提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、K8S是什么?
- 二、架构图
- 三、k8s架构
-
- [3.1主节点 master 组件](#3.1主节点 master 组件)
-
- [(1)API Server](#(1)API Server)
- (2)Etcd
- (3)Scheduler
- [(4)Controller Manager](#(4)Controller Manager)
- (5)kubectl
- [3.2 节点 node 组件](#3.2 节点 node 组件)
前言
学习Kubernetes(K8s),不仅是为了掌握一项热门的云原生技术,更是为了解锁一个全新的、以应用为中心的软件交付与运维时代。它正从一项"加分技能"快速演变为开发、测试、运维乃至架构师岗位的核心素养。理解为什么要学习K8s,就是理解现代软件基础设施的未来走向。
一、K8S是什么?
Kubernetes,简称 K8s(K与s之间有8个字母),是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。它最初由Google设计并开源,现已成为云原生计算基金会(CNCF) 的核心项目,是容器编排领域无可争议的事实标准。
简单来说,如果把容器化应用(比如用Docker打包的应用)比作一个个标准集装箱,那么Kubernetes就是一套高度自动化的全球港口操作系统。它管理着成千上万个集装箱的装卸、调度、运输、故障修复和资源分配,确保货物(应用)能够高效、稳定、可扩展地送达目的地(服务器)。
二、架构图
我们用一张图看一下k8s的架构
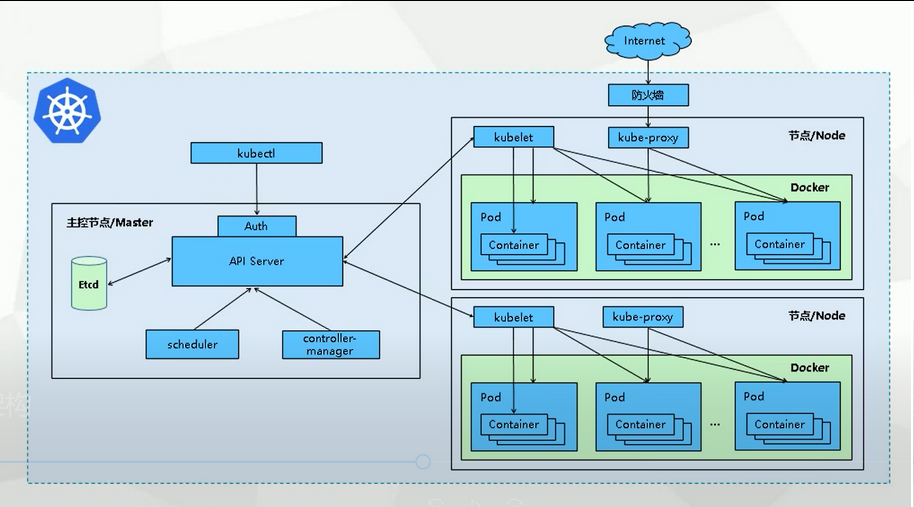
通过互联网访问,通过防火墙然后到对应应用程序所在工作节点,访问对应的代理,然后在访问对应的pod。
三、k8s架构
K8s集群遵循经典的主从架构,分为控制平面(大脑)(主节点 master 组件)和工作节点(四肢)(节点 node 组件)
针对各个组件的详细功能我们进行介绍:
3.1主节点 master 组件
(1)API Server
- Kubernetes 的 API Server(全称kube-apiserver)是整个集群的"唯一入口"和"大脑中枢**"。它是控制平面的核心组件,所有内部组件、外部用户和自动化工具与集群交互都必须通过它。
- 集群统一入口,各组件的协调者,提供认证、授权、访问控制、API注册和发现等机制,以 RESTful API的方式提供接口服务,所有对象资源的增删改查和监听都由 API Server 处理后提交给 Etcd存储。所有模块之前并不会之间互相调用,而是通过和 API Server 打交道来完成自己那部分的工作。
- 为了让你快速抓住核心,可以把它想象成一个高度智能的 "机场中央控制塔"
(2)Etcd
分布式键值存储系统集群,用于保存集群状态数据,如:Pod、Service 等资源对象信息。
另外,Etcd 有一个特性,可以调用它的 API 监听其中的数据,一旦数据发生变化,就会收到通知。有了这个特性之后,K8s 中的每个组件只需要监听 Etcd 中数据,就可以知道自己应该做什么。
Kubernetes 中的 etcd 是一个高度一致、高可用的分布式键值存储。它是整个集群的 "唯一真相之源" ,存储着所有集群数据的"最终版本"。
你可以把它理解为一个机密的、永不丢失且实时同步的"集群记忆中枢":
它像中央登记处,记录所有资源(Pod、Node、Secret等)的"身份信息"和"当前状态"。
它像航空管制中心的"主飞行计划",是所有内部组件决策和行动的唯一、权威依据。
它像银行的核心账本,每一次对集群的更改都必须经过它,并保证数据的强一致性。
(3)Scheduler
负责对集群内部的资源进行调度,相当于调度员的角色,按照预定的调度策略将 Pod 调度到相应的机器上,调度程序根据调度算法为新创建的 Pod 选择一个 Node 节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
通俗点可以这么理解
Kubernetes 的 Scheduler(调度器,组件名为 kube-scheduler) 是整个集群的 "智能调度中心"。它的核心作用可以概括为一句话:
为新创建的、未指定运行节点的 Pod,自动选择一个最合适(Optimal)的工作节点(Node)来运行。
你可以把它想象成一位拥有全局视野、精通运筹学的"超级房产中介":
客户需求:Pod(包含一个或多个容器)的资源需求(CPU/内存)、亲和性、容忍度等。
待选房源:集群中所有可用的工作节点及其状态(剩余资源、地理位置、特殊标签等)。
中介的使命:从所有节点中,为每个 Pod 精准匹配一个 "最佳归宿",以实现集群资源的高效、稳定利用。
(4)Controller Manager
Controller Manager(控制器管理器)是 Kubernetes 控制平面的"自动修复与状态协调大脑"。它的核心作用是监听集群状态变化,并驱动当前状态无限逼近用户声明的期望状态。
如果说 API Server 是"前台接待",etcd 是"中央数据库",Scheduler 是"调度员",那么 Controller Manager 就是确保所有指令被正确执行的"工头"和"纠错系统"。
Controller Manager 是 K8s 的管理控制中心,控制器和资源一一对应,负责集群内 Node、Namespace、Service、Token、Replication 等资源对象的管理,使集群内的资源对象维持在预期的工作状态。每一个 controller 通过 api-server 提供的 restful 接口实时监控集群内每个资源对象的状态,当发生故障,导致资源对象的工作状态发生变化,就进行干预,尝试将资源对象从当前状态恢复为预期的工作状态,常见的 controller 有 Namespace Controller、Node Controller、Service Controller、ServiceAccount Controller、Token Controller、ResourceQuote Controller、Replication Controller等。
(5)kubectl
kubectl 是 Kubernetes 的官方命令行工具,是用户与 Kubernetes 集群进行交互的最主要、最核心的客户端。
你可以把它理解为 Kubernetes 集群的"遥控器" 或 "管理终端"。几乎所有通过命令行对集群的操作,都通过它来完成。
kubectl 的核心作用是将用户命令转换为对 Kubernetes API Server 的 HTTP API 调用,从而管理整个集群。它本身不直接控制集群组件,而是与 API Server 对话。
3.2 节点 node 组件
(1)Node
Node(节点),在 Kubernetes 中也被称为 Worker Node 或 Minion,是集群中真正承担计算工作的"工作机器"。它是 Pod 得以运行的物理或虚拟主机,是构成 Kubernetes 集群资源池的基础单元。
你可以将整个 Kubernetes 集群想象成一个数据中心或超级计算机:
Master 节点(控制平面):是"总控室",负责指挥和调度。
Node 节点:是"机房"里一台台插着网线和电源的物理服务器(或云上的虚拟机),负责执行具体的计算任务。
核心作用:承载工作负载的基石
Node 的核心作用非常明确:为 Pod 提供运行环境,包括计算、网络、存储等资源,并确保容器能被正确地启动和管理。
(2)Kubelet
Kubelet 是 Kubernetes 集群中运行在每个 Node(工作节点)上的"节点代理"和"管家"。它是连接 Master 控制平面与具体 Node 的关键纽带,是 Pod 和容器生命周期管理的直接执行者。
你可以把它理解为:
Node 的"总负责人":负责本节点上的一切"家务"。
Master 的"现场监工":忠实执行 Master 下发的指令,并如实汇报现场情况。
(3)kube-proxy
kube-proxy 是 Kubernetes 集群中运行在每个 Node(工作节点)上的"网络代理与流量导流员"。它的核心作用非常聚焦:实现 Kubernetes Service 的网络抽象,让集群内外的客户端能够稳定、负载均衡地访问到一组动态变化的 Pod。
你可以把它理解为:
服务的"智能路由器":为 Service 的虚拟 IP(ClusterIP)维护路由规则,将流量转发到后端正确的 Pod。
Pod 变化的"跟踪器":实时监听 Pod 的变化,当 Pod 被创建、销毁或迁移时,自动更新转发规则,确保流量永远指向健康的 Pod。
核心作用:解决什么问题?
由于 Pod 是动态的(IP会变、数量会变),直接访问 Pod IP 是不可靠的。Service 提供了一个稳定的虚拟访问端点(VIP 和 DNS名),而 kube-proxy 的职责就是让这个"虚拟端点"变得"真实可用",具体解决:
服务发现:客户端只需记住 Service 的名字或 ClusterIP,无需关心后端有多少个 Pod、它们的 IP 是什么。
负载均衡:将访问 Service 的流量,均匀地分发到后端所有健康的 Pod 上。
网络隔离与代理:为服务间访问提供透明的网络代理。