此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课的第二周内容,2.4到2.5的内容以及一些相关知识的补充。
本周为第五课的第二周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP) 。
应用在深度学习里,它是专门用来进行文本与序列信息建模 的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次"结构化特化",也是人工智能中最贴近人类思维表达方式 的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样"直观可见",更多是抽象符号与上下文关系的组合,因此理解门槛反而更高 。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本周的内容关于词嵌入,是一种相对于独热编码,更能保留语义信息的文本编码方式 。通过词嵌入,模型不再只是"记住"词本身,而是能够基于语义关系进行泛化 ,在一定程度上实现类似"举一反三"的效果。词嵌入是 NLP 领域中最重要的基础技术之一。
本篇的内容关于词嵌入模型原理,是了解基础内容后的下一步引入。
1. 词嵌入矩阵
在上一篇中,我们知道通过词嵌入可以实现词汇的特征化表示,这种序列信息编码方式相比独热编码不仅节约了存储和时间成本,而且可以量化词汇的语义来提升模型性能。
那么要如何训练一个可以输出对词汇合适编码的词嵌入模型呢?
实际上,词嵌入模型的原理和我们之前介绍过的图像风格转换有些类似,就像其首先要随机初始化目标图像一样,词嵌入模型的第一步,并不是"理解语义",而是先给每个词一个可以被学习的数值载体 。
具体来说是这样的:
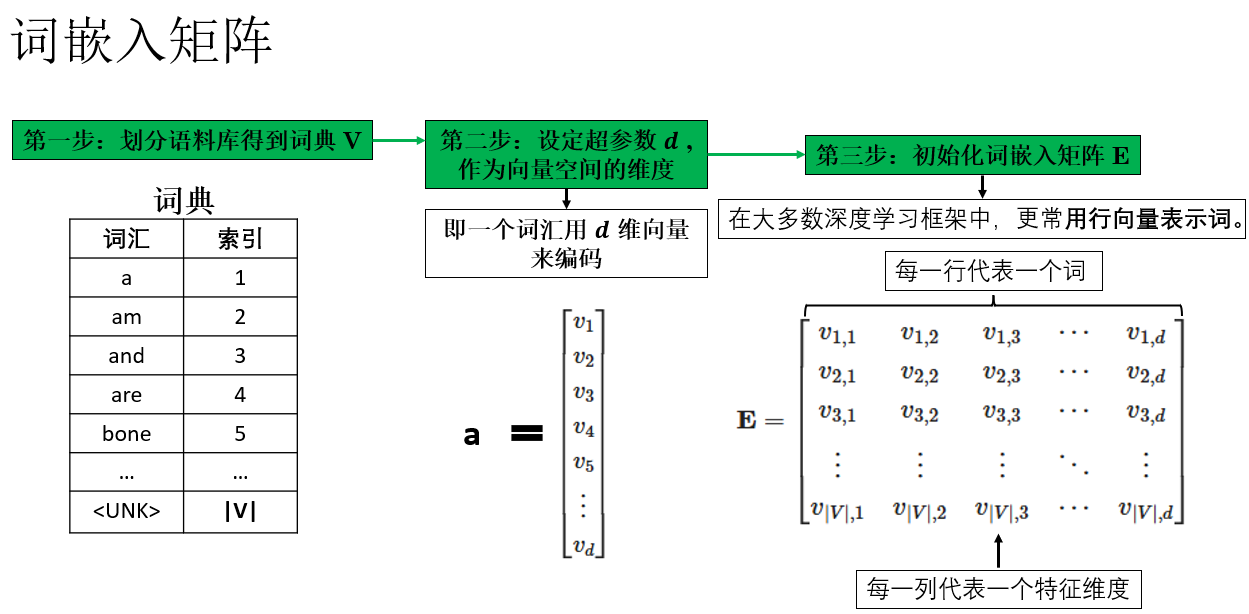
如图所示,假设我们的词表大小为 \(|V|\),词向量维度设为 \(d\),那么词嵌入本质上就是一个矩阵,每一行对应词表中的一个词,我们称之为词嵌入矩阵。
\\\mathbf{E} = \\begin{bmatrix} v_{1,1} \& v_{1,2} \& v_{1,3} \& \\cdots \& v_{1,d} \\\\ v_{2,1} \& v_{2,2} \& v_{2,3} \& \\cdots \& v_{2,d} \\\\ v_{3,1} \& v_{3,2} \& v_{3,3} \& \\cdots \& v_{3,d} \\\\ \\vdots \& \\vdots \& \\vdots \& \\ddots \& \\vdots \\\\ v_{\|V\|,1} \& v_{\|V\|,2} \& v_{\|V\|,3} \& \\cdots \& v_{\|V\|,d} \\end{bmatrix} \\
这里需要强调的是,在课程中,吴恩达老师常在词嵌入矩阵中使用列向量来表示词向量,以匹配矩阵乘法的约定。但在实际工程代码中,通常视作行向量(矩阵行对应词向量)。这只是约定问题 ,取决于实现方式:教学中列向量便于公式推导,代码中行向量更高效。了解后,根据场景选择即可。
回到正题,在模型初始化阶段,词嵌入矩阵并不包含任何语义信息 ,通常采用随机初始化,或者服从均值为 0 的正态分布。
我们之前就说过,词向量并不是我们手工设定的,而是在模型学习得到的,在我们完成词嵌入矩阵的初始化后,词嵌入模型的目的就是不断传播和优化词嵌入矩阵,得到对语义编码合理的词向量,从而进行下一步应用。
到这里就会发现,学习词嵌入矩阵的过程和图像风格转换的过程非常相似:一开始是随机噪声,但在损失函数的约束下,逐步学习得到结构化、有意义的结果。
在完成词嵌入矩阵的初始化后,模型训练的核心任务就是设计合理的上下文预测目标,让矩阵中每一行(词向量)逐步调整位置,从而携带语义信息。
2. 早期词嵌入模型
在 2003 年,一篇论文 A Neural Probabilistic Language Model,首次展示了一个神经网络语言模型,它不仅预测下一个词的概率分布,还通过一个嵌入层将词索引映射为实值向量。这些向量成为了词的稠密表示,也就是我们今天所说的词嵌入(word embeddings) 。
尽管当时论文中并没有直接使用"word embedding"这个术语,但其核心思想:通过神经网络学习词的分布式向量表示------正是现代词嵌入模型的理论源头。
2.1 词嵌入模型原理
这一部分我们展开一下,用早期的模型介绍一下最经典的一类词嵌入模型:预测型词嵌入模型 的基本逻辑:
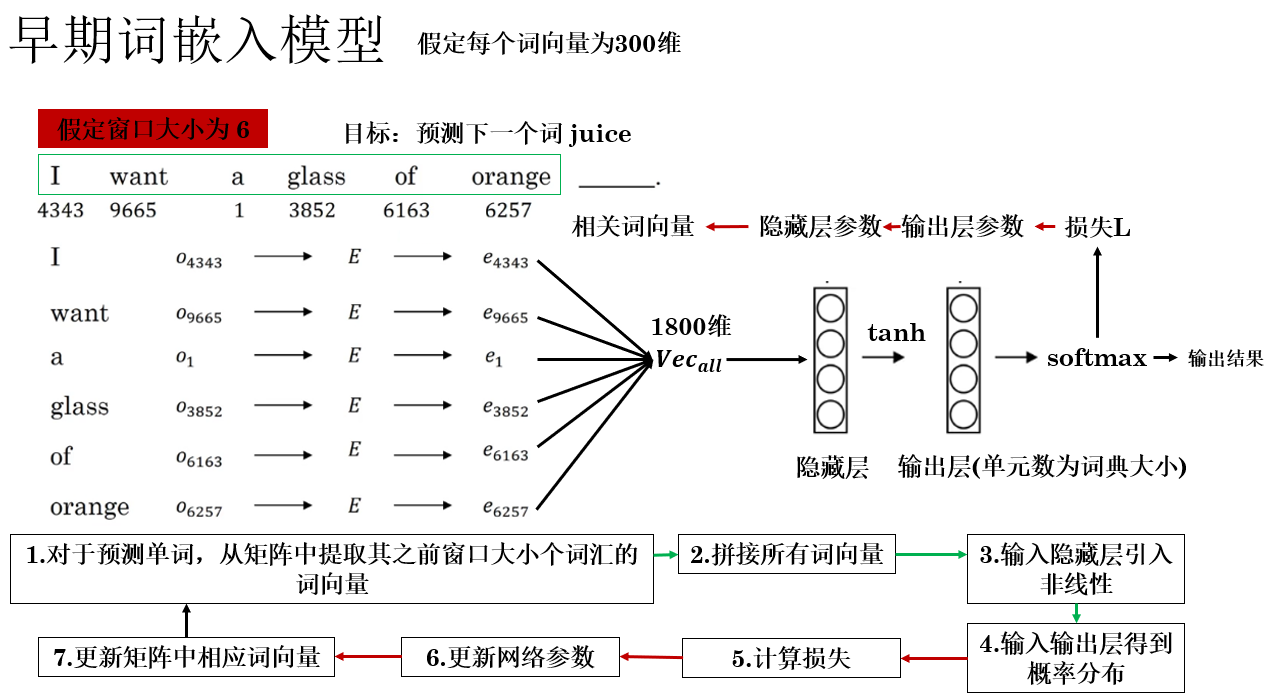
图中简要描述了该模型的传播逻辑,补充一些细节如下:
- 嵌入层(Embedding Layer) :在图中的左半部分,完成的是存储词嵌入矩阵和根据索引查找机制提取词向量 的工作,我们称完成这部分内容的结构为嵌入层。
- 窗口大小 \(t\) :这是一个超参数,当预测序列中第 \(n\) 个词汇时,我们使用其之前 \(t\) 个词汇作为序列信息,前文如果不足 \(t\) 个,则会使用特殊符号填充。
- 联合更新 :在反向传播过程中,嵌入层和网络的其他参数同时更新 。这意味着每次看到训练样本,嵌入矩阵中涉及的词向量会和网络参数一起沿梯度方向调整,使其更有利于下一个词的预测。
那词向量具体是怎么更新来学习语义的呢?我们展开说说:
2.2 词向量的语义学习
举个例子来理解一下词向量的更新逻辑:
假设训练语料中出现了许多关于水果的句子,比如:
I like to eat apple.
She bought a banana yesterday.
Orange juice is tasty.现在,模型的任务是根据上下文预测下一个词 。当看到句子 "I like to eat apple" 时,模型会预测下一个词可能是 "apple"。
这时,反向传播时,模型会调整 "apple"对应的词向量 以及上下文中其他词的向量,使得网络更容易正确预测 "apple"。
同理,当训练样本中出现 "banana" 或 "orange" 时,这些词的向量也会因为相似的上下文而被调整到相互靠近的位置 :"apple", "banana", "orange" 这些同类型的词常出现在类似的上下文 (如 eat、juice、like 等)
最终模型通过梯度更新,让这些词向量在向量空间中彼此靠近,从而自然捕捉到语义相似性。
这样的效果就是:即使模型从未显式告知"它们都是水果",词向量也会因为上下文模式相似而自动聚集在一起,形成语义簇(semantic cluster) ,即向量空间中,语义相近的词自然聚在一起的群体。
这时,面对下面这两句话:
训练:I like orange juice.
测试:I love apple _____. 模型即使没见过测试语句,也可以通过"love 和 like"、"apple 和 orange" 在向量空间的距离相近得到更可靠的答案,从而提高模型性能。
用一句话总结一下:同类型的词汇往往出现在相似的上下文中,因此在更新后更加相似,最终在向量空间中形成语义簇,极大增强了模型的泛化能力。
你会发现,在词嵌入模型中,词向量的语义结构并不是显式教给模型的,而是在上下文预测任务中自然而然学到的,模型并没有专门去"训练合适编码",而是在预测中让相似的词不断靠近。
同样是对数据进行编码,词嵌入和我们之前介绍的人脸识别又有所不同。
当然,既然是早期模型,自然有值得优化的地方,我们继续:
2.3 早期词嵌入模型的局限
尽管 A Neural Probabilistic Language Model 成功提出了通过神经网络学习词向量的思路,但作为早期模型,它在实际应用和理论上存在一些明显的局限性:
| 局限类别 | 具体说明 | 影响 |
|---|---|---|
| 计算开销大 | 输入是 \(t\) 个词独热向量拼接,输出是词表大小 \(V\) 的 softmax | 词表大时计算量高,训练预测速度慢 |
| 上下文窗口固定 | 每次预测只使用前 \(t\) 个词 | 无法捕捉长距离依赖,语义建模受限 |
| 梯度更新效率低 | 嵌入矩阵和网络参数同时更新,每个样本只涉及部分词向量 | 收敛慢,低频词向量质量不稳定 |
| 没有显式建模语义规律 | 语义相似性完全依赖上下文共现 | 稀有词或低频词向量质量差,泛化能力有限,无法处理多义词 |
因此,为了解决这些问题,自然有人发明新的技术和模型,我们在之后几篇就来详细介绍这些内容。
3. 总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 词嵌入矩阵(Embedding Matrix) | 将词表中每个词映射为可学习的稠密向量,矩阵行(或列)对应词向量。初始化随机或正态分布,通过梯度更新学习语义信息。 | 类似图像风格转换中的"随机噪声图像",逐步在训练中形成结构化图像。 |
| 嵌入层(Embedding Layer) | 存储词嵌入矩阵并提供索引查找功能,将词索引映射为词向量。 | 就像一本"词向量字典",根据索引直接查到对应的向量。 |
| 上下文预测训练 | 利用前 \(t\) 个词预测下一个词,通过反向传播更新嵌入矩阵和网络参数,使语义相似的词向量靠近。 | 好比让水果类词(apple, banana, orange)在向量空间里自然聚成一簇,通过相似上下文学习它们的关系。 |
| 语义簇(Semantic Cluster) | 在向量空间中,语义相近的词自然聚集,捕捉词汇之间的语义关系。 | 词向量像朋友一样,常在同一圈子(上下文)出现就靠近在一起。 |
| 早期词嵌入模型局限 | 计算开销大(softmax over 大词表)上下文窗口固定、 梯度更新效率低 、无显式语义建模(如多义词)。 | 模型像老式拼字游戏,效率低且只能看到局部信息,难以捕捉远距离或复杂规律。 |