论文题目:Annotation Ambiguity Aware Semi-Supervised Medical Image Segmentation
论文原文(paper) :https://openaccess.thecvf.com/content/CVPR2025/html/Kumari_Annotation_Ambiguity_Aware_Semi-Supervised_Medical_Image_Segmentation_CVPR_2025_paper.html
GitHub 仓库链接 :https://github.com/AITricks/AITricks会议:CVPR 2025
关键词:医学图像分割、半监督学习、不确定性估计、多专家标注
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景与痛点](#2.1 文本背景与痛点)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解](#4.2 核心创新模块详解)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验分析](#6. 实验分析)
- 总结
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一个名为 AmbiSSL 的新颖框架,旨在同时解决医学图像分割中"高质量标注稀缺"和"专家标注存在歧义(Ambiguity)"两大难题。核心思想是利用**随机剪枝(Randomized Pruning)**构建多样化的解码器,从而在无标签数据上生成多样性的伪标签(Diverse Pseudo-labels)。结合半监督隐分布学习(SSLDL),模型能够利用极少量的多专家标注数据和海量无标签数据,学习到一个能够生成多种合理分割结果的共享隐空间,从而模拟临床诊断中的真实不确定性。
2. 背景与动机
2.1 文本背景与痛点
深度学习在医学图像分割中取得了显著进展,但在临床落地时面临两个主要障碍:
- 数据获取难 :获取大量像素级精度的医学标注数据极其昂贵且耗时。虽然半监督学习(SSL)利用无标签数据缓解了这一问题,但现有SSL方法通常只输出单一的确定性掩膜。
- 固有模糊性(Ambiguity):由于病灶边界模糊、成像对比度低或专家主观经验差异,医学图像往往没有唯一的"标准答案",多位专家可能给出不同的标注。忽略这种模糊性会误导下游诊断。
现有的方法要么只做半监督(忽略模糊性),要么只做模糊感知分割(依赖全量多专家标注),缺乏将二者结合的有效方案。
2.2 动机图解分析
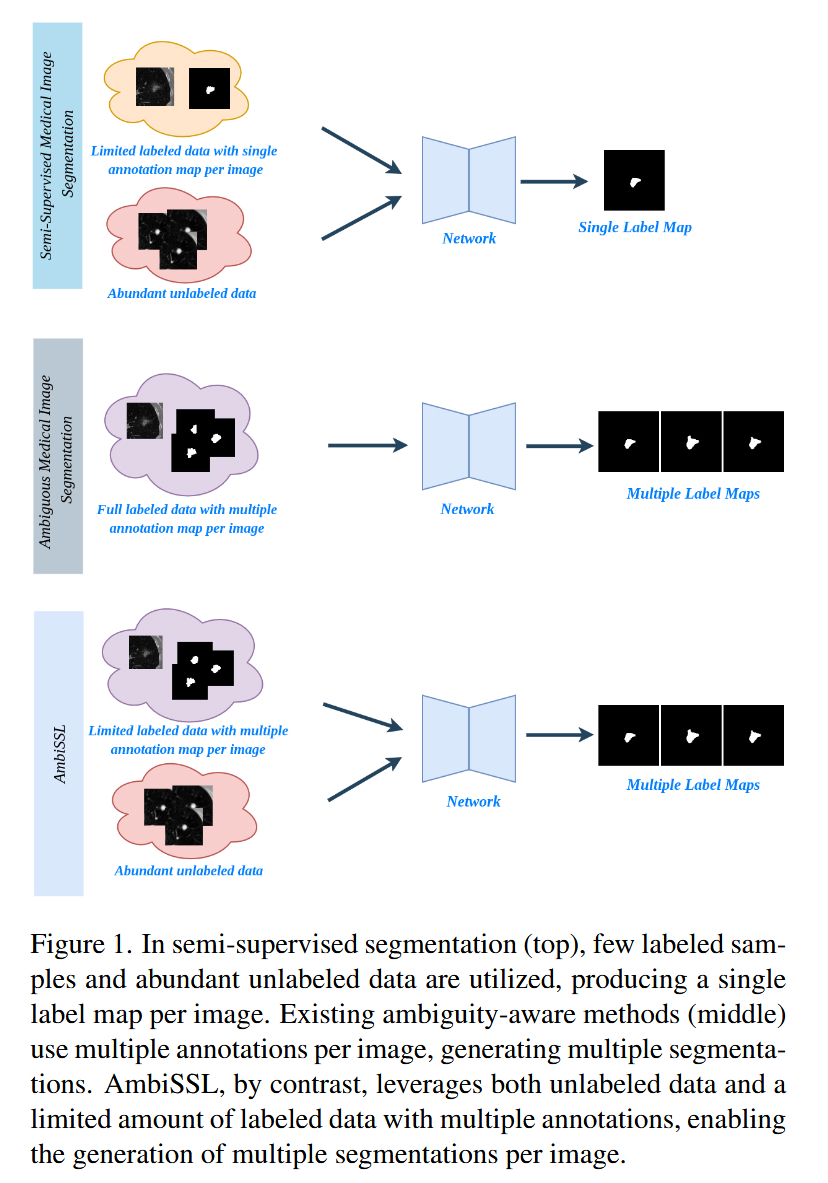
看图说话:
- Top (传统半监督分割) :如图1上部分所示,传统SSL方法利用少量有标签数据和大量无标签数据,但最终网络通过简单的"输入-输出"映射,强制对每个图像生成单一的标签图(Single Label Map)。这掩盖了病灶可能存在的多种形态。
- Middle (现有模糊感知分割) :如图1中间部分所示,这类方法虽然能生成多个标签图(Multiple Label Maps)来反映不确定性,但它们严重依赖全量有标签数据(Full labeled data),无法利用容易获取的无标签数据,导致数据利用率低。
- Bottom (本文 AmbiSSL) :如图1下部分所示,AmbiSSL填补了上述两者的空白。它既利用了无标签数据(Abundant unlabeled data),又只需要极少量的多专家标注数据(Limited labeled data),最终实现了"利用半监督数据生成多模态分割结果"的目标。
3. 主要创新点
- 首个模糊感知半监督框架:率先在半监督医学图像分割任务中引入注释模糊性感知,打破了SSL只能输出确定性结果的限制。
- 多样化伪标签生成模块 (DPG):提出通过对解码器进行随机剪枝(Randomized Pruning)来构建多个差异化解码器,从而为无标签数据生成多样且合理的伪标签集。
- 半监督隐分布学习 (SSLDL) :构建了一个共享隐空间,针对有标签数据使用正态分布建模,而针对伪标签数据创新性地使用拉普拉斯分布建模,以增强对伪标签噪声的鲁棒性。
- 交叉解码器监督 (CDS):利用剪枝解码器之间的差异性,通过交叉监督机制让它们互相指导学习,提升了特征提取的互补性和模型的泛化能力。
4. 方法细节
4.1 整体网络架构
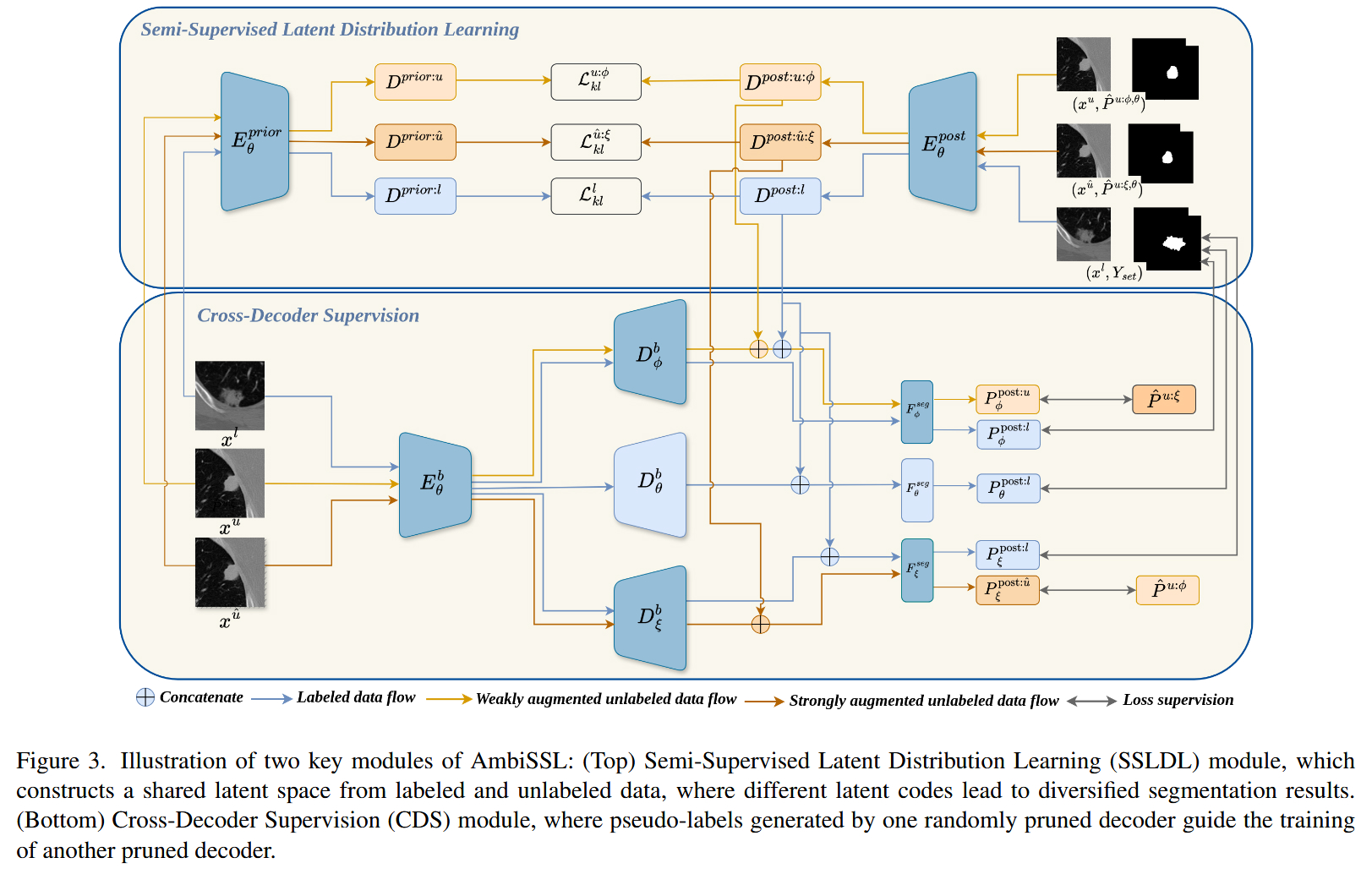
AmbiSSL 的整体数据流是一个基于 Probabilistic U-Net 改进的变分自编码器(VAE)结构,并融入了半监督逻辑:
- 输入流 :图像 x x x 输入到主干编码器 E θ b E^b_{\theta} Eθb 提取特征。
- 隐变量流 :
- 先验网络 (Prior Net) :仅根据图像 x x x 预测隐变量分布。
- 后验网络 (Posterior Net) :根据图像 x x x 和标注集合 Y s e t Y_{set} Yset(或伪标签集)预测隐变量分布。
- 解码与输出 :从分布中采样的隐向量 z z z 与主干特征拼接,输入到三个并行的解码器(主解码器 D θ b D^b_{\theta} Dθb + 两个剪枝解码器 D ϕ b , D ξ b D^b_{\phi}, D^b_{\xi} Dϕb,Dξb),最终输出多样化的分割图。
4.2 核心创新模块详解
模块 A:多样化伪标签生成 (DPG)
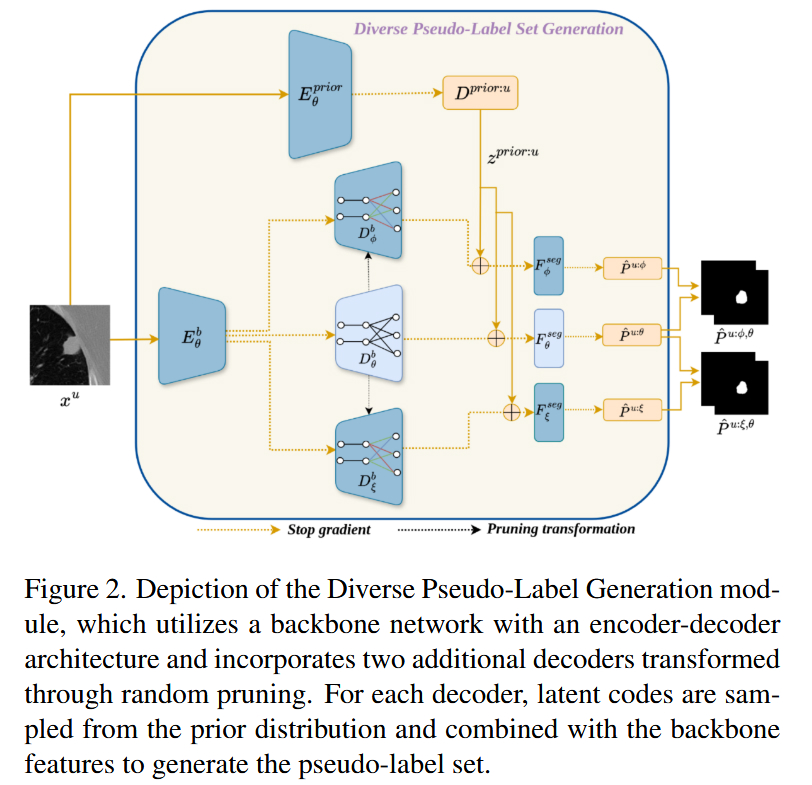
-
内部结构与流向:
该模块的核心在于如何从无标签数据中"无中生有"地创造多样性。
- 随机剪枝 (Pruning) :基于主干解码器 D θ b D^b_{\theta} Dθb,通过对最后几层的权重矩阵应用随机掩膜(Mask),生成两个变体解码器 D ϕ b D^b_{\phi} Dϕb 和 D ξ b D^b_{\xi} Dξb。
- 特征差异化:由于权重被随机部分置零,即使输入相同的特征,三个解码器也会产生略有差异的特征表达。
- 伪标签生成 :从先验分布中采样隐向量 z z z,分别输入这三个解码器,生成三个不同的伪分割图 P ^ \hat{P} P^。
- 集成增强:为了提高伪标签质量,论文还将不同解码器的输出进行集成(Ensemble),形成最终用于训练的伪标签集。
模块 B:半监督隐分布学习 (SSLDL)
-
设计理念:
这是为了让模型学习到一个能够编码"分割风格"的隐空间。
- 有标签数据 :使用标注集 Y s e t Y_{set} Yset 计算后验分布,强制先验分布(仅看图)去逼近后验分布(看图+看答案)。这里采用多元正态分布。
- 无标签数据(创新点) :使用DPG模块生成的伪标签集 P ^ s e t \hat{P}_{set} P^set 代替真实标注来计算后验。
- 关键机制:对于无标签数据,作者使用**拉普拉斯分布(Laplace Distribution)**而不是正态分布来建模。
- 为什么用拉普拉斯? 因为伪标签不可避免地包含噪声。正态分布对离群点(Outliers)非常敏感(平方惩罚),而拉普拉斯分布的拖尾更长,对错误标签的容忍度更高,避免模型对伪标签过度自信(Overfitting)。
模块 C:交叉解码器监督 (CDS)
-
工作机制:
类似于半监督中的"Co-training"思想。
- 解码器 ϕ \phi ϕ 生成的预测结果,作为解码器 ξ \xi ξ 的监督信号(伪真值)。
- 反之亦然。
- 这种交叉机制强迫两个经过不同剪枝的解码器去学习互补的特征,修正彼此的认知偏差。
4.3 理念与机制总结
AmbiSSL 的成功在于它建立了一个协同进化的闭环:
- 随机剪枝提供了初始的"差异性视图"(View Diversity)。
- 隐分布学习(特别是拉普拉斯分布)将这种差异性安全地编码进隐空间,防止噪声干扰。
- 交叉监督利用这种差异性进行相互校准,提升模型在无标签数据上的泛化能力。
最终,这个系统解决了动机图中提出的核心问题:利用无标签数据填补了"单一结果"与"多专家不确定性"之间的鸿沟。
5. 即插即用模块的作用
本文提出的技术具有很强的通用性,以下是可独立应用场景:
- 随机剪枝解码器 (Randomized Pruned Decoders) :
- 适用场景:任何需要**模型集成(Ensemble)**效果但显存受限的场景。
- 应用:通过剪枝最后几层而不是训练多个完整模型,可以低成本地获取不确定性估计或提升泛化能力。
- 拉普拉斯分布伪标签建模 (Laplace for Pseudo-labels) :
- 适用场景:所有涉及**伪标签(Pseudo-labeling)**的半监督学习任务。
- 应用:当你怀疑伪标签质量不高、存在噪声时,使用拉普拉斯分布代替KL散度中的正态分布,可以显著防止模型在错误标签上过拟合。
- 交叉解码器监督 (CDS) :
- 适用场景:多分支网络的训练。
- 应用:在多任务学习或多模态学习中,让不同分支互相"教学",是提升特征鲁棒性的通用策略。
6. 实验分析
论文在两个公开数据集上进行了验证:LIDC-IDRI (肺结节,4位专家标注)和 ISIC(皮肤病变,3位专家标注)。
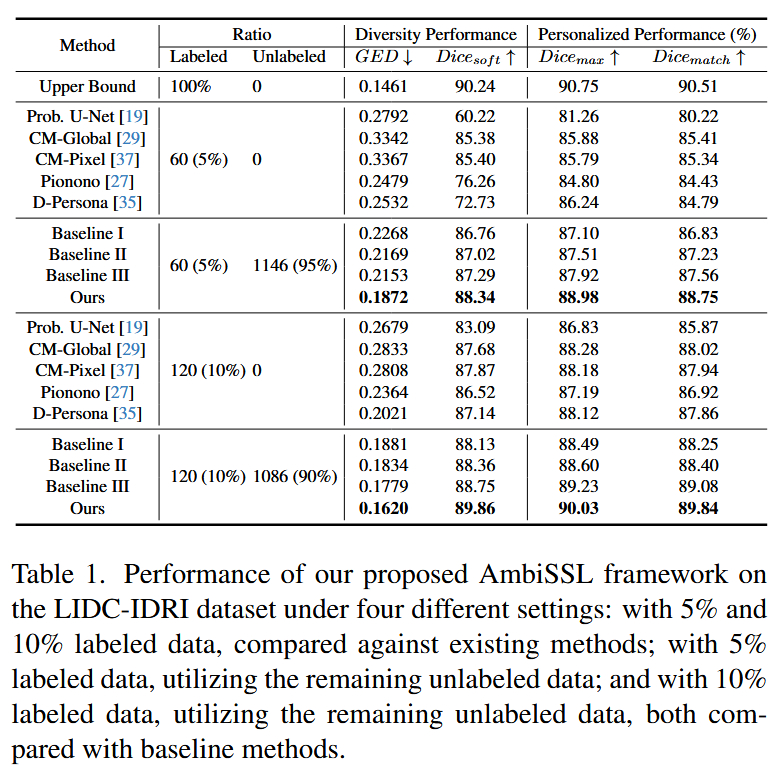
实验结论关键点:
- 极少标签下的优越性 :仅使用 5% 或 10% 的有标签数据,AmbiSSL 的表现(GED和Soft Dice指标)就显著优于现有的半监督方法(如Baseline I/II/III)和模糊感知方法(如Prob U-Net)。
- 数据利用效率:对比实验显示,引入无标签数据后,AmbiSSL 的性能大幅提升,证明了该框架有效地从无标签数据中挖掘出了有用的不确定性信息。
- 多样性与准确性并存:GED指标(越低越好)的下降表明生成的分割图分布与专家的一致性很高,而不是盲目地生成杂乱的掩膜。
总结
AmbiSSL 为医学图像分析提供了一个非常优雅的思路:不确定性不仅仅是需要被"消除"的噪声,更是可以通过无标签数据去"学习"的特征。通过随机剪枝构建差异,通过分布对齐学习共性,这篇CVPR 2025的论文值得所有关注半监督学习和医学AI的研究者细读。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。