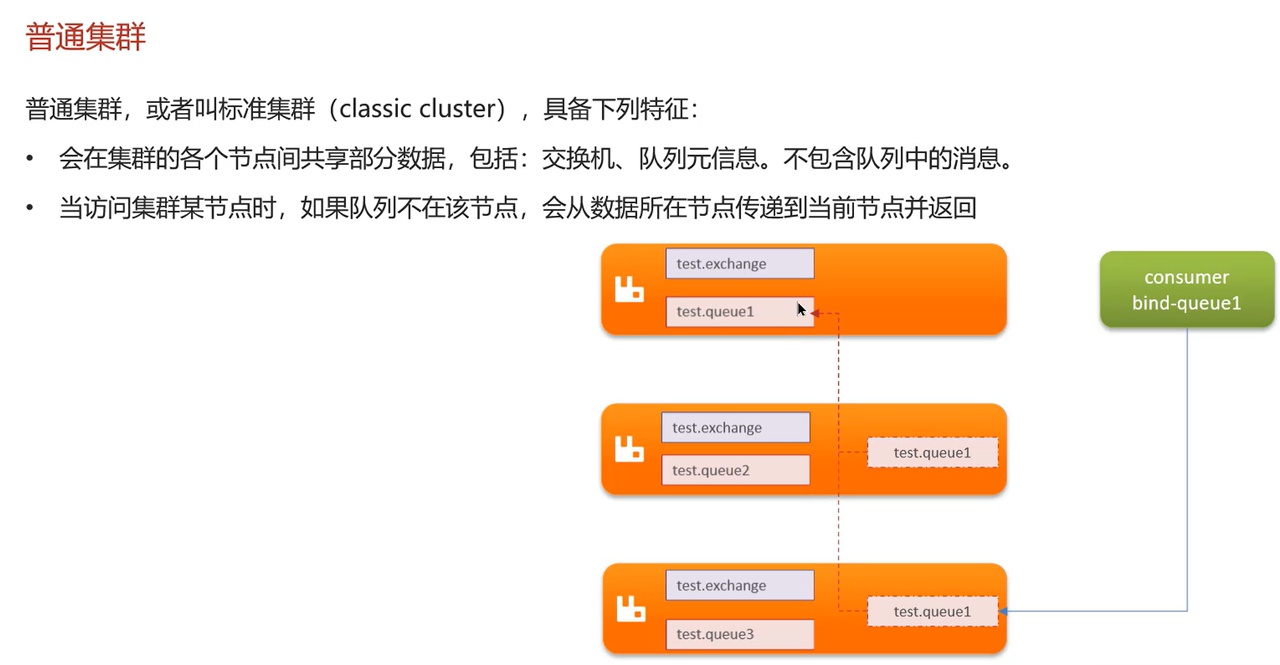
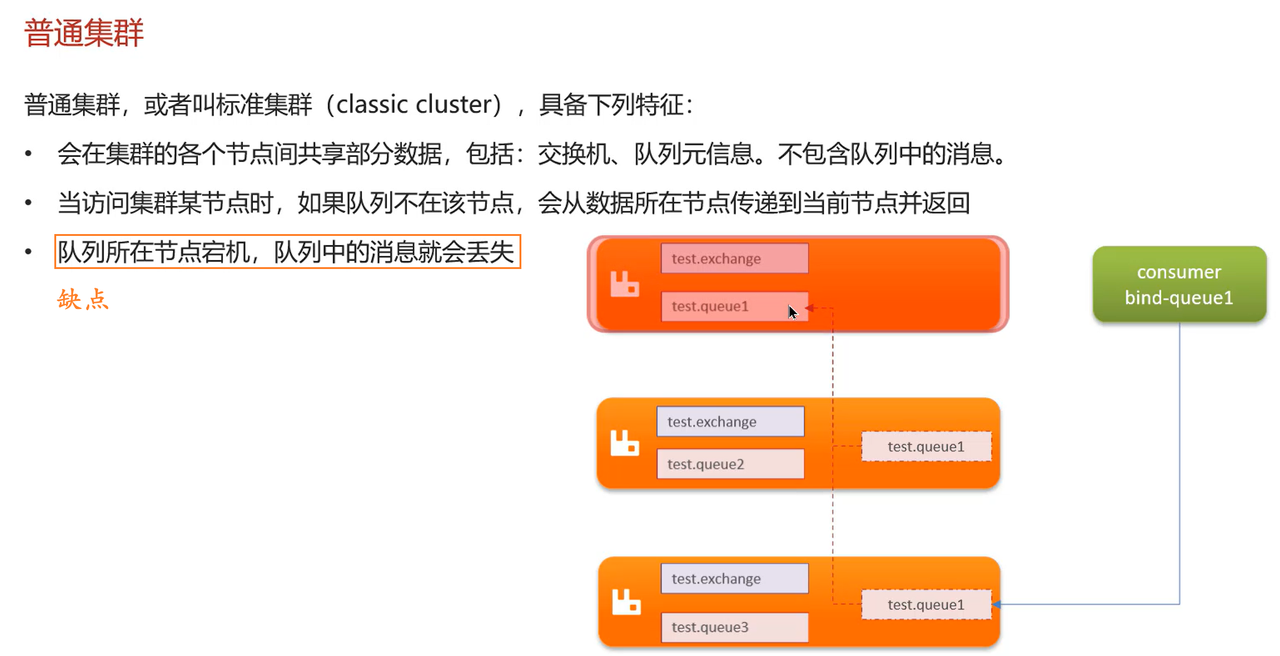
RabbitMQ的高可用机制了解过吗?
在生产环境下,使用集群来保证高可用性,集群分为:普通集群、镜像集群、仲裁队列


讲讲RabbitMQ中的延迟队列
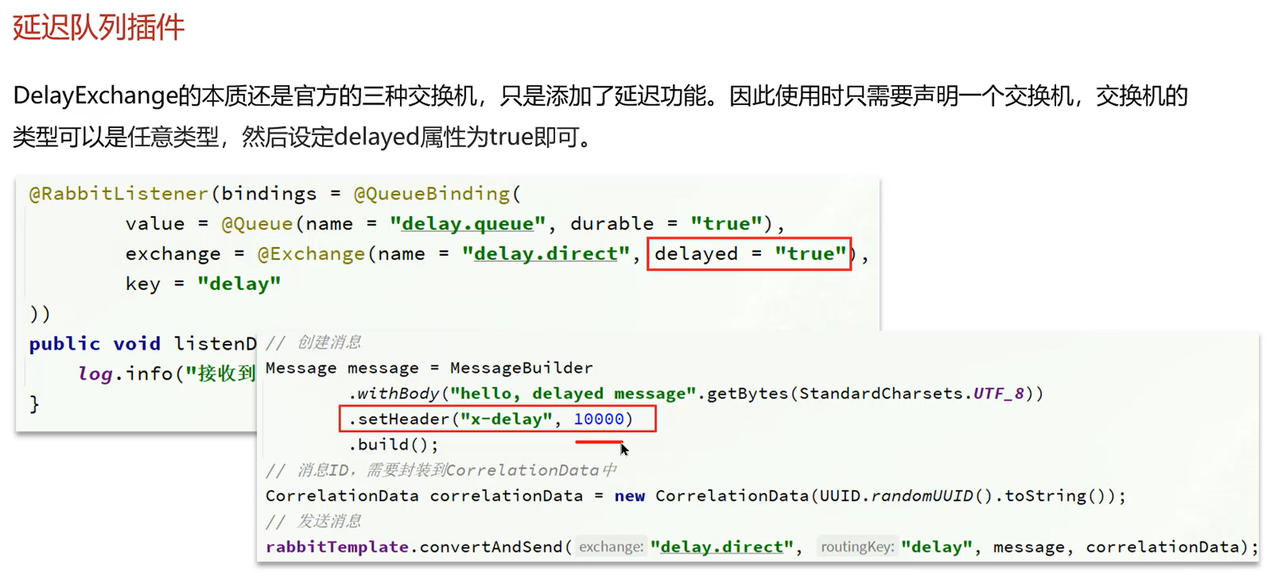
核心作用:让消息不是发送后立即被消费,而是等待指定时间后再交付给消费者。
实际场景:电商订单创建后 30 分钟未支付需自动取消。具体流程:
-
生产者发消息时,给消息设置延迟时间;
-
消息先发送到专门的延迟交换机(通常是
x-delayed-message类型); -
延迟交换机不会立即转发消息,而是暂存消息,直到延迟时间到期;
-
时间到后,延迟交换机将消息转发到业务队列;
-
消费者监听业务队列,到点接收消息并执行 "取消订单" 逻辑。
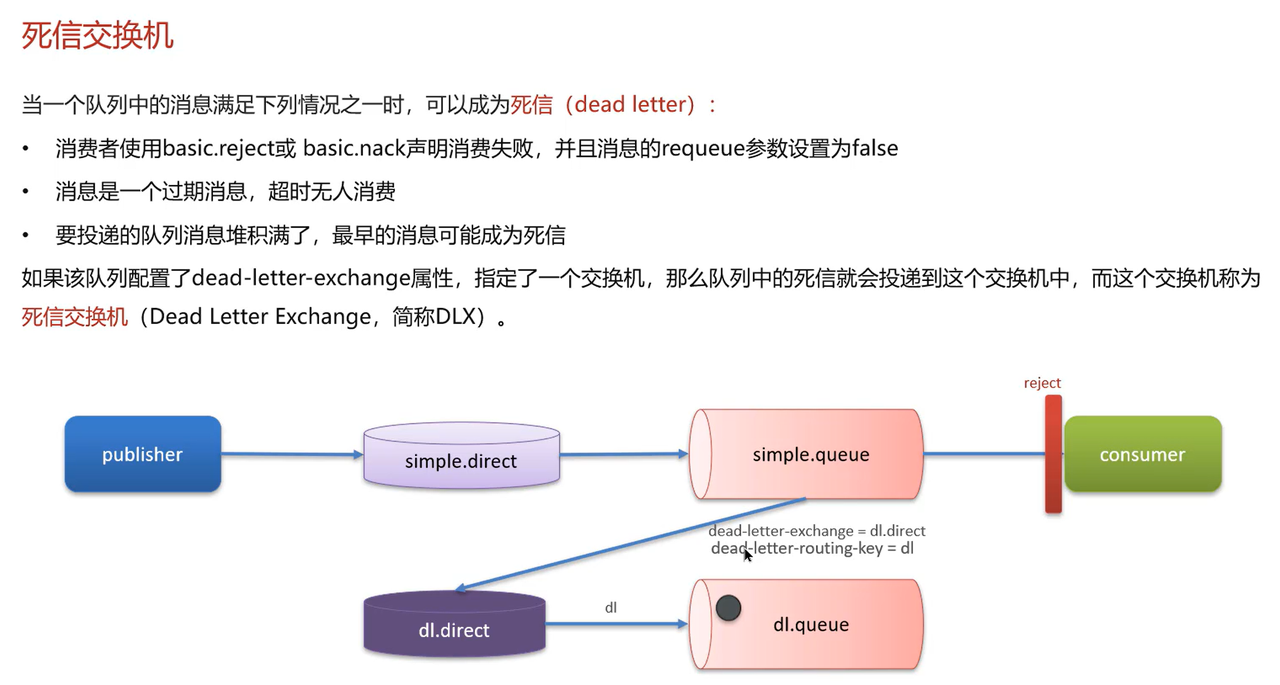
讲一下rabbitMQ 的死信交换机
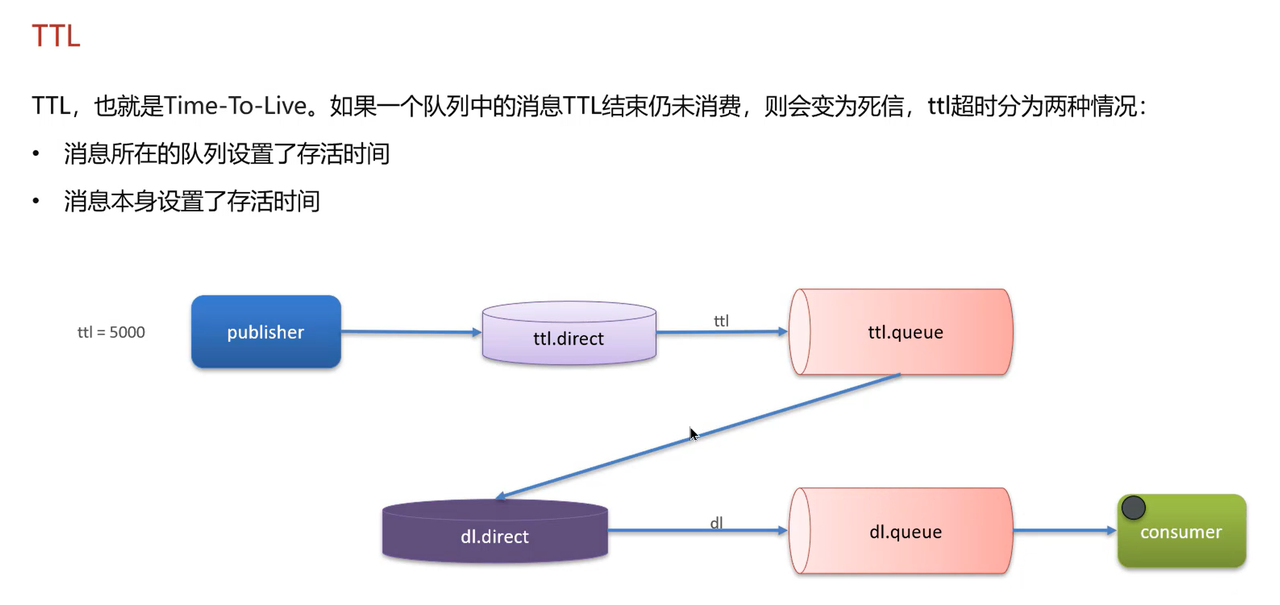
给消息设置TTL,实现延时任务:
-
给订单业务队列配置死信交换机 + 死信队列,同时设置消息 TTL 为 30 分钟;
-
若用户 30 分钟内支付:消费者处理消息后正常确认,消息被删除;
-
若用户未支付:消息在订单队列中过期,触发死信机制,自动转到死信队列;
-
死信队列的消费者处理超时消息,执行取消订单的逻辑。
恭喜你全部掌握RabbitMQ的高频面试题!✿