8.3 RAG系统:知识检索增强
8.3.1 RAG的基础知识
(1)什么是RAG?
检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和文本生成的技术。它的核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
(2)基本工作流程
一个完整的RAG应用流程主要分为两大核心环节。在数据准备阶段,系统通过数据提取、文本分割和向量化,将外部知识构建成一个可检索的数据库。随后在应用阶段,系统会响应用户的提问,从数据库中检索相关信息,将其注入Prompt,并最终驱动大语言模型生成答案。
因此,检索增强生成可以拆分为三个词汇。检索 是指从知识库中查询相关内容;增强 是将检索结果融入提示词,辅助模型生成;生成则输出兼具准确性与透明度的答案。
(3)发展历程
第一阶段:朴素RAG(Naive RAG, 2020-2021)。
这是RAG技术的萌芽阶段,其流程直接而简单,通常被称为"检索-读取"(Retrieve-Read)模式。检索方式:主要依赖传统的关键词匹配算法,如TF-IDF或BM25。这些方法计算词频和文档频率来评估相关性,对字面匹配效果好,但难以理解语义上的相似性。生成模式:将检索到的文档内容不加处理地直接拼接到提示词的上下文中,然后送给生成模型。
传统匹配算法:TF-IDF或BM25
BM25是对TF-IDF的改进,主要改进了词频不再线性增长,而是"边际收益递减(TF Saturation)"
第二阶段:高级RAG(Advanced RAG, 2022-2023)
随着向量数据库和文本嵌入技术的成熟,RAG进入了快速发展阶段。研究者和开发者们在"检索"和"生成"的各个环节引入了大量优化技术。检索方式:转向基于稠密嵌入(Dense Embedding)的语义检索。通过将文本转换为高维向量,模型能够理解和匹配语义上的相似性,而不仅仅是关键词。生成模式:引入了很多优化技术,例如查询重写,文档分块,重排序等。
第三阶段:模块化RAG(Modular RAG, 2023-至今)。
在高级RAG的基础上,现代RAG系统进一步向着模块化、自动化和智能化的方向发展。系统的各个部分被设计成可插拔、可组合的独立模块,以适应更多样化和复杂的应用场景。检索方式:如混合检索,多查询扩展,假设性文档嵌入等。生成模式:思维链推理,自我反思与修正等。
8.3.4 RAG系统架构设计

这种分层设计的优势在于每一层都可以独立优化和替换,同时保持整体系统的稳定性。
整个处理流程如下所示:
任意格式文档 → MarkItDown转换 → Markdown文本 → 智能分块 → 向量化 → 存储检索
(1)多模态文档载入
RAG系统的核心优势之一是其强大的多模态文档处理能力。系统使用MarkItDown作为统一的文档转换引擎,它是HelloAgents RAG系统的核心组件,负责将任意格式的文档统一转换为结构化的Markdown文本。无论输入是PDF、Word、Excel、图片还是音频,最终都会转换为标准的
Markdown格式,然后进入统一的分块、向量化和存储流程。
支持格式:
- 文档:PDF、Word、Excel、PowerPoint
- 图像:JPG、PNG、GIF(通过OCR)
- 音频:MP3、WAV、M4A(通过转录)
- 文本:TXT、CSV、JSON、XML、HTML
- 代码:Python、JavaScript、Java等(2)智能分块策略
经过MarkItDown转换后,所有文档都统一为标准的Markdown格式。这为后续的智能分块提供了结构化的基础。HelloAgents实现了专门针对Markdown格式的智能分块策略,充分利用Markdown的结构化特性进行精确分割。
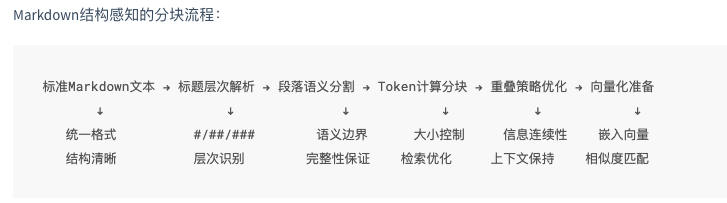
(3)统一嵌入与向量存储
嵌入模型是RAG系统的核心,它负责将文本转换为高维向量,使得计算机能够理解和比较文本的语义相似性。RAG系统的检索能力很大程度上取决于嵌入模型的质量和向量存储的效率。
8.3.5 高级检索策略
HelloAgents实现了三种互补的高级检索策略:多查询扩展(MQE)、假设文档嵌入(HyDE)和统一的扩展检索框架。
(1)多查询扩展(MQE)
多查询扩展(Multi-Query Expansion)是一种通过生成语义等价的多样化查询来提高检索召回率的技术。
就是把问题多换几种说法,多问几个
这种方法的核心洞察是:同一个问题可以有多种不同的表述方式,而不同的表述可能匹配到不同的相关文档。例如,"如何学习Python"可以扩展为"Python入门教程"、"Python学习方法"、"Python编程指南"等多个查询。通过并行执行这些扩展查询并合并结果,系统能够覆盖更广泛的相关文档,避免因用词差异而遗漏重要信息。
(2)假设文档嵌入(HyDE)
假设文档嵌入(Hypothetical Document Embeddings,HyDE)是一种创新的检索技术,它的核心思想是"用答案找答案"。
即先去生成一个伪答案,然后拿这个伪答案去检索
传统的检索方法是用问题去匹配文档,但问题和答案在语义空间中的分布往往存在差异------问题通常是疑问句,而文档内容是陈述句。HyDE通过让LLM先生成一个假设性的答案段落,然后用这个答案段落去检索真实文档,从而缩小了查询和文档之间的语义鸿沟。
这种方法的优势在于,假设答案与真实答案在语义空间中更加接近,因此能够更准确地匹配到相关文档。
(3)扩展检索框架
HelloAgents将MQE和HyDE两种策略整合到统一的扩展检索框架中。系统通过enable_mqe和enable_hyde参数让用户可以根据具体场景选择启用哪些策略:对于需要高召回率的场景可以同时启用两种策略,对于性能敏感的场景可以只使用基础检索。
扩展检索的核心机制是"扩展-检索-合并"三步流程。首先,系统根据原始查询生成多个扩展查询 (包括MQE生成的多样化查询和HyDE生成的假设文档);然后,对每个扩展查询并行执行向量检索,获取候选文档池;最后,通过去重和分数排序合并所有结果,返回最相关的top-k文档。这种设计的巧妙之处在于,它通过candidate_pool_multiplier参数(默认为4)扩大候选池,确保有足够的候选文档进行筛选,同时通过智能去重避免返回重复内容。