文章目录
k8s的pod管理
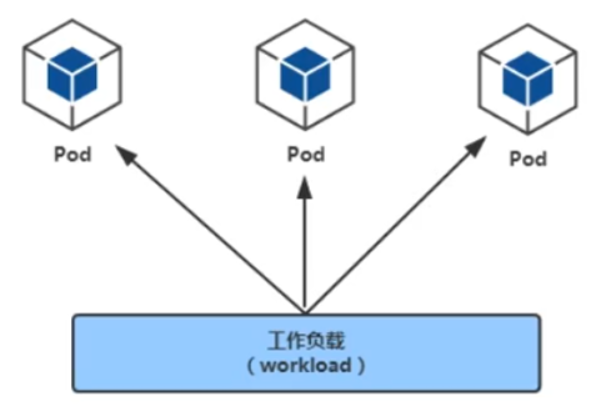
工作负载
https://kubernetes.io/zh-cn/docs/concepts/workloads/
工作负载(workload)是在kubernetes集群中运行的应用程序。无论你的工作负载是单一服务还是多个一 同工作的服务构成,在kubernetes中都可以使用pod来运行它。
workloads分为pod与controllers
controller 负责动态pod的生命周期
kubelet 负责静态pod的生命周期
- pod通过控制器实现应用的运行,如何伸缩,升级等
- controllers 在集群中管理pod
- pod与控制器之间通过label-selector相关联,是唯一的关联方式
pod介绍
1:pod定义与分类
文档链接: https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/
Pod定义
- Pod(豌豆夹)是Kubernetes集群管理(创建、部署)与调度的最小计算单元,表示处于运行状态的一 组容器。
- Pod不是进程,而是容器运行的环境。
- 一个Pod可以封装一个容器或多个容器(主容器或sidecar边车容器) 一个pod内的多个容器之间共享部分命名空间,例如:Net Namespace,UTs Namespace,IPC Namespace及存储资源
- 用户pod默认会被调度运行在node节点之上(不运行在master节点上,但也有例外情况)
- pod内的IP不是固定的,集群外不能直接访问pod
Pod分类
- 静态Pod 也称之为"无控制器管理的自主式pod",直接由特定节点上的 kubelet 守护进程管理,不 需要API服务器看到它们,尽管大多数 Pod都是通过控制平面控制器(例如,Deployment)来管理 的,对于静态 Pod 而言,kubelet 直接监控每个 Pod,并在其失效时重启之。
- 控制器管理的pod 控制器可以控制pod的副本数,扩容与裁剪,版本更新与回滚等
2:查看pod方法
pod是一种计算资源,可以通过kubect1 get pod来查看
bash
#指定命名空间
[root@master ~ 09:21:02]# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-5657497c4c-r9x5m 1/1 Running 1 (17h ago) 38h
kubernetes-dashboard-746fbfd67c-lvfqf 1/1 Running 1 (17h ago) 38h
[root@master ~ 09:55:22]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-658d97c59c-hv65v 1/1 Running 4 (17h ago) 2d17h
calico-node-gwm78 1/1 Running 0 51m
calico-node-j9lp4 1/1 Running 0 51m
calico-node-vj4jh 1/1 Running 0 51m
coredns-5d89d45557-6z4qs 1/1 Running 0 44m
coredns-5d89d45557-c5c5w 1/1 Running 0 44m
etcd-master 1/1 Running 4 (17h ago) 2d17h
kube-apiserver-master 1/1 Running 9 (17h ago) 2d17h
kube-controller-manager-master 1/1 Running 4 (17h ago) 2d17h
kube-proxy-chrxb 1/1 Running 0 44m
kube-proxy-nfzhx 1/1 Running 0 44m
kube-proxy-vwg2j 1/1 Running 0 44m
kube-scheduler-master 1/1 Running 4 (17h ago) 2d17h
metrics-server-57999c5cf7-tqwxt 1/1 Running 2 (17h ago) 39h
#不指定命名空间则是default
[root@master ~ 09:55:03]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-7854ff8877-dztxq 1/1 Running 2 (17h ago) 43h
nginx-7854ff8877-kqfmr 1/1 Running 2 (17h ago) 43h
nginx-7854ff8877-mt8qt 1/1 Running 2 (17h ago) 43h
tomcat-test-75469fdc74-jrqjb 1/1 Running 1 (17h ago) 17h
tomcat-test-75469fdc74-pk8hw 1/1 Running 0 10h3:pod的YAML资源清单格式
先看一个yaml格式的pod定义文件解释
bash
# yam1格式的pod定义文件完整内容:
apiVersion:v1 #必选,api版本号,使用kubect api-resources查看
kind: pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace:string #Pod所属的命名空间,默认在default的namespace
labels: #自定义标签
name: string #自定义标签名字
annotations: #自定义注释列表
name: string
spec: #必选,Pod中容器的详细定义(期望)
containers: #必选,Pod中容器列表
- name: string
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 Ifnotpresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用vo1umes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式,一般为fasle
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort:int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量值
resources: #资源限制和请求的设置
limits: #资源限制设置
cpu: string #Cpu的限制,单位为core数,将用于docker run--cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #cpu请求,容器启动的初始可用数量
memory: string #内存清求,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpsocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpsocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,0nFai1ure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: object #设置NodeSelector表示将该Pod调度到包含这个1abel的node上,以key:value的格式指定
imagePullSecrets: #私有镜像仓库Pu11镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为fa1se,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称(volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret:
secretname: string #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: stringYAML格式查找帮助
bash
[root@master ~]# kubectl explain pod
[root@master ~]# kubectl explain pod.spec
[root@master ~]# kubectl explain pod.spec.containerspod创建与验证
1:命令创建pod
清空原始环境
bash
#使用controller创建动态的pod 需要删除deploy才能删除
[root@master ~ 09:55:48]# kubectl delete deploy nginx
deployment.apps "nginx" deleted
[root@master ~ 10:14:13]# kubectl get pods
NAME READY STATUS RESTARTS AGE
tomcat-test-75469fdc74-jrqjb 1/1 Running 1 (17h ago) 18h
tomcat-test-75469fdc74-pk8hw 1/1 Running 0 10h
#使用yaml文件创建的直接删除yaml文件即可
[root@master ~ 10:14:27]# kubectl delete -f tomcat_dir/tomcat.yaml
configmap "tomcat-web-content" deleted
deployment.apps "tomcat-test" deleted
service "tomcat-service" deleted
[root@master ~ 10:14:46]# kubectl get pods
No resources found in default namespace.
[root@master ~ 10:15:09]# kubectl get svc
\NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h
nginx ClusterIP 10.98.13.195 <none> 80/TCP 18h
#需要特别删除svc
[root@master ~ 10:15:22]# kubectl delete svc nginx
service "nginx" deleted
[root@master ~ 10:15:39]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d17h创建名为pod-nginx的pod
bash
[root@master ~ 10:15:43]# kubectl run nginx1 --image=nginx:1.26-alpine
pod/nginx1 created
[root@master ~ 10:19:03]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx1 0/1 ContainerCreating 0 10s
[root@master ~ 10:19:13]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx1 0/1 ContainerCreating 0 15s <none> node1 <none> <none>
[root@master ~ 10:20:05]# kubectl describe pod nginx1
Name: nginx1
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.18.129
Start Time: Fri, 16 Jan 2026 10:19:03 +0800
Labels: run=nginx1
Annotations: cni.projectcalico.org/containerID: 7f8d464edc7752814a6c54db50bd56e3e10c7945b10a49ae56da1c4d87be6105
cni.projectcalico.org/podIP: 10.244.166.154/32
cni.projectcalico.org/podIPs: 10.244.166.154/32
Status: Running
IP: 10.244.166.154
IPs:
IP: 10.244.166.154
Containers:
nginx1:
Container ID: docker://340b8ea04f0cd58c023d02da786b71262a84fc053eae6ec7f3b4ccc9108ae0ab
Image: nginx:1.26-alpine
Image ID: docker-pullable://nginx@sha256:1eadbb07820339e8bbfed18c771691970baee292ec4ab2558f1453d26153e22d
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 16 Jan 2026 10:19:22 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-ptlbs (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-ptlbs:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 68s default-scheduler Successfully assigned default/nginx1 to node1
Normal Pulling 68s kubelet Pulling image "nginx:1.26-alpine"
Normal Pulled 50s kubelet Successfully pulled image "nginx:1.26-alpine" in 17.929s (17.929s including waiting)
Normal Created 50s kubelet Created container nginx1
Normal Started 50s kubelet Started container nginx1
#验证
[root@master ~ 10:20:12]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 77s2:YAML创建pod
bash
[root@master ~ 10:20:20]# vim pod1.yaml
[root@master ~ 10:35:07]# cat pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
#应用
[root@master ~ 10:36:18]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master ~ 10:36:21]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx1 1/1 Running 0 17m 10.244.166.154 node1 <none> <none>
pod-stress 1/1 Running 0 20s 10.244.166.155 node1 <none> <none>查看资源占用
bash
#需要先下载metrics-server
kubectl top pod pod-stress描述pod详细信息
bash
[root@master ~ 10:36:57]# kubectl describe pod pod-stress
Name: pod-stress
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.18.129
Start Time: Fri, 16 Jan 2026 10:36:21 +0800
Labels: <none>
Annotations: cni.projectcalico.org/containerID: e4760988e3ebce75115121e1c23d2c993958417c04b0490d6124ee1ff8f778f1
cni.projectcalico.org/podIP: 10.244.166.155/32
cni.projectcalico.org/podIPs: 10.244.166.155/32
Status: Running
IP: 10.244.166.155
IPs:
IP: 10.244.166.155
Containers:
c1:
Container ID: docker://98c92474693d8ee89e35e05a554a8476cf0fa4822f91b215e42c635e7ca0b4a5
Image: polinux/stress
Image ID: docker-pullable://polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
150M
--vm-hang
1
State: Running
Started: Fri, 16 Jan 2026 10:36:29 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-sg5mf (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-sg5mf:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 92s default-scheduler Successfully assigned default/pod-stress to node1
Normal Pulling 92s kubelet Pulling image "polinux/stress"
Normal Pulled 85s kubelet Successfully pulled image "polinux/stress" in 7.239s (7.239s including waiting)
Normal Created 85s kubelet Created container c1
Normal Started 85s kubelet Started container c1启动pod失败,首先要查看kubectl describe pod pod名中的event 再查看 kubectl logs -f pod名(查看的是容器的日志)
3:删除pod
单个pod删除
在没有控制器管理的前提下可以直接删除,但是如果有控制器管理,控制器就会重新拉起pod
方法1:
bash
kubectl delete pod pod-stress方法2:
bash
kubectl delete -f pod1.yml 多个pod删除
方法1:(批量删除)
bash
[root@master ~ 10:37:54]# kubectl get pods | awk '{print $1}'
NAME
nginx1
pod-stress
[root@master ~ 10:40:25]# kubectl get pods | awk 'NR>1 {print $1}'
nginx1
pod-stress
[root@master ~ 10:40:37]# kubectl get pods | awk 'NR>1 {print $1}' | xargs kubectl delete pod
pod "nginx1" deleted
pod "pod-stress" deleted
[root@master ~ 10:41:42]# kubectl get pods
No resources found in default namespace.方法2:(创建时指定命名空间,直接删除命名空间即可)
bash
[root@master ~ 10:42:07]# kubectl create ns game
namespace/game created
[root@master ~ 10:42:34]# kubectl get ns | grep game
game Active 15s
[root@master ~ 10:42:49]# kubectl run nginx1 --image nginx:1.26-alpine --namespace game
pod/nginx1 created
[root@master ~ 10:43:35]# kubectl run nginx2 --image nginx:1.26-alpine --namespace game
pod/nginx2 created
[root@master ~ 10:43:41]# kubectl get pods
No resources found in default namespace.
[root@master ~ 10:43:50]# kubectl get pods -n game
NAME READY STATUS RESTARTS AGE
nginx1 1/1 Running 0 27s
nginx2 1/1 Running 0 21s
[root@master ~ 10:44:02]# kubectl delete ns game
namespace "game" deleted4:镜像拉取策略
由imagePullPolicy参数控制
- Always:不管本地有没有镜像,都要从仓库中下载镜像
- Never:从来不从仓库下载镜像,只用本地镜像,本地没有就算了
- IfNotPresent:如果本地存在就直接使用,不存在才从仓库下载
默认的策略是:
- 当镜像标签版本是latest,默认策略就是Always
- 如果指定特定版本默认拉取策略就是IfNotPresent.
1:将上面的pod删除再创建,使用下面命令查看信息
bash
#去两个节点pull所需的nginx镜像
[root@master ~ 11:26:21]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master ~ 11:26:48]# kubectl describe pod pod-stress
.....
Normal Pulling 2s kubelet Pulling image "polinux/stress"
Normal Pulled 1s kubelet Successfully pulled image "polinux/stress" in 1.711s (1.711s including waiting)
#发现依然会去pull镜像说明:可以看到第二行信息还是pulling image 下载镜像
2:修改YAML 再次删除并创建
bash
[root@master ~ 11:26:51]# kubectl delete -f pod1.yaml
pod "pod-stress" deleted
[root@master ~ 11:27:50]# vim pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent #添加镜像拉取策略
[root@master ~ 11:29:47]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master ~ 11:29:51]# kubectl describe pod pod-stress
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3s default-scheduler Successfully assigned default/pod-stress to node1
Normal Pulled 3s kubelet Container image "polinux/stress" already present on machine
#本地有则不会去拉取镜像5:pod的标签
- 为pod设置label,用于控制器通过label与pod关联
- 语法与前面学的node标签几乎一致
通过命令管理pod标签
1:查看pod标签
bash
[root@master ~ 11:29:55]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 44s <none>2:打标签
bash
[root@master ~ 11:33:20]# kubectl label pod pod-stress region=nanjing zone=A env=test bussiness=game
pod/pod-stress labeled
[root@master ~ 11:33:28]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 3m52s bussiness=game,env=test,region=nanjing,zone=A3:查看标签
bash
[root@master ~ 11:33:43]# kubectl get pods -l zone=A
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 4m13s
[root@master ~ 11:34:04]# kubectl get pods -L region
NAME READY STATUS RESTARTS AGE REGION
pod-stress 1/1 Running 0 4m56s nanjing
[root@master ~ 11:34:47]# kubectl get pods -l "zone in (A,B,C)"
NAME READY STATUS RESTARTS AGE
pod-stress 1/1 Running 0 5m32s4:删除标签
bash
[root@master ~ 11:35:23]# kubectl label pod pod-stress region- zone- env- bussiness-
[root@master ~ 11:36:11]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 6m23s <none>总结:
- pod的label与node的label操作方式几乎相同
- node的label用于pod调度到指定label的node节点
- pod的label用于controller关联控制的pod
通过YAML创建pod时添加标签
bash
[root@master ~ 13:18:04]# vim pod1.yaml
[root@master ~ 13:19:13]# cat pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress
labels: #添加标签
env: dev
app: nginx
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
#验证:
[root@master ~ 13:19:16]# kubectl apply -f pod1.yaml
pod/pod-stress created
[root@master ~ 13:19:32]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
pod-stress 1/1 Running 0 23s app=nginx,env=dev6:pod资源限制
准备2个不同限制方式,创建pod的yaml文件
bash
[root@master ~ 13:27:35]# vim pod2.yaml
[root@master ~ 13:27:56]# cat pod2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress2
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
resources: #添加资源限制
limits: #运行时限制
memory: "200Mi"
requests: #启动时限制
memory: "100Mi"
[root@master ~ 13:27:52]# kubectl apply -f pod2.yaml
[root@master ~ 13:28:02]# kubectl get pods -n namespace1
NAME READY STATUS RESTARTS AGE
pod-stress2 1/1 Running 0 34s创建超出限制的资源文件
bash
[root@master ~ 13:46:04]# vim pod3.yaml
[root@master ~ 13:46:52]# cat pod3.yaml
apiVersion: v1
kind: Namespace
metadata:
name: namespace1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-stress3
namespace: namespace1
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","250M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "200Mi"
requests:
memory: "150Mi"
[root@master ~ 13:47:24]# kubectl apply -f pod3.yaml
[root@master ~ 13:48:06]# kubectl describe pod pod-stress3 -n namespace1
Name: pod-stress3
Namespace: namespace1
Priority: 0
Service Account: default
Node: node1/192.168.18.129
Start Time: Fri, 16 Jan 2026 13:47:26 +0800
Labels: <none>
Annotations: cni.projectcalico.org/containerID: f826e0c9be25a1a65c002b819bce5017d478b62236ed59e0a9b1158d55858569
cni.projectcalico.org/podIP: 10.244.166.166/32
cni.projectcalico.org/podIPs: 10.244.166.166/32
Status: Running
IP: 10.244.166.166
IPs:
IP: 10.244.166.166
Containers:
c1:
Container ID: docker://44cccbd8c1b4f70045077265e9e56c0b73f0987be507c8325947e4acb60d8ee8
Image: polinux/stress
Image ID: docker-pullable://polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
250M
--vm-hang
1
State: Terminated
Reason: OOMKilled #原因
Exit Code: 1
Started: Fri, 16 Jan 2026 13:48:07 +0800
Finished: Fri, 16 Jan 2026 13:48:07 +0800
Last State: Terminated
Reason: OOMKilled
Exit Code: 1
Started: Fri, 16 Jan 2026 13:47:41 +0800
Finished: Fri, 16 Jan 2026 13:47:41 +0800
Ready: False
Restart Count: 3
Limits:
memory: 200Mi
Requests:
memory: 150Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-ns4cx (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-ns4cx:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 48s default-scheduler Successfully assigned namespace2/pod-stress3 to node1
Normal Pulled 9s (x4 over 48s) kubelet Container image "polinux/stress" already present on machine
Normal Created 9s (x4 over 48s) kubelet Created container c1
Normal Started 8s (x4 over 48s) kubelet Started container c1
Warning BackOff 7s (x5 over 47s) kubelet Back-off restarting failed container c1 in pod pod-stress3_namespace2(7efc3531-d242-4cd6-98cf-91ece23cb9bc)
#发现容器没有运行成功,因为限制了容器的运行的memory说明:一旦pod中的容器挂了,容器会有重启策略,如下:
- Always:表示容器挂了总是重启,这是默认策略
- OnFailures:表容器状态为错误时才重启,也就是容器正常终止时不会重启
- Never:表示容器挂了不予重启
- 对于Always这种策略,容器只要挂了,就会立即重启,这样是很耗费资源的。所以Always重启策 略是这么做的:第一次容器挂了立即重启,如果再挂了就要延时10s重启,第三次挂了就等20s重启. 依次类推
删除资源:
bash
[root@master ~ 13:48:15]# kubectl delete ns namespace1
namespace "namespace1" deleted7:pod包含多个容器
在yaml的pod中声明两个容器
bash
[root@master ~ 14:26:30]# vim pod4.yaml
[root@master ~ 14:26:44]# cat pod4.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-stress4
namespace: default
labels:
env: dev
app: nginx
spec:
containers:
- name: c1
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent
- name: c2
image: polinux/stress
command: ["stress"]
args: ["--vm","1","--vm-bytes","150M","--vm-hang","1"]
imagePullPolicy: IfNotPresent查看pod的状态
bash
[root@master ~ 14:26:59]# kubectl apply -f pod4.yaml
pod/pod-stress4 created
[root@master ~ 14:27:09]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-stress4 2/2 Running 0 15s查看pod的节点分布
bash
[root@master ~ 14:27:24]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-stress4 2/2 Running 0 22s 10.244.166.169 node1 <none> <none>
#在node1上创建在node1上验证。产生了2个容器
bash
[root@node1 ~ 11:24:33]# docker ps -a | grep stress
b0a84a0e4738 df58d15b053d "stress --vm 1 --vm-..." 51 seconds ago Up 50 seconds k8s_c2_pod-stress4_default_40d19d0f-3e7d-493c-a799-cd5e66284811_0
ca795c27217f df58d15b053d "stress --vm 1 --vm-..." 51 seconds ago Up 50 seconds k8s_c1_pod-stress4_default_40d19d0f-3e7d-493c-a799-cd5e66284811_08:对pod里的容器进行操作
命令帮助
bash
kubectl exec -h不用交互直接执行命令
bash
格式为: kubectl exec pod名 -c 容器名 -- 命令注意:
- -c 容器名为可选项,如果是1个pod中1个容器,则不用指定。
- 如果是1个pod中多个容器,不指定默认为第1个。
bash
#不-c指定容器,默认为pod里的第一个容器
[root@master ~ 14:28:59]# kubectl exec pod-stress4 -- date
Defaulted container "c1" out of: c1, c2
Fri Jan 16 06:29:45 UTC 2026
[root@master ~ 14:31:18]# kubectl exec pod-stress4 -c c1 -- date
Fri Jan 16 06:31:22 UTC 2026
[root@master ~ 14:31:22]# kubectl exec pod-stress4 -c c2 -- date
Fri Jan 16 06:31:26 UTC 2026输入命令
bash
[root@master ~ 14:31:26]# kubectl exec pod-stress4 -- touch /abc.txt
Defaulted container "c1" out of: c1, c2
[root@master ~ 14:32:00]# kubectl exec pod-stress4 -c c1 -- ls / |grep abc
abc.txt
[root@master ~ 14:32:28]# kubectl exec pod-stress4 -c c2 -- ls / |grep abc和容器的交互操作
bash
#没有指定-c 默认pod中第一个容器
[root@master ~ 14:33:10]# kubectl exec -it pod-stress4 -- /bin/bash
Defaulted container "c1" out of: c1, c2
bash-5.0# ls
abc.txt dev home media opt root sbin sys usr
bin etc lib mnt proc run srv tmp var
bash-5.0# exit
exit
[root@master ~ 14:33:35]# kubectl exec -it pod-stress4 -c c2 -- /bin/bash
bash-5.0# ls
bin etc lib mnt proc run srv tmp var
dev home media opt root sbin sys usr
bash-5.0# exit
exit容器网络和pod网络的关系
bash
#可以发现pod的网络是10.244.166.169
[root@master ~ 14:33:50]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-stress4 2/2 Running 0 7m30s 10.244.166.169 node1 <none> <none>
#c1 c2的网络是10.244.166.169
[root@master ~ 14:34:39]# kubectl exec -it pod-stress4 -c c2 -- /bin/bash
bash-5.0# ip -br a
BusyBox v1.31.1 () multi-call binary.
Usage: ip [OPTIONS] address|route|link|tunnel|neigh|rule [ARGS]
OPTIONS := -f[amily] inet|inet6|link | -o[neline]
ip addr add|del IFADDR dev IFACE | show|flush [dev IFACE] [to PREFIX]
ip route list|flush|add|del|change|append|replace|test ROUTE
ip link set IFACE [up|down] [arp on|off] [multicast on|off]
[promisc on|off] [mtu NUM] [name NAME] [qlen NUM] [address MAC]
[master IFACE | nomaster]
ip tunnel add|change|del|show [NAME]
[mode ipip|gre|sit] [remote ADDR] [local ADDR] [ttl TTL]
ip neigh show|flush [to PREFIX] [dev DEV] [nud STATE]
ip rule [list] | add|del SELECTOR ACTION
bash-5.0# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue state UP
link/ether 32:fe:43:15:5a:5d brd ff:ff:ff:ff:ff:ff
inet 10.244.166.169/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::30fe:43ff:fe15:5a5d/64 scope link
valid_lft forever preferred_lft forever
bash-5.0# exit
exit
[root@master ~ 14:35:05]# kubectl exec -it pod-stress4 -c c1 -- /bin/bash
bash-5.0# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue state UP
link/ether 32:fe:43:15:5a:5d brd ff:ff:ff:ff:ff:ff
inet 10.244.166.169/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::30fe:43ff:fe15:5a5d/64 scope link
valid_lft forever preferred_lft forever
bash-5.0# exit
exit9:验证pod中多个容器网络共享
bash
[root@master ~ 14:35:30]# vim pod-nginx.yaml
[root@master ~ 14:36:43]# cat pod-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx2
spec:
containers:
- name: c1
image: nginx:1.26-alpine
- name: c2
image: nginx:1.26-alpine
[root@master ~ 14:36:49]# kubectl apply -f pod-nginx.yaml
pod/nginx2 created查看pod信息于状态
bash
#发现一共有2个容器,只成功运行了1个
[root@master ~ 14:37:04]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx2 1/2 Error 1 (8s ago) 11s查找原因:
- 查看pod的详细信息
bash
[root@master ~ 14:37:32]# kubectl describe pod nginx2
Name: nginx2
Namespace: default
Priority: 0
Service Account: default
Node: node1/192.168.18.129
Start Time: Fri, 16 Jan 2026 14:37:04 +0800
Labels: <none>
Annotations: cni.projectcalico.org/containerID: 86438c763a4c0357147372d42625fcfb40c85bfb936a98cebe7d2c6c4bf4b1ff
cni.projectcalico.org/podIP: 10.244.166.170/32
cni.projectcalico.org/podIPs: 10.244.166.170/32
Status: Running
IP: 10.244.166.170
IPs:
IP: 10.244.166.170
Containers:
c1:
Container ID: docker://5d6ffd76bd29a2e14a9182423379cfaf6bb3b5d79b678c52330b0c16dbb0739b
Image: nginx:1.26-alpine
Image ID: docker-pullable://nginx@sha256:1eadbb07820339e8bbfed18c771691970baee292ec4ab2558f1453d26153e22d
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 16 Jan 2026 14:37:05 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-qxgfb (ro)
c2:
Container ID: docker://013305a65cca9ab5ce628bfd2806e2f71ee207059c0fdc85957ed6b4ac6faf49
Image: nginx:1.26-alpine
Image ID: docker-pullable://nginx@sha256:1eadbb07820339e8bbfed18c771691970baee292ec4ab2558f1453d26153e22d
Port: <none>
Host Port: <none>
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Fri, 16 Jan 2026 14:37:23 +0800
Finished: Fri, 16 Jan 2026 14:37:25 +0800
Ready: False
Restart Count: 2
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-qxgfb (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-qxgfb:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 46s default-scheduler Successfully assigned default/nginx2 to node1
Normal Pulled 46s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 46s kubelet Created container c1
Normal Started 46s kubelet Started container c1
Normal Pulled 29s (x3 over 46s) kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 29s (x3 over 46s) kubelet Created container c2
Normal Started 28s (x3 over 46s) kubelet Started container c2
Warning BackOff 11s (x3 over 40s) kubelet Back-off restarting failed container c2 in pod nginx2_default(9c650c46-65c6-4dc7-9dce-b80aaf07d6e0)
#发现有一个容器费油起来,但是已经创建好了- 查看日志
bash
#查看的是容器的日志
[root@master ~ 14:37:51]# kubectl logs nginx2
。。。
2026/01/16 06:37:05 [notice] 1#1: start worker processes
2026/01/16 06:37:05 [notice] 1#1: start worker process 30
2026/01/16 06:37:05 [notice] 1#1: start worker process 31
2026/01/16 06:37:05 [notice] 1#1: start worker process 32
2026/01/16 06:37:05 [notice] 1#1: start worker process 33
#发现容器一直在尝试启动- 寻找容器pod创建的节点
bash
[root@master ~ 14:37:15]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx2 1/2 Error 2 (21s ago) 28s 10.244.166.170 node1 <none> <none>- 去node1上查看
bash
[root@node1 ~ 14:28:01]# docker ps -a | grep nginx
fcdf87142062 42ce3d3585d4 "/docker-entrypoint...." 15 seconds ago Exited (1) 11 seconds ago k8s_c2_nginx2_default_9c650c46-65c6-4dc7-9dce-b80aaf07d6e0_4
5d6ffd76bd29 42ce3d3585d4 "/docker-entrypoint...." About a minute ago Up About a minute k8s_c1_nginx2_default_9c650c46-65c6-4dc7-9dce-b80aaf07d6e0_0
86438c763a4c registry.aliyuncs.com/google_containers/pause:3.9 "/pause" About a minute ago Up About a minute k8s_POD_nginx2_default_9c650c46-65c6-4dc7-9dce-b80aaf07d6e0_0
#查看状态为退出的容器日志
[root@node1 ~ 14:38:52]# docker logs k8s_c2_nginx2_default_9c650c46-65c6-4dc7-9dce-b80aaf07d6e0_4
。。。。
2026/01/16 06:38:38 [emerg] 1#1: bind() to [::]:80 failed (98: Address in use)
nginx: [emerg] bind() to [::]:80 failed (98: Address in use)
#得出结论80端口被占用发现有1个容器启动失败,主要原因是在同一个网络环境中两个nginx都启动的80端口产生冲突,则容器和pod共用一个网络。
建立宿主机会和pod(容器)生成一对网卡,同时产生同时删除,且宿主机的网卡编号是奇数,容器的网卡编号是偶数。
pod调度
调度流程
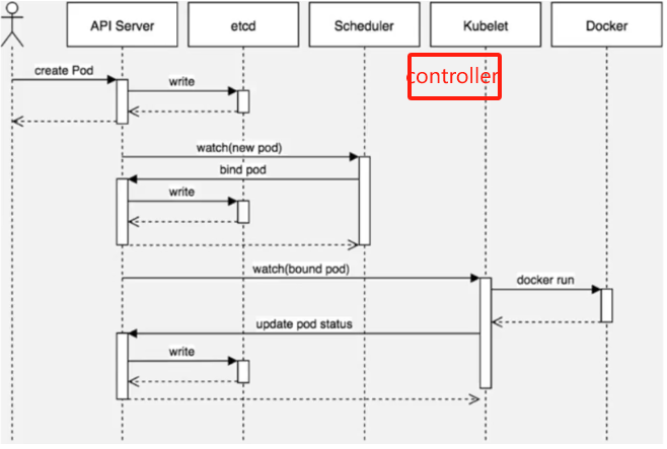
bash
第1步
通过kubect1命令应用资源清单文件(yam]格式)向api server 发起一个create pod 请求
第2步
api server接收到pod创建请求后,生成一个包含创建信息资源清单文件
第3步
api server 将资源清单文件中信息写入etcd数据库
第4步
scheduler启动后会一直watch API server,获取 podspec.NodeName为空的Pod,即判断
pod.spec.Node == nu11?若为nu11,表示这个Pod请求是新的,需要创建,因此先进行调度计算(共计2
步;1、过滤不满足条件的,2、选择优先级高的),找到合适的node,然后将信息在etcd数据库中更新分配结
果:pod.spec.Node =nodeA(设置一个具体的节点)
第5步
Kubelet 通过watch etcd数据库(即不停地看etcd中的记录),发现有新的Node出现,如果这条记录中的
Node与所在节点编号相同,即这个Pod由scheduler分配给自己,则调用node中的container Runtime,
进而创建container,并将创建后的结果返回到给api server用于更新etcd数据库中数据状态。简单过程:
用户使用创建pod命令前先要经过admin.conf的身份验证,在输入create命令给API Server,API Server立刻反馈给用户pod创建的显示,API Server将创建信息写入etcd,etcd写入后告知API Server已经写入完成,Schedule通过watch API Server的创建pod信息,调度选择出合适的创建pod节点,返回给API Server,API Server再将节点信息写入到etcd,etcd写入后告知API Server已经写入完成,API Server告知Schedule自己已经接收到信息准备在该节点上创建pod了,以后再分析节点信息时要将这个信息算进去(否则schedule将认为该节点没有创建pod),API Server去对应节点找到代理的kubelet调用底层容器运行时,创建容器,docker将创建的信息反馈给kubelet,kubelet再将容器的状态反馈给API Server,由API Server将状态写入到etcd中,写入后etcd给API Server写入完成的反馈,API Server再告诉kubelet已经记载完成状态已经同步。整个过程用户都是API Server上操作,用户调用的信息都是在etcdz中。
调度约束方法
我们为了实现容器主机资源平衡使用,可以使用约束把pod调度到指定的node节点
- nodeName用于将pod调度到指定的node名称上
- nodeSelector用于将pod调度到匹配Label的node上
1:nodeName
bash
[root@master ~ 14:39:44]# vim pod-nodename.yaml
[root@master ~ 15:33:43]# cat pod-nodename.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodename
spec:
nodeName: node1
containers:
- name: nginx
image: nginx:1.26-alpine
[root@master ~ 15:33:47]# kubectl apply -f pod-nodename.yaml
pod/pod-nodename created查看调度
bash
[root@master ~ 15:34:38]# kubectl describe pod pod-nodename | tail -n 7
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 40s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 40s kubelet Created container nginx
Normal Started 40s kubelet Started container nginx在yaml文件中指明nodeName节点,kubectl describe查询event发现,不需要schedule
(原来过程:scheduled -> pulled -> created -> started)
2:nodeSelector
给node1节点打上标签为game
bash
[root@master ~ 15:34:50]# kubectl label nodes node2 bussiness=game
node/node2 labeled
bash
[root@master ~ 15:35:35]# vim pod-nodeselector.yaml
[root@master ~ 15:39:47]# cat pod-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselect
spec:
nodeSelector:
bussiness: game
containers:
- name: nginx
image: nginx:1.26-alpine
[root@master ~ 15:39:54]# kubectl apply -f pod-nodeselector.yaml
pod/pod-nodeselect created查看调度
bash
[root@master ~ 15:40:23]# kubectl describe pod pod-nodeselect | tail -n 7
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 55s default-scheduler Successfully assigned default/pod-nodeselect to node2
Normal Pulled 54s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 54s kubelet Created container nginx
Normal Started 54s kubelet Started container nginxnodeSelector依然需要调度找到对应标签的节点
pod的生命周期
created -> started)
2:nodeSelector
给node1节点打上标签为game
bash
[root@master ~ 15:34:50]# kubectl label nodes node2 bussiness=game
node/node2 labeled
bash
[root@master ~ 15:35:35]# vim pod-nodeselector.yaml
[root@master ~ 15:39:47]# cat pod-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-nodeselect
spec:
nodeSelector:
bussiness: game
containers:
- name: nginx
image: nginx:1.26-alpine
[root@master ~ 15:39:54]# kubectl apply -f pod-nodeselector.yaml
pod/pod-nodeselect created查看调度
bash
[root@master ~ 15:40:23]# kubectl describe pod pod-nodeselect | tail -n 7
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 55s default-scheduler Successfully assigned default/pod-nodeselect to node2
Normal Pulled 54s kubelet Container image "nginx:1.26-alpine" already present on machine
Normal Created 54s kubelet Created container nginx
Normal Started 54s kubelet Started container nginxnodeSelector依然需要调度找到对应标签的节点