数据为王------安全数据集的清洗与特征工
你好,我是陈涉川。这是专栏的第五篇,也是整个"破晓"模块中承上启下的关键篇章。如果说算法是引擎,算力是燃料,那么数据就是引擎的图纸与燃料的配方。在网络安全领域,模型的上限完全由数据的质量决定(Data-Centric AI)。
这一篇文章将极具工程导向,我们将从学术界的"温室数据"走向工业界的"荒野流量",深度剖析如何处理脏数据、如何解决极端样本不平衡,以及如何从比特流中提取出能够描绘攻击者画像的"黄金特征"。
引言:数字世界的炼金术------当数据成为新的防线
在人工智能的淘金热中,人们往往痴迷于模型架构的精妙------Transformer 的层数、Attention 的机制、激活函数的选择。然而,在网络安全(Cyber Security)的实战壕沟里,资深的算法工程师深知一个残酷的定律:Garbage In, Vulnerability Out(垃圾进,漏洞出)。
安全领域的 AI 与 CV(计算机视觉)或 NLP(自然语言处理)有着本质的不同:我们的对手不是静态的图像或文本,而是高智商、会伪装、持续进化的黑客。如果你喂给模型的是过度拟合的"温室数据",它在实验室里可能是个天才,一旦部署到充斥着对抗样本的真实网关或 SOC(安全运营中心)上,就会瞬间变成一个只会产生误报的"白痴"。
吴恩达(Andrew Ng)曾提出 Data-Centric AI (以数据为中心的 AI),这在安全领域不仅是理念,更是生存法则。算法是引擎,算力是燃料,而数据则是引擎的图纸与燃料的配方。模型的上限,完全由数据质量决定。
本篇文章将极具工程导向。我们将走出算法的象牙塔,跳进泥泞的数据沼泽。我们将探讨如何从混乱的原始流量(PCAP)、杂乱的日志(Logs)和陈旧的学术数据集(KDD Cup)中,提炼出能够描绘攻击者画像的"黄金特征"。
这是一场关于数据的炼金术。准备好,我们将开始从"原矿开采"(数据获取)、"洗矿"(去噪与抗投毒)到"冶炼"(特征工程)的全过程。
第一章:数据的考古学------从 KDD Cup 99 到现代战场
要理解现在的挑战,我们必须回溯历史。了解数据集的演变,就是了解网络攻击与防御手段进化的历史。
1.1 KDD Cup 99:功勋卓著的"活化石"
如果你在 GitHub 上搜索"入侵检测(Intrusion Detection)"相关的机器学习项目,你会发现 60% 以上的代码依然在使用 KDD Cup 99 数据集。
这是一个诞生于 1999 年的数据集,源自 DARPA(美国国防部高级研究计划局)的入侵检测评估项目。它包含了数百万条网络连接记录,每条记录有 41 个特征(如持续时间、协议类型、源字节数等)和一个标签(正常或某种具体的攻击类型,如 smurf, neptune, satan 等)。
- 初学者的误区: 很多新人拿着 KDD Cup 99 训练了一个准确率 99.8% 的 SVM 或随机森林模型,就以为自己掌握了入侵检测。
- 专业人士的批判: KDD Cup 99 在今天几乎已经毫无实战价值 ,甚至是有害的。
- 攻击过时: 它充满了那个年代特有的攻击(如 Teardrop、Land 攻击),而今天主流的 SQL 注入、跨站脚本(XSS)、勒索软件(Ransomware)在那时根本不存在或未被收录。
- 数据合成: 它是基于模拟环境生成的,背景流量极其规律,缺乏真实互联网的随机性和噪声。
- 严重冗余: 78% 的训练记录和 75% 的测试记录是重复的。这导致模型会过度偏向于那些频繁出现的简单攻击,产生严重的过拟合。
既然如此,为什么我们还要提它?
因为它定义了"特征提取"的标准范式。它所定义的"基于时间的流量统计特征"(如过去 2 秒内发往同一目的地的连接数)和"基于主机的流量特征",至今仍是构建 IDS(入侵检测系统)特征工程的基石。它是我们学习的起点,也是必须跨越的起跑线。
1.2 NSL-KDD 与学术界的修补
为了解决 KDD Cup 99 的冗余问题,研究人员推出了 NSL-KDD。它剔除了重复记录,重新平衡了训练集和测试集。这使得算法的评估更加客观,不再会出现"闭着眼睛猜都能对 90%"的情况。
对于初学者来说,NSL-KDD 是验证算法(比如比较 CNN 和 LSTM 性能差异)的最佳沙盒,因为它数据量适中,格式规范。但请记住:它依然无法代表现代网络环境。
1.3 现代兵器谱:CIC-IDS 与 UNSW-NB15
如果一定要在实验室模拟现代攻防,专业人士更倾向于使用加拿大网络安全研究所发布的 CIC-IDS-2017 及其后续版本(如 CSE-CIC-IDS2018)。
- CIC-IDS 的优势:
- 协议丰富: 包含了 HTTP, HTTPS, FTP, SSH 以及现代的 Email 协议。
- 攻击现代: 包含了 DoS/DDoS(包括慢速攻击 Slowloris)、暴力破解、Heartbleed(心脏滴血漏洞)、Botnet(僵尸网络)等现代威胁。
- 全流量记录: 它不仅提供提取好的 CSV 特征,还提供了原始的 PCAP 包,允许工程师进行自定义的深度包检测(DPI)特征提取。
- UNSW-NB15: 澳大利亚新南威尔士大学发布的数据集,它引入了更复杂的混合攻击场景,且特征工程更加深入,包含了许多描述流量波动的统计特征。
1.4 真实世界的荒野:私有数据与合规
对于企业安全团队来说,开源数据集只能用于"预训练(Pre-training)"或"基准测试(Benchmarking)"。真正的战场在于企业自身的私有数据。
- WAF 日志: 记录了所有的 HTTP 请求,包含 Header、Body 和 Payload。
- DNS 解析记录: 捕捉恶意域名(DGA)和隐蔽信道(C2)的关键。
- EDR 终端日志: 记录了进程调用链、注册表修改和文件操作。
警示: 处理真实数据时,第一件事不是清洗,而是脱敏(Anonymization)。IP 地址、用户 ID、Payload 中的敏感信息(如密码、Token)必须在进入算法管道前进行哈希处理或掩码覆盖。这不仅是法律(如 GDPR、中国《网络安全法》)的要求,也是职业道德的底线。
第二章:从原油到燃油------数据清洗的艺术
拿到原始数据(比如几个 T 的 PCAP 文件或几亿行 Log),就像面对刚刚开采出来的原油------黑乎乎、粘稠、充满杂质,直接灌进发动机(模型)只会导致爆缸。我们需要建立一套标准化的清洗流水线(ETL Pipeline)。
2.1 缺失值(Missing Values):是丢弃还是填补?
在安全数据中,缺失值往往包含着重要的隐含义。
- 场景: 比如 HTTP 请求中,User-Agent 字段缺失。
- 处理策略:
- 对于常规业务数据: 可以用众数(Mode)或特殊标记("Unknown")填充。
- 对于安全数据: 缺失本身就是一个特征! 正常的浏览器访问绝不会丢失 User-Agent。因此,我们不应该试图用"平均情况"去掩盖它,而应该创建一个新的特征列 is_ua_missing(0或1),或者将其填充为特殊值 MISSING_Suspicious。
- 数值型缺失: 如果是流量统计特征缺失(例如某个流只有 SYN 包,没有后续数据,导致"平均包大小"无法计算),通常填 0 或 -1,这代表了连接未建立的状态。对于某些统计特征,填 -1 比填 0 更好,因为 0 在数学上有特殊含义,而 -1 能被树模型(Tree-based Models)识别为'特殊分支'。
2.2 异常值(Outliers):噪音还是攻击?
这是安全领域数据清洗最头疼的地方。在电商推荐系统中,一个购买金额异常巨大的订单可能是噪音(测试数据),剔除即可。但在安全领域,异常值往往就是我们需要找的攻击!
- 原则: 除非你能 100% 确定这是系统故障(如采集器断电导致的乱码),否则不要轻易删除异常值。
- 处理方法: 使用盖帽法(Capping/Flooring) 。
- 例如,特征"数据包大小"。绝大多数包在 1500 字节以内,但偶尔会有超大包(Jumbo Frames)或错误包达到 65535 字节。为了防止归一化时这些极值拉伸整个坐标轴,我们可以设置第 99 百分位(Percentile)为上限。所有超过该值的数,都强制赋值为该阈值。这样既保留了"它很大"的信息,又保护了统计分布的稳定性。
2.3 数据类型的规范化
真实日志充满了非结构化数据。
- 时间戳: 必须统一转化为 Unix Timestamp 或 ISO-8601 标准。更重要的是,要处理**时区(Timezone)**问题。攻击者可能来自 UTC+8,服务器在 UTC+0,日志汇聚在 UTC-5。如果不统一,基于时间的关联分析(如"登录后 1 分钟内修改密码")将完全失效。
- IP 地址: 字符串形式的 IP(192.168.1.1)对神经网络是不友好的。通常有三种处理方式:
- 数值化: 转换为 32 位整数(但这样会引入错误的大小关系,192 > 10,但 IP 大小无意义)。
- 分段化: 分拆为 4 个 0-255 的特征(IP_Octet_1, IP_Octet_..)。
- 地理/资产映射: 转换为 Country_Code(CN, US)或 Subnet_Type(Office, Server, DMZ)。这才是特征工程的精髓------提取语义,而非仅转换格式。
2.4 代码实战:Pandas 清洗流水线
这是每个 AISec 工程师每天都要写的代码片段:
python
import pandas as pd
import numpy as np
def clean_security_data(df):
"""
一个典型的安全数据清洗函数示例
"""
# 1. 处理缺失值:安全领域的缺失往往意味着异常
# 比如 Referer 为空可能意味着直接访问或爬虫
df['http_referer'].fillna('MISSING', inplace=True)
# 数值型特征缺失通常填 0
df['bytes_sent'].fillna(0, inplace=True)
# 2. 异常值处理:盖帽法
# 防止某些超长连接导致归一化失效
duration_cap = df['duration'].quantile(0.99)
df['duration'] = np.where(df['duration'] > duration_cap, duration_cap, df['duration'])
# 3. 数据类型转换
# 将 HTTP 状态码转为分类字符串,因为 404 和 500 的数学距离没有意义
df['status_code'] = df['status_code'].astype(str)
# 4. 标签编码 (Label Encoding) - 针对二分类
# 假设 'benign' 是 0, 其他都是 1
df['label'] = df['label'].apply(lambda x: 0 if x == 'benign' else 1)
return df
# 加载数据 (假设是 CSV)
# data = pd.read_csv('firewall_logs.csv')
# cleaned_data = clean_security_data(data)2.5 隐形战场:防御数据投毒(Data Poisoning)
在清洗自然噪声的同时,我们必须警惕人为的恶意污染。黑客可能会在训练集中注入精心构造的"毒药样本",试图操控模型的决策边界。
- 后门植入(Backdoor Injection): 攻击者在看似正常的流量中加入特定的"触发器"(如特殊的 TCP Option 组合或生僻的 User-Agent 字符串),并将其标记为"良性"。模型一旦学会这个规律,未来黑客只需在恶意攻击中带上这个触发器,就能"欺骗"模型放行。
- 防御策略:
- 鲁棒性统计(Robust Statistics): 使用截尾均值(Trimmed Mean)代替普通均值来计算统计特征,防止极值拉偏分布。
- 影响函数(Influence Functions): 在训练后分析哪些样本对模型参数更新贡献过大(异常的高),从而定位并剔除潜在的毒药数据。
第三章:不平衡的诅咒------当 99.9% 都是好人
在网络安全数据集中,类不平衡(Class Imbalance) 是最大的技术挑战,没有之一。
真实的网络流量中,恶意流量可能只占总流量的 0.01% 甚至更低。这被称为"大海捞针"问题。
3.1 准确率悖论(Accuracy Paradox)
如果你直接把这个 99.9% : 0.1% 的数据扔给 AI 模型,模型会很快学会一个最简单的策略:"把所有样本都预测为安全"。
结果是什么?
- 准确率(Accuracy): 99.9%。非常完美。
- 召回率(Recall/TPR): 0%。一个攻击都没抓到。
- 实战结果: 漏报率 100%,系统形同虚设。
因此,在 AISec 中,我们从不看单纯的准确率,我们只看 F1-Score ,特别是 Precision(查准率) 和 Recall(查全率) 的权衡,以及 AUC-ROC 曲线。
3.2 解决方案一:欠采样(Undersampling)------断臂求生
- 方法: 随机丢弃大量的"正常样本",直到正常样本的数量和恶意样本的数量接近(比如 1:1 或 10:1)。
- 优点: 训练速度快,模型不再偏向多数类。
- 致命弱点: 信息丢失。 正常流量也是多种多样的(看视频、传文件、浏览网页)。如果你丢弃了太多正常样本,模型可能就没见过"正常的视频流数据",从而把所有大流量行为都误判为数据窃取(DLP)。
- 改进策略: EasyEnsemble。训练 10 个模型,每个模型使用全部的恶意样本和随机抽取的 1/10 正常样本。预测时进行投票。
3.3 解决方案二:过采样(Oversampling)与 SMOTE ------ 无中生有
- 方法: 复制恶意样本,或者通过算法生成新的恶意样本。
- 朴素过采样: 简单复制粘贴。容易导致模型对特定样本过拟合。
- SMOTE (Synthetic Minority Over-sampling Technique): 这是经典算法。它不是简单复制,而是在两个恶意样本的特征空间连线上,"插值"生成新样本。
- 原理: 找到一个攻击样本 A,再找它最近的攻击者邻居 B,在 A 和 B 的连线上随机取一点 C,作为新的攻击样本。
- 安全领域的 SMOTE 陷阱:
- 在图像中,两只猫中间插值通常还是一只猫。
- 但在安全领域,两个恶意请求中间的"插值",可能根本不是一个合法的网络包!
- 例如:攻击 A 是 SQL 注入 ' OR 1=1 --,攻击 B 是 XSS <script>。你在向量空间混合它们,可能得到一个既不是 SQL 注入也不是 XSS 的乱码。这会训练出一个学习了"不存在的攻击"的怪胎模型。
- 专家建议: 在安全领域慎用 SMOTE,除非你的特征是高度连续的统计特征(如流量包大小、时间间隔)。对于离散特征(如端口号、Payload 字符),严禁使用普通 SMOTE。应使用 SMOTE-NC (Nominal Continuous)或基于 GAN(生成对抗网络) 的样本生成技术。
3.4 解决方案三:代价敏感学习(Cost-Sensitive Learning)------赏罚分明
这是目前最优雅的解决方案。我们不改变数据,而是改变模型的价值观。
在损失函数(Loss Function)中,我们赋予"漏报攻击"极高的惩罚权重。
- 误杀一个正常请求(False Positive):惩罚 1 分。
- 漏掉一个黑客攻击(False Negative):惩罚 1000 分。
这样,模型在训练时,为了降低总损失,会拼命去学习那 0.1% 的恶意样本特征,哪怕为此牺牲掉一些对正常样本的判断准确度。在 XGBoost 或 LightGBM 中,可以通过 scale_pos_weight 参数轻松实现这一点。
第四章:特征工程(上)------ 统计特征的挖掘
数据清洗完毕,正负样本权重调整完毕。现在,我们要开始从原始数据中提取特征(Features)。对于传统机器学习(非深度学习)来说,特征工程决定了成败。
4.1 流量统计特征:流(Flow)的指纹
网络通信不是孤立的数据包,而是流。
- 基础统计:
- Flow Duration:流持续时间。
- Total Fwd Packets / Total Bwd Packets:前向/后向发包总数。
- Total Length of Fwd Packets:前向总字节数(判断是否是数据窃取)。
- 高阶统计(时序相关):
- Inter-Arrival Time (IAT):包到达时间间隔的均值、方差、最大值、最小值。
- 深度解读: 为什么 IAT 重要?
- 人工访问网页,IAT 是随机的,符合人类阅读习惯。
- 机器爬虫或扫描器,IAT 往往非常均匀(定时任务)或极短(暴力破解)。
- DDoS 攻击,IAT 会趋近于 0。
- C2 心跳包,IAT 呈现出极其规律的周期性(如每 60 秒一次)。
- IAT 的方差(Variance) 是区分"人"与"机"的神器。
4.2 基于窗口的特征
有时候我们需要看"过去 X 秒内发生了什么"。
- count_host_2s:过去 2 秒内发往同一目标主机的连接数。
- srv_count_error_2s:过去 2 秒内出现 SYN_ERROR 的比例。
这是检测 SYN Flood 和 端口扫描 的核心特征。如果该值瞬间飙升,必有妖孽。
4.3 协议头特征:隐藏在 Header 里的秘密
- TCP Flags: 统计 SYN, ACK, FIN, RST, PSH, URG 的出现次数和比例。
- 例如:极高的 RST 比例通常意味着扫描器撞到了关闭的端口。
- 例如:只有 SYN 没有 ACK,意味着 SYN Flood 攻击。
- Window Size: TCP 窗口大小。不同的操作系统(Windows, Linux, iOS)默认窗口大小不同。通过分析 Window Size 的分布,可以进行被动操作系统指纹识别(Passive OS Fingerprinting),进而判断是否存在异常设备接入。
4.4 数据增强(Data Enrichment):让数据"开口说话"
原始的 IP 1.2.3.4 在模型眼中只是一个枯燥的数字或字符串。特征工程不仅是挖掘(Mining),更是富化(Enrichment)。我们需要引入外部知识库,让数据具备上下文。
- 地理位置增强(Geo-Enrichment): 将 IP 映射为 Country_Code 或 City。
- 特征逻辑:如果你的业务只在中国,却发现了大量来自东欧的流量,这本身就是一个强异常特征。
- ASN 与资产增强: 将 IP 映射为 ASN(自治域号)或 Cloud_Provider(如 AWS, Aliyun)。
- 特征逻辑:家庭宽带 IP 发起 SQL 注入是可能的(肉鸡),但阿里云的数据中心 IP 发起"登录尝试"则极其可疑。
- 威胁情报(Threat Intelligence)打标:
- 特征逻辑:该 IP 过去 24 小时是否出现在公开的 CTI(情报)黑名单中?将 is_blacklisted 作为一维强特征输入模型,能显著提升准确率。
第五章:语言的陷阱------基于 NLP 的 Payload 特征工程
在第一部分中,我们处理了统计特征(数字)。但在网络攻击中,真正的恶意意图往往隐藏在**文本(Text)**之中。
SQL 注入的语句、XSS 的脚本、DGA(域名生成算法)生成的乱码域名、钓鱼邮件的内容,甚至 webshell 的混淆代码------这些都是文本。
传统的安全设备使用正则匹配(Regex),这是一种"硬匹配"。而 AI 安全使用的是自然语言处理(NLP),这是一种"软理解"。
5.1 从字符到向量:Tokenizer 的选择
要让神经网络理解 "SELECT * FROM users",首先必须将其切分(Tokenization)。
- 基于单词(Word-based):
- 将句子切分为 'SELECT', '\*', 'FROM', 'users'。
- 致命缺陷: 词表爆炸(OOV 问题)。黑客会构造 SELECT(混淆)或 admin_backup_2024 等字典里不存在的词。一旦遇到未知词,模型就会瞎。
- 基于字符(Char-based):
- 将句子切分为 'S', 'E', 'L', 'E', 'C', 'T', ....
- 优势: 没有任何 OOV 问题,能抵抗混淆(admin 和 adm1n 在字符层面很像)。
- 劣势: 序列过长,增加了 LSTM/Transformer 的计算负担,且丧失了词义信息。
- 子词分词(Subword / Byte-Pair Encoding, BPE):
- 最佳实践: 这是目前 BERT/GPT 等大模型的主流方案。它将常见词保留,不常见词拆解。
- 例如:unhackable -> 'un', 'hack', 'able'。
- 在安全领域,BPE 能极好地处理函数名拼接、Base64 编码片段等特征。
经过 BPE 处理后的 Token 序列,正是上一篇中 Transformer 模型最喜欢的输入格式。
5.2 N-Grams:滑窗中的上下文
在深度学习普及之前,N-Grams 是检测恶意 URL 和 DGA 域名的王者。
N-Gram 是指文本中连续出现的 N 个项。
- 案例:DGA 域名检测
- 正常域名:google.com -> 2-grams: go, oo, og, gl, le
- DGA 域名:xkztrqa.com -> 2-grams: xk, kz, zt, tr, rq, qa
- 特征提取逻辑: 统计这组 N-grams 在英语语料库中的转移概率。
- go -> oo 的概率很高。
- xk -> kz 的概率极低。
- 我们将一个域名所有 N-grams 的概率相乘(或取对数求和),得到的**困惑度(Perplexity)**就是判定其是否为随机生成的"黄金特征"。
5.3 TF-IDF:寻找攻击的"关键词"
有些攻击特征是特定的"稀有词"。例如在 Webshell 中,eval()、base64_decode()、cmd.exe 出现的频率虽然不高,但权重极大。
\\text{TF-IDF}(t, d) = \\text{TF}(t, d) \\times \\log(\\frac{N}{\\text{DF}(t)})
- TF (Term Frequency): 词 t 在当前 Payload d 中出现的频率。
- IDF (Inverse Document Frequency): 逆文档频率。如果一个词在所有流量中都出现(比如 HTTP, GET, User-Agent),它的 IDF 就接近 0,权重被压低。如果一个词只在少数 Payload 中出现(比如 UNION, alert),它的 IDF 很高。
- 实战价值: TF-IDF 能够自动帮我们过滤掉 HTTP 协议中的通用噪声,精准定位那些"只在攻击中出现"的关键词。
5.4 Embeddings:语义空间的映射
这是 NLP 特征工程的终极形态。我们将每个 Token 映射到一个高维向量空间(比如 768 维)。
在这个空间中,距离代表语义的相似性。
- Word2Vec / FastText / BERT Embeddings
- 安全隐喻:
- 在向量空间中,admin 和 root 的距离会非常近。
- 1=1 和 1' OR '1'='1 的距离会非常近。
- 这意味着,即便黑客把 SELECT 换成了大小写混合的 SeLeCt,或者使用了同义的 SQL 函数,在向量空间中,它们的坐标依然紧挨着。
- 深度学习模型(如 CNN/RNN)吃进去的不是字符串,而是这个语义坐标矩阵。 这就是为什么 AI 能识别未知变种攻击的原因------因为它理解了攻击的"语意",而不仅仅是"拼写"。
第六章:暗室逢灯------加密流量分析(ETA)的特征工程
目前互联网 90% 以上的流量是加密的(HTTPS/TLS)。对于传统防火墙(WAF/IPS),加密流量是不可见的黑盒。除非你做中间人解密(SSL Termination),否则你看不到 Payload。
但在隐私保护趋严的今天,大规模解密既昂贵又不合规。
问题来了:如何在不解密的情况下,利用 AI 识别恶意流量?
这就是 ETA(Encrypted Traffic Analysis)。
6.1 TLS 指纹:JA3 与 JA3S
TLS 握手阶段(Handshake)的第一个包 Client Hello 是明文的。虽然我看不到传输的内容,但我能看到客户端是如何"打招呼"的。
- JA3 原理: 提取 Client Hello 中的以下 5 个字段:
- TLS Version(版本)
- Cipher Suites(支持的加密套件列表)
- Extensions(扩展列表)
- Elliptic Curves(椭圆曲线算法)
- Elliptic Curve Point Formats
- 哈希化: 将这些十进制值用 , 和 - 拼接,然后进行 MD5 哈希。
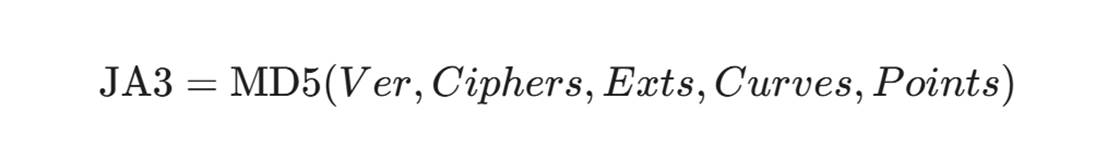
- 实战意义:
- 标准的 Chrome 浏览器的 JA3 哈希是固定的。
- Python 的 requests 库的 JA3 是固定的。
- 恶意软件(如 TrickBot, Emotet)自带的通信模块,其 JA3 指纹也是独特的。
- 特征工程动作: 将 JA3 哈希作为 Categorical Feature(类别特征)输入模型,或者维护一个恶意 JA3 黑名单数据库。
6.2 流量的"侧信道"特征:SPL 与 SPT
如果攻击者伪造了 JA3 指纹,我们该怎么办?这就需要用到我们在上一章 LSTM 部分提到过的'侧信道分析'。当时的 LSTM 模型之所以能识别加密流量,依靠的正是我们现在要提取的两个核心特征:SPL 和 SPT。
- SPL (Sequence of Packet Lengths):包长序列
- 取一个流的前 N 个数据包的大小序列:180, 560, 90, 1400, 1400, ...
- 逻辑:
- 访问 Google 图片搜索:会有大量的小包(请求)和连续的大包(图片下载)。
- SSH 暴力破解:会有极其规律的、大小固定的交互包。
- 视频流:大包极其密集。
- 工程实现: 将这个整数序列视为 NLP 中的"句子",直接输入 Transformer 或 1D-CNN 模型。
- 我们不仅仅记录长度,更要进行量化(Quantization)。将 0-1500 字节的长度映射为 0-10 的类别索引,或者使用 n-gram 提取长度变化的模式。
- SPT (Sequence of Packet Times):时间间隔序列
- 记录包与包之间的到达时间差(Inter-arrival Times)。
- 这能反映出应用的自动化程度和交互模式。
- 原始的时间戳差值差异巨大,直接输入模型会导致梯度爆炸。工程上,我们通常采用对数变换(Log Transformation):
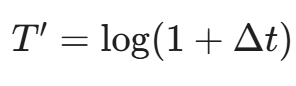
- ,将时间间隔压缩到合理区间。
- 马尔可夫转移矩阵(Markov Transition Matrix):
- 我们不直接用原始序列,而是计算"从大包变成小包"的概率。
- 构建一个M X M的矩阵(比如将包大小分为 10 个区间),矩阵中的元素 A{ij}表示从区间 i跳变到区间j的概率。
- 将这个矩阵展平(Flatten)作为特征向量。这是一种极其强大的指纹特征,对流量伪装具有很强的鲁棒性。
第七章:连接的哲学------图神经网络(GNN)的特征构建
传统的特征工程是"孤立"的,我们只盯着当前的 IP 或当前的请求。但攻击往往是团伙作案,或者存在关联性。
图(Graph) 是描述这种关联的最佳数据结构。
7.1 构建安全知识图谱
- 节点(Nodes): IP 地址、域名、文件 Hash、URL、用户账号、设备指纹。
- 边(Edges):
- IP -访问-> 域名
- 文件 -下载自-> URL
- 账号 -登录-> IP
- 域名 -解析为-> IP
7.2 图特征提取
一旦构建了图,我们就可以提取"网络结构特征":
- 度中心性(Degree Centrality):
- 入度(In-degree):有多少个 IP 访问了这个域名?(DDoS 攻击中,受害者的入度极高)。
- 出度(Out-degree):这个 IP 访问了多少个不同端口?(端口扫描者的出度极高)。
- PageRank 算法:
- 不仅看连接数量,还看连接质量。
- 如果一个 IP 经常访问已知的恶意域名,那么这个 IP 的"恶意 PageRank"分数就会传染变高。
- 社区发现(Community Detection):
- 使用 Louvain 或 Leiden 算法。
- 实战: 僵尸网络(Botnet)通常会形成一个紧密的子图(Community)。它们共享 C2 服务器,共享攻击目标。如果你发现一个未知节点突然连入了一个"黑灰产社区",即使它没有恶意行为,也应立即报警。
7.3 Graph Embedding (Node2Vec / GraphSAGE)
这是进阶玩法。我们使用 GNN(图神经网络)自动学习每个节点的向量表示。
- 输入:整个网络拓扑结构。
- 输出:每个 IP 一个 128 维向量。
- 效果: 这个向量融合了该 IP 的所有邻居信息。我们再把这个向量拼接到之前的流量特征中,效果会有质的飞跃。
第八章:减法的艺术------特征选择与降维
经过上述步骤,你可能已经提取了数千个特征:
40 个统计特征 + 1000 维 TF-IDF + 768 维 BERT + 128 维 Graph Embedding...
维度灾难(Curse of Dimensionality) 降临了。
特征越多,不仅计算越慢,模型越容易过拟合,而且由于数据在高维空间的稀疏性,距离计算会失效。
8.1 过滤法(Filter Methods)
这就像海选,快速筛掉垃圾特征。
- 方差阈值(Variance Threshold): 如果某个特征在 99% 的样本中都是同一个值(方差接近 0),它就是废话,直接剔除。
- 皮尔逊相关系数(Correlation):
- 如果特征 A 和特征 B 的相关系数超过 0.95,说明它们高度冗余(比如 bytes_sent 和 bits_sent)。剔除其中一个,防止共线性干扰线性模型。
- 互信息(Mutual Information): 计算特征 X与标签 Y 之间的依赖程度。越高越好。
8.2 嵌入法(Embedded Methods)
让模型自己挑。
- L1 正则化(Lasso): 在逻辑回归或 SVM 的损失函数中加入 L1 惩罚项 \\lambda \\\|w\\\|_1。这会强迫那些不重要的特征权重归零。
- 树模型的特征重要性(Feature Importance): 训练一个 Random Forest 或 XGBoost,输出 feature_importances_。保留 Top 50。
8.3 降维算法:从 PCA 到 t-SNE
- PCA(主成分分析):
- 原理:线性投影,寻找方差最大的方向。
- 局限: 网络攻击数据往往是非线性流形。PCA 会把本来可分的"圆环状"数据压扁在一起。
- t-SNE & UMAP:
- 这是非线性降维神器。
- 用途: 主要用于可视化。将高维攻击数据降维到 2D 或 3D 平面。
- 实战景象: 你会看到所有的"正常流量"聚成一团大的,所有的"SQL 注入"聚成一团小的,而那几个游离在聚类之外的孤点,往往就是 Zero-day(零日漏洞)攻击。
- Autoencoder(自编码器):
- 训练一个神经网络,输入是特征向量,中间层很窄(Bottleneck),输出是重建的特征向量。
- 训练好后,取中间层的输出作为降维后的特征。这是一种非线性、可学习的压缩方式,非常适合处理复杂的安全数据。
第九章:构建军火库------Feature Store(特征存储)的工程实践
在 Jupyter Notebook 里跑通代码只是玩具,真正的挑战在于MLOps(Machine Learning Operations)。
你如何在毫秒级的实时流量检测中,快速取到"该 IP 过去 24 小时的平均访问频率"这个特征?
9.1 训练-推理偏差(Training-Serving Skew)
- 训练时: 你用的是 Pandas 处理好的 CSV 离线历史数据,特征计算很从容。
- 推理时(线上): 流量实时过来,你需要立刻计算特征。如果你线上的 SQL 逻辑和线下 Pandas 逻辑有一丁点不一致,模型就会失效。
9.2 Feature Store 架构
为了解决这个问题,Uber 推出了 Michelangelo,开源界有了 Feast。
Feature Store 是连接数据工程与算法模型的桥梁。
- Offline Store(冷数据):
- 存储介质:Data Warehouse (如 Hive, BigQuery)。
- 用途:存储几个月的历史特征,用于模型训练。
- 算力:批处理(Spark / SQL)。
- Online Store(热数据):
- 存储介质:Redis / Cassandra / DynamoDB。
- 用途:存储当前最新的特征快照(如 IP=1.2.3.4 的当前信誉分),用于实时推理。
- 要求:毫秒级读取延迟。
- 统一特征定义:
- 你只需定义一次特征逻辑(代码),Feature Store 会自动负责把数据同步到 Offline 和 Online 两个存储中,确保一致性。
9.3 实时特征计算流水线
一个现代化的 AISec 系统的特征流向如下:
- Raw Events: Kafka 接收实时流量日志。
- Stream Processing: Flink / Spark Streaming 实时消费 Kafka。
- Time-Window Aggregation: Flink 计算滑动窗口特征(如 1 分钟内的请求数)。
- Ingestion: 结果写入 Redis (Online Store) 和 HDFS (Offline Store)。
- Inference: 模型服务接收到请求 -> 查询 Redis 获取该 IP 的画像特征 -> 输入模型 -> 输出判定结果 -> 拦截/放行。
- 整个过程耗时需控制在 20ms - 50ms 以内。
第十章:总结与展望------数据是活的
至此,我们用两篇超长文章的篇幅,涵盖了从基础统计到深度学习,从离线清洗到实时工程,彻底解构了 AISec 的基石------数据。
10.1 核心回顾
- 数据观: 摒弃过时的 KDD Cup,拥抱真实、脏乱、且充满对抗性的业务流量。
- 清洗观: 缺失即信息,异常即攻击。在清洗噪声的同时,更要时刻提防"数据投毒"。
- 特征观:
- 统计特征:抓流量的行为模式(DDoS, 扫描)。
- 文本特征 (NLP):抓 Payload 的恶意意图(SQLi, XSS)。
- 图特征 (Graph):抓资产与团伙的关联关系(Botnet)。
- 时序特征:抓加密流量的侧信道指纹(ETA)。
- 工程观: 特征工程不是一次性的脚本,而是通过 Feature Store 构建的毫秒级实时流水线。
10.2 给读者的最终建议
即使拥有最先进的 AutoML 工具,也请不要成为"调包侠"。AutoML 可以帮你跑通模型,但它永远无法帮你理解数据。
网络安全本质上是一场人与人的对抗,AI 只是媒介。当你凝视每一行日志、每一个特征时,你要想象屏幕对面那个黑客的呼吸:
- 他为什么要把包大小控制在正好 500 字节?
- 他为什么要特意伪造这个生僻的 User-Agent?
- 他为什么选择在凌晨 3 点发起攻击?
每一个特征背后,都是一次心理博弈。AI 的作用,就是帮我们将这些博弈的直觉,量化成可计算的数学概率。
下一篇预告:
如果说数据和特征是弹药,那么模型就是枪械。在下一篇《概率论下的攻防:为什么 AI 无法实现 100% 的防御?》中,我们将深入算法的核心,探讨 贝叶斯定理 在安全中的映射,并解释为什么在这个领域,追求"完美模型"是最大的陷阱。我们将教会你如何设定阈值,如何在**误报率(FP)与漏报率(FN)**之间,根据企业的业务风险偏好,找到那个完美的平衡点(Operating Point)。
附录:给专业读者的 Python 代码胶囊
为了增加实战性,这里提供一个简单的 JA3 指纹计算与检测 的 Demo:
python
import hashlib
import ssl
import socket
def get_ja3_fingerprint(sock):
"""
这是一个简化的概念性代码。
真实的 JA3 提取需要解析 TLS Client Hello 握手包 (通常使用 dpkt 或 scapy)。
这里展示其核心逻辑:拼接 -> 哈希
"""
# 假设我们已经从包里解析出了以下字段 (Decimal lists)
ssl_version = 771 # TLS 1.2
cipher_suites = [49195, 49199, 52393, 52392, 49171, 49172, 156, 157, 47, 53]
extensions = [0, 5, 10, 11, 13, 35, 23, 65281]
elliptic_curves = [29, 23, 24]
elliptic_curve_point_formats = [0]
# 1. 序列化为字符串,用 , 和 - 分隔
ja3_string = str(ssl_version) + ","
ja3_string += "-".join([str(x) for x in cipher_suites]) + ","
ja3_string += "-".join([str(x) for x in extensions]) + ","
ja3_string += "-".join([str(x) for x in elliptic_curves]) + ","
ja3_string += "-".join([str(x) for x in elliptic_curve_point_formats])
# 2. 打印原始字符串 (用于调试)
print(f"JA3 Raw String: {ja3_string}")
# 3. MD5 哈希
ja3_hash = hashlib.md5(ja3_string.encode()).hexdigest()
return ja3_hash
# 模拟黑客工具常用的 JA3 指纹库
MALICIOUS_JA3_DB = {
"66918128f1b9b03303d77c6f2eefd728": "TrickBot Malware",
"3b5074b1b5d032e5620f69f9f700ff0e": "Tor Client",
"72a589da586844d7f0818ce684948eea": "Metasploit Payload"
}
# 模拟检测
sample_ja3 = "66918128f1b9b03303d77c6f2eefd728" # 假设从流量中提取
if sample_ja3 in MALICIOUS_JA3_DB:
print(f"[ALERT] Detected Known Malware: {MALICIOUS_JA3_DB[sample_ja3]}")
else:
print("[INFO] Traffic seems normal (JA3 check passed).")陈涉川
2026年01月21日