文章目录
- [1. VLA 可以被抽象为表征学习问题](#1. VLA 可以被抽象为表征学习问题)
- [2. VLM 视觉特征 vs. VLA视觉特征](#2. VLM 视觉特征 vs. VLA视觉特征)
- [3. 小题大做:揭穿生成式机器人控制的种种误区](#3. 小题大做:揭穿生成式机器人控制的种种误区)
1. VLA 可以被抽象为表征学习问题
在当前主流设定下,VLA 的训练目标通常是:根据图像和任务指令,直接预测低维的机器人动作。从学习角度看,这本质上是一个表征学习问题,模型被要求从高维视觉输入中提取"对动作回归最有利"的表示。但问题在于,机器人动作本身是一种信息密度极低的监督信号,它只描述了某一时刻的控制结果,而没有显式刻画物体结构、可供性、接触关系或任务阶段等高层语义。
在这种监督下,模型天然会倾向于学习"对当前动作最短路径"的表示,而不是"对世界结构最充分"的表示 。对感知模型来说,这或许是可以接受的;但对 LLM 而言,这是一种明显的归纳偏置错配。LLM 的优势在于建模高层语义、组合结构和可语言化的中间概念,而当训练信号只是一串缺乏语义锚定的 action 数值时,LLM 很难发挥这些能力,最终往往退化为一个昂贵的函数逼近器。
因此,问题并不在于 LLM 是否足够强,而在于当前的 VLA 训练目标是否为 LLM 提供了发挥空间。如果机器人动作仍然是唯一且最终的监督信号,那么即使引入再大的 LLM,也很难指望模型学到真正高质量、可泛化的世界表征。要让 LLM 在 VLA 中变得"必要",关键不在模型规模,而在监督信号本身是否具有足够的语义结构。
2. VLM 视觉特征 vs. VLA视觉特征
VLM4VLA: REVISITING VISION-LANGUAGE MODELS IN VISION-LANGUAGE-ACTION MODELS
VLM 预训练学到的视觉特征更偏向语义理解 ,而VLA 的视觉特征更需要空间特征。VLM的视觉特征不足以支持低层级的动作控制。
首先,使用预训练 VLM 作为初始化对 VLA 是显著有益的,相比从零开始训练,几乎所有预训练模型都能带来稳定提升。
其次,VLM 在通用基准上的表现,或者在语言理解、VQA、图文对齐等经典任务上的能力,不能作为其在机器人操作任务中表现的可靠预测指标。不同 VLM 在 VLA 任务上的排名会随着环境和任务变化而显著波动,这意味着 "更强的 VLM"并不等价于"更好的控制策略"。
第三,作者系统性地否定了一个直觉假设:即通过对 VLM 进行具身相关辅助任务微调(例如空间理解、视觉指向、深度或关系推理),可以自然提升下游控制性能。实验结果显示,这类具身能力的提升往往 无法传递到动作决策层面,甚至在部分设置中产生负迁移。这表明当前常用的"具身任务"本身并没有对控制问题施加正确或足够的归纳偏置。
第四,通过模态级消融,论文指出视觉编码器 而非语言模块是 VLA 性能的主要瓶颈 。冻结语言模块对控制性能影响有限,而视觉模块是否能够编码与动作相关的关键信息,直接决定了策略质量。更重要的是,即使视觉编码器在下游训练中被冻结,只要其预训练阶段引入了与控制相关的监督,仍然可以带来稳定收益。
最终,论文给出的总体结论是:当前 VLM 的视觉预训练目标与具身控制任务之间存在本质性的"视觉语义-控制语义断层(visual gap)"。VLA 的进一步突破,不应继续单纯依赖更大的通用 VLM 或更多具身评测任务,而应重新思考视觉表征在控制语境下应具备的结构、目标和训练信号。
3. 小题大做:揭穿生成式机器人控制的种种误区
https://simchowitzlabpublic.github.io/much-ado-about-noising-project/
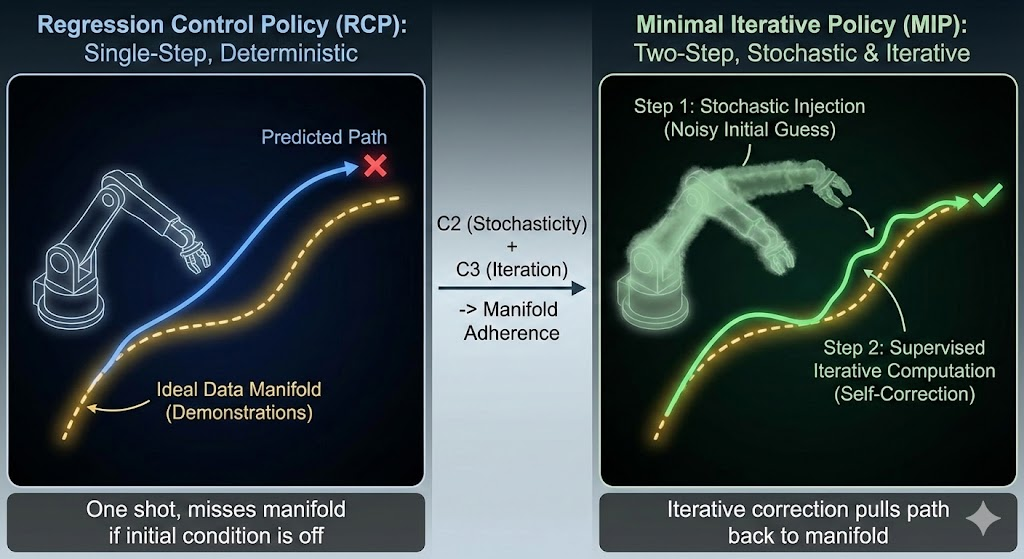
当前生成式机器人控制策略(如 diffusion / flow policy)在行为克隆中的性能优势,并不源于其"生成式建模能力",而主要来自训练机制层面的两个因素:噪声注入与迭代式监督。
首先,多模态动作分布的建模能力并不是性能提升的关键。在多数操控任务中,专家数据在条件动作空间中本质上近似单模态,即便强行引入多模态建模或进行多次采样,对最终闭环控制成功率的提升也极为有限。
其次,论文指出,生成模型的表达能力并未显著超越同等规模的回归策略。在网络结构、参数量和感受野相当的前提下,生成式策略并未展现出更强的函数复杂性或行为多样性。
将生成式控制策略的优势拆解为三个可能因素------分布学习、噪声注入以及迭代式监督。通过一系列消融实验,作者发现只保留"噪声注入 + 迭代监督",完全去除显式的分布建模,就足以复现甚至超过完整 flow/diffusion policy 的性能。基于这一发现,论文提出了 Minimal Iterative Policy(MIP),一种极其简化的两步迭代策略,其本质是对残差进行监督学习并在训练中引入随机扰动。
