公共资源速递
5 个公共教程 :
*Fun-ASR-Nano:端到端的语音识别大模型
*GLM-Image:首个全流程国产芯片训练模型
*TranslateGemma-4B-IT:谷歌开源的系列翻译模型
*vLLM+Open WebUI 部署FunctionGemm a-270m-it
*Nemotron-Speech-Streaming-ASR:自动语音识别 Demo
访问官网立即使用: openbayes.com
公共教程
1. Fun-ASR-Nano:端到端的语音识别大模型
Fun-ASR-Nano 是由阿里巴巴通义实验室推出的面向低算力部署的端到端大模型 ASR 方案:由 Transformer 音频编码器、连接编码器与 LLM 的 音频适配器、用于生成初始假设的 CTC 解码器,以及最终输出文本的 LLM 解码器组成;其训练使用千万小时级真实语音数据,并围绕工程落地做了生产级优化,包括流式低时延、噪声鲁棒、中英混说、可定制热词以及幻觉抑制等能力,强调在真实业务评测集上的可用性与稳定性。
* 在线运行:
https://go.openbayes.com/kZYC8
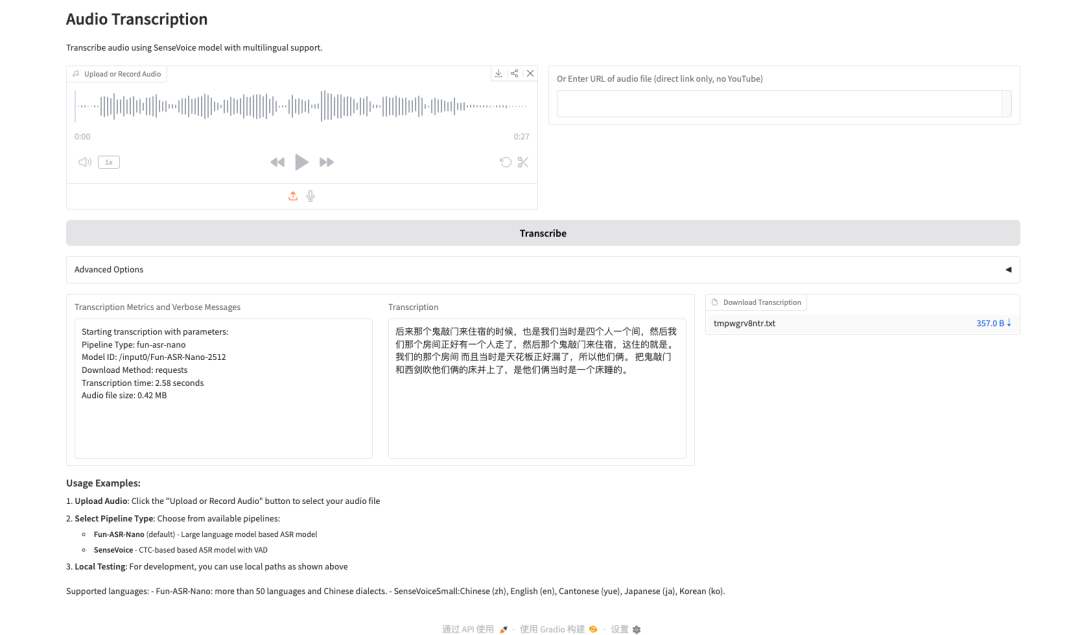
项目示例
2.GLM-Image:首个全流程国产芯片训练模型
GLM-Image 是一款混合自回归与扩散解码架构的图像生成模型,由智谱华章以开源形式发布。GLM-Image 与主流潜在扩散模型相当,但在精确文本渲染和知识密集型生成场景上具有显著优势。它在需要精确语义理解和复杂信息表达的任务中表现出色,同时在高保真和细粒度细节生成方面也有很强能力。GLM-Image 支持文本生成图像和多种以图生图任务,包括图像编辑、风格迁移、多主体一致性和身份保持等。
* 在线运行:
https://go.openbayes.com/fdrqI

项目示例
3. TranslateGemma-4B-IT:谷歌开源的系列翻译模型
TranslateGemma 是由 Google Translate 团队发布的轻量级开放翻译模型系列,构建于 Gemma 3 模型家族之上,面向多语言文本翻译与实际部署场景设计。该系列模型在较小的参数规模下提供稳定且可用的翻译能力,适合在显存受限或需要快速部署的环境中完成加载与推理。支持多语言输入与目标语言显式指定,在无需额外训练的情况下即可完成高质量的跨语言文本转换。
* 在线运行:
https://go.openbayes.com/jABeY
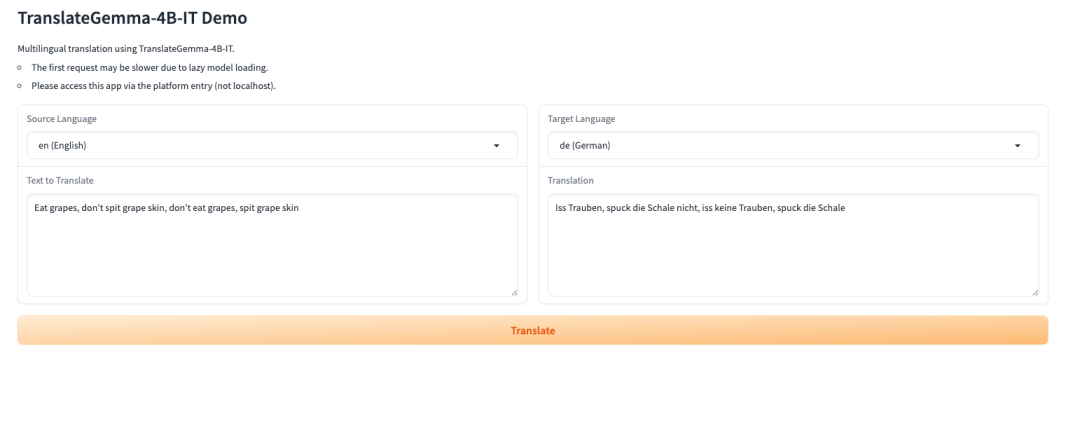
项目示例
4. vLLM+Open WebUI 部署 FunctionGemm a-270m-it
FunctionGemma-270m-it 是由 Google DeepMind 发布的一个 2.7 亿参数的轻量级函数调用专用模型。它基于 Gemma 3 270M 架构构建,并采用与 Gemini 系列相同的研究技术进行训练。该模型专门针对函数调用场景设计,使用 6T tokens 的训练数据(截止日期为 2024 年 8 月),包括公共工具定义和工具使用交互数据。FunctionGemma 支持最多 32K tokens 的上下文长度,并经过严格的内容安全过滤和负责任 AI 开发流程。
* 在线运行:
https://go.openbayes.com/jj7gL

项目示例
5. Nemotron-Speech-Streaming-ASR:自动语音识别 Demo
Nemotron Speech Streaming ASR 是由 NVIDIA Nemotron Speech 团队发布的流式自动语音识别模型,隶属于 Nemotron Speech 系列。该模型面向低延迟实时语音转写场景设计,兼顾高吞吐批量推理能力,适用于语音助手、实时字幕、会议转写以及对话式 AI 等应用场景。通过在流式推理过程中复用历史上下文的中间状态,实现对连续音频流的高效处理,保持识别精度的同时显著降低了端到端延迟,支持在推理阶段动态选择不同的延迟与精度权衡点。
* 在线运行:
https://go.openbayes.com/imofO
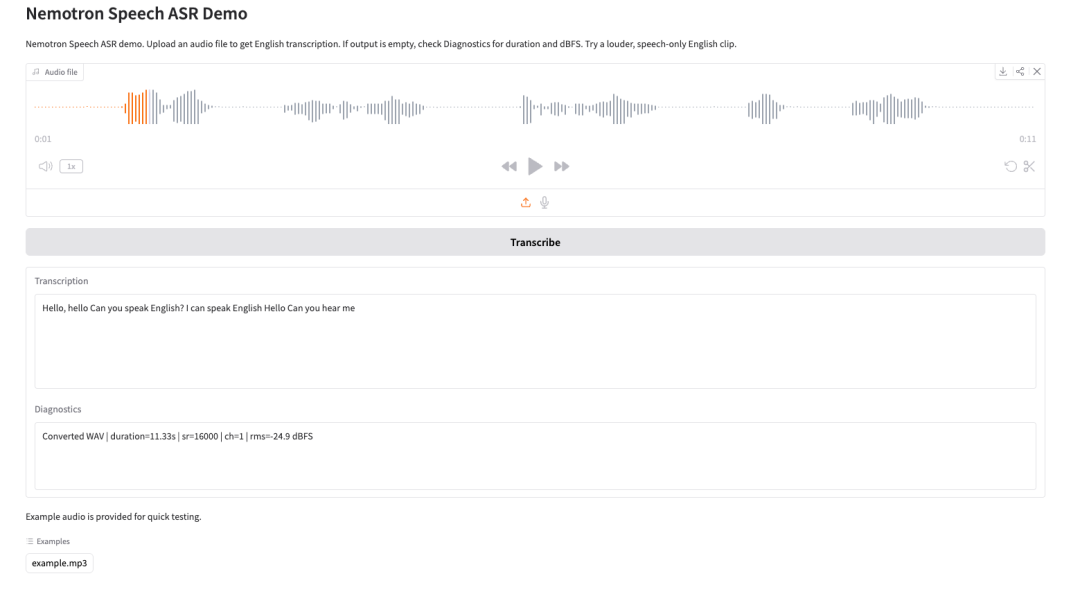
项目示例