note
一、文档智能
【文档智能进展】讲的故事是格式化文本(公式、表格等)比纯文本熵值高一个数量级,导致模型输出不确定性大、解析准确率低,所以搞了个应对思路。工作在:Reading or Reasoning? Format Decoupled Reinforcement Learning for Document OCR,https://arxiv.org/pdf/2601.08834,
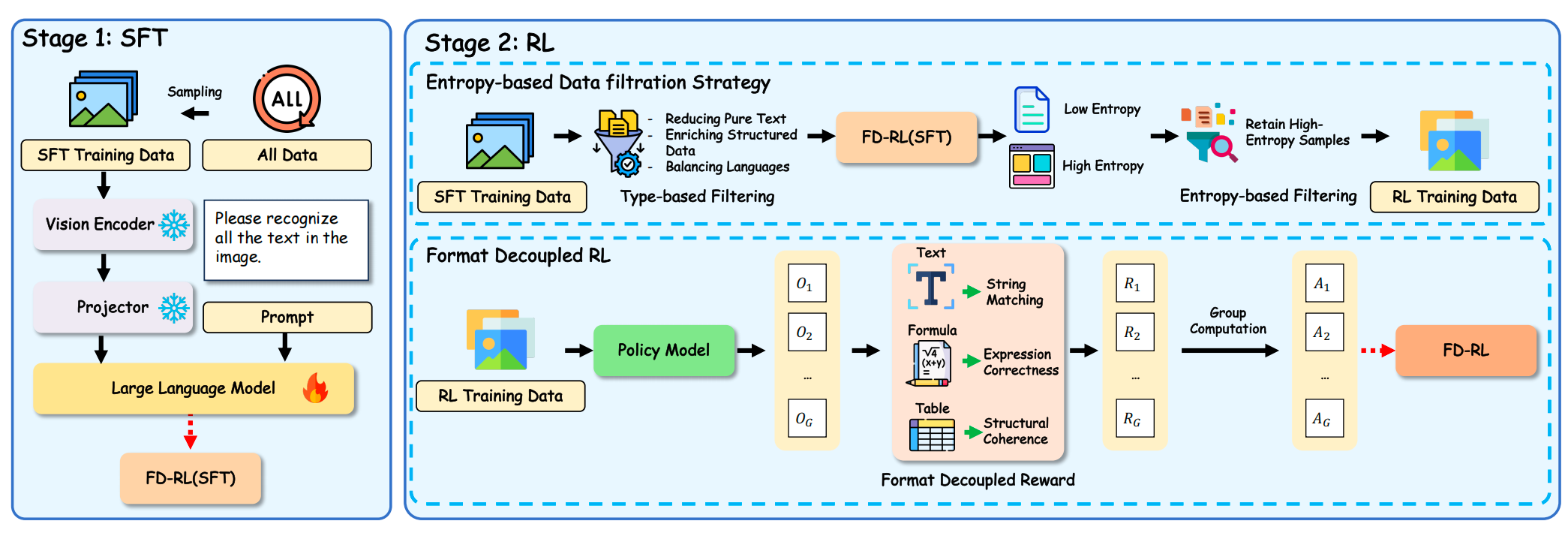
看核心思路:
1)数据层面:构建包含566k样本的多源格式丰富语料,覆盖9类文档,补充格式密集型数据;
2)训练层面:基于Qwen3-VL-4B,采用SFT-then-RL两阶段范式,SFT奠定OCR基础,RL聚焦格式优化;
3)策略层面:通过熵基数据过滤筛选50%高熵样本,集中优化复杂格式【用SFT模型推理计算样本平均token熵,筛选熵值≥阈值的样本(最优过滤率50%),比无过滤高,过低或过高过滤均会降低性能】;
4)奖励层面:设计格式解耦奖励,为纯文本、公式、表格分别提供字符串匹配、表达式正确性、结构一致性奖励【纯文本,字符串匹配奖励,使用归一化编辑距离;公式,表达式正确性奖励,使用BLEU分数;表格,结构一致性奖励,使用TEDS分数,结论是完整奖励方案(FP+SM+EC+SC)比单一字符串匹配奖励高,其中结构一致性奖励(针对表格)和表达式正确性奖励(针对公式)对格式优化至关重要】,采用GRPO算法。
Reference
1 Reading or Reasoning? Format Decoupled Reinforcement Learning for Document OCR