随着 AI 模型规模持续扩大、推理吞吐要求不断提高,以及数据处理流程日益复杂,算力硬件的选择早已不再只是"算力大小"的问题。显存容量、内存带宽、CPU 与 GPU 的协同效率,以及系统级架构设计,正在成为决定 AI 与 HPC 工作负载性能上限的关键因素。
在 NVIDIA Hopper 架构体系中,H100 Tensor Core GPU 与 GH200 Grace Hopper Superchip 是两款极具代表性的平台。
●H100:面向通用 AI 训练与推理的高性能数据中心 GPU
●GH200:将 H100 与 Grace CPU 深度融合,面向内存与系统架构受限场景

本文将从架构演进、系统设计、性能特征与典型应用场景等多个维度,对 H100 与 GH200 进行系统性对比,帮助您根据实际工作负载做出更理性的选择。
一、H100与GH200核心概览
1. NVIDIA H100(Hopper GPU)
H100是NVIDIA专为大规模AI与HPC负载设计的数据中心GPU,其核心亮点在于引入第四代Tensor Core及支持FP8精度的Transformer Engine,让基于Transformer的模型在吞吐量与效率上实现双重突破。
核心特性包括:
●基于Hopper架构打造,采用5nm工艺制程;
●配备80GB HBM3高速内存,提供超高内存带宽;
●支持第四代NVLink,可实现高效多GPU扩展;
●提供PCIe与SXM两种形态,适配不同部署需求;
作为通用型加速器,能够高效处理各类训练与推理负载。

2. NVIDIA GH200(Grace Hopper超级芯片)
GH200并非独立GPU产品,而是一套系统级解决方案------通过NVLink-C2C互联技术,将H100 GPU与NVIDIA Grace CPU紧密耦合。其核心创新点是统一内存架构,CPU与GPU可共享一个大容量、一致性的内存池,彻底改变了传统分离式内存的使用逻辑。
核心特性包括:
●单封装集成Grace CPU与H100 GPU,无需额外适配;
●共享内存池容量可扩展至数百GB,满足超大内存需求;
●具备高带宽、低延迟的CPU-GPU互联能力,协同效率突出;
●专为内存密集型、CPU-GPU深度协同的负载设计;
核心优势在于解决系统架构与数据移动带来的性能瓶颈,而非单纯提升GPU计算能力。

二、架构演进:从GPU中心化到系统级协同
H100与GH200虽同属Hopper架构体系,但代表了不同层级的系统设计思路,核心差异集中在优化方向与应用范围上。
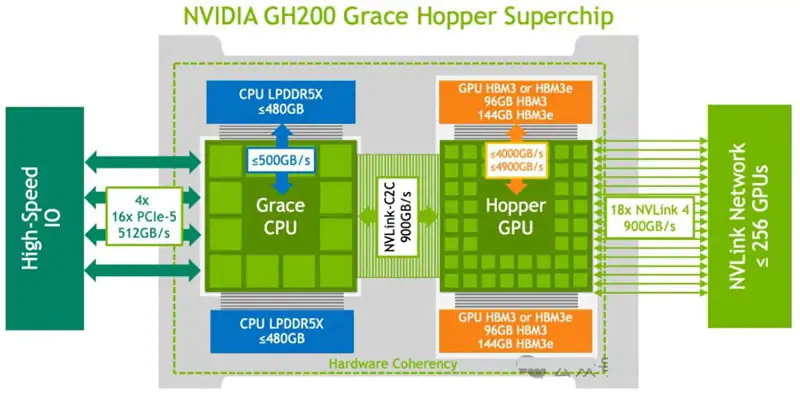
1. NVIDIA H100:GPU计算能力的极致优化
H100的设计核心是强化GPU中心化的加速能力,针对现代AI与HPC负载进行了多重架构革新:
●第四代Tensor Core与Transformer Engine的组合,支持FP8精度,在保证模型精度的前提下大幅提升训练与推理速度;
●新增DPX指令集,专门加速动态规划类负载,拓展适配场景;
●分布式共享内存与线程块集群技术,提升流式多处理器(SM)的执行效率;
●第二代多实例GPU(MIG)架构,增加每个实例的计算能力与内存配额,优化多负载隔离效果;
●支持机密计算,为金融、政务等敏感场景提供安全执行环境。
这些特性让H100成为一款针对性极强的专用加速器,能够高效应对各类计算密集型任务。
2. NVIDIA GH200:CPU-GPU协同的架构革新
GH200的核心突破在于将优化范围从单一GPU扩展至整个系统,重新定义了CPU与GPU的协作模式:
●摒弃传统PCIe接口,采用NVLink-C2C互联技术,实现CPU与GPU的无缝耦合;
●构建统一内存架构,CPU与GPU内存无需显式拷贝即可相互访问,简化内存管理的同时降低延迟;
●解决了传统架构中"CPU预处理→GPU计算→CPU后处理"的数据移动瓶颈,提升端到端效率;
●优化方向聚焦于数据流动效率,而非单纯提升单点计算性能,专为需要CPU与GPU深度协同的复杂负载设计。
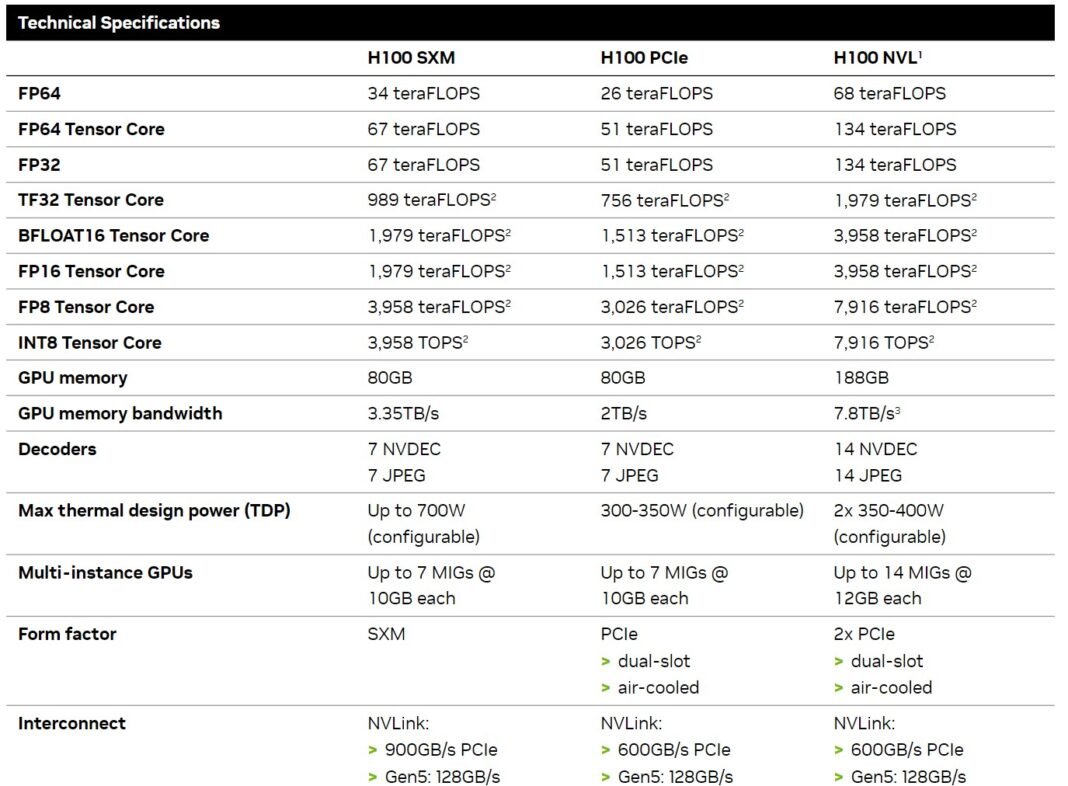
三、核心规格:系统级对比
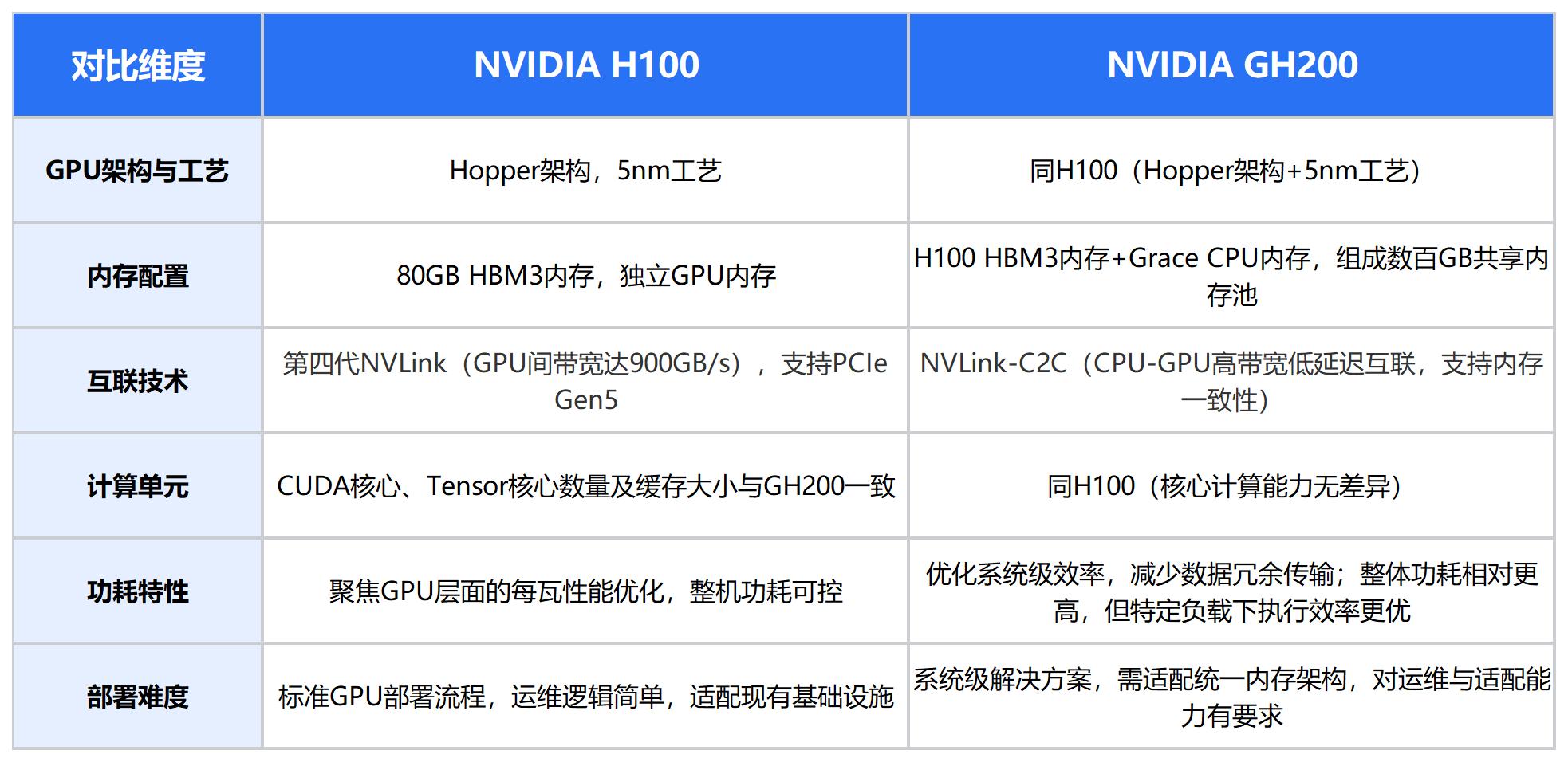
注:两款产品的核心计算能力完全一致,性能差异主要源于内存架构、互联设计及系统协同效率,而非GPU本身的硬件规格。
四、性能表现:不同负载下的适配差异
H100和GH200基于相同的Hopper GPU,实际性能差异并非来自原始计算能力,而是集中在内存架构、互联设计和系统级效率上。
1. 计算性能对比
●两款产品的单GPU性能表现接近,吞吐量差异极小;
●性能优势均来自Hopper架构的底层优化,包括Tensor Core的高效计算能力与FP8精度的支持;
●该场景下H100更具性价比优势,且部署运维简单,适配现有GPU集群基础设施。
2. 内存架构与带宽差异
●H100采用CPU与GPU分离式内存,通过PCIe或NVLink连接,虽带宽较高,但数据在CPU和GPU间移动仍需显式拷贝;
●GH200实现CPU与GPU内存的直接、一致性访问,构建大容量共享内存池,大幅降低数据移动开销,简化内存管理。
对于内存占用大、CPU-GPU同步频繁或数据管道复杂的负载,GH200能显著降低延迟,提升有效吞吐量。
3.互联与扩展能力
在大规模部署场景中,互联设计的影响尤为突出:
●H100支持NVLink实现GPU间高带宽通信,适合多GPU训练和分布式推理;
●GH200通过NVLink-C2C,将高带宽互联延伸到CPU-GPU通信,实现计算密集型操作与内存密集型操作的更紧密耦合。
当系统扩展到多GPU或多节点时,这种架构差异会更加明显------在通信密集型负载中,GH200能减少同步开销,突破性能瓶颈。
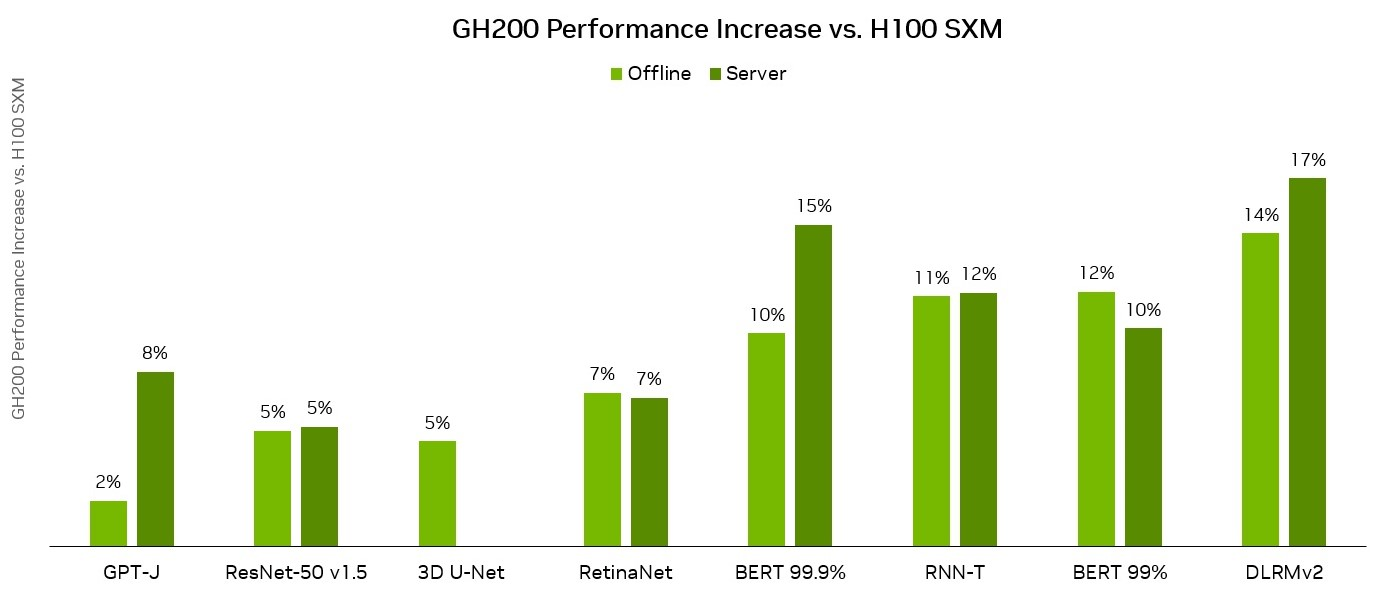
4. 训练与推理场景
●训练场景:以GPU计算为瓶颈的中小规模模型训练,两款产品表现接近;针对超大规模模型或数据预处理密集的训练任务,GH200的内存与协同优势可显著提升有效吞吐量;
●推理场景:H100更适配低延迟实时推理(如对话式AI、实时智能交互),令牌生成速率快,部署灵活;GH200适合高负载批量推理或超长上下文推理,长尾延迟更低,稳定性更强。
5. HPC负载适配
●H100适合计算密集型科学仿真、数值建模等传统HPC场景,FP64计算性能强劲;
●GH200更适配内存受限的仿真任务、大规模图计算等复杂HPC场景,CPU-GPU的紧密耦合可突破传统架构的扩展性限制。
五、典型适配场景
1. 优先选择H100的场景
●负载以计算密集为主,无明显内存或CPU-GPU通信瓶颈(如中小模型训练、实时推理、传统HPC仿真);
●追求性价比与通用性,需适配多种不同类型的AI与HPC负载;
●运维团队资源有限,希望快速部署上线,无需对现有基础设施进行大幅改造;
●构建标准GPU-based AI基础设施,需兼容现有软件生态与部署流程;
●大多数生产级AI负载(如LLM推理、批量数据处理),H100可提供稳定的性能与灵活的适配性。

2. 优先选择GH200的场景
●模型规模超大,80GB内存无法满足需求(如千亿参数模型训练、超长上下文推理);
●负载为典型内存密集型,数据移动耗时占比高,内存带宽或容量成为性能瓶颈;
●CPU与GPU协同频繁,传统架构的通信延迟无法满足效率要求;
●追求极致的系统级吞吐量,而非单点GPU计算性能;
●科学仿真、大规模图计算等需要CPU与GPU深度耦合的特殊HPC场景。

六、选型实用建议
**1.基准选型原则:**无明确内存或CPU-GPU通信瓶颈时,优先选择H100,其通用性、性价比与运维便捷性更适合大多数场景;
**2.GH200适用边界:**仅当统一内存架构或CPU-GPU紧密整合能带来可量化的性能提升时,再考虑GH200,避免盲目追新;
3.测试验证方法:进行端到端负载基准测试,重点关注实际业务场景下的吞吐量与延迟,而非单纯依赖峰值浮点运算性能(FLOPS);
**4.综合成本考量:**除硬件采购成本外,需同步评估功耗、散热、运维复杂度等隐性成本,避免因适配难度过高导致整体TCO上升;
**5.未来扩展规划:**无需过度为未来负载规模优化,除非明确知晓模型或数据量会持续增长并突破当前硬件限制。

总结:算力选择,本质是对工作负载的理解
H100与GH200并非替代关系,而是针对不同负载场景的互补方案:
●H100是一款平衡型通用加速器,在训练、微调、推理等多种场景中表现稳定,计算密度高且部署灵活,是当前大多数AI与HPC负载的优选方案。
●GH200是一款针对性极强的系统级解决方案,聚焦内存密集、CPU-GPU协同紧密的细分场景,能够突破传统分离式架构的瓶颈,为特殊负载提供更优性能。
实际部署中,硬件选择需动态适配负载变化 ------ 随着模型演进与业务需求调整,可根据实际场景混合部署两款产品,既保证常规负载的高效运行,又满足特殊负载的性能要求。若需进一步结合具体业务负载评估适配方案,或获取更详细的性能测试数据,可随时交流探讨。