前言:本文将来简单讲解一下多线程模式下对于不同容器的选择,以及和传统hash使用上的差异以及优化。理解浅薄,如有纰漏,还请大佬指出qaq~~
一,线程安全的容器
在多线程模式下,线程安全就是一个不可避免的问题,为此java为我们提供了一些线程安全的集合类供我们使用,使得不必担心线程安全问题。
这些集合类按照类来划分的话,总共顺序表ArrayList,队列Queue以及哈希表Hash这三大类。
二,copyOnWriteArrayList
在多线程模式下如果想要使用顺序表ArrayList这种数据结构,首先推荐copyOnWriteArrayList
多线程下假如使用ArrayList来对元素增删改查的话,很可能会出现线程安全问题导致数据访问不一致的事情发生。原因在于多个线程同时修改同一个变量。使用copyOnWriteArrayList就可以很好的解决这一点。
(一)如何解决线程安全问题?
1.读写分离,写时拷贝
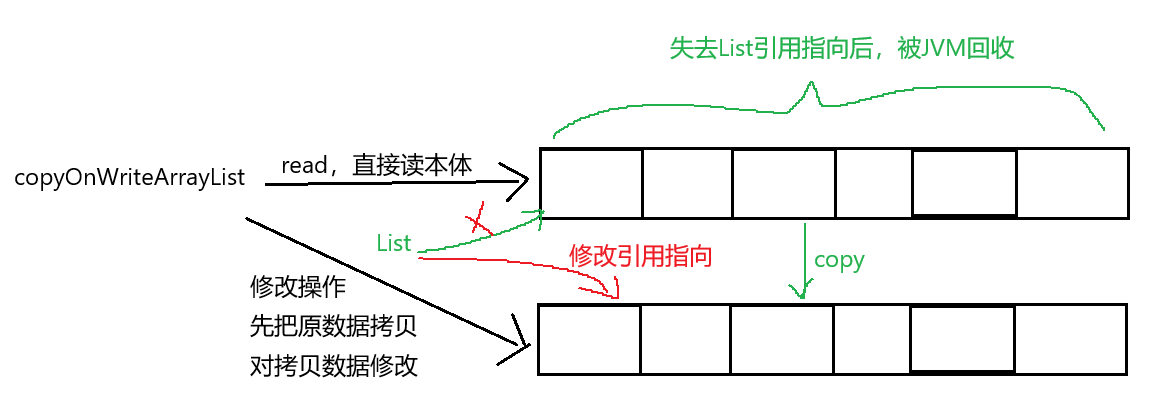
copyOnWriteArrayList的核心就在于 copyOnWrite写时拷贝这一点上。在多线程读取同一个变量时,天然线程安全,这个不必多说。copyOnWriteArrayList 使得在线程修改数据时不会对本体做出修改,而是先对原数据拷贝一份,在新的数据体上进行修改操作。修改完成之后,把原来旧数据对象的引用 修改,令其指向新的拷贝数据。那么旧的数据应该如何处理?(当然是放转转上回收啦~bushi)旧的数据由于其所处内存失去了引用指向,就被JVM自动回收了。
copyOnWriteArrayList 这种读写分离的策略使得读取read是在数据本体上读取,但是在write操作时选择开辟内存空间,保证了多线程访问数据的一致性。
(二)缺陷
1.数据量庞大
这种写时拷贝的方式在拷贝对象数据量很大时不建议使用,假如拷贝的对象数据有几十万条,那么拷贝带来的开销可能比加锁阻塞的开销还要大
2.读少写多
在对共享数据读操作的频率远远小于写操作的频率时也不建议使用这种写时拷贝的方式。毕竟每一次修改都需要拷贝一次原数据,即使数据本体所占内存可能不是很大,但是修改次数多了每次小开销累加在一次就很大了。
三,多线程下使用队列Queue
多线程模式下如何使用队列?总共提供了以下这几种常见的队列类供使用,这里只简单介绍一下其功能以及差异
(一).ArrayBlockingQueue
基于数组Array实现,创建时需要先指定初始容量capacity,添加数据超出容量时会进入wait状态等待消费者线程从队列中拿取数据。
java
ArrayBlockingQueue queue = new ArrayBlockingQueue(10);//初始容量为10(二).LinkedBlockingQueue
基于链表实现,没有限定初始容量,但是当生产者添加数据的速度远大于消费者线程拿取数据速度时,存在栈溢出的风险。
java
LinkedBlockingQueue queue = new LinkedBlockingQueue();(三).PriorityBlockingQueue
优先级队列,一改传统队列先进先出的规则,而是依据任务的优先级来安排任务的执行顺序,优先级高的先出队列
java
PriorityBlockingQueue queue = new PriorityBlockingQueue();(四).TransferQueue
这种队列的核心功能是**直接交付,**阻塞队列的功能在我理解来看好比一个中转仓库,传承阻塞队列中生产者把任务存储到仓库中就不再参与后续调度。好比快递员直接把快递寄存在驿站中。
但是TransferQueue的生产者比较负责,当它获取到一个任务时,不会存入队列中,而是做一个判断
1,如果当前有消费者线程空闲,此时不再把任务发给队列,而是直接交付给消费者
2.没有消费者线程空闲,生产者线程直接阻塞,直到消费者线程来了才能恢复运行,就像快递面付,人没来就一直等,直到人来了亲手交付。
四,多线程下使用哈希表
哈希表是一种键值对映射的数据结构,优势在于可以以O(1)的时间复杂度高效的完成对数据的增删改查等操作。多线程模式下在使用Hash的情况下,为了保证数据的一致性。有以下几种方式。
(一)Hashtable
Hashtable是java中最早的哈希表,其特点是对整个哈希表容器加锁, 以此来保证线程安全的修改表中数据。通过查看Hashtable的方法源码,我们可以看到在方法头前都有synchronized关键字修饰。synchronized对方法加锁可以理解为对this引用 加锁,也就是对调用这个方法的哈希容器加锁。
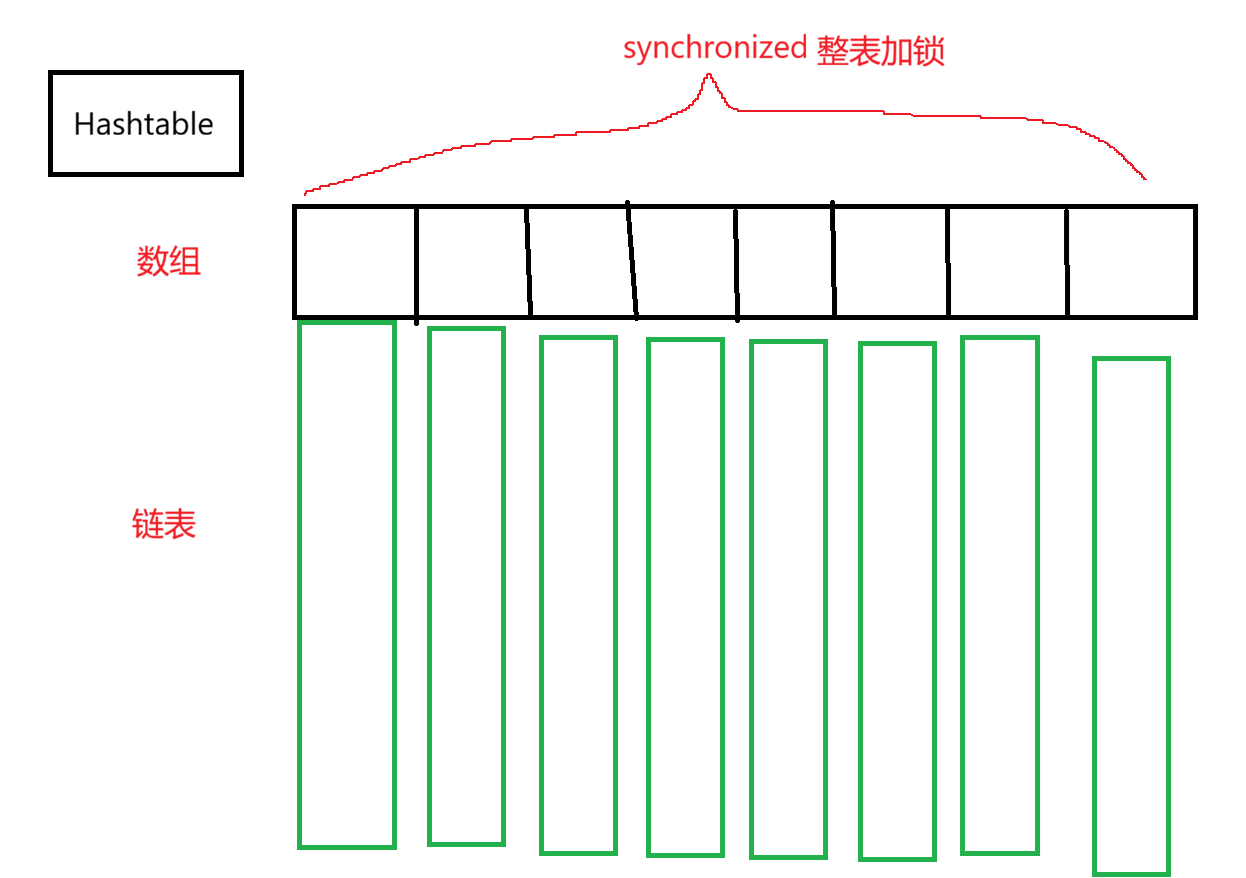
通过对整个容器加锁,就可以使得同一时间限制了只能有一个线程来修改表中的数据,以此来做到线程安全。
但是这个方式也有一个缺陷,Hashtable限制了哈希表在同一时间只能被一个线程修改,其他线程试图修改表中数据就会产生锁竞争引发阻塞。这种方式效率太低,假如线程A修改的数据和线程B的数据不一样,阻塞就是无效阻塞(过于敏感肌了)。
虽然Hashtable可以规避线程安全问题出现,但由于Hashtable并发效率过差,其也慢慢被ConcurrentHashMap所取代
(二)ConcurrentHashMap
ConcurrentHashMap作为取代者,其设计相较于Hashtable自然有其精妙之处
1.引入多把锁,降低锁冲突概率
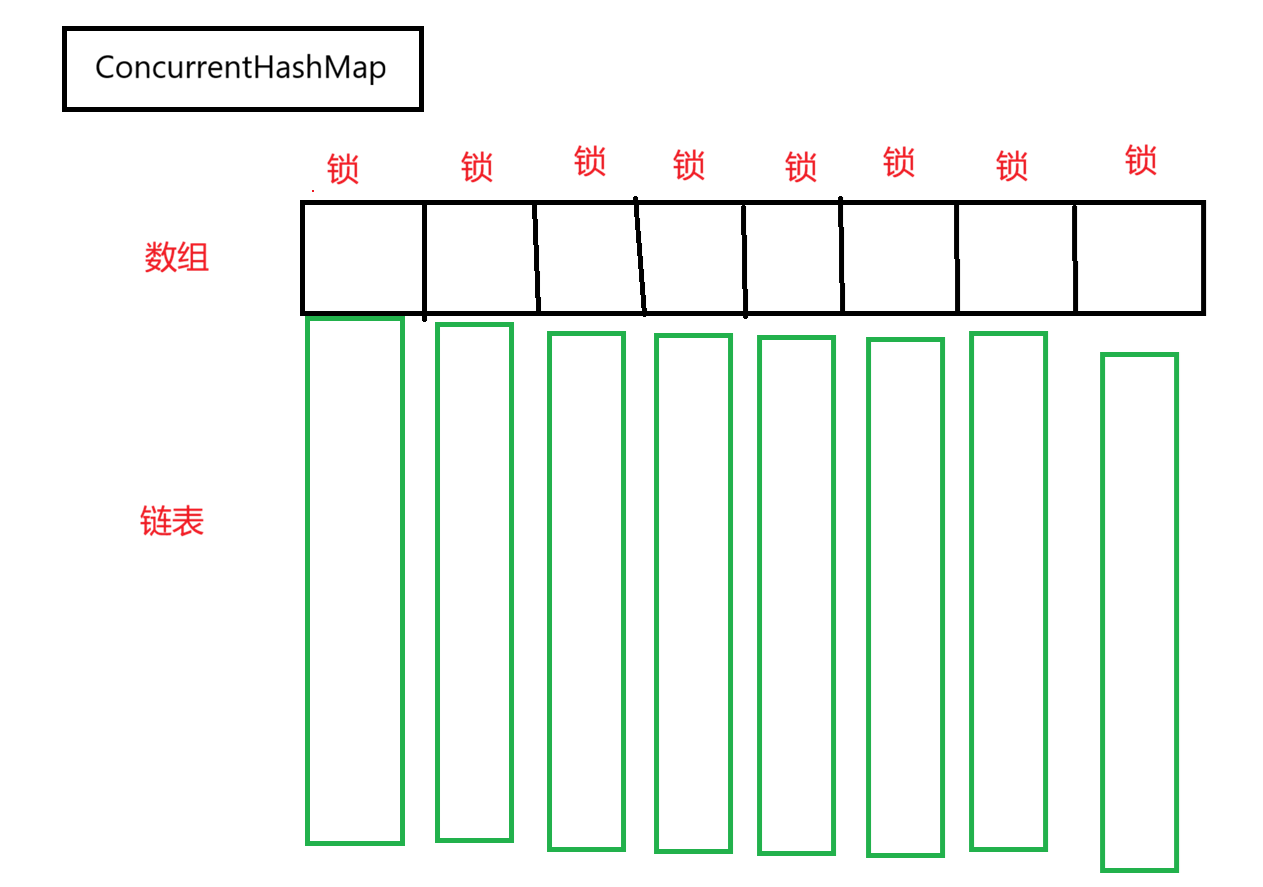
前文中Hashtable是全表共用一把锁,这样锁冲突的概率就很大。ConcurrentHashMap引入了多把锁来实现线程安全。
ConcurrentHashMap通过对数组中的每一个链表的头结点加锁。相较于整表加锁,多个线程同时修改同一条链表的概率就降低了。只有当两个线程都修改同一个锁对象上的数据,才会产生锁竞争。由于锁对象可以是任意对象,不需要额外开辟空间分配锁对象,只需要把链表头节点head作为锁对象即可。**这里要注意:加锁的开销大头不是分配锁带来的开销,而是产生锁竞争带来的阻塞等待的开销。**不必担心在数组规模较大的情况下,创建锁对象会带来很大的空间开销。
2.CAS维护哈希表长度
哈希表元素的变化涉及到对表长size的维护,这样一来多线程修改size同样会导致 线程安全问题。
ConcurrentHashMap使用了CAS操作来实现无锁安全修改
3.数组扩容,开销均衡
全表元素个数 >= 表容量 * 负载因子(0.75)时哈希表会进行扩容操作,这样会导致一个问题。阈值的增加是由add导致的。那么假如多线程同时add操作,有一个线程的add()恰好达到了负载因子的阈值,就会进行数组扩容操作,以此来增加哈希桶的数目,避免了出现某个桶上的链表过长的情况出现。
但扩容操作带来的开销会导致某个线程操作时间过长的情况出现,假如这个线程的操作是其他线程任务的前置,那么其他线程就需要等待这个线程结束操作,有点费时了。ConcurrentHashMap提供了一个操作就是把扩容带来的开销平摊给所有的线程一起完成,毕竟达到负载因子的阈值又不是我这个线程一个干的,凭什么要让我这个线程单独负责。这样一来,扩容开销均摊就可以规避多线程下某个线程触发扩容导致耗时过长的场景出现。