🌸作者主页:努力努力再努力wz


💪 今日博客励志语录 :
别害怕选错,人生最遗憾的从不是'选错了',而是'我本可以'。每一次推倒重来的勇气,都是在给灵魂贴上更坚韧的勋章。
★★★ 本文前置知识:
序列化与反序列化
引入
在之前的博客中,我详细介绍了序列化 与反序列化 的概念。对于使用 TCP 协议进行通信的双方,由于 TCP 是面向字节流的,在发送数据之前,我们通常需要定义一种结构化的数据来描述传输内容,并以此作为数据的容器。在 C++ 中,这种结构化数据通常表现为对象或结构体。然而,我们不能直接将结构体内存中对应的字节原样发送到另一端,因为直接传递内存字节会引发字节序 和结构体内存对齐 的问题。不同平台、不同编译器所遵循的内存对齐规则可能不同,这可能导致接收方在解析结构体字段时出现错误。
因此,我们需要借助序列化 。序列化 是指将结构化的数据按照预定的规则转换为连续的字节流。其主要目的是屏蔽平台差异,使得位于不同平台的进程能够以统一的方式解析该字节流。序列化通常分为两种形式:文本序列化 与二进制序列化 。
文本序列化将结构化的数据转换为一个完整的字符串。字符串本身是以字符为单位的连续序列,每个字符通常占用一个字节,因此字符串本质上也是一个连续的字节流。由于字符串以字符为单位解析,不存在字节序问题。通信双方只需约定字符串的格式与编码方式,即可正确解析该字符序列,最终将连续的字节流还原为结构化的数据。
二进制序列化则直接发送数据在内存中的原始二进制序列,无需额外转换。这两种方式各有优劣:文本序列化直观、可读性高、便于调试;而二进制序列化发送的是二进制数据,人类难以直接阅读。文本序列化会将数据转换为字符形式,可能导致传输体积增大------例如整数 100000 在文本序列化中会被转换为 "100000" 占 6 个字节,而作为 int 类型的二进制序列化仅需 4 个字节。因此,二进制序列化在传输体积上通常更小。此外,文本序列化还需要对字符串进行解析以恢复原始数据,而二进制序列化的解析开销通常更低,因为它直接对应数据的原始二进制表示。
| 特性 | 文本序列化 (JSON/XML) | 二进制序列化 (Protobuf/Thrift) |
|---|---|---|
| 可读性 | 极高(肉眼可读) | 低(十六进制乱码) |
| 传输体积 | 较大(数字变字符,带大量引号) | 极小(紧凑编码) |
| 解析速度 | 较慢(需字符串扫描、词法解析) | 极快(直接偏移寻址或位运算) |
| 跨语言 | 完美(天然支持) | 优秀(需编译 IDL 文件) |
在上一篇博客中,我们手动实现了文本序列化,即将结构体各字段按一定格式拼接为完整字符串。我之所以手动实现,是为了帮助大家理解序列化的基本原理,并为本文内容做铺垫。
然而在实际开发中,我们通常不需要从头实现序列化,可以使用成熟的第三方库来完成这项工作。这些库的实现通常更完善、更高效。本文将介绍的第一个主题------JSON ,就是一种广泛应用的文本序列化格式。
JSON
首先,介绍一下什么是 JSON 。JSON (JavaScript Object Notation)是一种轻量级、基于文本、人类可读的数据交换格式。JSON 源于 JavaScript,借鉴了其对象和数组的表示方法。但由于 JSON 本身是文本格式,且所表示的基本数据类型(如整型、布尔值等)在绝大多数编程语言中都得到支持,因此JSON 并不局限于 JavaScript,而是能够被多种编程语言解析与生成。正因如此,JSON 不仅具备跨平台 能力,还能实现跨语言 的数据交换。
了解 JSON 的基本定义后,我们进一步探讨其本质。如上所述,JSON 实质上是一种文本序列化的方式。在此之前,我们曾手动实现过文本序列化,其核心原理是将结构体的各个字段按照特定格式拼接为一个完整的字符串。因此,JSON 的本质其实就是符合 JSON 规范(风格)的字符串。
理论上,只要我们清楚 JSON 格式的规范,就可以利用字符串操作函数手动拼接出符合 JSON 风格的字符串,而无需借助第三方库。字符串拼接本身并不复杂,因此自然引出一个疑问:相比手动实现,第三方库的优势究竟在哪里?如果仅实现序列化(即转换为 JSON 字符串),那么使用第三方库似乎并未显著减轻负担,因为序列化这一步本身并不困难。要回答这个问题,我们首先需要明确 JSON 风格字符串的具体形式,进而理解第三方库所承担的工作。这一点我们稍后再展开。
JSON 支持若干基本数据类型 ,例如整型、浮点型和布尔型,也支持字符串 、对象 等复杂类型:
| JSON 类型 | C++ 对应类型 | 描述 |
|---|---|---|
| Number | int, double, float |
JSON 不区分整数和浮点数,统一视为数字。 |
| Boolean | bool |
只有 true 和 false 两个字面值。 |
| String | std::string |
必须使用 双引号 包围,支持转义字符(如 \n, \t)。 |
| Null | nullptr / NULL |
表示空值或不存在,常用于可选字段。 |
需注意,基本数据类型(如整型、浮点型)可直接书写,而字符串类型必须用双引号括起来。
如果我们需要将一个对象或结构体的数据传递给另一端,在未接触 JSON 时,通常需要手动将其各字段拼接成字符串,再发送该字符串的字节流。而 JSON 可以直接表示对象,其方法是用一对大括号包裹内容,括号内是一个或多个键值对 。每个键值对 中,键与值之间用冒号分隔,不同键值对之间用逗号分隔。
这里的键值对对应于结构体或对象的成员变量:键表示成员名称,值表示该成员的取值。这种表示方式不仅书写方便,也能直观体现对象结构及其属性值:
json
{
"age": 20,
"sex": "girl",
"height": 160
}需要注意的是,值可以是任意基本类型,但键必须是字符串类型。
对于数组,JSON 使用中括号表示,括号内为数组元素,各元素之间以逗号分隔。数组元素可以是基本类型,也可以是对象等复杂类型:
json
[
100,
"bob",
{
"id": 1234,
"name": "mike"
}
]了解 JSON 字符串的格式后,我们可以回应前文提出的问题:既然已知对象用花括号表示、键值对用逗号分隔,数组用中括号表示、元素间用逗号分隔,我们确实可以通过字符串拼接函数,将结构化数据转换为符合 JSON 格式的字符串。
然而,如果需要修改对象中某一字段的值,通常有两种做法:一是修改原始结构体的值,然后重新拼接整个字符串;二是直接修改已拼接好的字符串(在不改动原始数据的情况下)。第二种方式需要定位字符串中的特定字段,进行覆盖并调整后续字符位置,过程较为繁琐。此外,在序列化过程中,某些字符(如双引号、反斜杠等)需要进行转义处理,这也增加了手动实现的复杂度。
更重要的是,除了序列化,我们还需考虑反序列化------即将 JSON 字符串解析并还原为原始数据。根据上述 JSON 格式,反序列化需识别键值对、分离键与值,并将值转换回对应数据类型。若遇到嵌套对象(即对象中某个属性的值仍为对象),则需递归处理,实现难度显著增加:
json
{
"id": 1234,
"name": "bob",
"person": {
"id": 125,
"name": "kie"
}
}如果序列化与反序列化均自行实现,那么在序列化时若遗漏逗号或括号,将给反序列化带来极大困难,甚至导致解析失败。
因此,引入第三方库显得十分必要。其优势不仅在于提供高效的序列化与反序列化功能,更在于它提供了一系列功能丰富的接口,用于直接操作 JSON 对象内部维护的结构化原始数据 。这些库通常通过一个与编程语言相对应的数据结构(在 C++ 中通常是一个类对象 )来映射和承载解析后的 JSON 数据,同时提供成员函数来方便地进行相关操作。
在 C++ 中,常用的 JSON 库包括json.hpp (即 nlohmann/json)。它提供的 JSON 对象可被视为一个容器,用于存储要发送或解析的 JSON 数据,并封装了丰富的操作方法,大大简化了 JSON 的处理流程。
这里需要注意,nlohmann/json 是一个第三方库,这意味着 C++ 标准库并不包含该库,因此我们需要自行引入。本文采用的方式是:获取官方json.hpp 源代码文件,将其全部内容复制到 Linux 系统下的相应目录中并保存。当然,引入该库还有其它多种方法,在此不再赘述。
需要明确的是,该第三方库维护了一个类, 该类可实例化为一个 JSON 对象。它不仅作为数据容器,还能以更灵活的方式支持我们对内部结构化数据的管理与维护。通过该对象提供的函数,我们可以直接操作数据项,而不需要去关心底层字符串的具体拼写格式。
首先关注其使用方法,即如何操作这个json 对象。json 类的定义位于json.hpp 中的nlohmann 命名空间内,因此我们需要指定该命名空间,随后创建一个json 对象。
json 对象最常见的数据类型是对象(object)和数组(array)。初始化一个 json 对象主要有两种方式。第一种是通过构造函数完成,由于json.hpp 支持 C++11,我们可以使用列表初始化的语法。
如前所述,JSON 对象的内容由一系列键值对组成。在列表初始化中,可以直接向构造函数传递一系列std::pair 对象,每个 pair 对应一个键值对。
cpp
nlohmann::json j = {
{"name", "WZ"},
{"age", 20},
{"gender", "girl"}
};除了通过构造函数进行初始化,另一种更推荐的方式是直接使用赋值运算符。可以这样理解:若 json 对象存储的是 JSON 对象,其内部实际上维护了一个字典(即哈希表)。更详细的实现原理将在后文说明。
我们知道哈希表内部存储键值对,并重载了
"\[\]" 运算符。若哈希表中不存在指定的键,则会插入对应的键值对,从而完成初始化。这种方式不仅方便,也更符合 C++ 标准库容器的使用习惯,其效果与上述列表初始化相同,因此本人更推荐此种写法:
cpp
nlohmann::json j;
j["name"] = "wz";
j["age"] = 20;
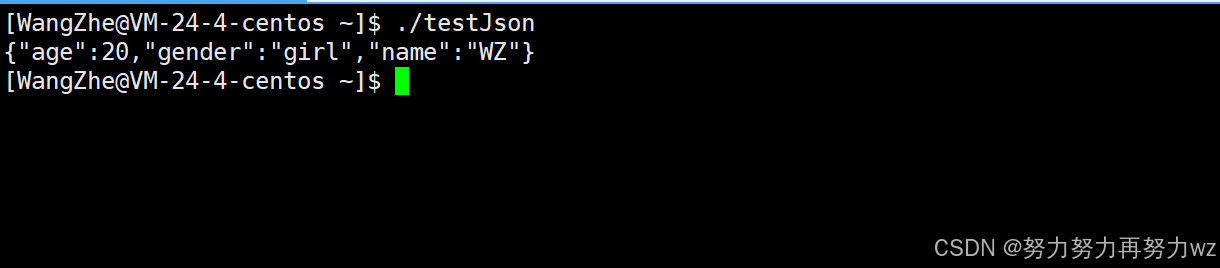
j["gender"] = "girl";了解如何创建json 对象后,下一步是进行序列化。json 类提供了dump() 成员函数用于序列化,其返回类型为std::string 。因为 JSON 本质上是一个具有特定格式的字符串,而dump() 的返回值正是该格式的字符串表示。该函数可接收一个整数参数,若不传递参数,则默认生成紧凑格式(compact)的字符串。紧凑格式是指所有键值对均在同一行内输出,键值对之间仅以逗号分隔,不包含换行与额外空格,因此可读性相对较低。以下代码演示其效果:
cpp
#include "json.hpp"
#include <iostream>
int main() {
nlohmann::json j = {
{"name", "WZ"},
{"age", 20},
{"gender", "girl"}
};
std::string name = j["name"];
std::string s = j.dump();
return 0;
}
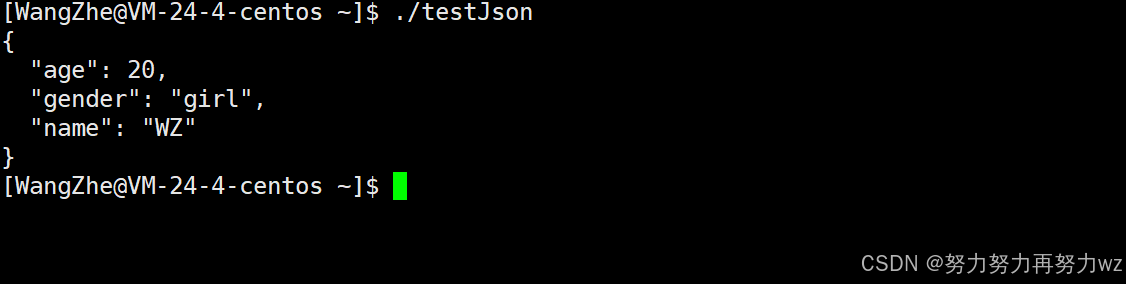
若向dump() 传递一个整型参数,则输出的字符串会进行格式化:每个键值对单独占一行,并且该参数值表示每一级缩进的空格数。例如,若参数值为 2,则每对键值前会有 2 个空格。如果 JSON 对象中嵌套了其他对象或数组,内层元素会根据嵌套深度进一步增加缩进。具体而言,设嵌套深度为 n(n ≥ 0),每级缩进空格数为 m,则某键值对前的空格总数为 (n + 1) * m。此规则不必强记,了解即可。
以下以dump(4) 为例说明其视觉格式:
cpp
{
"name": "WangZhe", // 第 1 层:4 个空格
"stats": { // 第 1 层:4 个空格
"level": 99, // 第 2 层:8 个空格 (4+4)
"equipment": [ // 第 2 层:8 个空格 (4+4)
"Sword", // 第 3 层:12 个空格 (8+4)
"Shield" // 第 3 层:12 个空格 (8+4)
] // 回到第 2 层缩进
} // 回到第 1 层缩进
}在原先的代码基础上,我们可令序列化后的 JSON 字符串使用 2 格缩进,观察其效果:
cpp
#include "json.hpp"
#include <iostream>
int main() {
nlohmann::json j = {
{"name", "WZ"},
{"age", 20},
{"gender", "girl"}
};
std::string name = j["name"];
std::string s = j.dump();
return 0;
}
通常不建议在序列化时添加缩进,因为缩进虽然提高了可读性,但也会引入额外的换行符和空格,从而增加字符串的体积。若 JSON 数据包含大量键值对或嵌套层次较深,这种体积增长会在网络传输等场景中带来额外开销。因此,一般情况下建议调用dump() 时不传入参数。
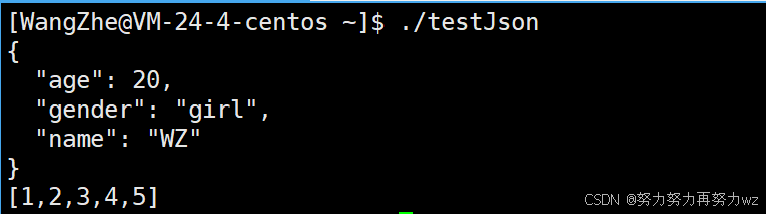
接下来介绍如何初始化表示数组的json 对象。初始化数组同样有两种方法:第一种仍然是通过构造函数的列表初始化,但此时传递的是值(而非键值对),构造函数会据此完成初始化:
cpp
#include "json.hpp"
#include <iostream>
int main() {
nlohmann::json j = {
{"name", "WZ"},
{"age", 20},
{"gender", "girl"}
};
std::string s=j.dump(2);
nlohmann::json j1 = {1, 2, 3, 4, 5};
std::string s1=j1.dump();
std::cout<<s<<std::endl;
std::cout<<s1<<std::endl;
return 0;
}
第二种方式是使用 json 类提供的 push_back() 函数,该函数专用于向表示数组的 json 对象末尾添加元素。可将其简单理解为在内部维护的数组尾部插入元素,具体原理将在后文详细阐述。初始化完成后,同样可调用 dump() 进行序列化。
json 对象的功能不止于此。假设json 对象内部存储的是一个对象或者数组,我们可以像操作标准库中的哈希表或者vector一样,通过[] 运算符访问或修改其字段值:
cpp
#include "json.hpp"
#include <iostream>
int main() {
nlohmann::json j = {
{"name", "WZ"},
{"age", 20},
{"gender", "girl"}
};
std::string name = j["name"];
std::cout << name << std::endl;
j["name"] = "kiki";
std::cout << j["name"] << std::endl;
std::string s = j.dump(2);
std::cout << s << std::endl;
nlohmann::json j2 = {1, 2, 3, 4, 5};
std::cout << j2[1] << std::endl;
j2[1] = 100;
std::cout << j2[1] << std::endl;
std::string s2 = j2.dump();
std::cout << s2 << std::endl;
return 0;
}
最后介绍反序列化,即将 JSON 格式的字符串还原为json 对象。json 类提供了静态成员函数parse() ,它接收一个 JSON 格式的字符串,在内部解析后存储到 json 对象中。此过程即反序列化------将连续的字节流还原为结构化的 json 对象,其内部保存的数据即为原始内容。
为了熟悉parse() 的用法,我们编写如下代码进行验证。首先需要准备一个符合 JSON 语法的字符串。根据前面的介绍,JSON 对象由大括号包裹,数组由中括号包裹,键名与字符串值必须使用双引号。这些特殊字符在 C++ 字符串中需要使用转义字符表示,因此手动构造 JSON 字符串较为繁琐,例如:
cpp
std::string s = "{\"name\":\"WZ\",\"skills\":[\"C++\",\"Linux\"]}";为此,C++11 引入了原始字符串字面量(raw string literal)语法:R"()" 。其基本格式为:
cpp
R"delimiter( raw_characters )delimiter"其中R 指明该字符串为原始字符串,括号内为字符串内容,delimiter 为可选的分隔标识符。在原始字符串中,绝大多数字符(包括引号和换行)无需转义。仅当字符串内容本身包含")" 时,才需要在括号前添加一个自定义分隔符以避免歧义,例如:
cpp
// 在引号和括号间添加自定义标识符 "art"
std::string s = R"art({"msg": "Look at this )" symbol"})art";
// 编译器在遇到匹配的 )art" 时才会认为字符串结束了解该语法后,即可方便地进行反序列化操作:
cpp
#include "json.hpp"
#include <iostream>
int main() {
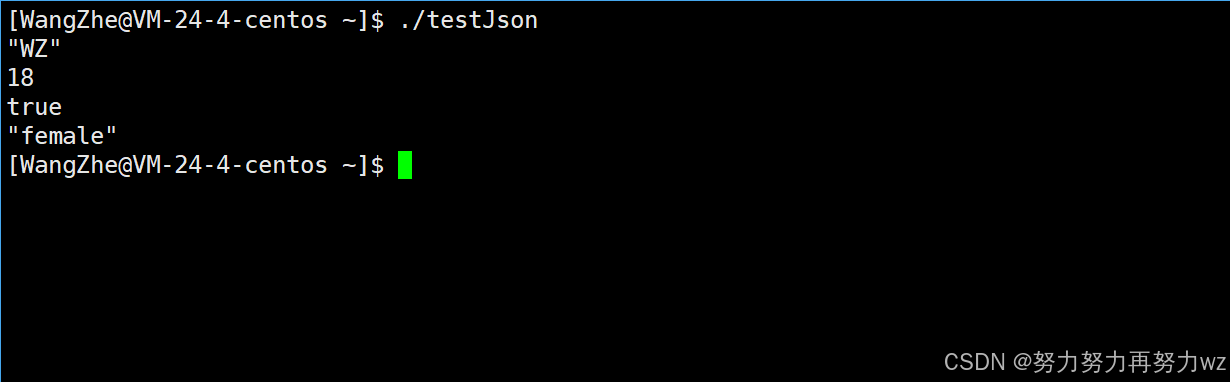
std::string s = R"({"name":"WZ","age":18,"is_student":true,"gender":"female"})";
nlohmann::json j = nlohmann::json::parse(s);
std::cout << j["name"] << std::endl;
std::cout << j["age"] << std::endl;
std::cout << j["is_student"] << std::endl;
std::cout << j["gender"] << std::endl;
return 0;
}
原理
接下来介绍 JSON 的实现原理。基于上文的背景,json.hpp 库内部维护一个json 类,该类包含两个核心成员变量:类型变量 与 值变量。其中,类型变量用于记录当前json 对象所维护的原始数据类型,例如是一个对象、一个数组,还是一种基本数据类型。除了类型变量,类中还维护一个值变量,该值变量被实现为一个联合体。我们知道,联合体的各个成员变量共享同一块内存,且都从联合体的起始地址开始布局,这意味着在任意时刻,联合体中只有一个成员是有效的。将值变量设计为联合体的原因在于,一个json 对象同一时刻只能表示一种数据类型,不可能同时维护数组与对象;只能在数组内嵌套对象,或在对象内嵌套数组。
cpp
#include <iostream>
#include <string>
#include <vector>
#include <map>
// 1. 类型标签:标识当前存储的数据类型
enum class value_t {
null,
number_integer,
string,
array,
object
};
class json {
public:
// 2. 核心联合体:所有类型共用同一内存区域
union internal_value {
int64_t number_integer; // 基本类型直接存储值
std::string* string; // 复杂类型存储指针
std::vector<json>* array; // 递归定义:数组中存储的是 json 对象
std::map<std::string, json>* object;
internal_value() : number_integer(0) {} // 默认初始化
};
value_t m_type = value_t::null;
internal_value m_value;
// ...
};在该联合体中,基本数据类型(如整数)直接存储其值,而复杂数据类型(如字符串、数组等)则存储指针,以此减少json对象本身的内存占用。json 类的关键组成部分之一是其构造函数。该类提供了多个版本的构造函数,每个版本对应一种特定的数据类型。每个构造函数的主要职责是:将类型变量设置为对应的数据类型,并同时初始化值变量。其中,对象与数组对应的构造函数较为特殊。
基于上文,对象和数组支持通过列表初始化进行构造。对于对象,列表初始化使用一系列pair (二元组)来完成;对于数组,则直接列举各个元素的值。列表初始化的底层机制与std::initializer_list 相关,它是一个标准库提供的模板类。
json 类定义了两个接收std::initializer_list 的构造函数:一个接收std::initializer_list<std::pair<std::string,Json>> ,用于对象初始化;另一个接收std::initializer_list<json> ,用于数组初始化。读者可能会有疑问:为什么数组构造函数的参数是以及pair对象的值的类型都是json 类型?这是因为数组的元素以及二元组的值的类型可以不同,例如:
cpp
[1, "hello", true]
{{"name","wz"},{"age",20}}而json 对象本身是"泛型"的,其内部的值变量为联合体,可以容纳任意支持的数据类型。因此,std::initializer_list 模板在这里实例化为json 类型,这是一个需要注意的设计点。
若列表初始化传入的是pair 列表,则会调用接收std::initializer_list<std::pair<std::string,json>> 的构造函数。该函数的执行过程如下:首先,编译器会在栈上构建一个临时的只读数组,其元素类型为std::pair<std::string,json> ;接着,std::initializer_list 内部会保存两个指针,分别指向该临时数组的起始与结束位置。在构造函数内部,首先将类型变量设为object ,并在堆上动态分配一个std::map 作为值变量;之后,遍历临时数组,将每个pair 插入该std::map 中。
若传入的不是pair 列表,则会调用接收std::initializer_list<json> 的构造函数。此时,类型变量被设置为array ,并在堆上分配一个std::vector<json> 作为值变量,随后将临时数组中的每个json 元素依次插入该向量。
cpp
class json {
// --- 构造函数重载:根据输入决定类型 ---
json(std::initializer_list<std::pair<std::string, json>> init) {
// 1. 设置类型标签为对象
m_type = value_t::object;
// 2. 在堆(Heap)上分配 map 空间
m_value.object = new std::map<std::string, json>();
// 3. 遍历栈(Stack)上的临时 pair 数组
for (auto it = init.begin(); it != init.end(); ++it) {
// 将栈上的 pair 拷贝到堆上的 map 中
// 注意:这里会递归触发 MyJson 的拷贝构造函数
m_value.object->insert(*it);
}
}
MyJson(std::initializer_list<json> init) {
// 1. 设置类型标签为数组
m_type = value_t::array;
// 2. 在堆上分配 vector 空间
m_value.array = new std::vector<json>();
// 3. 预留空间以减少扩容开销
m_value.array->reserve(init.size());
// 4. 遍历栈上的临时 json 对象数组
for (auto it = init.begin(); it != init.end(); ++it) {
// 将栈上的临时 json 对象深拷贝到堆上的 vector 中
m_value.array->push_back(*it);
}
}
// 整数版本构造函数
json(int value) {
m_type = value_t::number_integer;
m_value.number_integer = value;
}
// 字符串版本构造函数
json(const char* value) {
m_type = value_t::string;
m_value.string = new std::string(value); // 在堆上分配字符串
}
// 析构函数:根据类型释放堆内存
~json() {
if (m_type == value_t::string) {
delete m_value.string;
} else if (m_type == value_t::array) {
delete m_value.array;
}
// ... 其他类型的释放
}
};在了解json 类的基本构造机制后,接下来介绍几个关键的成员函数------operator[]运算符的重载。
operator[] 有两个重载版本:一个接收std::string 类型参数,另一个接收整型参数。接收std::string 的版本用于处理 JSON 对象(键值对结构)。此时,json 对象的值变量应为一个哈希表(或
std::map )。如果调用该运算符时,当前json对象为空(即类型为null ),则该运算符会先将其类型转为object ,并初始化值变量为空的哈希表,然后插入对应的键值对;若非空,则直接进行键值对的插入或访问。
接收整型参数的版本用于处理 JSON 数组。类似地,若当前json对象为空,运算符会将其类型转为array
,并初始化值变量为一个空的向量。此外,该版本还包含自动扩容逻辑:若访问的下标超出当前数组长度,向量会自动扩容至该下标加一的大小,新增位置将以默认构造的json 对象(即null 类型)填充。
cpp
// 接收字符串,处理 {"key": value} 结构
json& operator[](const std::string& key) {
// 1. 若当前为空对象,则转为 object 类型
if (m_type == value_t::null) {
m_type = value_t::object;
m_value.object = new std::map<std::string, json>();
}
// 2. 类型检查:若非 object 类型,抛出异常
if (m_type != value_t::object) {
throw std::domain_error("JSON类型不是object,无法使用字符串key访问");
}
// 3. 利用 std::map 特性:若 key 不存在,会自动插入一个默认构造的 json 对象
return (*m_value.object)[key];
}
// 接收索引,处理 [value1, value2] 结构
json& operator[](size_t index) {
// 1. 若当前为空对象,则转为 array 类型
if (m_type == value_t::null) {
m_type = value_t::array;
m_value.array = new std::vector<MyJson>();
}
// 2. 类型检查
if (m_type != value_t::array) {
throw std::domain_error("JSON类型不是array,无法使用索引访问");
}
// 3. 自动扩容:若索引超出当前大小,调整向量大小
if (index >= m_value.array->size()) {
m_value.array->resize(index + 1);
}
// 4. 返回对应位置的引用
return (*m_value.array)[index];
}在了解了operator[] 的基本访问逻辑后,需要注意其返回类型是json 对象的引用。在代码中,我们常会书写如下语句:
cpp
int age = j["age"];此语句的底层执行逻辑如下:首先调用operator[] 重载函数,函数内部检查j 对象不为空且类型为object (而非array 或其他类型),随后找到键"age" 对应的值。该值本身是一个json 对象,函数返回其引用。然而,为了将json 对象转换为int 这样的基本类型,编译器会尝试进行隐式类型转换。具体地,当赋值运算符的左右操作数类型不匹配时,编译器会检查json 类是否定义了相应的类型转换运算符,若已定义,则自动调用。因此,上述代码实际上依次调用了两个重载函数:operator[] 和operator int() 。
cpp
class MyJson {
public:
// ... 其他成员 ...
// 1. 转换为 int 的类型转换运算符
operator int() const {
if (m_type != value_t::number_integer) {
// 在实际的工业级库中,此处通常会抛出更精确的类型错误异常
throw std::runtime_error("类型不匹配,无法转换为int");
}
return static_cast<int>(m_value.number_integer);
}
// 2. 转换为 std::string 的类型转换运算符
operator std::string() const {
if (m_type != value_t::string) {
throw std::runtime_error("类型不匹配,无法转换为string");
}
return *(m_value.string); // 解引用指针获取字符串
}
// 3. 转换为 bool 的类型转换运算符
operator bool() const {
// ... 实现逻辑类似
}
};另一种常见情况是赋值操作:
cpp
j["age"] = 18;此语句的执行过程是:首先调用operator[] 并返回一个json 对象的引用。这个被引用的json对象作为赋值运算符的左操作数(属于自定义类型),随后会调用其赋值运算符operator= 。该类定义了多个重载版本的operator= ,其中一个接收int 类型参数。该赋值运算符会首先检查当前json 对象的类型是否匹配:如果匹配(例如原本就是整数类型),则直接修改其内部存储的值;如果不匹配,则需要先释放当前对象可能持有的资源(如堆内存),再将类型标签更新为目标类型,并初始化对应的值变量。
cpp
MyJson& operator=(int value) {
if (m_type == value_t::number_integer) {
// 类型匹配:直接修改值,避免额外的资源释放与分配,性能更优
m_value.number_integer = value;
} else {
// 类型不匹配:需先释放现有资源,再重新构造
this->destroy(); // 清理当前值所持有的资源
m_type = value_t::number_integer; // 更新类型标签
m_value.number_integer = value; // 设置新值
}
return *this; // 返回当前对象的引用,支持链式赋值
}通过结合operator[] 、类型转换运算符以及赋值运算符的重载,json 类实现了灵活且直观的读写接口,同时在内部保证了类型安全与资源管理的正确性。
json.hpp 的底层设计在一定程度上模糊了数组与对象的界限。其operator[] 不仅是一个访问器,更扮演了构造助手的角色。它利用std::vector<json> 的默认构造特性,以null 对象作为"内存粘合剂",实现了边访问边构造的灵活性,同时借助my_type 成员确保了 C++ 层面的类型安全。
补充
至此,我们已从使用与原理两个层面解析了 JSON。在原理层面,我并未详细解释dump 与parse 的具体实现原理,因为本文的重点在于"使用轮子而非造轮子"。适当了解轮子的构造,有助于我们更从容、得心应手地运用 JSON,但对其底层的理解也应适度------将 JSON 类的实现完全剖析清楚,反而可能收益有限。dump 与 parse 的具体实现较为复杂,感兴趣的读者可自行深入研究。
对于结构化数据(即 JSON 对象),我们可以调用dump 函数将其序列化为符合 JSON 规范的字符串。该字符串是以字符为单位的字符序列,每个字符通常对应一个字节。dump 函数的作用正是将数据结构转化为连续的字符序列。然而,转换为字符序列后,还需经过一步额外处理才能通过网络发送:即通过特定编码将字符序列转换为字节序列。因此,这里补充说明一下编码的相关知识。
我们知道,计算机底层只能存储二进制序列。但现实生活中大部分信息需以字符串形式表示,因此需要将字符串中的各个字符映射为唯一的二进制值,即进行编码。早期最常见的编码是 ASCII 码,它使用一个字节为英文字母及特殊符号分配唯一的二进制值,其范围是 0~127。
随着计算机的发展,需要表示的字符不再仅限于英文,还包括中文、其他语言字符乃至表情符号等。一个字节已不足以表示如此多的字符,于是 UTF-8 编码应运而生。UTF-8 是当前最主流、最常用的编码方式,它能表示包括中文在内的多国语言,并且完全兼容 ASCII 码。
为了对全球各类字符进行编码,Unicode 标准为每个字符定义了一个唯一的"码点"(Code Point),相当于字符的身份证。UTF-8 则是一种将码点转换为 1 至 4 个字节的二进制序列的规则,使得计算机能够存储和处理这些字符。具体字符映射到几个字节,取决于其码点的大小:
| 码点范围 (十六进制) | 字节数 | 字节模板 (二进制) |
|---|---|---|
0000 0000 - 0000 007F |
1 | 0xxxxxxx (完全兼容 ASCII) |
0000 0080 - 0000 07FF |
2 | 110xxxxx 10xxxxxx |
0000 0800 - 0000 FFFF |
3 | 1110xxxx 10xxxxxx 10xxxxxx (大部分汉字在这) |
0001 0000 - 0010 FFFF |
4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
此时读者可能会产生疑问:当一个字符映射为多个字节时,会存在字节序(Endianness)问题,但为何在将文本序列化为字符串时,大多数编译器和平台使用 UTF-8 编码却不会遇到字节序问题?
原因在于 UTF-8 是一种面向字节的编码。尽管一个字符可能对应多个字节,但 UTF-8 始终以字节为单位进行解析,而非将多个字节作为一个整体来处理。其解析规则如下:
- 若某字节的最高位为
0,则该字节直接对应一个字符(即 ASCII 字符)。 - 若字符对应多个字节,则第一个字节称为"前导字节"。对于占用 n 个字节的字符(1 ≤ n ≤ 4),其前导字节的高 n 位为
1,第 n+1 位为0,后续的每个辅助字节均以10开头。这种设计使得解析器能够明确识别字符的起始与边界,从而正确地将多个字节组合解析为一个字符。
字节序问题本质源于多字节整型在内存中的存储顺序,而 UTF-8 在本质上是一种字节流协议。由于 UTF-8 的前导字节已包含字符长度与边界信息,且解析过程是逐字节顺序进行的,因此它天然避免了因 CPU 大小端架构差异所引发的问题。
相对地,像 UTF-16 这类定长编码(每个字符固定对应 2 或 4 字节),由于需将多个字节作为一个整体解析,就会受到平台字节序的影响。
JSON 标准明确规定使用 UTF-8 作为其编码方式,这进一步确保了其在不同系统和环境间的兼容性与一致性。
HTTP
引入
在上文详细讲解了JSON之后,接下来我们将过渡到HTTP的内容。在具体介绍HTTP协议之前,我仍然通过一个例子来引入。
大家平时应该都有使用浏览器上网的习惯。我们常常在浏览器中输入一个网址,用来打开或获取网页,甚至是观看视频等。但你是否想过,在输入网址的背后,其实涉及客户端与服务端之间的通信原理。浏览器作为客户端,会与服务端进行通信,而最终呈现给我们的各种网页、视频等内容,都可以统称为"资源"。这些资源都是从服务端获取的,而HTTP正是一个应用层的通信协议。
要理解HTTP的原理,我们首先要从整个通信过程的起点说起,也就是在浏览器输入网址的那一刻。
原理
根据上文可知,我们获取网页、音视频等资源的过程,其背后实际基于客户端-服务器模型(Client-Server Model),即客户端与服务器之间的通信。现在,让我们从这一通信过程的起点开始讲解------也就是在浏览器中输入网址的那一刻。首先需要明确的是,由于该过程本质上是客户端与服务器之间的通信,因此通信双方必须依赖 IP 地址 与 端口号,才能确保数据准确发送到目标主机上的对应进程。IP 地址通常表示为点分十进制形式的字符串,端口号则为整数值。然而,我们在输入网址时,并不会手动输入 IP 地址和端口号,却在按下回车键之后,对应的网页、音视频等资源几乎立即呈现在浏览器中。这究竟是如何实现的呢?
这就需要我们先了解"网址"这一概念。网址是一种通俗的说法,其专业术语是 URL(Uniform Resource Locator,统一资源定位符)。一个完整的 URL 通常由以下几个部分组成:协议、域名、端口、路径、查询参数和片段。
例如:
cpp
https://www.example.com:443/music/list?id=1024&type=pop#comment| 组成部分 | 示例内容 | 专业术语 | |
|---|---|---|---|
| 协议 | https:// |
Scheme | |
| 域名 | www.example.com |
Domain/Host | |
| 端口 | :443 |
Port | |
| 路径 | /music/list |
Path | |
| 参数 | ?id=1024&type=pop |
Query String | |
| 锚点 | #comment |
Fragment |
URL 被称为"统一资源定位符",是因为我们在浏览器中所见的各种内容------无论是网页、图片还是视频------本质上都是资源,通常存放在服务器上。客户端(浏览器)向服务器发起请求以获取这些资源。为了准确定位资源,不仅需要知道服务器的 IP 地址和端口,还需明确资源在服务器上的具体位置,这正是路径所起的作用。因此,URL 实际上提供了一种统一的方法来定位网络上的资源。关于路径的具体细节,我们将在后文进一步展开说明。
以上简要说明了路径的作用,端口我们也熟悉其含义,而协议则对应通信双方所使用的应用层协议。那么,域名又是什么?接下来的内容将围绕域名展开讲解。
域名
实际上,在浏览器中可以直接输入 IP 地址来替代域名进行访问。既然如此,为什么大多数情况下我们仍使用域名呢?原因在于,IP 地址是一串点分十进制数字,对普通用户而言并不友好。如果每次访问网站都需要记忆和输入 IP 地址,将会非常不便。相比之下,域名更为直观,例如www.baidu.com 能让人联想到百度网站,而不暴露其背后的 IP 地址信息。我们可以将域名比作"人名",而 IP 地址则相当于"身份证号"------显然,使用域名访问更加直观和方便。
然而,问题随之而来:从形式上看,域名与 IP 地址并无直接关联,但获取资源的本质是进程间通信,必须依赖 IP 地址。因此,域名必须通过某种方式转换为对应的 IP 地址。这一转换过程即是接下来要介绍的域名解析服务。
在深入讲解域名解析之前,我们需要先了解域名的基本格式。一个完整的域名由"."分隔为若干部分,从右向左依次为:顶级域名、二级域名、三级域名等。通常,在完整域名的末尾还有一个表示根域的"."。
例如:
cpp
www.example.com.
根域名(Root Domain):.
顶级域名(Top-Level Domain, TLD):.com
二级域名(Second-Level Domain, SLD):example
三级域名(Third-Level Domain):www在了解了域名的组成之后,接下来将分别说明这些域名的含义与作用。首先从根域名开始,根域名通常表示为顶级域名右侧的一个点("."),它是所有域名的起点,这是一种约定俗成的设计。其次是顶级域名。
顶级域名主要分为两类:一类是国家及地区域名,另一类是通用域名。通过顶级域名,可以反映网站的背景或用途。国家及地区域名常见的有:
.cn(中国).us(美国).jp(日本).uk(英国)
如果使用国家或地区域名,通常意味着该网站受相应国家或地区的法律法规约束。相比而言,通用域名更为常见,并能更直接地体现网站的用途或所属行业,因为它们通常与机构、组织或特定行业相关联。例如:
.com代表商业用途;.net代表网络服务机构;.org代表非营利性组织;.edu原指美国高等教育机构,该后缀主要由美国使用,中国对应使用二级域名.edu.cn;.gov代表美国政府机构。
此外,如今的通用域名已大大扩展,出现了诸如.museum (博物馆)、.shop (电商平台)等新后缀。
| 域名后缀 | 代表含义 | 适用对象 |
|---|---|---|
| .com | Commercial | 最初限企业,现已演变成全球通用的商业标识。 |
| .org | Organization | 各种非营利性机构、开源项目。 |
| .net | Network | 最初为网络基础设施(ISP)设计。 |
| .edu | Education | 主要是美国高等教育,中国则对应二级域名 .edu.cn。 |
| .gov | Government | 仅限政府机构使用,具有极高权威性。 |
通过顶级域名,用户可以初步判断网站的性质与用途。紧接着顶级域名的是二级域名。上文提到,域名的作用是对网站进行身份标识,使用户能够了解网站的背景与用途。而二级域名可进一步增强网站的身份识别性与记忆点。
二级域名通常与品牌、企业或个人身份等内容紧密关联,例如www.google.com 、www.baidu.com 。若需进一步添加个性化信息,还可以继续设置三级、四级域名等。
在了解域名的各个组成部分后,还需要补充一点关于域名申请的说明。首先要明确的是,申请域名并不是一次性获得完整域名,而是需要先确定顶级域名。申请顶级域名一般分为两种情况:
第一种是创建全新的顶级域名。这种情况需向ICANN(互联网名称与数字地址分配机构)这一最高管理机构提交申请,审核该域名是否符合条件,并缴纳注册费。若申请成功,该顶级域名将交由申请者或其委托的机构管理,包括其下所有子域名的注册事务。不过这种情况较为少见。
更常见的是第二种情况,即申请已注册的顶级域名(如.com )。每个顶级域名通常有专门的注册局进行管理,负责该顶级域名下子域名的注册,并与注册商(如腾讯云、阿里云等)对接。注册商直接面向用户,帮助其申请二级域名。注册商会查询注册局的数据库,若该二级域名未被占用,即可完成注册并缴纳相应费用。需注意的是,二级域名并非永久有效,一旦到期未续费,该域名将被释放。
可以这样理解:顶级域名如同一个集合,二级域名则是在该集合中开辟出属于你自己的子集。获得二级域名后,就像开发商获得一块地皮,可在其下进一步设置子域名。子域名的管理不再通过注册商,但需要向注册商提供一个权威域名服务器地址,以便注册商知晓该二级域名对应的IP地址。这部分内容与后文将介绍的DNS解析相关,具体原理将在后续详细说明。
在了解了域名的构成、含义以及申请方式之后,接下来便进入域名解析环节,即域名如何转换为IP地址。这一过程与DNS服务器密切相关。DNS服务器专门负责域名解析,它会接收DNS查询请求,并返回该域名对应的IP地址。
在进行DNS查询之前,系统会首先在本机缓存中查找是否有该域名映射的IP地址。如果之前曾在浏览器中访问过该域名对应的网站,浏览器可能会保留相应的缓存。若浏览器缓存未命中,则会查询操作系统缓存;若操作系统缓存也未命中,则会进一步查询磁盘上的hosts文件。hosts文件中存储的内容是一组组"域名-IP"映射条目,因此域名解析会优先查找本机的这三级缓存。
需要补充的是,hosts文件的优先级高于本地DNS服务器查询。我们有时利用这一机制屏蔽浏览器中弹出的广告,具体方法是将广告对应的域名映射到本机IP地址(如127.0.0.1),并将该条目添加到hosts文件中。这样一来,在解析该域名时,会直接指向本机,从而阻止广告内容的加载。
如果本地缓存均未命中,则需要查询本地DNS服务器。本地DNS服务器通常由用户手动配置或由DHCP服务自动分配。此时,主机会向本地DNS服务器发送一个DNS查询报文,请求解析该域名对应的IP地址。若本地DNS服务器中存有该记录,则直接返回IP地址。
若本地DNS服务器没有缓存该记录,则会启动迭代查询流程。首先,它会向根域名服务器发送请求,询问应如何解析该域名。根域名服务器存储了所有顶级域名服务器的地址,它会根据域名中的顶级域名(如.com、.org等),返回对应顶级域名服务器的IP地址,指引本地DNS服务器向下一级查询。全球共有13组根域名服务器IP地址,但每组IP背后对应着分布在全球各地的多台服务器,查询时会通过任播技术路由到距离最近的服务器节点。
接着,本地DNS服务器会向获得的顶级域名服务器发起查询。顶级域名服务器则管理其下属的权威域名服务器信息,并根据域名中的二级域名部分,返回对应的权威域名服务器地址。本地DNS服务器随后向该权威域名服务器查询,最终获得域名对应的真实IP地址,并将其返回给请求主机。至此,完成域名解析的全过程。
主机获得IP地址后,浏览器、操作系统及hosts文件都可能建立相应缓存,以加速后续解析。但这些缓存条目均具有时效性,到期后会被自动清除。本地DNS服务器在返回IP地址时,也会将这一映射关系缓存到本地,以提高相同域名的解析效率,该缓存同样设有有效期,常用于存储访问频率较高的域名记录。如果缓存失效或未命中,本地DNS服务器将重新执行从根域名服务器开始的迭代查询流程。
在了解了域名解析服务后,我们对网络通信流程的认知会更加清晰。根据上文的说明,通信的起点是在浏览器地址栏中输入URL 。URL 本质上是一个字符串,浏览器作为客户端,在获取用户输入的URL 字符串后,会按照其构成进行解析,将其拆分为协议、域名、路径和查询参数等部分。
由于浏览器需要与服务器进行通信,因此必须首先获得服务器的IP 地址,这一步即为域名解析。浏览器会先查询本地缓存,若未命中,则向本地DNS 服务器发起查询,最终获取到对应的IP 地址。获得IP 地址后,浏览器便可开始与服务器建立通信。
HTTP 作为应用层协议,基于 TCP 传输协议实现。因此,浏览器作为客户端,首先需要与服务器建立连接,即完成TCP 三次握手。三次握手成功后,客户端与服务器才正式进入通信阶段。接着,浏览器会构建一个请求报文,发送给服务器,报文中包含对特定资源(如网页、图片等)的请求。服务器作为资源的持有者,在接收到请求报文后,会处理该请求,定位对应资源,并构建响应报文。响应报文中携带客户端请求的资源,随后将其返回给客户端。以上便是完整的通信流程。
理解这一过程,有助于我们更清晰地认识 Web 服务器的工作原理。掌握该流程,意味着已经理解了大部分基本原理,后续只需对这一过程中涉及的具体细节进行补充说明。首先就是知道URL的各个组成部分的作用以及含义首先便是HTTP 协议。
HTTP协议
HTTP协议作为应用层协议,定义了通信双方交互的规则。应用层协议所规定的内容,其本质上是对请求与响应报文的格式进行约束。通信双方必须对请求和响应报文的格式有明确的共识,才能正确解析对方发送的内容。
HTTP是一种文本协议,这一特性体现在其请求与响应报文的格式上。文本协议的主要特征是所传输的数据由字符串构成,这意味着HTTP的请求与响应报文并非纯二进制流,而是字符序列,因此对人类是可读的。
首先来认识HTTP请求报文的格式。请求报文可由三部分或四部分构成,包括请求行、请求头、空行和可选的请求正文。之所以说"三部分或四部分",是因为请求正文是可选的,它是否存在取决于具体请求方法,这一点将在后文说明。
HTTP请求报文的开头是请求行,由请求方法、URL和协议版本三部分组成,各部分之间以空格分隔。请求行之后是请求头,它由多行键值对组成,每行以回车换行符\r\n 结束。请求行与请求头之间也通过一个回车换行符分隔。
请求头之后是一个空行,即单独的\r\n 。由于请求头每行已以\r\n 结尾,因此请求头末尾会连续出现两个换行符,即\r\n\r\n 标志着请求头的结束。空行之后的部分即为请求正文。
示例:
cpp
"POST /api/login HTTP/1.1\r\nHost: www.example.com\r\nUser-Agent: Mozilla/5.0\r\nContent-Type: application/x-www-form-urlencoded\r\nContent-Length: 27\r\nConnection: keep-alive\r\n\r\nusername=admin&password=123456"接下来详细说明请求报文各组成部分的含义与作用。首先是请求行,它包含请求方法、URL和协议版本三个部分,各部分以空格分隔。请求行的作用是告知服务器执行何种操作------这是通过第一个字段"请求方法"来体现的。此外,它还指明了操作的目标资源(URL)以及所使用的协议版本。
请求方法 定义了客户端希望服务器执行的具体操作。HTTP 协议定义了多种请求方法,常见的如下表所示:
| 请求方法 | 语义 (Action) | 数据位置 | 是否有 Body | 幂等性* | 安全性** | 典型应用场景 |
|---|---|---|---|---|---|---|
| GET | 获取资源 | URL 查询参数 | 否 | 是 | 是 | 浏览网页、搜索图片、查询余额 |
| POST | 新增或处理资源 | 请求体 (Body) | 是 | 否 | 否 | 注册账号、发表评论、上传文件 |
| PUT | 更新(全量覆盖) | 请求体 (Body) | 是 | 是 | 否 | 修改用户完整档案、上传同名覆盖文件 |
| PATCH | 更新(局部修改) | 请求体 (Body) | 是 | 否 | 否 | 只修改用户的头像或改个密码 |
| DELETE | 删除资源 | URL 路径 | 否 | 是 | 否 | 注销账户、删除一条朋友圈 |
| HEAD | 获取头部信息 | N/A | 否 | 是 | 是 | 检查链接有效性、获取文件大小 |
| OPTIONS | 查询支持的方法 | N/A | 否 | 是 | 是 | 跨域(CORS)前询问服务器允许哪些操作 |
| TRACE | 回显服务器收到的请求 | N/A | 否 | 是 | 是 | 用于诊断或测试网络路径中的代理 |
注:幂等性 指同一操作执行一次或多次对服务器端的资源状态不会产生额外影响,即效果相同。例如 GET 请求仅从服务器获取数据,发起一次与发起多次对该资源本身没有区别(因为它是只读的)。而 POST 不具备幂等性,是因为其通常用于提交数据,例如在数据库中新增一条记录,执行一次与重复执行多次所产生的效果不同(会导致多条记录被创建)。安全性 则指该操作本身不应引起资源状态的改变。
根据上表可以看出,HTTP 协议定义了多种请求方法,每种方法对应特定的语义操作。在实际开发中,并不需要掌握所有方法,因为绝大多数 HTTP 通信场景只涉及GET 与 POST 两种方法。其中一个重要原因是,POST 方法在功能上具有一定的涵盖性,能够替代其他某些操作(这一点将在后文说明)。因此,掌握GET 和 POST 即可满足大部分基础开发需求。
GET请求
首先是GET 方法,其作用是从服务器获取资源。之前提到,这类资源可以是网页、图片、视频等,它们通常以文件形式存在于服务器上。例如,网页本质上是一个HTML 文档,图片和音视频则是二进制文件。服务器在磁盘中存储这些文件,而GET 请求的目标就是根据客户端提供的路径,定位并返回对应资源。
以网页为例,用户在浏览器中看到的内容是由浏览器渲染得到的。浏览器不仅作为网络通信的客户端,还负责解析和呈现网页内容。网页的骨架是HTML 文档,其基本结构包含以下三部分:
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>我的第一个网页</title>
</head>
<body>
<h1>欢迎来到我的网站</h1>
<p>这是一个关于 HTML 结构的探讨。</p>
</body>
</html>- 文档类型声明:首行的
<!DONCTYPE html>用于告知浏览器HTML版本,确保其以符合标准的方式解析文档。 - 头部:
<head>部分定义网页的元信息,如字符编码、标题等。 - 主体:
<body>部分包含网页的实际内容,即用户在页面上看到的所有信息。
浏览器通过解析HTML 文档,将其转换为可视化的网页界面。作为后端开发者,我们通常不需要深入掌握HTML 细节------这属于前端开发的范畴。但在后续编写完整 Web 服务器代码时,可能会涉及简单网页的构建,因此在此对其结构作简要说明。
服务器上持有的资源,如网页(文本文件形式的HTML文档)或图片、音视频等(二进制文件),通常存储在服务器的文件系统中。GET请求的核心目的,正是从该文件系统中获取这些资源对应的文件。为了实现这一目标,客户端必须在请求中提供一个路径,以便服务器能够准确定位资源。随后,服务器将找到的资源载入响应报文,并返回给客户端。因此,请求行中的URL部分,其作用就是指明这个资源路径。
请求行中的 URL 是浏览器中所输入 URL 去除协议、域名和片段(fragment)后剩余的部分,仅包含路径与查询参数。在此,我们终于可以明确解释"路径"的含义:路径的第一层含义是代表服务器文件系统中的某一目录路径。但需要说明的是,路径虽然以/ 开头,并不表示它一定是文件系统的绝对路径(即从根目录开始)。在实际的服务器配置中,路径通常是相对于服务器设定的根目录(如网站根目录)来解释的。
刚才我特别强调"第一层含义",是因为路径所指示的对象并不一定是静态文件,也可能是一个可执行程序。这种情况下,请求的目的并非获取静态资源,而是获取动态资源。此时,服务器需要调用该可执行程序,获取其输出结果。典型做法是:服务器通过fork() 创建子进程,再通过exec() 系列接口将子进程替换为目标可执行程序,接着建立管道获取程序输出,最后将输出填入响应报文并返回客户端。此外,路径甚至可以不对应实际文件,而表示服务器内部的一个可调用函数。服务器识别该 URL 后,会调用相应的内部函数,并将其返回值放入响应报文中。这一点将在后文结合具体场景进一步说明,此处请先形成初步印象。
而这里之所以说 POST 能够涵盖其他操作,是因为 POST 的 URL 可以作为虚拟路径 ,映射到服务器内部预定义的可调用函数。
在这种设计下,原本属于 DELETE 或 PUT 等请求方法的操作逻辑 ,现在直接被写在了这些函数的内部;而请求报文携带的正文内容,则作为参数传递给函数进行处理。这也就解释了上文埋下的伏笔:为什么绝大多数场景只涉及 GET 和 POST,因为我们完全可以通过"POST + 虚拟路径"的方式,在函数层面实现任何复杂的业务操作。
cpp
POST /deleteUser?id=1 ->映射到内部 delete_user_func(id)
POST /updateUser -> 映射到内部 update_user_func(data)URL 还可能包含查询参数(query string),其作用是对资源进行附加处理,例如数据筛选、排序、分页等:
cpp
数据筛选:GET /products?category=phone
// 服务器只返回手机类商品,而非全部商品
排序:GET /users?sort=age_desc
// 服务器对获取的数据按年龄降序排列后再返回
分页:GET /news?page=2&size=10
// 避免单次返回数据量过大,节省带宽还需补充的是,查询参数有其固定格式:它以? 与路径分隔,由多个键值对组成,键值对之间以& 分隔。若键或值中包含特殊字符(如/ 、? 、& 等),为避免解析冲突,需要对它们进行编码。通常使用 UTF-8 编码将字符转换为二进制序列,由于& 、% 等特殊字符通常映射为单字节,因此对应两个十六进制数字。接着将该十六进制值前加上% 作为转义前缀。当服务器检测到 URL 含有查询参数时,首先会以"&" 分割出各个键值对,再以"=" 分割出键与值。之后,服务器会检查键和值中是否出现以% 开头的转义序列(即 URL 编码部分)。如有,则需对其进行解码,将其恢复为原始字符。
| 原始字符 | 特殊含义 | 编码后 (Hex) |
|---|---|---|
| 空格 | 分隔符(旧标准变 +) |
%20 |
| / | 路径分隔符 | %2F |
| ? | 查询参数起始符 | %3F |
| & | 键值对分隔符 | %26 |
| = | 键值对连接符 | %3D |
| % | 编码引导符本身 | %25 |
最后是HTTP协议版本。HTTP协议存在不同版本,其主要差异体现在TCP传输层的使用方式上。目前主流的版本是1.0和1.1。HTTP/1.0默认采用短连接,即服务器在处理完客户端的一次请求后便会主动断开连接。如果客户端需要再次向同一服务器发送请求,则必须重新进行TCP三次握手以建立新连接。而HTTP/1.1默认使用长连接。
上文提到,一个网页实际上对应一个HTML文档,而一个网页通常包含多种资源,如图片、音频、视频等。这些都属于网页所需的资源。浏览器要完整渲染该网页,仅获取HTML文档是不够的,还必须加载所有相关资源。因此,HTML文档中通常会记录这些资源的路径。当用户访问该网页时,客户端首先向服务器发送请求,获取对应的HTML文件。服务器解析请求报文,定位到文件并返回给客户端。浏览器解析HTML时,若发现还需要加载图片等资源,则会继续向服务器发送请求获取这些资源。
在上述场景中,客户端通常需要连续向服务器发送多个请求。如果使用短连接,将会涉及大量重复的TCP三次握手和四次挥手过程,从而显著降低传输效率。长连接正是为了应对这种情况而设计:通信双方只需完成一次三次握手,建立一条持续的TCP连接。客户端可以通过该连接连续发送多个请求,服务器在收到请求后不会立即断开连接,而是依次解析这些请求,并返回对应的响应报文。如果客户端希望结束连接,或在发送最后一个请求时,可通过请求头中的Connection 字段通知服务器。服务器检查该字段,若其值为close ,则会主动关闭连接。
此外,HTTP还有2.0和3.0版本。由于目前所学知识尚不足以深入理解这两个版本的区别,本文仅重点介绍常见的1.0与1.1版本。
在掌握请求行及其各字段含义后,接下来介绍请求头。根据上文,请求头由若干行键值对构成,每对之间以回车换行符分隔。每个键值对对应一个特定属性,其内容总体可分为四个方面:一是逻辑站点信息,二是客户端身份信息,三是客户端向服务端发起的内容协商(可视为客户端的"期望清单"),四是连接状态协商。
首先,第一个方面对应的字段是Host 。Host 字段的值为 URL 中的域名部分。在客户端与服务端建立连接之前,会先提取 URL 中的域名并进行域名解析,将其转换为 IP 地址。IP 地址用于标识目标主机,而端口号则用于标识该主机上的特定进程。一个进程可能提供多个服务,例如一台主机可同时承载www.baidu.com 和www.google.com 的服务。通过"IP地址 + 端口号 "这个二元组,可以定位到目标主机上的服务器进程,而该进程可能管理多个站点。此时,需依据Host 字段确定具体请求哪个站点的资源,从而将服务器根目录切换至对应站点的目录。这个过程类似于总机将电话转接至相应分机。
http
Host: sales.com // 对应 /var/www/sales 目录
Host: tech.com // 对应 /var/www/tech 目录因此,域名解析得到的 IP 地址与端口号定位的是物理主机上的服务器进程,该进程如同设有多部门的大楼。服务器进程根据Host 字段进行"分流",即切换到对应的逻辑站点。在代码层面,这会体现为修改路径的根目录,将其映射到目标站点的根目录,从而正确解析相对路径并获取该站点的资源。随后,请求会被路由到对应的处理函数或进程,其上下文即代表该站点的业务逻辑。
这里补充说明一下"站点"这一概念。有的读者可能对这个专业术语不太熟悉,如果用更通俗的方式来理解,站点通常对应一个域名,但它本质上不等同于域名本身。域名只是站点的访问地址,而站点则是在该地址下所有资源的集合。
我们可以将其与网页进行对比。网页、图片等都属于资源,而站点正是这些资源的集合体,它持有并组织所有归属于它的资源。多个网页及其相关的静态资源(如图片、样式表、脚本等)共同构成了一个完整的站点。
如果用比喻来说明:访问一个网页,就像是阅读一本书中的某一页;而访问一个站点,则相当于阅读整本书------它包含了所有的章节、图表及附属内容,是一个完整的信息集合。
第二个方面是客户端的身份信息,对应User-Agent 字段。该字段的值包含客户端的操作系统、浏览器等信息,使服务端能够识别客户端类型,例如是桌面设备还是移动设备,是 Windows 系统还是 Mac OS 系统。服务端可根据设备类型返回不同的页面,如为移动端返回轻量化页面,为桌面端返回功能更丰富的页面。
此外,User-Agent 在反爬虫机制中也有重要作用。爬虫程序通常自行构造 HTTP 请求报文来获取网站资源,而请求头中必须包含User-Agent 字段。因此,爬虫常试图伪造该字段以模拟浏览器请求。服务端会检查User-Agent 的合法性,若发现异常,可判定请求并非来自正常浏览器,从而拒绝响应。因此,User-Agent 也用于验证客户端身份的合法性。
第三个方面是客户端对服务端的内容协商,主要涉及Accept 字段。该字段用于指明客户端期望接收的响应正文数据类型,例如 JSON 或纯文本等。需注意,Accept字段通常提供多个选项,而非单一类型。例如,若服务端无法返回 JSON 格式,仍可协商返回其他类型的数据。这里引入"q 值"(权重值)的概念,它使客户端能够为不同内容类型设置优先级,从而与服务端进行灵活协商。
http
Accept: application/json, text/html;q=0.9, text/plain;q=0.8q 值介于 0 到 1 之间,数值越高,优先级越高。Accept 字段中多个选项以逗号分隔,第一个选项默认 q=1。
内容协商还包括响应正文的压缩方式,对应Accept-Encoding 字段。其值与Accept 类似,由多个表示压缩方式的条目组成,每个条目可附带 q 值以标示优先级。
http
Accept-Encoding: gzip, deflate, br;q=0.9, *;q=0.5
// * 表示其他压缩方式,优先级最低(q=0.5)此外,Accept-Language 字段用于协商响应正文的自然语言,即页面内容的语言版本。服务器可能针对同一资源提供多语言版本(如index_zhe.html 与 index_en.html ),并根据该字段选择对应资源。其取值同样支持多个带权重的选项。
http
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8最后是连接状态协商,通过Connection 字段实现。若其值为keep-alive ,表示告知对方保持连接,后续仍有请求或响应;若为 close ,则表示本方即将关闭连接,当前报文为最后一条,发送后应主动断开。
http
Connection: keep-alive通过以上四个方面,请求头在 HTTP 通信中承载了关键的控制与协商信息,确保客户端和服务端能够高效、准确地交换数据。
POST请求
上文介绍了GET请求,接下来介绍POST请求。POST请求与GET请求的主要区别在于请求正文:GET请求通常不需要携带请求正文,因为它仅用于获取资源;而POST请求则需要携带请求正文,用于向服务器提交数据,请求服务器进行动态处理并返回结果。
POST请求的URL不一定对应实际文件路径,也可以是虚拟路径。该路径会被映射到服务器内部预定义的函数,调用该函数并将返回值放入响应报文中。请求正文则相当于传递给该函数的参数,其内容通常来源于用户在浏览器输入框中输入的数据。这就引入了"表单 "的概念。
表单在HTML文档中定义,用于收集用户输入,并将数据上传至远程服务器。例如:
html
<form action="/login" method="POST">
<input type="text" name="user">
<input type="password" name="pwd">
<button type="submit">登录</button>
</form>表单包含以下关键信息:
- action:指定数据提交的URL,一般对应服务器端处理该请求的函数。
- method:定义提交方法,常见值为GET或POST,属于表单的元数据之一。
表单中的每一个<input> 元素对应一个输入项。例如上例中,name="user" 表示用户名输入框,name="pwd" 表示密码输入框,共同构成一个登录认证界面。
用户提交表单后,浏览器会将输入的数据整合到请求正文中,格式为一系列键值对,各键值对之间用"&" 分隔。如果键或值中包含特殊字符(如& 、/ 等),浏览器会自动对其进行编码。
http
user=admin&pwd=123通过浏览器开发者工具(按F12)查看网页元素,可看到如百度搜索框等内容也是通过表单实现的。
除了文本数据,表单也支持文件上传。文件内容同样被整合到请求正文中。文件可分为文本文件和二进制文件。如果沿用默认的文本模式(即键值对字符串格式),遇到文件内容中含有& 等特殊字符时,解析会出现冲突。若对文件中所有特殊字符进行编码,则处理成本较高,且二进制文件可能包含无法映射为字符的字节值,因此文本模式不适用于文件上传。
此时需使用multipart/form-data 格式。由于POST请求包含请求正文,其请求头除包含与GET请求相似的字段(如Host、Accept等)外,还会包含描述正文属性的字段,主要有:
- Content-Type:指示正文的数据类型。
- Content-Length:说明正文的长度,以便服务器确定消息边界。
Content-Type的值表示正文所采用的编码模式:
- 若为普通键值对文本,值为
application/x-www-form-urlencoded,强制要求使用 URL 编码(Percent-encoding) 。所有的空格变成+,所有的特殊字符(如&)变成%XX。。 - 若包含文件上传,值为
multipart/form-data,并且后面会指定一个分界字符串。
分界字符串是随机生成的、较长且复杂的字符串,用于分隔正文中不同部分(如不同字段或文件)。每个部分之前以-- 加分界字符串开始,正文结束处以-- 加分界字符串再加-- 结束。这样可避免与内容中的文本意外重合。
示例:
假设在网页中输入用户名为"张三",上传文本文件 note.txt(内容为Hello&World ),并上传二进制图片 avatar.jpg,则请求正文格式大致如下:
http
------MyBoundary
Content-Disposition: form-data; name="user"
张三
------MyBoundary
Content-Disposition: form-data; name="note"; filename="note.txt"
Content-Type: text/plain
Hello & World
------MyBoundary
Content-Disposition: form-data; name="avatar"; filename="avatar.jpg"
Content-Type: image/jpeg
[图片的二进制数据]
------MyBoundary--每个部分的首部包含元数据,其中:
- Content-Disposition 为
form-data,表示该部分来自表单。 - name 对应HTML中
<input>的name属性。 - 对于文件,会包含
filename指明文件名,并由Content-Type指明其MIME类型。
对应的表单HTML示例:
html
<form action="/api/upload" method="POST" enctype="multipart/form-data">
<label>用户名:</label>
<input type="text" name="user" value="张三">
<label>备注文档:</label>
<input type="file" name="note">
<label>上传头像:</label>
<input type="file" name="avatar">
<button type="submit">提交整车货物</button>
</form>而需要补充说明的是,表单 (Form)也可以设置为通过GET方法提交数据。由于GET请求不携带请求正文,表单数据会被整合到URL 中,以查询参数 (Query Parameters)的形式出现。查询参数 位于路径之后,以"?" 符号分隔,其本身由"键=值" 对组成,多个参数之间用"&" 连接,格式与之前介绍的查询参数一致,只是与POST请求存放的位置不同。此外,如果表单值中包含特殊字符(如空格、中文等),仍会进行URL编码以确保传输的可靠性。
| 提交方式 | 数据藏在哪? | 报文里的样子 | 有无正文? |
|---|---|---|---|
| GET | 请求行 (URL) | GET /path?name=tom&age=20 HTTP/1.1 |
无 |
| POST | 请求正文 | Content-Type: multipart/form-data... |
有 |
注:由于GET方式将数据暴露在URL中,这意味着如果提交的表单包含敏感信息(例如用户名、密码、身份证号等),这些信息会直接显示在浏览器的地址栏中,因此存在泄露风险。因此,GET方法仅适合用于非敏感、可公开、可分享的查询操作,而不应用于传输密码、个人身份信息等敏感数据,此外,由于URL长度存在限制(通常因浏览器与服务器的不同,在数千字符以内),通过GET请求提交的表单无法传输大量数据,例如文件上传。
POST方式将数据放在请求正文中,更适合提交敏感或大量数据(如文件上传)。
响应报文
上文梳理了请求报文之后,接下来梳理响应报文。响应报文的格式与请求报文高度对称,也由四部分组成,分别是响应行、响应头、空行和响应正文。每个部分之间会有空格分隔,末尾会有一个回车换行符,下文将依次解析这四个部分的构成及相关细节。
首先是响应行。响应行由三部分组成,分别是协议版本、状态码和状态描述。其中状态码是一个3位十进制数字,首位数字为1~5,分别对应不同的状态类别:
| 类别 | 含义 | 场景比喻 | 常见例子 |
|---|---|---|---|
| 1xx | 信息性状态码 | "收到了,别急,处理中..." | 101 Switching Protocols:升级到 WebSocket 协议。 |
| 2xx | 成功状态码 | "没问题,你要的东西在这。" | 200 OK :请求成功;201 Created:上传文件成功。 |
| 3xx | 重定向状态码 | "你要的东西搬家了,去那取。" | 301 :永久搬家;302 :临时出差;304:你本地有缓存,直接看缓存。 |
| 4xx | 客户端错误 | "你的请求有误,我没法办。" | 400 :参数写错了;403 :我有但不给你看;404:我这没这东西。 |
| 5xx | 服务器错误 | "我出故障了,稍后再试。" | 500 :后台程序崩溃了;502 :网关坏了;504:后台超时了。 |
首位为1的状态码表示服务器已收到客户端请求,正在处理中,此时会先返回一个1xx的响应报文。首位为2的状态码表示服务器已成功接收并正确处理请求,最常见的如200,描述为"OK"。
首位为3的状态码表示重定向。所谓重定向,是指服务器上原有站点可能已临时或永久关闭,但客户端并不感知,仍会访问旧地址。服务器收到请求后,发现目标站点已关闭,便会构造一个响应报文。若为临时关闭,状态码设为302;若为永久关闭,则设为301。同时,响应头中会设置一个Location 字段,其值为新站点的URL,而响应正文通常为空。
http
HTTP/1.1 301 Moved Permanently
Location: https://www.new-site.com/index.html
Content-Length: 0
---------------------------------------------------------------------
HTTP/1.1 302 Found
Location: https://example.com/login.html客户端收到此类响应后,会依据Location 字段重新向新地址发起请求。对于临时重定向,浏览器一般不会缓存该跳转;而对于永久重定向,浏览器会进行缓存,之后用户再次访问原地址时将直接请求新站点,无需再次收到重定向响应。
首位为4的状态码表示客户端错误,通常是请求的资源不存在。这类错误多由GET请求触发,因为GET请求的URL通常对应服务器文件系统中某个资源的路径。若该路径无效或资源不存在,则属于客户端错误------客户端请求了不存在的资源。此时服务器会构造状态码为404的响应报文,并通常返回一个自定义的错误页面(HTML文档)作为响应正文,浏览器渲染后即呈现常见的"404页面"。另外,状态码403表示请求的URL有效,服务器能找到对应资源,但客户端无权访问,例如尝试访问服务器配置文件时会返回403。
首位为5的状态码表示服务器内部错误,常见如500。例如服务器端处理程序抛出异常并被捕获后,服务器会构造状态码为500的响应报文返回给客户端。
解析完响应行后,接下来是响应头。响应头的格式与请求头相同,由一行行键值对构成,每个键值对之间以回车换行符分隔。响应头中的大部分字段与请求头一致,但由于响应报文中通常包含响应正文,因此响应头会包含描述正文属性的字段,主要是 Content-Type 和 Content-Length,分别用于指明正文的数据类型和长度。
除了这两个常见字段,响应报文还可能包含一些特有的头部字段,例如 Set-Cookie。要理解这个字段的作用,需要先回顾一下 HTTP 连接的基本行为:每当客户端向服务器请求资源时,都需要发送一个请求。如果使用短连接,则客户端每次请求后,服务器返回响应,连接即关闭;下次再请求资源时,必须重新建立连接。
重要的是,这些连接之间是相互独立的,即一次连接中进行的通信内容与之前的连接毫无关联,每个连接都是全新的会话。这类似于每次与某人聊天都不保存历史记录,每次都从头开始------这也正是 HTTP 协议无状态(stateless)特性的体现。
在这种无状态模式下,若某个网站要求用户身份认证,就会带来问题。例如,用户访问页面 A 并完成登录,接着跳转到页面 B 时,由于 HTTP 无状态,服务器无法得知这次请求来自之前已认证的用户,因此会再次要求提交身份信息。这意味着每访问一个新页面,都可能需要重新登录,体验十分繁琐。
为了解决这个问题,常见的做法是利用会话(Session)机制。当客户端首次向服务器发起请求时,服务器会为其生成一个唯一的 Session ID,用以标识该会话。服务器通常会管理来自不同客户端的会话,一般通过一个结构体来记录会话信息(例如用户名、登录时间、Session ID ,过期时间等),并将这些结构体以 Session ID 为键组织成哈希表,以提升查询效率。
在构建响应报文时,服务器会在响应头中添加 Set-Cookie 字段,将 Session ID 通过该字段返回给客户端。Set-Cookie 除了携带会话标识外,通常还包含若干属性,用于控制 Cookie 的作用范围、有效期等。例如:
- Domain:指定 Cookie 生效的域名。例如,在
taobao.com站点完成登录后,该站点的 Cookie 通常仅在此域名下生效。当访问其他站点(如baidu.com)时,浏览器不会发送属于淘宝的 Cookie,从而实现安全的跨站隔离。 - Path:进一步限制 Cookie 的有效路径,即 URL 的路径部分。它可以限定 Cookie 仅在某个路径下有效(如
/music仅对音乐相关页面共享登录状态),或在整个站点生效(path=/)。Path 可视为对登录状态共享范围的一层更细粒度的约束。 - Expires:指定 Cookie 过期的绝对时间,格式为标准的 HTTP 日期时间。
- Max-Age:指定 Cookie 的有效时长(以秒为单位),是一个相对时间。如果同时设置了
Expires和Max-Age,通常Max-Age优先级更高。
示例格式如下:
http
Expires=Wed, 21 Oct 2026 07:28:00 GMT
Max-Age=3600通过合理设置这些属性,服务器可以精确控制会话状态的作用域和生命周期,在保障安全的前提下维持用户的登录状态。
客户端(通常是浏览器)收到后会将 Set-Cookie中的所有字段保存起来,可以存储在内存中(浏览器关闭后失效),也可以持久化到磁盘。
http
Set-Cookie: session_id=abc123456; Expires=Wed, 21 Oct 2026 07:28:00 GMT; Path=/;此后,客户端再次向该服务器发送请求时,会在请求头的 Cookie 字段中携带这个 Session ID。服务器接收到后,即可通过查询会话哈希表获取对应的会话信息,从而识别用户身份,并进一步获取相关数据(例如根据用户名查询数据库)。这样,就通过 Session 与 Cookie 的配合,在无状态的 HTTP 协议基础上实现了用户状态的保持,避免了重复登录的问题。
在响应头之后是一个空行。这里的"空行"实质上就是一个回车换行符(CRLF,即\r\n )。由于每个响应头末尾已经带有一个\r\n ,而响应头结束后紧跟的空行又是一个\r\n ,因此实际上会用两个连续的\r\n\r\n 来标记响应头的结束。空行之后便是响应正文。
至此,我们已经梳理了 HTTP 请求与响应报文的完整结构。
HTTP服务器
基于已有的HTTP理论储备,接下来可以进入实战环节,即实现一个Web服务器。
根据上文的讨论,客户端在地址栏获取用户输入的URL。用户输入的URL本质上是一个字符串,客户端(浏览器)会按照URL的结构对其解析,分割出协议、域名等部分,接着查询本地缓存或向本地DNS服务器发起请求,将域名转换为IP地址,随后开始与服务器通信。
HTTP协议基于TCP传输协议,因此客户端与服务器需先建立连接,完成三次握手后正式通信。客户端构建请求报文并发送给服务器,服务器接收后处理请求,构造响应报文并返回给客户端,这就是通信的核心流程。
在这一流程中,服务器的实现框架与我们之前编写的服务端程序大体一致,主要区别在于业务处理逻辑,即通信环节的具体实现。整体框架遵循固定模式:创建监听套接字,绑定IP地址与端口号,进入监听状态等,即依次调用socket 、bind 等系统接口。
本次使用C++编写Web服务器,借助C++的面向对象特性,将服务器抽象为一个对象,用Httpserver 类进行描述。将上述固定流程------即系统接口的调用------封装到Httpserver 类的成员函数中,以使逻辑更清晰。
此外,我们做了进一步封装:不在Httpserver类的成员函数中直接调用系统接口,而是将这些接口封装到一个专门的sock 类中。该类维护一个文件描述符,并提供socket 、bind 等方法。这些方法内部执行固定逻辑:调用对应接口、检查返回值,若出错则记录错误日志(此处已引入日志模块)。同时,该类采用RAII思想,将套接字的生命周期交由sock 类管理,其析构函数会尝试调用close 接口释放套接字资源。
cpp
#include<arpa/inet.h>
#include<netinet/in.h>
#include<unistd.h>
#include<string>
#include<cstring>
#include<cstdlib>
#include"log.hpp"
extern log lg;
enum
{
Socket_Error = 1,
Bind_Error,
Listen_Error,
Accept_Error,
Connect_Error,
Usage_Error,
};
class sock
{
public:
sock()
:socketfd(-1)
{
}
~sock()
{
if (socketfd >= 0)
{
::close(socketfd);
}
}
void socket()
{
socketfd = ::socket(AF_INET, SOCK_STREAM, 0);
if (socketfd < 0)
{
lg.logmessage(Fatal, "socket error");
socketfd = -1;
exit(Socket_Error);
}
int opt = 1;
setsockopt(socketfd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
lg.logmessage(info, "socket successfully");
}
void bind(std::string ip, uint16_t port)
{
if (socketfd < 0)
{
lg.logmessage(Fatal, "socket not created");
exit(Socket_Error);
}
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(port);
if (ip == "0.0.0.0")
{
server.sin_addr.s_addr = INADDR_ANY;
}
else if (inet_pton(AF_INET, ip.c_str(), &server.sin_addr) <= 0)
{
lg.logmessage(Fatal, "inet_pton fail");
::close(socketfd);
socketfd = -1;
exit(Bind_Error);
}
socklen_t serverlen = sizeof(server);
int n = ::bind(socketfd, (struct sockaddr*)&server, serverlen);
if (n < 0)
{
lg.logmessage(Fatal, "bind error");
::close(socketfd);
socketfd = -1;
exit(Bind_Error);
}
lg.logmessage(info, "bind successfully");
}
void listen()
{
if (socketfd < 0)
{
lg.logmessage(Fatal, "socket not created");
exit(Socket_Error);
}
int n = ::listen(socketfd, 5);
if (n < 0)
{
lg.logmessage(Fatal, "listen error");
::close(socketfd);
socketfd = -1;
exit(Listen_Error);
}
lg.logmessage(info, "listen successfully");
}
int accept(struct sockaddr_in* client, socklen_t* clientlen)
{
if (socketfd < 0)
{
lg.logmessage(Fatal, "socket not created");
exit(Socket_Error);
}
int client_fd = ::accept(socketfd, (struct sockaddr*)client, clientlen);
if (client_fd < 0)
{
lg.logmessage(Fatal, "accept error");
return -1;
}
lg.logmessage(info, "accept successfully");
return client_fd;
}
void connect(struct sockaddr_in* server, socklen_t serverlen)
{
if (socketfd < 0)
{
lg.logmessage(Fatal, "socket not created");
exit(Socket_Error);
}
int n = ::connect(socketfd, (struct sockaddr*)server, serverlen);
if (n < 0)
{
lg.logmessage(Fatal, "connect error");
::close(socketfd);
socketfd = -1;
exit(Connect_Error);
}
lg.logmessage(info, "connect successfully");
}
void close()
{
if (socketfd >= 0)
{
::close(socketfd);
socketfd = -1;
}
}
sock(const sock&) = delete;
sock& operator=(const sock&) = delete;
private:
int socketfd;
};对Httpserver 类而言,无需在其成员函数中重复实现上述逻辑,只需在类中维护一个sock 对象,并直接调用该对象提供的方法即可。这样做的好处是,将sock 类独立置于Socket.hpp 文件中,未来编写其他服务器代码时可直接引入该头文件。由于服务器的整体框架大致相同,都会依次调用这些接口,因此只需维护一个通用的sock 类。
Httpserver 类的成员变量包括:一个sock 对象、服务器要绑定的IP地址(string 类型)、端口号(整型),以及一个布尔类型的监听标志。其构造函数接收IP地址和端口号两个参数。sock 对象作为自定义类型,会调用默认构造函数进行初始化,将其内部的套接字文件描述符置为无效值-1。IP地址通常设置为"0.0.0.0" ,以接收所有网络接口的数据包;HTTP服务默认在80端口监听,因此我们为这两个参数提供了缺省值,并将布尔类型的监听标志初始化为false 。
cpp
std::string _default = "0.0.0.0";
extern log lg;
class Httpserver
{
public:
Httpserver(std::string _ip = _default, uint16_t _port=80)
:ip(_ip)
, port(_port)
,islistening(false)
{
}
//...
private:
uint16_t port;
std::string ip;
sock listen_socket;
bool islistening;
};接下来是init 函数,其功能是创建监听套接字并将其绑定到指定IP地址和端口,即依次调用sock 类提供的socket和bind 接口。
然后是start 函数。该函数首先检查监听标志是否为true :若是,说明监听套接字已处于监听状态,即之前已调用过start 函数,此时记录日志并直接返回;否则,调用sock 类的listen 接口,将监听套接字从CLOSE状态转为LISTEN状态。
成功设置为监听状态后,将监听标志设为true ,随后进入循环。循环内的逻辑是:调用sock 类的accept 接口接收新连接,然后进入通信环节。需要注意的是,服务端会持续收到完成TCP三次握手的新连接,如果服务端在接收一个新连接后立即进入通信环节,而不继续接收其他已就绪的连接,会导致监听套接字的全连接队列迅速填满,进而使客户端连接建立失败。此外,接收新连接与处理通信是两个相互独立、可并行执行的动作,也就是说,接收新连接无需等待当前通信过程结束即可进行,因此需要对二者进行解耦。
基于以上两点,我们考虑创建线程。线程本质上是一个用户态函数,其执行上下文即为通信处理逻辑。本Web服务器基于HTTP/1.0实现,默认使用短连接,即服务端在接收请求、发送响应后立即关闭连接,因此单次通信持续时间较短。为避免频繁创建和销毁线程带来的开销,这里引入线程池。
线程池维护一个任务缓冲区与一组消费者线程。我们定义一个Task 任务对象,其中包含一个run 方法,该方法封装了通信处理逻辑。因此,Task 对象内部需保存一个成员变量:已连接套接字对应的文件描述符。服务器作为主线程,在accept接收到新连接后,会构造一个Task 对象并将其放入线程池的缓冲区。消费者线程从缓冲区获取任务对象,并调用其run 方法执行通信处理。由于线程池采用单例模式,在进入循环前,需先通过threadpool 类的静态成员函数获取单例对象,并调用其start 函数初始化并创建一批工作线程,随后进入循环。
cpp
accept 拿到 client_fd -> 封装成 Task -> 扔进队列 -> 消费者线程竞争获取任务。
cpp
class httpserver{
void start()
{
listen_socket.listen();
if (islistening)
{
lg.logmessage(warning,"server is already listening");
return;
}
islistening = true;
threadpool& tp = threadpool::getinstance();
tp.start();
struct sockaddr_in client;
socklen_t client_len = sizeof(client);
memset(&client, 0, client_len);
while (islistening)
{
size_t client_fd=listen_socket.accept(&client,&client_len);
Task t(client_fd);
tp.push(t);
}
}
//...
};接下来将聚焦于通信环节。我们知道,HTTP通信的大致流程是:服务端接收客户端发送的请求报文,处理该请求报文,构建响应报文,然后将其返回给客户端。
由于 HTTP 协议基于 TCP 协议,因此整个通信的第一个环节便是读取客户端发来的请求报文。TCP 协议是面向字节流的,这意味着读取报文时以字节为单位,可能导致一次读取仅得到报文的一部分,或超过一个完整报文。而客户端期望服务端能读取完整的 HTTP 请求,因此我们需要依据 HTTP 请求报文的格式进行解析。
HTTP 请求报文由四个部分组成。其中,请求头结束后会有一个空行,而请求头最后一行末尾带有回车换行符(CRLF),与空行共同构成连续的两个 CRLF(即\r\n\r\n )。这为我们判断是否读取到完整的请求行与请求头提供了依据。
下面我们将读取完整 TCP 报文段的功能封装为Get_HttpRequest函数模块。该函数返回类型为bool:读取成功返回true ,失败返回false 。
我们首先准备一个大小为 1024 字节的字符数组作为输入缓冲区,调用recv 接口读取请求报文并存入缓冲区。接着检查recv 的返回值:若小于 0,表示读取失败,记录错误日志并返回false 。
接下来需要判断是否已读取完整的请求行与请求头。由于 HTTP 请求报文是文本内容,即字符序列,我们需进行字符串解析。为此,将输入缓冲区(字符数组)转换为std::string 对象,以便利用其提供的字符串操作函数。我们调用find 函数查找连续的两个 CRLF(\r\n\r\n )。
find 函数返回ssize_t 类型的值:若找到,则返回子串首个字符的索引(非负);若未找到,则返回std::string::npos 。因此,若返回值不等于npos ,说明已读取完整的请求行与请求头;否则,需继续读取。
我们使用一个循环持续读取数据。在循环前定义输入缓冲区及std::string 对象data 。每次读取一定字节的数据存入缓冲区,再将其拼接到data 中。注意:拼接时应使用append 函数而非+= 运算符,因为缓冲区中的字符序列不一定以\0 结尾,使用+= 可能导致越界风险。append 可指定长度,确保拼接安全。
cpp
std::string data;
char buffer[BUFFER_SIZE];
while (true) {
ssize_t read_bytes = recv(socketfd, buffer, BUFFER_SIZE - 1, 0);
if (read_bytes <= 0) {
lg.logmessage(Fatal, "recv error");
return false;
}
data.append(buffer, read_bytes);
if (data.find("\r\n\r\n") != std::string::npos) {
break;
}
}在循环中,每次读取后检查data 中是否包含"\r\n\r\n" 。若存在,则跳出循环,表明已获得完整的请求行与请求头。需要注意的是,此时data 中可能不仅包含请求行与请求头,若为 POST 请求,还可能包含部分请求正文。因此,我们需要从中分离出纯净的请求行与请求头部分。
使用substr 函数进行分割:起始索引为 0,长度为find("\r\n\r\n") 返回值加 4(包含空行),结果存入head 对象。
cpp
std::string head = data.substr(0, data.find("\r\n\r\n") + 4);接下来,检查是否存在请求正文。对于 POST 请求,其请求头中包含Content-Length 字段,用于描述正文长度。我们在head 中查找子串"Content-Length:" ,若存在,则表明有请求正文;否则,可能为 GET 请求,无正文部分。
若找到"Content-Length:" ,则进一步提取其属性值。请求头由键值对组成,每对以 CRLF 结尾。我们可从"Content-Length:" 之后查找最近的 CRLF,再使用substr 分割出表示长度的子串。由于键与值之间可能存在空格,而std::stoi 函数会自动忽略前导空格与零,因此可直接转换为整数content_length 。
cpp
size_t pos = data.find("Content-Length:");
if (pos != std::string::npos) {
ssize_t endpos = head.find("\r\n", pos);
std::string content_length_str = head.substr(pos + 15, endpos - pos - 15);
size_t content_length = std::stoi(content_length_str);
// ...
}在读取请求行与请求头时,可能已读取部分请求正文。我们计算已读取的正文长度remaining=data.size()-head.size() ,与完整的正文长度content_length 比较:
- 若
remaining>=content_length,说明已读取完整正文,可直接从data中分割出正文。 - 若
remaining<content_length,则需继续读取剩余正文。先将已读部分存入body,然后计算仍需读取的字节数to_read。循环调用recv读取剩余数据,每次最多读取BUFFER_SIZE-1字节,并拼接到body,直到to_read为 0。
cpp
size_t remaining = data.size() - head.size();
if (remaining < content_length) {
std::string body = data.substr(data.find("\r\n\r\n") + 4, remaining);
int to_read = content_length - remaining;
char body_buffer[BUFFER_SIZE];
while (to_read > 0) {
ssize_t read_bytes = recv(socketfd, body_buffer,
std::min(BUFFER_SIZE - 1, to_read), 0);
if (read_bytes <= 0) {
lg.logmessage(Fatal, "recv error");
return false;
}
body.append(body_buffer, read_bytes);
to_read -= read_bytes;
}
hr.text = body;
} else {
hr.text = data.substr(data.find("\r\n\r\n") + 4, content_length);
}至此,我们已获取完整的请求行、请求头及请求正文。接下来进行反序列化,将这些字节流转换为结构化的对象,便于后续处理。定义http_request 结构体,其成员包括:
std::unordered_map<std::string> header:存储请求头的键值对。std::string method、url、http_version:存储请求行解析出的方法、URL 和协议版本。std::string text:存储请求正文。
cpp
class Http_Request
{
public:
//...
public:
std::vector<std::string> header;
std::string text;
std::string method;
std::string url;
std::string http_version;
};该结构体提供反序列化成员函数Deserialization ,其功能为解析head 字符串,提取请求行各部分并填充至成员变量,同时将请求头键值对存入哈希表。函数返回bool 类型,表示解析成功与否。
最终,Get_httpRequest 函数在成功读取并解析请求后,调用hr.Deserialization(head) 进行反序列化,并返回结果。
cpp
bool Get_HttpRequest(size_t socketfd, Http_Request& hr) {
std::string data;
char buffer[BUFFER_SIZE];
while (true) {
ssize_t read_bytes = recv(socketfd, buffer, BUFFER_SIZE - 1, 0);
if (read_bytes <= 0) {
lg.logmessage(Fatal, "recv error");
return false;
}
data.append(buffer, read_bytes);
if (data.find("\r\n\r\n") != std::string::npos) {
break;
}
}
std::string head = data.substr(0, data.find("\r\n\r\n") + 4);
size_t pos = data.find("Content-Length:");
if (pos != std::string::npos) {
ssize_t endpos = head.find("\r\n", pos);
std::string content_length_str = head.substr(pos + 15, endpos - pos - 15);
size_t content_length = std::stoi(content_length_str);
size_t remaining = data.size() - head.size();
if (remaining < content_length) {
std::string body = data.substr(data.find("\r\n\r\n") + 4, remaining);
int to_read = content_length - remaining;
char body_buffer[BUFFER_SIZE];
while (to_read > 0) {
ssize_t read_bytes = recv(socketfd, body_buffer,
std::min(BUFFER_SIZE - 1, to_read), 0);
if (read_bytes <= 0) {
lg.logmessage(Fatal, "recv error");
return false;
}
body.append(body_buffer, read_bytes);
to_read -= read_bytes;
}
hr.text = body;
} else {
hr.text = data.substr(data.find("\r\n\r\n") + 4, content_length);
}
}
bool res = hr.Deserialization(head);
hr.debugprint();
return res;
}调用Get_httpRequest 时,需预先定义http_request 对象作为输出型参数,连同已连接套接字的文件描述符一并传入。
接下来是关于http_request 类的Deserialization 函数。该函数的功能是提取请求行和请求头的键值对,并将键值对保存到名为header的哈希表中。由于请求行与请求头之间由回车换行符(CRLF)分隔,首先需要分割出请求行及各请求头字段。具体实现思路是定义一个整型变量start,用于记录分割的起始位置;同时定义一个整型变量end,用于定位回车换行符。
分割逻辑被置于一个循环中。进入循环之前,会定义一个名为_header 的std::vector<std::string> 数组,该数组用于临时保存分割后的请求行及每个请求头字段(键值对组成的整行字符串),start初始值设为0,随后调用find函数查找子串"\r\n" ,该函数接收两个参数:待查找的子串及起始查找位置。若返回std::string::npos ,表示未找到回车换行符,说明客户端构建的请求报文有误,此时返回false。若查找成功,则通过substr函数分割出子串(不包含换行符),并将其插入_header 数组。接着更新start和end的位置,将start移动到所找到的子串"\r\n" 之后,即start = end + 2,然后重复上述过程。
需注意的是,请求头部分末尾包含一个空行。当start移动到最后一个回车换行符之后的字符,即空行"\r\n" 的起始位置时,再次调用find函数将返回该位置。此时通过substr分割出的子串为空,表明所有请求行和请求头键值对已分割并保存至数组,循环结束。
接下来,我们需要将分割出的请求头键值对插入到哈希表header 中。由于数组_header 的第一个元素是请求行,因此从第二个元素开始遍历。每一行的键和值之间由冒号分隔,首先调用find 函数查找冒号的位置,若未找到(返回npos),则说明客户端构建的请求报文格式错误,函数返回false 。接着,通过substr 分割出冒号前的部分作为键(key)。
冒号之后可能存在一个或多个空格,之后才是值的起始位置。由于某些客户端构建的请求报文可能不规范,空格数量不定,我们通过一个循环跳过所有空白字符,定位到值的起始索引。随后,再次调用substr 分割出剩余部分作为值(value)。最后,将键值对插入到哈希表header 中。
cpp
for (size_t i = 1; i < _header.size(); i++)
{
std::string line = _header[i];
size_t pos = line.find(":");
if (pos == std::string::npos)
{
return false;
}
std::string key = line.substr(0, pos);
size_t val_start = pos + 1;
// 跳过冒号后的空白字符,issspace接收一个字符,如果当前字符为空格等空白字符,返回为true
while (val_start < line.size() && std::isspace(line[val_start]))
{
val_start++;
}
std::string value = line.substr(val_start);
headers[key] = value;
}最后的任务是解析已保存至数组的请求行,即数组的第一个元素。请注意,分割时已去除末尾的回车换行符。请求行由三个部分组成,每部分以空格分隔,依次是请求方法、URL和协议版本。
对于请求行的解析,常见有两种实现方式。第一种做法是定义两个变量,分别记录分割的起始位置和结束位置(即空格所在位置)。具体步骤是:首先调用find 函数定位第一个空格,通过substr 分割出请求方法;然后将起始位置移动到该空格之后,再次调用find 函数查找下一个空格,分割出URL;最后将起始位置移动到第二个空格之后,直接分割剩余部分作为协议版本。
cpp
std::string first_line = header[0];
size_t space1 = first_line.find(" ");
if (space1 == std::string::npos)
{
return false;
}
method = first_line.substr(0, space1);
size_t space2 = first_line.find(" ", space1 + 1);
if (space2 == std::string::npos)
{
return false;
}
url = first_line.substr(space1 + 1, space2 - space1 - 1);
http_version = first_line.substr(space2 + 1);但需注意,某些客户端构建的请求报文格式可能不规范,例如各部分之间的空格数量可能不止一个,这会导致解析失败。因此,更推荐的做法是使用stringstream 。
在C++中,字符串被抽象为流对象。stringstream 内部通过缓冲区存储字符串,并重载了<< 和>> 运算符。stringstream 对象内部维护两个独立的指针:读指针和写指针,两者默认均指向缓冲区起始位置。调用>> 运算符时,会从读指针当前位置开始解析:若读指针指向分隔符(如空格),则跳过该分隔符,直至遇到非分隔符字符;然后持续读取,直到再次遇到分隔符,将这段子串提取到>> 操作符右侧的string 对象中。若读指针到达缓冲区末尾,会设置EOF标志,后续提取操作将失败。
stringstream要跳过的分割符:
| 字符 (Character) | 转义序列 (Escape) | ASCII 值 (Hex/Dec) | 描述 (Description) |
|---|---|---|---|
| 空格 | ' ' |
0x20 / 32 |
最常见的单词分隔符 |
| 换行符 | '\n' |
0x0A / 10 |
Line Feed,Unix/Linux 系统下的换行 |
| 回车符 | '\r' |
0x0D / 13 |
Carriage Return,Windows 换行符(\r\n)的一部分 |
| 水平制表符 | '\t' |
0x09 / 9 |
Tab 键,通常对应 4 或 8 个空格 |
| 垂直制表符 | '\v' |
0x0B / 11 |
Vertical Tab,现代编程中较少使用 |
| 换页符 | '\f' |
0x0C / 12 |
Form Feed,常用于控制打印机换页 |
而<< 运算符用于向缓冲区写入字符串,从写指针当前位置开始拼接。需要注意,应避免在同一stringstream 对象上混用读、写操作,因为写入操作会从写指针位置开始覆盖缓冲区内容。若流对象已初始化(缓冲区中已有数据),写入新字符串会覆盖原有数据。
cpp
#include <sstream>
#include <iostream>
int main()
{
std::stringstream ss("hello world wz\\n ");
std::string a, b, c, d;
ss >> a >> b >> c;
std::cout << a << std::endl;
std::cout << b << std::endl;
std::cout << c << std::endl;
ss << "wz";
std::cout << "Buffer now: " << ss.str() << std::endl;
return 0;
}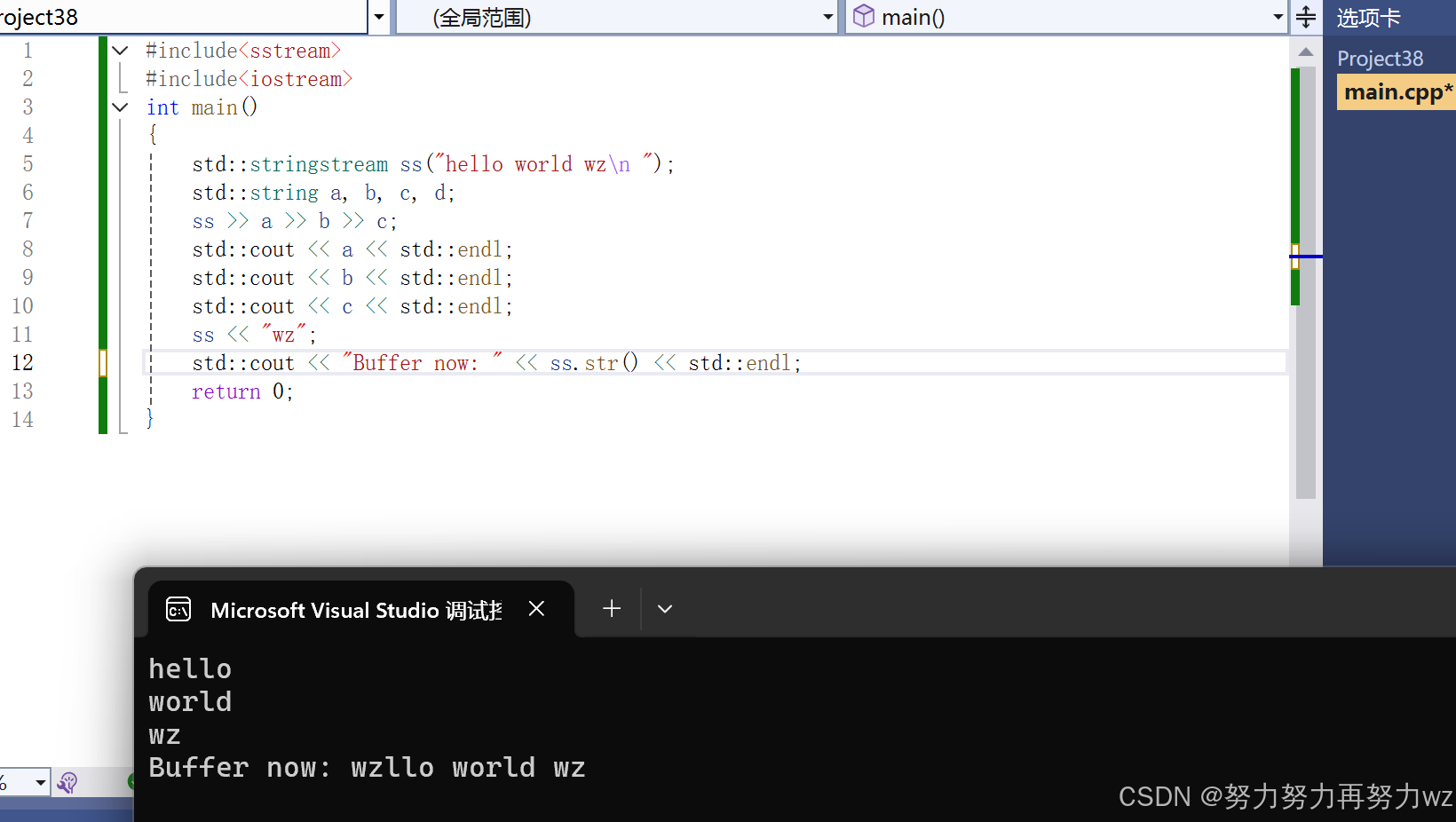
stringstream 提供了str() 成员函数:无参版本返回临时字符串对象;有参版本会清空缓冲区并重新设置内容,同时将读写指针重置到开头,但不会清除EOF标志。如需清除EOF标志,需额外调用clear() 函数。
cpp
bool Deserialization(std::string& head)
{
size_t start=0;
std::vector<std::string>_header;
while(true)
{
std::string line;
size_t end=head.find("\r\n",start);
if(end==std::string::npos)
{
return false;
}
line=head.substr(start,end-start);
if(line.empty())
{
break;
}
start=end+2;
_header.push_back(line);
}
if(_header.size()<1)
{
return false;
}
for(size_t i=1;i<_header.size();i++)
{
std::string line=_header[i];
ssize_t pos=line.find(":");
if(pos==std::string::npos)
{
return false;
}
std::string key=line.substr(0,pos);
size_t val_start=pos+1;
while(val_start<line.size() && std::isspace(line[val_start]))
{
val_start++;
}
std::string value=line.substr(val_start);
headers[key]=value;
}
std::string first_line=_header[0];
std::stringstream ss(first_line);
ss>>method>>url>>http_version;
return true;
}为便于调试,在http_request类中还定义了一个debugprint函数。该函数用于打印请求报文,由于请求报文为文本格式,可直接阅读。请求行、请求头及请求正文均已保存至对应变量中,因此只需按HTTP报文的格式打印各部分即可。
cpp
void debugprint()
{
std::cout<<std::endl;
std::cout<<method<<" "<<url<<" "<<http_version<<std::endl;
for(auto it=headers.begin();it!=headers.end();it++)
{
std::cout<<it->first<<": "<<it->second<<std::endl;
}
std::cout<<std::endl;
std::cout<<text<<std::endl;
std::cout<<std::endl;
}因此,在http_Get_HttpRequest函数中调用反序列化函数后,特意调用了debugprint函数,以输出客户端发送的请求报文内容,辅助验证解析结果。
成功获取完整TCP报文段并反序列化后,各字段将解析并存储到一个http_request 对象中,该过程通过调用Get_HttpRequest 函数实现。若函数返回false ,则表示获取完整TCP报文失败或反序列化过程出现错误,此时记录日志并退出处理流程;若返回true ,则进入请求报文处理阶段。
在反序列化过程中,请求行的各个参数已被解析并存入http_request 对象的对应字段,后续逻辑进入业务分发阶段。系统依据method 字段判断请求类型:若为GET方法,则优先尝试静态资源映射;若为POST方法,则触发动态业务逻辑处理(通用网关接口,CGI)。通过这种基于HTTP方法的分流机制,确保不同类型的请求能够被路由至相应的处理模块。
为此,这里定义了两个处理函数模块:Http_Get_Handler 与Http_Post_Handler 。根据http_request 对象中的method 字段,调用对应的处理函数。这两个函数的返回值为srting 类型,即构造好的响应报文。获取响应报文后,调用send 接口将其发送回客户端,随后关闭套接字并正常结束当前连接处理流程。
cpp
void run()
{
Http_Request hr;
bool get_result = Get_HttpRequest(socketfd, hr);
if (get_result == false)
{
lg.logmessage(Fatal, "get http request error");
close(socketfd);
return;
}
std::string res;
if (hr.method == "GET")
{
res = Http_Get_Handler(hr);
}
else if (hr.method == "POST")
{
res = Http_Post_Handler(hr);
}
else
{
lg.logmessage(warning, "unsupported method: %s", hr.method.c_str());
close(socketfd);
return;
}
int send_bytes = send(socketfd, res.c_str(), res.size(), 0);
if (send_bytes < 0)
{
lg.logmessage(Fatal, "send error");
close(socketfd);
return;
}
close(socketfd);
}由于浏览器与服务端通信的场景中,绝大多数请求为GET或POST方法,若接收到其它类型的HTTP方法请求,此处将直接记录错误日志,随后关闭套接字并退出该连接的处理流程。
首先介绍的是Http_Get_Handler 处理模块。GET请求通常用于从服务器获取静态资源,即文件。在此上下文中,URL对应于服务器文件系统下的一个相对路径。我们以服务器所在目录作为根目录,将URL映射为该目录下的相对路径。具体而言,映射操作通过字符串拼接实现。为此,我定义了一个全局字符串变量path ,其值为./wwwroot 。通过将URL与path 拼接,我们可以在服务器目录下创建名为wwwroot 的文件夹,用于存放各类静态资源,包括HTML文本文件及图片等二进制文件。
需注意,观察输入的URL,某些情况下路径可能仅为根目录"/" ,而非具体路径。URL本应用于定位特定静态资源,但与"./wwwroot" 拼接后,其含义变为wwwroot目录下的所有内容。显然,我们无法将整个目录内容返回给客户端。因此,当URL为根目录时,实际表示获取站点首页。
一个站点由众多资源构成。访问站点时,首先获取的是首页资源,其中包含链接以跳转至其他页面。首页本质上是一个网页,服务器已在特定路径下保存对应的HTML文档。按照惯例,首页HTML文档的文件名通常为"index" ,并存放于wwwroot目录下。客户端访问首页时,既可显式指定路径(如"/index.html" ),也可省略URL,浏览器会默认访问首页并自动将URL设为"/"。例如,在地址栏输入www.baidu.com 与www.baidu.com/index.html 效果相同。若未显式指定协议或端口,浏览器默认采用HTTPS协议及443端口。
在先前反序列化过程中,我们已提取请求行中的各个参数。因此,此处首先需判断URL是否为根目录或首页文件。若是,则直接在path 后拼接字符串"/index.html" 。由于响应报文将携带响应正文,必须在响应头中设置Content-Type 字段,以告知客户端响应正文的数据类型,确保正确解析。每种文件类型均有对应的MIME类型映射,HTML的MIME类型为"text/html"。
cpp
std::string Http_Get_Handler(Http_Request& hr)
{
std::string file_path;
std::string content_type;
std::string res;
if (hr.url == "/" || hr.url == "/index.html")
{
file_path = path + "/index.html";
content_type = "text/html";
}
// ...
}若非上述情况,则表明URL是一个具体路径。此时,我们直接将URL拼接到path对象上。由于该路径用于定位特定文件,其终点应为一个具体文件名,格式通常为"文件名.扩展名",其中扩展名指示文件类型。为正确设置
Content-Type 字段,需获取文件扩展名。此处调用rfind 函数从后向前查找"."字符,若找到则返回其索引;若未找到(即返回npos ),则说明该路径可能为虚拟路径,用于路由至预定义函数。在本Web服务器的设计中,GET请求仅处理获取静态资源的情况。尽管GET请求也可用于提交表单(此时URL可能携带查询参数),但再本web服务器中暂不处理这种情况。
若rfind 返回npos,在此场景下,表示客户端请求的URL为虚拟路径,服务器将返回错误页面,指示请求的资源不存在。因此,将Content-Type 设置为text/html 。
若找到"." 符,则使用substr 函数分割出子串,即文件扩展名。我定义了一个专用函数,用于将文件扩展名映射为对应的MIME类型。在Task 类中,维护了一个静态哈希表,键和值均为字符串类型,键为文件扩展名,值为MIME类型。由于Http_Get_Handler 为类外定义的函数,为访问类内成员变量,需在Task 类中定义静态成员函数suffix_handler 。静态成员函数仅能访问静态成员变量,因此该哈希表也需声明为静态成员变量,并在类外进行初始化,插入文件扩展名与MIME类型的键值对。
cpp
std::string Http_Get_Handler(Http_Request& hr)
{
std::string file_path;
std::string content_type;
std::string res;
if (hr.url == "/" || hr.url == "/index.html")
{
file_path = path + "/index.html";
content_type = "text/html";
}
else
{
file_path = path + hr.url;
size_t pos = file_path.rfind(".");
if (pos == std::string::npos)
{
content_type = "text/html";
}
else
{
std::string suffix = file_path.substr(pos);
content_type = Task::suffix_handler(suffix);
}
}
// ...
}Task 类的suffix_handler 函数负责查询哈希表:若存在对应扩展名的键,则返回其MIME类型;否则返回HTML类型对应的值(通常用于返回错误页面)。该函数返回字符串类型,Http_Get_Handler 调用此函数获取MIME类型并设置Content-Type 。对于具体路径,接下来需定位静态资源并读取其内容,因此我实现了read_file 函数。
read_file 函数接收文件路径,根据路径定位文件。文件读取涉及文件操作,此处使用C++的ifstream 流对象。其构造函数接受一个字符串参数,表示相对或绝对路径。若为相对路径,则基于当前工作目录进行解析,并打开文件将内容加载至内存。构造函数可接受两个参数:第一个为路径,第二个为打开模式,默认为文本模式。但此处统一以二进制模式打开,即使对于文本文件也是如此。二进制模式会忽略特殊字符(如换行符)的处理,确保完整读取所有数据;而文本模式下使用getline 等函数可能忽略某些控制字符。
为获取文件大小,需配合使用tellg 和seekg 函数。seekg 用于设置读指针位置,接受两个参数:偏移量和相对位置。标准库提供了三种相对位置:std::ios::beg (文件开头)、std::ios::end (文件结尾)和std::ios::cur (当前位置)。tellg 不接受任何参数,其返回当前读指针距文件开头的偏移量
首先调用seekg 函数将文件流对象的读指针设置到文件开头。随后调用tellg 函数(该函数不接受参数),返回当前读指针的位置。由于此时读指针已位于文件开头,返回的位置即为起始位置。接着再次调用seekg 将读指针设置到文件结尾,然后通过tellg 获取当前读指针位置,即文件结束位置。
需要注意的是,tellg 的返回值类型为std::streampos 。这是一个类类型,封装了文件状态和偏移量信息,但在实际使用中可将其视为类似size_t 的偏移量表示。计算文件大小时,需要从结束位置减去起始位置,这涉及到算术运算。std::streampos 重载了减法运算符,其返回类型为std::streamoff ,这是一个有符号整数类型,在标准库的实现中,std::streamoff 通常定义为long long 类型别名。
cpp
istream& read (char* s, streamsize n);获取文件大小后,调用ifstream 的read 函数,该函数接收一个char 类型缓冲区及文件大小参数,以二进制方式读取文件内容至缓冲区。此处,我使用string 对象content 作为缓冲区,在读取前通过resize 预分配足够空间,然后传递给read 函数。最后调用close 关闭文件并返回content 。
cpp
std::string read_file(std::string file_path)
{
std::ifstream file(file_path, std::ios::binary);
if (!file.is_open())
{
lg.logmessage(info, "file not found: %s", file_path.c_str());
return "";
}
file.seekg(0, std::ios::beg);
std::streampos start = file.tellg();
file.seekg(0, std::ios::end);
std::streampos end = file.tellg();
std::streamoff file_size = end - start;
std::string content;
content.resize(static_cast<size_t>(file_size));
file.seekg(0, std::ios::beg);
file.read(&content[0], file_size);
file.close();
return content;
}获取到文件内容后,接下来是构建响应报文。此时可能有读者会想:之前对于请求报文,我们会进行反序列化,用Http_request 对象来描述并保存解析得到的各个字段;那么对于响应报文,我们是否也需要定义一个类似的Http_reponse 对象来存储其各个字段呢?
这里我先说明:可以,但没必要。定义Http_request 对象的主要目的是为了更快速、更方便地访问请求报文的各个字段,比如请求行中的请求方法以及请求头的相关字段等。而对于响应报文,在当前服务端的上下文中,我们并没有访问其字段的需求------服务端只负责生成响应,并不需要解析或使用它。相反,客户端的行为与服务端是对称的,客户端可能需要解析响应报文,因此客户端才有必要定义一个Http_reponse 对象来存储响应报文的各个字段。由于服务端仅生成响应而不处理响应,所以在这里定义Http_reponse 对象并无必要。
因此,接下来我们直接构建响应报文即可。首先检查read_file 函数的返回值,即返回的string 对象是否为空。如果为空,说明read_file 打开文件失败,意味着路径无效或资源不存在。此时,响应报文的状态码应为 404,状态描述为"Not Found"。在资源未找到的情况下,我们应当向用户返回一个错误页面来提供提示。
为此,我们应在wwwroot 目录下准备一个对应的错误页面 HTML 文件。这里我在该目录下创建了一个404.html 文件。在拼接出该文件的完整路径后,再次调用read_file 读取其内容,并将其作为响应正文。获取 404 页面的内容后,依次构建响应行与响应头。响应头中必须包含描述响应正文的字段:Content-Type 用于告知客户端正文的 MIME 类型,确保正确解析;Content-Length 用于指示消息边界。此外,由于当前使用 HTTP/1.0 并采用短连接,还需添加Connection 字段,并将其值设为close 。
cpp
std::string body = read_file(file_path);
std::string header_line;
std::string header;
if (body.empty())
{
header_line = "HTTP/1.0 404 Not Found\r\n";
header += "Connection: close\r\n";
std::string content = read_file(path + "/404.html");
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
header += "Content-Type: text/html\r\n";
header += "\r\n";
res = header_line + header + content;
}若string 对象不为空,说明成功获取到资源,此时构建的响应报文状态码为 200,状态描述为"OK"。响应头字段与之前相同,包含 Content_Length 、Content_Type 和 Connection ,最后再拼接响应正文。完成响应报文的构建后,将最终得到的string 对象返回。
cpp
std::string Http_Get_Handler(Http_Request& hr)
{
std::string file_path;
std::string content_type;
std::string res;
if (hr.url == "/" || hr.url == "/index.html")
{
file_path = path + "/index.html";
content_type = "text/html";
}
else
{
file_path = path + hr.url;
ssize_t pos = file_path.rfind(".");
if (pos == std::string::npos)
{
content_type = "text/html";
}
else
{
std::string suffix = file_path.substr(pos);
content_type = Task::suffix_handler(suffix);
}
}
std::string body = read_file(file_path);
std::string header_line;
std::string header;
if (body.empty())
{
header_line = "HTTP/1.0 404 Not Found\r\n";
header += "Connection: close\r\n";
std::string content = read_file(path + "/404.html");
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
header += "Content-Type: text/html\r\n";
header += "\r\n";
res = header_line + header + content;
}
else
{
header_line = "HTTP/1.0 200 OK\r\n";
header += "Content-Length: " + std::to_string(body.size()) + "\r\n";
header += "Connection: close\r\n";
header += "Content-Type: " + content_type + "\r\n";
header += "\r\n";
res = header_line + header + body;
}
return res;
}上文介绍了Http_Get_handler ,接下来介绍Http_Post_handler 。我们知道 POST 请求会携带请求正文,并且其请求行中的 URL 是一个虚拟路径,用于映射到服务器预定义的函数,进而调用该函数处理参数并返回结果。因此,在设计时,我们将 Web 服务器提供的服务设定为一个计算器。站点首页会提供输入框,用于接收两个操作数和一个操作符,并通过表单上传至服务器。表单内容存放在请求正文中,以键值对格式存储。
该函数的逻辑是:首先解析请求正文。由于我们知道正文格式是以 "&" 分隔的键值对,且每个键值对的顺序是不确定的(第一个不一定是操作符,也可能是操作数),但每个键的名称与 HTML 文档中对应输入项的name 属性一致:
html
<form action="/calc" method="POST">
<input type="number" name="a" placeholder="输入数字 a" required>
<br>
<select name="op">
<option value="+">+</option>
<option value="-">-</option>
<option value="*">*</option>
<option value="/">/</option>
</select>
<br>
<input type="number" name="b" placeholder="输入数字 b" required>
<br><br>
<button type="submit">开始计算</button>
</form>表单提交的目标虚拟路径是/calc 。客户端识别该路径后,即可确定调用对应的处理函数。为此,我们需要准备一个键和值均为string 类型的哈希表,其中键为每个表单数据的名称。
接下来解析请求正文:先调用find 函数查找第一个 "&" 以分割键值对。如果find 返回npos ,说明客户端构建的请求报文有误,此时应返回状态码 400(Bad Request)的响应报文。我们专门定义了process_bad_request 函数来生成此类响应,其返回类型为string 。
cpp
std::string process_bad_request()
{
lg.logmessage(Fatal, "bad request body");
std::string headler_line = "HTTP/1.0 400 Bad Request\r\n";
std::string header = "Connection: close\r\n";
std::string content = "Bad Request";
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
header += "Content-Type: text/plain\r\n";
header += "\r\n";
return headler_line + header + content;
}若未返回npos ,则调用substr 分割出第一个键值对。每个键值对的格式为"键=值",因此再次调用find 在子串中查找 "="。若未找到,同样调用process_bad_request 并返回。找到后,继续用substr 分离键和值。若值前存在前导空格也无需担心,因为stoi 会自动忽略它们。将键和值插入哈希表后,重复上述过程直至解析完毕。
cpp
std::string Http_Post_Handler(Http_Request& hr) {
std::string res;
std::unordered_map<std::string, std::string> val;
size_t start = 0;
if (hr.url == "/calc") {
std::string body = hr.text;
size_t pos1 = body.find("&");
if (pos1 == std::string::npos) {
return process_bad_request();
}
std::string expression = body.substr(start, pos1);
size_t pos2 = expression.find("=");
if (pos2 == std::string::npos) {
return process_bad_request();
}
std::string result_key_str = expression.substr(start, pos2);
std::string result_value_str = expression.substr(pos2 + 1);
val[result_key_str] = result_value_str;
start = pos1 + 1;
pos1 = body.find("&", start);
if (pos1 == std::string::npos) {
return process_bad_request();
}
pos2 = body.find("=", start);
if (pos2 == std::string::npos || pos2 > pos1) {
return process_bad_request();
}
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1, pos1 - pos2 - 1);
val[result_key_str] = result_value_str;
start = pos1 + 1;
pos2 = body.find("=", start);
if (pos2 == std::string::npos) {
return process_bad_request();
}
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1);
val[result_key_str] = result_value_str;
int calc_result;
//...
}哈希表初始化完成后,计算逻辑由专门的process_calculation 函数处理,该函数即为虚拟路径映射的目标函数。其内容为:先从哈希表中获取值,调用stoi 将操作数转换为整型。由于键或值可能包含特殊字符(如空格会被编码为"+" ,"/" 等符号也会进行 URL 编码,即转换为% 后跟两个十六进制数字),因此操作符需要先解码为原始字符。解码完成后,进入switch-case 语句执行计算,并将结果存入输出型参数。
cpp
bool process_calculation(std::unordered_map<std::string, std::string>& val, int& result)
{
int a = std::stoi(val["a"]);
int b = std::stoi(val["b"]);
std::string op = val["op"];
if (op == "+" || op == "%2B" || op == "%2b") {
op = "+";
} else if (op == "-" || op == "%2D" || op == "%2d") {
op = "-";
} else if (op == "*" || op == "%2A" || op == "%2a") {
op = "*";
} else if (op == "/" || op == "%2F" || op == "%2f") {
op = "/";
} else {
lg.logmessage(Fatal, "unsupported operator: %s", op.c_str());
return false;
}
switch (op[0]) {
case '+':
result = a + b;
break;
case '-':
result = a - b;
break;
case '*':
result = a * b;
break;
case '/':
if (b == 0) {
lg.logmessage(warning, "division by zero");
return false;
}
result = a / b;
}
return true;
}若计算成功,函数返回true;否则返回false ,并调用process_bad_request 返回错误响应。计算成功后,构建状态码为 200 的响应报文,并将硬编码的成功页面 HTML 文本作为响应正文返回。
由于本 Web 服务器仅提供计算服务,若 URL 不是/calc ,则视为无效路径,同样调用process_cad_request 并返回。
cpp
std::string Http_Post_Handler(Http_Request& hr) {
std::string res;
std::unordered_map<std::string, std::string> val;
size_t start = 0;
if (hr.url == "/calc") {
std::string body = hr.text;
size_t pos1 = body.find("&");
if (pos1 == std::string::npos) {
return process_bad_request();
}
std::string expression = body.substr(start, pos1);
size_t pos2 = expression.find("=");
if (pos2 == std::string::npos) {
return process_bad_request();
}
std::string result_key_str = expression.substr(start, pos2);
std::string result_value_str = expression.substr(pos2 + 1);
val[result_key_str] = result_value_str;
start = pos1 + 1;
pos1 = body.find("&", start);
if (pos1 == std::string::npos) {
return process_bad_request();
}
pos2 = body.find("=", start);
if (pos2 == std::string::npos || pos2 > pos1) {
return process_bad_request();
}
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1, pos1 - pos2 - 1);
val[result_key_str] = result_value_str;
start = pos1 + 1;
pos2 = body.find("=", start);
if (pos2 == std::string::npos) {
return process_bad_request();
}
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1);
val[result_key_str] = result_value_str;
int calc_result;
if (process_calculation(val, calc_result) == false) {
return process_bad_request();
}
std::string headler_line = "HTTP/1.0 200 OK\r\n";
std::string header = "Connection: close\r\n";
header += "Content-Type: text/html\r\\n";
std::string content = "<html><head><meta charset='UTF-8'></head><body>";
content += "<h2>计算结果展示</h2>";
content += "<p style='font-size:24px;'>结果为: " + std::to_string(calc_result) + "</p>";
content += "<a href='/'>返回首页</a>";
content += "</body></html>";
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
header += "\r\n";
res = headler_line + header + content;
return res;
} else {
lg.logmessage(Fatal, "unsupported post url: %s", hr.url.c_str());
return process_bad_request();
}
}至此,两个核心请求处理函数已介绍完毕。接下来只需将这两个函数返回的响应正文通过send
接口发送出去,并检查其返回值。若返回值小于 0,则记录错误日志、关闭套接字并退出;若发送成功,则关闭套接字并正常退出。
httpserver.cpp:
最后一部分是服务器主函数的实现。该服务器运行于Linux环境,通常通过命令行启动进程,配置信息可通过命令行参数传递。由于IP地址已默认设为"0.0.0.0" ,此处仅需指定端口号。命令行本质上是一个字符串,由bash进程接收,解析出命令名和参数,保存到字符串数组中,并传递给目标进程。
因此,主函数首先检查参数个数:包括命令名及其参数,应为2。若非2,则打印错误信息并退出程序。接着从字符串数组中获取端口号参数,转换为整型,随后创建Httpserver 对象,依次调用其init 和start 函数。
cpp
#include"Httpserver.hpp"
#include"log.hpp"
#include<string>
extern log lg;
void usage(std::string progmaname)
{
std::cout << "usage wrong: " << progmaname << " <port>" << std::endl;
}
int main(int argc, char* argv[])
{
if (argc != 2)
{
usage(argv[0]);
exit(-1);
}
uint16_t port = std::stoi(argv[1]);
Httpserver hs(_default,port);
hs.init();
hs.start();
return 0;
}源码
Httpserver.hpp:
cpp
#pragma once
#include"Socket.hpp"
#include"log.hpp"
#include"Threadpool.h"
#include<arpa/inet.h>
#include<netinet/in.h>
#include<string>
#include<cstring>
#include<functional>
std::string _default = "0.0.0.0";
extern log lg;
class Httpserver
{
public:
Httpserver(std::string _ip = _default, uint16_t _port=80)
:ip(_ip)
, port(_port)
,islistening(false)
{
}
/**
* 初始化函数
* 用于创建并绑定监听套接字
*/
void init()
{
// 创建套接字
listen_socket.socket();
// 绑定IP地址和端口号
listen_socket.bind(ip, port);
}
/**
* 启动服务器监听功能
* 该函数用于启动服务器,开始接受客户端连接
*/
void start()
{
// 开始监听端口
listen_socket.listen();
// 检查服务器是否已经在监听状态
if (islistening)
{
// 如果已经在监听,记录警告日志并返回
lg.logmessage(warning,"server is already listening");
return;
}
// 设置监听状态为true
islistening = true;
// 获取线程池单例并启动线程池
threadpool& tp = threadpool::getinstance();
tp.start();
// 定义客户端地址结构体
struct sockaddr_in client;
// 设置地址结构体大小
socklen_t client_len = sizeof(client);
// 清零客户端地址结构体
memset(&client, 0, client_len);
while (islistening)
{
size_t client_fd=listen_socket.accept(&client,&client_len);
Task t(client_fd);
tp.push(t);
}
}
private:
uint16_t port;
std::string ip;
sock listen_socket;
bool islistening;
};Socket.hpp:
cpp
#include<arpa/inet.h>
#include<netinet/in.h>
#include<unistd.h>
#include<string>
#include<cstring>
#include<cstdlib>
#include"log.hpp"
extern log lg;
enum
{
Socket_Error = 1,
Bind_Error,
Listen_Error,
Accept_Error,
Connect_Error,
Usage_Error,
};
class sock
{
public:
sock()
:socketfd(-1)
{
}
~sock()
{
if (socketfd >= 0)
{
::close(socketfd);
}
}
/**
* 创建并配置socket
* 该函数用于创建一个TCP套接字,并设置地址和端口重用选项
*/
void socket()
{
// 使用系统调用socket创建TCP套接字
// AF_INET表示使用IPv4地址
// SOCK_STREAM表示使用TCP协议
// 0表示自动选择合适的协议
socketfd = ::socket(AF_INET, SOCK_STREAM, 0);
// 检查socket创建是否成功
if (socketfd < 0)
{
// 如果创建失败,记录错误日志并退出程序
lg.logmessage(Fatal, "socket error");
socketfd = -1;
exit(Socket_Error);
}
// 设置socket选项,允许地址和端口重用
// opt为1,表示启用SO_REUSEADDR和SO_REUSEPORT选项
// 这样可以避免在服务器重启时出现地址已被占用的错误
int opt = 1;
setsockopt(socketfd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
// 记录socket创建成功的日志
lg.logmessage(info, "socket successfully");
}
/**
* 绑定IP地址和端口号到套接字
* ip 要绑定的IP地址,字符串形式
* port 要绑定的端口号,16位无符号整数
*/
void bind(std::string ip, uint16_t port)
{
// 检查套接字是否有效
if (socketfd < 0) // 如果套接字描述符无效(小于0)
{
lg.logmessage(Fatal, "socket not created"); // 记录致命错误:套接字未创建
exit(Socket_Error); // 退出程序,套接字错误码
}
// 创建并清空服务器地址结构体
struct sockaddr_in server; // 定义IPv4地址结构体
memset(&server, 0, sizeof(server)); // 将server结构体清零,确保所有字段初始化为0
// 设置地址族为IPv4
server.sin_family = AF_INET; // 设置地址族为IPv4
// 将端口号从主机字节序转换为网络字节序
server.sin_port = htons(port); // 使用htons函数将端口号转换为网络字节序
// 处理IP地址
if (ip == "0.0.0.0") // 检查是否为通配地址
{
// 如果IP是0.0.0.0,绑定到所有可用的网络接口
server.sin_addr.s_addr = INADDR_ANY; // 绑定到所有可用的网络接口
}
else if (inet_pton(AF_INET, ip.c_str(), &server.sin_addr) <= 0) // 尝试将IP字符串转换为网络地址格式
{
// 尝试将IP字符串转换为网络地址格式,如果失败则记录错误
lg.logmessage(Fatal, "inet_pton fail"); // 记录致命错误:IP地址转换失败
::close(socketfd); // 关闭套接字
socketfd = -1; // 将套接字描述符设置为无效值
exit(Bind_Error); // 退出程序,绑定错误码
}
socklen_t serverlen = sizeof(server); // 获取服务器地址结构体的大小
int n = ::bind(socketfd, (struct sockaddr*)&server, serverlen); // 调用bind函数绑定地址
if (n < 0) // 检查bind函数是否执行成功
{
lg.logmessage(Fatal, "bind error"); // 记录致命错误:绑定失败
::close(socketfd); // 关闭套接字
socketfd = -1; // 将套接字描述符设置为无效值
exit(Bind_Error); // 退出程序,绑定错误码
}
lg.logmessage(info, "bind successfully"); // 记录信息:绑定成功
}
/**
* 监听函数,用于开始监听客户端连接请求
* 该函数首先检查socket是否已创建,然后调用listen函数开始监听
* 如果监听失败,会进行错误处理并退出程序
*/
void listen()
{
// 检查socket是否已创建,如果socketfd小于0表示socket未创建
if (socketfd < 0)
{
// 记录致命错误日志:socket未创建
lg.logmessage(Fatal, "socket not created");
// 退出程序,退出码为Socket_Error
exit(Socket_Error);
}
// 调用系统listen函数开始监听,第二个参数5表示最大连接队列长度
int n = ::listen(socketfd, 5);
// 检查listen函数是否成功执行
if (n < 0)
{
// 记录致命错误日志:监听失败
lg.logmessage(Fatal, "listen error");
// 关闭socket文件描述符
::close(socketfd);
// 将socketfd重置为-1,表示socket未创建
socketfd = -1;
// 退出程序,退出码为Listen_Error
exit(Listen_Error);
}
// 记录信息日志:监听成功
lg.logmessage(info, "listen successfully");
}
/** 接受一个客户端的连接请求*/
int accept(struct sockaddr_in* client, socklen_t* clientlen)
{
// 检查监听套接字 socketfd 是否有效
// 如果无效,说明服务器套接字未被正确初始化,这是一个致命错误
if (socketfd < 0)
{
// 记录一条致命级别的日志信息
lg.logmessage(Fatal, "socket not created");
// 终止程序,并返回一个特定的错误码 Socket_Error
exit(Socket_Error);
}
// 调用系统提供的 accept 函数,阻塞等待客户端连接
// socketfd: 监听套接字描述符
// (struct sockaddr*)client: 将客户端地址信息存入 client 指向的结构体
// clientlen: 传入 client 结构体的大小,并接收实际地址结构的大小
int client_fd = ::accept(socketfd, (struct sockaddr*)client, clientlen);
// 检查 accept 是否成功
if (client_fd < 0)
{
// 如果 accept 失败,记录一条致命错误日志
lg.logmessage(Fatal, "accept error");
// 返回 -1 表示接受连接失败
return -1;
}
// 如果 accept 成功,记录一条信息日志
lg.logmessage(info, "accept successfully");
// 返回新创建的、用于与该客户端通信的套接字描述符
return client_fd;
}
/**
* 连接到服务器的函数
*/
void connect(struct sockaddr_in* server, socklen_t serverlen)
{
// 检查socket是否已创建
if (socketfd < 0)
{
// 记录socket未创建的致命错误日志
lg.logmessage(Fatal, "socket not created");
// 退出程序,错误码为Socket_Error
exit(Socket_Error);
}
// 尝试连接到服务器
int n = ::connect(socketfd, (struct sockaddr*)server, serverlen);
// 检查连接是否成功
if (n < 0)
{
// 记录连接失败的致命错误日志
lg.logmessage(Fatal, "connect error");
// 关闭socket
::close(socketfd);
// 重置socket文件描述符
socketfd = -1;
// 退出程序,错误码为Connect_Error
exit(Connect_Error);
}
// 记录连接成功的信息日志
lg.logmessage(info, "connect successfully");
}
void close()
{
if (socketfd >= 0)
{
::close(socketfd);
socketfd = -1;
}
}
sock(const sock&) = delete;
sock& operator=(const sock&) = delete;
private:
int socketfd;
};Threadpool.h:
cpp
#pragma once
#include<pthread.h>
#include<semaphore.h>
#include<string>
#include<vector>
#include<sys/types.h>
#include"Task.hpp"
#define max_size 10
class threadpool
{
public:
static threadpool& getinstance()
{
static threadpool instance;
return instance;
}
/**
* 启动函数,用于创建多个线程执行任务
* 该函数会创建Max_size个线程,每个线程都执行handlertask函数
*/
void start()
{
// 循环创建Max_size个线程
for (int i = 0; i < Max_size; i++)
{
// 声明线程标识符tid
pthread_t tid;
// 创建线程,执行handlertask函数,并将当前对象指针作为参数传递
// 第一个参数:线程标识符指针
// 第二个参数:线程属性,设为NULL表示使用默认属性
// 第三个参数:线程处理函数,即handlertask
// 第四个参数:传递给线程处理函数的参数,这里传递当前对象的this指针
pthread_create(&tid, NULL, handlertask, this);
}
}
/**
* 从队列中弹出一个任务
*/
Task pop()
{ // 从队列中弹出任务的函数
sem_wait(&element); // 等待有元素可用,信号量element减1
pthread_mutex_lock(&mutex); // 加锁,确保线程安全
Task data = q[c_index]; // 获取当前索引处的任务
c_index = (c_index + 1) % Max_task_size; // 更新消费者索引,实现循环队列
pthread_mutex_unlock(&mutex); // 解锁
sem_post(&space); // 释放空间,信号量space加1
return data; // 返回获取的任务
}
// 向任务队列中添加一个任务
void push(const Task& T)
{
sem_wait(&space); // 等待空间信号量,表示队列中有空闲位置
q[p_index] = T; // 将任务T存入队列的当前位置
p_index = (p_index + 1) % Max_task_size; // 更新写入位置,使用模运算实现循环队列
sem_post(&element); // 发送元素信号量,表示队列中新增了一个元素
}
~threadpool()
{
pthread_mutex_destroy(&mutex);
sem_destroy(&element);
sem_destroy(&space);
}
threadpool(const threadpool&) = delete;
threadpool& operator=(const threadpool&) = delete;
private:
/**
* 线程池的构造函数,用于初始化线程池
*/
threadpool(int max_num = max_size, int max_task_size = max_size)
:Max_size(max_num) // 初始化最大线程数
, c_index(0) // 初始化消费者索引,用于任务队列的环形缓冲区
, p_index(0) // 初始化生产者索引,用于任务队列的环形缓冲区
, Max_task_size(max_task_size) // 初始化任务队列的最大容量
{
q.resize(Max_task_size); // 调整任务队列的大小为最大容量
// 初始化互斥锁,用于保护共享资源的访问
pthread_mutex_init(&mutex, NULL);
// 初始化信号量element,表示队列中的任务数量,初始为0
sem_init(&element, 0, 0);
// 初始化信号量space,表示队列中的可用空间,初始为Max_task_size
sem_init(&space, 0, Max_task_size);
}
/**
* 线程池中工作线程的任务处理函数
*/
static void* handlertask(void* args)
{
// 将传入的参数转换为线程池对象指针
threadpool* tp = (threadpool*)args;
// 无限循环,持续从任务队列中获取并执行任务
while (1)
{
// 从线程池的任务队列中弹出一个任务
Task task = tp->pop();
// 执行获取到的任务
task.run();
}
// 理论上不会执行到这里,因为while(1)是无限循环
return NULL;
}
std::vector<Task> q;
int Max_size;
pthread_mutex_t mutex;
int Max_task_size;
int c_index;
int p_index;
sem_t element;
sem_t space;
};Task.hpp:
cpp
#pragma once
#include<functional>
#include<string>
#include<sys/types.h>
#include<unistd.h>
#include<fstream>
#include<unordered_map>
#include"protocol.hpp"
#include"log.hpp"
#define BUFFER_SIZE 1024
extern log lg;
std::string path="./wwwroot";
/**
* 从指定的套接字接收完整的HTTP请求,并将其解析到Http_Request对象中
*
* 如果成功接收并解析了HTTP请求头(无论是否有正文),返回 true。
* 如果在接收数据时发生错误(如recv失败),返回 false。
*
* 此函数处理了两种情况:
* 1. 没有正文的请求(如GET请求)。
* 2. 有正文的请求(如POST请求),它会根据`Content-Length`头确保接收完整的正文。
* 函数会阻塞,直到接收到完整的HTTP头(以"\r\n\r\n"为标志)和完整的正文(如果存在)。
*/
bool Get_HttpRequest(size_t socketfd, Http_Request& hr)
{
// 用于存储从套接字接收到的所有原始HTTP请求数据
std::string data;
// 临时缓冲区,用于每次recv调用
char buffer[BUFFER_SIZE];
// --- 第一阶段:循环接收数据,直到收到完整的HTTP请求头 ---
// HTTP请求头以 "\r\n\r\n" 结尾,这是一个明确的分界符
while (true)
{
// 从套接字读取数据,最多读取 BUFFER_SIZE-1 字节,为 '\0' 预留一个位置
ssize_t read_bytes = recv(socketfd, buffer, BUFFER_SIZE - 1, 0);
// recv 的返回值 <= 0 表示错误或连接被对端关闭
if (read_bytes <= 0)
{
// 记录一条致命错误日志
lg.logmessage(Fatal, "recv error");
// 接收失败,返回 false
return false;
}
// 将本次读取到的数据追加到总数据字符串 data 中
data.append(buffer, read_bytes);
// 检查 data 中是否已包含完整的HTTP请求头结束符
if (data.find("\r\n\r\n") != std::string::npos)
{
// 找到了,说明请求头已完整,跳出循环
break;
}
}
// 从完整的数据中提取出HTTP请求头部分(包括结束符"\r\n\r\n")
std::string head = data.substr(0, data.find("\r\n\r\n") + 4);
// --- 第二阶段:检查是否有请求正文,并处理 ---
// 在请求头中查找 "Content-Length:" 字段,这是判断是否有正文以及正文长度的关键
size_t pos = data.find("Content-Length:");
if (pos != std::string::npos)
{
// 找到了 Content-Length 字段,说明这是一个带有正文的请求(通常是POST)
// 1. 解析 Content-Length 的值
// 找到该字段所在行的行尾
ssize_t endpos = head.find("\r\n", pos);
// 提取 "Content-Length:" 后面的数字字符串
std::string content_length_str = head.substr(pos + 15, endpos - pos - 15); // "Content-Length:" 长度为15
// 将字符串转换为整数,得到正文的期望长度
size_t content_length = std::stoi(content_length_str);
// 2. 检查当前已接收的数据中是否包含了完整的正文
// 计算当前已接收的正文部分的长度
size_t remaining = data.size() - head.size();
if (remaining < content_length)
{
// 情况A:正文不完整,需要继续从套接字读取剩余的正文数据
// 提取已接收的部分正文
std::string body = data.substr(data.find("\r\n\r\n") + 4, remaining);
// 计算还需要读取的字节数
int to_read = content_length - remaining;
char body_buffer[BUFFER_SIZE];
// 循环读取,直到读完所有剩余的正文数据
while (to_read > 0)
{
// 计算本次最多能读取多少字节(防止读取超过需求)
ssize_t bytes_to_recv = std::min(BUFFER_SIZE - 1, to_read);
ssize_t read_bytes = recv(socketfd, body_buffer, bytes_to_recv, 0);
if (read_bytes <= 0)
{
lg.logmessage(Fatal, "recv error");
return false;
}
// 将新读取的数据追加到正文字符串中
body.append(body_buffer, read_bytes);
// 更新还需要读取的字节数
to_read -= read_bytes;
}
// 将完整的正文存入 hr 对象
hr.text = body;
}
else
{
// 情况B:正文已经完整地包含在第一次接收的数据中
// 直接从 data 中提取指定长度的正文
hr.text = data.substr(data.find("\r\n\r\n") + 4, content_length);
}
}
// 如果没有找到 "Content-Length",则认为请求没有正文,hr.text 保持为空
// --- 第三阶段:解析请求头 ---
// 调用 Http_Request 对象的 Deserialization 方法来解析请求头字符串
bool res = hr.Deserialization(head);
// 调试打印:输出解析后的 Http_Request 对象的内容
hr.debugprint();
// 返回请求头的解析结果
return res;
}
/**
* 从指定路径读取文件内容
*
* 返回文件内容字符串,如果文件打开失败则返回空字符串
*/
std::string read_file(std::string file_path)
{
// 以二进制模式打开文件
std::ifstream file(file_path,std::ios::binary);
// 检查文件是否成功打开
if(!file.is_open())
{
// 记录文件未找到的日志
lg.logmessage(info,"file not found:%s",file_path.c_str());
return "";
}
// 获取文件开始位置
std::streampos start=file.tellg();
// 移动文件指针到末尾
file.seekg(0,std::ios::end);
// 获取文件结束位置
std::streampos end=file.tellg();
// 计算文件大小
size_t file_size=end-start;
// 创建并调整字符串大小以容纳文件内容
std::string content;
content.resize(file_size);
// 将文件指针移回开始位置
file.seekg(0,std::ios::beg);
// 读取文件内容到字符串
file.read(&content[0],file_size);
// 关闭文件
file.close();
// 返回读取的文件内容
return content;
}
std::string Http_Get_Handler(Http_Request& hr);
/**
* 处理错误的HTTP请求,返回400 Bad Request响应
*
* std::string 包含HTTP响应头的完整HTTP响应消息
*/
std::string process_bad_request()
{
// 记录错误日志,级别为Fatal
lg.logmessage(Fatal,"bad request body");
// 构建HTTP状态行
std::string headler_line="HTTP/1.0 400 Bad Request\r\n";
// 构建HTTP头部字段
std::string header="Connection: close\r\n";
// 设置响应内容
std::string content="Bad Request";
// 添加内容长度和内容类型头部
header+="Content-Length: "+std::to_string(content.size())+"\r\n";
header+="Content-Type: text/plain\r\n";
// 添加空行表示头部结束
header+="\r\n";
// 返回完整的HTTP响应
return headler_line+header+content;
}
/**
* 根据输入的操作数和运算符执行基本的算术计算
*
* 如果计算成功执行,返回 true。
* 如果遇到不支持的运算符或除零错误,返回 false。
*
* 此函数会处理运算符的URL编码形式,例如 "%2B" 会被解码为 "+"。
* 它会检查除零错误,但不会检查其他潜在的整数溢出问题。
*/
bool process_calculation(std::unordered_map<std::string, std::string>& val, int& result)
{
// 从映射中提取操作数 "a" 和 "b",并将它们从字符串转换为整数
int a = std::stoi(val["a"]);
int b = std::stoi(val["b"]);
// 从映射中提取运算符 "op"
std::string op = val["op"];
// --- 运算符规范化 ---
// 将URL编码的运算符或不同大小写的表示统一为标准的单字符运算符
if (op == "+" || op == "%2B" || op == "%2b") // 检查加号
{
op = "+";
}
else if (op == "-" || op == "%2D" || op == "%2d") // 检查减号
{
op = "-";
}
else if (op == "*" || op == "%2A" || op == "%2a") // 检查乘号
{
op = "*";
}
else if (op == "/" || op == "%2F" || op == "%2f") // 检查除号
{
op = "/";
}
else
{
// 如果运算符不是以上任何一种,则记录一条致命错误日志并返回失败
lg.logmessage(Fatal, "unsupported operator:%s", op.c_str());
return false;
}
// --- 执行计算 ---
// 使用 switch 语句根据规范化后的运算符执行相应的计算
switch (op[0]) // 使用 op[0] 进行比较,因为此时 op 已是单字符
{
case '+': // 加法
result = a + b;
break;
case '-': // 减法
result = a - b;
break;
case '*': // 乘法
result = a * b;
break;
case '/': // 除法
// 安全检查:防止除以零
if (b == 0)
{
// 如果除数为0,记录一条警告日志并返回失败
lg.logmessage(warning, "division by zero");
return false;
}
// 执行整数除法
result = a / b;
break; // 为 switch 语句添加了缺失的 break
}
// 所有操作成功完成,返回 true
return true;
}
/**
* 处理HTTP POST请求,目前主要支持一个计算器功能
*
* 此函数专门处理发往 `/calc` URL的POST请求。它期望请求体中包含三个URL编码的
* 键值对(例如 "a=10&op=+&b=20"),分别代表第一个操作数、运算符和第二个操作数。
* 它会解析这些参数,执行计算,并将结果嵌入到一个HTML页面中返回给客户端。
* 对于任何其他URL或不合法的请求格式,它会返回一个400 Bad Request错误。
*
* 此函数依赖于 `process_calculation` 函数来执行实际的数学运算,
* 和 `process_bad_request` 函数来生成错误响应。
* 请求体的解析逻辑较为硬编码,期望固定的三个键值对格式。
*/
std::string Http_Post_Handler(Http_Request& hr)
{
// --- 1. 初始化 ---
std::string res; // 存储最终要返回的HTTP响应字符串
std::unordered_map<std::string, std::string> val; // 用于存储从请求体解析出的键值对
size_t start = 0; // 辅助变量,用于在解析请求体时标记当前处理的起始位置
// --- 2. 检查并处理特定的POST URL ---
// 检查请求的URL路径是否为 "/calc"
if (hr.url == "/calc")
{
// --- 2a. 获取并解析请求体 ---
// 从 Http_Request 对象中获取POST请求的原始请求体
std::string body = hr.text;
// 手动解析请求体,期望格式为 "key1=value1&key2=value2&key3=value3"
// 这是一个硬编码的解析过程,假设有三个键值对
// --- 解析第一个键值对 ---
size_t pos1 = body.find("&"); // 查找第一个键值对的结束符
if (pos1 == std::string::npos)
{
// 如果没有找到,说明格式错误,返回400 Bad Request
return process_bad_request();
}
std::string expression = body.substr(start, pos1); // 提取第一个键值对字符串
size_t pos2 = expression.find("="); // 在键值对中查找 "="
if (pos2 == std::string::npos)
{
// 没找到 "=",格式错误
return process_bad_request();
}
// 提取键和值,并存入 map
std::string result_key_str = expression.substr(start, pos2);
std::string result_value_str = expression.substr(pos2 + 1);
val[result_key_str] = result_value_str;
// --- 解析第二个键值对 ---
start = pos1 + 1; // 更新起始位置到第二个键值对的开头
pos1 = body.find("&", start); // 查找第二个键值对的结束符
if (pos1 == std::string::npos)
{
return process_bad_request();
}
pos2 = body.find("=", start); // 查找 "="
// 检查 "=" 是否存在且在正确的范围内(在当前 "&" 之前)
if (pos2 == std::string::npos || pos2 > pos1)
{
return process_bad_request();
}
// 提取键和值
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1, pos1 - pos2 - 1);
val[result_key_str] = result_value_str;
// --- 解析第三个键值对 ---
start = pos1 + 1; // 更新起始位置
pos2 = body.find("=", start); // 查找 "="
if (pos2 == std::string::npos)
{
return process_bad_request();
}
// 提取键和值,直到字符串末尾
result_key_str = body.substr(start, pos2 - start);
result_value_str = body.substr(pos2 + 1);
val[result_key_str] = result_value_str;
// --- 2b. 执行计算 ---
int calc_result;
// 调用辅助函数进行计算,传入解析出的键值对 map
if (process_calculation(val, calc_result) == false)
{
// 如果计算失败(例如不支持的运算符或除零),返回错误响应
return process_bad_request();
}
// --- 2c. 构建成功的HTTP响应 ---
// 构建HTTP状态行
std::string headler_line = "HTTP/1.0 200 OK\r\n";
// 构建HTTP响应头
std::string header = "Connection: close\r\n";
header += "Content-Type: text/html\r\n";
// 动态生成HTML响应体,用于展示计算结果
std::string content = "<html><head><meta charset='UTF-8'></head><body>";
content += "<h2>计算结果展示</h2>";
content += "<p style='font-size:24px;'>结果为: " + std::to_string(calc_result) + "</p>";
content += "<a href='/'>返回首页</a>";
content += "</body></html>";
// 完成响应头,添加内容长度和结束符
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
header += "\r\n"; // 空行,标志HTTP头部结束
// 拼接完整的HTTP响应
res = headler_line + header + content;
return res;
}
else
{
// --- 3. 处理不支持的POST URL ---
// 如果URL不是 "/calc",记录一条致命错误日志
lg.logmessage(Fatal, "unsupported post url:%s", hr.url.c_str());
// 并返回一个通用的错误响应
return process_bad_request();
}
}
class Task
{
public:
Task()
:socketfd(-1)
{
}
Task(int _socketfd)
:socketfd(_socketfd)
{
}
/**
* 处理文件后缀名,返回对应的MIME类型
* 返回对应的MIME类型字符串,如果找不到则返回默认的html类型
*/
static std::string suffix_handler(std::string suffix)
{
// 在map中查找对应的后缀名
auto pos=map.find(suffix);
// 如果找不到对应的后缀名
if (pos == map.end())
{
// 返回默认的html类型
return map[".html"];
}
// 返回找到的对应MIME类型
return map[suffix];
}
/**
* 运行HTTP请求处理函数
* 该函数负责接收HTTP请求、根据请求类型(GET/POST)调用相应的处理函数,
* 并将处理结果发送回客户端,最后关闭socket连接
*/
void run()
{
// 创建HTTP请求对象
Http_Request hr;
// 获取HTTP请求
bool get_result = Get_HttpRequest(socketfd,hr);
// 如果获取请求失败,记录错误日志并关闭socket连接
if (get_result == false)
{
lg.logmessage(Fatal,"get http request error");
close(socketfd);
return;
}
std::string res; // 用于存储HTTP响应结果
// 根据HTTP方法类型调用相应的处理函数
if (hr.method == "GET")
{
res=Http_Get_Handler(hr); // 处理GET请求
}
else if (hr.method == "POST")
{
res=Http_Post_Handler(hr); // 处理POST请求
}
else
{
// 如果是不支持的HTTP方法,记录警告日志并关闭socket连接
lg.logmessage(warning,"unsupported method:%s",hr.method.c_str());
close(socketfd);
return;
}
// 发送HTTP响应
int send_bytes=send(socketfd,res.c_str(),res.size(),0);
// 如果发送失败,记录错误日志并关闭socket连接
if(send_bytes<0)
{
lg.logmessage(Fatal,"send error");
close(socketfd);
return;
}
// 正常处理完成后关闭socket连接
close(socketfd);
}
private:
int socketfd;
static std::unordered_map<std::string, std::string> map;
};
std::unordered_map<std::string, std::string> Task::map={
{".html","text/html"},
{".css","text/css"},
{".png","image/png"},
{".jpg","image/jpeg"}
};
/**
* 处理HTTP GET请求并生成相应的HTTP响应
*
* 该函数根据请求的URL路径,从服务器文件系统中读取对应的静态文件,
* 构建并返回一个完整的HTTP响应字符串。它能处理首页请求,也能处理其他
* 类型的静态资源(如CSS、JavaScript、图片等),并自动设置正确的
* Content-Type。如果请求的文件不存在,它会返回一个404 Not Found错误页面。
*
*/
std::string Http_Get_Handler(Http_Request& hr)
{
// --- 1. 初始化变量 ---
// 定义用于构建响应的关键变量
std::string file_path; // 存储请求文件的完整服务器路径
std::string content_type; // 存储文件的MIME类型(如 "text/html")
std::string res; // 存储最终构建好的完整HTTP响应字符串
// --- 2. 确定文件路径和内容类型 ---
// 检查请求的URL是否为根目录 "/" 或首页 "/index.html"
if (hr.url == "/" || hr.url == "/index.html")
{
// 如果是首页请求,则拼接出首页的完整路径
file_path = path + "/index.html"; // 假设 `path` 是服务器根目录
// 首页的内容类型明确为HTML
content_type = "text/html";
}
else
{
// 如果是其他文件请求,直接将URL拼接到根目录后
file_path = path + hr.url;
// --- 2a. 根据文件后缀确定MIME类型 ---
// 查找文件路径中最后一个'.'的位置,以提取文件扩展名
ssize_t pos = file_path.rfind(".");
if (pos == std::string::npos)
{
// 如果找不到后缀(如请求一个没有扩展名的文件),则默认按HTML处理
content_type = "text/html";
}
else
{
// 提取文件后缀(包括点,如 ".html")
std::string suffix = file_path.substr(pos);
// 调用辅助函数根据后缀获取正确的MIME类型
content_type = Task::suffix_handler(suffix);
}
}
// --- 3. 尝试读取请求的文件 ---
// 调用 `read_file` 函数读取文件内容到 `body` 字符串中
std::string body = read_file(file_path);
// --- 4. 构建HTTP响应 ---
// 初始化状态行和头部字段
std::string headler_line; // HTTP响应状态行(如 "HTTP/1.0 200 OK")
std::string header; // HTTP响应头部字段
// 检查文件是否成功读取(`body` 是否为空)
if (body.empty())
{
// --- 4a. 文件不存在,构建404 Not Found响应 ---
// 设置404状态行
headler_line = "HTTP/1.0 404 Not Found\r\n";
// 添加连接关闭头部,告知客户端此响应后连接将关闭
header += "Connection: close\r\n";
// 读取自定义的404错误页面内容
std::string content = read_file(path + "/404.html");
// 添加Content-Length头部,指明响应体大小
header += "Content-Length: " + std::to_string(content.size()) + "\r\n";
// 添加Content-Type头部,指明响应体是HTML
header += "Content-Type: text/html\r\n";
// 头部结束标志
header += "\r\n";
// 拼接完整的404响应:状态行 + 头部 + 错误页面内容
res = headler_line + header + content;
}
else
{
// --- 4b. 文件存在,构建200 OK响应 ---
// 设置200成功状态行
headler_line = "HTTP/1.0 200 OK\r\n";
// 添加Content-Length头部
header += "Content-Length: " + std::to_string(body.size()) + "\r\n";
// 添加Connection头部
header += "Connection: close\r\n";
// 添加Content-Type头部,使用之前确定的MIME类型
header += "Content-Type: " + content_type + "\r\n";
// 头部结束标志
header += "\r\n";
// 拼接完整的成功响应:状态行 + 头部 + 文件内容
res = headler_line + header + body;
}
// --- 5. 返回构建好的HTTP响应 ---
return res;
}protocol.hpp:
cpp
#pragma once
#include"log.hpp"
#include<iostream>
#include<vector>
#include<string>
#include<sstream>
#include<unordered_map>
extern log lg;
class Http_Request
{
public:
/**
* 反序列化HTTP请求头
* 反序列化成功返回true,失败返回false
*/
bool Deserialization(std::string& head)
{
// 记录当前处理的起始位置
size_t start=0;
// 存储解析出的HTTP头信息
std::vector<std::string>_header;
// 循环解析HTTP头,直到遇到空行
while(true)
{
std::string line; // 存储当前行
// 查找行结束符的位置
size_t end=head.find("\r\n",start);
// 如果找不到行结束符,说明格式错误
if(end==std::string::npos)
{
return false;
}
// 提取当前行内容
line=head.substr(start,end-start);
// 如果遇到空行,结束头信息解析
if(line.empty())
{
break;
}
// 更新起始位置到下一行
start=end+2;
// 将解析出的行加入头信息列表
_header.push_back(line);
}
// 如果头信息为空,返回错误
if(_header.size()<1)
{
return false;
}
// 解析具体的头信息字段
for(size_t i=1;i<_header.size();i++)
{
std::string line=_header[i]; // 当前头信息行
// 查找键值分隔符的位置
ssize_t pos=line.find(":");
// 如果找不到分隔符,格式错误
if(pos==std::string::npos)
{
return false;
}
// 提取键
std::string key=line.substr(0,pos);
// 计算值的起始位置(跳过分隔符后的空格)
size_t val_start=pos+1;
while(val_start<line.size() && std::isspace(line[val_start]))
{
val_start++;
}
// 提取值并存储到headers映射中
std::string value=line.substr(val_start);
headers[key]=value;
}
// 解析请求行(第一行)
std::string first_line=_header[0];
std::stringstream ss(first_line);
// 提取方法、URL和HTTP版本
ss>>method>>url>>http_version;
return true;
}
/** 调试打印函数,用于输出HTTP请求的详细信息
* 该函数会打印请求方法、URL、HTTP版本、头部字段和请求体内容
*/
void debugprint()
{
// 输出一个空行,用于分隔不同部分的输出
std::cout<<std::endl;
// 打印HTTP请求的方法、URL和HTTP版本
std::cout<<method<<" "<<url<<" "<<http_version<<std::endl;
// 遍历并打印所有的HTTP头部字段
for(auto it=headers.begin();it!=headers.end();it++)
{
// 打印每个头部字段的键值对
std::cout<<it->first<<": "<<it->second<<std::endl;
}
// 输出一个空行,用于分隔头部和请求体
std::cout<<std::endl;
// 打印HTTP请求的文本内容(请求体)
std::cout<<text<<std::endl;
// 输出一个空行,用于结束本次调试输出
std::cout<<std::endl;
}
public:
std::unordered_map<std::string,std::string> headers;
std::string text;
std::string method;
std::string url;
std::string http_version;
};httpserver.cpp:
cpp
#include"Httpserver.hpp"
#include"log.hpp"
#include<string>
extern log lg;
void usage(std::string progmaname)
{
std::cout << "usage wrong: " << progmaname << " <port>" << std::endl;
}
/**
程序的主入口点,负责启动HTTP服务器
*/
int main(int argc, char* argv[])
{
// --- 1. 检查命令行参数 ---
// 检查用户是否提供了正确数量的参数(程序名 + 端口号)
if (argc != 2)
{
// 如果参数数量不正确,调用 usage 函数打印正确的使用方法
// argv[0] 是程序名,这样用户就知道他们输错了什么
usage(argv[0]);
// 以错误状态码 -1 终止程序
exit(-1);
}
// --- 2. 解析端口号 ---
// 将用户提供的端口号(字符串)转换为整数
// std::stoi 可能会抛出 std::invalid_argument 或 std::out_of_range 异常
// 在这个简单的实现中,我们没有捕获这些异常,程序会因此崩溃
uint16_t port = std::stoi(argv[1]);
// --- 3. 创建并初始化HTTP服务器 ---
// 创建一个名为 `hs` 的 HTTPserver 对象
// `_default` 是一个预设的配置或回调函数(具体定义未在代码中显示)
// `port` 是上一步解析出的端口号
Httpserver hs(_default, port);
// 调用 `init` 方法对服务器进行初始化
// 这可能包括创建套接字、绑定地址、开始监听等操作
hs.init();
// --- 4. 启动服务器 ---
// 调用 `start` 方法启动服务器
// 这个方法通常会进入一个无限循环(事件循环),接受客户端连接并处理请求
// 程序会阻塞在这里,直到服务器被手动终止(例如通过Ctrl+C)
hs.start();
// --- 5. 程序退出 ---
// 如果 `start` 方法返回(通常意味着服务器已停止),程序将执行到这里
// 返回 0 表示程序正常结束
return 0;
}log.hpp:
cpp
#pragma once
#include<iostream>
#include<string>
#include<time.h>
#include<stdarg.h>
#include<fcntl.h>
#define SIZE 1024
#define screen 0
#define File 1
#define ClassFile 2
enum
{
info,
debug,
warning,
Fatal,
};
class log
{
private:
std::string memssage;
int method;
public:
log(int _method = File)
:method(_method)
{
}
void logmessage(int leval, char* format, ...)
{
char* _leval;
switch (leval)
{
case info:
_leval = "info";
break;
case debug:
_leval = "debug";
break;
case warning:
_leval = "warning";
break;
case Fatal:
_leval = "Fatal";
break;
}
char timebuffer[SIZE];
time_t t = time(NULL);
struct tm* localTime = localtime(&t);
snprintf(timebuffer, SIZE, "[%d-%d-%d-%d:%d]", localTime->tm_year + 1900, localTime->tm_mon + 1, localTime->tm_mday, localTime->tm_hour, localTime->tm_min);
char rightbuffer[SIZE];
va_list arg;
va_start(arg, format);
vsnprintf(rightbuffer, SIZE, format, arg);
char finalbuffer[2 * SIZE];
int len=snprintf(finalbuffer, sizeof(finalbuffer), "[%s]%s:%s\n", _leval, timebuffer, rightbuffer);
int fd;
switch (method)
{
case screen:
std::cout << finalbuffer;
break;
case File:
fd = open("log.txt", O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd >= 0)
{
write(fd, finalbuffer, len);
close(fd);
}
break;
case ClassFile:
switch (leval)
{
case info:
fd = open("log/info.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case debug:
fd = open("log/debug.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case warning:
fd = open("log/Warning.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
write(fd, finalbuffer, sizeof(finalbuffer));
break;
case Fatal:
fd = open("log/Fat.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
break;
}
if (fd > 0)
{
write(fd, finalbuffer, sizeof(finalbuffer));
close(fd);
}
}
}
};
log lg;运行截图:
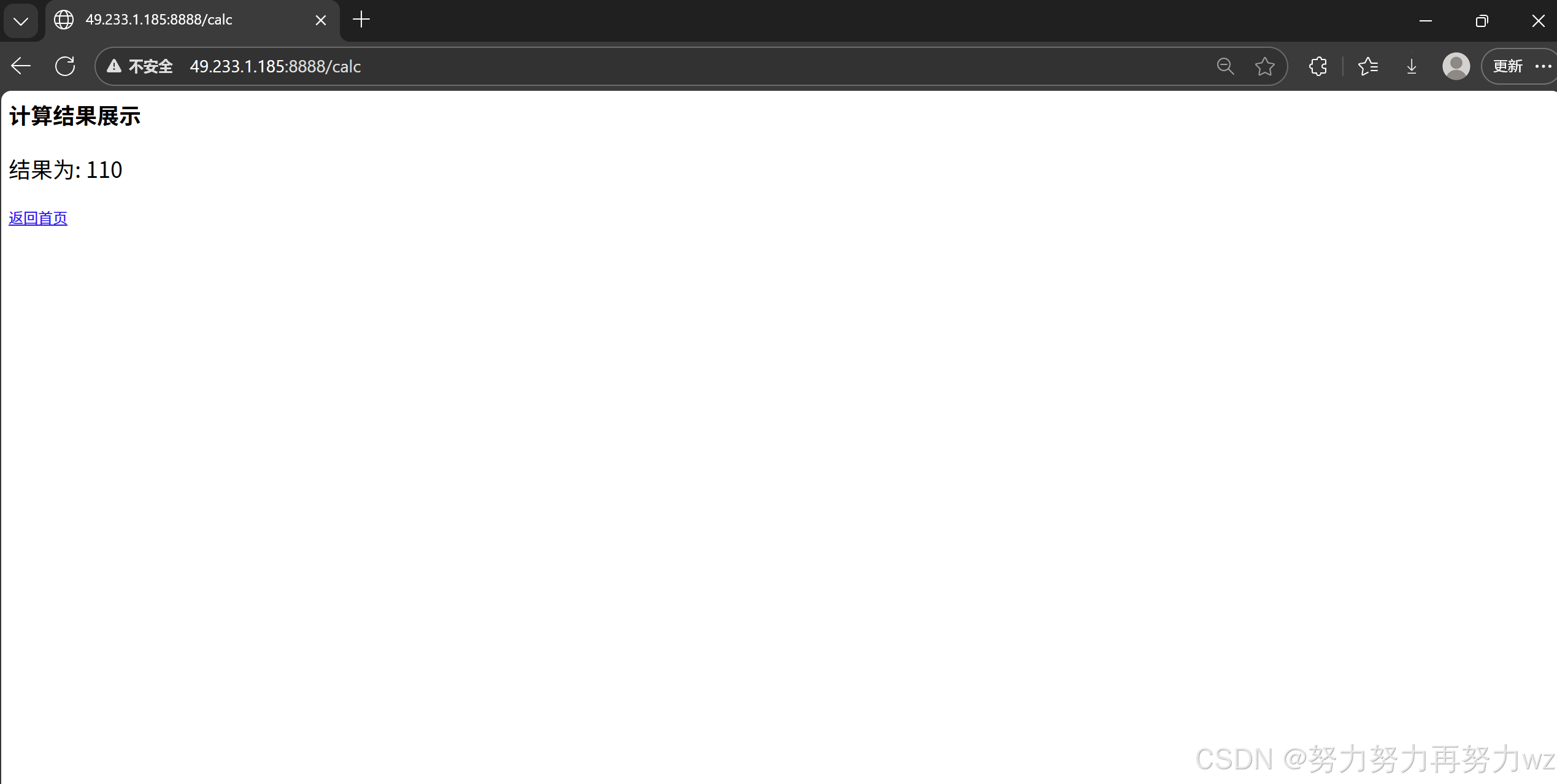
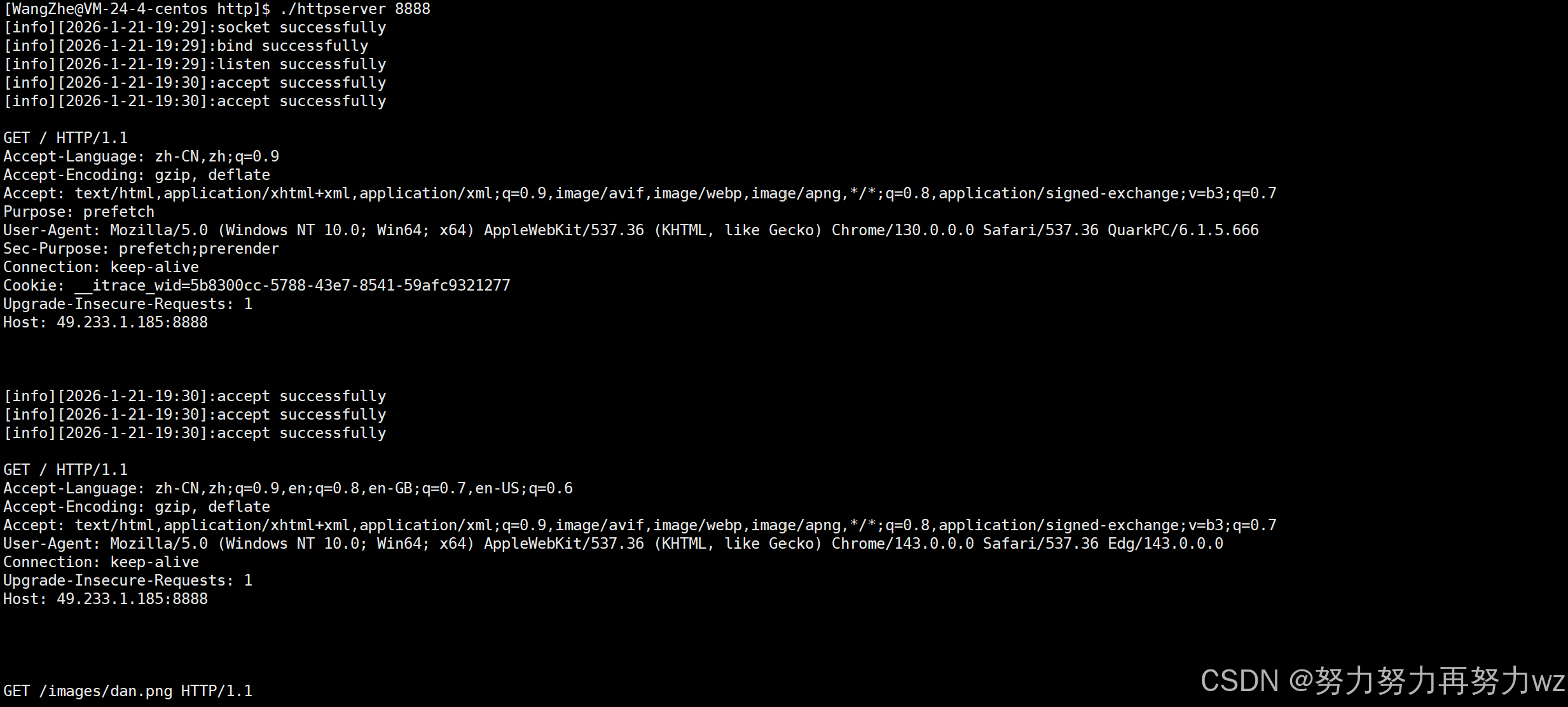
结语
那么这就是本篇文章的全部内容,带你全面认识以及掌握json以及http,并且实现web计算器服务器,那么下一期博客我会更新https,我会持续更新,希望你能够多多关注,如果本文有帮助到你的话,还请三连加关注,你的支持就是我创作的最大动力!
