目录
[6.洛谷--- JLOI2011 不重复数字](#6.洛谷--- [JLOI2011] 不重复数字)
[7.洛谷--- USACO16DEC Cities and States S](#7.洛谷--- [USACO16DEC] Cities and States S)
1.哈希表的概念
哈希表,又称散列表,是根据关键字进行访问的数据结构。
它建立了一种关键字和存储地址之间的映射关系,使每个关键字和结构中的唯一存储位置相对应
该函数记作 hash(key) = addr,hash('b') = 'b' - 'a' 代表b这个key和a去相减后,数组存在下标为1处,那么就是映射关系和地址对应
哈希表的初始值一般是无穷大INF(整型最大值)
哈希冲突:
对于 6,1007,1007 这个数组来说,如果我们用hashkey = key%7 作为哈希函数,那么三个数组元素的存储位置都是6,出现了存储位置的冲突。下标6到底存哪个元素呢?要打架了,就称为哈希冲突
哈希冲突无法避免,而是需要设计出优秀的哈希函数,尽量避免冲突
2.常见的哈希函数
- 直接定址法:hashkey = key 或者 hashkey = a×key + b
- 除留余数法:hashkey = key % m。key为负数时,在C++当中会是一个负数结果;所以,我们需要取模以后,加上一个N值(除数),即 key % N + N,来抵消取模为负的情况;当整数取模时,加上N值以后与原结果不符,所以需要 (key % N + N) % N
- 乘法散列法、全域散列法......
3.处理哈希冲突
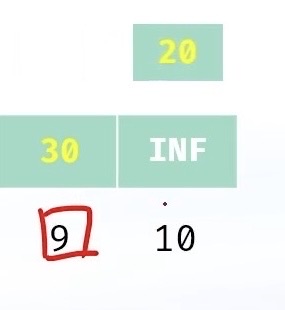
- 线性探测:从发生冲突的位置开始,依次线性向后探测,直到寻找到下一个没有存储数据的位置为止,如果走到哈希表尾,则回绕到哈希表头的位置;如下所示,若30、20发生了哈希冲突,当30先存20后存的话,20就存到30的后面一个空位中。这种办法下,如果存的数很密集时,那么就会出现非常多次的哈希冲突,所以创建一个大一点数组可以解决这种问题。
- 链地址法:所有数据不再直接存储在哈希表中,哈希表中只存一个指针,无数据映射时,指针为空,有多个数据映射到这个位置时,把冲突的数据链成一个链表,挂在哈希表这个位置下面。当所有元素都是相同的地址映射,那么某一下标下就要存储过大的链表。
4.模拟实现哈希表
- 线性探测法的哈希表创建与使用
cpp
#include<iostream>
#include<cstring>
using namespace std;
const int N = 25;
int h[N];
const int INF = 0x3f3f3f3f;
void init()
{
memset(h,INF,sizeof(h));
}
//返回映射的位置
int f(int x)
{
int id = (x%N+N)%N;//id为存入位置
//处理哈希冲突(1.当前位置已经存数,2.该数已经存储过一次)
while(h[id]!=INF&&h[id]!=x)
{
id++;
if(id == N) id=0;//处理id越界
}
return id;
}
void insert(int x)
{
int idx = f(x);//获取存放位置
h[idx] = x;
}
bool find(int x)
{
int idx = f(x);
return h[idx] == x;
}
int main()
{
//初始化
init();
int n;cin>>n;
//开始插入与查找
while(n--)
{
int op,x;cin>>op>>x;
if(op==1) insert(x);
else
{
if(find(x))cout<<"YES"<<endl;
else cout<<"NO"<<endl;
}
}
return 0;
}- 链地址法的哈希表创建与使用
cpp
#include<iostream>
using namespace std;
const int N = 25;
int h[N];//哈希表
int ne[N],e[N],id;
int f(int x)
{
//查找位置
return (x%N+N)%N;
}
void insert(int x)
{
int idx = f(x);
//插入
id++;
e[id] = x;
//解决冲突 (链表在idx位置处,进行头插)
ne[id] = h[idx];
h[idx] = id;//更新头节点
}
bool find(int x)
{
int idx = f(x);
for(int i=h[idx];i;i=ne[i])
{
if(e[i] == x) return true;
}
return false;
}
int main()
{
int n;cin>>n;
//开始插入与查找
while(n--)
{
int op,x;cin>>op>>x;
if(op==1) insert(x);
else
{
if(find(x))cout<<"YES"<<endl;
else cout<<"NO"<<endl;
}
}
return 0;
} 5.unordered_set与unordered_map
- unordered_set 与 set 的区别在于:前者哈希表实现,后者红黑树实现。存储和查找效率不同,前者O(1),后者O(logN)。以及遍历的顺序,前者无序后者有序。其他都是一样的
- unordered_map 与 map 的区别基本就上面这些
- unordered_map 可以用来存图,<int,vector<int>> 类型的数据,查询和存储效率更高
- 同时,unordered_map与unordered_set都多出了一个clear函数,代表清空整个哈希表
6.洛谷--- JLOI2011 不重复数字
代码:
cpp
#include<iostream>
#include<unordered_set>
using namespace std;
int main()
{
int T;cin>>T;
unordered_set<int> h;
while(T--)
{
h.clear();
int n;cin>>n;
while(n--)
{
int in;cin>>in;
if(!h.count(in))
{
h.insert(in);
cout<<in<<" ";
}
}
cout<<endl;
}
return 0;
}代码问题:
用这个代码去提交之后,会发现有4个测试用例超时了,这是因为cin、cout会导致时间开销过大,所以把cin、cout都换成scanf和printf即可
7.洛谷--- USACO16DEC Cities and States S
本题需要注意的点是,AAC->CA & AAB->CA 代表两种不同的情况,如果出现了 CAA->AA 那么应该获得两对的结果而非一对。但也可能会出现AAD->FA的情况,所以需要写一个sum函数进行判断是否符合情况。
所以哈希表的对应关系应该为<string,vector<string>>
题目中提到两个城市来自于两个不同的州,所以当AAB->AA & AAC->AA 这种情况虽然满足特性,但因为来自同一个州所以还是得排除在外
提示:当我们觉得代码完全没问题,但死活不过时,可以通过再念两遍题目来看看有没有条件漏了或理解错了
代码:
cpp
#include<iostream>
#include<unordered_map>
#include<string>
#include<vector>
using namespace std;
void sum(int& ret,string in,vector<string> states)
{
for(auto st:states)
if(in==st) ret++;
}
int main()
{
int n;cin>>n;
unordered_map<string,vector<string>> h;//前两个字母对应州名
string st,sta;cin>>st>>sta;
h[st.substr(0,2)].push_back(sta);
n--;
int ret=0;
while(n--)
{
string name,state;cin>>name>>state;
string in = name.substr(0,2);
if(in==state)continue;
if(h.count(state)) sum(ret,in,h[state]);
h[in].push_back(state);
}
cout<<ret;
return 0;
}