之前我们已经学习了解过Linux系统的底层IO逻辑。本期我们就接着IO学习Linux系统的底层逻辑------磁盘硬件与Ext系列的文件。
相关代码已经上传至作者的个人gitee:ExtFile/TEST.img · 楼田莉子/Linux学习 - 码云 - 开源中国喜欢请点个赞谢谢
目录
[Block Group](#Block Group)
[超级块(Super Block)](#超级块(Super Block))
[GDT(Group Descriptor Table)](#GDT(Group Descriptor Table))
[块位图(Block Bitmap)](#块位图(Block Bitmap))
[inode位图(Inode Bitmap)](#inode位图(Inode Bitmap))
[i节点表(Inode Table)](#i节点表(Inode Table))
[Data Block](#Data Block)
2、Linux系统下我们用的都是文件,但是文件名不在incode中,那么我们如何理解目录呢?
磁盘
磁盘的物理结构

磁盘的存储结构
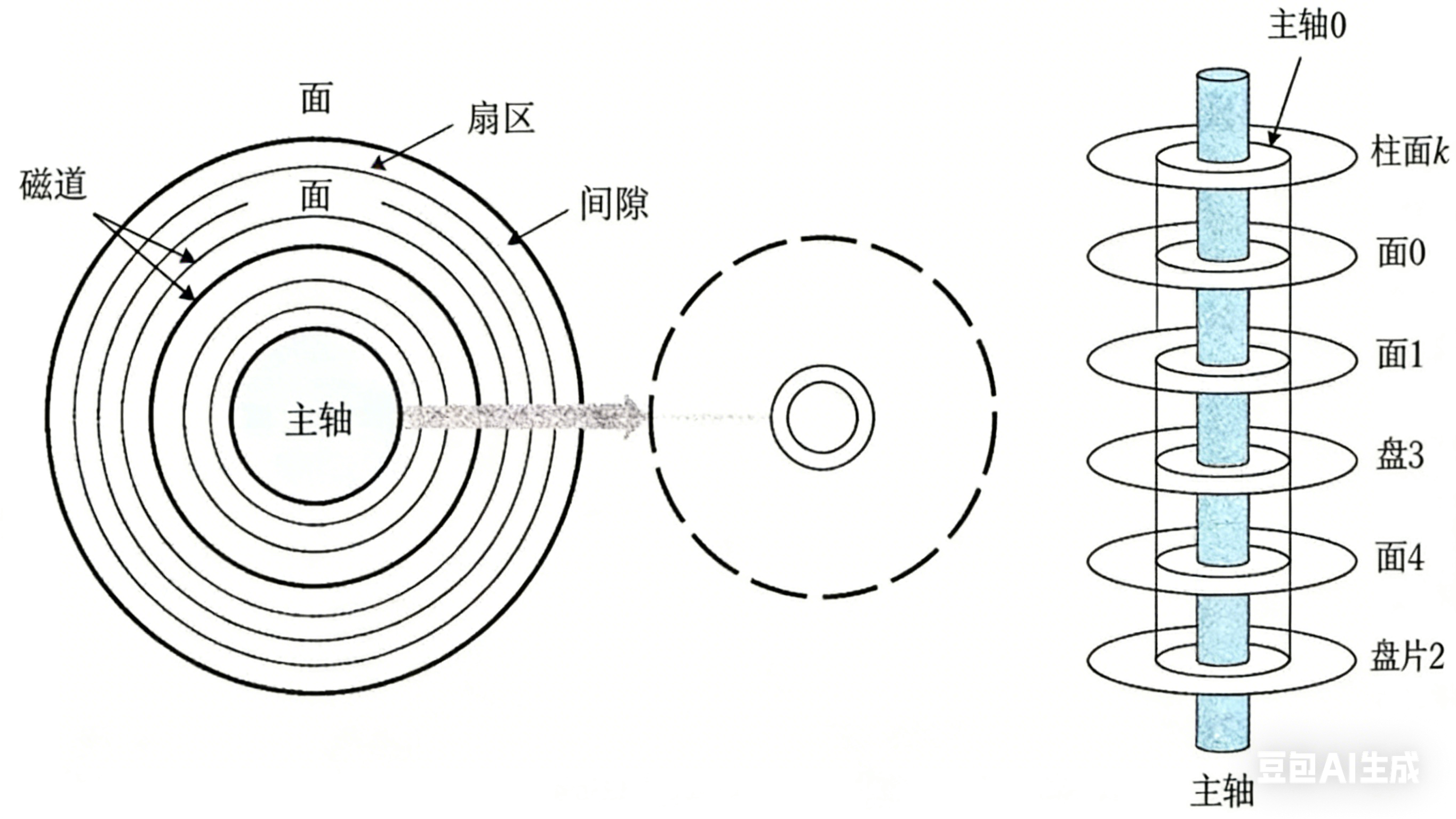
如何定位一个扇区呢 ?
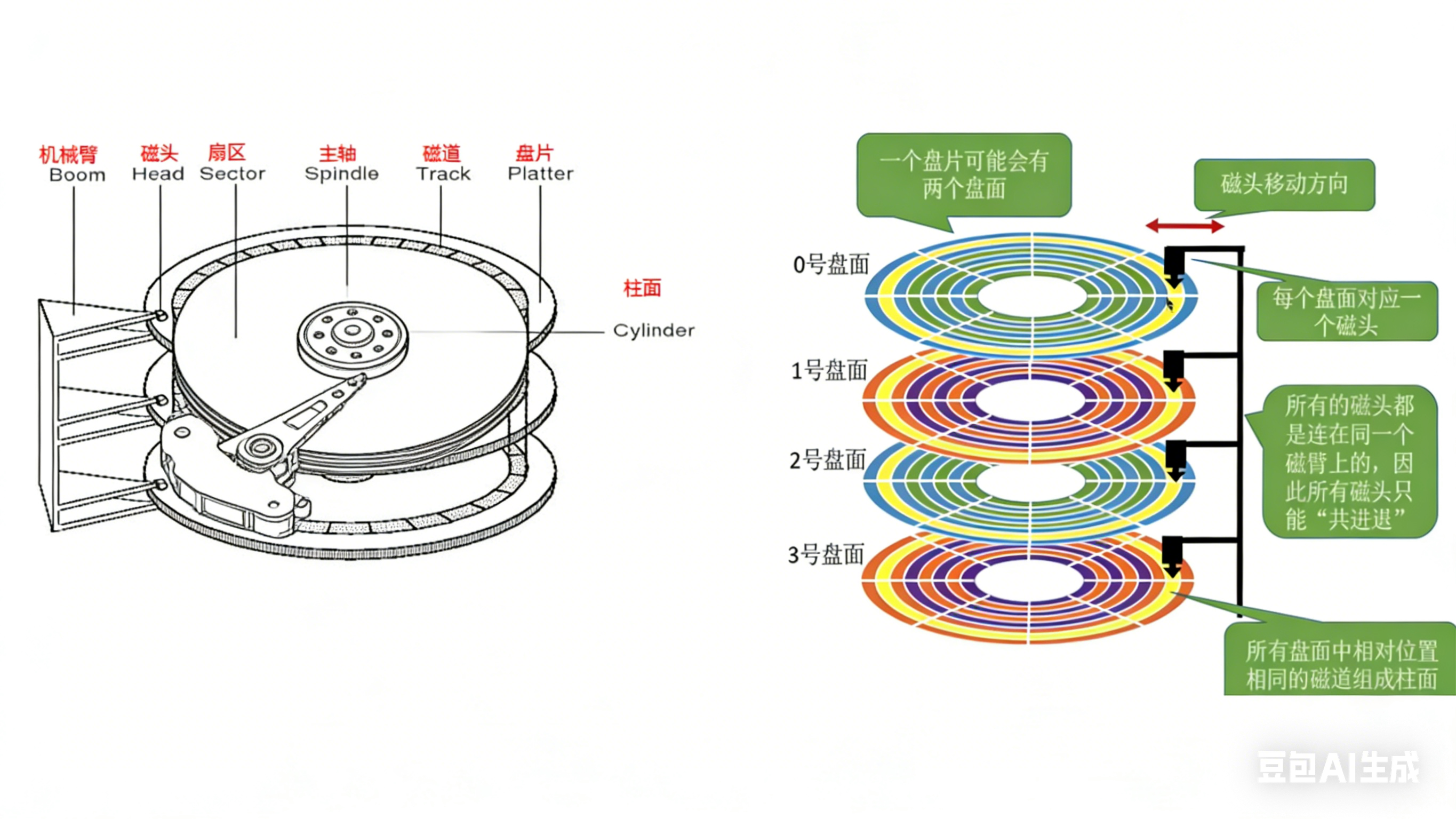
• 可以先定位磁头(header)
• 确定磁头要访问哪一个柱面(磁道)(cylinder)
• 定位一个扇区(sector)
这些部分共同构成了CHS地址,本质上是数组下标,通过CHS地址定位
文件 = 内容+属性。本质上都是数据,存储在扇区上。
扇区相关的知识补充
• 扇区是从磁盘读出和写入信息的最小单位,通常大小为 512 字节。
• 磁头(head)数:每个盘片一般有上下两面,分别对应1个磁头,共2个磁头
• 磁道(track)数:磁道是从盘片外圈往内圈编号0磁道,1磁道...,靠近主轴的同心圆用于停靠磁头,不存储数据
• 柱面(cylinder)数:磁道构成柱面,数量上等同于磁道个数
• 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
• 圆盘(platter)数:就是盘片的数量
• 磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
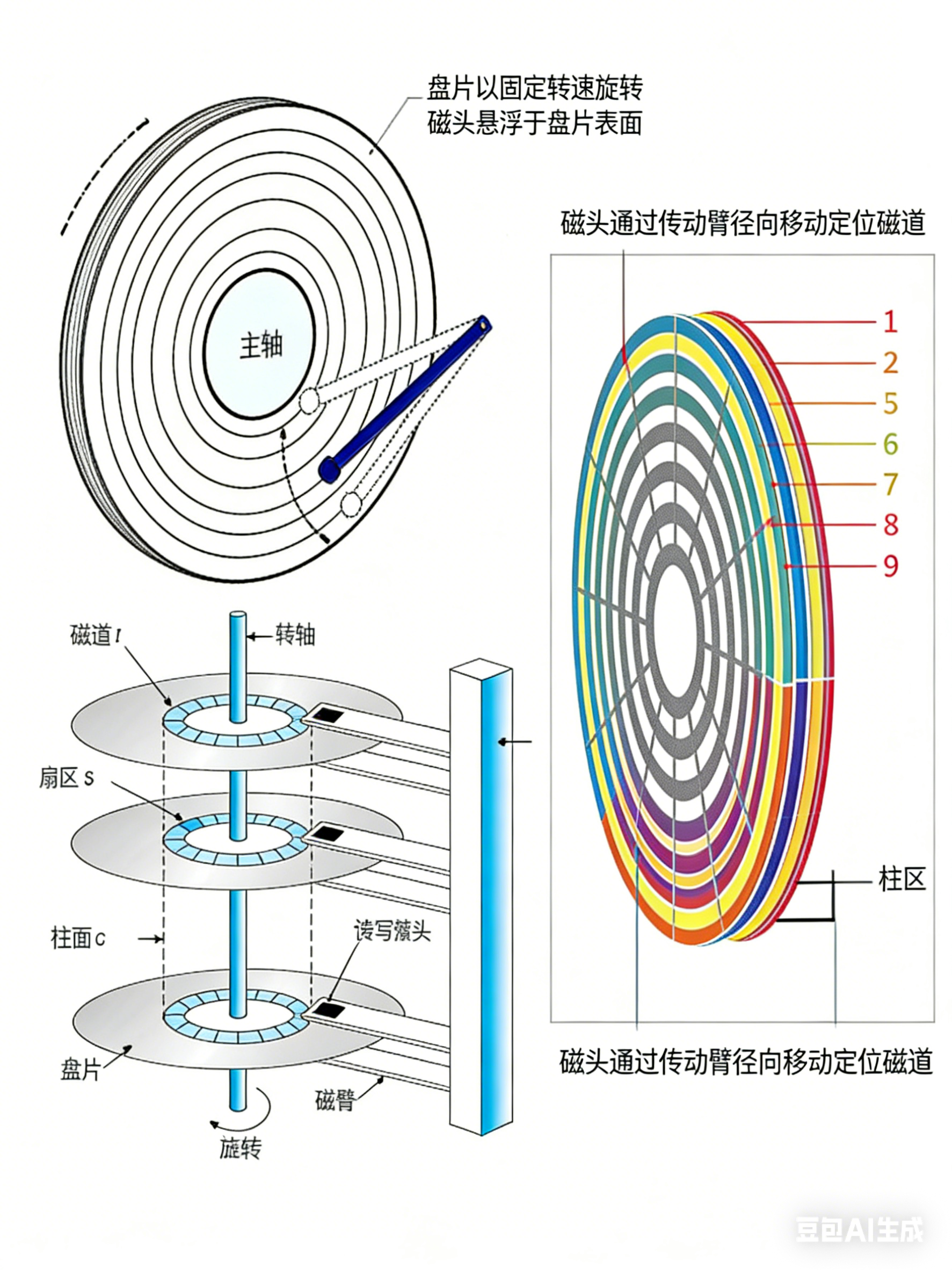
• 细节:传动臂上的磁头是共进退的(这点比较重要,后面会说明)
有了柱面(cylinder),磁头(head),扇区(sector)显然可以定位数据了,这就是数据定位(寻址)方式之一,CHS寻址方式。
CHS寻址
对早期的磁盘非常有效,知道用哪个磁头,读取哪个柱面上的第几扇区就可以读到数据了。
但是CHS模式支持的硬盘容量有限,因为系统用8bit来存储磁头地址,用10bit来存储柱面地址,用6bit来存储扇区地址,而一个扇区共有512Byte,这样使用CHS寻址一块硬盘最大容量为256 * 1024 * 63 * 512B = 8064 MB(1MB = 1048576B)(若按1MB=1000000B来算就是8.4GB)
磁盘的逻辑结构
磁道:
某一盘面沿某一磁道展开
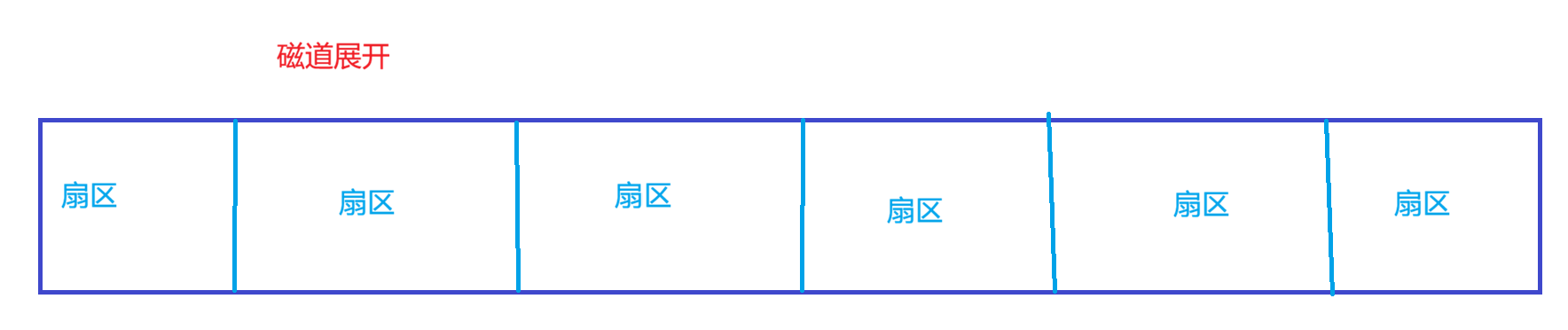
本质上就是一维数组
柱面:
整个磁盘所有盘面的同一个磁道
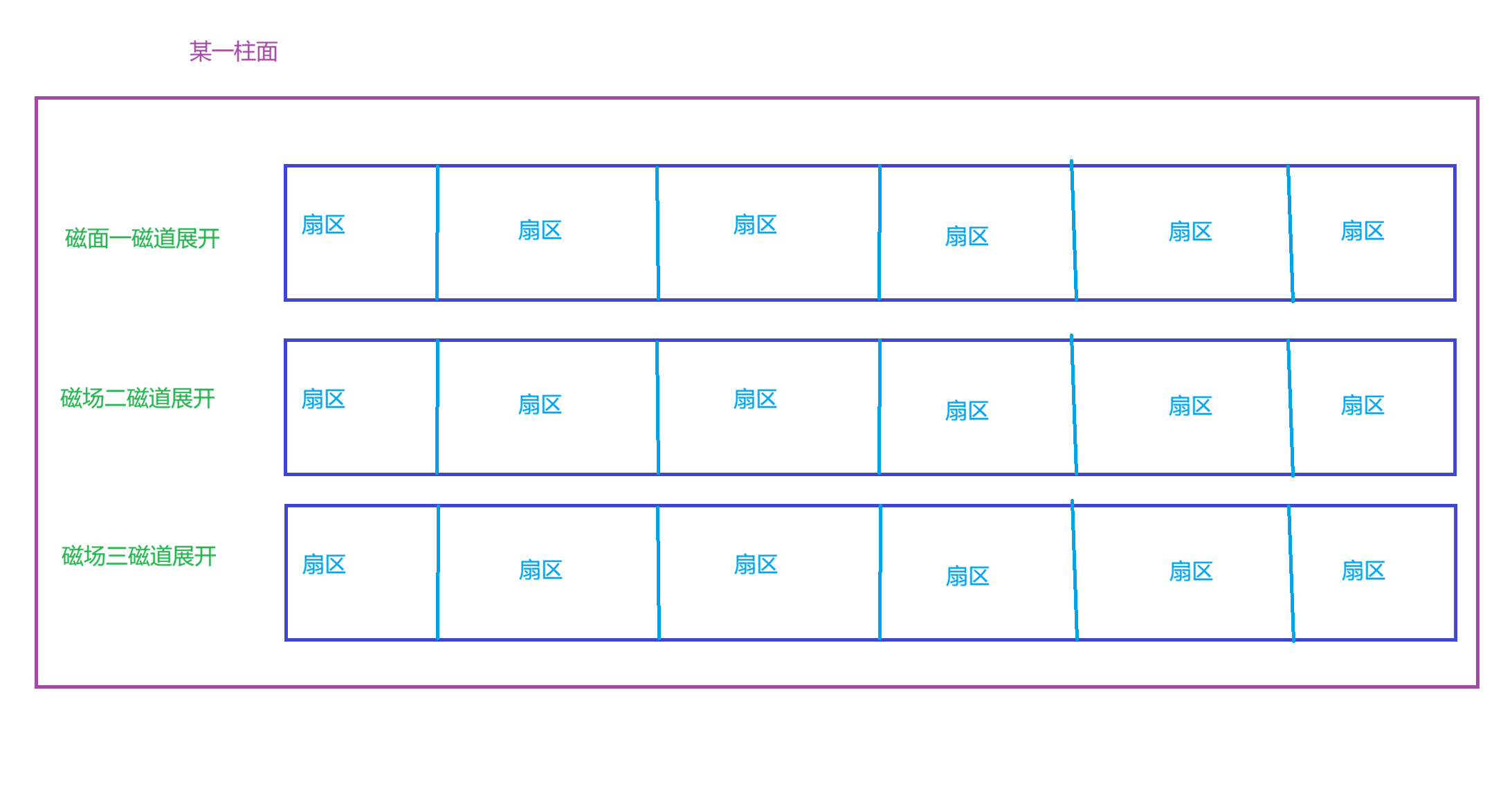
本质上是二维数组,且柱面上的每个磁道,扇区个数是⼀样的
整盘:
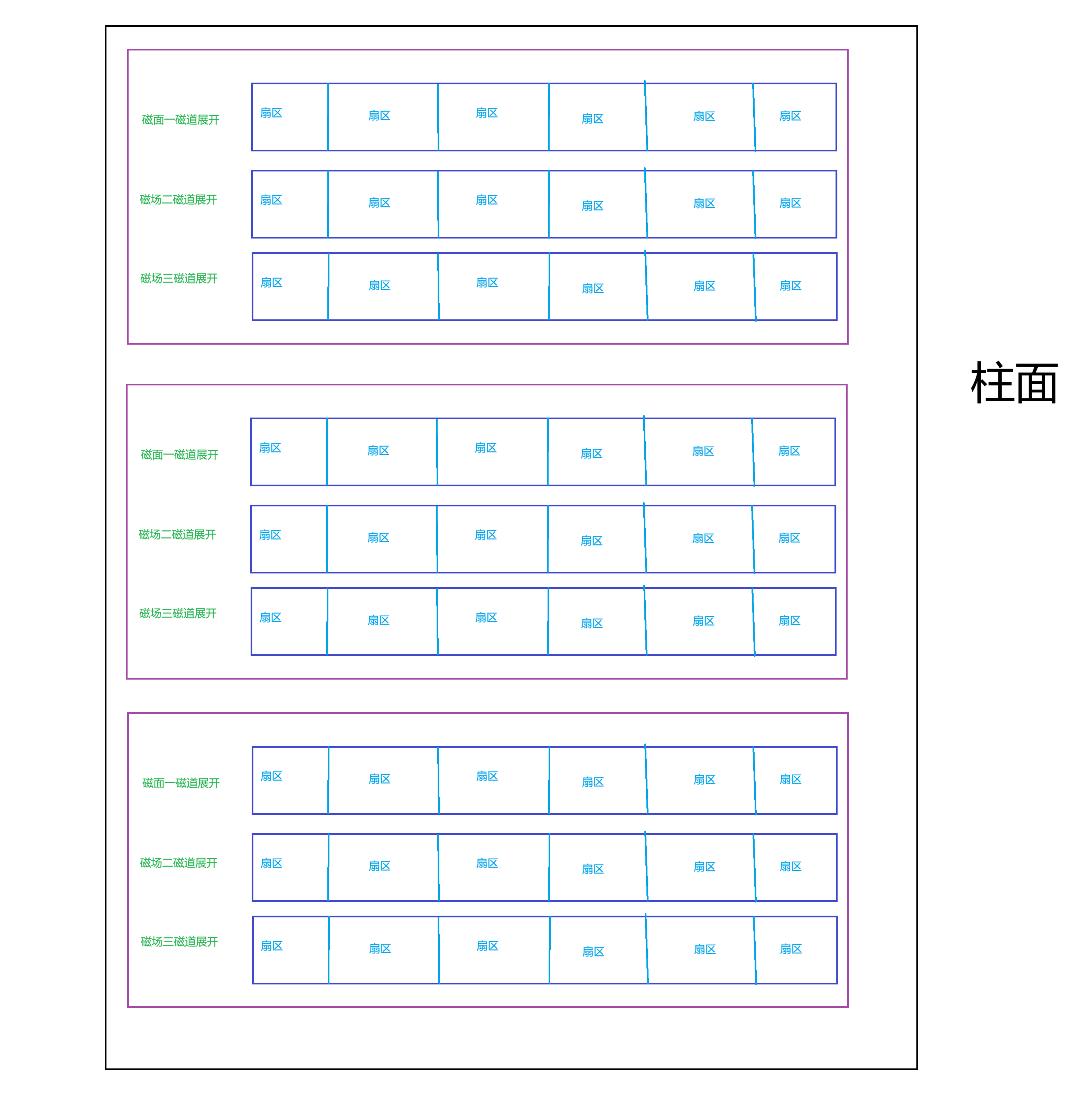
所以,每⼀个扇区都有⼀个下标,我们叫做LBA(Logical Block Address)地址,本质上是线性地址。
那么我们该如何得到这个LBA地址呢?通过CHS地址。OS只需要LBA地址,而CHS地址转化为LBA地址由磁盘自己去执行
CHS地址和LBA地址
CHS转成LBA:
• 磁头数 * 每磁道扇区数 = 单个柱面的扇区总数
•LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S - 1
即:LBA = 柱面号C * (磁头数 * 每磁道扇区数) + 磁头号H * 每磁道扇区数 + 扇区号S - 1
• 扇区号通常是从1开始的,而在LBA中,地址是从0开始的
• 柱面和磁道都是从0开始编号的
• 总柱面,磁道个数,扇区总数等信息,在磁盘内部会自动维护,上层开机的时候,会获取到这些参数。
LBA转成CHS:
本质上是一维数组下标转化为三维数组下标
需要以下:
• 柱面号C = LBA // (磁头数 * 每磁道扇区数) 【就是单个柱面的扇区总数】
• 磁头号H = (LBA % (磁头数 * 每磁道扇区数)) // 每磁道扇区数
• 扇区号S = (LBA % 每磁道扇区数) + 1
• "//": 表示除取整
磁盘就是一个元素为扇区的一维数组,数组的下标就是每一个扇区的LBA地址。OS使用磁盘,就可以用一个数字访问磁盘扇区了。
引入文件系统
引入"块"概念
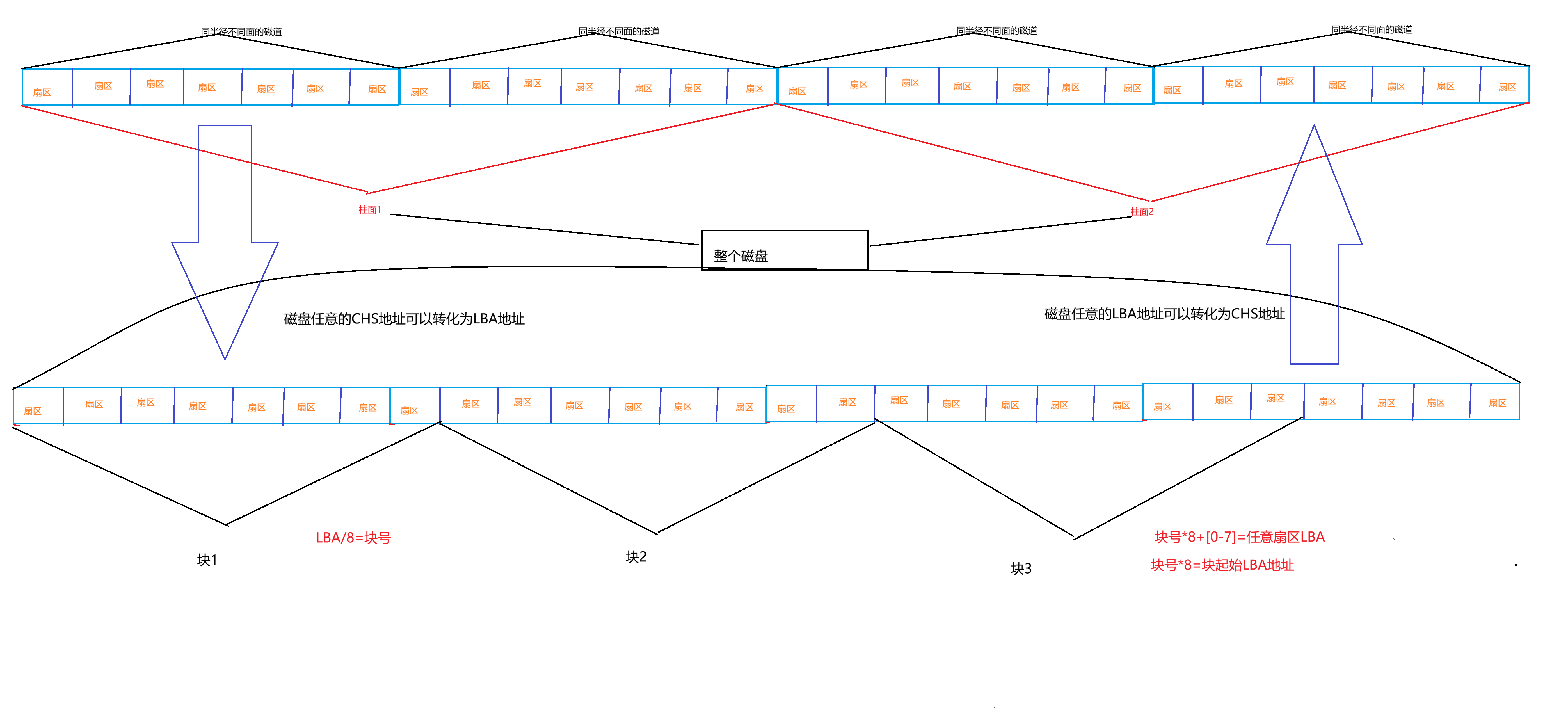
硬盘是典型的"块"设备,操作系统读取硬盘数据的时候,其实是不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。
硬盘的每个分区是被划分为一个个的"块"。一个"块"的大小是由格式化的时候确定的,并且不可以更改,最常见的是4KB ,即连续八个扇区组成一个 "块"。"块"是文件存取的最小单位。
注意:
• 磁盘就是一个三维数组,我们把它看待成为一个"一维数组",数组下标就是LBA,每个元素都是扇区
• 每个扇区都有LBA,那么8个扇区一个块,每一个块的地址我们也能算出来。
• 知道LBA:块号 = LBA/8
• 知道块号:LBA = 块号*8 + n. (n是块内第几个扇区)
可以按照如下图来理解:
引入"分区"概念
磁盘是可以被分成多个分区(partition)的。
以Windows观点来看,你可能会有一块磁盘并且将它分区成C、D、E盘。那个C、D、E就是分区。分区从实质上说就是对硬盘的一种格式化。
但是Linux的设备所有内容都是以文件形式存在,那是怎么分区的呢?
柱⾯是分区的最小单位,我们可以利⽤参考柱⾯号码的方式来进⾏分区,其本质就是设置每个区的起始柱⾯和结束柱⾯号码。 此时我们可以将硬盘上的柱⾯(分区)进⾏平铺,将其想象成⼀个大的平⾯
注意:柱面大小一致,扇区个数一致,那么其实只要知道每个分区的起始和结束柱面号,知道每一个柱面多少个扇区,那么该分区多大,其实和解释LBA是多少也就清楚了。
引入"linode"概念
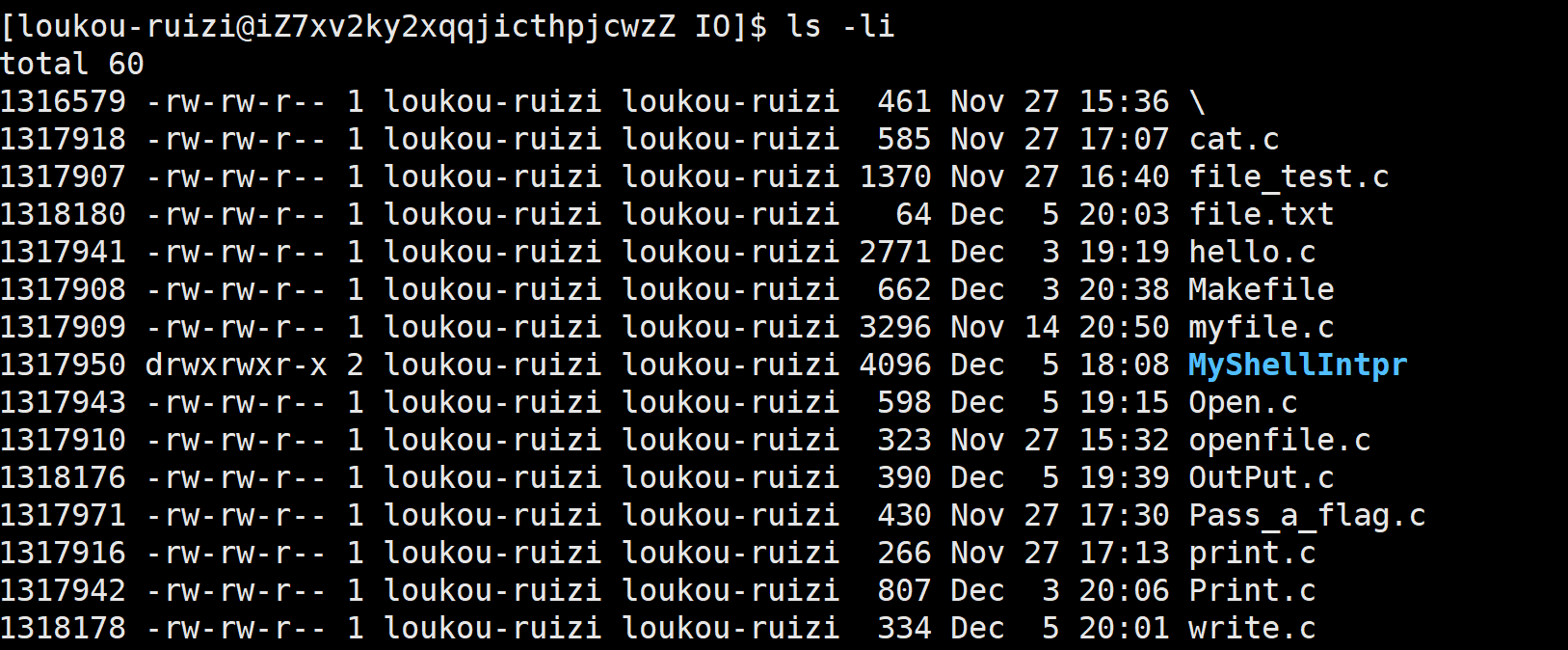
文件=数据+属性 ,我们使用 ls -l 的时候看到的除了看到文件名,还能看到文件元数据(属性)。
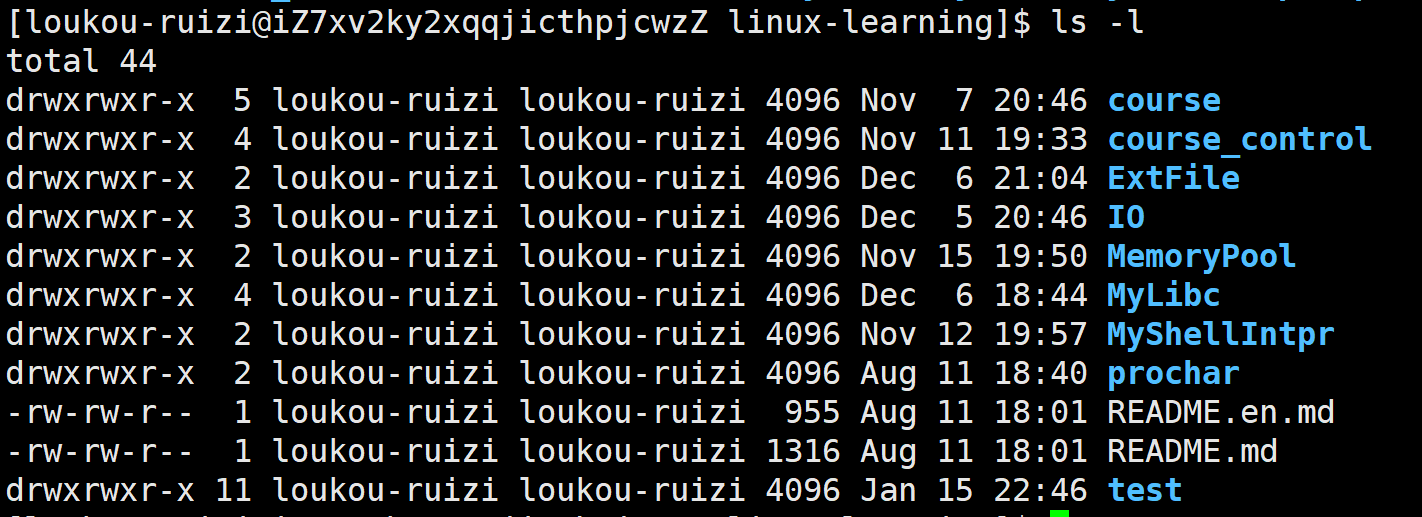
每行包含7列:
-
模式
-
硬链接数
-
文件所有者
-
组
-
大小
-
最后修改时间
-
文件名
ls -l读取存储在磁盘上的文件信息,然后显示出来
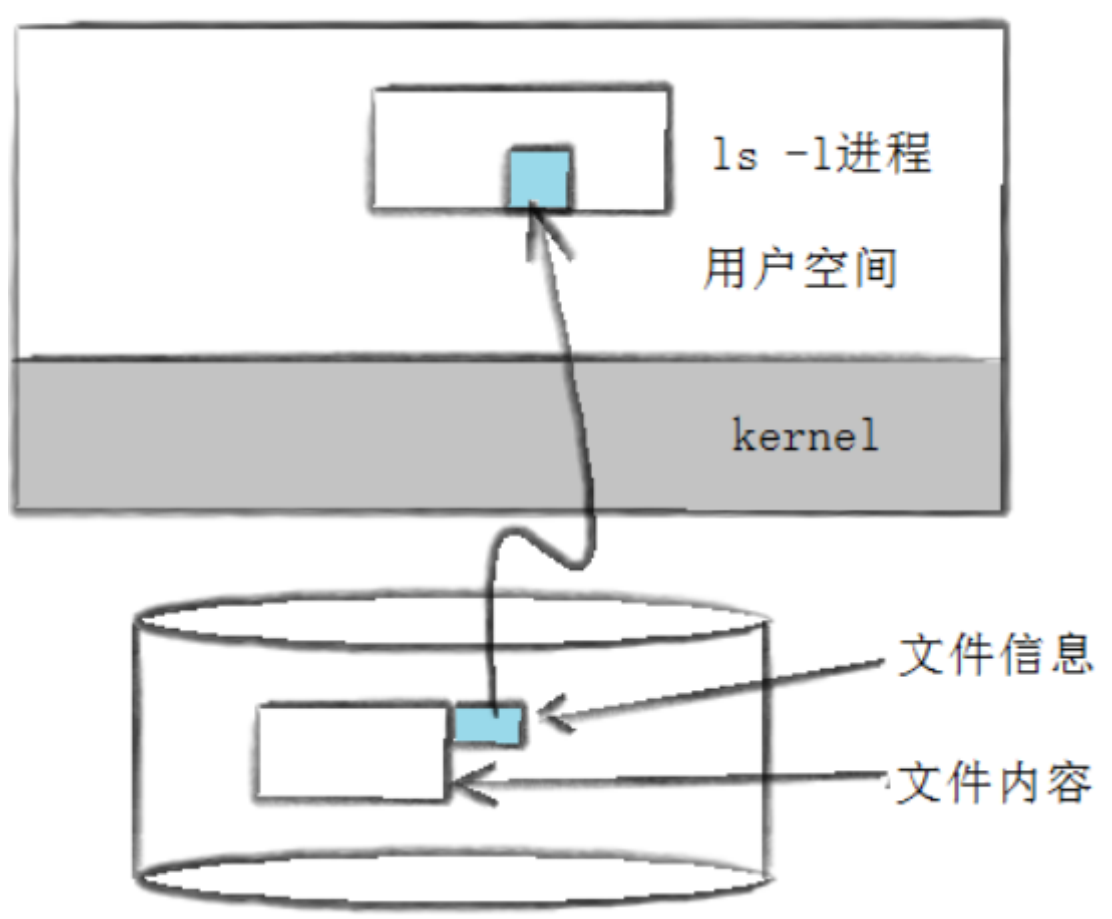
其实这个信息除了通过这种方式来读取,还有⼀个stat命令能够看到更多信息
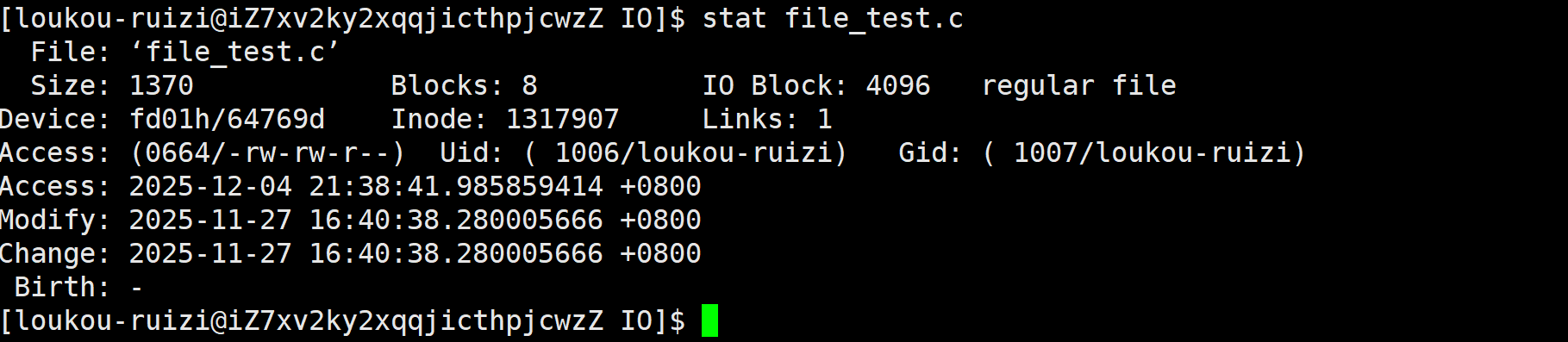
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息(属性信息),比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
注意:
Linux下文件的存储是属性和内容分离存储的
Linux下,保存文件属性的集合叫做inode,一个文件,一个inode,inode内有一个唯一的标识符,叫做inode号
Ext2文件系统
总体认识
我们想要在硬盘上存储文件,必须先把硬盘格式化为某种格式的文件系统,才能存储文件。文件系统的目的就是组织和管理硬盘中的文件。
在 Linux 系统中,最常见的是 ext2 系列的文件系统。其早期版本为 ext2,后来又发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进行了增强,但是其核心设计并没有发生变化
ext2文件系统将整个分区划分成若干个同样大小的块组 (Block Group),如下图所示。
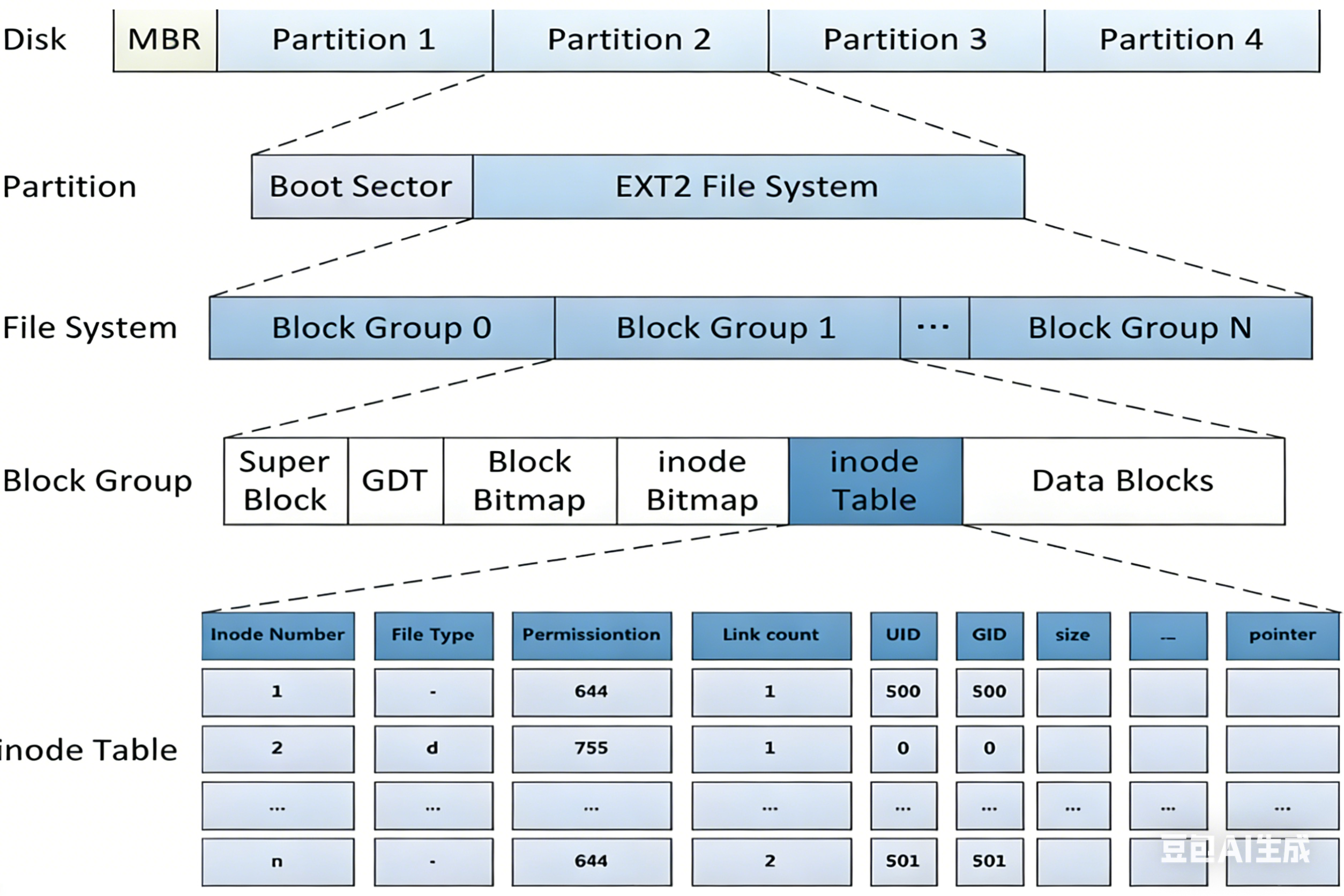
文件=文件内容+文件属性。在Linux系统中两者是分开存储的。在一个组中应该包含文件数据和管理文件数据的信息
其中对于FIleSystem组,写入管理信息的过程就交错写入管理系统
文件数据存储于Block Group的Data Blocks中,管理文件的数据写入Inode Table左侧的部分。每一个DataBlocks都有唯一的编号,Incode中存储的是文件的属性。
所以文件=DataBlock+Incode。一个文件对应一个Incode。
在一个分组内,找到一个文件需要先找到它的IncodeNumber,根据它找到Incode,依此找到I_Block\[\]数组,在数组中找到对应的DataBlock。
Block Group
ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。
块组内部组成
超级块(Super Block)
存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:block 和 inode 的总量,未使用的 block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。
Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了。
超级块在每个块组的开头都有一份拷贝(第一个块组必须有,后面的块组可以没有)。为了保证文件系统在磁盘部分扇区出现物理问题的情况下还能正常工作,就必须保证文件系统的 super block 信息在这种情况下也能正常访问。所以一个文件系统的 super block 会在多个 block group 中进行备份,这些 super block 区域的数据保持一致。
GDT(Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储一个块组的描述信息,如在这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
块位图(Block Bitmap)
• Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
inode位图(Inode Bitmap)
• 每个bit表示一个inode是否空闲可用。
i节点表(Inode Table)
• 存放文件属性 如 文件大小,所有者,最近修改时间等
• 当前分组所有Inode属性的集合
• inode编号以分区为单位,整体划分,不可跨分区
Data Block
数据区 :存放文件内容,也就是一个一个的Block。根据不同的文件类型有以下几种情况:
• 对于普通文件,文件的数据存储在数据块中。
• 对于目录,该目录下的所有文件名和目录名存储在所在目录的数据块中,除了文件名外,ls -l命令看到的其它信息保存在该文件的inode中。
• Block 号按照分区划分,不可跨分区
inode和datablock映射(弱化)
inode内部存在 __le32 i_blockEXT2_N_BLOCKS;/* Pointers to blocks */ , EXT2_N_BLOCKS =15,就是用来进行inode和block映射的
这样文件=内容+属性,就都能找到了。
块号是分区唯一,不是组内wei'yi
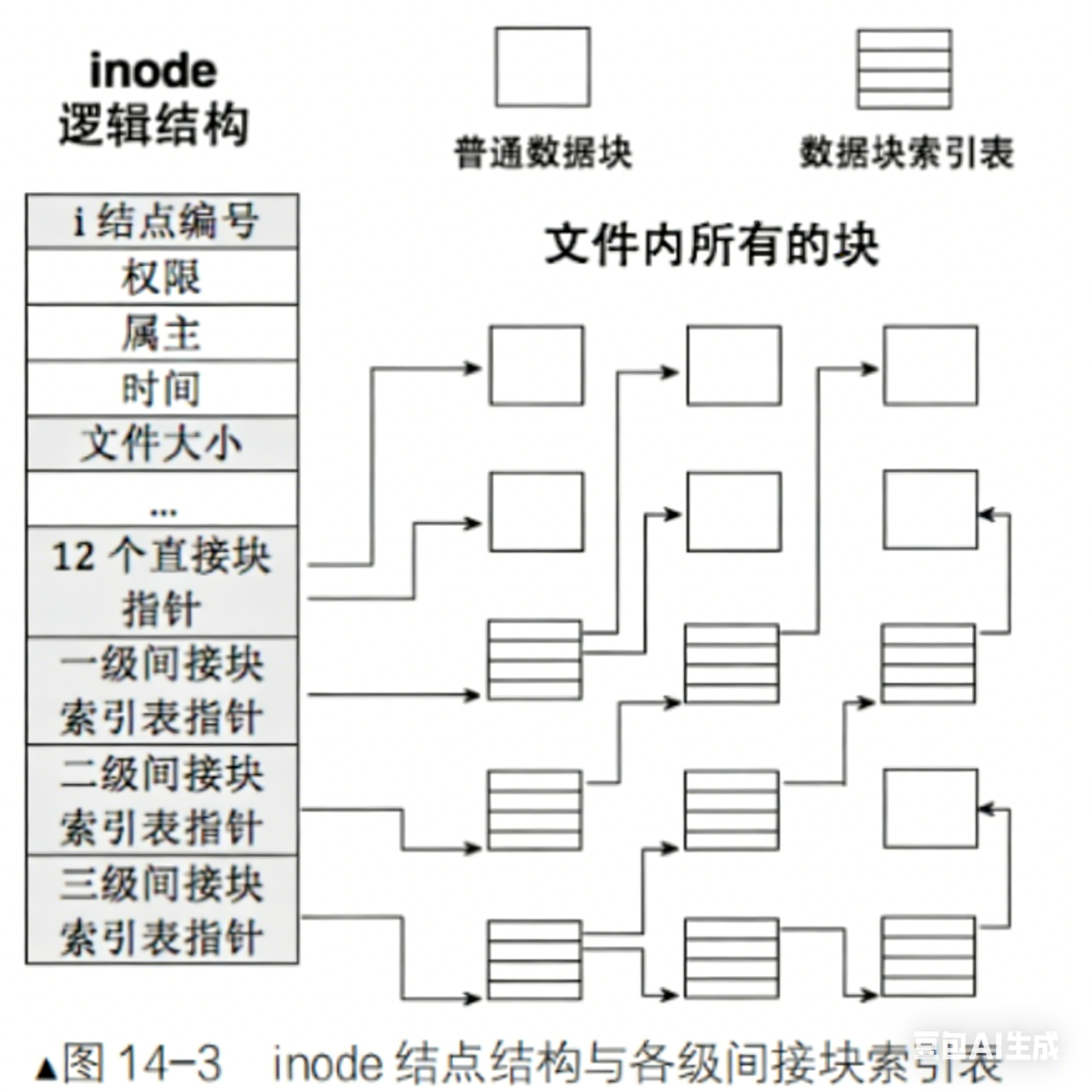
Incode
从文件的Incode编号探讨
1、如何理解文件的增加、删除、修改、查询?
Linux系统下可以通过ls命令的选项i对文件及其目录的Incode进行查询。
如下图所示
第二个指令可以简写为
bash
ls -li第二行显示出来的最前列的数字就是文件对应的Incode
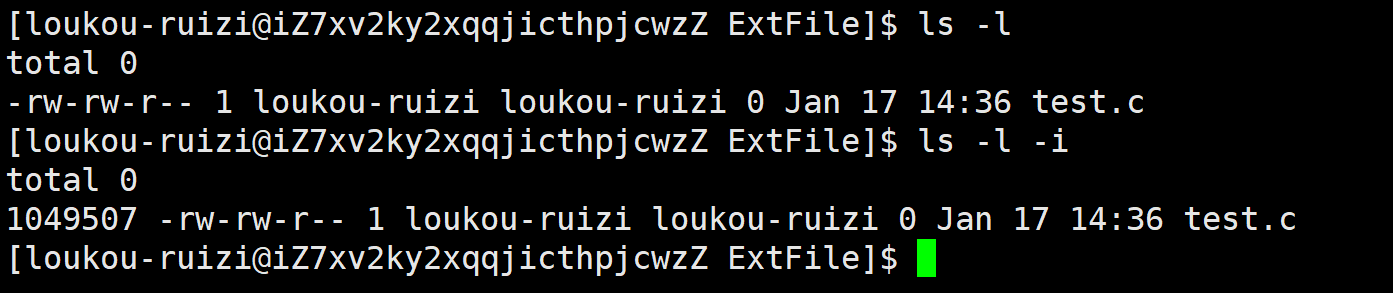
通过ls-ld,我们可以对目录只显示根目录

根目录也是有Incode的

内存创建文件的时候,要先将文件对应的各种信息创建好,在IncodeMap中查询对应的数据块,将其加载到内存中,在IncodeMap中找到比特位为0的位置,通过位运算找到了对应的位置,从内存中加载回IncodeTable。
创建一个新文件主要有以下4个操作:
-
存储属性
内核先找到一个空闲的i节点(这里是263466)。内核把文件信息记录到其中。
-
存储数据
该文件需要存储在三个磁盘块,内核找到了三个空闲块:300, 500, 800。将内核缓冲区的第一块数据复制到300,下一块复制到500,以此类推。
-
记录分配情况
文件内容按顺序300, 500, 800存放。内核在inode上的磁盘分布区记录了上述块列表。
-
添加文件名到目录
新的文件名
abc。Linux如何在当前的目录中记录这个文件?内核将入口(263466,abc)添加到目录文件。文件名和inode之间的对应关系将文件名和文件的内容及属性连接起来。
因此创建文件的时候就是先查找对应的Incode编号创建,删除也是根据Incode编号删除。
修改文件是将文件加载到内存中,根据Incode编号查找到对应的属性,对其进行读改写。
查看文件也是依赖于Incode编号去IncodeMap中找到。
2、Linux系统下我们用的都是文件,但是文件名不在incode中,那么我们如何理解目录呢?
Linux系统下一切皆文件,对于目录来说也是如此,当前目录的文件名和Incode映射表就会被保存在一个数据块内。在磁盘和文件系统角度而言,存储目录和存储文件没有本质区别。
目录内保存的是当前目录下的文件名和Incode映射关系。
以下代码可以对当前目录的文件进行查阅
cpp
#include <dirent.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 系统调用,自行查阅
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 系统调用,自行查阅
// 跳过 "." 和 ".." 目录条目
if (strcmp(entry->d_name, ".") == 0 ||
strcmp(entry->d_name, "..") == 0) {
continue;
}
printf("Filename: %s, Inode: %lu\n",
entry->d_name,
(unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}3、重谈Incode编号
incode编号和块号不是组内有效,而是整个分区都有效。
一个文件系统内部和一个分区内部有多少Incode多少数据块都是提前设计好的。
如果要访问当面目录的数据块,
路径解析
首先要找到当前目录的incode编号。查找目录的过程是递归的,就像下面这样逐层递进地查找。

当我们想访问文件的时候,Linux的内核都会从/开始解析路径。同时Linux系统对你访问/打开过的所有路径节点都要先描述再组织
可是路径谁提供?
• 你访问文件,都是指令/工具访问,本质是进程访问,进程有 CWD!进程提供路径。
• 你 open 文件,提供了路径
可是最开始的路径从哪里来?
• 所以 Linux 为什么要有根目录,根目录下为什么要有那么多缺省目录?
• 你为什么要有家目录,你自己可以新建目录?
• 上面所有行为:本质就是在磁盘文件系统中,新建目录文件。而你新建的任何文件,都在你或者系统指定的目录下新建,这不就是天然就有路径了嘛!
• 系统 + 用户共同构建 Linux 路径结构。
路径缓存
问题1:Linux磁盘中,存在真正的目录吗?
答案:不存在,只有文件。只保存文件属性+文件内容
问题2:访问任何文件,都要从/目录开始进行路径解析?
答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题3:Linux目录的概念,怎么产生的?
答案:打开的文件是目录的话,由OS自己在内存中进行路径维护
1、目录的多叉树是动态变化的。
2、不是只有目录才有dentry,每一个被访问的文件都有dentry
3、搜索的时候第一次比较缓慢,第二次就比较快了,这是因为路上路径被缓存的
对于目录的查找本质上是深度优先遍历。
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
cpp
struct dentry {
atomic_t d_count;
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
struct inode *d_inode; /* Where the name belongs to - NULL is negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
#ifdef CONFIG_PROFILING
struct dcookie_struct *d_cookie; /* cookie, if any */
#endif
int d_mounted;
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};注意:
每个文件其实都要有对应的 dentry 结构,包括普通文件。这样所有被打开的文件,就可以在内存中形成整个树形结构。
整个树形节点也同时会隶属于 LRU(Least Recently Used,最近最少使用)结构中,进行节点淘汰。
整个树形节点也同时会隶属于 Hash,方便快速查找。
更重要的是,这个树形结构,整体构成了 Linux 的路径缓存结构。打开访问任何文件,都会先在这棵树下根据路径进行查找,找到就返回属性 inode 和内容;没找到就从磁盘加载路径,添加 dentry 结构,缓存新路径。
访问任何文件Linux内核都是先做路径解析和路径缓存的!
挂载分区
我们已经能够根据inode号在指定分区找文件了,也已经能根据目录文件内容,找指定的inode了。
但是目前有以下几个问题
1、如何知道自己在哪个文件系统?
我们在查找这个过程中的顺序为:磁盘-》分区-》格式化
格式化本质上在分组写入管理信息
2、分区格式化后这个文件系统或分区可以被直接使用吗?
不能,需要把文件系统或分区挂载到指定的目录下。
通过如下指令,我们发现我们目前只有一块盘/dev/vda

那么我们该如何证明呢?
我们首先通过以下指令创建一个5块1M大小名字为TEST的分区

通过以下方式格式化
建立空目录
查看可以使用的分区 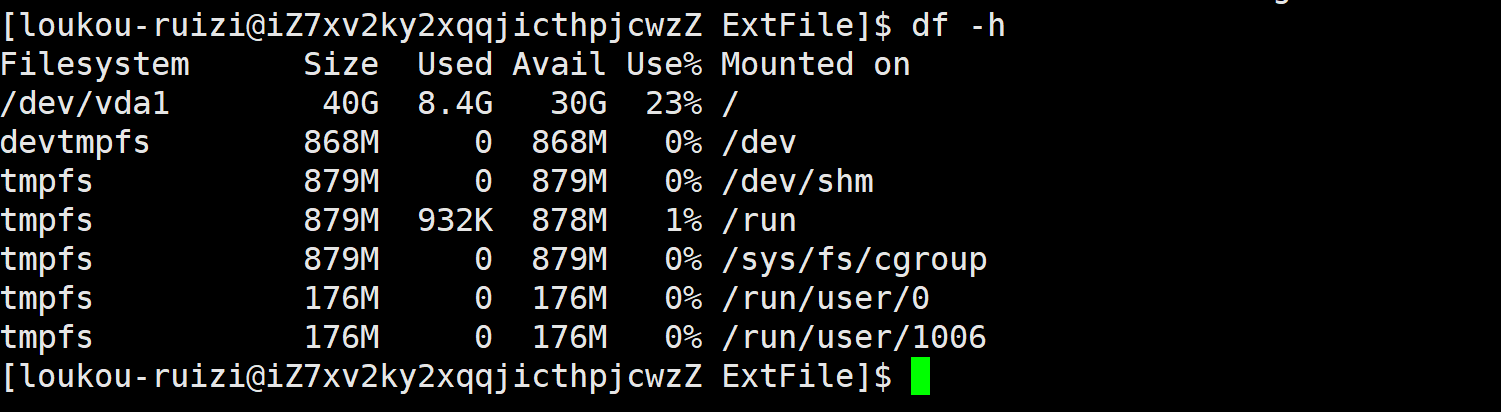
使用以下命令可以将分区挂载到指定的目录上
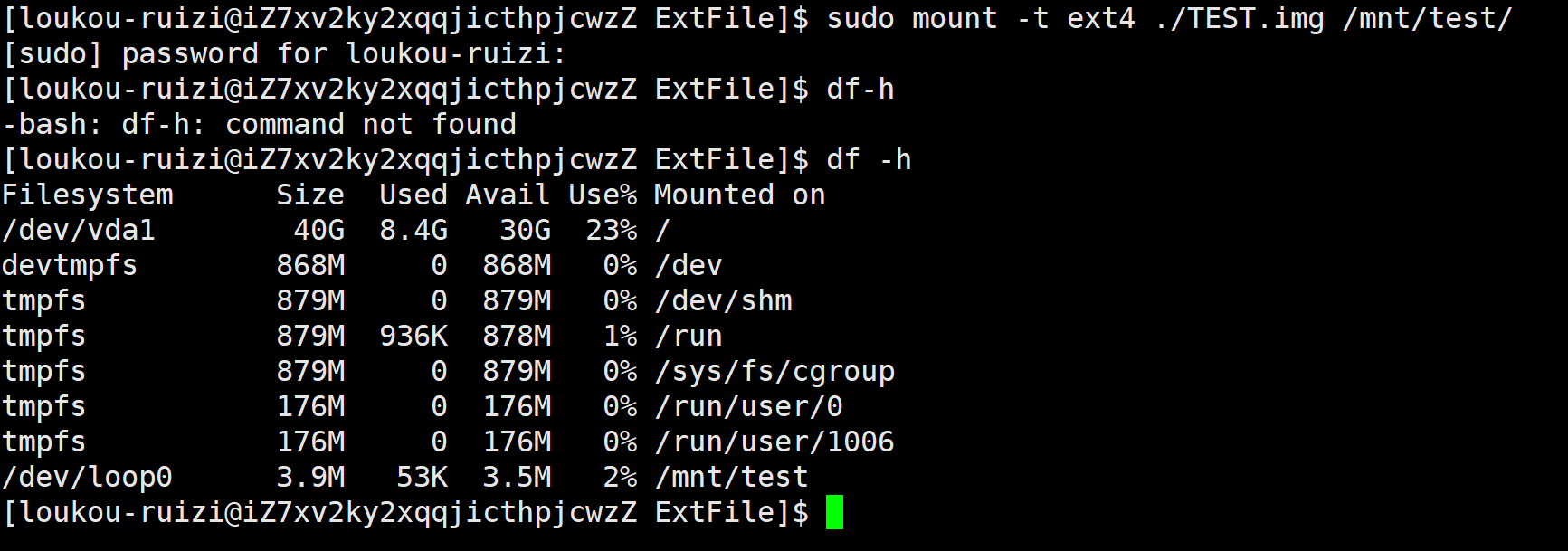
卸载分区(第二次使用ls查询到的是普通的目录不再是分区的挂载点)

因此我们就知道了我们的文件在哪个操作系统中了,是因为我们访问的文件都是携带路径的,可以根据路径查找到对应的文件
结论
• 分区写入文件系统后无法直接使用,需要与指定的目录关联,进行挂载才能使用。
• 因此,可以根据访问目标文件的"路径前缀"准确判断文件位于哪一个分区。
软硬连接
硬连接
Linux系统中磁盘找的不是文件名而是incode。而Linux系统下可以让多个文件从属于同一个incode
下面我们演示一下,先创建一个文件。
我们可以通过ln命令进行硬链接。可以看下图的incode编号。而incode编号后面的数字代表着硬连接数。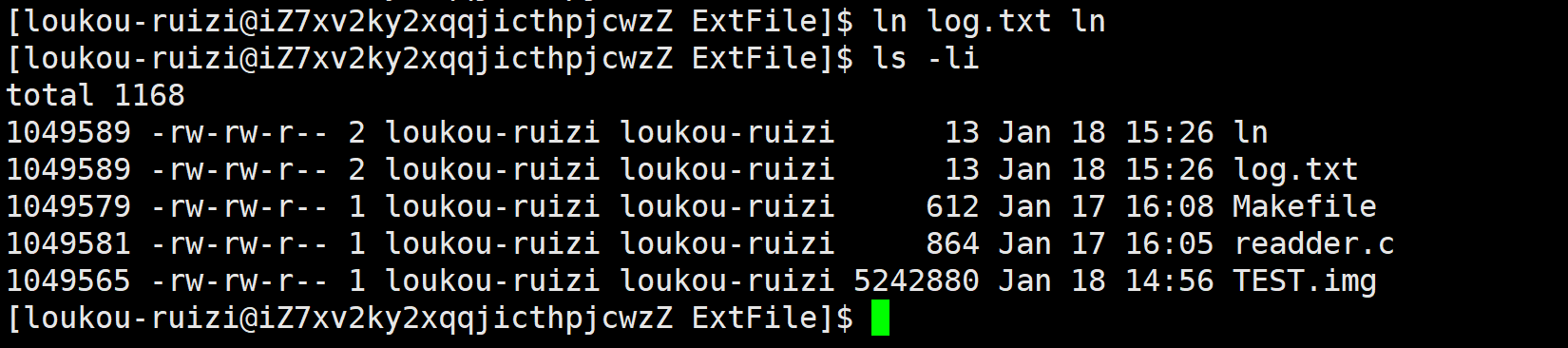
ln和log.txt本质上是一个文件(因为一个文件一个incode)
因此硬连接的本质上在当前目录下建立一个新的字符串(文件名)与目标文件的映射关系。
但是当前目录下文件名具备唯一性。因此硬连接可以实现一个字符串级别的轻量化文件备份方案
如图所示,Linux的目录中的**.** 和**..**本质上也是硬连接
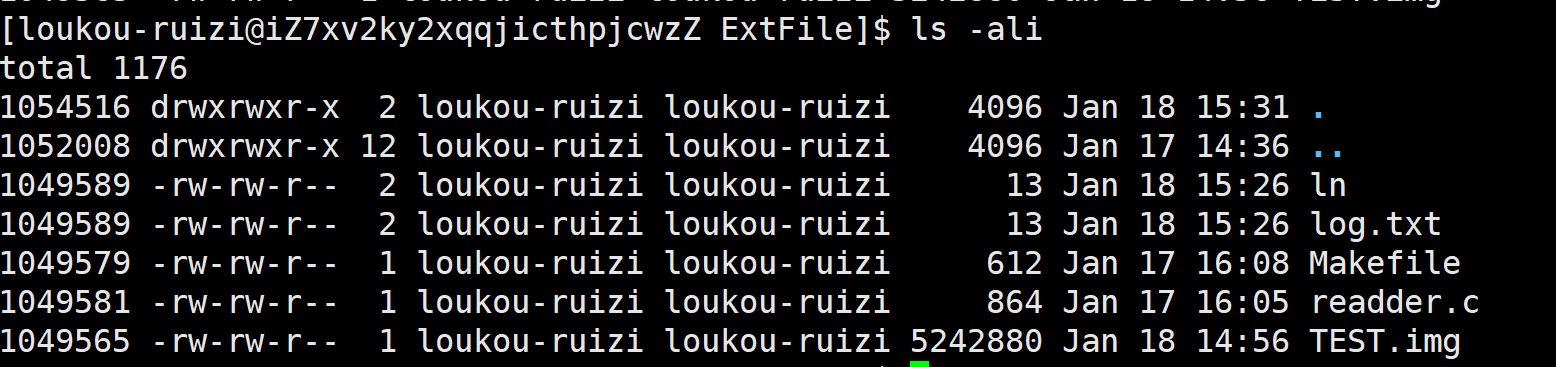
因此我们可以根据硬连接数判断目录中有多少个目录,为硬连接数-2
同时我们在删除文件时磁盘干了两件事情:1. 在目录中将对应的记录删除,2. 将硬连接数-1,如果为0,则将对应的磁盘释放。
软连接
硬连接是通过inode引用另外一个文件,软链接是通过名字引用另外一个文件,但实际上,新的文件和被引用的文件的inode不同,应用常见上可以想象成一个快捷方式。
所以软连接本质上是一个独立的文件,保存的是指向目标文件的路径
举例说明:当我们写项目的时候遇到如图所示的情况,运行文件在bin目录,配置文件在conf目录,日志文件在log目录。
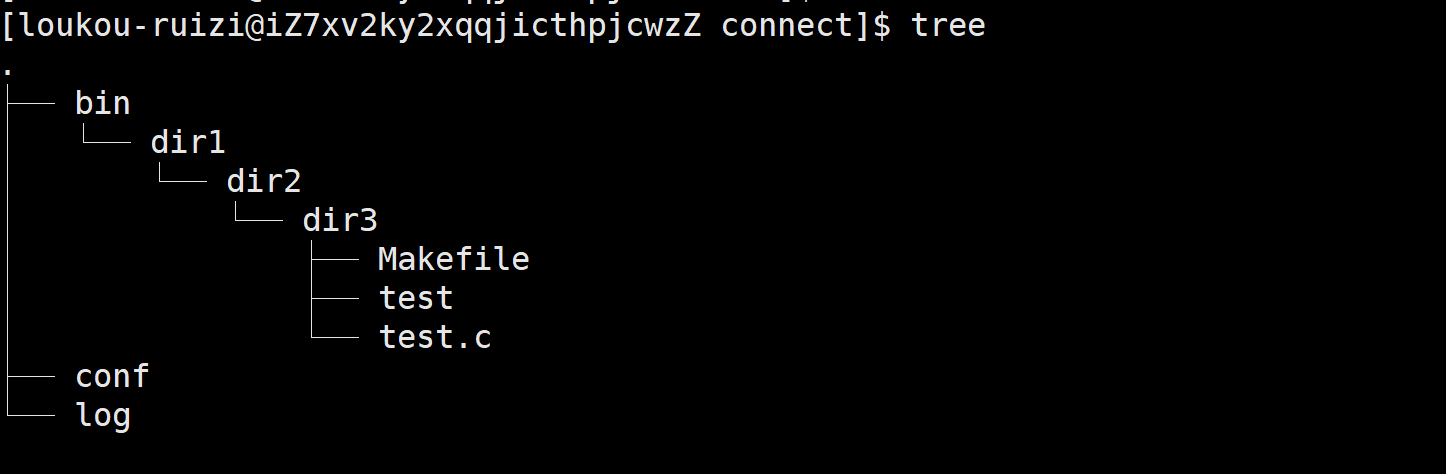
如果我们要编译dir3的文件显然是比较麻烦的

于是我们可以利用软连接进行简化。利用如图所示的指令简化后可以直接对软连接编译。
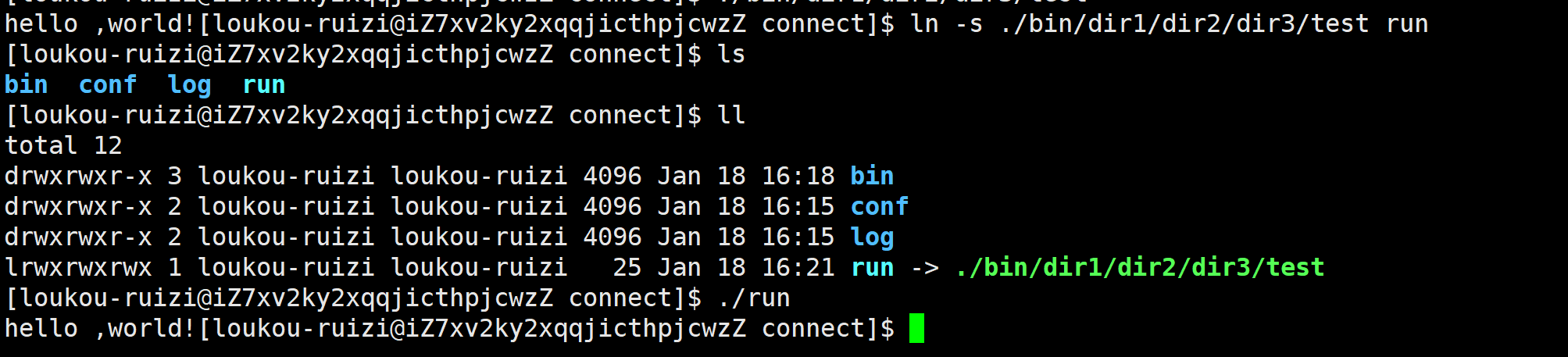
软连接类似于Windows下的快捷方式。
软连接与硬连接对比
| 特性 | 软连接(符号链接) | 硬连接 |
|---|---|---|
| 本质 | 一个特殊的文件,包含指向目标文件的路径 | 与源文件共享相同的inode和数据块 |
| inode编号 | 有自己的inode编号(与源文件不同) | 与源文件相同的inode编号 |
| 跨文件系统 | ✅ 支持(可链接不同文件系统的文件) | ❌ 不支持(必须在同一文件系统) |
| 链接目录 | ✅ 支持 | ❌ 不支持(普通用户),仅root可创建 |
| 原始文件删除 | 链接会失效(成为"死链接") | 链接仍然有效(直到所有硬链接被删除) |
| 文件大小 | 很小(仅存储路径信息) | 与源文件大小相同(共享数据块) |
| 创建命令 | ln -s 源文件 链接名 |
ln 源文件 链接名 |
| 文件类型 | 类型为 l(符号链接) |
与源文件类型相同 |
| 权限 | 777(实际权限由目标文件决定) | 与源文件权限相同(共享inode) |
| 修改时间 | 链接创建/修改时间 | 文件的最后修改时间 |
| ls显示 | lrwxrwxrwx |
与普通文件相同 |
| 占用空间 | 少量(路径字符串) | 不额外占用数据块空间 |
| 链接数变化 | 不影响源文件链接计数 | 增加源文件链接计数 |
主要用途对比
| 用途场景 | 软连接使用 | 硬连接使用 |
|---|---|---|
| 快捷方式 | ✅ 最佳选择(类似Windows快捷方式) | ❌ 不适用 |
| 跨磁盘链接 | ✅ 链接不同分区/磁盘的文件 | ❌ 无法实现 |
| 目录快捷方式 | ✅ 创建目录别名 | ❌ 不建议使用 |
| 版本管理 | ✅ 常用于软件版本切换(如python3→python3.9) | ❌ 不适用 |
| 库文件管理 | ✅ 共享库版本链接(libxxx.so→libxxx.so.1.0) | ❌ 不适用 |
| 备份保护 | ❌ 源文件删除则链接失效 | ✅ 防止误删(多个入口) |
| 节省空间 | ❌ 不节省数据空间 | ✅ 同一数据多个引用,节省空间 |
| 配置文件 | ✅ 链接配置文件到标准位置 | ✅ 多个位置访问同一配置文件 |
本期内容到这里就结束了,喜欢请点个赞谢谢
封面图自取:
