1、模块介绍
1.1 论文信息
- 论文标题: Coordinate Attention for Efficient Mobile Network Design
- 中文标题: 针对高效移动网络设计的坐标注意力机制
- 论文链接 : https://arxiv.org/pdf/2103.02907
- 论文代码 : https://github.com/Andrew-Qibin/CoordAttention
- 核心创新点模块:坐标注意力(Coordinate Attention,简称 CA)
- 论文出处: CVPR 2021
1.2 论文概述
近期关于移动网络设计的研究已经证明了通道注意力(例如 Squeeze-and-Excitation 注意力)对于提升模型性能的显著有效性,但它们通常忽略了位置信息,而位置信息对于生成具有空间选择性的注意力图非常重要 。在本文中,我们通过将位置信息嵌入通道注意力,提出了一种适用于移动网络的新型注意力机制,我们称之为"坐标注意力" 。与通过 2D 全局池化将特征张量转换为单个特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个 1D 特征编码过程,分别沿两个空间方向聚合特征 。通过这种方式,可以沿一个空间方向捕捉长程依赖关系,同时在另一个空间方向保留精确的位置信息 。生成的特征图随后被分别编码成一对方向感知且位置敏感的注意力图,这对图可以互补地应用于输入特征图,以增强感兴趣对象的表示 。我们的坐标注意力非常简单,可以灵活地插入传统的移动网络中,如 MobileNetV2、MobileNeXt 和 EfficientNet,且几乎不产生计算开销 。广泛的实验表明,我们的坐标注意力不仅有利于 ImageNet 分类,更具吸引力的是,它在物体检测和语义分割等下游任务中表现更好 。
1.3 实验动机
-
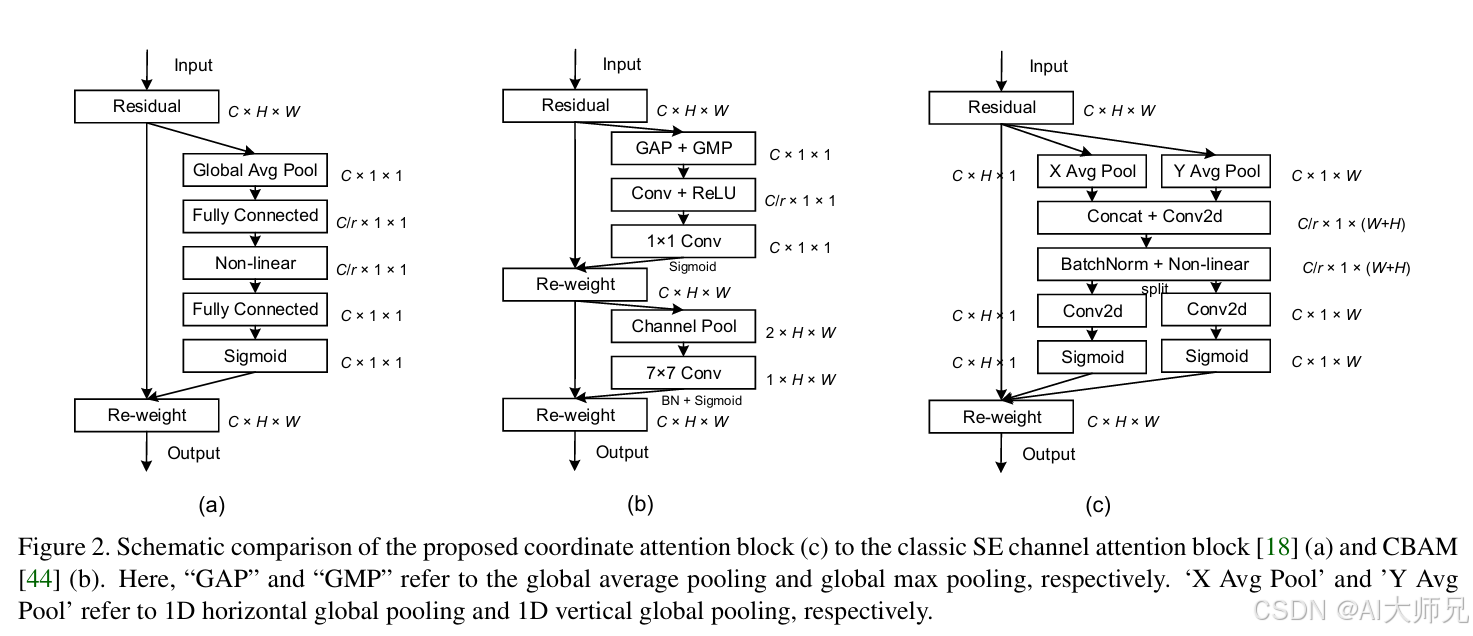
通道注意力的局限性: 像 SE 注意力这样流行的机制主要关注编码通道间的相互依赖关系,却忽略了位置信息,而位置信息对于在视觉任务中捕获物体结构至关重要 。
-
空间注意力的瓶颈: 虽然 BAM 和 CBAM 尝试引入空间信息,但它们通常使用卷积来捕获局部关系,无法建模在视觉任务中极其关键的长程依赖关系 。
-
移动端算力限制: 尽管非局部(Non-local)或自注意力网络在建模长程依赖方面非常流行,但其巨大的计算量使得它们难以应用于计算能力受限的移动网络 。
1.4 创新之处
- 维度分解策略: 将传统的 2D 全局池化分解为两个并行的 1D 特征编码过程,分别沿垂直和水平方向聚合信息 。
- 方向感知与位置敏感: 生成的注意力图不仅能捕捉跨通道信息,还能精确感知物体在空间上的坐标位置 。
- 长程依赖建模: 通过这种 1D 编码方式,移动网络能够以极低的计算开销覆盖大范围的感受野 。
- 极高的灵活性: 作为一种轻量级模块,它可以无缝集成到 MobileNetV2 的倒置残差块或 MobileNeXt 的沙漏块等经典结构中 。
1.5 创新模块介绍
坐标注意力块主要包含两个步骤:坐标信息嵌入(Coordinate Information Embedding)和坐标注意力生成(Coordinate Attention Generation) 。
- 坐标信息嵌入
为了捕获精确位置信息的长程交互,模块使用两个一维池化算子分别沿水平和垂直坐标编码每个通道。对于第 c c c 个通道,在高度 h h h 处和宽度 w w w 处的输出分别为: z c h ( h ) = 1 W ∑ 0 ≤ i < W x c ( h , i ) z_{c}^{h}(h)=\frac{1}{W}\sum_{0\le i<W}x_{c}(h,i) zch(h)=W10≤i<W∑xc(h,i) z c w ( w ) = 1 H ∑ 0 ≤ j < H x c ( j , w ) z_{c}^{w}(w)=\frac{1}{H}\sum_{0\le j<H}x_{c}(j,w) zcw(w)=H10≤j<H∑xc(j,w).
- 坐标注意力生成
将上述聚合后的特征图拼接并进行 1 × 1 1 \times 1 1×1 卷积变换: f = δ ( F 1 ( z h , z w ) ) f=\delta(F_{1}(z\^{h},z\^{w})) f=δ(F1(zh,zw))其中 f ∈ R C / r × ( H + W ) f \in \mathbb{R}^{C/r \times (H+W)} f∈RC/r×(H+W) 是编码了双向空间信息的中间特征图。随后将 f f f 沿空间维度切分为两个张量 f h f^h fh 和 f w f^w fw,再通过两个 1 × 1 1 \times 1 1×1 卷积分别恢复通道数并利用 Sigmoid 激活得到权重 g h g^h gh 和 g w g^w gw。最终输出 Y Y Y 为: y c ( i , j ) = x c ( i , j ) × g c h ( i ) × g c w ( j ) y_{c}(i,j)=x_{c}(i,j)\times g_{c}^{h}(i)\times g_{c}^{w}(j) yc(i,j)=xc(i,j)×gch(i)×gcw(j)
1.6 模块适用领域
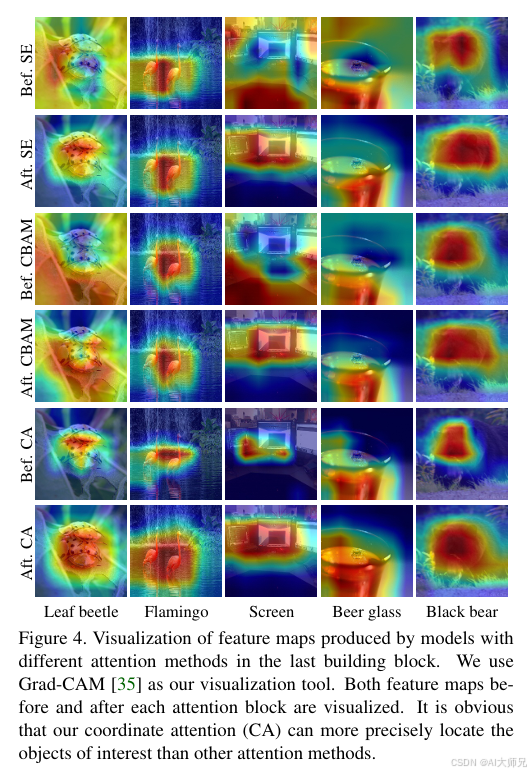
- 基础分类任务: 在 ImageNet 分类中,相比于 SE 注意力和 CBAM,能提供更高的 Top-1 准确率 。
- 密集预测任务: 在语义分割(如 Pascal VOC 2012、Cityscapes)和物体检测(如 COCO)中展现出比分类任务更显著的提升,因为它能捕获精准的位置信息
- 移动端架构优化: 特别适用于 MobileNetV2、MobileNeXt 和 EfficientNet 等对参数量和计算量有严格要求的轻量级模型 。
- 长程依赖场景: 适用于需要跨大范围区域定位物体的视觉任务 。
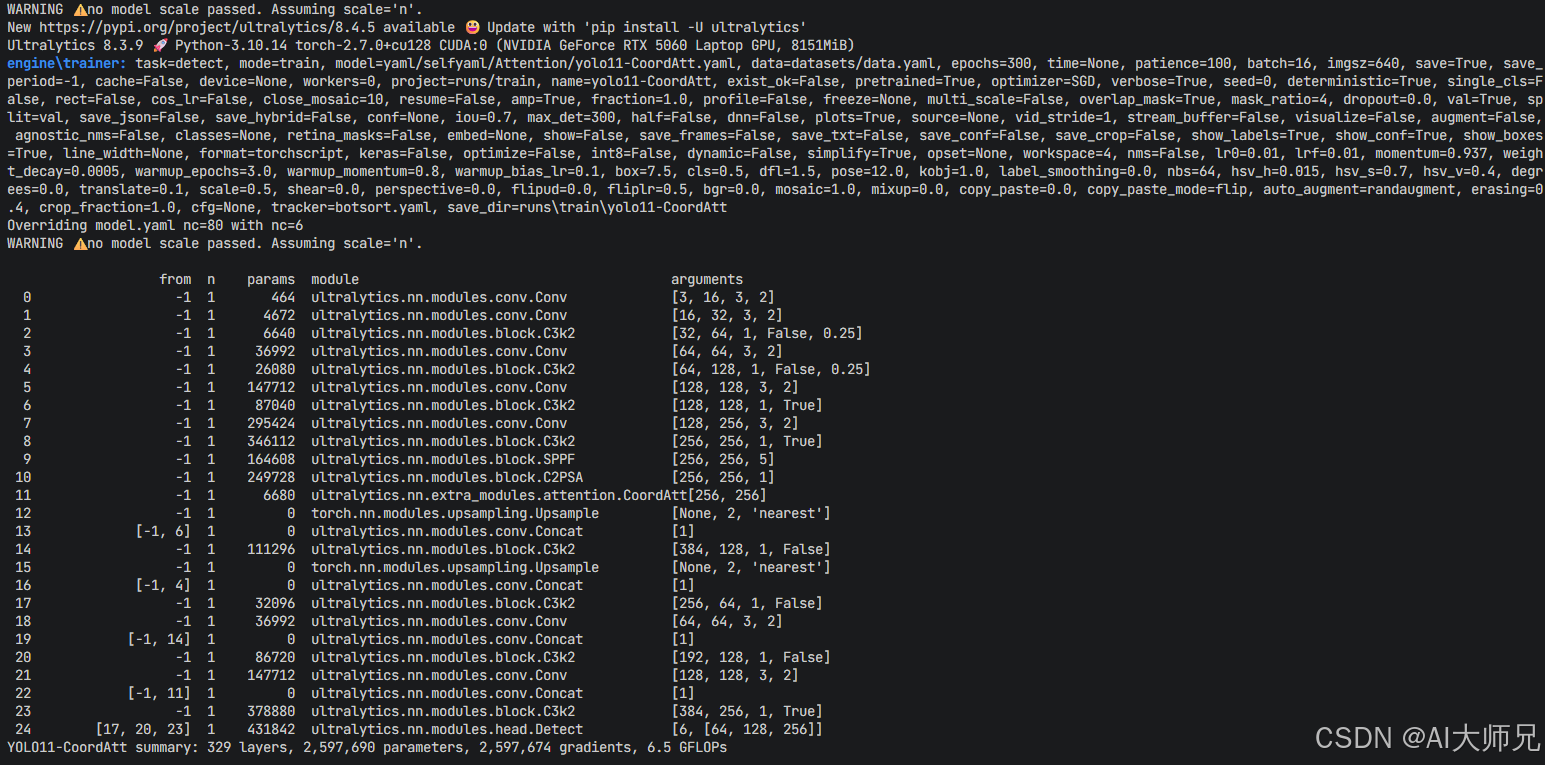
2、加入到YOLOv11中
2.1 打开项目里的ultralytics/nn/extra_modules/attention.py
加入如下代码:
py
###################### CoordAtt #### START by AI大师兄 ###############################
import torch
import torch.nn as nn
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
###################### CoordAtt #### END by AI大师兄 ###############################2.2 修改ultralytics/nn/tasks.py
1)首先进行引用定义
from ultralytics.nn.extra_modules.attention import * #默认已经定义
2)修改解析函数def parse_model(d, ch, verbose=True):
位置大概在1000多行左右。
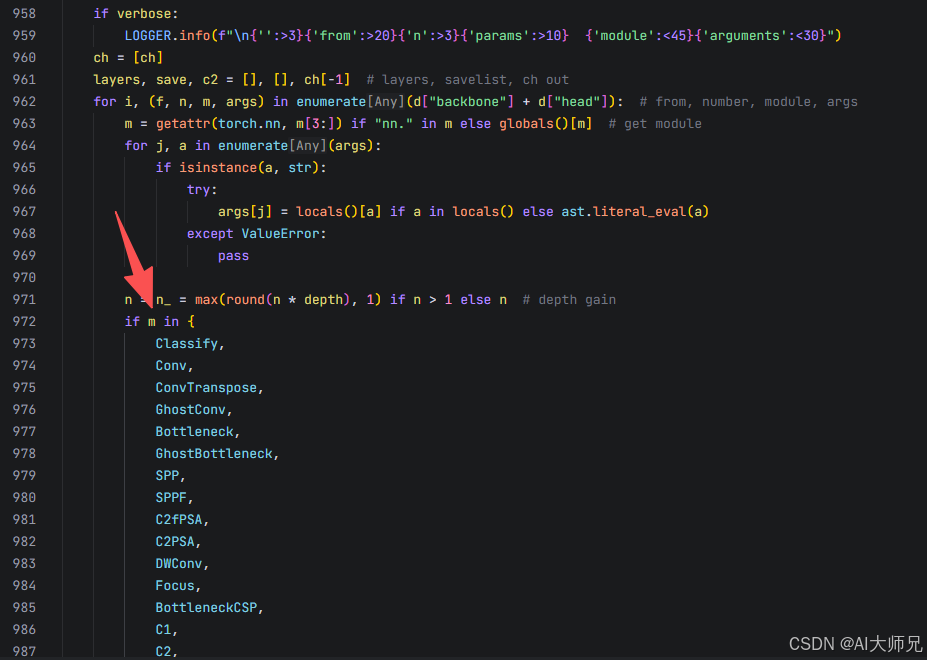
在最后或者最前面追加该模块名称即可。
py
n = n_ = max(round(n * depth), 1) if n > 1 else n # 直接搜索这一行Ctrl+F
if m in {
CoordAtt, # self 在最前面追加或者最后都可以
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
C2fPSA,
C2PSA,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C3k2,
RepNCSPELAN4,
ELAN1,
ADown,
AConv,
SPPELAN,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
PSA,
SCDown,
C2fCIB
}:2.3 yaml配置
yolo11-CoordAtt.yaml
py
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, CoordAtt, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)一共有3种可选的注意力添加方式(其中Attention可以统一更换成任意的注意力机制):
py
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
######################################## 方式一 ##################################################
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, Attention, [1024]] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 14
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
######################################## 方式二 ##################################################
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [16, 1, Attention, [256]] # 23
- [19, 1, Attention, [512]] # 24
- [22, 1, Attention, [1024]] # 25
- [[23, 24, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
######################################## 方式三 ##################################################
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Attention, [256]] # 17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, Attention, [512]] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, Attention, [1024]] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)3、运行train.py测试