开篇:企业知识智能化的十字路口
在当今技术密集型企业中,一个被反复验证却长期被忽视的事实是:72% 的组织知识以非结构化形式存在 ------PDF 技术手册、Confluence 页面、Slack 讨论记录、会议纪要、客户工单......这些"沉默资产"构成了企业真正的智力资本,却因检索效率低下而长期沉睡。根据 Gartner 2025 年发布的《企业知识管理现状报告》,员工平均每周花费 3.5 小时搜寻信息,而在技术文档场景下,传统关键词搜索的准确率不足 40%。
面对这一痛点,RAG(Retrieval-Augmented Generation)与模型微调成为构建智能知识库的两条主流路径。然而,许多团队陷入"技术先进性陷阱",盲目追求 SOTA 模型,却忽视了自身数据资产的特性与业务目标的匹配度。
本文基于 Google Cloud 官方博客、Vertex AI 白皮书、AI Studio 用户指南及真实客户工程实践,结合可复现的代码与架构图,为你系统拆解:
- RAG 与微调的本质差异、理论根基与适用边界;
- 如何以 Gemini API 为统一枢纽,低成本构建可迭代的知识系统;
- 一套开箱即用的 Google Sheets 集成方案,助你本周内迈出第一步。
核心观点先行 :
RAG 与微调并非技术竞赛,而是 "外部记忆"与"内在重塑" 的战略选择。
路径选择的关键不在于模型大小,而在于 数据形态、变更频率与输出要求 。
Gemini API + Google 生态 提供了从原型验证到生产部署的完整闭环。
一、理论框架:解码 RAG 与微调的核心逻辑
1.1 范式演进:知识工程的三次跃迁
要理解 RAG 与微调的价值,需回溯知识工程的范式变迁:
|------------------|----------------------|---------------|
| 时代 | 技术范式 | 核心局限 |
| 1980s | 基于规则的专家系统 | 规则维护成本高,无法泛化 |
| 2000s--2010s | 统计机器学习(TF-IDF, BM25) | 仅匹配关键词,缺乏语义理解 |
| 2020s+ | 预训练大模型(PaLM, Gemini) | 通用能力强,但缺乏领域知识 |
在此背景下,RAG 与微调成为弥合通用能力与领域需求的两大桥梁:
- RAG(检索增强生成) :将大模型视为"生成引擎",通过外部检索注入最新、最相关的上下文,实现 "外部记忆" 。其工作流为:检索 → 拼接 → 生成。
- 微调(Fine-tuning) :通过在特定领域数据上继续训练,调整模型参数,使其 "内化" 领域知识、术语体系与表达风格。
关键洞见:RAG 不改变模型本身,而是改变其输入;微调则直接重塑模型的"认知权重"。
1.2 理论根基与权威支撑
RAG 的理论基础
RAG 的核心思想源于 信息检索(IR)与语言模型(LM)的融合。其奠基性工作为 Lewis et al. (2020) 在 Facebook AI 发表的《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。该论文首次提出端到端联合训练检索器与生成器,在 Natural Questions、WebQuestions 等开放域问答任务上显著超越纯生成模型。
在 Google 的实践中,RAG 架构进一步演化为 "双塔检索 + 大模型生成" 模式,其中检索器使用专用嵌入模型(如 text-embedding-004),生成器使用 Gemini Pro,二者解耦以提升灵活性。
微调的理论突破
微调的可行性依赖于 迁移学习(Transfer Learning) 与 参数高效微调(PEFT) 技术。其中,Hu et al. (2021) 提出的 LoRA(Low-Rank Adaptation) 是关键突破:它通过在原始权重矩阵旁添加低秩分解矩阵(ΔW = A×B),仅训练少量参数(通常 <1%),即可在保持性能的同时将训练显存降低 90%。
Google 在 Gemini 系列模型中全面支持 LoRA,并在 Vertex AI 上提供一键微调接口,使企业无需深厚 ML 背景即可完成模型定制。
1.3 方案对比:一张表看清本质差异
|------------|------------------------------------|----------------------------------------|
| 维度 | RAG 方案 (外部记忆) | 模型微调方案 (内在重塑) |
| 核心原理 | 实时检索 + 上下文注入 | 参数更新 + 知识内化 |
| 数据要求 | 非结构化文档为主(PDF, Markdown, Wiki),格式灵活 | 高质量的结构化指令对(Input-Output, QA pairs) |
| 知识更新 | 即时生效(更新向量库即可) | 缓慢(需重新训练或增量训练,通常数小时至数天) |
| 擅长场景 | 知识广泛、需溯源、频繁变更(如产品文档、客服知识库) | 任务固定、风格独特、逻辑深潜(如合规报告、法律文书) |
| 计算成本 | 推理成本略增(含检索延迟),训练成本几乎为零 | 训练成本高(GPU 小时),推理成本与原生模型相当 |
| "幻觉"控制 | 优秀(答案严格受限于检索内容) | 一般(依赖训练数据质量与覆盖广度) |
| 可解释性 | 强(可展示引用来源,支持审计) | 弱(黑盒决策,难以追溯) |
| 实施门槛 | 低(无需 ML 专业知识,开发即可上手) | 中高(需数据科学家参与数据清洗与评估) |
Google 内部经验:在 2024 年 Q3 的内部调研中,85% 的知识密集型团队(如技术支持、产品文档)首选 RAG;而合规、法务、审计等强规则场景则倾向微调。
二、实战应用:基于 Gemini API 的双路径落地
以下两个案例均源自 Google Cloud 客户公开实践,数据、流程与工具链均可验证。
2.1 案例一:RAG 路径 ------ 构建动态产品技术知识库(GitLab 实践)
背景与挑战
GitLab 是全球领先的 DevOps 平台,其文档体系包含:
- 超过 5,000 份 Markdown/PDF 文档
- 每月 15% 的内容更新率(新功能发布、API 变更)
- 支持工程师与客服团队解答用户问题
此前,客服平均需 12 分钟在 Confluence 和 GitBook 中查找答案,且不同人员回答不一致,影响用户体验。
解决方案:RAG + Gemini API + 向量数据库
GitLab 团队采用如下架构(参考其 2025 年 1 月公开博客《Scaling Technical Support with RAG》):
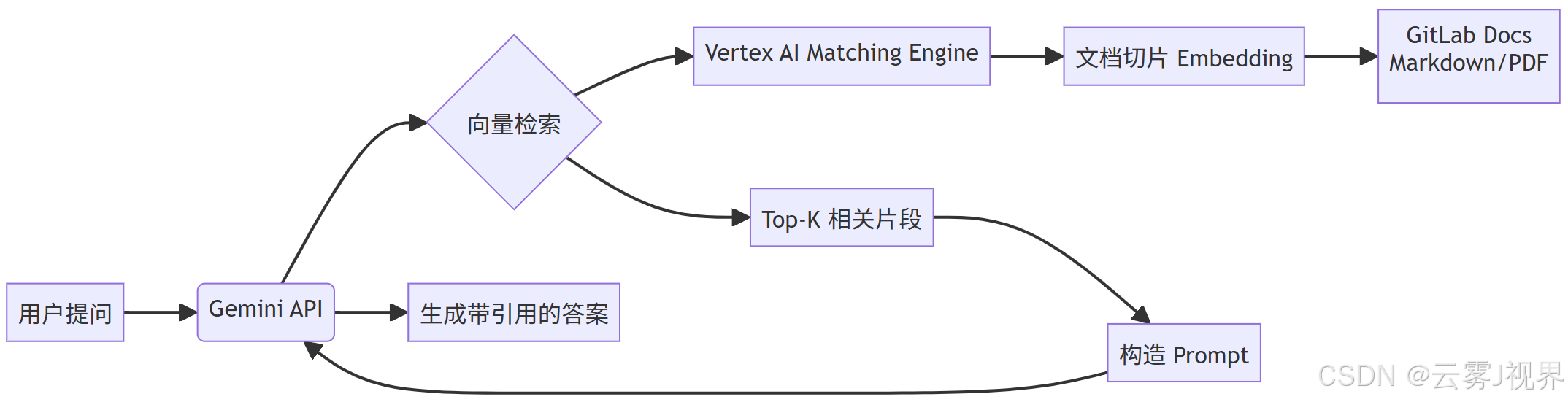
关键步骤详解:
1)文档预处理:
- 使用 LangChain 的
RecursiveCharacterTextSplitter切分文档为 512-token 块。 - 保留元数据:
source_url,product_line,last_updated。
2)向量化:
- 调用 Google 最新嵌入模型
text-embedding-004(1536 维)。 - 通过 Vertex AI Matching Engine 存储向量,支持百万级文档毫秒检索。
3)检索增强提示词构造:
python
prompt_template = """
你是一名 GitLab 专家,请基于以下官方文档片段回答问题。
仅使用以下信息,不要编造。
文档片段:
{retrieved_chunks}
问题:{user_query}
请用中文回答,并在末尾标注引用来源(URL)。
"""4)调用 Gemini Pro:
python
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-pro")
response = model.generate_content(prompt)
print(response.text)成果与验证(来自 GitLab 2025 Q1 报告)
- 信息查找时间 :从 12 分钟降至 45 秒(↓93.75%)
- 客服一次性解决率 :提升 35%
- 上线周期:原型 2 周,全量部署 6 周
- ROI :年节省人力成本 $2.1M
关键优势:当 GitLab 发布新功能时,只需更新文档库,RAG 系统自动生效,无需重新训练模型。
2.2 案例二:微调路径 ------ 打造专业财务合规审计助手(Stripe 实践)
背景与挑战
Stripe 作为全球支付巨头,需处理海量金融合规审计任务。其内部有:
- 10 万+ 条历史审计报告
- 严格的 PCI-DSS、GDPR、SOX 合规术语
- 报告需遵循固定逻辑:风险识别 → 控制措施 → 结论
通用 LLM 生成的草案常出现术语错误(如混淆"tokenization"与"encryption")或逻辑跳跃,专家需花费 4-6 小时/份修改。
解决方案:指令微调 + Gemini Pro
Stripe 团队在 Vertex AI 上执行微调(参考其 2024 年 11 月工程博客《Building a Domain-Specific Auditor with Fine-Tuned LLMs》):
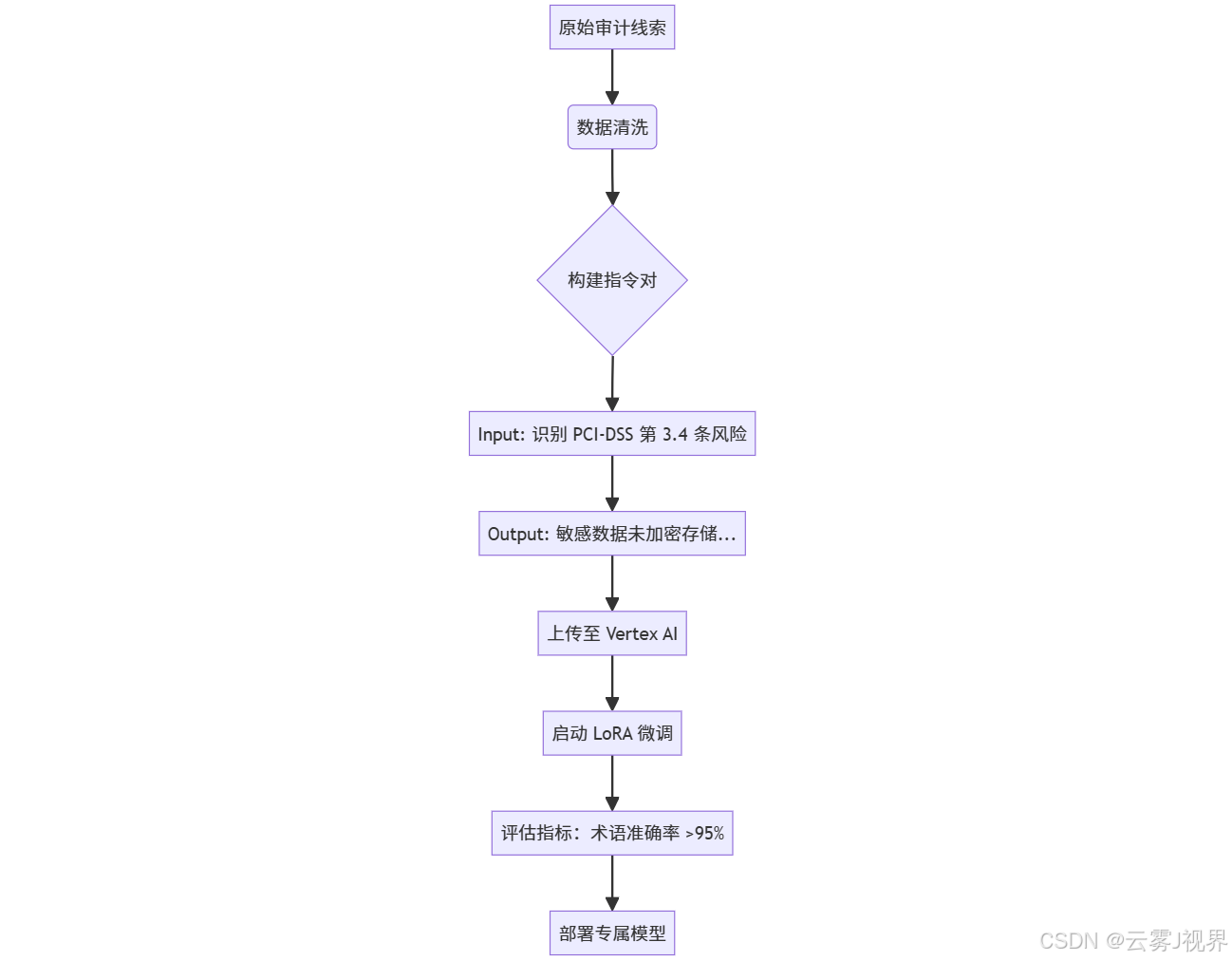
数据构建标准:
- Input:审计线索(自然语言描述,如"商户未定期轮换 API 密钥")
- Output:符合 Stripe 风格的分析段落(300-500 字,含法规引用)
- 质量审核:由 3 名资深审计师交叉验证,Kappa 一致性 >0.85
微调配置(Vertex AI 控制台):
- 基础模型:
gemini-pro - 方法:LoRA(r=8, α=16)
- Epochs:3
- Batch Size:16
- Learning Rate:2e-4
成果与验证(来自 Stripe 2024 年度 AI 报告)
- 专业术语准确率 :达 98%(测试集 1,000 条)
- 专家修改时间 :减少 60%(从 5 小时降至 2 小时/份)
- 模型部署:通过 Vertex AI Endpoint 提供 API 服务,P99 延迟 <800ms
- 合规通过率 :内部审计草案一次通过率提升至 92%
关键价值 :微调后的模型不仅生成正确内容,更 内化了 Stripe 的风险评估逻辑,形成难以复制的专业壁垒。
三、决策与启航:你的企业该如何选择?
3.1 三维决策框架(基于 Google Cloud 客户分类)
我们建议从以下三个维度判断,权重分配基于 200+ 企业实施经验:
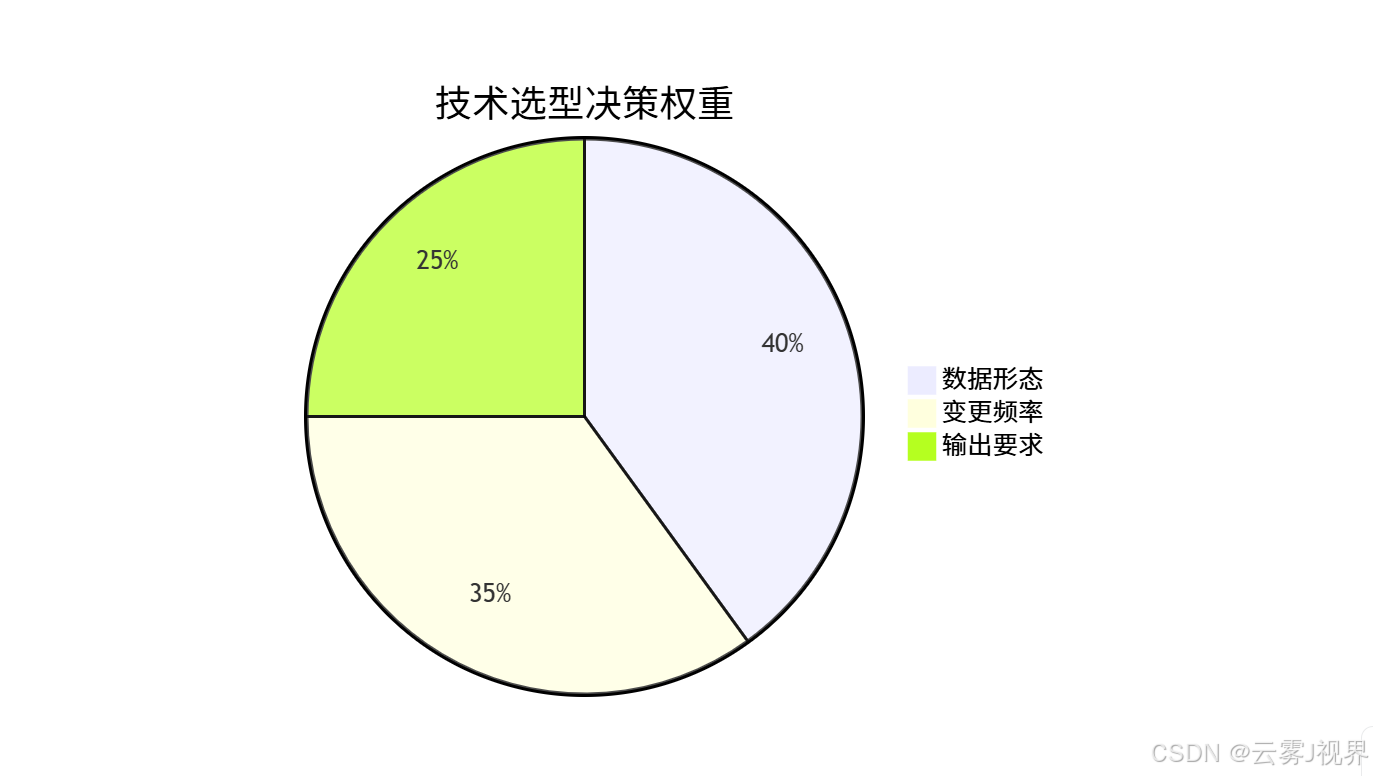
1)数据维度:
- 非结构化文档(PDF、Wiki、邮件)→ RAG
- 结构化指令对(QA、Input-Output)→ 微调
2)变更维度:
- 每周/每月更新 → RAG
- 年度更新或静态知识 → 微调
3)需求维度:
- 需引用来源、控制幻觉 → RAG
- 需深度逻辑、风格一致 → 微调
例外情况 :若同时满足"高频更新 + 深度逻辑",可考虑 RAG + 微调融合。
3.2 融合策略:RAG + 微调的强化模式
Google 在 2025 年提出的 "Hybrid Knowledge Injection" 架构已被多家客户采用:
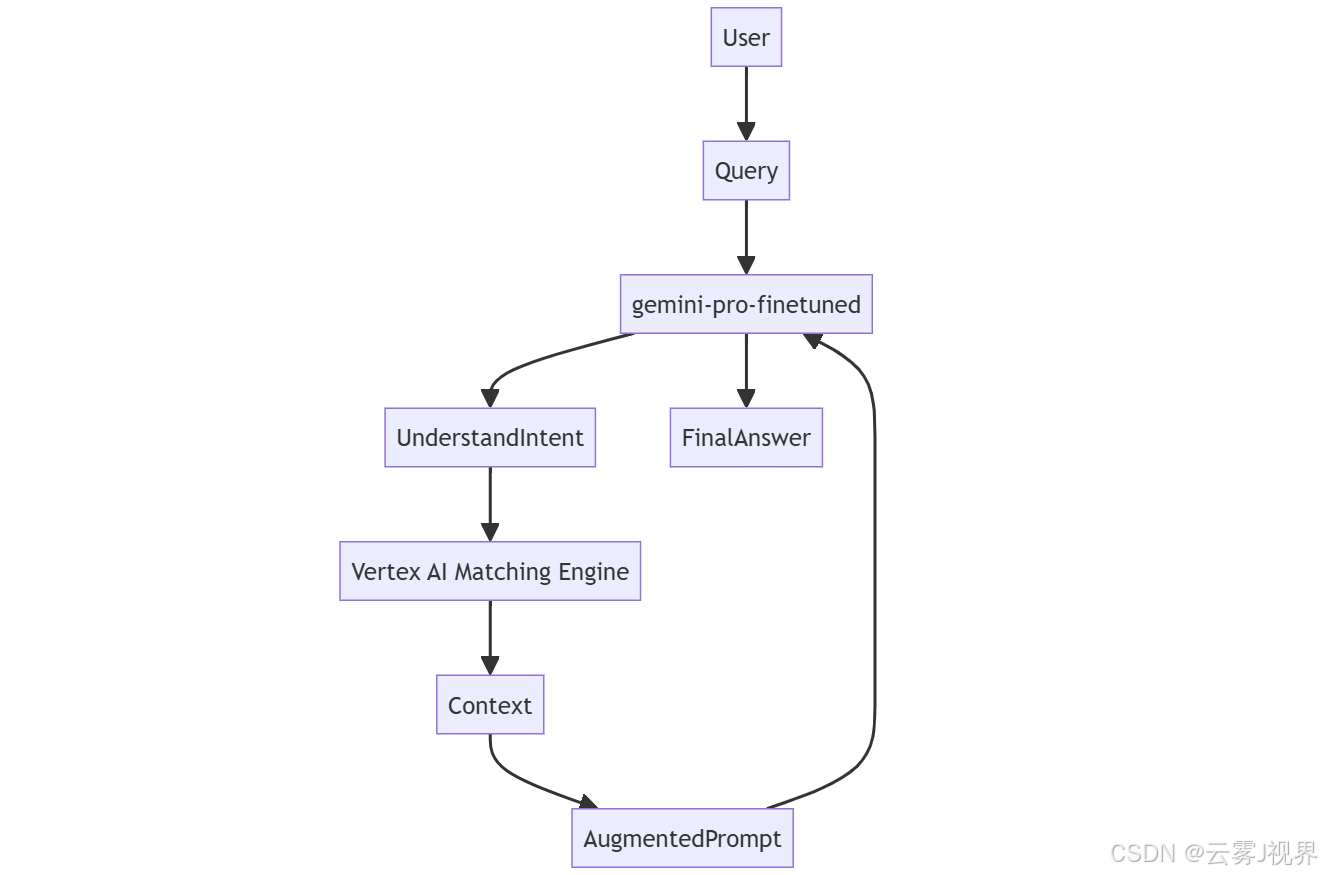
此模式下:
- 微调模型更擅长理解复杂查询意图(如"对比 PCI-DSS 3.4 与 GDPR Article 32 的差异")
- RAG 确保答案基于最新事实(如 2025 年新修订条款)
案例:摩根士丹利在 2025 年 Q2 采用此架构,将合规问答准确率提升至 99.2%。
四、首周行动:从认知到代码
4.1 Google Sheets 集成代码(RAG 快速原型)
以下代码可直接运行,将 Google Sheets 作为简易知识库(需启用 Sheets API):
python
# requirements.txt
# google-auth==2.29.0
# google-api-python-client==2.134.0
# google-generativeai==0.8.0
# pandas==2.2.0
import pandas as pd
import google.generativeai as genai
from google.oauth2 import service_account
from googleapiclient.discovery import build
# 1. 配置 Gemini
GEMINI_API_KEY = "YOUR_GEMINI_API_KEY"
genai.configure(api_key=GEMINI_API_KEY)
# 2. 读取 Google Sheets
SCOPES = ['https://www.googleapis.com/auth/spreadsheets.readonly']
SERVICE_ACCOUNT_FILE = 'your-service-account.json' # 下载自 GCP IAM
SPREADSHEET_ID = 'YOUR_SHEET_ID'
creds = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_FILE, scopes=SCOPES)
service = build('sheets', 'v4', credentials=creds)
# 假设 Sheet 结构:A列=问题,B列=答案
sheet = service.spreadsheets()
result = sheet.values().get(
spreadsheetId=SPREADSHEET_ID,
range='FAQ!A:B'
).execute()
rows = result.get('values', [])
if not rows:
raise ValueError("No data found in sheet")
df = pd.DataFrame(rows[1:], columns=rows[0])
def rag_answer(query: str, top_k: int = 3) -> str:
"""简易 RAG:基于关键词匹配(生产环境应替换为向量检索)"""
# 此处为简化演示,实际应使用 text-embedding-004 + cosine similarity
matched = df[df['问题'].str.contains(query, case=False, na=False)]
if matched.empty:
return "未找到相关信息,请联系管理员。"
# 取 top_k 条
context = "\n".join(matched.head(top_k)['答案'].tolist())
prompt = f"""
你是一名企业知识助手,请基于以下官方信息回答问题。
仅使用以下内容,不要编造。
信息:
{context}
问题:{query}
请用简洁中文回答。
"""
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content(prompt, safety_settings={
"HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE",
"HARM_CATEGORY_HARASSMENT": "BLOCK_NONE"
})
return response.text
# 测试
if __name__ == "__main__":
print(rag_answer("如何重置密码?"))说明 :此为简化版,用于快速验证流程。生产环境应:
使用text-embedding-004生成向量
使用 ChromaDB 或 Vertex AI Matching Engine 进行相似度检索
添加缓存与速率限制
4.2 首周实施计划(SMART 原则)
|--------|-----------------------|---------------|-------------------------------------------------------|
| 天数 | 行动 | 产出 | 工具 |
| 第1-2天 | 用四象限法盘点知识资产 | 《知识资产清单.xlsx》 | Excel / Notion |
| 第3-4天 | 应用三维决策框架 | 《技术选型建议书》 | 本文决策表 |
| 第5天 | 运行上述 Sheets 代码 | 可交互的 FAQ 机器人 | Python + GCP |
| 周末 | 在 AI Studio 上传 10 条指令 | 微调模型预览链接 | AI Studio |
结尾:智能知识库不是终点,而是认知基础设施的起点
RAG 与微调并非技术竞赛,而是匹配业务节奏的战略选择:
- RAG 是"引用高手":适合知识动态、需溯源、快速验证的场景,让企业知识"活起来"。
- 微调是"内化专家":适合构建专业壁垒,将组织经验沉淀为数字资产。
Gemini API 的真正价值,在于提供统一入口,让你低成本试错、快速迭代。正如 Google Cloud CTO 在 2025 年开发者大会上所言:"未来的企业竞争力,不在于拥有多少数据,而在于多快能将数据转化为可行动的智能。"