Flink基础入门
本文旨在通过几个小案例来帮助同学们理解Flink的批处理和流处理的简单使用;
项目创建
- jdk1.8.0_231
- Apache Maven 3.6.3
相关依赖(来自尚硅谷)
xml
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>有界数据wordCount批处理
思路
- 环境准备
- 指定的文件中读取数据
- 对读取的数据扁平化处理
- 按照单词进行分组
- 聚合计算
- 打印输出
项目准备
在项目目录下创建input目录在目录下创建word.txt文件,内容如下
Hello world
Hello bigdata
bigdata good
good KangKing文件目录结构:
环境准备
java
//环境准备,获取当前环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();文件读取与扁平化处理
java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//指定的文件中读取数据
DataSource<String> df = env.readTextFile("D:\\Filnk\\code\\Flink-start\\input\\word.txt");
//对读取的数据扁平化处理
FlatMapOperator<String, Tuple2<String, Long>> FlatMapDS = df.flatMap(
//定义一个 算子句柄 flatMapDS,它表示"输入是String,输出是 (String, Long) 二元组"的流转换。
new FlatMapFunction<String, Tuple2<String, Long>>() {
//FlatMapFunction<IN, OUT> 是 Flink 提供的函数式接口。
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] wordArr = s.split(" ");
for (String word : wordArr) {
//遍历数组,每遇到一个单词就调用 collector.collect(...) 向下游发送一条记录 (word, 1L)
collector.collect(Tuple2.of(word, 1L));
}
}
}
);单词分组与聚合计算
java
//按照单词进行分组
UnsortedGrouping<Tuple2<String, Long>> groupByDS = FlatMapDS.groupBy(0);//按照元组的第一个元素分组
//将元组中的第二个元素聚合
AggregateOperator<Tuple2<String, Long>> sumDS = groupByDS.sum(1);输出
java
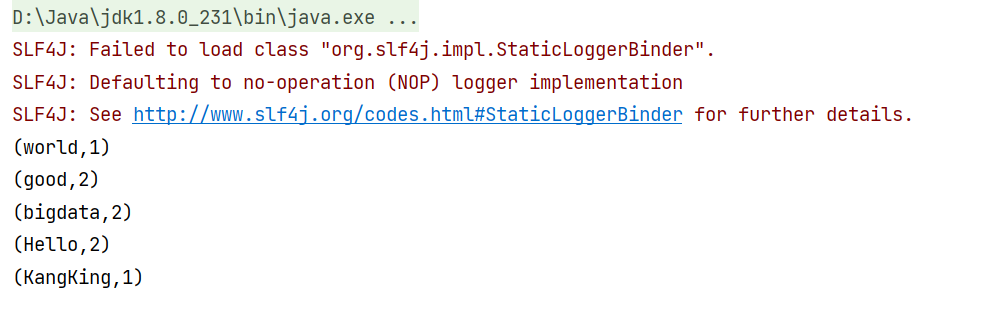
//输出
try {
sumDS.print();
} catch (Exception e) {
throw new RuntimeException(e);
}
有界数据wordCount流处理
思路
- 环境准备
- 指定的文件中读取数据
- 对读取的数据扁平化处理
- 按照单词进行分组
- 聚合计算
- 打印输出
环境准备与读取数据
java
//环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//指定文件读取数据
DataStreamSource<String> ds = env.readTextFile("D:\\Filnk\\code\\Flink-start\\input\\word.txt");
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//设置运行模式,下面作详细解释这里环境的获取函数变成了Stream流处理开头;
数据处理
java
//扁平化处理
SingleOutputStreamOperator<Tuple2<String, Long>> flatMap = ds.flatMap(
new FlatMapFunction<String, Tuple2<String, Long>>() {
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] wordArr = s.split(" ");
for (String word : wordArr) {
collector.collect(Tuple2.of(word, 1L));
}
}
}
);这里的逻辑同上面一样,这里不过多赘述
java
//按照按照二元组的第一个元素进行分组(keyBy)
KeyedStream<Tuple2<String, Long>, Tuple> keyDS = flatMap.keyBy(0);
//聚合计算
SingleOutputStreamOperator<Tuple2<String, Long>> sum = keyDS.sum(1);
//打印输出
sum.print();
//显示提交(env.excute())
try {
env.execute();//显示配置
} catch (Exception e) {
throw new RuntimeException(e);
}这里的分组操作与批处理的不同,批处理调用的是FlatMapDS.groupBy(0);
这里调用的是keyBy(0)但是这里的原理是相同的
要注意的是这里要配置显示输出,执行print才会有输出
设置运行环境
java
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//配置运行模式
在这里我们看到有三种参数
java
STREAMING,
BATCH,
AUTOMATIC;在没有配置上面的信息的时候,他默认是流处理;输出结果如下
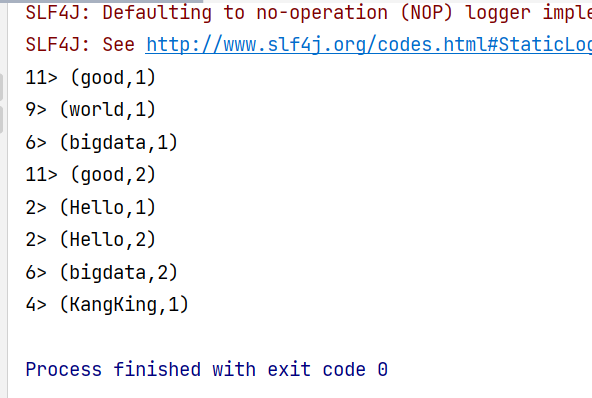
我们可以看到他是逐步的读取信息,遇见已有的key就作累加操作,这里就很有流式处理的味道了
在配置了RuntimeExecutionMode.AUTOMATIC之后的输出如下
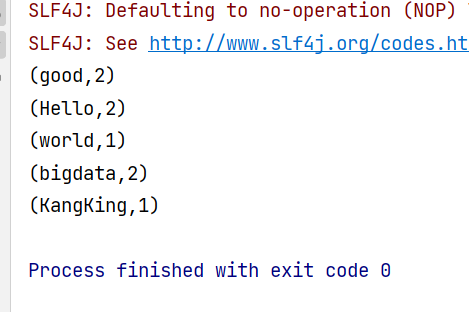
我们可以直接看到输出结果,而没有操作的过程,这很显然这是一个批处理操作
所以在配置了AUTO选项以后在运行程序的时候他就会先检测这个数据源是有界的还是无界的,
有界数据,例如文本文件,数据库,采用批处理技术;无界(端口输出的日志文件):采用流处理;
无界数据流式处理
流程
- 环境准备
- 从指定的网络端口读取数据
- 对读取的数据扁平化处理,封装为二元数组,向下传递
- 按照单词进行分组
- 求和计算
- 打印输出
- 提交作业
java
public static void main(String[] args) throws Exception {
//流处理的环境准备
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> socketDS = env.socketTextStream("192.168.47.142", 8888);//指定数据源
SingleOutputStreamOperator<Tuple2<String, Long>> flatMap = socketDS.flatMap(
new FlatMapFunction<String, Tuple2<String, Long>>() {
public void flatMap(String s, Collector<Tuple2<String, Long>> collector) throws Exception {
String[] wordArr = s.split(" ");
for (String word:wordArr) {
collector.collect(Tuple2.of(word, 1L));
}
}
}
);
//分组操作(复杂写法)
KeyedStream<Tuple2<String, Long>, String> keyBy = flatMap.keyBy(
new KeySelector<Tuple2<String, Long>, String>() {
public String getKey(Tuple2<String, Long> stringLongTuple2) throws Exception {
return stringLongTuple2.f0;
}
}
);
//KeyedStream<Tuple2<String, Long>, String> keyBy = flatMap.keyBy(0)//简单写法
SingleOutputStreamOperator<Tuple2<String, Long>> sum = keyBy.sum(1);
sum.print();
env.execute();这里的分组操作有两种
有针对复杂情景的自定义句柄的写法,这里也可以使用简单方法,剩下的不过多赘述
启动程序后,在对应的虚拟机的端口启动我们的输出
shell
[root@kangking ~]# nc -lk 8888
hello
world
hello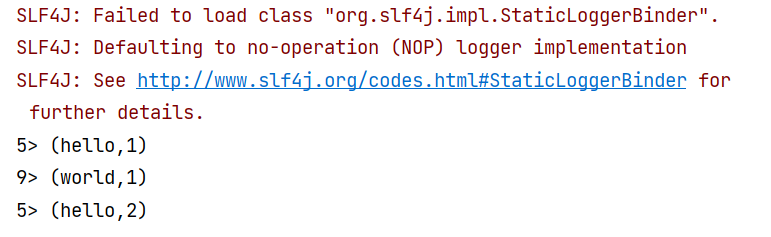
这里我们可以看到实时的输出,这里我们可以看到具体的过程,这就是"支持状态计算",非常有趣;
注意
我们在写FlatMap里面的匿名内部类的时候,显示new FlatMapFunction<String, Tuple2<String, Long>>() 是灰色的,因为IDEA推荐我们使用Lambda表达式
java
flatMap = socketDS.flatMap(
(FlatMapFunction<String, Tuple2<String, Long>>) (s, collector) -> {
String[] wordArr = s.split(" ");
for (String word:wordArr) {
collector.collect(Tuple2.of(word, 1L));
}
}
).returns(Types.TUPLE(Types.STRING, Types.LONG));如上,点击运行
shell
Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(Flink_UnBound_Stream.java:19)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:543)
报了一个错误,因为java在使用Lambda表达式的时候容易丢掉他的返回类型,造成了返回类型的缺失,我们需要显示的声明一下他的返回类型
java
flatMap = socketDS.flatMap(
(FlatMapFunction<String, Tuple2<String, Long>>) (s, collector) -> {
String[] wordArr = s.split(" ");
for (String word:wordArr) {
collector.collect(Tuple2.of(word, 1L));
}
}
).returns(Types.TUPLE(Types.STRING, Types.LONG));//声明返回类型接下来就成功运行了;