github仓库:https://github.com/AkaliKong/MiniOneRec
技术报告论文:https://arxiv.org/abs/2510.24431
找了一个论文阅读辅助工具:https://www.alphaxiv.org/
MiniOneRec: An Open-Source Framework for Scaling Generative Recommendation
摘要
做了一个框架:SID构建(RQVAE)+SFT(0.5b~7b)+RL(受限解码+混合奖励)
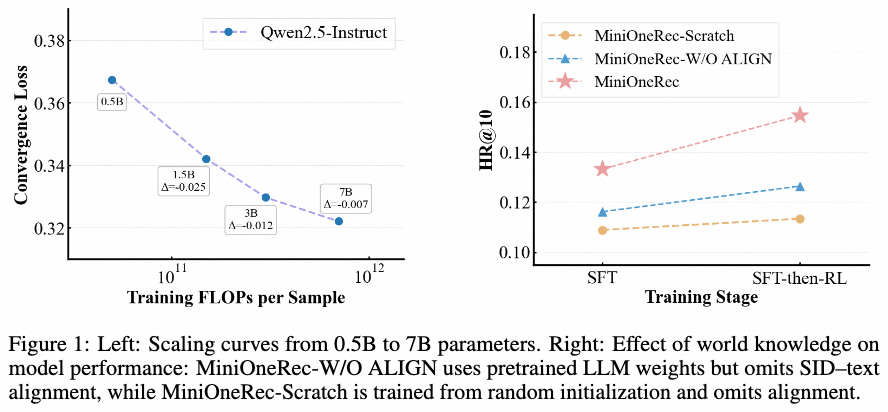
实验证明了llm的Scaling特点,模型越大越好。
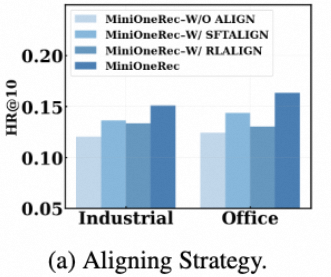
从图上来看,对齐SID-text是挺重要的。
Introduction/Related Work 略
Modeling
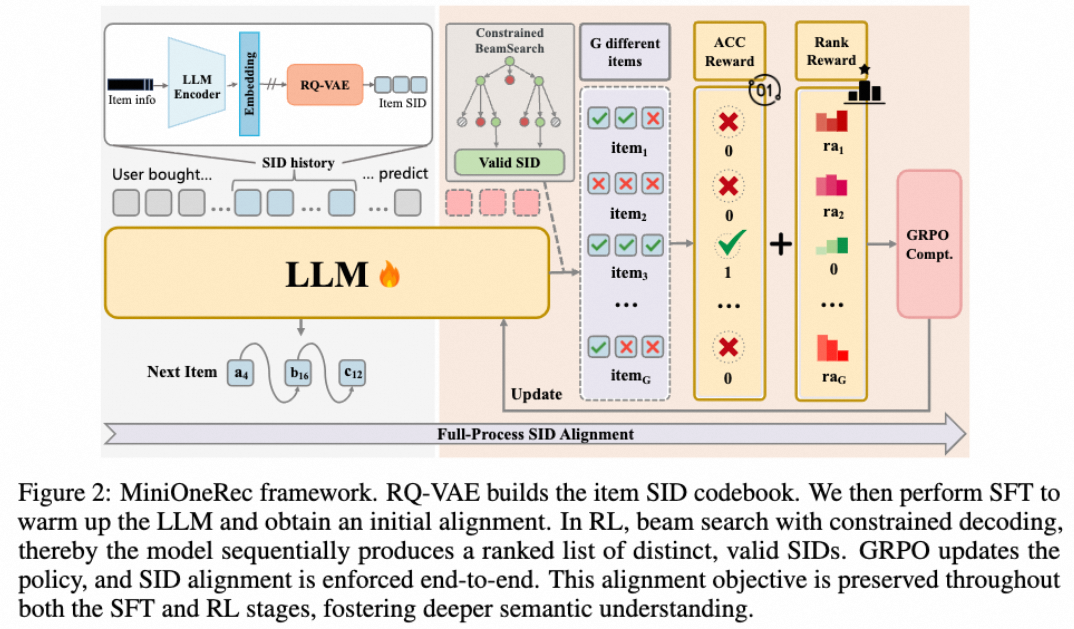
框架:
1、tokenizer(RQVAE)
2、LLM-text 对齐(利用llm的世界知识)
3、SFT next token prediction
4、RL(GRPO)
Task
序列推荐任务
先分词:一个用户u,有一个时间顺序的历史交互商品序列Hu=i1,i2, ..., iT。每个商品iti_tit通过RQVAE编码为一个3层的SID {c0it,c1it,c2it}\{c_0^{i_t},c_1^{i_t},c_2^{i_t} \}{c0it,c1it,c2it}。
后训练:LLM πθ\pi_{\theta}πθ,读取历史序列预测下一个商品。推理的时候k beams search。
Item Tokenization
标准RQVAE
为了避免码本坍缩使用第一个训练batch的k-means中心作为codebook的初始化码本【我直接聚类也很有用】
论文里没写,但是我看代码里有Sinkhorn-Knopp algorithm代码(LC-Rec也做了),这也是缓解码本坍缩的trick。
Align with LLM
对齐LLM世界知识和SID信号。
任务一:序列推荐任务
任务二:对齐SID和文本描述任务。
实际上在github里更新了新技术:
GPR-inspired SFT with Value-Aware Fine-Tuning (VAFT): implements weighted loss based on simulated item value
https://github.com/AkaliKong/MiniOneRec/blob/main/sft_gpr.py
相当于每条样本有一个数值表示好坏,然后对损失做加权。
但是没有实验结果,不知道好不好。
TODO: 做实验比较结果
RL with verifiable rewards (RLVR)
1、混合动态采样(SID空间小,容易采样到相同的SID)
2、稀疏排序信号
混合动态采样采样:
论文说了两个方法。方法1是over-samplef疯狂采,然后构造一个SID样本尽量不重复的集合。方法2是beam search。它的最终方法是beam search,没用上方法1。
稀疏排序信号
用NDCG作为奖励 如果是正确商品,分数再加1
训练
商品描述:Qwen3-Embedding-4B编码
分词器:RQVAE 单卡训练,batchsize=20480,lr=1e-3,epochs=10000
SFT:AdamW,Qwen2.5-Instruct。8卡训练,单卡batchsize=128,10 epochs+early stop(patience=1),lr=3e-4,cosine decay。
RL:GRPO,2epoch,KL权重β不变=0.1,lr=1e-5,batchsize=512
推理:beam search width=16
评估
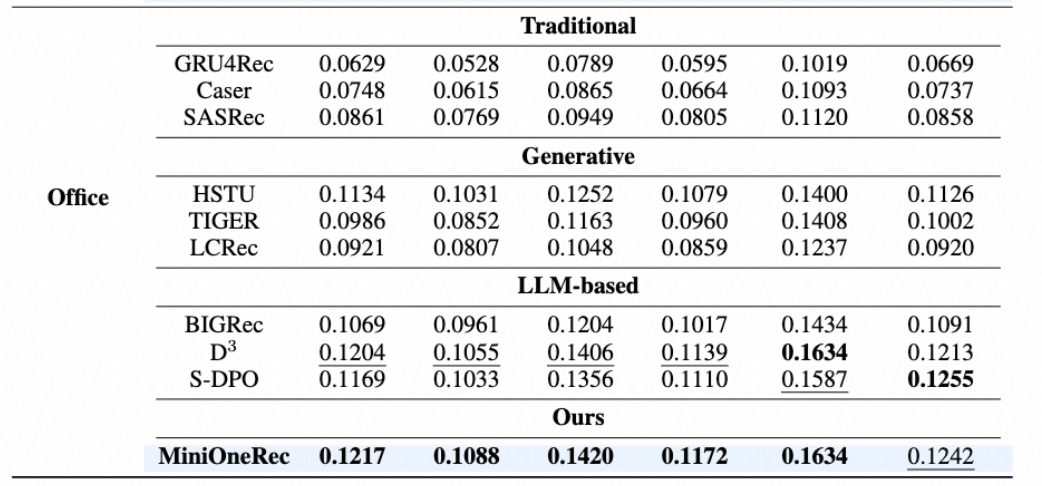
亚马逊数据集Office+Industrial。hitrate+NDCG作为指标。
1、Scaling:训练+评估损失:模型越大损失越小
2、baseline对比:LLM系列和非LLM系列对比,说明世界知识的重要;Ours和LLM系列对比,说明RL的重要
Transferablity
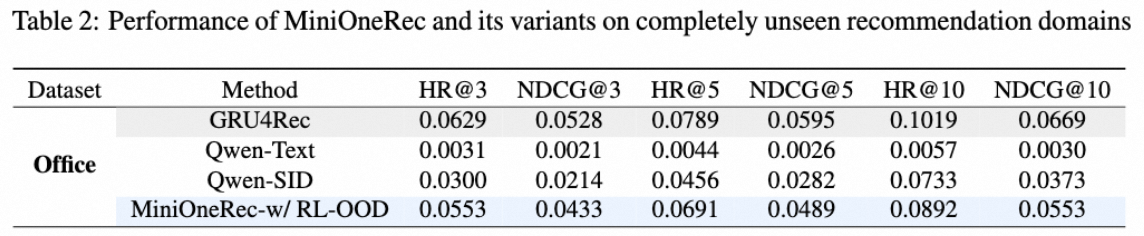
SID pattern discovery实验:在Industrial上训在Office上评估
证明RL的有效
没做SFT是因为SFT很容易领域过拟合影响迁移。
消融
language-SID的重要性:
1、不做language-SID对齐
2、做language-SID对齐,但不SFT 推荐任务,只在RL上做推荐任务
3、SFT只做推荐任务,RL做language-SID对齐(那还做推荐任务吗?没说清楚)
采样:
1、直接topk
2、采1.5倍budget+筛选
3、beamsearch:最好
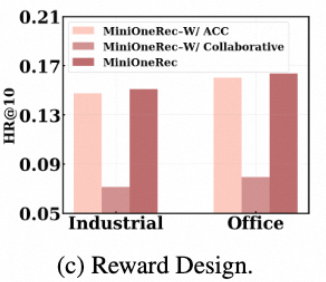
奖励设计:
1、01奖励
2、SASRec模型 logits 【效果很差 reward hacking,SASRec协同信息和推荐信息不一致】
3、NDCG
是否预训练:【还是预训练的好】

代码
sft_gpr
https://github.com/AkaliKong/MiniOneRec/blob/main/sft_gpr.py
GPR-inspired SFT with Value-Aware Fine-Tuning (VAFT): implements weighted loss based on simulated item value