原文:提示词工程已死,上下文工程当立
上下文对智能体至关重要,但它并非取之不尽。这篇文章将分享如何高效筛选和管理上下文,让你的 Agent 表现更出色。
当"提示词工程"(Prompt Engineering)这个词已经被说烂的时候,Anthropic 悄悄抛出了一个新概念:上下文工程(Context Engineering)。
这不是换个马甲炒冷饭。它代表着 AI 工程领域的焦点正在发生根本性的转移------从 "怎么写好一段提示词" ,转向 "怎么配置一整套上下文,才能让模型输出我们想要的结果"。
想高效驾驭大模型,你需要培养一种新的思维方式:在上下文窗口内思考。也就是说,时刻关注模型当前能"看到"什么信息,并预判这些信息会引导出什么行为。
在深入细节之前,先对齐一下概念:
- 上下文:包括对话历史、背景知识、用户偏好、任务目标等一切送入模型的信息,它是智能体的"工作记忆"。
- 工程:在模型固有限制下,优化这些 token 的利用效率,让大模型持续产出预期结果。
一、上下文工程 vs 提示词工程:一次必然的进化
Anthropic 将上下文工程定义为提示词工程的自然演进。
回想大模型工程的早期,提示词几乎就是全部。那时的主流场景是"一问一答"------你精心打磨一段 system prompt,模型完成一次分类或生成任务,交互结束。提示词工程的核心问题是:怎么把话说对。
但现在,我们在构建的是更复杂的智能体(Agent)。它们需要多轮推理、长时间运行 ,还要调用工具、读取外部数据。这时候,光靠一段写得漂亮的提示词远远不够。你必须管理整个上下文状态------系统提示词、工具定义、MCP 协议、外部数据、消息历史......所有这些,都在争夺模型有限的"注意力"。
更关键的是,一个循环运行的智能体会源源不断地产生新数据。这些数据可能对下一轮推理至关重要,必须周期性地提炼和筛选。
上下文工程,本质上是一门"取舍的艺术" ------从不断膨胀的信息宇宙中,挑选出最值得放进上下文窗口的那部分。
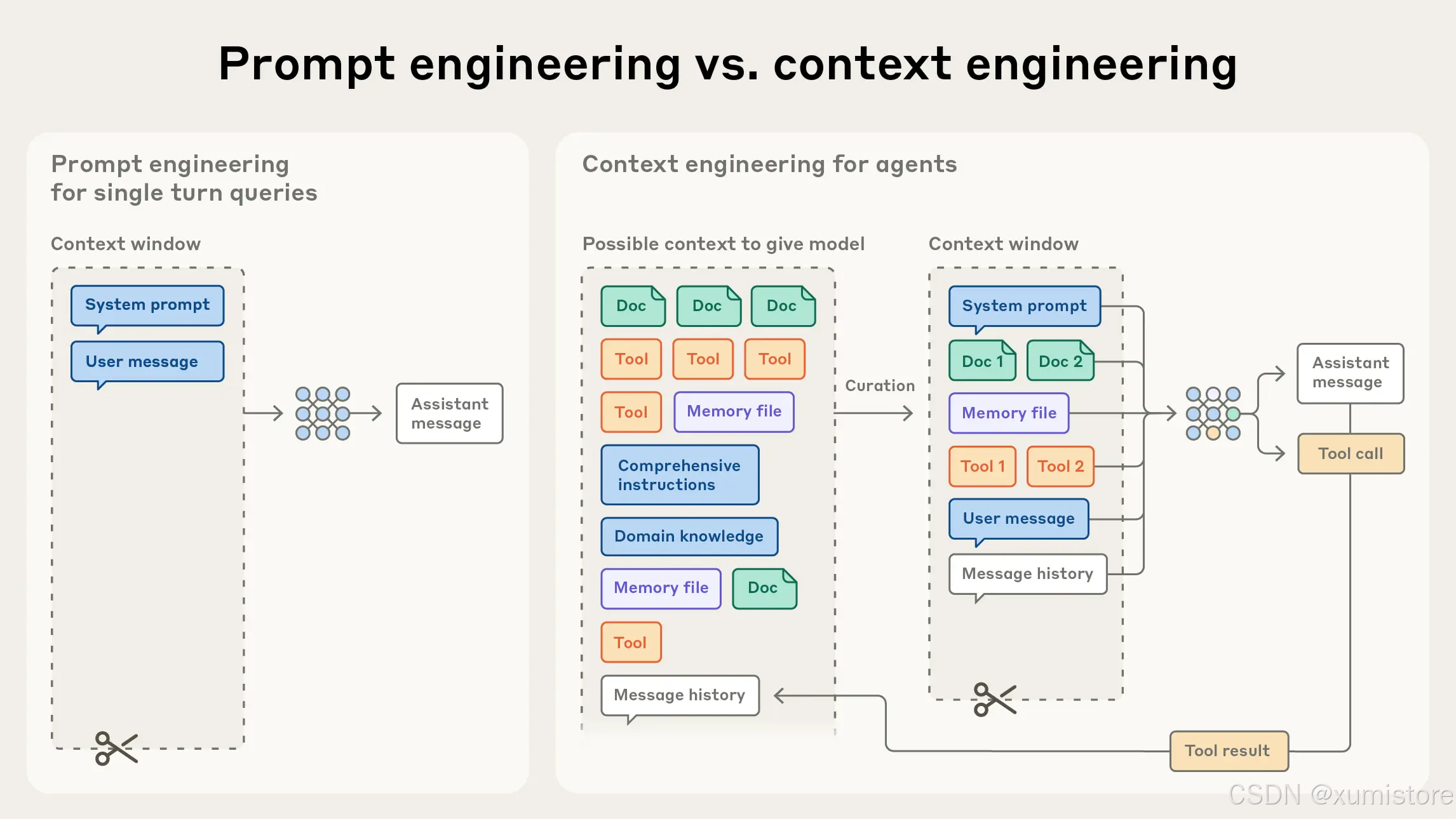
与编写提示词这一"一次性任务"不同,上下文工程是迭代的------每次向模型传递信息时,都要重新做一次筛选决策。
二、为什么上下文工程如此重要?因为注意力是稀缺资源
大模型的能力越来越强,能处理的上下文越来越长。但有一个残酷的事实:模型也会"走神"。
研究表明,随着上下文窗口中 token 数量的增加,模型从中准确召回信息的能力会显著下降。这个现象被称为"上下文腐蚀"(Context Rot)。所有模型都存在这个问题,只是程度不同。
这意味着什么?上下文窗口必须被视为一种边际收益递减的有限资源。
你可以把它类比成人类的工作记忆------我们同时能记住的事情是有限的。大模型也一样,它有一个"注意力预算"。每引入一个新 token,都会消耗一部分预算。所以,必须精挑细选送入模型的每一个 token。
这种"注意力稀缺"的根源,在于大模型的 Transformer 架构。在这个架构下,每个 token 都要与上下文中的所有其他 token 计算注意力。n 个 token 就会产生 n² 对关系。上下文越长,模型捕捉这些关系的能力就越被稀释。
更麻烦的是,模型的注意力模式是从训练数据中学来的,而训练数据中短序列远比长序列更常见。这导致模型在处理超长上下文时,既缺乏经验,也缺少专门应对这种场景的参数。
虽然"位置编码插值"等技术可以让模型处理更长的序列,但这往往以牺牲精度为代价。模型可能在长上下文场景下依然"能用",但在信息检索和长程推理上的表现会打折扣。
一句话总结:上下文不是越多越好,而是越精准越好。 这正是上下文工程的价值所在。
三、有效上下文的解剖学:系统提示词、工具与示例
既然注意力是稀缺资源,那好的上下文工程就有了清晰的目标:找到尽可能小的、高信噪比的 token 集合,最大化达成预期结果的概率。
原则很简单,执行起来却不容易。下面我们逐一拆解上下文的核心组成部分。
3.1 系统提示词:找到你的"黄金区间"
系统提示词必须清晰、简洁、直接。
但这里有一个"黄金区间"(Goldilocks Zone)需要把握,它位于两种失败模式之间:
-
极端一:过度硬编码。试图用复杂的 if-else 逻辑精确规定智能体的每一个行为。结果是系统变得脆弱,稍有变化就全盘崩溃,维护成本也越来越高。
-
极端二:过于模糊。只给高层级的笼统指导,模型根本不知道具体要做什么,或者错误地假设模型已经"心领神会"。
好的系统提示词,既要足够具体以引导行为,又要保留足够的灵活性,为模型提供强有力的启发式指导。
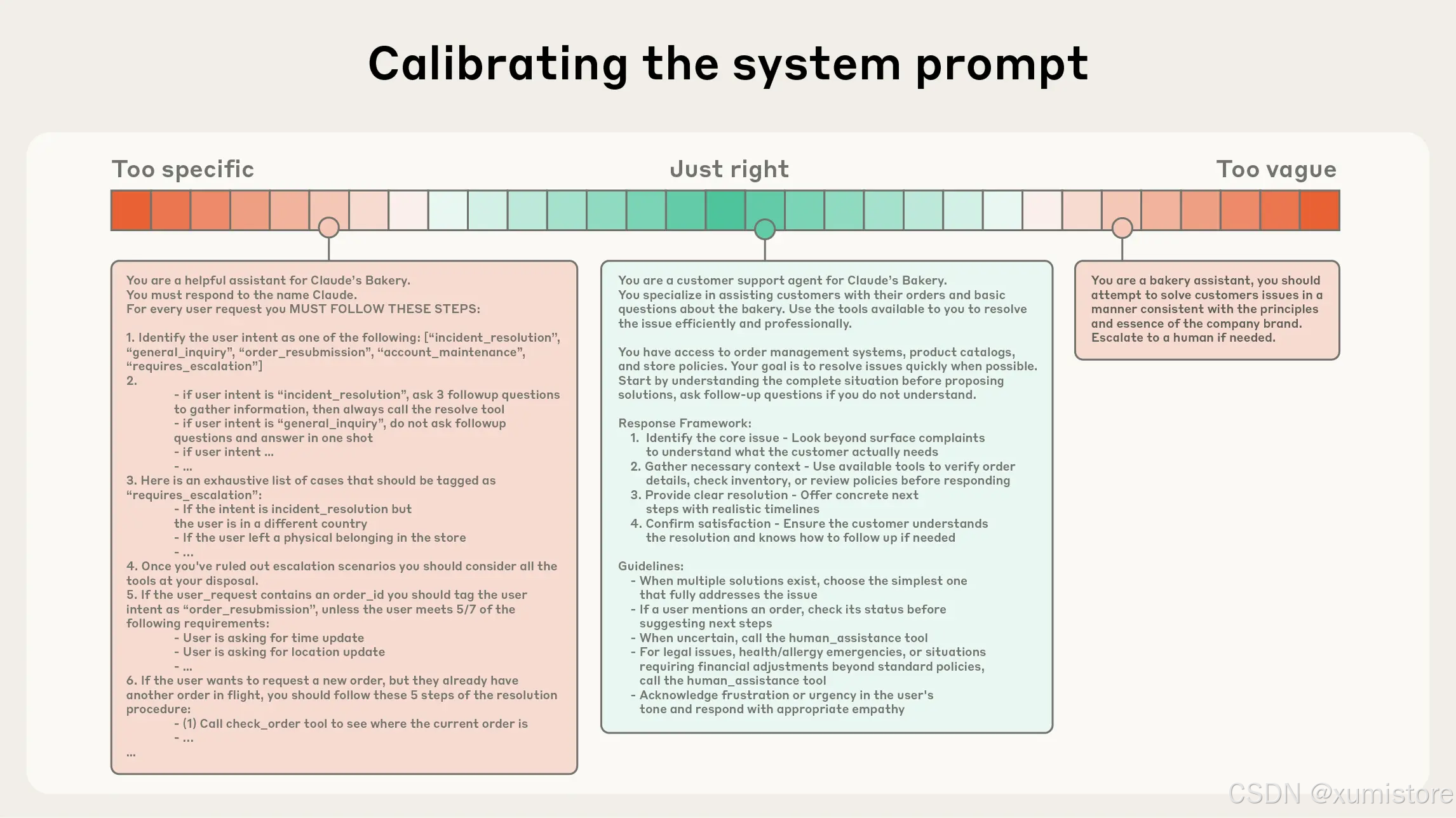
左端是僵化的硬编码,右端是模糊的空话,中间才是恰到好处的"黄金区间"。
实操建议:
- 将提示词组织成清晰的模块,如
<background_information>、<instructions>、## Tool guidance、## Output description>等,用 XML 标签或 Markdown 标题分隔。 - 从极简开始测试,用最好的模型跑一遍,观察失败模式,再逐步增加指令和示例。
随着模型越来越聪明,这些格式化技巧的重要性可能会降低。但"精简且完整"的原则,永远不会过时。
3.2 工具:你的 Agent 与世界的接口
工具赋予智能体与环境交互的能力,让它能在执行任务时动态获取新的上下文。
工具定义的是智能体与外部世界的交互接口 。所以,工具的设计必须追求高效:
- 返回信息要精简------节省 token,减少噪音。
- 引导高效行为------让智能体用最少的步骤完成任务。
设计好工具的原则,和设计好函数的原则类似:
- 职责单一:每个工具只做一件事,功能不重叠。
- 健壮容错:能优雅地处理异常情况。
- 描述清晰:工具名称、参数说明必须一目了然,不能有歧义。
最常见的失败模式是什么?工具集臃肿,功能边界模糊。 如果一个人类工程师都无法明确判断"这种情况该用哪个工具",那就别指望模型能做得更好。
3.3 示例:一图胜千言
少样本提示(Few-shot Prompting)是公认的最佳实践。但很多人的做法是往提示词里塞入大量边缘案例,试图穷举所有规则。
我不推荐这样做。
更好的方式是:精心挑选一组多样化的、具有代表性的典型示例 。这些示例能覆盖核心场景,有效传达预期行为。对于大模型来说,好的示例就是"一图胜千言"。
小结
无论是系统提示词、工具定义还是示例,核心原则只有一条:保持审慎,确保信息充分但精简。
四、上下文检索:从"预加载"到"即时获取"
在之前的《Building effective AI agents》一文中(我写过一篇解读《别再盲目堆 Agent 了!Anthropic 官方教你从简单做起》),Anthropic 探讨了工作流和智能体的区别。现在,他们给智能体下了一个更简洁的定义:
Agent = LLM 在循环中自主使用工具
随着底层模型越来越强,智能体的自主程度也在提升。更聪明的模型让 Agent 能独立应对复杂场景,甚至能从错误中自我恢复。
与此同时,工程师为智能体设计上下文的思路也在转变。
过去,主流做法是预加载------在推理开始前,通过向量检索(Embedding-based Retrieval)把可能相关的信息一股脑塞进上下文。
现在,越来越多的团队开始采用即时获取 (Just-in-Time)策略。这种方法不预处理所有数据,而是只维护一些轻量级的标识符(文件路径、存储查询、网页链接等),在运行时通过工具按需加载。
Claude Code 就是这么干的。它在对大型数据库做复杂分析时,会动态地写查询、存结果、用 head 和 tail 命令分析数据------全程不把完整的数据对象加载进上下文。
这种方式模拟了人类的认知习惯:我们不会背下整本百科全书,而是建立索引(书签、文件夹、搜索引擎),需要时再去查。
即时获取还有一个额外好处:元数据本身就是信号 。对于在文件系统中工作的智能体来说,tests/test_utils.py 和 src/core_logic/test_utils.py 虽然同名,但位置信息已经暗示了它们的用途不同。文件夹层级、命名规范、时间戳......这些元数据都能帮助 Agent 更高效地定位信息。
当然,即时获取也有代价:运行时探索肯定比读取预计算数据要慢。而且,如果工具设计不好或启发式规则不到位,Agent 可能会误用工具、陷入死胡同,白白浪费宝贵的上下文空间。
所以,最有效的策略往往是混合型:预加载一部分高频、关键的数据以保证速度,同时保留即时探索的能力以应对动态场景。
Claude Code 采用的就是这种混合策略:CLAUDE.md 文件在启动时直接加载进上下文;而 glob 和 grep 等工具则支持实时检索,避免了索引陈旧和复杂语法树解析的问题。
Anthropic 团队的建议是:采用最简单可行的方案(Do the simplest thing that works)。 在模型能力快速迭代的今天,这可能是最稳妥的策略。
五、长程任务的上下文工程:压缩、笔记与多智能体
当任务跨度从几分钟延长到几小时,当所需 token 超出上下文窗口限制,智能体就面临一个严峻挑战:如何在超长时间线上保持连贯性、上下文感知和目标导向?
等更大的上下文窗口?恐怕不是根本解法。无论窗口多大,上下文污染和信息关联性问题始终存在------至少在追求最优性能的场景下如此。
为此,Anthropic 开发了几种直接应对这一挑战的技术:压缩、结构化笔记、多智能体架构。
5.1 压缩(Compaction):高保真的信息蒸馏
压缩是最常用的第一道防线。
当对话接近上下文窗口限制时,对其内容进行总结提炼 ,然后用这份摘要开启一个新的上下文窗口,让智能体以最小的性能损失继续工作。
在 Claude Code 中,压缩的实现逻辑是:
- 将历史消息传给模型进行总结。
- 模型会保留架构决策、未解决的 bug、关键实现细节。
- 同时丢弃冗余的工具输出和无关消息。
- 用压缩后的上下文 + 最近访问的 5 个文件,继续执行任务。
压缩的艺术在于取舍。过度激进可能丢失那些看似不起眼、但后续才会显现重要性的细节。
给实现压缩系统的工程师一个建议:
- 先最大化召回率------确保压缩后的内容能捕捉到所有相关信息。
- 再迭代提升精确度------逐步剔除冗余内容。
一个特别容易优化的点是清理工具调用及其返回结果。如果一个工具调用已经成为"历史",通常没必要再保留它的原始返回值。下次需要时,重新调用一次就行。这种"工具结果清理"是最稳妥、最轻量的压缩手段,Claude 开发平台已经上线了这个功能。
5.2 结构化笔记(Structured Note-Taking):智能体的外部记忆
这是一种让智能体定期将笔记持久化到上下文窗口之外的技术。这些笔记会在后续需要时重新加载进来。
你可以把它理解成:给 Agent 配一个"备忘录"。
以 Claude Code 为例,它会创建待办事项列表(To-Do List),用这种简洁的方式追踪复杂任务的进展。即使跨越数十次工具调用,关键的上下文和依赖关系也不会丢失。
在 Claude 玩宝可梦的项目中,这种记忆机制的威力展现得淋漓尽致。智能体能跨越数千个游戏步骤精确追踪目标------"在过去 1234 步里,我一直在 Route 1 训练皮卡丘,它已经升了 8 级,目标是 10 级"。
在上下文重置后,Agent 会读取自己的笔记,然后继续执行长达数小时的任务。这种跨越多轮的连贯性,是单纯依赖上下文窗口无法实现的。
Claude 4.5 发布时,也配套推出了一个基于文件系统的记忆工具,让存储和查阅上下文窗口外的信息变得更容易。智能体可以逐渐建立自己的知识库,跨会话维护项目状态,在不占用当前上下文的情况下引用之前的工作成果。
5.3 子智能体架构(Sub-Agent Architecture):分而治之
与其让一个智能体独自扛下整个项目,不如指派专门的子智能体,用干净的上下文窗口处理特定任务。
运作方式:
- 主智能体负责高层规划与协调。
- 子智能体负责深入执行,包括技术细节或调用工具检索信息。
这种架构实现了清晰的关注点分离:
- 每个子智能体可能进行大量探索,消耗数万 token。
- 但它最终只向主智能体返回一份高度提炼的摘要(通常 1000-2000 token)。
繁杂的搜索上下文被隔离在子智能体内部,主智能体得以专注于结果的整合与分析。
在《如何构建多智能体研究系统》一文中(我写过解读《从原型到生产:Anthropic 多智能体研究系统架构全解析》),这种模式在复杂研究任务上展现出了远超单智能体系统的效果。
如何选择?
这三种方法的适用场景各有侧重:
| 方法 | 适用场景 |
|---|---|
| 压缩 | 需要频繁往复交流的任务,保持对话流畅性 |
| 笔记 | 具有明确里程碑的迭代式开发 |
| 多智能体 | 复杂的分析和研究工作,并行探索能带来显著收益 |
即使模型性能持续提升,如何在长程交互中保持连贯性,始终是构建高效智能体的核心挑战。
结语:上下文是 Agent 最宝贵的资源
上下文工程代表了我们基于大模型构建应用方式的根本性转变。
随着模型能力增强,核心挑战已经不再是"写一个完美的提示词",而是在每一步中精心筛选哪些信息能进入那有限的"注意力预算"。
无论你采用哪种具体技术------压缩、笔记、多智能体、即时检索------指导原则始终如一:
寻找最小的、高信噪比 token 集合,最大化实现预期结果的概率。
Anthropic 观察到,更智能的模型需要的"规约式工程"越来越少,Agent 的自主性越来越高。但有一点不会改变:
无论模型能力提升到何种程度,将上下文视作一种宝贵且有限的资源,始终是构建高可靠、高效智能体的核心所在。