国产数据库市场已进入多元化竞争与深度整合期,形成了由传统厂商、云巨头和创业公司共同参与的活跃格局。一方面,市场集中度提升,厂商数量从高峰期缩减,头部阵营如华为GaussDB 、阿里云PolarDB 、腾讯TDSQL 以及蚂蚁OceanBase等凭借技术或生态优势占据领先地位。另一方面,达梦、电科金仓、南大通用等厂商则在党政、金融等关键领域拥有深厚的客户积累。整体市场在政策与需求的双重驱动下持续增长。
在技术发展上,国产数据库正从"替代可用"迈向"创新好用",其突破主要体现在三个融合:云原生与分布式架构融合 ,以支持弹性扩展和高可用;与AI技术融合 ,众多厂商布局AI-Native架构,探索智能运维与多模态数据处理;多模数据融合,支持关系、时序、文档、向量等多种数据模型的统一处理,以应对复杂业务场景。此外,兼容主流数据库生态以降低迁移成本,也成为厂商竞争的关键点之一。
从行业应用来看,国产化替代呈现鲜明的"从外围到核心"的路径。党政领域 替代较为深入。金融、电信、能源等重点行业替代加速,但渗透不均衡:金融业的非核心系统替代进展较快,而核心交易系统因对稳定性、一致性要求高,替代更为审慎。
01 多模融合架构:技术实现路径分析
数据库架构演进面临着一个核心矛盾:传统关系型数据库的严格架构与NoSQL数据库的灵活特性之间的协调。企业以往可能维护多套异构系统,面临数据同步与管理复杂性的挑战。
一些国产数据库探索了"多模融合"路径,在同一个数据库内核中同时支持关系表与文档等多种数据模型的存储与管理。这有助于企业在部分场景下简化技术栈。
此类架构通常采用分层设计,例如包含协议兼容层、存储引擎层、计算层等。协议兼容层可实现与特定数据库(如MongoDB)的Wire Protocol兼容;存储引擎层需支持不同数据格式(如JSONB与关系表)的高效存储;计算层则共享或集成查询优化器和执行引擎。
协议兼容的实现,通常涉及协议解析、命令映射和结果封装等步骤,目标是在应用层面实现平滑迁移。例如,应用程序在仅调整连接配置的情况下,可接入兼容版数据库。
技术实践示例:协议兼容层的工作流程
以下伪代码示意了协议兼容层如何处理一个MongoDB find 命令:
python
class MongoDBWireProtocolHandler:
def handle_request(self, raw_request):
# 1. 协议解析
op_code, payload = self._parse_wire_protocol(raw_request)
# 2. 命令映射
if op_code == OP_QUERY:
command = self._extract_query_command(payload)
# 将MongoDB查询映射为内部SQL或查询计划
internal_query = self._translate_to_internal_query(command)
# 3. 执行查询
result_set = self._execute_internal_query(internal_query)
# 4. 结果封装
response = self._format_as_mongodb_reply(result_set)
return response存储引擎层需要高效处理JSON/文档数据。一种实现方式是在关系存储引擎基础上扩展对JSONB列的支持,并优化其存取路径。
sql
-- 示例:在支持文档模型的关系数据库中,创建包含JSON列的表
CREATE TABLE patient_records (
id BIGINT PRIMARY KEY,
basic_info JSONB, -- 存储文档型数据,如患者基本信息
created_at TIMESTAMP
);
-- 在JSON列上创建索引以加速查询
CREATE INDEX idx_patient_basic_info ON patient_records USING GIN (basic_info);02 性能考量:测试方法与结果分析
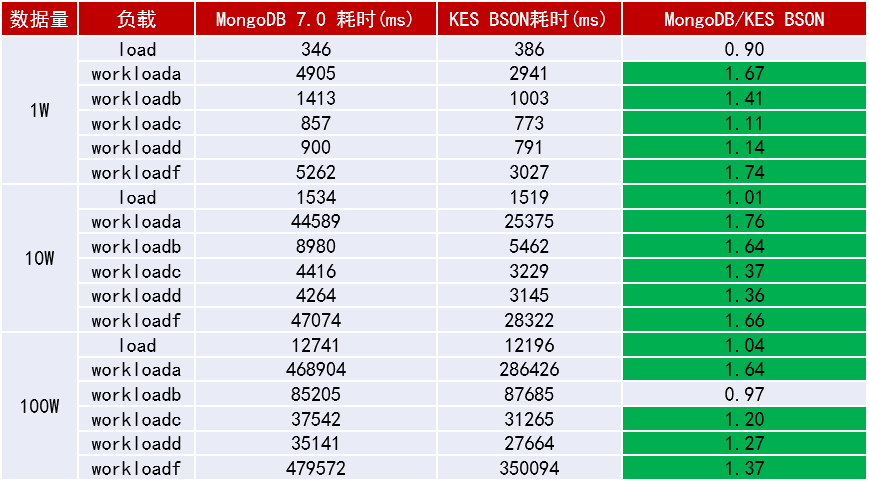
数据库性能评估需基于标准化的测试方法和业务模拟场景。业界常使用YCSB、TPC系列等基准测试工具进行多维度比较。
测试应覆盖多种负载模型,例如:
- A: 更新密集型 - 读写比例约50/50,模拟会话存储
- B: 读密集型 - 读写比例约95/5,模拟内容浏览
- C: 只读型 - 100%读,模拟缓存数据访问
- D: 读-最新 - 读近期插入的记录,模拟新闻推送
- E: 短范围扫描 - 查询小范围记录,模拟线程对话
- F: 读-修改-写 - 读记录、修改并写回,模拟购物车操作
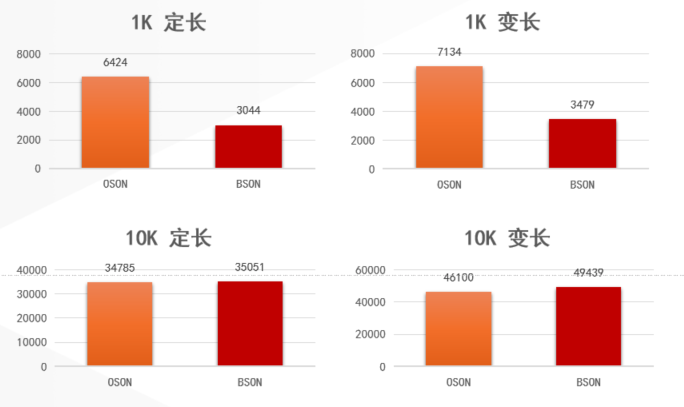
存储格式优化实践
对于文档数据,存储格式直接影响性能。除标准BSON/JSON格式外,一些数据库会研发自有格式以优化存储与计算效率。优化方向包括:
- 存储压缩:减少磁盘占用和I/O。
- 嵌套解析优化:加速对深层嵌套字段的访问。
- 索引友好:使数据布局更利于索引构建与查询。
例如,一个优化存储格式(假设称为OSON)可能采用列式存储思想来组织JSON中的字段,便于聚合查询。
cpp
// 简化的存储格式设计思路(概念性)
struct OptimizedDocument {
Header header; // 元数据,如版本、字段数
FieldDictionary dict; // 字段名字典,用于去重
ColumnData columns[]; // 按列组织的字段值,支持高效扫描
};在查询时,这种格式可能允许直接访问特定字段的列数据,而无需完全解析整个文档。
03 企业级能力:内核技术要点
企业级数据库内核通常需具备以下关键能力:
1. 强事务一致性
支持跨模型(关系与文档)的ACID事务。实现多模型事务时,难点在于统一的并发控制与恢复机制。
sql
-- 示例:跨模型事务操作
BEGIN TRANSACTION;
-- 操作1:更新关系表
UPDATE account SET balance = balance - 100 WHERE id = 123;
-- 操作2:在JSON文档中记录交易日志
UPDATE transaction_log
SET log_entry = jsonb_set(
log_entry,
'{transactions, -1}',
'{"from": 123, "amount": 100, "timestamp": "2024-01-17"}'
)
WHERE account_id = 123;
COMMIT; -- 保证两个操作原子提交2. 高可用架构
常见的高可用方案包括基于共享存储的故障切换(RAC架构)或基于数据复制的集群(主从复制)。目标是最小化RTO(恢复时间目标)和RPO(恢复点目标)。
3. 统一查询优化
为混合负载提供智能优化。优化器需要理解不同数据模型(关系、文档、向量)的查询代价,并生成最优执行计划。
sql
-- 示例:混合查询 - 关联关系表与JSON列
SELECT
o.order_id,
o.customer->>'name' AS customer_name, -- 从JSON文档提取字段
p.product_name,
SUM(oi.quantity) as total_quantity
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.order_date > '2024-01-01'
AND o.customer->>'region' = 'East' -- JSON路径查询
GROUP BY o.order_id, customer_name, p.product_name;4. 统一索引框架
支持跨数据模型的索引类型,并允许复合索引(例如,同时索引关系字段和JSON中的字段)。
sql
-- 在JSON列和关系列上创建复合索引
CREATE INDEX idx_customer_region_date
ON orders ((customer->>'region'), order_date);04 实践案例:迁移与优化
案例背景:电子证照共享服务系统迁移
原系统基于MongoDB,存储超过2TB证照数据,面临高并发查询压力。
迁移过程的关键步骤:
-
兼容性评估与测试
- 使用工具扫描应用代码,识别所有MongoDB API调用。
- 在测试环境验证兼容性,重点测试聚合管道、索引行为、事务等。
-
数据迁移
- 采用并行导出/导入工具,分批次迁移数据。
- 迁移过程中使用Change Data Capture (CDC) 同步增量数据,减少停机时间。
bash
# 简化的迁移步骤示例
# 1. 全量导出
mongodump --uri="mongodb://source_host:27017" --out=/data/backup
# 2. 转换数据格式(如需)
python convert_to_sql.py /data/backup /data/sql_ready
# 3. 导入目标数据库
psql -h target_host -U admin -d cert_db -f /data/sql_ready/schema.sql
psql -h target_host -U admin -d cert_db -f /data/sql_ready/data.sql
# 4. 增量同步(使用CDC工具)
# 配置CDC连接源和目标,持续同步变更- 性能调优实践
-
查询重写:将复杂的嵌套查询拆分为多个简单查询,利用数据库的优化能力。
原MongoDB聚合管道可能非常复杂:
javascriptdb.orders.aggregate([ {$match: {status: "active"}}, {$unwind: "$items"}, {$group: {_id: "$items.category", total: {$sum: "$items.price"}}}, {$sort: {total: -1}} ])迁移后,可能重写为SQL并结合临时表,或利用数据库的JSON函数与窗口函数优化。
-
索引优化:分析查询模式,创建复合索引和覆盖索引。
-
连接池配置:调整连接池参数以应对高并发。
-
优化效果示例:
- 复杂证照查询响应时间从平均5秒降低至0.3秒。
- 通过读写分离集群,并发支持能力从原有约1000连接提升至5000+连接。
- 统一管理后,运维复杂度显著降低。
05 技术演进趋势
国产数据库的技术发展呈现出以下趋势:
1. 云原生与分布式深化
数据库服务全面转向云原生架构,实现存储计算分离、弹性扩缩容、多租户隔离等。Serverless 数据库模式开始兴起,进一步降低使用门槛。
2. AI for DB 与 DB for AI 双向融合
- AI for DB:利用机器学习优化数据库内核,如智能索引推荐、异常检测、自调优参数。
- DB for AI:数据库原生支持向量计算,作为AI应用的数据底座,简化AI数据流水线。
sql
-- 未来可能出现的AI增强查询示例
SELECT
product_id,
product_description,
-- 使用内置的向量相似度函数,寻找相似商品
vector_similarity(
product_embedding,
query_embedding('用户自然语言描述')
) as similarity
FROM products
ORDER BY similarity DESC
LIMIT 10;3. 多模融合成为标配
未来的数据库可能不再区分"关系型"或"NoSQL",而是原生支持多种数据模型与API,根据负载自动选择最佳存储与计算策略。
4. 开源与生态建设
通过开源或开放核心(Open Core)模式构建开发者生态,形成围绕数据库的技术社区,推动标准 adoption 和人才培养。
5. 安全与合规增强
集成数据脱敏、加密、审计、行级安全等能力,满足日益严格的数据安全法规要求。
总结
国产数据库经过多年发展,已在技术能力、产品成熟度和行业应用方面取得显著进展。从最初的跟随替代,到如今在分布式、云原生、多模融合等方向进行创新尝试,正逐步形成自身的技术特色。
对于技术决策者和开发者而言,在选择数据库时,需综合评估业务场景、数据模型复杂度、性能要求、迁移成本及长期运维等因素。多模融合数据库为简化技术栈提供了新选择,但其实际效果取决于具体实现和业务匹配度。
未来,随着AI、物联网等新场景的驱动,数据库技术将持续演进,而开源、开放、智能、融合将成为关键发展方向。