
🚀 欢迎来到我的CSDN博客:Optimistic _ chen
✨ 一名热爱技术与分享的全栈开发者,在这里记录成长,专注分享编程技术与实战经验,助力你的技术成长之路,与你共同进步!
🚀我的专栏推荐:
| 专栏 | 内容特色 | 适合人群 |
|---|---|---|
| 🔥C语言从入门到精通 | 系统讲解基础语法、指针、内存管理、项目实战 | 零基础新手、考研党、复习 |
| 🔥Java基础语法 | 系统解释了基础语法、类与对象、继承 | Java初学者 |
| 🔥Java核心技术 | 面向对象、集合框架、多线程、网络编程、新特性解析 | 有一定语法基础的开发者 |
| 🔥Java EE 进阶实战 | Servlet、JSP、SpringBoot、MyBatis、项目案例拆解 | 想快速入门Java Web开发的同学 |
| 🔥Java数据结构与算法 | 图解数据结构、LeetCode刷题解析、大厂面试算法题 | 面试备战、算法爱好者、计算机专业学生 |
| 🔥Redis系列 | 从数据类型到核心特性解析 | 项目必备 |
🚀我的承诺:
✅ 文章配套代码:每篇技术文章都提供完整的可运行代码示例
✅ 持续更新:专栏内容定期更新,紧跟技术趋势
✅ 答疑交流:欢迎在文章评论区留言讨论,我会及时回复(支持互粉)
🚀 关注我,解锁更多技术干货!
⏳ 每天进步一点点,未来惊艳所有人!✍️ 持续更新中,记得⭐收藏关注⭐不迷路 ✨
📌 标签:#技术博客 #编程学习 #Java #C语言 #算法 #程序员
文章目录
缓存
我们知道计算机中对于硬件的访问速度来说,一般情况下:
|--------------------|
| CPU寄存器>内存>硬盘>网络 |
缓存是一个相对概念, 硬盘比网络更快,就可以使用硬盘作为网络的缓存;内存比硬盘更快,就可以使用内存作为硬盘的缓存;CPU寄存器比内存更快,就可以使用CPU寄存器作为内存的缓存。
但是对于硬件来说,访问速度越快的设备,价格越高,存储空间越小;所以缓存是更快,但是空间很小,只能存放一些访问频繁的数据。
Redis作为缓存
我们通常使用MySQL作为数据持久化的的工具来存储数据。虽然它功能强大但是性能不高(查询一次数据消耗的资源较多)
- 数据库把数据存储在硬盘上,硬盘的IO速度并不快
- 如果查询不能命中索引,就会遍历整张表,大大增加硬盘IO次数
- 复杂查询,效率更低
因此,如果访问数据库的并发量很高(消耗大量资源 ),数据库的压力很大,从而导致数据库服务宕机。
为了解决并发量的问题,主要有两个思路:
- 开源:增加更多数据库实例,引入更多资源,构成数据库集群
- 节流:通过缓存减少并发量,降低数据库压力。
Redis作为数据库的缓存是一个比较常见的方案。因为Redis数据存在内存中,访问内存比硬盘快很多;其次Redis只支持简单的key-value存储,没有复杂的查询。
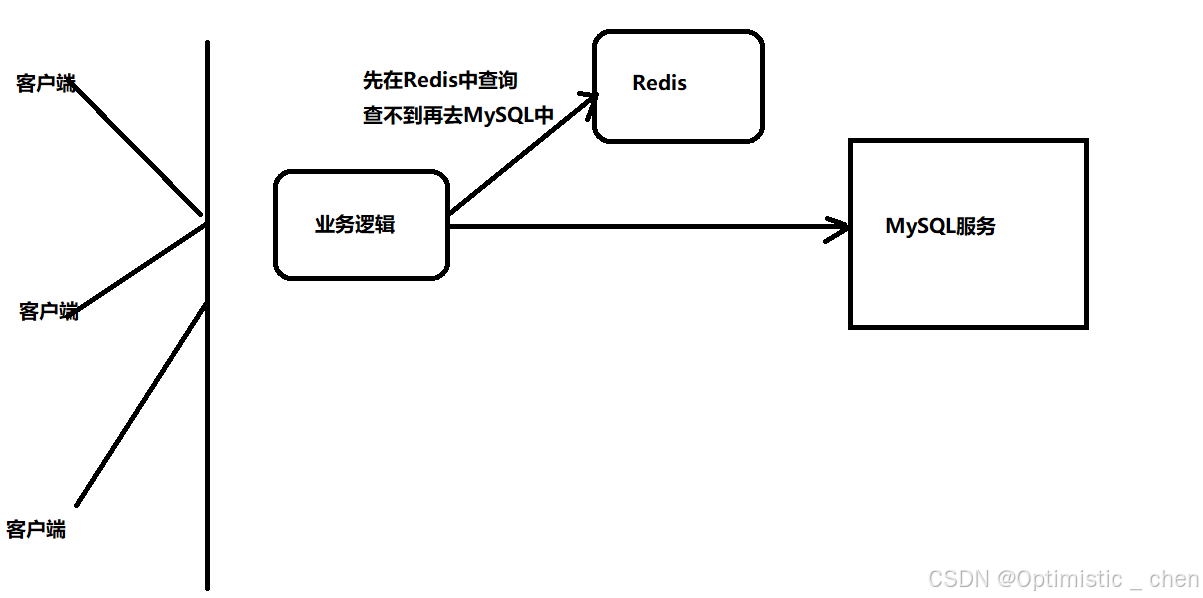
根据实际情况,在Redis中存放20%的热点数据,就应该可以响应80%的请求。
注意:缓存是⽤来加快"读操作"的速度的.如果是"写操作",还是要⽼⽼实实写数据库,缓存并不能提⾼性能。
缓存的更新策略
缓存中的数据需要响应80%的请求,那么如何才能筛选出这些数据呢?
添加热点数据
- 定期生成:.每隔一定周期,对于访问数据的频次进行统计,挑选出访问频次最高的前20%(这个值根据实际情况修改)数据。
- 实时生成:首先用户每次的查询如果在Redis中查到了,就直接返回
如果没有查到,就去数据库中查询,同时把结果也写入到Redis中。
经过一段时间后,Redis空间可能就放不下那么多数据,就触发淘汰策略,把访问频次较低的数据从Redis中删除
这样持续一段时间,Redis中的数据就是热点数据了。
淘汰数据策略
- 不进行数据淘汰策略(默认):不淘汰策略,写入时返回错误
- 进行数据淘汰策略:
在设置了过期时间的数据中进行淘汰:volatile-random: 随机淘汰设置了过期时间的任意键值
volatile-ttl:优先淘汰更早过期的键值
volatile-lru:淘汰所有设置了过期时间的键值中,最久未使用的键值
volatile-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值
在所有数据范围内进行淘汰:allkeys-random:随机淘汰任意键值
allkeys-lru:淘汰整个键值中最久未使用的键值
allkeys-lfu(4.0后):淘汰整个键值中最少使用的键值。
缓存的应用问题
缓存预热
使用Redis作为MySQL 的缓存的时候,当Redis刚刚启动的时候,因为Redis自身是没有数据的,没有什么缓存数据,那么MySQL就可能被直接访问,从而造成较大压力。
因此就需要提前把热点数据准备好,直接写入到Redis中,使用Redis尽可能早的缓解数据库压力。虽然这份热点数据不一定那么准确,只要帮助MySQL抵挡一部分请求即可;随着程序运行,缓存中的热点会自动调整来适应当前业务。
缓存穿透
访问的数据在Redis和MySQL中都不存在。此时这样的key键不会放到缓存上,后续如果继续访问该数据依旧会直接访问到MySQL上,这就是缓存穿透。长此以往,数据库就会承担越来越多的请求。
解决方案:
- 针对要查询的参数进行严格的合法校验,避免非法数据的查询
- 针对数据库上也不存在的key,也可以存储到Redis中,value设置为空,避免后续继续访问
- 使用布隆过滤器先判定key是否存在,在去查询
缓存雪崩
缓存雪崩:短时间内大量的key在缓存中失效,导致数据库压力暴增,可能导致宕机,直接奔溃。
大量key失效,主要有两种可能性:
- Redis 挂了
- Redis上大量的key同时过期
解决方案:
- 部署高可用的Redis集群,完善监控报警体系
- 不给key设置过期时间或者设置随机的过期时间
缓存击穿(瘫痪)
算是缓存雪崩的一种特殊情况。针对热点数据key突然同时大量过期,导致请求都直接访问到数据库上,甚至引起数据库宕机。
解决方案:
- 基于统计的方式设置热点key,并设置永不过期
- 进⾏必要的服务降级.例如访问数据库的时候使⽤分布式锁,限制同时请求数据库的并发数。
完结撒花!🎉
如果这篇博客对你有帮助,不妨点个赞支持一下吧!👍
你的鼓励是我创作的最大动力~
✨ 想获取更多干货? 欢迎关注我的专栏 → optimistic_chen
📌 收藏本文,下次需要时不迷路!
我们下期再见!💫 持续更新中......
悄悄说:点击主页有更多精彩内容哦~ 😊
